ChatGPT的原理與前端領域實踐
一、ChatGPT 簡介
ChatGPT的火爆
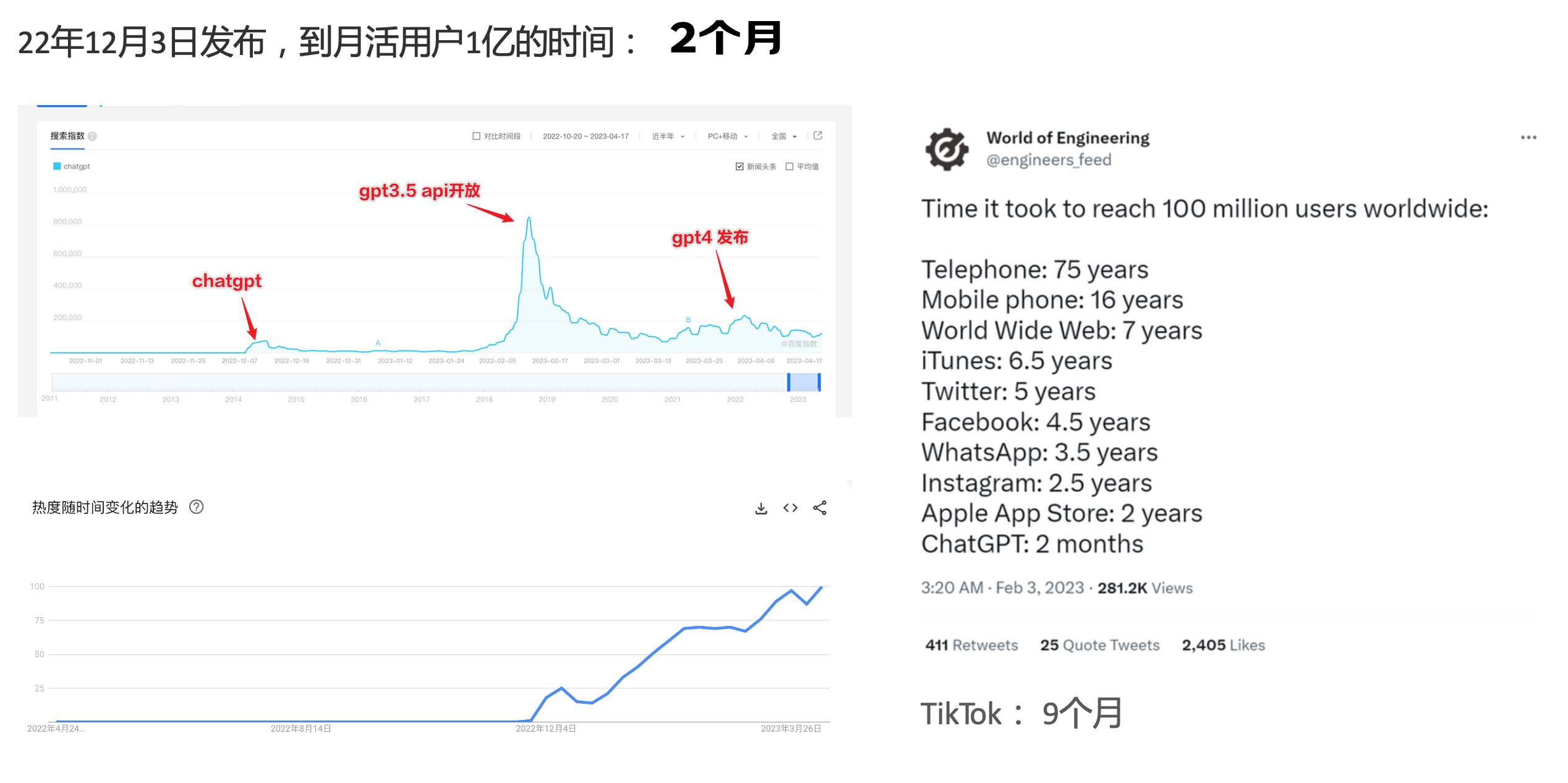
ChatGPT作為一個web應用,自22年12月釋出,僅僅不到3個月的時間,月活使用者就累積到1億。在此之前,最快記錄的保持者也需要9個月才達到月活1億。
ChatGPT的反爬
