Java NIO原理 (Selector、Channel、Buffer、零拷貝、IO多路複用)
零丶背景
最近有很多想學的,像netty的使用、原理原始碼,但是苦於自己對於作業系統和nio瞭解不多,有點無從下手,遂學習之。
一丶網路io的過程
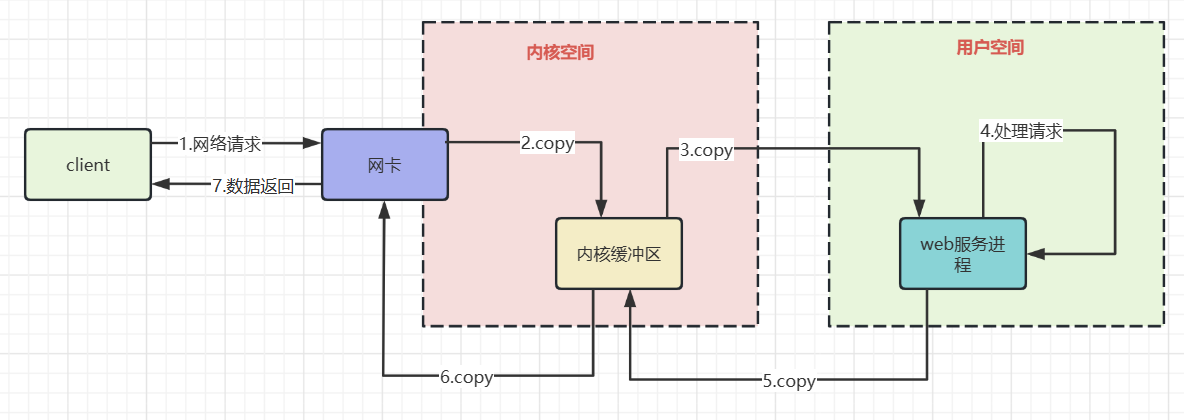
上圖粗略描述了網路io的過程,瞭解其中的拷貝過程有利於我們理解非阻塞io,以及IO多路複用的必要性。
-
資料從網路卡到核心緩衝區
網路卡通過DMA的方式將網路幀copy到核心空間並不是拷貝到核心空間就完事了,因為還需要根據協定對資料進行處理。
所以網路卡使用硬中斷通知cpu,cpu響應後會使用網路卡註冊函數進行收包,然後協定層處理網路幀。
-
資料從核心緩衝區到使用者空間
根據協定處理好的資料,還需要拷貝到使用者空間才能被執行在核心態的應用程式使用==>cpu進行資料拷貝。隨後核心喚醒使用者程序,相當於我們的java程式從阻塞io中被喚醒,繼續執行下一行程式碼的執行。
二丶Socket通訊過程與其中的阻塞點
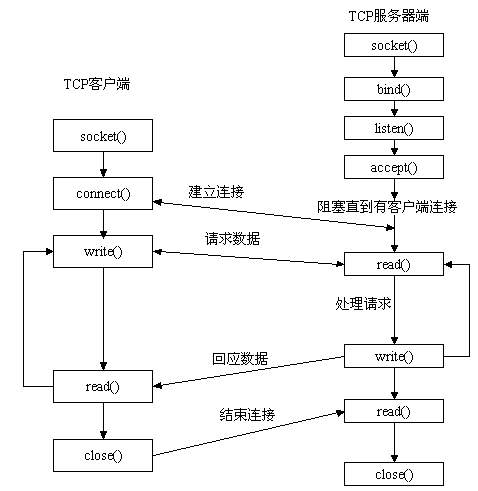
這其中有幾個阻塞的過程
-
accept 系統呼叫:等待使用者端建立tcp連線
這個問題不大,沒有連線那麼阻塞伺服器端執行緒,可以節約cpu資源。
-
read系統呼叫:等待請求資料來到使用者空間
資料從網路卡到使用者空間的過程,執行緒時阻塞的
-
Servlet#service 處理請求是一個同步過程
tomcat根據http協定構造request,並和response作為引數,找到對應Servlet呼叫service方法,Servlet#service方法執行結束,返回內容才能通過write系統呼叫回應資料。
這導致在業務處理上需要使用執行緒池來讓伺服器端可以處理多個並行請求。
-
write系統呼叫:響應資料寫回
write系統呼叫將servlet處理後的響應資料,寫回到檔案描述符中。
三丶NIO解決了什麼問題
1.單執行緒監測若干個檔案描述符是否可以執行IO操作
這就是常說的IO多路複用,那為什麼需要IO多路複用?
儘量使用較少的系統資源處理更多的連線,如果當前單臺伺服器接收了1w個請求,伺服器端當如何處理?
