聲音克隆,精緻細膩,人工智慧AI打造國師「一鏡到底」鬼畜視訊,基於PaddleSpeech(Python3.10)
電影《滿江紅》上映之後,國師的一段採訪視訊火了,被無數段子手惡搞做成鬼畜視訊,誠然,國師的這段採訪文字相當經典,他生動地描述了一個牛逼吹完,大家都信了,結果發現自己沒辦法完成最後放棄,隨後瘋狂往回找補的過程。
最離譜的是,他這段採訪用極其豐富的細節描述了一個沒有發生且沒有任何意義的事情,堪比單口相聲,形成了一種荒誕的美感,毫無疑問,《滿江紅》最大的貢獻就是這個採訪素材了。
往這個文字裡套內容並沒有什麼難度,小學生也可以,但配音是一個瓶頸,也就是說,普通人想染指鬼畜視訊還是有一定門檻的,這個領域往往是專業配音演員的天下,但今時非比往日,人工智慧AI技術可以讓我們基於PaddleSpeech克隆出精緻細膩的國師原聲,普通人也可以玩轉搞笑配音。
資料集準備和清洗
我們的目的是克隆國師的聲音,那麼就必須要有國師的聲音樣本,這裡的聲音樣本和使用so-vits-svc4.0克隆歌聲一樣,需要相對「乾淨」的素材,所謂乾淨,即沒有背景雜音和空白片段的音訊素材,也可以使用國師採訪的原視訊音軌。
需要注意的是,原視訊中女記者的提問音軌需要刪除掉,否則會影響模型的推理效果。
隨後,將訓練集資料進行切分,主要是為了防止爆視訊記憶體問題,可以手動切為長度在5秒到15秒的音軌切片,也可以使用三方庫進行切分:
git clone https://github.com/openvpi/audio-slicer.git
隨後編寫指令碼:
import librosa # Optional. Use any library you like to read audio files.
import soundfile # Optional. Use any library you like to write audio files.
from slicer2 import Slicer
audio, sr = librosa.load('國師採訪.wav', sr=None, mono=False) # Load an audio file with librosa.
slicer = Slicer(
sr=sr,
threshold=-40,
min_length=5000,
min_interval=300,
hop_size=10,
max_sil_kept=500
)
chunks = slicer.slice(audio)
for i, chunk in enumerate(chunks):
if len(chunk.shape) > 1:
chunk = chunk.T # Swap axes if the audio is stereo.
soundfile.write(f'master_voice/{i}.wav', chunk, sr) # Save sliced audio files with soundfile.
注意這裡min_length的單位是毫秒。
由於原始視訊並未有背景音樂,所以分拆之前我們不用拆分前景音和背景音,如果你的素材有背景音樂,可以考慮使用spleeter來進行分離,具體請參照:人工智慧AI庫Spleeter免費人聲和背景音樂分離實踐(Python3.10),這裡不再贅述。
如果對原視訊的存在的雜音不太滿意,可以通過noisereduce庫進行降噪處理:
from scipy.io import wavfile
import noisereduce as nr
# load data
rate, data = wavfile.read("1.wav")
# perform noise reduction
reduced_noise = nr.reduce_noise(y=data, sr=rate)
wavfile.write("1_reduced_noise.wav", rate, reduced_noise)
訓練集數量最好不要低於20個,雖然音訊訓練更適合小樣本,但數量不夠也會影響模型質量。
最後我們就得到了一組資料集:
D:\work\speech\master_voice>dir
驅動器 D 中的卷是 新加捲
卷的序列號是 9824-5798
D:\work\speech\master_voice 的目錄
2023/06/13 17:05 <DIR> .
2023/06/13 20:42 <DIR> ..