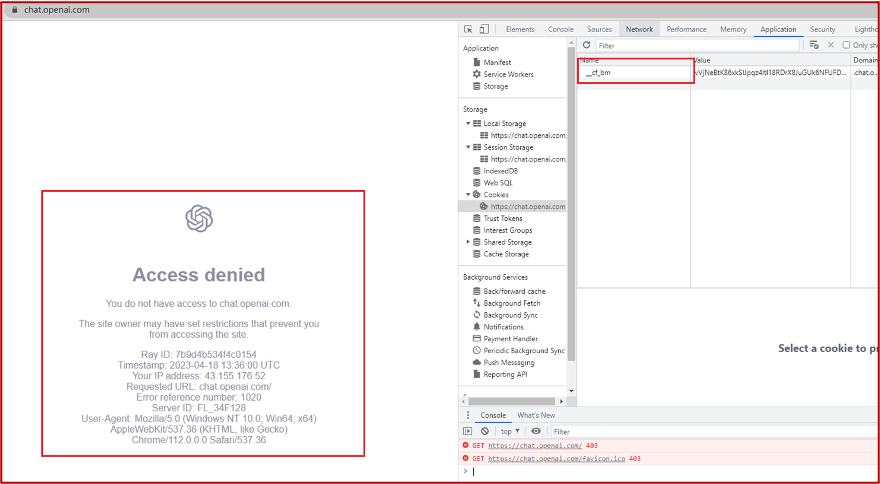
https://chat.openai.com 因為各種政策&傾向性問題,ChatGPT目前在中國無法存取。而它又是如此火爆,所以就有大量使用者通過代理、爬蟲等形式來體驗ChatGPT。
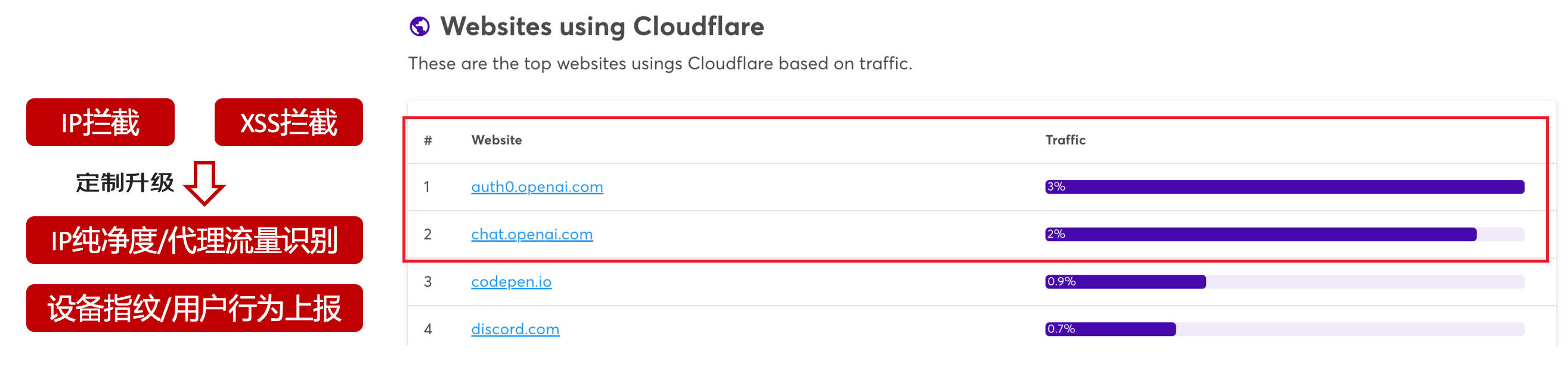