1.1 傳統BIO模型

上面是一段java BIO模型並行處理多請求的範例程式碼,它有以下不足
- 大量的執行緒佔用很大的記憶體空間
- 執行緒切換會帶來很大的開銷
- process方法中需要需要呼叫read系統呼叫,阻塞直到可讀,並沒有真正進行讀寫操作。
1.2. 非阻塞IO
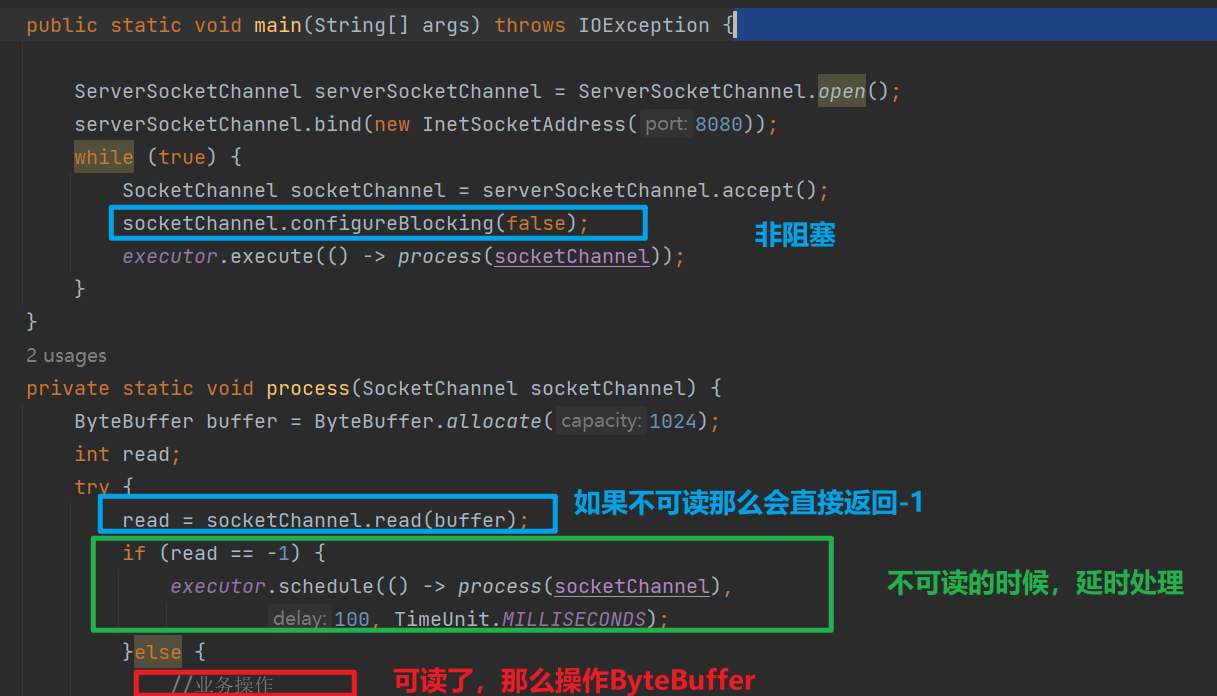
上面是非阻塞IO的一個範例
socketChannel.configureBlocking(false)可以讓後續的read在通道資料沒有就緒的時候直接返回-1,而不是讓執行緒阻塞。這個特性讓排程執行緒池中的執行緒減少了阻塞,從而節省了執行緒資源。
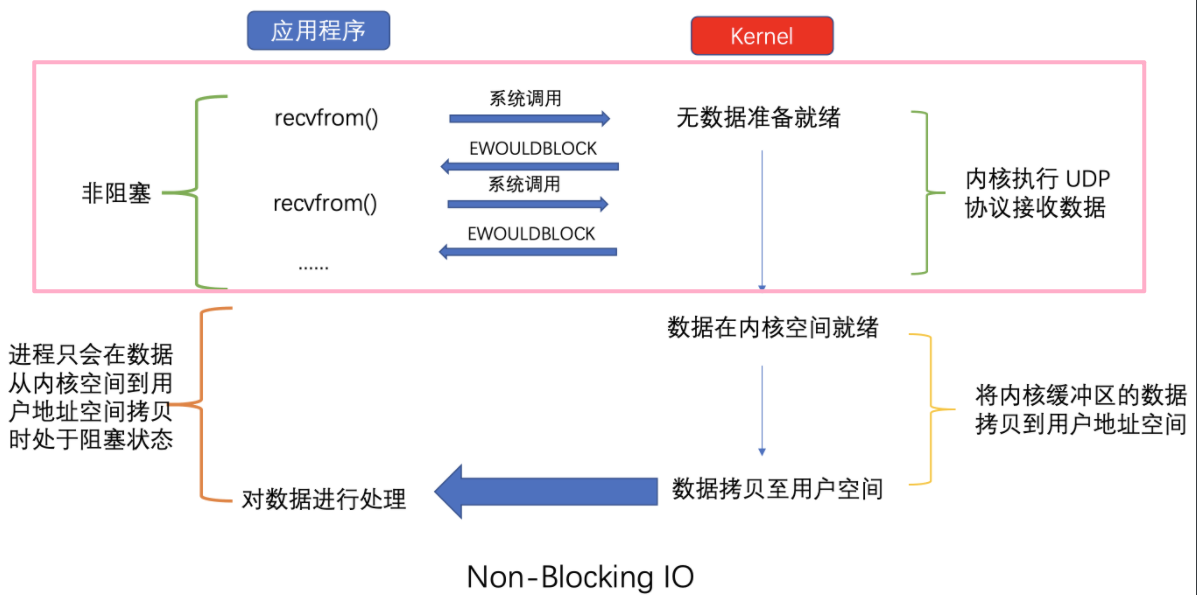
但是這種方式也不是沒有任何缺點,多次系統意味著多次系統呼叫,每次系統呼叫都需要,使用者態<=>核心態的來回切換,需要cpu儲存程序的上下文,呼叫結束還需要恢復程序的上下文。
