Falcon 登陸 Hugging Face 生態
引言
Falcon 是由位於阿布扎比的 技術創新研究院 (Technology Innovation Institute,TII) 建立的一系列的新語言模型,其基於 Apache 2.0 許可釋出。 值得注意的是,Falcon-40B 是首個「真正開放」的模型,其能力可與當前許多閉源模型相媲美。這對從業者、愛好者和行業來說都是個好訊息,因為「真開源」使大家可以毫無顧忌地基於它們探索百花齊放的應用。
本文,我們將深入探討 Falcon 模型: 首先探討它們的獨特之處,然後 展示如何基於 Hugging Face 生態提供的工具輕鬆構建基於 Falcon 模型的多種應用 (如推理、量化、微調等) 。
目錄
Falcon 模型
Falcon 家族有兩個基礎模型: Falcon-40B 及其小兄弟 Falcon-7B。 40B 引數模型目前在 Open LLM 排行榜 中名列前茅,而 7B 模型在同等引數量的模型中表現最佳。
執行 Falcon-40B 需要約 90GB 的 GPU 視訊記憶體 —— 雖然還是挺多的,但比 LLaMA-65B 少了不少,況且 Falcon-40B 的效能還優於 LLaMA-65B。而 Falcon-7B 只需要約 15GB 視訊記憶體,即使在消費類硬體上也可以進行推理和微調。 (我們將在後文討論如何使用量化技術在便宜的 GPU 上使用 Falcon-40B!)
TII 還提供了經過指令微調的模型: Falcon-7B-Instruct 以及 Falcon-40B-Instruct。這兩個實驗性的模型變體經由指令和對話資料微調而得,因此更適合當前流行的助理式任務。 如果你只是想把 Falcon 模型快速用起來,這兩個模型是最佳選擇。 當然你也可以基於社群構建的大量資料集微調一個自己的模型 —— 後文會給出微調步驟!
Falcon-7B 和 Falcon-40B 分別基於 1.5 萬億和 1 萬億詞後設資料訓練而得,其架構在設計時就充分考慮了推理優化。 Falcon 模型質量較高的關鍵在於訓練資料,其 80% 以上的訓練資料來自於 RefinedWeb —— 一個新的基於 CommonCrawl 的網路資料集。 TII 選擇不去收集分散的精選資料,而是專注於擴充套件並提高 Web 資料的質量,通過大量的去重和嚴格過濾使所得語料庫與其他精選的語料庫質量相當。 在訓練 Falcon 模型時,雖然仍然包含了一些精選資料 (例如來自 Reddit 的對話資料),但與 GPT-3 或 PaLM 等最先進的 LLM 相比,精選資料的使用量要少得多。你知道最妙的是什麼嗎? TII 公佈了從 RefinedWeb 中提取出的含有 6000 億詞元的資料集,以供社群在自己的 LLM 中使用!
Falcon 模型的另一個有趣的特性是其使用了 多查詢注意力 (multiquery attention)。原始多頭 (head) 注意力方案每個頭都分別有一個查詢 (query) 、鍵 (key) 以及值 (value),而多查詢注意力方案改為在所有頭上共用同一個鍵和值。
 |
|---|
| 多查詢注意力機制在注意力頭之間共用同一個鍵嵌入和值嵌入。圖片由 Harm de Vries 提供。 |
這個技巧對預訓練影響不大,但它極大地 提高了推理的可延伸性: 事實上, 該技巧大大減少了自迴歸解碼期間 K,V 快取的記憶體佔用,將其減少了 10-100 倍 (具體數值取決於模型架構的設定),這大大降低了模型推理的記憶體開銷。而記憶體開銷的減少為解鎖新的優化帶來了可能,如省下來的記憶體可以用來儲存歷史對話,從而使得有狀態推理成為可能。
| 模型 | 許可 | 能否商用? | 預訓練詞元數 | 預訓練算力 [PF-天] | 排行榜得分 | K,V 快取大小 (上下文長度為 2048) |
|---|---|---|---|---|---|---|
| StableLM-Alpha-7B | CC-BY-SA-4.0 | ✅ | 1,500B | 700 | 38.3* | 800MB |
| LLaMA-7B | LLaMA license | ❌ | 1,000B | 500 | 47.6 | 1,100MB |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 500 | 48.6 | 1,100MB |
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 700 | 48.8 | 20MB |
| LLaMA-33B | LLaMA license | ❌ | 1,500B | 3200 | 56.9 | 3,300MB |
| LLaMA-65B | LLaMA license | ❌ | 1,500B | 6300 | 58.3 | 5,400MB |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 2800 | 60.4 | 240MB |
- 上表中得分均為經過微調的模型的得分
演示
通過 這個 Space 或下面的應用,你可以很輕鬆地試用一下大的 Falcon 模型 (400 億引數!):
請點選 閱讀原文 檢視互動式範例。
上面的應用使用了 Hugging Face 的 Text Generation Inference 技術,它是一個可延伸的、快速高效的文字生成服務,使用了 Rust、Python 以及 gRPC 等技術。HuggingChat 也使用了相同的技術。
我們還構建了一個 Core ML 版本的 falcon-7b-instruct 模型,你可以通過以下方式將其執行至 M1 MacBook Pro:

請點選 閱讀原文 觀看視訊。
該視訊展示了一個輕量級應用程式,該應用程式利用一個 Swift 庫完成了包括載入模型、分詞、準備輸入資料、生成文字以及解碼在內的很多繁重的操作。我們正在快馬加鞭構建這個庫,這樣開發人員就能基於它將強大的 LLM 整合到各種應用程式中,而無需重新發明輪子。目前它還有點粗糙,但我們迫不及待地想讓它早點面世。同時,你也可以下載 Core ML 的權重檔案 自己探索!