OpenAI不是專業做網路服務的公司,因此把反爬交給第三方公司CloudFlare去做。

CloudFlare目前全球最大CDN服務商,佔比16%;而OpenAI的流量在CloudFlare中佔比已經佔據前二。
ChatGPT的打字效果
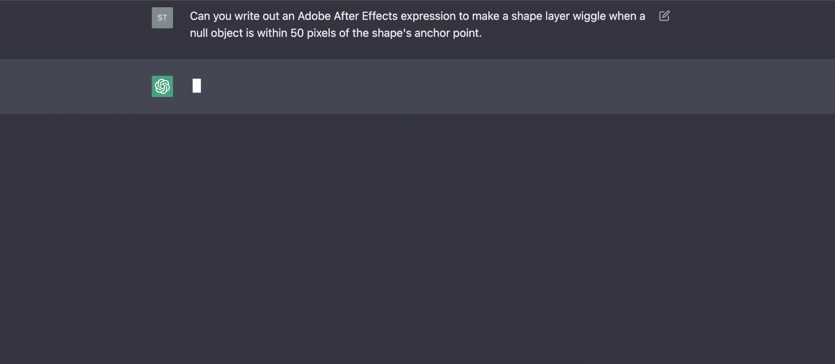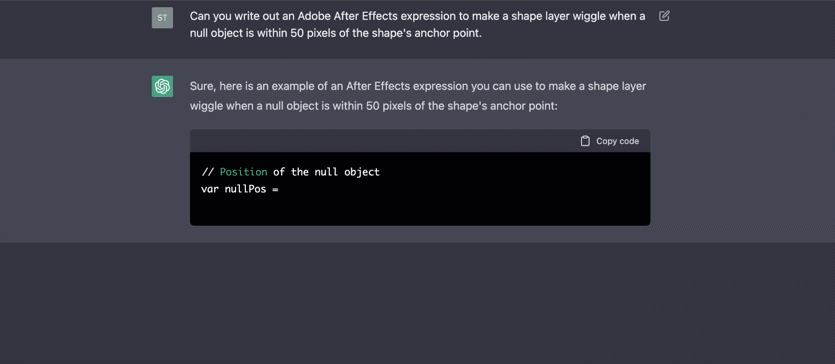