Redis系列16:聊聊布隆過濾器(原理篇)
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 叢集模式
追求效能極致:Redis6.0的多執行緒模型
追求效能極致:使用者端快取帶來的革命
Redis系列8:Bitmap實現億萬級資料計算
Redis系列9:Geo 型別賦能億級地圖位置計算
Redis系列10:HyperLogLog實現海量資料基數統計
Redis系列11:記憶體淘汰策略
Redis系列12:Redis 的事務機制
Redis系列13:分散式鎖實現
Redis系列14:使用List實現訊息佇列
Redis系列15:使用Stream實現訊息佇列
1 Bloom Filter 介紹
布隆過濾器(Bloom Filter)是 Redis 4.0 版本提供的新功能,我們一般將它當做外掛載入到 Redis 伺服器中,給 Redis 提供強大的去重功能。
它是一種概率性資料結構,可用於判斷一個元素是否存在於一個集合中。相比較之 Set 集合的去重功能,布隆過濾器空間上能節省 90% +,不足之處是去重率大約在 99% 左右,那就是有 1% 左右的誤判率,這種誤差是由布隆過濾器的自身結構決定的。
- 優點:空間效率和查詢時間都比一般的演演算法要好的多
- 缺點:有一定的誤識別率和刪除困難
2 原理分析
布隆過濾器(Bloom Filter)是一個高空間利用率的概率性資料結構,由二進位制向量(即位陣列)和一系列隨機對映函數(即雜湊函數)兩部分組成。
通過使用exists()來判斷某個元素是否存在於自身結構中。當布隆過濾器判定某個值存在時,其實這個值只是有可能存在;當它說某個值不存在時,那這個值肯定不存在,這個誤判概率大約在 1% 左右。
原理拆解如下:
- 在一個很長的二進位制向量和一系列隨機對映函數的基礎上,將元素雜湊成不同的位置,每個位置對應二進位制向量中的一個位元位。
- 當加入一個元素時,採用 n 個相互獨立的 Hash 函數計算key,然後將元素 Hash 對映的 n 個位置全部設定為 1。