推理
在使用熟悉的 transformers API 在你自己的硬體上執行 Falcon 模型時,你需要注意幾個以下細節:
- 現有的模型是用
bfloat16資料型別訓練的,因此建議你也使用相同的資料型別來推理。使用bfloat16需要你安裝最新版本的 CUDA,而且bfloat16在最新的卡 (如 A100) 上效果最好。你也可以嘗試使用float16進行推理,但請記住,目前我們分享的模型效果資料都是基於bfloat16的。 - 你需要允許遠端程式碼執行。這是因為
transformers尚未整合 Falcon 模型架構,所以,我們需要使用模型作者在其程式碼庫中提供的程式碼來執行。以falcon-7b-instruct為例,如果你允許遠端執行,我們將使用下列檔案裡的程式碼來執行模型: configuration_RW.py,modelling_RW.py。
綜上,你可以參考如下程式碼來使用 transformers 的 pipeline API 載入 falcon-7b-instruct 模型:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
然後,再用如下程式碼生成文字:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
最後,你可能會得到如下輸出:
Valencia, city of the sun
The city that glitters like a star
A city of a thousand colors
Where the night is illuminated by stars
Valencia, the city of my heart
Where the past is kept in a golden chest
對 Falcon 40B 進行推理
因為 40B 模型尺寸比較大,所以要把它執行起來還是挺有挑戰性的,單個視訊記憶體為 80GB 的 A100 都放不下它。如果用 8 位元模型的話,需要大約 45GB 的空間,此時 A6000 (48GB) 能放下但 40GB 的 A100 還是放不下。相應的推理程式碼如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
需要注意的是,INT8 混合精度推理使用的浮點精度是 torch.float16 而不是 torch.bfloat16,因此請務必詳盡地對結果進行測試。
如果你有多張 GPU 卡並安裝了 accelerate,你還可以用 device_map="auto" 將模型的各層自動分佈到多張卡上執行。如有必要,甚至可以將某些層解除安裝到 CPU,但這會影響推理速度。
在最新版本的 bitsandbytes、transformers 以及 accelerate 中我們還支援了 4 位元載入。此時,40B 模型僅需約 27GB 的視訊記憶體就能執行。雖然這個需求還是比 3090 或 4090 這些卡所能提供的視訊記憶體大,但已經足以在視訊記憶體為 30GB 或 40GB 的卡上執行了。
Text Generation Inference