1.3 IO多路複用

如上是Java IO多路複用的簡陋例子。作業系統提供了多路複用的機制,將連線上來的使用者端都進行註冊,然後不斷迴圈掃描各個使用者端連線,監聽使用者端的請求。但是,多路複用輪詢掃描各個使用者端連線的過程在作業系統核心中進行,極大的加快了多路複用的效率,減少了使用者態和核心態的切換。
2.減少堆內記憶體<=>堆外記憶體的拷貝開銷
使用NIO Channel讀寫時需要需要先讀到堆外記憶體,然後拷貝到堆內記憶體,如果直接使用堆外記憶體則可以減少堆外到堆內的拷貝過程。
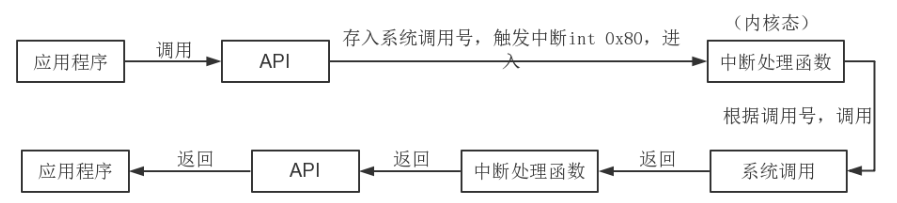
下圖是將Channel資料讀取到Buffer,呼叫IOUtil#read的原始碼
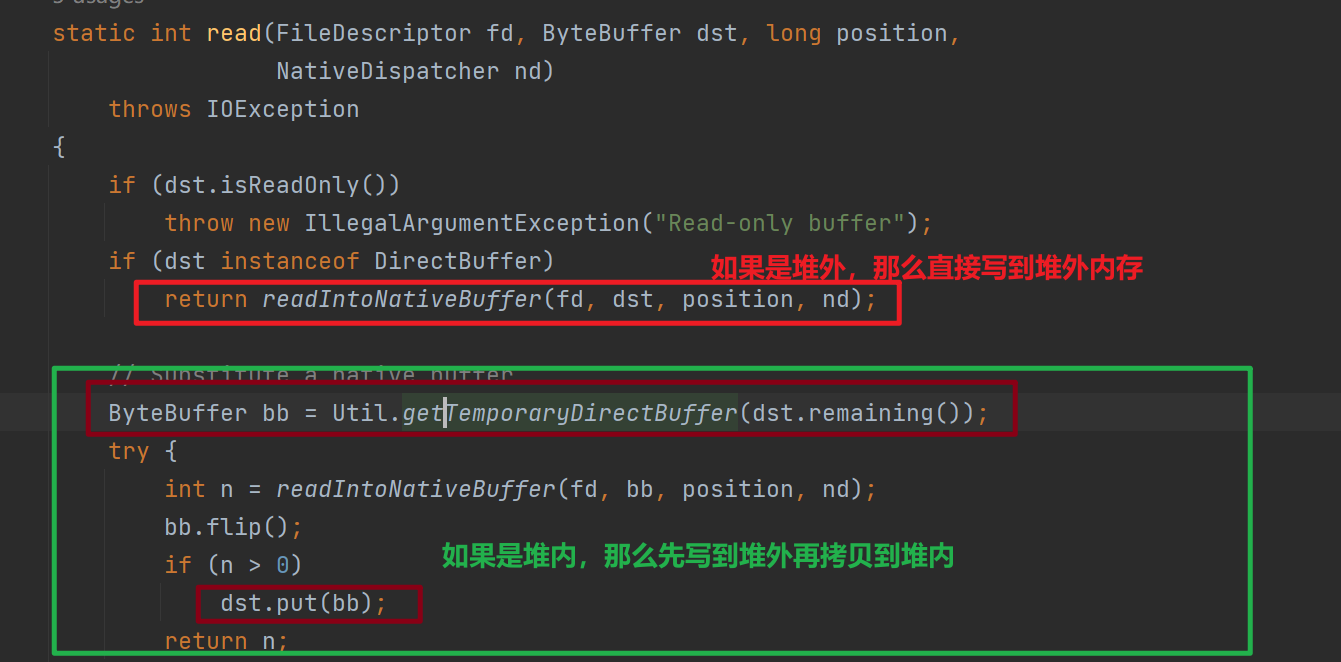
下圖是將Buffer資料寫入到Channel,呼叫IOUtil#write的原始碼
2.1 為什麼需要再堆外記憶體和堆內記憶體來回捯飭?
