MySQL讀取的記錄和我想象的不一致
摘要:並行的事務在執行過程中會出現一些可能引發一致性問題的現象,本篇將詳細分析一下。
本文分享自華為雲社群《MySQL讀取的記錄和我想象的不一致——事物隔離級別和MVCC》,作者:磚業洋__。
事務的特性簡介
1.1 原子性(Atomicity)
要麼全做,要麼全不做,一系列操作都是不可分割的,如果在執行操作的過程發生了錯誤,那麼就把已經執行的操作恢復成沒執行之前的樣子。比如轉賬不能只有一方扣錢另一方不增加餘額。
1.2 隔離性(Isolation)
任何其他狀態操作不能影響本次狀態操作轉換,比如A幾乎同時向B轉2次賬,不同的事務讀取出的卡上餘額都是12元,在第一個事務A-5元后,第二個事務A-5(那這裡是12-5還是7-5呢?),所以MySQL需要一些措施保證這些操作的隔離。
1.3 一致性(Consistency)
如果資料庫的資料全部符合現實世界的約束,則這些資料就是一致性的,或者說符合一致性的。
比如餘額不能小於0,有一些業務id不能為空。資料庫本身能為我們解決一部分一致性需求,比如NOT NULL來拒絕NULL值的插入,但是更多的是需要靠寫業務程式碼的程式設計師自己保證,比如在Spring Boot裡面,入參就可以@NotNull或者@NotBlank之類的來進行入參校驗。
資料庫檢查一致性是一個耗費效能的工作,比如為表建立一個觸發器,每當插入或更新記錄的時候就會校驗是否滿足條件,如果涉及到某一些列的計算,就會嚴重影響插入或更新的速度。
儘量不要把校驗引數的判斷條件(一致性檢查)寫在MySQL語句中,不僅影響插入更新的速度,而且資料庫連線也是很耗時的。能在業務層面解決就在業務層面判斷。
提示:建表時的CHECK子句對於一致性檢查沒什麼用,在MySQL中也不會去檢查CHECK子句中的約束是否成立。比如:
create table test ( id unsigned int not null auto_increment comment ‘主鍵id’, name varchar(100) comment ‘姓名’, balance int comment ‘餘額’, primary key (id), check (balance >= 0) );
1.4 永續性 (Durability)
資料庫修改的資料都應該在磁碟中保留下來,無論發生什麼事故,本次操作的影響都不應該丟失。比如轉賬成功後不可以又恢復到沒轉賬之前的樣子,那樣錢就沒了。
我們把這四種特性的首字母提出來加以排序就是一個英文單詞:ACID(英文中「酸」的意思),方便記憶
2. 建表
CREATE TABLE hero ( number INT, name VARCHAR(100), country varchar(100), PRIMARY KEY (number), KEY idx_hero_name (name) ) Engine=InnoDB CHARSET=utf8;
這裡把hero表的主鍵命名為number是為了與後面的事務id進行區分,為了簡單,就不寫約束條件和註釋了。
然後向這個表裡插入一條資料:
INSERT INTO hero VALUES(1, '劉備', '蜀');
現在表裡的資料就是這樣的:
3. 事務隔離級別
MySQL是一個使用者端/伺服器架構的軟體,對於同一個伺服器來說,可以有若干個使用者端與之連線,每個使用者端與伺服器連線後,就形成了一個對談(Session)。每個使用者端都可以在自己的對談中向伺服器發出請求語句,一個請求語句可能是某個事務的一部分。伺服器可以同時處理來自多個使用者端的多個事務。
3.1 事務並行執行時遇到的一致性問題
在不同隔離級別中,對資料庫的操作可能會出現幾種現象。如下:
3.1.1 髒寫(Dirty Write)(用於熟悉和理解ACID特性,實際中不可能存在髒寫)
如果一個事務修改了另一個未提交事務修改過的資料,那就意味著發生了髒寫。如下:
假設兩個對談各開啟了一個事務TA和TB,
- 原有x=0, y=0,TA先修改了x=3,TB修改了x=1,y=1,然後TB提交,最後TA回滾。
如果TA回滾導致x=0,那麼對於TB來說破壞了原子性,因為x被回滾,y還是正常修改。
如果TA回滾導致TB所有的修改都回滾,那麼對於TB來說破壞了永續性,明明TB都提交了,怎麼能讓一個未提交的TA將TB的永續性破壞掉呢?