- 檢測 key 是否存在,仍然用 Hash 函數計算出這 n 個位置,如果元素key 存在於集合中,則對應的位置為1,否則為0。
- 如果n個位置均為1的話,可以確定元素key可能存在於集合中;如果有一個為0,那麼元素的key一定不存在於集合中,下面會詳細分析這句話。
- 這種判斷機制會存在誤判的可能,但它以較小的空間代價和極簡的時間複雜度來近似解決集合交、並、差等操作。
2.1 新增元素步驟
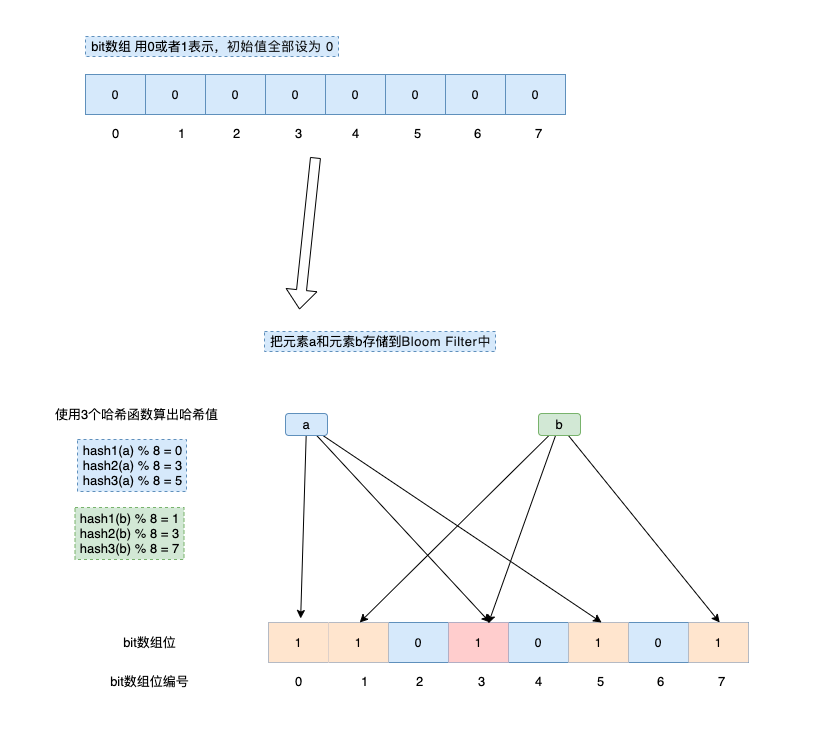
當使用布隆過濾器新增 key 時,會使用不同的 hash 函數對 key 儲存的元素值進行雜湊計算,從而會得到多個雜湊值。根據雜湊值計算出一個整數索引值,將該索引值與位陣列長度做取餘運算,最終得到一個位陣列位置,並將該位置的值變為 1。每個 hash 函數都會計算出一個不同的位置,然後把陣列中與之對應的位置變為 1。這邊可能出現元素碰撞的情況,比如位置3,a元素和b元素的hash計算位置一致,所以出現了碰撞。
2.2 判定元素是否存在步驟
如果我們要判定一個元素是否存在,需要如下步驟:
- 首先對給定元素key執行雜湊計算,這樣可以得到元素增加時的bit位陣列位置
- 判斷這些位置是否都為 1,如果其中有一個為 0,那麼說明元素不存在
- 若全部位置都為 1,則說明元素有可能存在。
為啥說是可能存在呢,因為上面說過了,雜湊函數出的結果會出現碰撞,所以布隆過濾器會存在誤判。
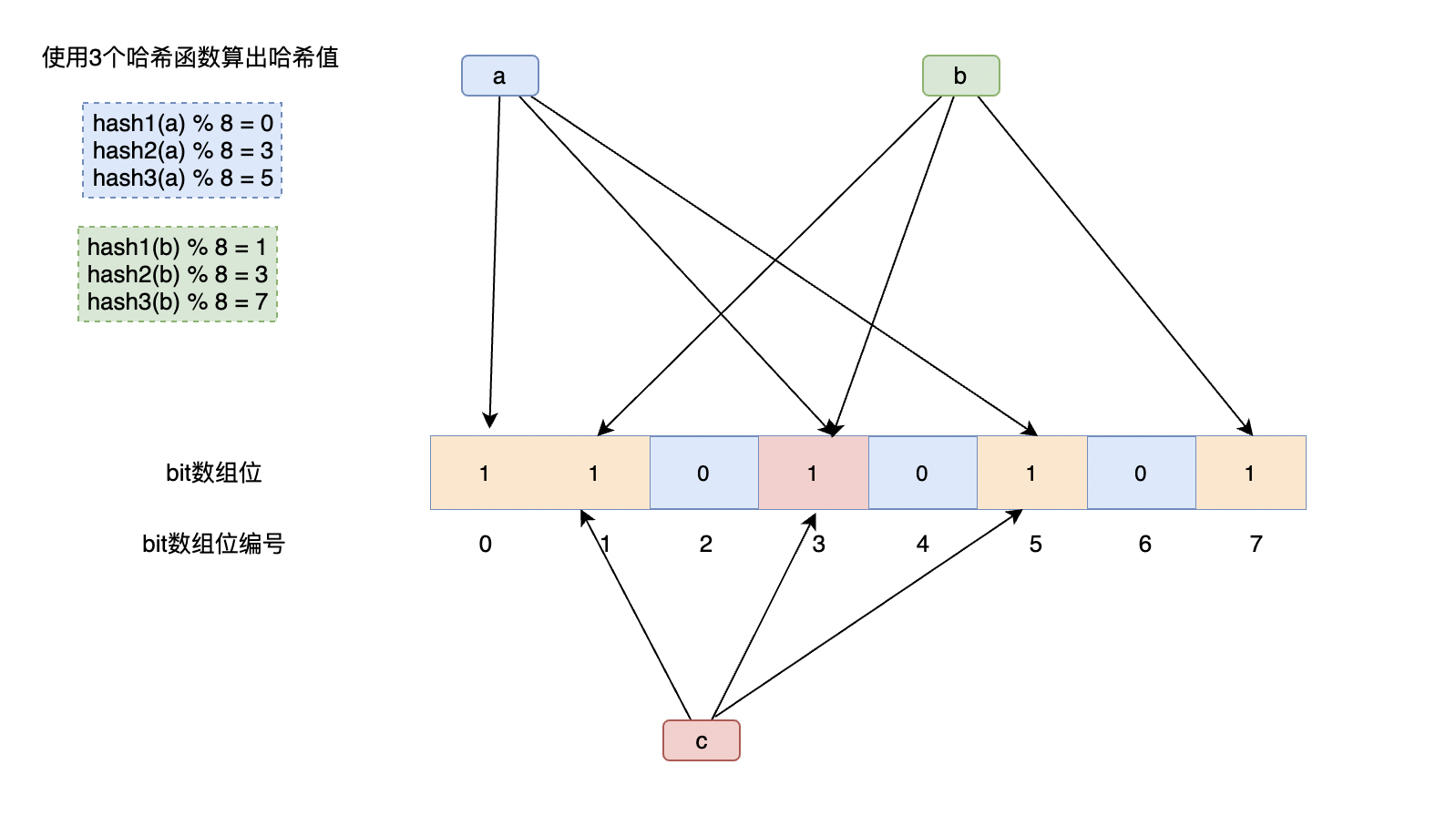
如上圖c,他的位置被其他元素的位置完全覆蓋,即使c沒有儲存,對應位置上也被a和b的Hash函數設定為1,這時候就可能誤判為c是有儲存的。
有概率存在這樣的 key,它們內容不同,但多次 Hash 後的 Hash 值都相同。
2.3 元素刪除步驟
一般不會刪除元素,我們上面說了,因為可能存在碰撞情況,所以也有可能存在誤刪除情況。
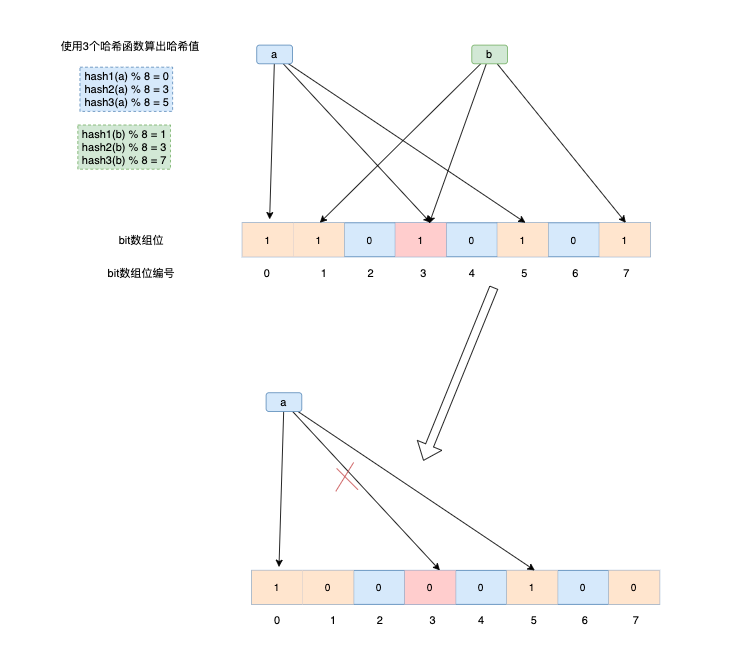
刪除意味著需要將對應的 n 個 bits 位置設定為 0,其中有可能是其他元素對應的位。
比如圖中的b刪除之後,位置3的值也被設定為0,這樣a也可能會被判定為不存在。
