Redis系列17:聊聊布隆過濾器(實踐篇)
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 叢集模式
追求效能極致:Redis6.0的多執行緒模型
追求效能極致:使用者端快取帶來的革命
Redis系列8:Bitmap實現億萬級資料計算
Redis系列9:Geo 型別賦能億級地圖位置計算
Redis系列10:HyperLogLog實現海量資料基數統計
Redis系列11:記憶體淘汰策略
Redis系列12:Redis 的事務機制
Redis系列13:分散式鎖實現
Redis系列14:使用List實現訊息佇列
Redis系列15:使用Stream實現訊息佇列
Redis系列16:聊聊布隆過濾器(原理篇)
1 介紹
布隆過濾器(Bloom Filter)是 Redis 4.0 版本提供的新功能,我們一般將它當做外掛載入到 Redis 伺服器中,給 Redis 提供強大的去重功能。
它是一種概率性資料結構,可用於判斷一個元素是否存在於一個集合中。相比較之 Set 集合的去重功能,布隆過濾器空間上能節省 90% +,不足之處是去重率大約在 99% 左右,那就是有 1% 左右的誤判率,這種誤差是由布隆過濾器的自身結構決定的。
- 優點:空間效率和查詢時間都比一般的演演算法要好的多
- 缺點:有一定的誤識別率和刪除困難
2 使用場景介紹
我們在遇到資料量大的時候,為了去重並避免大批次的重複計算,可以考慮使用 Bloom Filter 進行過濾。
具體常用的經典場景如下:
- 解決大流量下快取穿透的問題,參考筆者這篇《一次快取雪崩的災難覆盤》。
- 過濾被遮蔽、拉黑、減少推薦的資訊,一般你在瀏覽抖音或者百度App的時候,看到不喜歡的會設定減少推薦、遮蔽此類資訊等,都可以採用這種原理設計。
- 各種名單過濾,使用布隆過濾器實現第一層的白名單或者黑名單過濾,可用於各種AB場景。
下面以快取穿透為解決目標進行講解。
3 實戰介紹
快取穿透是指存取一個不存在的key,快取不起作用,請求會穿透到DB,流量井噴時會導致DB掛掉。
比如 我們查詢使用者的資訊,程式會根據使用者的編號去快取中檢索,如果找不到,再到資料庫中搜尋。如果你給了一個不存在的編號:XXXXXXXX,那麼每次都比對不到,就透過快取進入資料庫。
這樣風險很大,如果因為某些原因導致大量不存在的編號被查詢,甚至被惡意偽造編號進行攻擊,那將是災難。
解決方案質疑就是在快取之前在加一層 BloomFilter :
- 把存在的key記錄在BloomFilter中,在查詢的時候先去 BloomFilter 去查詢 key 是否存在,如果不存在則說明資料庫和快取都沒有,就直接返回,
- 存在再走查快取 ,投入資料庫去查詢,這樣減輕了資料庫的壓力。
3.1 巨量查詢資訊案例解析
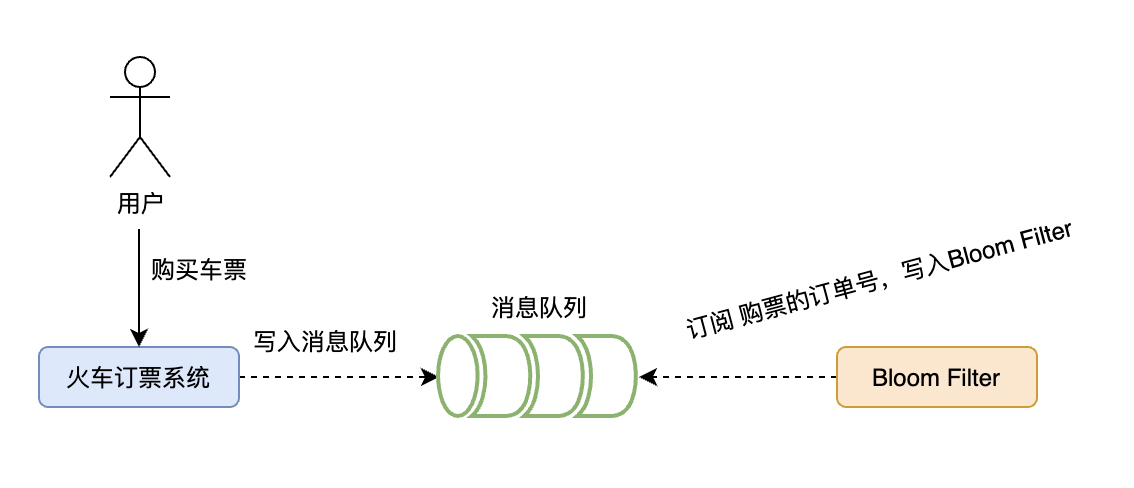
下面以火車票訂購和查詢為案例進行說明,如果火車票被惡意攻擊,模擬了一模一樣的火車票訂單編號,那很可能通過大量的請求穿透過快取層把資料庫打雪崩了,所以使用布隆過濾器為服務提供一層保障。
具體的做法就是,我們在購買火車票成功的時候,把訂單號的ID寫入(非同步或者訊息佇列的方式)到布隆過濾器中,保障後續的查詢都在布隆過濾器中走一遍再進到快取中去查詢。火車票訂單Id同步到 Bloom Filter 的步驟如下:
3.2 建立Bloom Filter的方式
建立 Bloom Filter 的語法如下:
# BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
BF.RESERVE ticket_orders 0.01 1000000
- key:布隆過濾器的名字,這邊指的是建立一個名為 ticket_orders 的過濾器。
- error_rate:期望的錯誤率,預設值為 0.1,值越低,需要的空間越大。就像我們上一節說的,空間越大碰撞的可能性越低。
- capacity:初始的空間容量,預設值為 100,當實際元素的數量超過這個初始化容量時,碰撞的可能性越高,誤判率也越高。
- EXPANSION:可選參,資料達到初始容量後,布隆過濾器會自動建立一個子過濾器,大小為上一個過濾器乘以 expansion。expansion 的預設值為 2,也就是說預設擴容2倍;
- NONSCALING:可選參,指的是資料達到初始容量後,不會擴容過濾器,並丟擲異常((error) ERR non scaling filter is full)。
而上面那句命令是,通過BF.RESERVE命令手動建立一個名字為 ticket_orders,錯誤率為 0.01 ,初始容量為 1000000 的布隆過濾器。
這邊需要注意的一些點是:
- error_rate 越小,對碰撞的容忍度越小,需要的儲存空間就越大。如果允許一定比例的不準確,對精確度要求不高的場景,error_rate 可以設的稍大一點。
- capacity 設定的過大,會浪費儲存空間,設定過小,準確度不高。所以評估的時候需要精準一點,既要避免浪費空間也要保證準確比例。
3.3 新增火車票訂單Id到Bloom Filter
# BF.ADD {key} {value ... }
# 新增單個訂單號
BF.ADD ticket_orders 2023061008795
(integer) 1
# 新增多個訂單號
BF.MADD ticket_orders 2023061008796 2023061008797 2023061008798
1) (integer) 1
2) (integer) 1
3) (integer) 1
以上的語句是將已經訂好的車票訂單號儲存到Bloom Filter中,包括一次儲存單個和一次儲存多個。
3.4 判斷火車票訂單Id是否存在
