HTTP請求:requests的進階使用方法淺析
1 背景
上篇文章講解了requests模組的基礎使用,其中有get、put、post等多種請求方式,使用data、json等格式做為請求引數,在請求體中新增請求頭部資訊的常見資訊,如:headers、cookies,以及對請求響應的處理方法。接下來講解一下requests的高階用法。
2 進階方法舉例
2.1 requests.request()
method:提交方式(get|post);
url:提交地址;
kwargs:14個控制存取的引數;
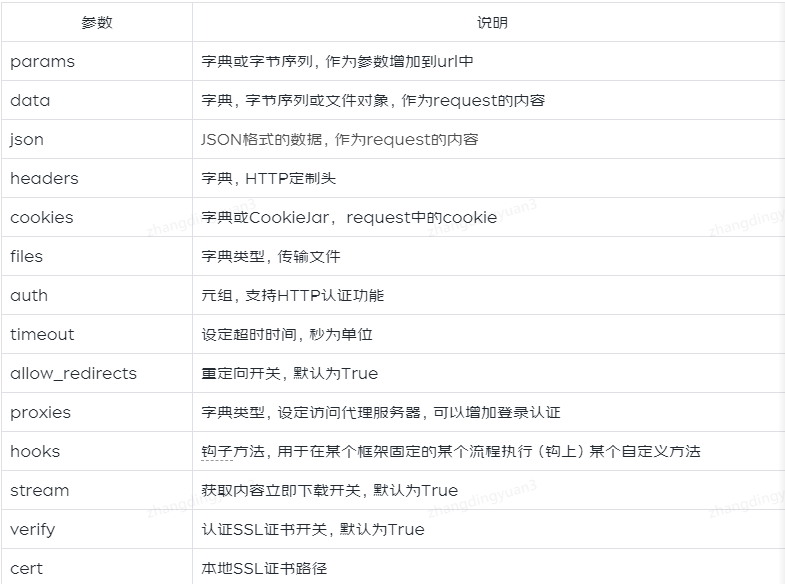
常用的引數有:params、data、json、headers、cookies,已在上篇文章中介紹過了,感興趣的朋友,可以到上篇文章再回顧一下。以下將講解與範例其他引數的使用。
範例:
2.1.1 files
請求攜帶檔案,如果有的請求需要上傳檔案,可以用它來實現。
import requests
# 上傳檔案
f= {"files": open("favicon.ico", "rb") }
data = {"name": "上傳檔案"}
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
data = data,
files = f
)
需注意:favicon.ico檔案需和當前指令碼在同一目錄下,如果不在,可以將檔名稱修改為檔案路徑
import requests
from requests.auth import HTTPBasicAuth, HTTPDigestAuth
# 1、Basic Auth認證
res = requests.request(
method = 'GET',
url = 'http://127.0.0.1:8080/example/request',
auth = HTTPBasicAuth("username", "password")
)
res.encoding = "gbk"
print(res.status) # 200
# 2、DIGEST 認證
res = requests.request(
method = 'GET',
url = 'http://127.0.0.1:8080/example/request',
auth = HTTPDigestAuth("username", "password")
)
res.encoding = "gbk"
print(res.status) # 200
http auth認證的兩種方式,分別為Basic方式和Digest認證,其中:Basic Auth的優點是提供簡單的使用者驗證功能,其認證過程簡單明瞭,適合於對安全性要求不高的系統或裝置中;同樣存在缺點:輸入的使用者名稱,密碼 base64編碼後會出現在Authorization裡,很容易被解析出來。
那麼Digest對比Basic認證有什麼不同呢?
- Digest思想,是使用一種亂數字串,雙方約定好對哪些資訊進行雜湊運算,即可完成雙方身份的驗證。Digest模式避免了密碼在網路上明文傳輸,提高了安全性,但它依然存在缺點,例如認證報文被攻擊者攔截到攻擊者可以獲取到資源。
- DIGEST 認證提供了高於 BASIC 認證的安全等級,但是和 HTTPS 的使用者端認證相比仍舊很弱。
- DIGEST 認證提供防止密碼被竊聽的保護機制,但並不存在防止使用者偽裝的保護機制。
- DIGEST 認證和 BASIC 認證一樣,使用上不那麼便捷靈活,且仍達不到多數 Web 網站對高度安全等級的追求標準。因此它的適用範圍也有所受限。
2.1.2 timeout
請求和響應的超時時間,在網路響應延遲或者無響應時,可以通過設定超時時間,避免等待。
import requests
# 設定請求超時1秒,1秒後無響應,將丟擲異常,1秒為connect和read時間總和
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
json = {'k1' : 'v1', 'k2' : 'v2'},
timeout = 1
)
# 分別設定connect和read的超時時間,傳入一個陣列
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
json = {'k1' : 'v1', 'k2' : 'v2'},
timeout = (5, 15)
)
# 永久等待
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
json = {'k1' : 'v1', 'k2' : 'v2'},
timeout = None
# 或者刪除timeout引數
)
# 捕捉超時異常
from requests.exceptions import ReadTimeout
try:
res = requests.get('http://127.0.0.1:8080/example/request', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print("捕捉到超時異常")
2.1.3 allow_redirects
設定重定向開關。
>>> import requests
>>> r = requests.get('http://github.com')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[<Response [301]>]
# 如果使用GET、OPTIONS、POST、PUT、PATCH或DELETE,則可以使用allow_redirects引數禁用重定向
>>> r = requests.get('http://github.com', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
# 用HEAD啟動重定向
>>> r = requests.head('http://github.com', allow_redirects=True)
>>> r.url
'https://github.com/'
>>> r.history
[<Response [301]>]
import requests
import re
# 第一次請求
r1=requests.get('https://github.com/login')
r1_cookie=r1.cookies.get_dict() #拿到初始cookie(未被授權)
authenticity_token=re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0] #從頁面中拿到CSRF TOKEN
# 第二次請求:帶著初始cookie和TOKEN傳送POST請求給登入頁面,帶上賬號密碼
data={
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':authenticity_token,
'login':'[email protected]',
'password':'password'
}
# 測試一:沒有指定allow_redirects=False,則響應頭中出現Location就跳轉到新頁面,
# r2代表新頁面的response
r2=requests.post('https://github.com/session',
data=data,
cookies=r1_cookie
)
print(r2.status_code) # 200
print(r2.url) # 看到的是跳轉後的頁面
print(r2.history) # 看到的是跳轉前的response
print(r2.history[0].text) # 看到的是跳轉前的response.text
