記一次加鎖導致ECS伺服器CPU飆高的處理
導航
- 火線告警,CPU飈了
- 版本回退,迅速救火
- 猜測:分散式鎖是罪魁禍首
- 程式碼重構,星夜上線
- 防患未然,功能可開關
- 高度戒備,應對早高峰
- 實時調整方案,穩了
- 結語
- 參考
本文首發於智客工坊-《記一次加鎖導致ECS伺服器CPU飆高分析》,感謝您的閱讀,預計閱讀時長3min。
每一次版本的上線都應該像火箭發射一樣嚴肅,同時還需要準備一些預案。
前言
此前,我曾在《對幾次通宵加班發版的覆盤和思考》文中,表達過"每一次版本上線都應該像火箭發射一樣嚴肅"的觀點。與此同時,我也分析其中的原因並提出相應的解決方案。
我堅信,那篇文章中的措施和方案已經覆蓋發版中遭遇的大部分場景。
儘管我們總是保持對技術的敬畏之心,每次發版也會驗證的比較充分,仍然會有一些相對不太容易預知的事情發生。
所以,我將"火箭發射"觀點改成了"每一次版本的上線都應該像火箭發射一樣嚴肅,同時還需要準備一些預案"。
火線告警,CPU飈了
如果你很難定位線上的問題,快速回退是一個好辦法。
在多年的職業歷練中,我養成了一個習慣——每次執行完發版任務的第二天,都會積極關注公司相關業務群的動向,並儘可能早的到公司。
這一天,和往常一樣,我在早高峰的路上奮力前行,突然群裡閃現出一條業務方發出的訊息。
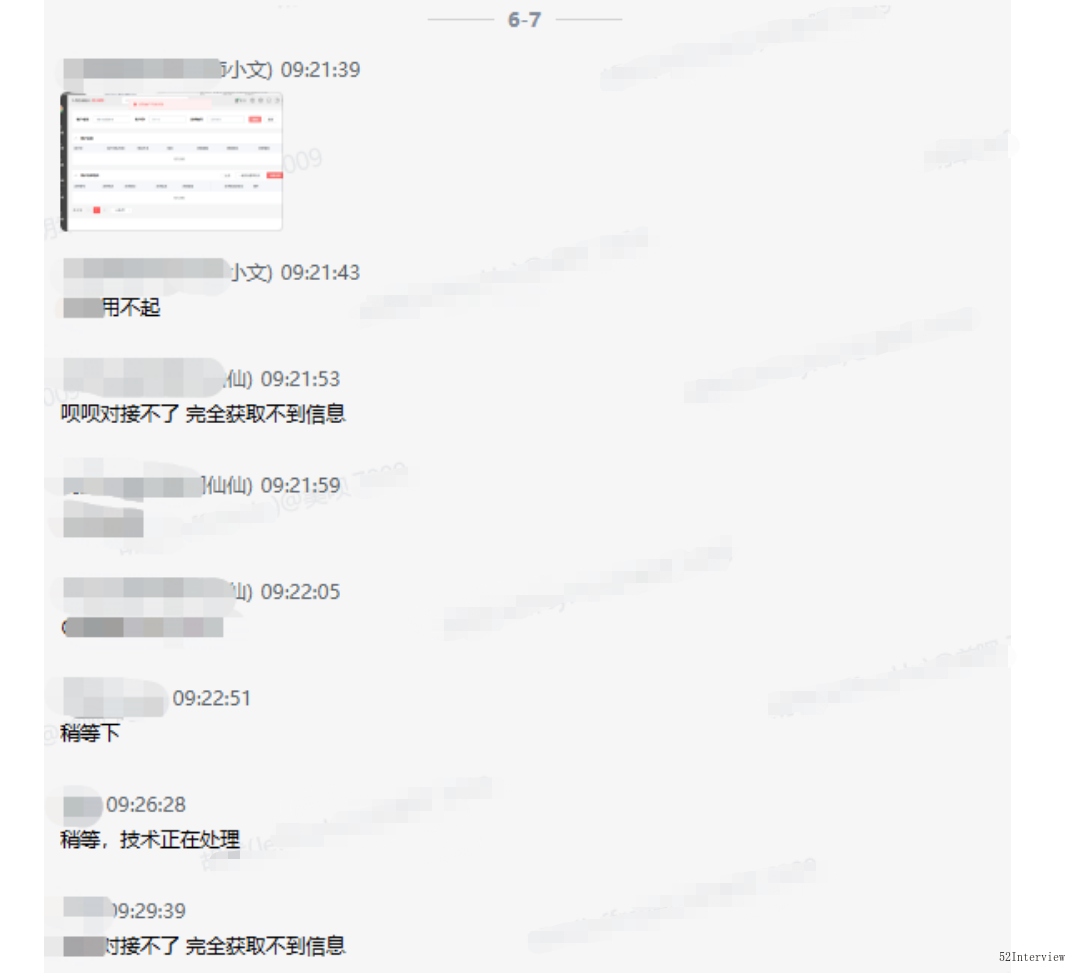
隨即便是更多的業務對接群開始炸鍋。
前段時間因為資料庫效能問題,已經出現了幾次線上宕機的情況,被使用者吐槽。(為啥出現效能問題,此處省略若干字,後續有機會再娓娓道來)。
所以,每次今天再次遇到這樣的問題,我們總是顯得很被動。
我和業務團隊的同事一邊安撫使用者的情緒,一邊快馬加鞭奔赴公司。
火速趕到公司之後,檢視了報警紀錄檔,發現部署該業務介面的ecs CPU飆高了...
