演演算法基礎(一):串匹配問題(BF,KMP演演算法)
好傢伙,學演演算法,
這篇看完,如果沒有學會KMP演演算法,麻煩給我點踩
希望你能拿起紙和筆,一邊閱讀一邊思考,看完這篇文章大概需要(20分鐘的時間)
我們學這個演演算法是為了解決串匹配的問題
那什麼是串匹配?
舉個例子:
我要在"彭于晏吳彥祖"這段字串中找到"吳彥祖"字串
這就是串匹配
這兩個演演算法太抽象了,我們直接做題吧
題目如下:
在A=「abcaaabaabaaac」中查詢子串B=「aabaaa」,寫出採用BF演演算法和KMP演演算法進行串匹配的全過程
1.BF (Brute Force,暴力)演演算法
(Brute Force,暴力)演演算法
暴力演演算法,我們從第一位開始進行匹配
1.1.若匹配成功,則匹配字串"B"的下一位,
1.2.若匹配失敗,則字串"B"整體向右移動
直到匹配成功
匹配流程圖:
第一次匹配:

可以看見在進行第二個字元"a"的匹配時,匹配失敗,字串"B"整體右移
第二次匹配:

第三次匹配:(不想畫圖..)
第四次匹配:
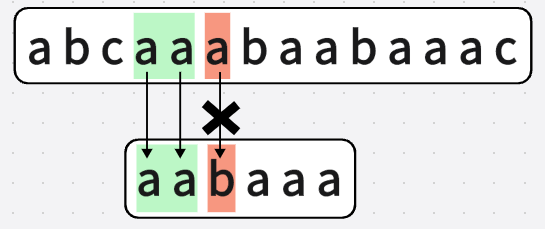
第五次匹配:
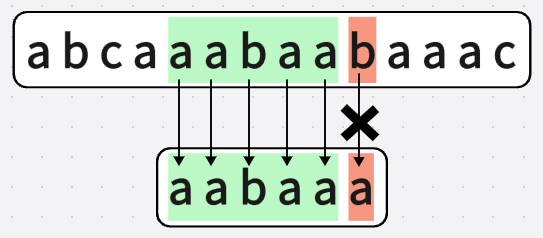
第六次匹配(不想畫圖....算了還是畫吧):
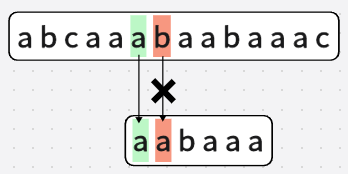
第七次匹配:
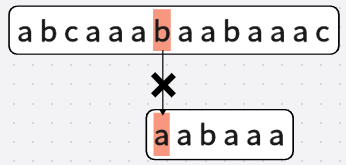
直到第八次:
直到全部字串B全部匹配成功(又或者出現無法匹配的情況)
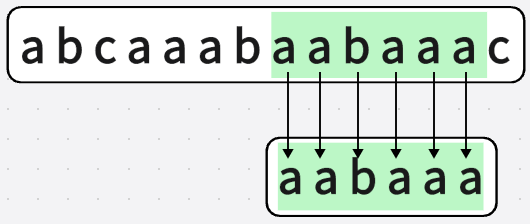
看看程式碼實現:
#include <stdio.h>
#include <string.h>
int find_substring(char *A, char *B) {
int m = strlen(A); // A串長度
int n = strlen(B); // B串長度
int i, j;
for (i = 0; i <= m - n; i++) { // i表示在A串中從第i開始查詢子串B
for (j = 0; j < n; j++) { // j表示在B串中與A串中的字元逐個比較
if (A[i+j] != B[j]) // 不匹配則退出j迴圈
break;
}
if (j == n) // 如果B串全部匹配,則返回A串中子串B第一次出現的位置
return i;
}
return -1; // 如果沒有匹配成功,則返回-1
}
int main() {