寫入Buffer資料到檔案描述符,or讀取檔案描述符資料到Buffer都是需要進行系統呼叫的,執行系統呼叫依賴於執行native方法,而執行native方法的執行緒被認為是處於SafePoint,處於SafePoint就有可能發生 GC 重排列物件記憶體的情況。
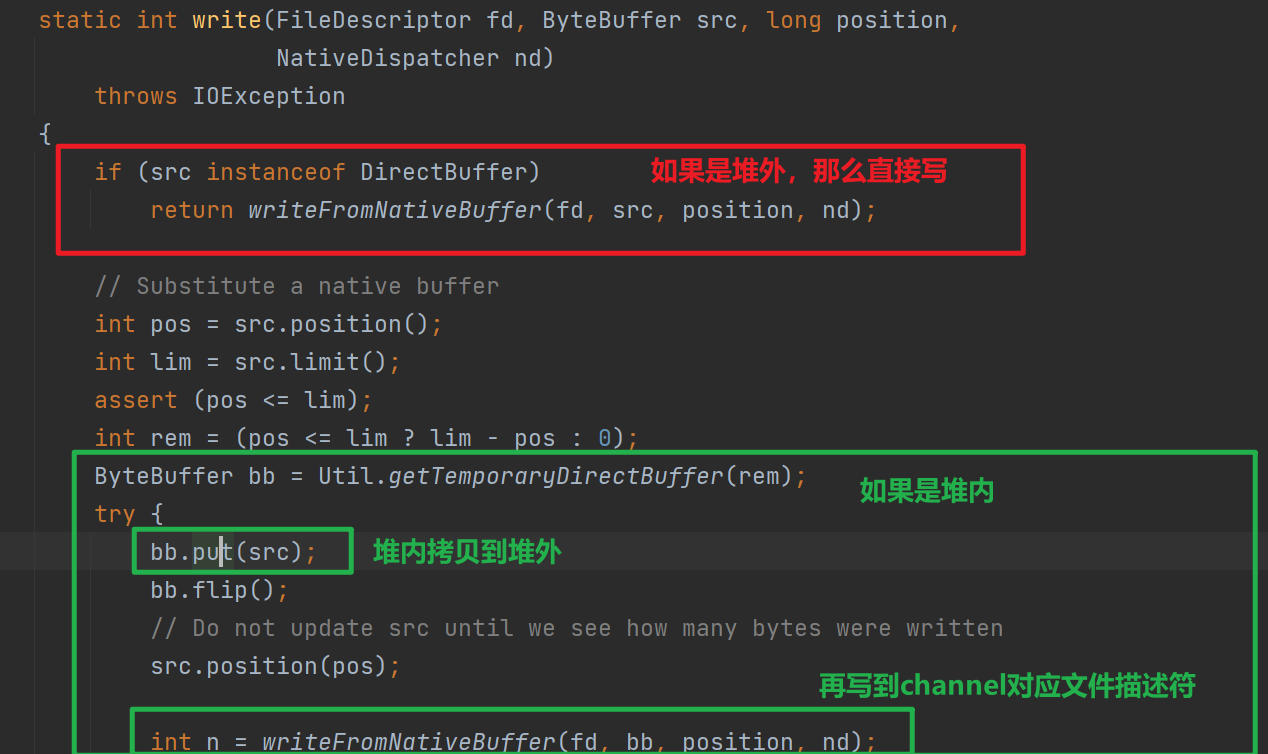
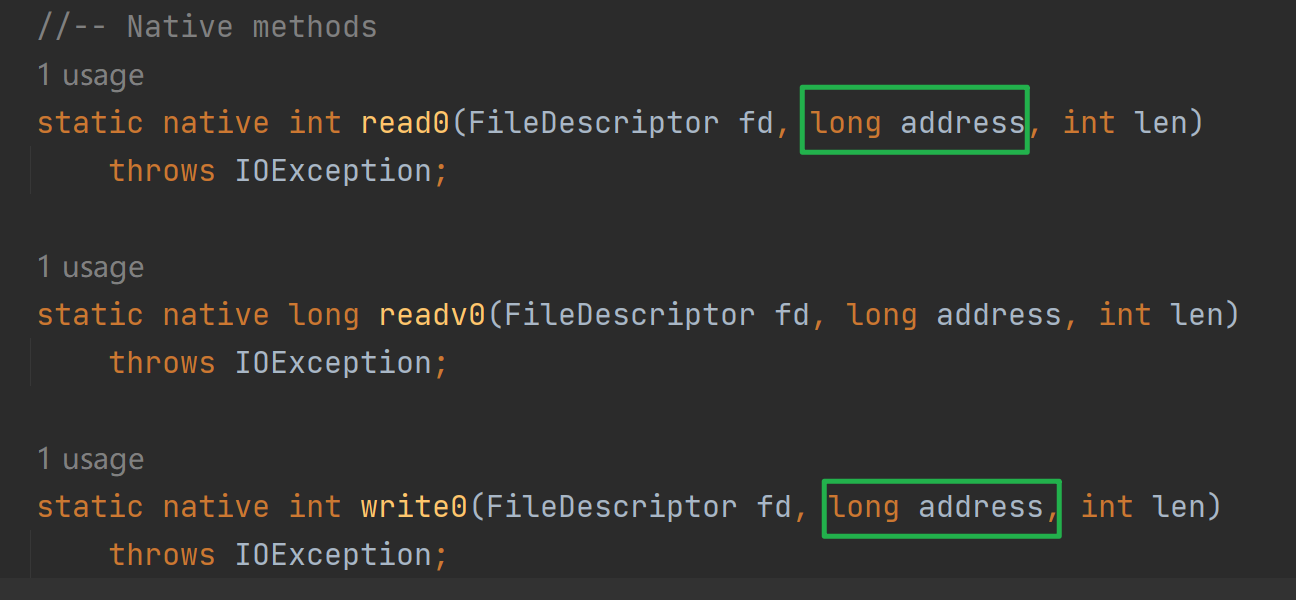
並且這個寫入和讀取是針對地址的(如下圖,最終的native呼叫需要傳入地址)如果寫入或者讀取buffer由於gc移動,那麼地址會改變,但是native方法呼叫可不管這個,就導致讀寫出現錯誤。因此需要依賴於堆外記憶體。
2.2 為什麼Socket基於Inpustream,OutputStream沒有這個問題

以SokcetInputStream的讀為例,讀最終呼叫socktRead0這個native方法,入參fd是當前Socket對應的檔案描述符,byte陣列就是資料最終讀入的目的地。
下圖是native 方法socketRead0的實現

可以看到,其實是先將socket fd內容讀取到c語言宣告的陣列,然後拷貝到Java byte[],這個c語言宣告的陣列其實作用類似於直接記憶體!