無論哪種隔離級別,都不允許髒寫的存在,所以髒寫也可以作為介紹事務特性的一個序言,瞭解即可。
3.1.2 髒讀(Dirty Read)
如果一個事務讀到了另一個未提交事務修改過的資料,那就意味著發生了髒讀,示意圖如下:
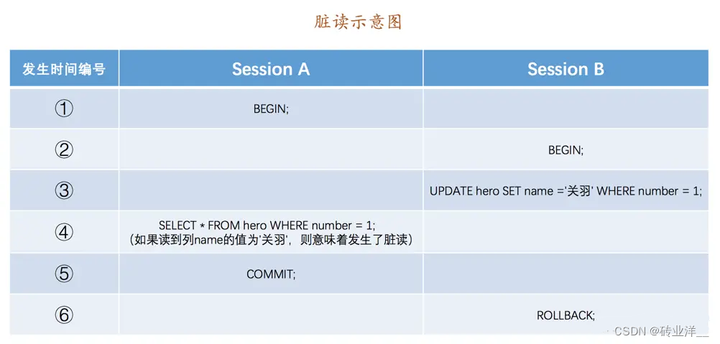
Session A和Session B各開啟了一個事務,Session B中的事務先將number列為1的記錄的name列更新為’關羽’,然後Session A中的事務再去查詢這條number為1的記錄,如果讀到列name的值為’關羽’,而Session B中的事務稍後進行了回滾,那麼Session A中的事務相當於讀到了一個不存在的資料,這種現象就稱之為髒讀。
這裡例子中Session B中的事務是rollback,即使是commit了,雖然最終資料庫的狀態是一致的,但是在Session A中的事務讀取number=1這條記錄的時候,這個事務卻得到了不一致的狀態。資料庫不一致的狀態是不應該暴露給使用者的。
嚴格一點的解釋:假設事務T1、T2並行執行,它們都要存取資料項X,T1先修改了X的值,然後T2又讀取了未提交事務T1修改後的X值,之後T1中止而T2提交。這就意味著T2讀到了一個根本不存在的值,這也是髒讀的嚴格解釋。
3.1.3 不可重複讀(Non-Repeatable Read)
如果一個事務修改了另一個未提交事務讀取的資料,就意味著發生了不可重複讀現象,或者叫模糊讀(Fuzzy Read)現象。
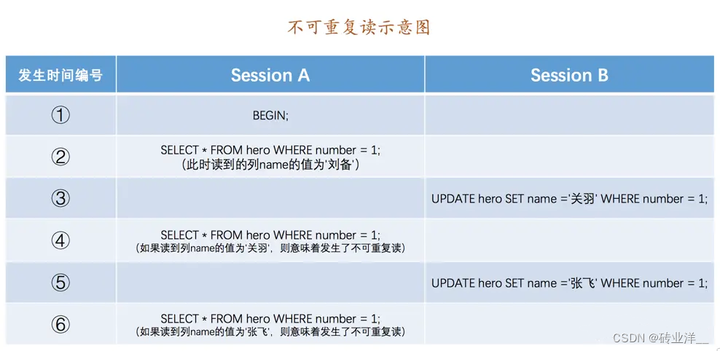
讀的’劉備’,被修改為’關羽’ ,讀的’關羽’ 又被修改為了’張飛’ 。
嚴格一點的解釋:假設事務T1、T2並行執行,它們都要存取資料項X,T1先讀取了X的值,然後T2又修改了未提交事務T1讀取的X的值,之後T2提交,然後T1再次讀取資料項X的值時會得到與第一次讀取時不同的值。
3.1.4 幻讀(Phantom)
如果一個事務先根據某些條件查詢出一些記錄,之後另一個事務又向表中插入了符合這些條件的記錄,原先的事務再次按照該條件查詢時,能把另一個事務插入的記錄也讀出來,那就意味著發生了幻讀,示意圖如下:
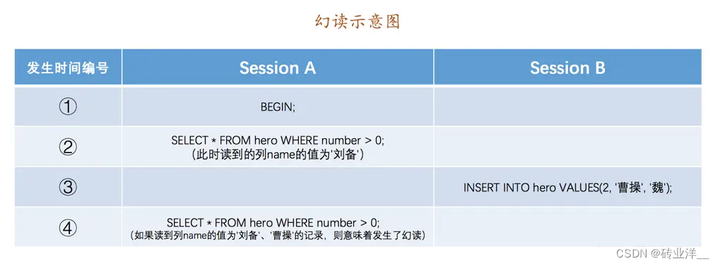
嚴格一點的解釋:假設事務T1、T2並行執行,T1先讀取符合搜尋條件P的記錄,然後T2寫入了符合搜尋條件P的記錄。之後T1再讀取符合搜尋條件P的記錄時,會發現兩次讀取的記錄時不一樣的。
如果Session B中是刪除了一些符合number > 0的記錄而不是插入新記錄,那Session A中之後再根據number > 0的條件讀取的記錄變少了,這種現象算不算幻讀呢?明確說明下,這種現象不屬於幻讀,幻讀強調的是一個事務按照某個相同條件多次讀取記錄時,後讀取時讀到了之前沒有讀到的記錄。
我們這裡只考慮SQL標準中提到的,不考慮其他論文的描述,對於MySQL來說,幻讀強調的是「一個事務在按照某個相同的搜尋條件多次讀取記錄時,在後續讀取到了之前沒讀到的記錄」,可能是別的事務insert操作引起的。那對於先前已經讀到的記錄,之後又讀取不到這種情況算啥呢?我們把這種現象認為是結果集中的每一條記錄分別發生了不可重複讀的現象。
比如:第一次讀到abc三條記錄,第二次讀到abd,既多了d記錄,又少了c記錄,這怎麼分析?