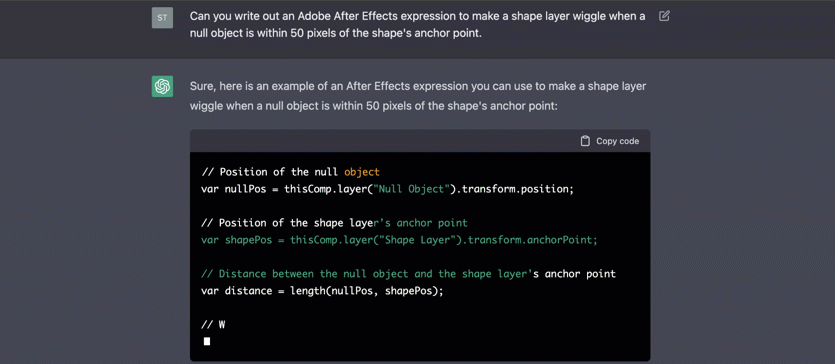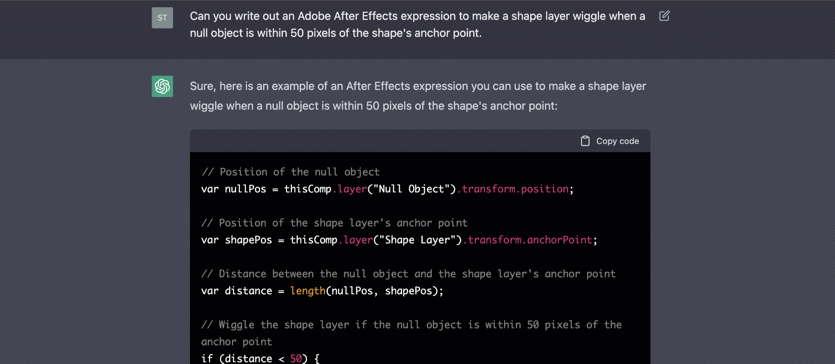
可以看到ChatGPT的輸出是逐字輸出的打字效果,這裡應用到了SSE(SeverSideEvent)伺服器端推播的技術。一個SSE服務的Chrome開發工具化network截圖 :