3.減少核心空間和使用者空間的拷貝開銷
上面說了直接記憶體的作用:減少堆外堆內的拷貝開銷。無論堆外堆內,都是使用者空間的拷貝。
3.1 DMA控制器替CPU打工

上圖是讀取磁碟檔案的時序圖,可以看到如果沒有DMA技術,藍色部分需要CPU來完成,將浪費寶貴的資源。
再DMA讀取到足夠資料後,會傳送中斷訊號給CPU,讓CPU將核心緩衝區資料,拷貝到使用者緩衝區,隨後CPU再來排程Java程式,Java程式才能操作到使用者緩衝區的資料。
3.2 零拷貝
3.2.1 傳統檔案傳輸
如下圖是我們使用IO流,讀取磁碟檔案,通過Socket API 傳送的流程,其中需要read,和 write 系統呼叫,每次系統呼叫都意味著使用者態與核心態的上下文切換。
並且還有四次資料拷貝,其中兩次由DMA負責打工,兩次由CPU負責拷貝。

如何優化:
- 如果Java程式不需要對磁碟資料內容進行再加工(業務操作)那麼不需要拷貝到使用者空間,從而減少拷貝次數
- 由於使用者空間沒有操作網路卡和磁碟的許可權,操作這些裝置需要由作業系統核心完成,那麼如果作業系統提供新的系統呼叫函數,豈不是就可以減少使用者態與核心態的上下文切換
3.2.2 mmap + write
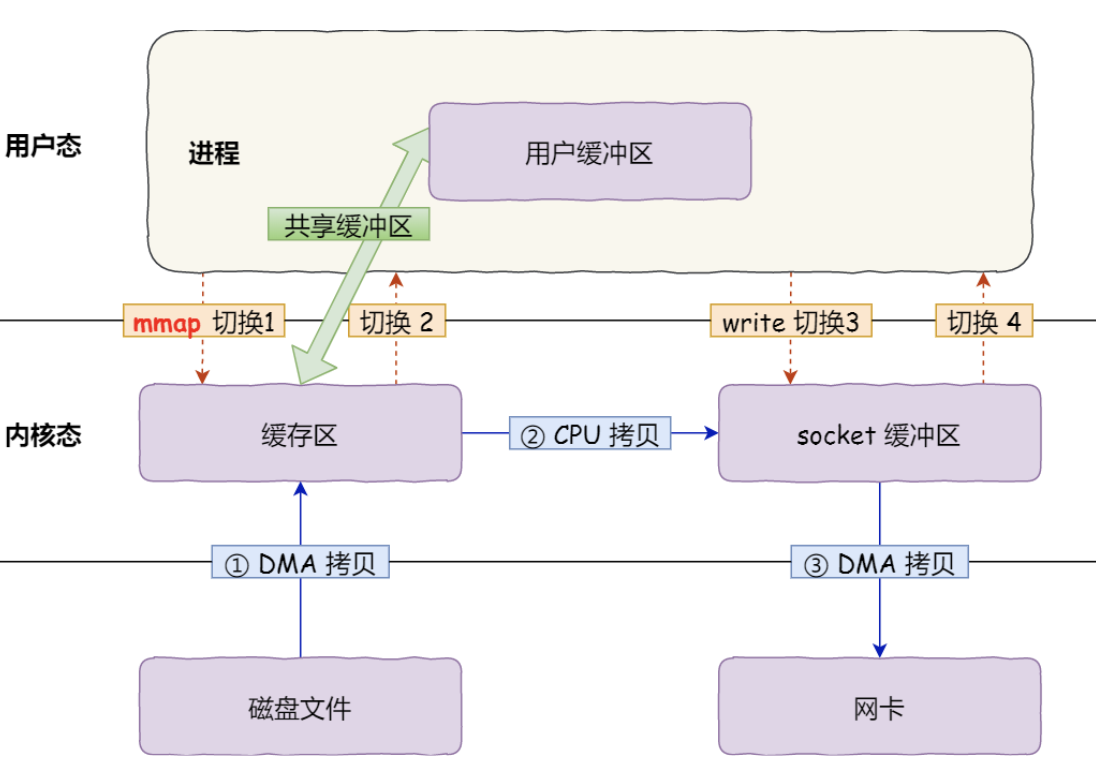
- 應用程序呼叫了
mmap()後,DMA 會把磁碟的資料拷貝到核心的緩衝區裡。接著,應用程序跟作業系統核心共用這個緩衝區; - 應用程序再呼叫
write(),作業系統直接將核心緩衝區的資料拷貝到 socket 緩衝區中,這一切都發生在核心態,由 CPU 來搬運資料; - 最後,把核心的 socket 緩衝區裡的資料,拷貝到網路卡的緩衝區裡,這個過程是由 DMA 搬運的
所以mmap優化了什麼?