對於記錄c來說,發生了不可重複讀,對於記錄d來說,發生了幻讀。一致性問題針對每條記錄分析即可。
是否有可能發生一致性問題的判斷依據是,在準備讀取的那一刻,想查詢的資料庫某些列的值與實際查詢出來的可能會有出入,則認為可能會發生一致性問題。
綜上:髒讀、不可重複讀、幻讀都可能會發生一致性問題。
既然會出現這些問題,那麼SQL也有一些標準來處理這些問題,接著看吧
3.2 SQL標準中的四種隔離級別
我們給可能導致一致性問題的嚴重性給這些現象排一下序:
髒讀 > 不可重複讀 > 幻讀
捨棄一部分隔離性來換取一部分效能在這裡就體現在:設立一些隔離級別,隔離級別越低,越可能發生嚴重的問題。有一幫人(並不是設計MySQL的大叔)制定了一個所謂的SQL標準,在標準中設立了4個隔離級別:
- READ UNCOMMITTED:未提交讀。
- READ COMMITTED:已提交讀 (又簡稱為RC) 。
- REPEATABLE READ:可重複讀 (又簡稱為RR)。
- SERIALIZABLE:可序列化。
SQL標準中規定(是SQL標準中規定,不是MySQL中規定),針對不同的隔離級別,並行事務可以發生不同的現象,具體情況如下:
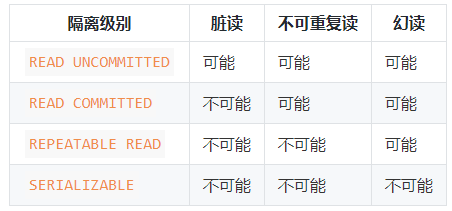
SQL92標準中並沒有指出髒寫的現象,髒寫這個現象對於一致性影響太嚴重了,無論哪種隔離級別都不允許髒寫的發生,這裡就不多提。
3.3 MySQL中支援的四種隔離級別
不同的資料庫廠商對SQL標準中規定的4種隔離級別支援不一樣,比方說Oracle就只支援READ COMMITTED(Oracle的預設隔離級別)和SERIALIZABLE隔離級別。這裡所討論的MySQL雖然支援4種隔離級別,但與SQL標準中所規定的各級隔離級別允許發生的問題卻有些出入,MySQL在REPEATABLE READ隔離級別下,是可以很大程度上禁止幻讀問題的發生的(關於如何禁止之後會詳細說明的)。
MySQL的預設隔離級別為REPEATABLE READ,我自己手上的專案在生產環境的隔離級別是READ COMMITTED,而且相關的一些介面可能同時操作同一張表的某一個賬號,並行性較高,我的操作是:每次進入事務之前都會用Redis分散式鎖去鎖住這個賬號再進入事務,操作同一個賬號同一時間只能有一個成功,這樣就不會出現多個事務並行去操作這個賬號相關性的資料,也就不會有這條記錄出現不可重複讀和幻讀的機會。
3.3.1 如何設定事務的隔離級別
我們可以通過下邊的語句修改事務的隔離級別(實際開發中是不會讓開發人員隨意有這種操作的,可以在自己電腦嘗試):
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level;
其中的level可選值有4個:
level: { REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE }
設定事務的隔離級別的語句中,在SET關鍵字後可以放置GLOBAL關鍵字、SESSION關鍵字或者什麼都不放,這樣會對不同範圍的事務產生不同的影響,具體如下:
- 使用GLOBAL關鍵字(在全域性範圍產生影響):
比如下面這樣:
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
則:
- 只對執行完該語句之後新產生的對談起作用。
- 當前已經存在的對談無效。
所謂新產生的對談,如果你是navicat操作,得關閉連線之後再開啟連線才算新的對談,如果僅僅是新建查詢還算同一個對談,是看不到設定前後隔離級別的變化的。
- 使用SESSION關鍵字(在對談範圍影響):
比方說這樣:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
則:
- 對當前對談的所有後續的事務有效
- 該語句可以在已經開啟的事務中間執行,但不會影響當前正在執行的事務。
- 如果在事務之間執行,則對後續的事務有效。
- 上述兩個關鍵字都不用(只對執行這個SET語句後的下一個事務產生影響):
比如下面這樣:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
則:
- 只對當前對談中下一個即將開啟的事務有效。
- 下一個事務執行完後,後續事務將恢復到之前的隔離級別。
- 該語句不能在已經開啟的事務中間執行,否則會報錯。
如果我們在伺服器啟動時想改變事務的預設隔離級別,可以修改啟動引數transaction-isolation的值,比方說我們在啟動伺服器時指定了--transaction-isolation=SERIALIZABLE,那麼事務的預設隔離級別就從原來的REPEATABLE READ變成了SERIALIZABLE。
可以通過檢視系統變數transaction_isolation的值來確定當前對談預設的隔離級別:
SHOW VARIABLES LIKE 'transaction_isolation';

注意:transaction_isolation是在MySQL 5.7.20的版本中引入來替換tx_isolation的,如果你使用的是之前版本的MySQL,請將上述用到系統變數transaction_isolation的地方替換為tx_isolation。