# 測試二:指定allow_redirects=False,則響應頭中即便出現Location也不會跳轉到新頁面,
# r2代表的仍然是老頁面的response
r2=requests.post('https://github.com/session',
data=data,
cookies=r1_cookie,
allow_redirects=False
)
print(r2.status_code) # 302
print(r2.url) # 看到的是跳轉前的頁面https://github.com/session
print(r2.history) # []
2.1.4 proxies
同新增headers方法一樣,代理引數是dict。
import requests
import re
def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html
def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="型別">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('代理')
print(sumray)
if __name__ == '__main__':
url = 'http://www.baidu.com'
get_ipport(get_html(url))
某些介面增加了防騷擾模式,對於大規模且頻繁的請求,可能會彈出驗證碼,或者跳轉到登入驗證頁面,或者封禁IP地址,此時如果想要正常存取,可以通過設定代理來解決這個問題。
除了基本的HTTP代理外,requests還支援SOCKS協定的代理。
# 安裝socks庫
pip3 install "requests[socks]"
# 進行代理
import requests
proxies = {
'http': 'socks5://user:password@host:port',
'https': 'socks5://user:password@host:port'
}
res = requests.get('http://www.baidu.com', proxies=proxies)
print(res.status) # 200
2.1.5 hooks
即勾點方法,requests庫只支援一個response的勾點,即在響應返回時,可以捎帶執行自定義方法。可以用於列印一些資訊、做一些響應檢查、或者向響應中新增額外的資訊。
import requests
url = 'http://www.baidu.com'
def verify_res(res, *args, **kwargs):
print('url', res.url)
res.status='PASS' if res.status_code == 200 else 'FAIL'
res = requests.get(url, hooks={'response': verify_res})
print(res.text) # <!DOCTYPE html><!--STATUS OK--><html>
print(res.status) # PASS
2.1.6 stream
獲取內容立即下載開關,response會將報文一次性全部載入到記憶體中,如果報文過大,可以使用此引數,迭代下載。
import requests
url="http://www.baidu.com"
r = requests.get(url, stream=True)
# 解析response_body,以\n分割
for lines in r.iter_lines():
print("lines:", lines)
# 解析response_body,以位元組分割
for chunk in r.iter_content(chunk_size=1024):
print("chunk:", chunk)
2.1.7 verify
認證SSL證書開關,當傳送HTTPS請求的時候,如果該網站的證書沒有被CA機構信任,程式將報錯,可以使用verify引數控制是否檢查SSL證書。
# 1、直接設定
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
# 2、請求時雖然設定了跳過檢查,但是程式執行時仍然會產生警告,警告中包含建議給我們的指定證書
# 可以通過設定,忽略遮蔽這個警告
from requests.packages import urllib3 # 如果報錯,則直接引入import urllib3
# 3、遮蔽警告
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code) # 200
# 4、通過cert直接宣告證書
# 本地需要有crt和key檔案(key必須是解密狀態,加密狀態的key是不支援的),並指定它們的路徑,
response = requests.get('https://www.12306.cn',cert('/path/server.crt','/path/key'))
print(response.status_code) # 200
2.2 requests庫的異常
如何判斷是否出現異常呢?
2.2.1 raise_for_status()
該方法在內部判斷res.status_code是否等於200,不是則產生異常HTTPError
範例:
# 1、HTTPError異常範例
import requests
from requests.exceptions import HTTPError
try:
res = requests.post("http://127.0.0.1:8080/example/post")
res.raise_for_status()
# 等同於
if res.status != 200:
raise HTTPError
return res
except HTTPError:
return False
2.2.2 ReadTimeout
該異常型別,將會捕捉到因請求/響應超時的請求。
# Timeout超時異常
import requests
from requests.exceptions import ReadTimeout
try:
res = requests.get('http://127.0.0.1:8080/example/post',timeout=0.5)
print(res.status_code)
return res
except ReadTimeout:
print('timeout')
2.2.3 RequestException
該異常型別,將會捕捉到因無請求引起的異常請求。
# RquestError異常
import requests
from requests.exceptions import RequestException
try:
res = requests.get('http://127.0.0.1:8080/example/post')
print(res.status_code)
return res
except RequestException:
print('reqerror')
3 總結
看到這裡,大家應該明白了,requests庫是一個比urilib2模組更加簡潔的第三方庫,它具有如下的特點:
- 支援HTTP連線保持和連線池
- 支援使用cookie、session保持對談
- 支援檔案上傳
- 支援自動響應內容的編碼
- 支援國際化的URL和Post資料自動編碼
- 支援自動實現持久連線keep-alive
因此,requests這個高度封裝的模組,可以使我們的HTTP請求,變得更加人性化,使用它將可以輕而易舉的完成瀏覽器請求的任何操作,充分詮釋了它的口號:「HTTP for Humans」。
作者:京東物流 駱銅磊
來源:京東雲開發者社群