mmap並沒有減少系統呼叫帶來的核心態使用者態切換開銷,只是應用程式和核心共用緩衝區,從而讓cpu可以直接將核心緩衝區的資料,拷貝到socket緩衝區,不需要拷貝到使用者緩衝區,再從使用者緩衝區拷貝到socket緩衝區。
3.2.3 sendfile
linux 提供sendfile系統呼叫,只需這一個系統呼叫就可以從一個檔案描述符拷貝資料到另外一個檔案描述符
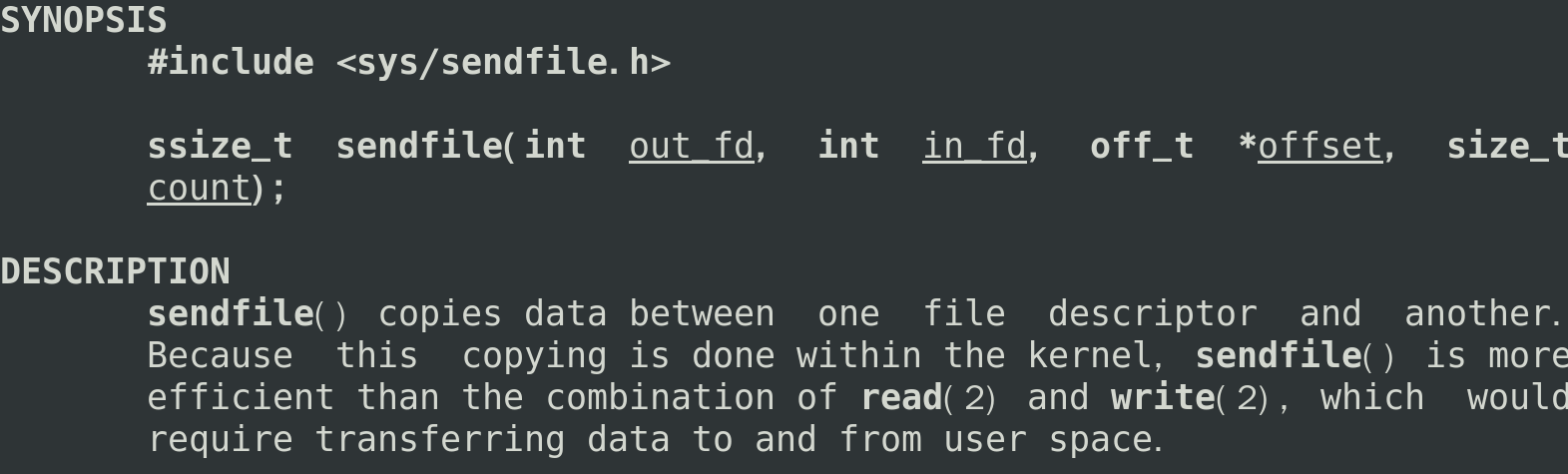

sendfile可以減少write,read導致的系統呼叫,從而優化效率。
如果網路卡支援 SG-DMA(The Scatter-Gather Direct Memory Access)技術,那麼還可以進一步優化。

- 通過 DMA 將磁碟上的資料拷貝到核心緩衝區裡;
- 緩衝區描述符和資料長度傳到 socket 緩衝區,這樣網路卡的 SG-DMA 控制器就可以直接將核心快取中的資料拷貝到網路卡的緩衝區裡,此過程
不需要將資料從作業系統核心緩衝區拷貝到 socket 緩衝區中,這樣就減少了一次資料拷貝。
這便是所謂的零拷貝,減少記憶體層面拷貝資料的次數,以及系統呼叫核心態使用者態的切換,從而優化效能。
3.3 NIO中的零拷貝
3.3.1 FileChannel#map
NIO中的FileChannel.map()方法使用了mmap系統呼叫實現記憶體對映方式
將核心緩衝區的記憶體和使用者緩衝區的記憶體做了一個地址對映。這種方式適合讀取大檔案,同時也能對檔案內容進行更改,但是如果其後要通過SocketChannel傳送,還是需要CPU進行資料的拷貝。

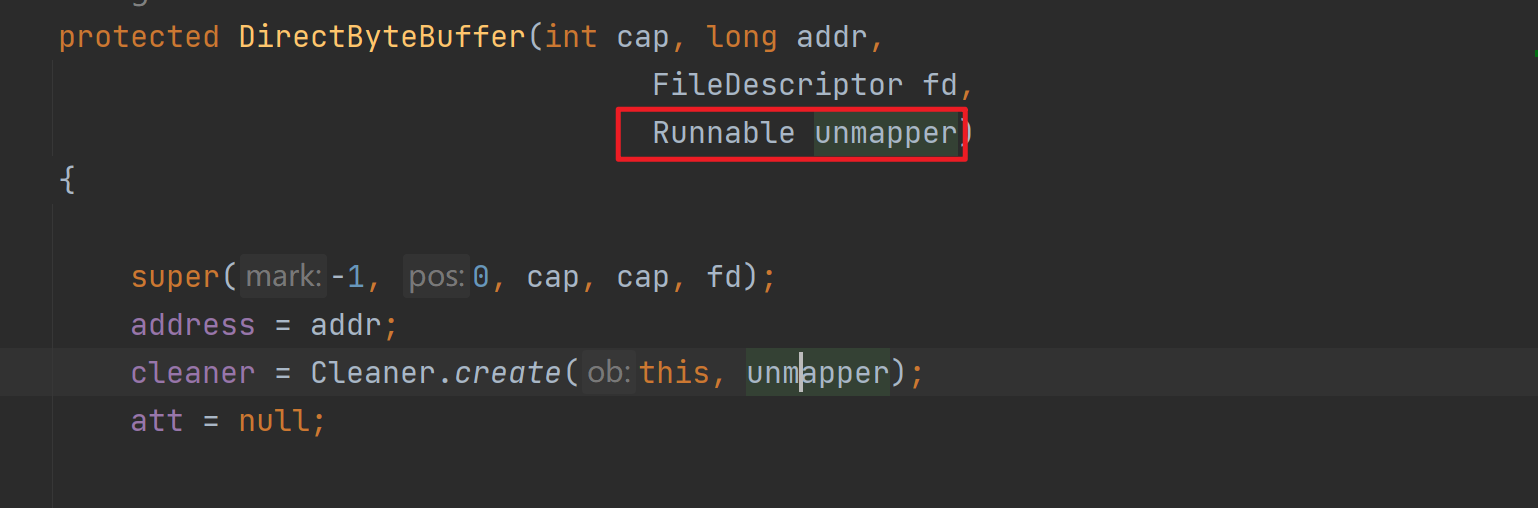
如上是MappedByteBuffer的獲取方式,其實底層是通過反射呼叫DirectByteBuffer的構造方法實現的,其中的cleaner是直接記憶體的回收器,傳入的unmapper會被回撥,從而呼叫native方法實現資源釋放。
這種方式適合讀取大檔案,同時也能對檔案內容進行更改。
3.3.2 FileChannel#transferTo,transerFrom
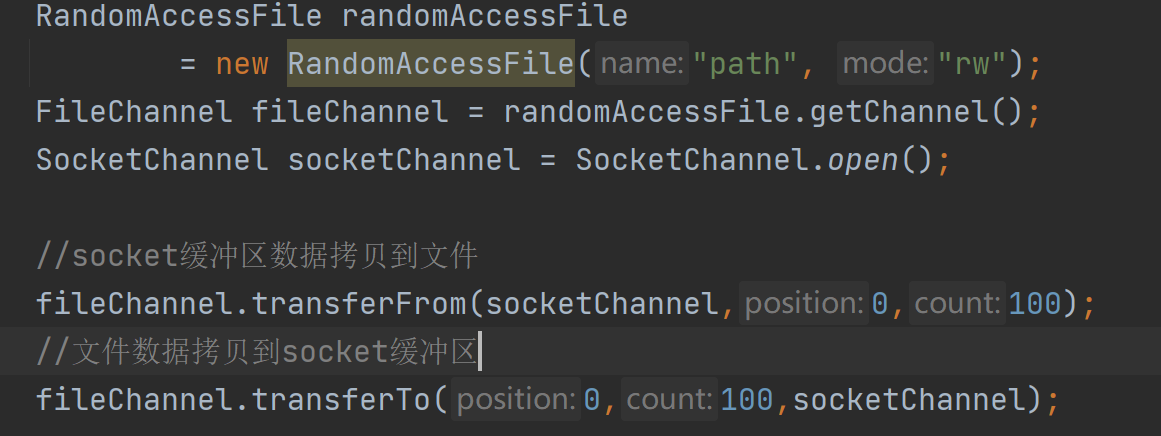
在作業系統層面是呼叫的一個sendFile系統呼叫。通過這個系統呼叫,可以在核心層直接完成檔案內容的拷貝。
4.FileChannel#force強制刷盤
由於CPU的執行速度非常快,所以CPU在執行指令時,通常只能與快取進行互動,而不適合直接操作像磁碟、網路卡這樣的硬體。也因此,在進行檔案寫入時,作業系統也是先寫入到page cache中,快取起來,然後再往硬體寫入。
快取有利也有弊,使用page cache頁快取,應用程式將資料都寫入到了page cache中,但是卻沒有真正寫入磁碟。如果這個時候出現斷電,那麼將出現快取資料丟失。
FileChannel#force會進行fsync系統呼叫

fsync可以實現將page cache快取內容進行落盤,從而保證不丟失(redis aof可以設定持久化機制,通常設定每秒落盤一次,這裡落盤也是fsync系統呼叫)。為了效能考慮,應用程式不可能每寫入一點資料就呼叫fsync,fsync也是有效能損耗的。