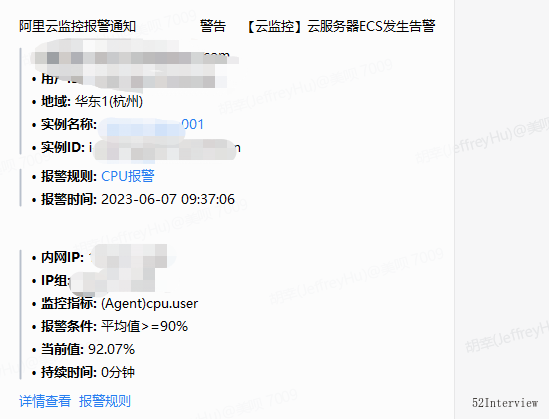

當機立斷,回滾到上一版本。
大約一分鐘之後,我們驗證了可用性,並檢視ecs和資料庫各項指標,正常。
於是大家一一回復了使用者群,對接群終於安靜了。
猜測:分散式鎖是罪魁禍
大膽假設,小心求證。
程式碼回滾之後一切變得正常,我們可以斷定此次線上問題的一定是和昨晚的發版有關。
但是,是哪個功能或者那句程式碼引發了ecs cpu標高呢?
第一時間閃現在腦海裡面的就是「一鍵已讀」功能。
該功能的程式碼大致如下(已脫敏):
@Override
public void oneKeyRead(OneKeyReadBo bo) {
//...
//1. 拉取的未讀的對談(群聊)
List<Long> unReadChatIds = listUnReadChatIds(loginUser.getUserId());
if (CollectionUtil.isEmpty(unReadChatIds)) {
log.info("當前使用者沒有未讀對談!");
return;
//2. 迴圈處理單個群的訊息已讀
CompletableFuture.runAsync(
() -> {
processOneKeyReadChats(realUnReadChatIds, loginUser);
})
.exceptionally(
error -> {
log.error("批次處理未讀的群對談異常:" + error, error);
return null;
});
}
@Resource
private Executor taskExecutor;
private void processOneKeyReadChats(List<Long> realUnReadChatIds, User loginUser) {
//迴圈處理單個群的訊息已讀
for (Long groupChatId : realUnReadChatIds) {
OneKeyReadMessageBo oneKeyReadMessageBo=new OneKeyReadMessageBo();
//...省略一些程式碼
oneKeyReadMessage(oneKeyReadMessageBo);
}
}
/**
* 單獨處理一個群的訊息已讀
*/
private void oneKeyReadMessage(OneKeyReadMessageBo bo) {
// 批次已讀,按對談加鎖
String lockCacheKey = StrUtil.format("xxx:lock:{}:{}", bo.getUserId(), bo.getChatId());
RLock lock = redissonClient.getLock(lockCacheKey);
boolean success = false;
try {
success = lock.tryLock(10, TimeUnit.SECONDS);
} catch (InterruptedException ignored) {
}
if (!success) {
log.info(StrUtil.format("使用者: {}, 訊息: {}, 訊息一鍵已讀失敗", bo.getUserId(), bo.getChatId()));
throw new BizException("訊息已讀失敗");
}
try {
//1. ack 已讀
//...省略若干程式碼
//2.chatmember已讀
//...省略若干程式碼
//3.groupMsg已讀
//...省略若干程式碼
} finally {
lock.unlock();
}
}
從上面的程式碼可以看出來,迴圈的最底層使用了分散式鎖,且鎖的時長是10s。
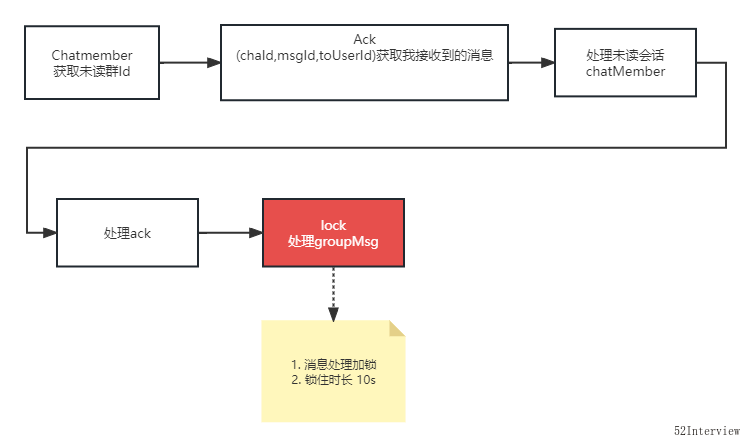
綜上可以推斷, ecs cpu爆高是底層訊息處理加鎖導致。
程式碼重構,星夜上線
重構應隨時隨地進行。
過去我們總是對舊專案中的「老程式碼」嗤之以鼻。回頭看自己寫過的程式碼,難免有點"時候諸葛亮"的意思。