# BF.EXISTS {key} {value} ,存在的話返回 1,不存在返回 0
BF.EXISTS ticket_orders 2023061008795
(integer) 1
# 批次判斷多個值是否存在於布隆過濾器,語句如下:
BF.MEXISTS ticket_orders 2023061008796 2023061008797 2023061008798
1) (integer) 0
2) (integer) 1
3) (integer) 0
BF.EXISTS 判斷一個元素是否存在於 Bloom Filter中,返回值 = 1 表示存在,返回值 = 0 表示不存在。可以一次性判斷單個元素,或者一次性判斷多個元素。
3.5 Review已建的布隆過濾器列表
# 使用 BF.INFO {key} 語法檢視
BF.INFO ticket_orders
1) Capacity
2) (integer) 1000000
3) Size
4) (integer) 3
5) Number of filters
6) (integer) 1
7) Number of items inserted
8) (integer) 3
9) Expansion rate
10) (integer) 2
返回值解析:
Capacity:預設容量,我們前面設定了1000000。
Size:實際佔用情況,我們前面設定了3個值:2023061008796、 2023061008797、 2023061008798。
Number of filters:過濾器的層數。
Number of items inserted:實際已插入的元素數量。
Expansion rate:子過濾器擴容的係數,咱們前面建立的時候未設值,所以這邊是預設 2。
綜上,我們通過 BF.RESERVE、BF.ADD、BF.EXISTS、BF.INFO 等幾個指令就能實現布隆過濾器的建設,避免快取穿透的情況發生。
因為你查詢快取的時候,必然你先到Bloom Filter中先過濾一次,這樣就不會因為無效的key把快取打穿。
4 程式實現說明
Spring Boot版本: 2.5.x。
4.1 新增 Redission Maven 依賴
如果實際情況可以使用更高版本
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.1</version>
</dependency>
4.2 Spring boot Yaml中的 Redission 設定
spring:
application:
name: redission
redis:
cluster:
nodeAddresses: [
"redis://127.0.0.1:8000",
"redis://127.0.0.1:8001",
"redis://127.0.0.1:8002",
"redis://127.0.0.1:8003",
"redis://127.0.0.1:8004",
"redis://127.0.0.1:8005"
]
password: ********
single:
address: "redis://127.0.0.1:6379"
database: 6
4.3 建立布隆過濾器相關
@Service
public class BloomFilterService {
@Autowired
private RedissonClient redissonClient;
/**
* 建立布隆過濾器
* @param filterKey 過濾器名稱,等同上面的key
* @param expectedCapacity 預計元素容量,等同於上面的capacity
* @param falseRate 允許的誤判率,等同於上面的error_rate
* @param <T>
* @return
*/
public <T> RBloomFilter<T> create(String filterKey, long expectedCapacity, double falseRate) {
// 叢集模式
RClusteredBloomFilter<T> bloomFilter = redissonClient.getClusteredBloomFilter(filterKey);
// 以下是單範例模式
// RBloomFilter<T> bloomFilter = redissonClient.getBloomFilter(filterKey);
bloomFilter.tryInit(expectedCapacity, falseRate);
return bloomFilter;
}
}
4.4 測試實現
@Autowired
private BloomFilterService bloomFilterService;
@Test
public void testBloomFilter() {
// 預計元素容量 1000000
long expectedCapacity = 1000000L;
// 錯誤率
double falseRate = 0.01;
RBloomFilter<Long> bloomFilter = bloomFilterService.create("ticket_orders", expectedCapacity, falseRate);
// 元素增加測試並輸出統計
for (long idx = 0; idx < expectedCapacity; idx++) {
bloomFilter.add(idx);
}
long eleCount = bloomFilter.count();
log.info("eleCount = {}.", elementCount);
}
5 總結
本篇介紹了布隆過濾器的幾種實現場景。
並以火車票訂單資訊查詢為案例進行說明,如何使用布隆過濾器避免快取穿透,避免被惡意攻擊。