四丶IO多路複用 select/poll/epoll
上面我們聊到了IO多路複用解決了什麼問題,以及NIO Selector的基本使用,但是沒有探究在作業系統層面是如何實現的,下面來學習一下。
1.select系統呼叫
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout)
- nfds: 最大的檔案描述符+1,代表監聽這一組描述符(為什麼要+1?因為除了當前最大描述符之外,還有可能有新的fd連線上來)
- fd_set: 是一個點陣圖集合, 對於同一個檔案描述符,可以監聽不同的事件
- readfds:檔案描述符「可讀」事件
- writefds:檔案描述符「可寫」事件
- exceptfds:檔案描述符「異常」事件,一般核心用的,實際程式設計很少使用
- timeout:超時時間:0是立即返回,-1是一直阻塞,如果大於0,則達到設定值的微秒數即返回
- 返回值: 所監聽的所有監聽集合中滿足條件的總數(滿足條件的讀、寫、異常事件的總數),出錯時返回-1,並設定errno。如果超時時間觸發,則返回0
select 其實就是把NIO中使用者態要遍歷的fd陣列拷貝到了核心態,讓核心態來遍歷,因為使用者態判斷socket是否有資料依舊需要通過系統呼叫,切換到核心態進行。
可以看到select依賴了很多點陣圖引數,系統呼叫完後需要使用者程式遍歷一次點陣圖才能直到哪一個fd具備了io事件,並且這個點陣圖大小最大為1024,導致select用起來需要很多位元運算並且最多隻能支援1024路IO。
2.poll系統呼叫
int poll(struct pollfd *fds, nfds_t nfds/*最大監聽的檔案描述符個數*/, int timeout/*最大監聽的檔案描述符個數*/);
其中pollfd為:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
poll可以看作升級版select,它突破了1024個檔案描述符的限制,並且poll函數的監聽和返回是分開的,簡化了程式碼實現。
雖然poll不需要遍歷所有的檔案描述符了,只需要遍歷加入陣列中的描述符,範圍縮小了很多,但缺點仍然是需要遍歷,當加入陣列描述符很多,但是存在事件的fd很少,這個遍歷操作還是有點不划算的。
3.epoll系統呼叫
在linux環境下,java nio中的selector就是基於epoll實現的。
3.1 epoll_create
int epoll_create(int size)
//返回一個fd
//傳入大小作為參考值
epoll_create返回一個特殊的檔案描述符,它代表紅黑樹的根節點。size則是樹的大小,它代表你將監聽多少個檔案描述符。epoll_create將按照傳入的大小,構造出一棵大小為size的紅黑樹。
3.2 epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 是epoll_create的返回值,也就說紅黑樹的根節點