2023/06/13 16:42 909,880 01.wav
2023/06/13 16:43 2,125,880 02.wav
2023/06/13 16:44 1,908,280 03.wav
2023/06/13 16:45 2,113,080 04.wav
2023/06/13 16:47 2,714,680 05.wav
2023/06/13 16:48 1,857,080 06.wav
2023/06/13 16:49 1,729,080 07.wav
2023/06/13 16:50 2,241,080 08.wav
2023/06/13 16:50 1,959,480 09.wav
2023/06/13 16:51 1,921,080 10.wav
2023/06/13 16:52 1,921,080 11.wav
2023/06/13 16:52 1,677,880 12.wav
2023/06/13 17:00 1,754,680 13.wav
2023/06/13 17:01 2,202,680 14.wav
2023/06/13 17:01 2,023,480 15.wav
2023/06/13 17:02 1,793,080 16.wav
2023/06/13 17:03 2,586,680 17.wav
2023/06/13 17:04 2,189,880 18.wav
2023/06/13 17:04 2,573,880 19.wav
2023/06/13 17:05 2,010,680 20.wav
20 個檔案 40,213,600 位元組
2 個目錄 399,953,739,776 可用位元組
當然,如果懶得準備訓練集,也可以下載我切分好的,大家豐儉由己,各取所需:
連結:https://pan.baidu.com/s/1t5hE1LLktIPoyF70_GsH0Q?pwd=3dc6
提取碼:3dc6
至此,資料集就準備好了。
雲端訓練和推理
資料集準備好了,我們就可以進行訓練了,在此之前,需要設定PaddlePaddle框架,但這一次,我們選擇在雲端直接進行訓練,如果想要本地部署,請移步:聲音好聽,顏值能打,基於PaddleGAN給人工智慧AI語音模型配上動態畫面(Python3.10)。
首先進入Paddle的雲端專案地址:
https://aistudio.baidu.com/aistudio/projectdetail/6384839
隨後點選啟動環境,注意這裡儘量選擇視訊記憶體大一點的算力環境:
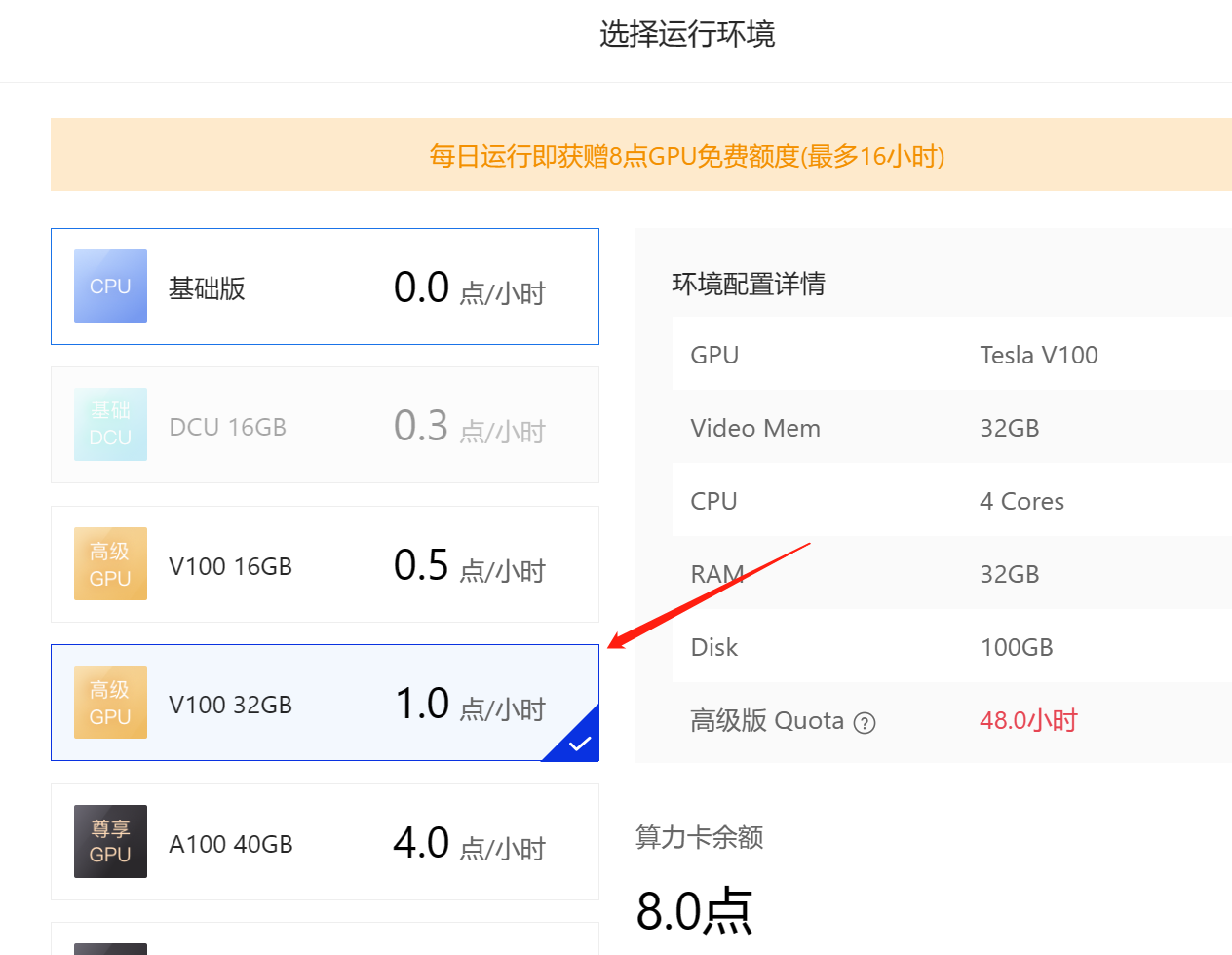
這裡的機器有點類似Google的colab,原則上免費,通過消耗算力卡來進行使用。
成功啟動環境之後,需要安裝依賴:
# 安裝實驗所需環境
!bash env.sh
!pip install typeguard==2.13
由於機器是共用的,一旦環境關閉,再次進入還需要再次進行安裝操作。