char A[] = "abcaaabaabaaac";
char B[] = "aabaaa";
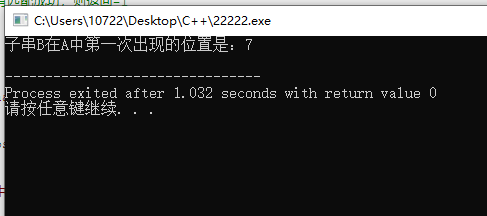
int index = find_substring(A, B);
if (index >= 0)
printf("子串B在A中第一次出現的位置是:%d\n", index);
else
printf("A中沒有子串B\n");
return 0;
}
嗯,看上去毫無技術含量
核心演演算法部分兩個for迴圈寫完了
接下來進入本篇的主要內容
2.KMP(Knuth Morris Pratt演演算法)
這個演演算法是以人名命名的,那麼,做好心理準備,這必然會有一定難度
2.1.我想偷懶(演演算法優化)
在前面BF演演算法的推演中,相信聰明的你一定察覺到了某些步驟看上去很多餘
2.1.1.情況一
回到前面的推演
如果我們用"人"的思維去進行字串匹配,會發現
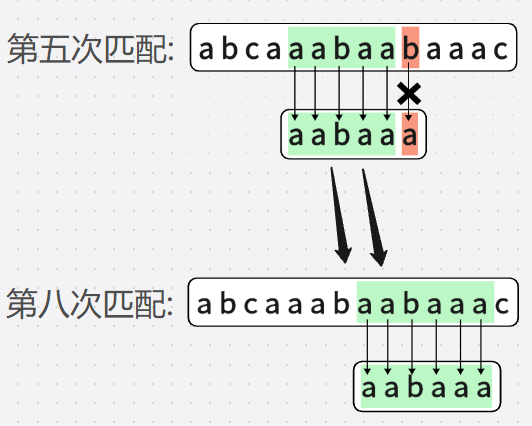
第六次匹配和第七次匹配完全是可以省略的,
我直接跳到"那個看上去正確"的位置
這麼做是對的,可是這沒有確切依據,憑藉的是"直覺"
2.2.2.情況二
你也可能會有這樣的想法:
我把已經配對過的字元全部跳過
"將匹配過的字元都跳過 "
於是,直接從第五次匹配跳到第十次匹配
直接跳到第十次匹配:
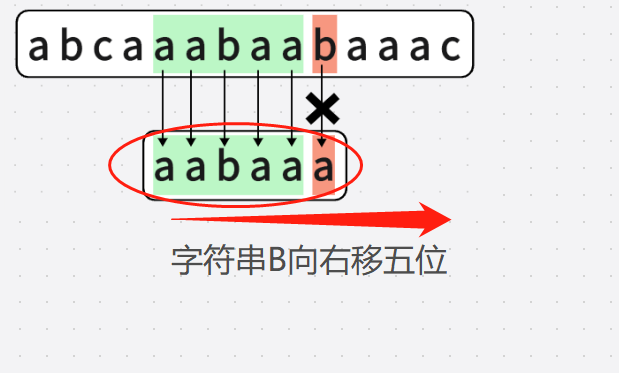
雖然達到了偷懶的目的,但錯過了正確的答案
但你同樣需要記住這個錯誤的情況
這有助於後續的理解
2.2.路標(部分匹配值表)
在前面,你知道,你不想達成情況二,你想要達成情況一
這時,你需要有個路標給你指示
(這或許是個不太好的比喻,
假設你現在吃壞肚子了,在某個大型的廣場找廁所,你會怎麼辦?
我會擡頭去找每個分岔路口的識別符號,

你看見識別符號了,在那邊..)
這時候,我把我的字串"B"的路標給你(後面會解釋路標怎麼來的)
部分匹配值表:
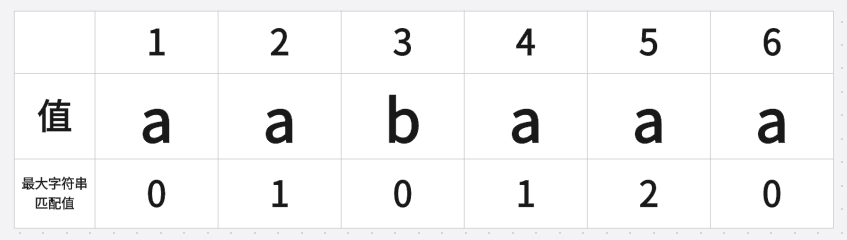
然後這個表該怎麼用呢?
當匹配失敗後,字串"B"的移動位數P等於已匹配字串數減去對應匹配值
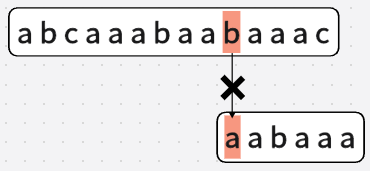
比如說在第五次匹配中,
事實上,它移動的位數P = 已匹配字串數 - 部分匹配值表對應匹配值
也就是 P = 5 - 2 = 3
而我們在推演中,也確實移動了3位
2.3.路標(部分匹配值表)的計算
這時候你開始疑問了?哥們,你這表怎麼來的?