// op 表示操作,比如增加,修改,刪除
//fd 是需要增加,修改,刪除的檔案描述符
// struct epoll_event *event 是一個結構體,如下
struct epoll_event {
uint32_t events; /* Epoll events 讀事件or寫事件,or 異常事件*/
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;//代表一個檔案描述符,初始化的時候傳入需要監聽的檔案描述符,當監聽返回時,此處會傳出一個有事件發生的檔案描述符,因此,無需我們遍歷得到結果了
uint32_t u32;
uint64_t u64;
} epoll_data_t;
用來操作epoll控制程式碼,可以使用該函數往紅黑樹裡增加檔案描述符,修改檔案描述符,和刪除檔案描述符。
3.3 epoll_wait
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
//epfd 是epoll_create的返回值,也就說紅黑樹的根節點
// struct epoll_event *events 是一個陣列,返回的所有觸發了事件的檔案描述符集合
//maxevents代表這個陣列的大小
//timeout 0代表立即返回,-1代表永久阻塞,如果大於0,則代表超時等待毫秒數
3.4 水平觸發,邊緣觸發
epoll有兩種觸發方式,分別為水平觸發和邊沿觸發。
-
水平觸發
只要有資料處於就緒狀態,那麼可讀事件就會一直觸發。
舉個例子,假設使用者端一次性發來了
4K資料 ,但是伺服器recv函數定義的buffer大小僅為1024位元組,那麼一次肯定是不能將所有資料都讀取完的,這時候就會繼續觸發可讀事件,直到所有資料都處理完成。epoll預設的觸發方式就是水平觸發。 -
邊緣觸發
只有資料傳送過來的時候會觸發一次,即使資料沒有讀取完,也不會繼續觸發。
-
觸發方式的設定:
水平觸發和邊沿觸發在核心裡 使用兩個
bit mask區分,分別為:- EPOLLLT 水平 觸發
- EPOLLET 邊沿觸發
需要在註冊事件的時候將其與需要註冊的事件做一個位或運算即可:
ev.events = EPOLLIN; //LT ev.events = EPOLLIN | EPOLLET; //ET
4.總結
select函數需要一次性傳入所有需要監控的連線(在核心中是FD),並在核心中對這些FD進行持續的掃描。當發現其中有FD不老實時,就會通知應用程式有使用者端事件發生了, 上層應用接到通知後,就只能自己再去遍歷所有的FD,尋找有事件發生的連線,然後進行業務處理。
但是select受限於作業系統,掃描的FD個數是受限的。
於是出現了Poll函數,解決了slelect檔案描述符受限的問題。但是,上層應用程式依然要自己去遍歷所有使用者端,尋找哪個使用者端上有事件發 生。高並行場景下,效能依然嚴重受限。
於是又出現了epoll機制。
epoll機制會直接返回有事件發生的FD。這樣就省掉了上層應用頻繁掃描所有使用者端的消耗,進一步解決多路複用的高並行問題。