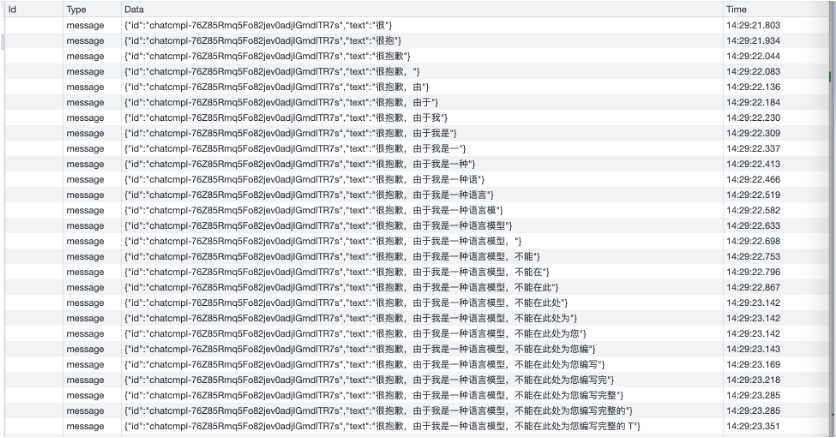
SSE對比常見Websocket如下:
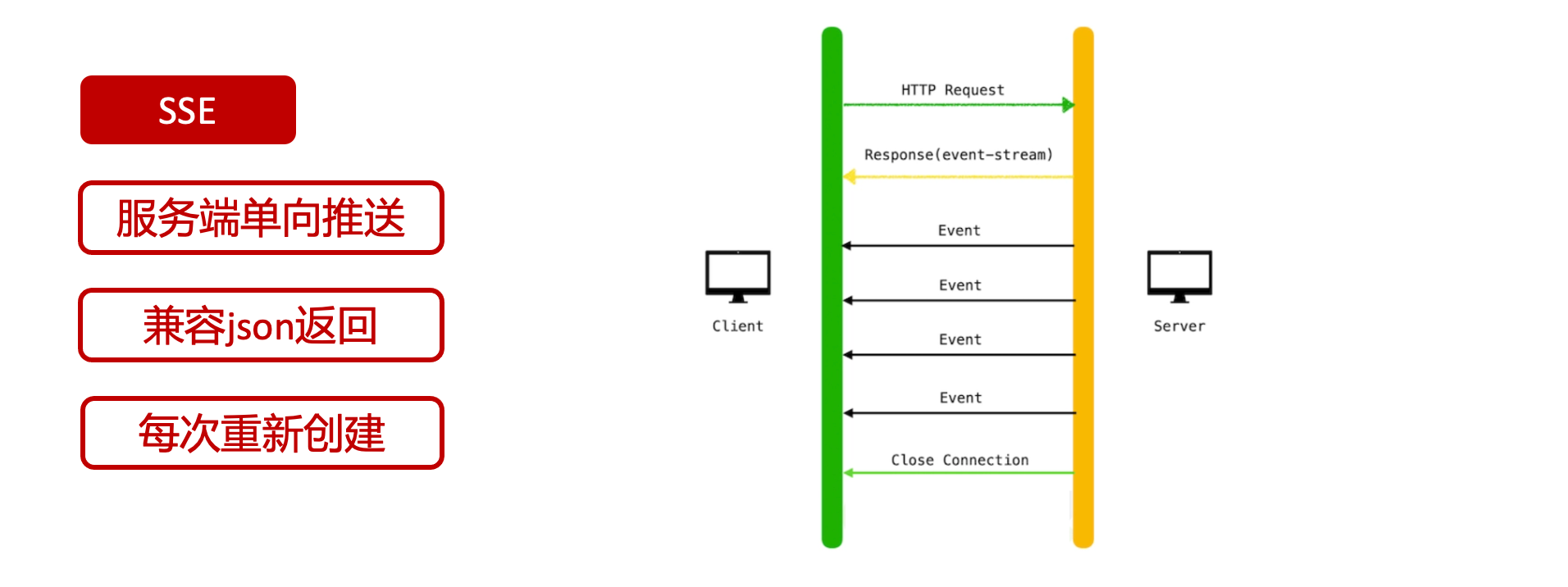
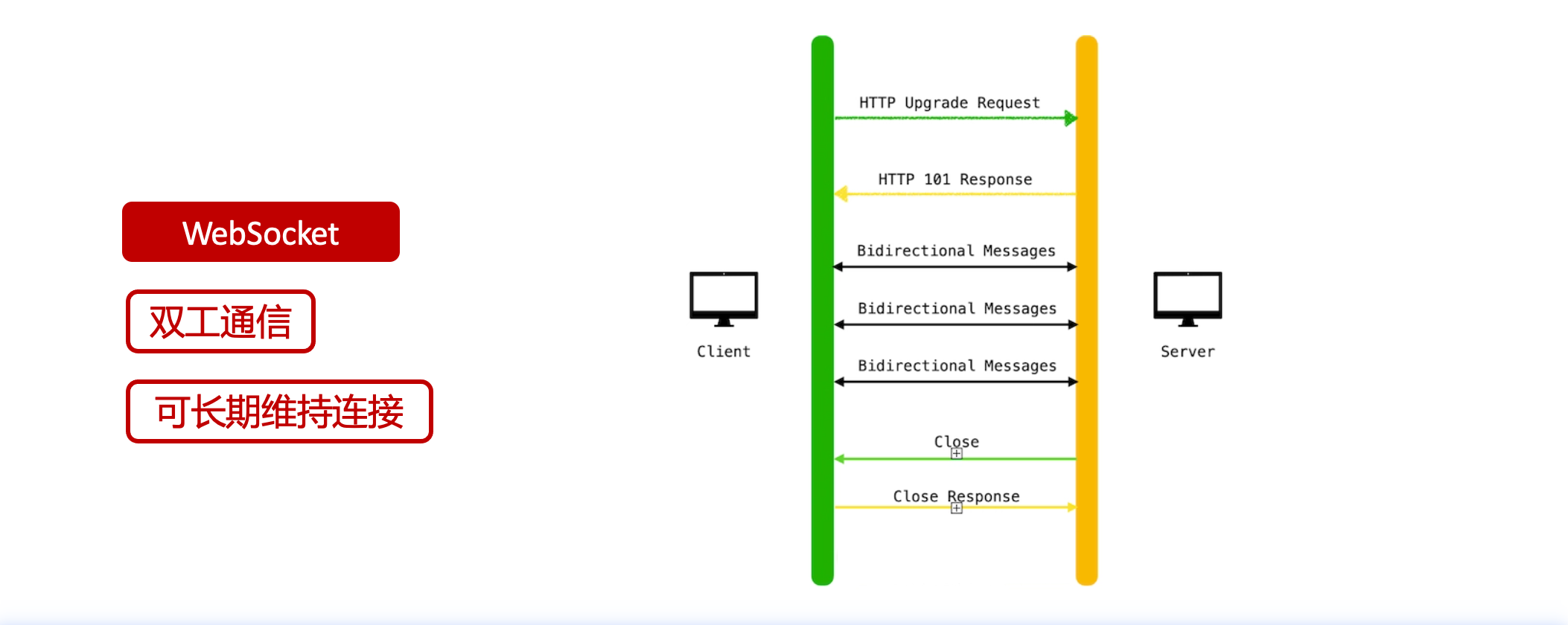
那麼這種打字效果它是故意的還是不小心的?