3 使用場景介紹
我們在遇到資料量大的時候,為了去重並避免大批次的重複計算,可以考慮使用 Bloom Filter 進行過濾。
具體常用的經典場景如下:
- 解決大流量下快取穿透的問題,參考筆者這篇《一次快取雪崩的災難覆盤》。
- 過濾被遮蔽、拉黑、減少推薦的資訊,一般你在瀏覽抖音或者百度App的時候,看到不喜歡的會設定減少推薦、遮蔽此類資訊等,都可以採用這種原理設計。
- 各種名單過濾,使用布隆過濾器實現第一層的白名單或者黑名單過濾,可用於各種AB場景。
4 安裝整合
如果是自己編譯安裝,可以從 github 下載,目前的latest 的 release 版本是 v2.4.5,下載地址如下:
https://github.com/RedisBloom/RedisBloom/releases/tag/v2.4.5

直接按照編譯的方式進行安裝:
# 解壓檔案:
tar -zxvf tar -zxvf RedisBloom-2.4.5.tar.gz
# 進入目錄:
cd RedisBloom-2.4.5
# 執行編譯命令,生成redisbloom.so 檔案:
make
# 拷貝至指定目錄:
cp redisbloom.so /usr/local/redis/RedisBloom-2.4.5/redisbloom.so
# 需要修改 redis.conf 檔案,新增 loadmodule設定,並重啟 Redis。
# 在redis組態檔里加入以下設定:
loadmodule /usr/local/redis/RedisBloom-2.4.5/redisbloom.so
# 設定完成後重啟redis服務:
redis-server /usr/local/redis/RedisBloom-2.4.5/redis.conf
# 測試是否安裝成功
127.0.0.1:6379> bf.add user brand
(integer) 1
127.0.0.1:6379> bf.exists user brand
(integer) 1
5 總結
大致說了布隆過濾器的原理和使用場景,下一篇我們來看看實戰。