或者使用更簡便的寫法:
SELECT @@transaction_isolation;

我們之前使用SET TRANSACTION語法來設定事務的隔離級別時,其實就是在間接設定系統變數transaction_isolation的值,我們也可以直接修改系統變數transaction_isolation來設定事務的隔離級別。系統變數一般系統變數只有GLOBAL和SESSION兩個作用範圍,而這個transaction_isolation卻有3個(GLOBAL、SESSION、僅作用於下一個事務),設定語法上有些特殊,更多詳情可以參見檔案:transaction_isolation。
這裡總結下:
4. MVCC原理
4.1 版本鏈
在前文底層揭祕MySQL行格式記錄頭資訊說過,對於使用InnoDB儲存引擎的表來說,它的聚簇索引記錄中都包含兩個必要的隱藏列(row_id並不是必要的,我們建立的表中有主鍵或者有NOT NULL限制的UNIQUE鍵時都不會包含row_id列):
- trx_id:每次一個事務對某條聚集索引記錄進行改動時,都會把該事務的事務id賦值給trx_id隱藏列。
- roll_pointer:每次對某條聚簇索引記錄進行改動時,都會把舊的版本寫入到undo紀錄檔中,然後這個隱藏列就相當於一個指標,可以通過它來找到該記錄修改前的資訊。
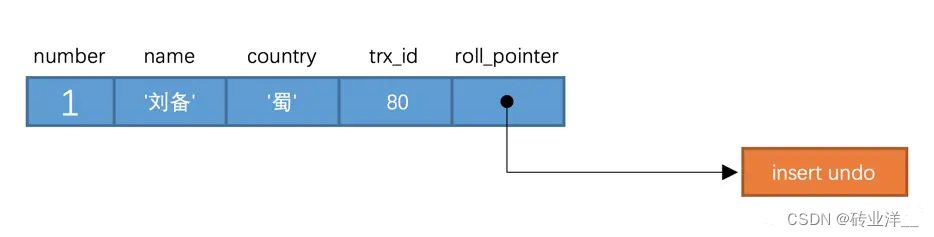
比方說我們的表hero現在只包含一條記錄:
假設插入該記錄的事務id為80,那麼此刻該條記錄的示意圖如下所示:
假設之後兩個事務id分別為100、200的事務對這條記錄進行UPDATE操作,操作流程如下:
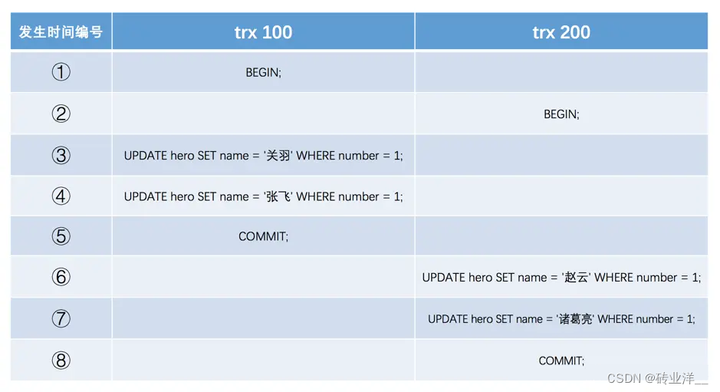
是否可以在兩個事務中交叉更新同一條記錄呢?不可以!這不就是一個事務修改了另一個未提交事務修改過的資料,淪為了髒寫了麼?InnoDB使用鎖來保證不會有髒寫情況的發生,也就是在第一個事務更新某條記錄前,就會給這條記錄加鎖,另一個事務再次更新該記錄時,就需要等待第一個事務提交,把鎖釋放之後才可以繼續更新。所以這裡trx 200在③④⑤步的時候因為鎖的原因是被阻塞的,關於鎖,後續文章再介紹。
每次對記錄進行改動,都會記錄一條undo紀錄檔,每條undo紀錄檔也都有一個roll_pointer屬性(INSERT操作對應的undo紀錄檔沒有該屬性,因為該記錄並沒有更早的版本),可以將這些undo紀錄檔都連起來,串成一個連結串列,所以現在的情況就像下圖一樣:
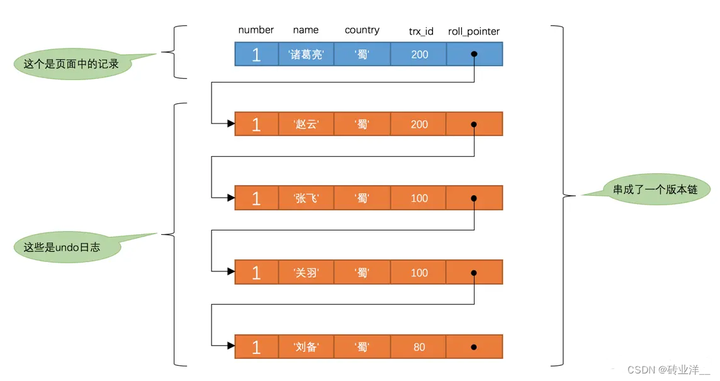
在每次更新該記錄後,都會將舊值放到一條undo紀錄檔中(就算是該記錄的一箇舊版本),隨著更新次數的增多,所有的版本都會被roll_pointer屬性連線成一個連結串列,我們把這個連結串列稱之為版本鏈,版本鏈的頭節點就是當前記錄最新的值。另外,每個版本中還包含生成該版本時對應的事務id(這很重要),我們之後會利用這個記錄的版本鏈來控制並行事務存取相同記錄的行為,我們把這種機制稱之為多版本並行控制(Multi-Version Concurrency Control,MVCC)
從上圖可以看到,聚集索引記錄和undo紀錄檔中的roll_pointer屬性可以串連成一個記錄的版本鏈。同一條記錄在系統中可以存在多個版本,就是資料庫的多版本並行控制(MVCC)
在UPDATE操作產生的undo紀錄檔中,只會記錄一些索引列以及被更新的列的資訊,並不會記錄所有列的資訊,上一張圖展示的undo紀錄檔中,之所以將一條記錄的全部列的資訊都畫出來是為了方便理解(因為這樣很直觀的顯示了該版本中各個列的值是什麼)。比如對於trx_id為80的那條undo紀錄檔來說,本身是沒有記錄country列的資訊的,那怎麼知道該版本中country列的值是多少呢?沒有更新該列則說明該列和上一個版本中的值相同。如果上一個版本的undo紀錄檔也沒有記錄該列的值,那麼就和上上個版本中該列的值相同。如果各個版本的undo紀錄檔都沒有記錄該列的值,說明該列從未被更新過,那麼trx_id為80的那個版本的country列的值就和資料頁中的聚集索引記錄的country列的值相同。
4.2 ReadView
一條記錄竟然更新了那麼多版本?版本鏈中的哪個版本的記錄是當前事務可見的?這在不同隔離級別中可見性是不相同的
- 對於使用READ UNCOMMITTED隔離級別的事務來說,由於可以讀到未提交事務修改過的記錄,所以直接讀取記錄的最新版本就好了。(不生成ReadView)
- 對於使用SERIALIZABLE隔離級別的事務來說,設計InnoDB的大叔規定使用加鎖的方式來存取記錄。(不生成ReadView)
- 對於使用READ COMMITTED和REPEATABLE READ隔離級別的事務來說,都必須保證讀到已經提交的事務修改過的記錄,也就是說假如另一個事務已經修改了記錄但是尚未提交,則不能直接讀取最新版本的記錄。(只有RC、RR這2個隔離級別在讀取資料的時候生成ReadView)