就兩個字"規律"
看看這字串吧"aabaaa"我們試圖從中找出{已匹配字串數}與{字串B}的聯絡
"字首"和"字尾"。 (1)"字首"指除了最後一個字元以外,一個字串的全部頭部組合;
(2)"字尾"指除了第一個字元以外,一個字串的全部尾部組合
"字首"和"字尾"的最長的共有元素的長度
當{已匹配字串數}為1,"a"的字首為空, 字尾為空 共有元素長度為0
當{已匹配字串數}為2,"aa"的字首為[a], 字尾為[a], 共有元素長度為1
當{已匹配字串數}為3,"aab"的字首為[a,aa], 字尾為[b,ab], 共有元素長度為0
當{已匹配字串數}為4,"aaba"的字首為[a,aa,aab], 字尾為[a,ba,aba], 共有元素長度為1
當{已匹配字串數}為5,"aabaa"的字首為[a,aa,aab,aaba], 字尾為[a,aa,baa,abaa], 共有元素長度為2
當{已匹配字串數}為6,"aabaaa"的字首為[a,aa,aab,aaba,aabaa],字尾為[a,aa,aaa,baaa,abaaa],共有元素長度為2,但是這已經無所謂,當匹配完成,部分匹配值表不再被需要
此時我們把共有元素填到表中,就得到了我們的"路標"表,當然了,他真正的名字是"部分匹配值表"
這時你會有兩個疑問:
1.子串B=「aabaaa」的部分匹配值表為什麼與A=「abcaaabaabaaac」是否有關?為什麼?
答:無關
在KMP演演算法中計運算元串B的部分匹配表時,我們只需要關注B本身,而不需要考慮B要在哪個字串中進行匹配。
具體而言,部分匹配值的計算是通過B串本身的字首和字尾來確定的,並不依賴於任何與B進行匹配的字串的特定屬性。
因此,子串B的部分匹配值表與A字串中的字元內容和長度無關。可以在不考慮主串A的情況下,完全獨立地計算出B的部分匹配值表。
2.為什麼要如此麻煩地使用KMP演演算法,而不是使用更為方便地BF演演算法?
來吧,演演算法永遠離不開的好朋友,時間複雜度O()
2.1.現在假設字串A,B的長度分別為n,m
(1)BF演演算法
BF演演算法如此暴力,他的時間複雜度自然也很暴力,
不考慮最好最壞,平均的情況:在文字串和模式串的匹配字元數量較為相等的情況下,BF演演算法的時間複雜度為O(nm/2),也就是O(nm)。
(2)KMP演演算法
考慮最好最壞情況
-
最好的情況:當文字串和模式串的匹配字元非常少時,KMP演演算法的時間複雜度為O(n),其中n是文字串的長度。
-
最壞的情況:當文字串和模式串匹配字元非常多且不匹配時,KMP演演算法的時間複雜度為O(n+m),其中n是文字串的長度,m是模式串的長度。
-
平均的情況:在文字串和模式串的匹配字元數量比較接近的情況下,KMP演演算法的時間複雜度為O(n+m)。
你看見了嗎? nm和n+m,直接少了一個數量級,以人名命名的演演算法還是有點東西的
所以,結論:因為KMP演演算法的時間複雜度遠低於BF演演算法,KMP演演算法更高效
好了你已經掌握了KMP演演算法思想的百分之七十了,其中最核心的部分匹配值表你已經掌握了
接下來的內容,是關於程式碼實現的
2.4.next()陣列
這是便於程式碼實現和使用的{部分匹配值表}版本,它本質上還是部分匹配值表
既然是不同版本,那麼它一定會遵循某些規則
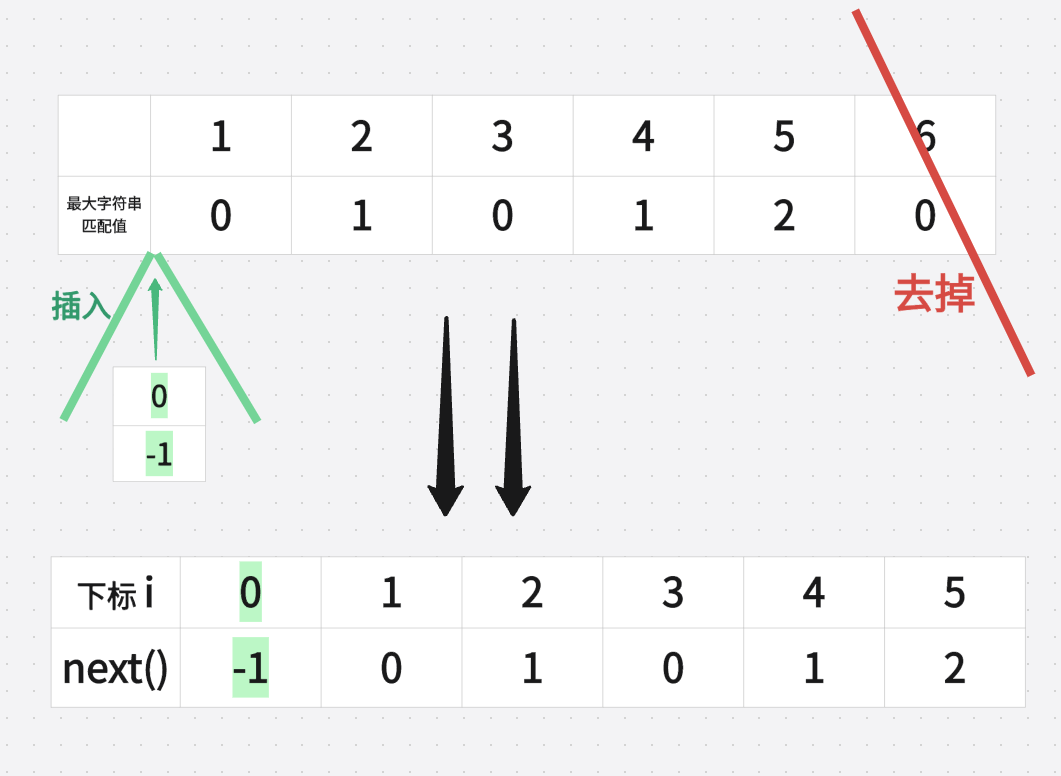
部分匹配表為[ 0 1 0 1 2 0 ],則對應的next陣列為[ -1 0 1 0 1 2]。
具體操作:整體右移,然後首位賦值為-1
(1)第一步:整體右移