二、ChatGPT核心原理

ChatGPT我們可以拆解成 Chat、G、P、T 這四個部分講述。在後續內容前,我們先補充幾個機器學習容易理解的概念:
1.模型:所謂模型,本質上就是一個程式(函數),類似 y=ax+bx^2,這裡的a和b就是引數,比如GPT3的引數量就是175B說的就是1750億引數的程式,ChatGLM-6B的引數量是60億。
2.機器學習:我們平時寫的函數,是人來控制的邏輯和引數,而機器學習指的是機器通過某種方式(訓練)來確認引數。這個找特定引數的函數的過程,一般分別為3步:
- 確定函數集合:儘可能窮盡所有引數的可能,比如文章中常見的CNN、RNN、Transform等就是函數集合;
- 資料:通過資料集,得到評價函數好壞的方式;
- 執行過程的引數:比如每批次對每個函數執行多少次,最大執行多少次等,這些引數一般稱為「超參」,區別於函數內的引數(演演算法工程師一般自嘲的調參工程師,指的是這個「超參」)
Generative 文字接龍
ChatGPT本質上是個不斷遞迴執行的生成式的函數,下面我們來看2個例子:
Case1:蘿蔔青菜
當你看到蘿蔔青菜這4個字的時候,腦海中想的是什麼?
我想大概率是各有所愛。
給到GPT的時候,GPT根據這4個字和逗號,推測出下個字的大概率是各

然後GPT會再次將蘿蔔青菜,各輸入給自己,推測出下個字的大概率是有

這就是ChatGPT在輸出文字時是逐字輸出的原因,這種形式最符合LLM執行的底層原理,在使用者體驗上也能讓使用者更快看到第一個字,體驗上接近聊天而不是閱讀。它是故意的。這裡我們得到第一個結論:
ChatGPT(模型 / Fn)的執行原理是每次輸入文字(包含上次返回的內容),預測輸出後續1個字詞。