一定要注意,沒有事務就沒有ReadView,ReadView是事務產生的,而且是基於整個資料庫的。
對此,設計InnoDB的大叔提出了一個ReadView(有的翻譯為「一致性檢視」)的概念
注意!在MySQL裡有兩個「檢視」的概念:
一個是view。它是一個用查詢語句定義的虛擬表,在呼叫的時候執行查詢語句並生成結果。建立檢視的語法是create view ...,而它的查詢方法與表一樣。 另一個是InnoDB在實現MVCC時用到的一致性讀檢視,即consistent read view,用於支援RC和RR隔離級別的實現。 ReadView它沒有物理結構,作用是事務執行期間用來定義「我能看到什麼資料」。
這個ReadView中主要包含4個比較重要的內容:
- m_ids:表示在生成ReadView時當前系統中活躍的讀寫事務的事務id列表。「活躍」指的就是,啟動了但還沒提交。
- min_trx_id:表示在生成ReadView時當前系統中活躍的讀寫事務中最小的事務id,也就是m_ids中的最小值。
- max_trx_id:表示生成ReadView時系統中應該分配給下一個事務的事務id值。
注意max_trx_id並不是m_ids中的最大值,事務id是遞增分配的。比方說現在有事務id為1,2,3這三個事務,之後事務id為3的事務提交了。那麼一個新的讀事務在生成ReadView時,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。 - creator_trx_id:表示生成該ReadView的事務的事務id。
只有在對錶中的記錄做改動時(執行INSERT、DELETE、UPDATE這些語句時)才會為事務分配trx_id,否則在一個唯讀事務中的事務id的值trx_id都預設為0,未分配trx_id前,creator_trx_id的值為0,分配trx_id後,creator_trx_id就變化成了對應的事務的trx_id。
在MySQL中,READ COMMITTED和REPEATABLE READ隔離級別的的一個非常大的區別就是它們生成ReadView的時機不同。我們還是以表hero為例來,假設現在表hero中只有一條由事務id為80的事務插入的一條記錄:
注意:當一個ReadView生成了,m_ids、min_trx_id、max_trx_id、creator_trx_id等變數的值都是固定的,比如此時有事務提交,m_ids活躍事務列表的值也不會變。ReadView就像快照一樣,生成了就不再變,除非生成新的。
接下來看一下READ COMMITTED和REPEATABLE READ所謂的生成ReadView的時機不同到底不同在哪裡。
4.2.1 READ COMMITTED —— 一個事務中每次讀取資料前都生成一個ReadView
比如,現在系統裡有兩個事務id分別為100、200的事務在執行:

再次強調,事務執行過程中,只有在第一次真正修改記錄時(比如使用INSERT、DELETE、UPDATE語句),才會被分配一個唯一的事務id,這個事務id是遞增的。所以我們才在Transaction 200中更新一些別的表的記錄,目的是讓它分配事務id。
此刻,表hero中number為1的記錄得到的版本連結串列如下所示:
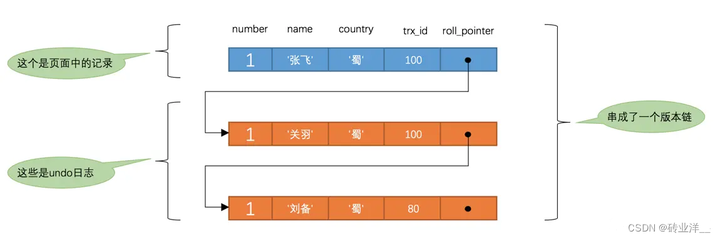
假設現在有一個使用READ COMMITTED隔離級別的事務開始執行:
# 使用READ COMMITTED隔離級別的事務 BEGIN; # SELECT1:Transaction 100、200未提交 SELECT * FROM hero WHERE number = 1; # 得到的列name的值為'劉備'
這個SELECT1的執行過程如下:
- 在執行SELECT語句時會先生成一個ReadView,ReadView的m_ids列表的內容就是[100, 200],min_trx_id為100,max_trx_id為201,creator_trx_id為0。
- 然後從版本鏈中挑選可見的記錄。從圖中可以看出,最新版本的列name的內容是’張飛’,該版本的trx_id值為100,在m_ids列表內,說明trx_id為100的事務還沒提交,所以不符合可見性要求,根據roll_pointer跳到下一個版本。
- 下一個版本的列name的內容是’關羽’,該版本的trx_id值也為100,也在m_ids列表內,所以也不符合要求,繼續跳到下一個版本。
- 下一個版本的列name的內容是’劉備’,該版本的trx_id值為80,小於ReadView中的min_trx_id值100,說明trx_id為80的事務已經提交了,所以這個版本是符合要求的,最後返回給使用者的版本就是這條列name為’劉備’的記錄。
之後,我們把事務id為100的事務提交一下,如下:
# Transaction 100 BEGIN; UPDATE hero SET name = '關羽' WHERE number = 1; UPDATE hero SET name = '張飛' WHERE number = 1; COMMIT;
然後再到事務id為200的事務中更新一下表hero中number為1的記錄:
# Transaction 200 BEGIN; # 更新了一些別的表的記錄 ... UPDATE hero SET name = '趙雲' WHERE number = 1; UPDATE hero SET name = '諸葛亮' WHERE number = 1;
此刻,表hero中number為1的記錄的版本鏈就長這樣:
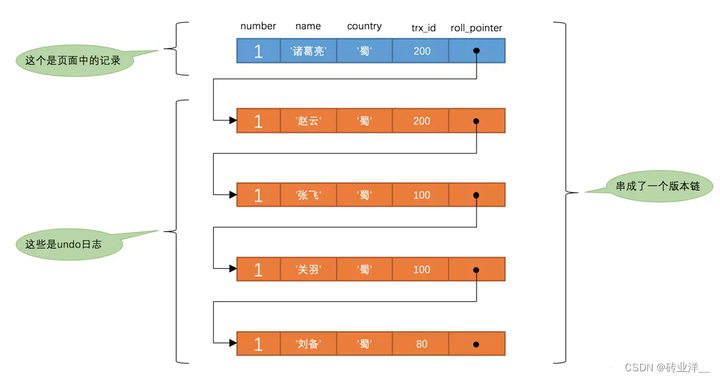
然後再到剛才使用READ COMMITTED隔離級別的事務中繼續查詢這個number為1的記錄,如下
# 使用READ COMMITTED隔離級別的事務 BEGIN; # SELECT1:Transaction 100、200均未提交(第一次查詢兩個事務均未提交) SELECT * FROM hero WHERE number = 1; # 得到的列name的值為'劉備' # SELECT2:Transaction 100提交,Transaction 200未提交(第二次查詢事務id為100的事務提交了) SELECT * FROM hero WHERE number = 1; # 得到的列name的值為'張飛'
分析一下SELECT2的執行過程
- 在執行SELECT語句時會又會單獨生成一個ReadView,該ReadView的m_ids列表的內容就是[200](事務id為100的那個事務已經提交了,所以再次生成ReadView時就沒有它了),min_trx_id為200,max_trx_id為201,creator_trx_id為0。
- 然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列name的內容是’諸葛亮’,該版本的trx_id值為200,在m_ids列表內,所以不符合可見性要求,根據roll_pointer跳到下一個版本。
- 下一個版本的列name的內容是’趙雲’,該版本的trx_id值為200,也在m_ids列表內,所以也不符合要求,繼續跳到下一個版本。
- 下一個版本的列name的內容是’張飛’,該版本的trx_id值為100,小於ReadView中的min_trx_id值200,所以這個版本是符合要求的,最後返回給使用者的版本就是這條列name為’張飛’的記錄。
以此類推,如果之後事務id為200的記錄也提交了,再次在使用READ COMMITTED隔離級別的事務中查詢表hero中number值為1的記錄時,得到的結果就是’諸葛亮’了。總結一下就是:使用READ COMMITTED隔離級別的事務在每次查詢開始時都會生成一個獨立的ReadView。
注意:RC下,在一個事務中,一條查詢語句執行完,事務生成的ReadView就沒用了,下次查詢得重新生成ReadView。
4.2.2 REPEATABLE READ —— 一個事務中第一次讀取資料時生成一個ReadView
按照可重複讀的定義,一個事務啟動的時候,能夠看到所有已經提交的事務結果。但是之後這個事務執行期間,其他事務的更新對它不可見。
對於使用REPEATABLE READ隔離級別的事務來說,只會在第一次執行查詢語句時生成一個ReadView,之後的查詢就不會重複生成了。來用和之前相同的例子再次分析。
比如,現在系統裡有兩個事務id分別為100、200的事務在執行:

此刻,表hero中number為1的記錄得到的版本連結串列如下所示:
假設現在有一個使用REPEATABLE READ隔離級別的事務開始執行:
# 使用REPEATABLE READ隔離級別的事務 BEGIN; # SELECT1:Transaction 100、200未提交 SELECT * FROM hero WHERE number = 1; # 得到的列name的值為'劉備'
這裡和4.2.1節的READ COMMITTED隔離級別的SELECT1分析過程一模一樣,不贅述。查詢出來是name為’劉備’ 的記錄。
我們把事務id為100的事務提交一下,如下:
# Transaction 100 BEGIN; UPDATE hero SET name = '關羽' WHERE number = 1; UPDATE hero SET name = '張飛' WHERE number = 1; COMMIT;
然後再到事務id為200的事務中更新一下表hero中number為1的記錄:
# Transaction 200 BEGIN; # 更新了一些別的表的記錄 ... UPDATE hero SET name = '趙雲' WHERE number = 1; UPDATE hero SET name = '諸葛亮' WHERE number = 1;
此刻,表hero中number為1的記錄的版本鏈就長這樣:
一直到這裡,例子分析和4.2.1節的READ COMMITTED隔離級別的分析過程一樣。接下來,不一樣的來了。
然後再到剛才使用REPEATABLE READ隔離級別的事務中繼續查詢這個number為1的記錄,如下:
# 使用REPEATABLE READ隔離級別的事務300 BEGIN; # SELECT1:Transaction 100、200均未提交 SELECT * FROM hero WHERE number = 1; # 得到的列name的值為'劉備' # SELECT2:Transaction 100提交,Transaction 200未提交 SELECT * FROM hero WHERE number = 1; # 得到的列name的值仍為'劉備'
注意,這個SELECT2的執行過程如下:
- 因為當前事務的隔離級別為REPEATABLE READ,而之前在執行SELECT1時已經生成過ReadView了,所以此時直接複用之前的ReadView。 之前的ReadView的m_ids列表的內容就是 [100, 200],min_trx_id為100,max_trx_id為201,creator_trx_id為0。
- 然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列name的內容是’諸葛亮’,該版本的trx_id值為200,在m_ids列表內,所以不符合可見性要求,根據roll_pointer跳到下一個版本。
- 下一個版本的列name的內容是’趙雲’,該版本的trx_id值為200,也在m_ids列表內,所以也不符合要求,繼續跳到下一個版本。
- 下一個版本的列name的內容是’張飛’,該版本的trx_id值為100,而m_ids列表中是包含值為100的事務id的,所以該版本也不符合要求,同理下一個列name的內容是’關羽’的版本也不符合要求。繼續跳到下一個版本。
- 下一個版本的列name的內容是’劉備’,該版本的trx_id值為80,小於ReadView中的min_trx_id值100,所以這個版本是符合要求的,最後返回給使用者的版本就是這條列name為’劉備’的記錄。
也就是說在REPEATABLE READ隔離級別下,事務的兩次查詢得到的結果是一樣的。記錄的name列值都是’劉備’,這就是為什麼在RR下,不會出現不可重複讀的理由。如果我們之後再把事務id為200的記錄提交了,然後再到剛才使用REPEATABLE READ隔離級別的事務中繼續查詢這個number為1的記錄,得到的結果還是’劉備’。
要想讀到最新name值為’諸葛亮’該如何操作呢?
前提: 把事務id為100、200的事務提交。
- 此時把事務id為300的事務提交,ReadView就沒用了,下次開啟新的事務查詢的時候會生成新的ReadView,m_ids列表中沒有100、200,就可以查詢到name為’諸葛亮’了。
- 如果新的查詢沒有事務,那就沒有ReadView這一說了,直接select查詢就可以查到name為’諸葛亮’的記錄,因為事務100、200已提交。
注意對比:
RR下,一個事務提交時,它生成的ReadView就沒用了。
RC下,在一個事務中,一條查詢語句執行完,事務生成的ReadView就沒用了,下次查詢得重新生成ReadView。
小提示:
在RR下,如果使用START TRANSACTION WITH CONSISTENT SNAPSHOT語句開啟事務,會在執行該語句後立即生成一個ReadView,而不是在執行第一條SELECT語句時才生成。
使用START TRANSACTION WITH CONSISTENT SNAPSHOT這個語句開始,建立一個持續整個事務的ReadView。所以在RC隔離級別下(每次讀都建立ReadView),這個用法就沒意義了,等效於普通的start transaction。
4.2.3 ReadView的可見性規則總結
在存取某條記錄時,只需要按照下邊的步驟判斷記錄的某個版本是否可見:
- trx_id = creator_trx_id時,意味著當前事務在存取它自己修改過的記錄,所以該版本可以被當前事務存取。
- trx_id < min_trx_id時,表明生成該版本的事務在當前事務生成ReadView前已經提交,所以該版本可以被當前事務存取。
- trx_id ≥ max_trx_id時,表明生成該版本的事務在當前事務生成ReadView後才開啟,所以該版本不可以被當前事務存取。
- min_trx_id ≤ trx_id ≤ max_trx_id之間,那就需要判斷一下trx_id屬性值是不是在m_ids列表中,如果在,說明建立ReadView時生成該版本的事務還是活躍的,該版本不可以被存取;如果不在,說明建立ReadView時生成該版本的事務已經被提交,該版本可以被存取。
如果某個版本的資料對當前事務不可見的話,那就順著版本鏈找到下一個版本的資料,繼續按照上邊的步驟判斷可見性,依此類推,直到版本鏈中的最後一個版本。如果最後一個版本也不可見的話,那麼就意味著該條記錄對該事務完全不可見,查詢結果就不包含該記錄。
上面說了,ReadView是基於整庫的。如果一個庫有100G,那麼我啟動一個事務,MySQL就要拷貝100G的資料出來嗎,這樣多慢啊,可是,我們平時的事務執行起來很快啊。
實際上,我們並不需要拷貝出這100G的資料。InnoDB利用版本鏈和活躍的事務id列表,可以實現「秒級建立ReadView」。
思考題:
RR隔離級別下事務T1和T2並行執行,T1先根據某個搜尋條件讀取到3條記錄,然後事務T2插入一條符合相應搜尋條件的記錄並提交,然後事務T1再根據相同搜尋條件執行查詢,結果如何?