(2)第二步:首位賦值-1,
在KMP演演算法中,next陣列的第一個元素next[0]的值必須為-1。
這是因為在演演算法中需要將待匹配串移動1個位置,如果next[0]的值為0,則下一次匹配就會跳過第一個字元,進入一個錯誤的狀態。
而將next[0]設定為-1,則下一次匹配將從第一個字元開始,以正確的方式繼續匹配。
又或者我們以另一種方式去理解:
第二種理解方式:
我們依舊使用那個方法去計算字串匹配失敗後移動的位數,移動位數P = 已配對字串數 - next[i]
所以 如果一個字元都沒配對,也就是匹配的字串為0那麼 移動位數 P = 已配對字串數 - next[0] = 0 - (-1) = 1
如果配對了5個字元,那麼 移動位數 P = 已配對字串數 - next[5] = 5 - 2 = 3
如果還是理解不了,試著自己做題,或者上機試試
例題:A="aabbaabbaaabaac" B="aaabaa" 寫出他的部分匹配表和next[]陣列,並寫出它匹配的過程
2.5.程式碼實現KMP演演算法
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void getNext(char* p, int* next, int n);
/* 在A中查詢子串B的位置 */
int kmp_search(char* A, int n, char* B, int m)
{
int i = 0, j = 0;
int *next = (int*)malloc(sizeof(int) * m); // 申請next陣列
getNext(B, next, m); // 計算B串的next陣列
while (i < n && j < m) { // 從頭到尾掃描A串和B串
if (j == -1 || A[i] == B[j]) { // 匹配成功或者失配
i++;
j++;
} else {
j = next[j]; // 失配時根據next陣列調整j的位置
}
}
free(next); // 釋放申請的空間
if (j == m) { // 匹配成功
return i - m;
} else { // 匹配失敗
return -1;
}
}
/* 計算模式串的next陣列 */
void getNext(char* p, int* next, int n)
{
int j = 0, k = -1;
next[0] = -1; // next陣列的第一個值為-1
while (j < n - 1) { // 計算next陣列
if (k == -1 || p[j] == p[k]) { // 相等情況
j++;
k++;
next[j] = k;
} else {
k = next[k]; // 不相等情況,回溯(k指標回溯)
}
}
}
int main()
{
char A[] = "abcaaabaabaaac";
char B[] = "aabaaa";
int lenA = strlen(A); // 計算A的長度
int lenB = strlen(B); // 計算B的長度
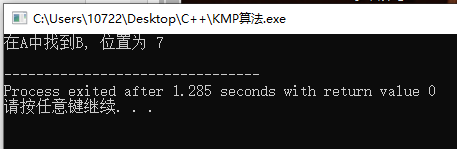
int pos = kmp_search(A, lenA, B, lenB); // 在A中查詢B的位置
if (pos == -1) {
printf("在A中沒找到B!\n");
} else {
printf("在A中找到B, 位置為 %d\n", pos);
}
return 0;
}