安裝好paddle依賴後,在左側找到檔案 untitled.streamlit.py ,雙擊檔案開啟,隨後點選web按鈕,進入web頁面。
接著在web頁面中,點選Browse files按鈕,將之前切分好的資料集上傳到伺服器內部。
接著點選檢驗資料按鈕,進行資料集的校驗。
最後輸入模型的名稱以及訓練輪數,然後點選訓練即可:
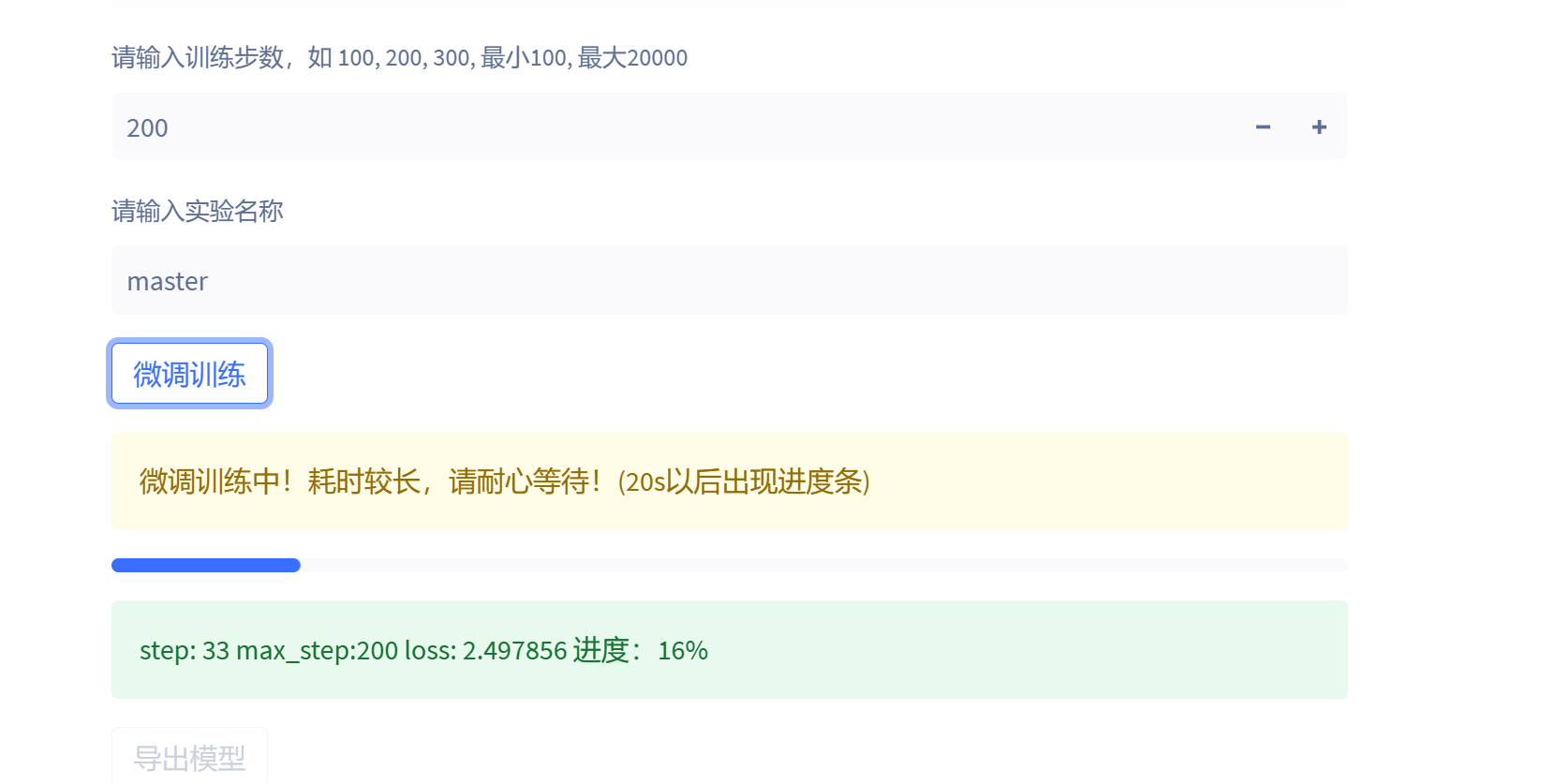
以TeslaV100為例子,20個檔案的資料集200輪訓練大概只需要五分鐘就可以訓練完畢。
模型預設儲存在專案的checkpoints目錄中,檔名稱為master。
點選匯出模型即可覆蓋老的模型:

最後就是線上推理:
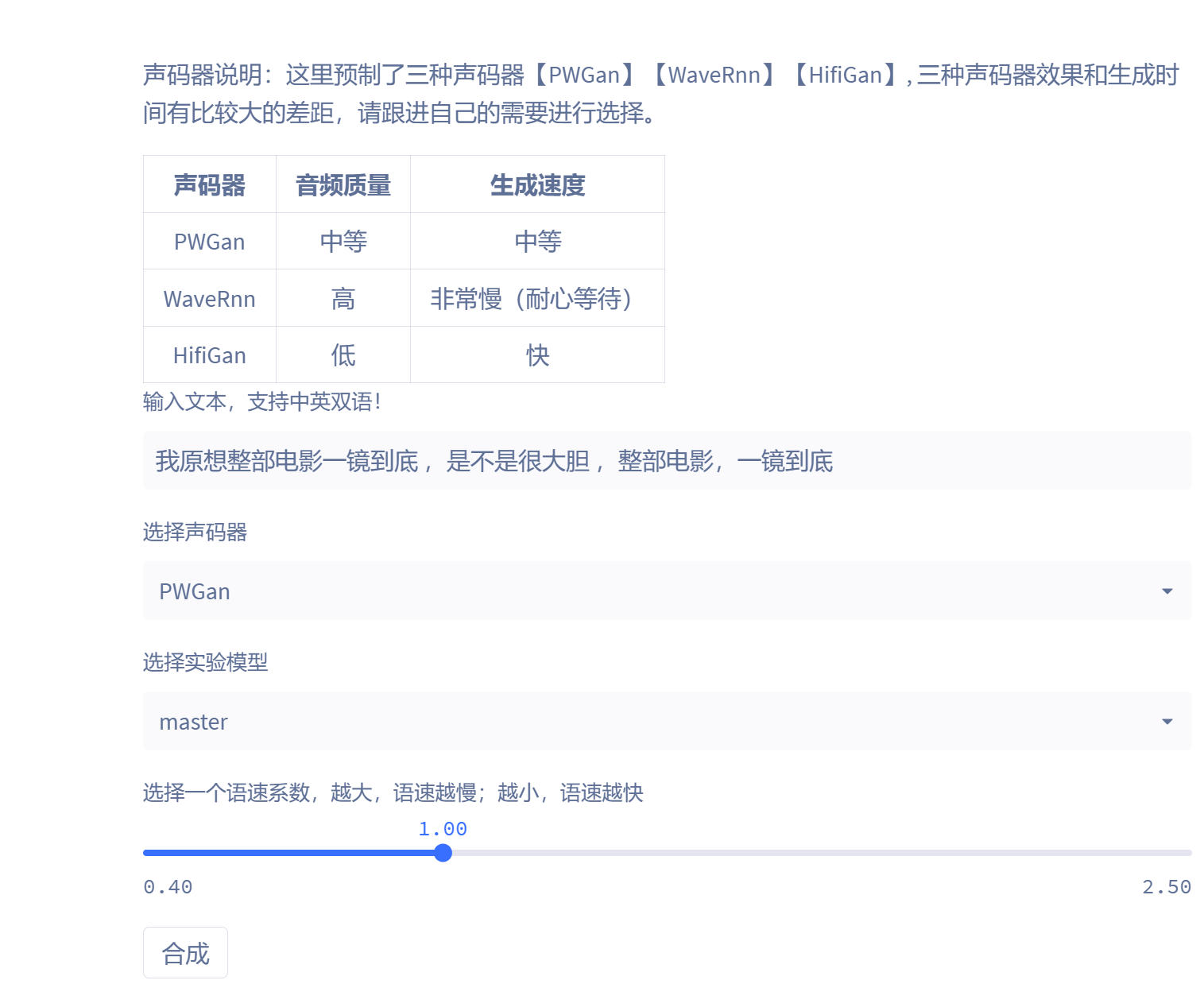
這裡預製了三種聲碼器【PWGan】【WaveRnn】【HifiGan】, 三種聲碼器效果和生成時間有比較大的差距,這裡推薦折中的PWGan聲碼器,因為畢竟是線上環境,每停留一個小時都會消耗算力點數。
合成完畢後,就可以拿到國師的克隆語音了。
結語
線上環境設定起來相對簡單,但要記住,完成克隆語音任務後,需要及時關閉環境,防止算力點數的非必要消耗,最後奉上國師的音色克隆模型,與君共觴:
連結:https://pan.baidu.com/s/1nKOPlI7P_u_a5UGdHX76fA?pwd=ygqp
提取碼:ygqp
克隆音色版本的國師鬼畜視訊已經上傳到Youtube(B站),歡迎諸君品鑑和臻賞。