在這次的版本中,為了節省時間,從專案中別處複用了處理groupMsg的程式碼(複製貼上確實很爽)。
但是,忽略了那個加鎖的方法在單個對談的處理是適合的,卻不適合大批次的處理。
於是對程式碼進行重構。
主要是如下幾個改進:
-
處理未讀對談提前,批次並使用同步的方式執行,後續流程非同步處理。
這樣做其實是為了快速相應前端,且前端立馬重新整理列表,讓使用者能夠感知到群對談的未讀數已經清除。 -
將unReadChatIds分批次處理,每次最大處理1000個。防止單次處理的未讀對談過大,最終到unReadMsg上訊息處理量控制在一萬以內。(Mysql in 的數量進行控制)。
-
訊息未讀數處理取消鎖。
大致程式碼如下:
@Override
public void oneKeyRead(OneKeyReadBo bo) {
//1. 拉取的未讀的對談(群聊)
List<Long> unReadChatIds = listMyUnReadChatIds(loginUser.getUserId(), bo.getBeginSendTime(), bo.getEndSendTime());
if (CollectionUtil.isEmpty(unReadChatIds)) {
log.info("當前使用者沒有未讀對談!");
return;
}
// 同步處理clear notify
batchClearUnreadCount(unReadChatIds, loginUser.getUserId());
//2. ack+groupMsg已讀
CompletableFuture.runAsync(
() -> {
processOneKeyReadChats(unReadChatIds, loginUser);
})
.exceptionally(
error -> {
log.error("批次處理未讀的群對談異常:" + error, error);
return null;
});
}
private void processOneKeyReadChats(List<Long> unReadChatIds, User loginUser) {
//批次處理
int total = unReadChatIds.size();
int pageSize = 1000;
if (total > pageSize) {
RAMPager<Long> pager = new RAMPager(unReadChatIds, pageSize);
System.out.println("unReadChat總頁數是: " + pager.getPageCount());
Iterator<List<Long>> iterator = pager.iterator();
while (iterator.hasNext()) {
List<Long> curUnReadChatIds = iterator.next();
if (CollectionUtil.isEmpty(curUnReadChatIds)) {
continue;
}
batchReadMessage(curUnReadChatIds, loginUser);
}
} else {
batchReadMessage(unReadChatIds, loginUser);
}
}
/**
* 批次處理訊息已讀
*/
private void batchReadMessage(List<Long> unReadChatIds, User loginUser) {
try {
//1. 批次ack 已讀
//...省略若干程式碼
//2. groupMsg已讀
//...省略若干程式碼
} catch (Exception ex) {
log.error(StrUtil.format("batchReadMessage 異常,error:{}", ex.getMessage()));
}
}
下班之後,火速上線。
防患未然,功能可開關
儘管從理論上我已經推斷出這個鎖是引發ecs cpu爆高的主要因素。但是,內心依然是忐忑的。
比如,這樣改造之後,到底能有多大的優化下效果?是否能夠抗住明天的早高峰?
如果CPU再次飆高怎麼辦?