分析:根據版本鏈和ReadView分析,T1第一次搜尋3條記錄的時候生成了ReadView,此時T1、T2都在m_ids列表,都是活躍的,那麼T2中插入的版本記錄T1是不可見的,所以事務T1第二次搜尋仍然是3條記錄。此時在RR下避免了幻讀的產生。
由於MySQL的具體實現問題,RR隔離級別下並不能完全避免幻讀(只能很大程度避免),只有加鎖才可以完全避免。
4.3 為什麼不推薦使用長事務?
前面講版本鏈的時候說過,每條記錄在更新的時候都會同時記錄一條回滾的 undo紀錄檔 (也稱為回滾段)。通過回滾操作,都可以得到前一個狀態的值。
當前number為1的記錄name為是'諸葛亮',但是在查詢這條記錄的時候,不同時刻啟動的事務會有不同的ReadView。如圖,要得到name為'劉備'的記錄,就必須將當前值依次執行圖中所有的回滾操作得到。
- 回滾段非常佔用記憶體,那回滾段什麼時候刪除呢?
從上圖可以看到回滾段裡都是之前事務修改過的記錄,事務提交後該記錄的舊版本就不需要了,所以只有當開啟回滾段以來的所有事務都提交的時候,回滾段就可以刪除。
- 為什麼不推薦使用長事務?
長事務意味著系統裡面會存在很老的記錄,事務不提交,記錄的舊版本會一直存在。由於這些事務隨時可能存取資料庫裡面的任何資料,所以這個事務提交之前,資料庫裡面它可能用到的回滾記錄都必須保留,這就會導致大量佔用儲存空間。
在MySQL 5.5及以前的版本,回滾紀錄檔是跟資料字典一起放在ibdata檔案裡的,即使長事務最終提交,回滾段被清理,檔案也不會變小。有時候資料只有20GB,而回滾段有200GB的庫。最終只好為了清理回滾段,重建整個庫。
除了對回滾段的影響,長事務還佔用鎖資源,也可能拖垮整個庫。
- 如何查詢長事務?
在information_schema庫的innodb_trx這個表中查詢長事務,比如下面這個語句,用於查詢持續時間超過60s的事務。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
4.4 非聚集索引與MVCC
前面說過,只有聚集索引記錄才有trx_id和roll_pointer隱藏列,如果某個查詢語句是使用二級索引來執行查詢時,該如何判斷可見性呢?
begin; select * from hero where name = '劉備';
這裡判斷條件是name了,這是一個普通的非聚集索引,沒有trx_id和roll_pointer該怎麼根據版本鏈和ReadView去判斷可見性呢?
注:trx_id是記錄存放該事務的事務id的地方,沒有這一列只能說明非聚集索引記錄沒存,並不代表執行事務時沒有事務id了。
過程如下:
步驟1:非聚集索引頁面的Page Header部分有一個名為PAGE_MAX_TRX_ID的屬性,每當對該頁面中的記錄執行增刪改操作的時候,如下:
// 這裡用虛擬碼說明更便捷 if(如果執行該事務的事務id > PAGE_MAX_TRX_ID) { PAGE_MAX_TRX_ID = 如果執行該事務的事務id; }
所以PAGE_MAX_TRX_ID屬性值代表修改該非聚集索引頁面的最大的事務id。
當SELECT語句根據條件找到某個非聚集索引記錄時,如下:
if (對應ReadView的min_trx_id > PAGE_MAX_TRX_ID) { 說明該頁面中的所有記錄都對該ReadView可見 } else { 執行步驟2 }
步驟2: 根據主鍵回表後,得到滿足搜尋條件的聚集索引記錄後,根據版本鏈找到該ReadView可見的第一個版本,然後判斷該版本中相應的非聚集索引列的值是否與利用該非聚集索引查詢時的值相同。本例子就是判斷可見版本的name是不是’劉備’。如果是,就把這條記錄傳送給使用者端(如果where子句中還有其他搜尋條件的話還需要繼續判斷篩選後再返回),否則就跳過該記錄。
4.5 MVCC小結
所謂的MVCC(Multi-Version Concurrency Control ,多版本並行控制)指的就是在使用READ COMMITTD、REPEATABLE READ這兩種隔離級別的事務執行普通的SELECT操作時,存取記錄的版本鏈的過程。這樣可以使不同事務的讀-寫、寫-讀操作並行執行,從而提升系統效能。READ COMMITTD、REPEATABLE READ這兩個隔離級別的一個很大不同,就是生成ReadView的時機不同,READ COMMITTD在一個事務中每一次進行普通SELECT操作前都會生成一個ReadView,而REPEATABLE READ在一個事務中只在第一次進行普通SELECT操作前生成一個ReadView,之後的查詢操作都重複使用這個ReadView。
5. 全篇的反思與小結,你需要弄懂這幾個問題
- 事務的概念是什麼?
- MySQL的事務隔離級別讀未提交, 讀已提交, 可重複讀, 序列讀各是什麼意思?
- 讀已提交, 可重複讀是怎麼通過檢視構建實現的?
- 事務隔離是怎麼通過ReadView(讀檢視)實現的?
- 並行版本控制(MVCC)的概念是什麼, 是怎麼實現的?
- 使用長事務的弊病? 為什麼使用長事務可能拖垮整個庫?
- 怎麼查詢各個表中的長事務?
- 如何避免長事務的出現?