Text Generation Inference 是 Hugging Face 開發的一個可用於生產的推理容器。有了它,使用者可以輕鬆部署大語言模型。
其主要特點有:
- 對輸入進行流式 batch 組裝 (batching)
- 流式生成詞,主要基於 SSE 協定 (Server-Sent Events,SSE)
- 推理時支援多 GPU 張量並行 (Tensor Parallelism ),推理速度更快
- transformers 模型程式碼由客製化 CUDA 核函數深度優化
- 基於 Prometheus 和 Open Telemetry 的產品級紀錄檔記錄、監控和跟蹤機制
從 v0.8.2 起,Text Generation Inference 原生支援 Falcon 7b 和 40b 模型,而無需依賴 transformers 的 「信任遠端程式碼 (trust remote code)」 功能。因此,Text Generation Inference 可以支援密閉部署及安全審計。此外,我們在 Falcon 模型的實現中加入了客製化 CUDA 核函數優化,這可顯著降低推理的端到端延遲。
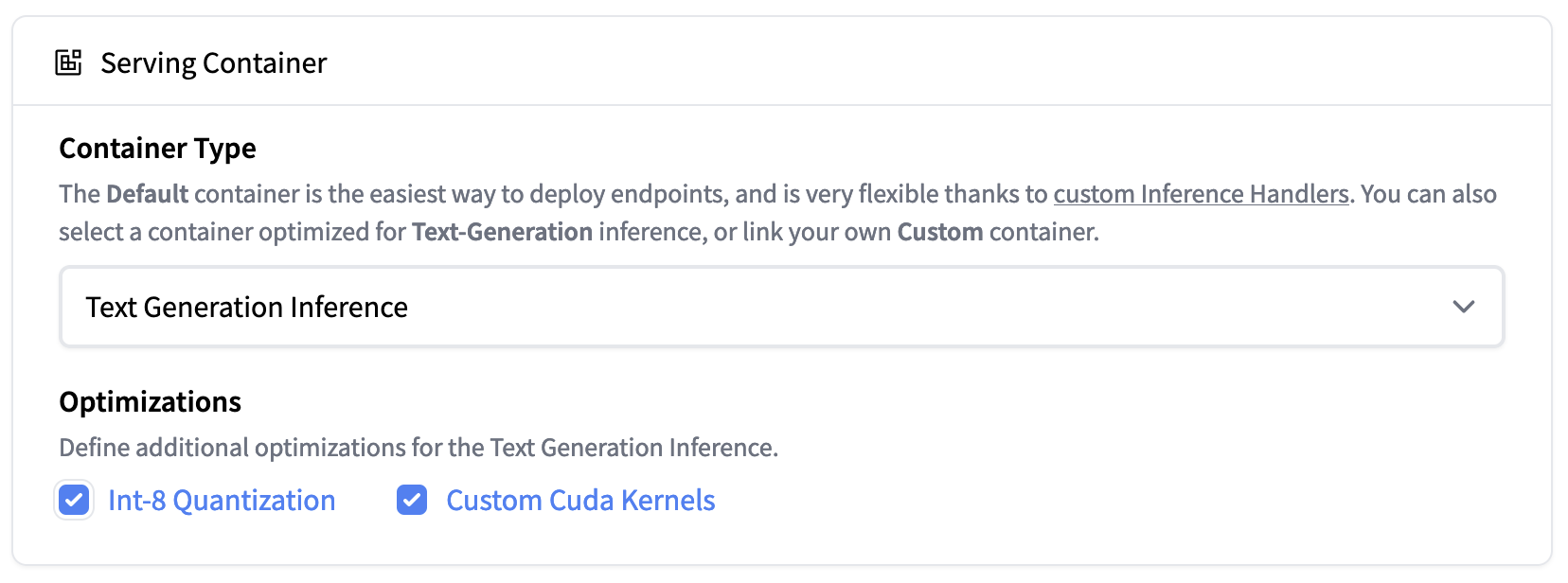 |
|---|
Hugging Face Inference Endpoint 現已支援 Text Generation Inference。你可以在單張 A100 上輕鬆部署 falcon-40b-instruct 的 Int8 量化模型。 |
Text Generation Inference 現已整合至 Hugging Face 的 Inference Endpoint。想要部署 Falcon 模型,可至 模型頁面 並點選 Deploy -> Inference Endpoints 按鈕。
如需部署 7B 模型,建議選擇 「GPU [medium] - 1x Nvidia A10G」。
如需部署 40B 模型,你需要在 「GPU [xlarge] - 1x Nvidia A100」 上部署且需要開啟量化功能,路徑如下:
Advanced configuration -> Serving Container -> Int-8 Quantization
注意: 在此過程中,如果你需要升級配額,可直接發電子郵件至 [email protected] 申請。
評估
那麼 Falcon 模型究竟效果如何? Falcon 的作者們馬上將會發佈一個深入的評估資料。這裡,我們僅在我們的 Open LLM 排行榜 上對 Falcon 基礎模型和指令模型進行一個初步評估。 Open LLM 排行榜主要衡量 LLM 的推理能力及其回答以下幾個領域的問題的能力:
- AI2 推理挑戰 (ARC): 小學程度有關科學的選擇題。
- HellaSwag: 圍繞日常事件的常識性問題。
- MMLU: 57 個科目 (包含職業科目及學術科目) 的選擇題。
- TruthfulQA: 測試模型從一組錯誤陳述中找出事實性陳述的能力。
結果顯示,40B 基礎模型和指令模型都非常強,目前在 Open LLM 排行榜 上分列第一和第二