看得出來,這個功能上線之後確實受到了客戶的青睞,所以能否抗住明天的早高峰,值得思考。
思考再三,為了能夠線上上遇到問題時,不用發版就能快速處理,我決定臨時給這個功能增加了一個開關。
這樣,當生產環境開始報警的時候,我就可以快速地關閉該功能。
辦法雖笨,但是道理很簡單,非常適合這樣的場景。
高度戒備,應對早高峰
我們的系統主打一個字,穩。
保持系統的穩定性幾乎是IT從業者的共識。
儘管我們已經做了程式碼重構,增加功能開關等工作,心裡依舊是忐忑的。
第二天一大早我就來到公司。隨時盯著各項監控指標,並等待早高峰的來臨。
從9:00開始,已經使用者開始使用我們的"一鍵已讀"功能,但是伺服器CPU使用率沒有飆升,也沒有報警。
觀察了一下資料庫的CPU使用率,逐漸開始走高並接近60%。

可以證明我們的程式碼重構是生效了的,這一點是值得欣慰的。
壓力給到了mysql資料庫,這是預料之中的,但是如果峰值超過90%,大概率會引發我們的系統崩潰。
我幾乎每5s重新整理一次資料庫使用率這個指標,到了09:32,資料庫使用率超過了98%,並且大約持續了1min,仍然在高位,系統已經遊走在崩潰的邊緣。
我迅速關閉了這個"一鍵已讀"功能。
然後,資料庫CPU使用率隨即驟降,迴歸到20%~40%的水平。
可能,您不太理解我為啥如此關注這個指標?
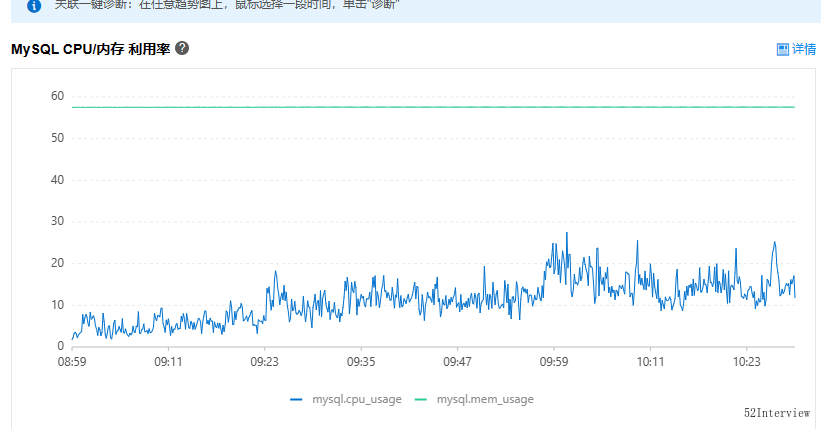
下圖是我們系統正常情況下的資料庫使用率,基本維持在30%以下。
實時調整方案,穩了
那是什麼原因導致資料庫cpu突然飆高呢?
經過排查紀錄檔,發現有人選擇近一個月的對談進行處理。
一個月的未讀對談數量可能超過5000,下沉到群訊息的未讀數量,預計會在1w以上。
而群訊息表的體量大概在2kw左右,這意味著要在這個大表裡面in接近1w個引數。
連續排查發現,凡是選擇一個月時間段的請求,資料庫cpu都會立馬飆升至60%以上。
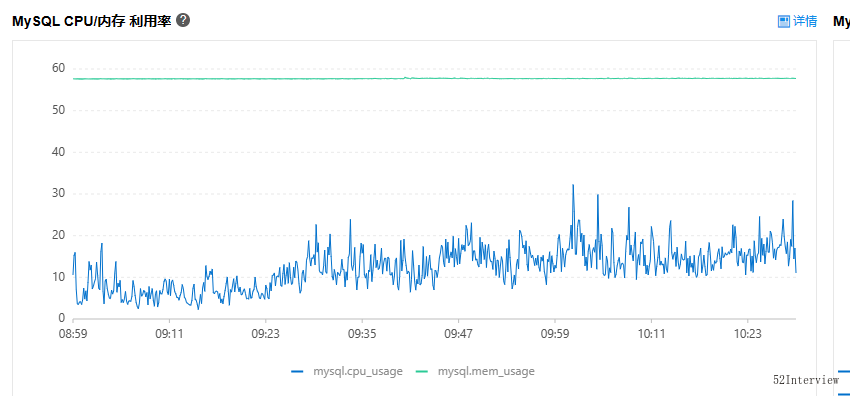
權衡再三,我們立馬將使用者可選擇的時長控制在一週以內(前端控制)。
再次開啟功能,系統各項指標平穩且維持在合理範圍。
至此,對該功能的處理終於完美收官了。
結語
哪有什麼歲月靜好,我們總是在打怪升級中成長。
在多年的職場洗禮之後,逐漸認識到技術並非孤立存在的。
或許對於大眾而言所謂的"技術好",不是單純的賣弄技術,而是能夠針對靈活多變的場景,恰到好處的運用技術。
活到老,學到老。
這裡筆者只根據個人多年的工作經驗,一點點思考和分享,拋磚引玉,歡迎大家怕批評和斧正。
參考