Case2:書呆子
舉個【原創】前端技術十年回顧 文章中的例子:

在這個例子中,為什麼輸出是「欺負一樣」?
從全文中看,這裡的主體應該是前端技術,單純考慮前端技術和就像在小學被,我們可以想出「推廣」、「普及。即使不考慮「前端技術」,單純從就像在小學被,還有可能推測出後文是「教育」、「表揚」。都很難聯想到「欺負」。
這裡出現「欺負」,很大原因是在前文中欺負(就像,這幾個關鍵字的影響遠大於前端技術。所以我們得到第二個結論:
在生成式語言模型中,上文單詞離得越遠,對生成結果的影響就越小
文字接龍VS完形填空
這裡補充下GPT類似的BERT,他們都是基於後面提到的Transform結構,他們的對比如下,總的來說,文字接龍更服務人類大部分情況下的語言模式,因此像馬斯克也更青睞於這種第一性原理的東西。

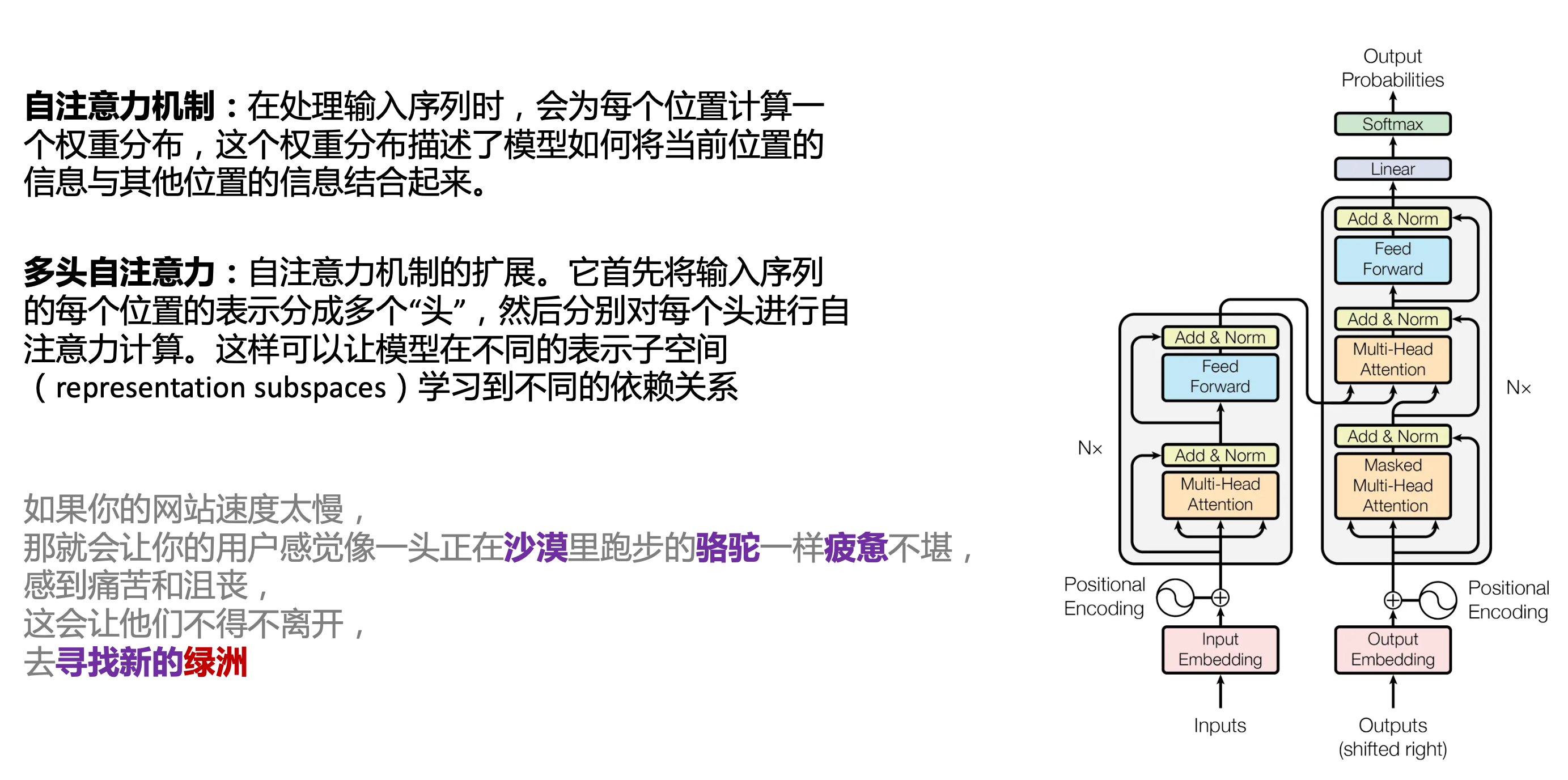
Transform 注意力機制
Case3:綠洲

在這個Case中,綠洲的出現,反而不是因為最近的尋找新的,而是3句話之前的沙漠和駱駝。這裡就不得不提到大名鼎鼎的Transform結構,這是Google在2017年在一篇論文 《Attention is all you need》首次提出的一種類神經網路結構,它和核心是自注意力機制,用來解決長距離文字的權重問題。
作者不是機器學習專業,就不展開說了,建議看相關論文和講解的文章。
Pretrained 預訓練
通過前面的文字接龍模式,用大量資料喂出來的預訓練模型,使其具備通用的語言能力,這裡的預訓練有2層含義:
- 能完成各種通用NLP任務(分類、排序、歸納等等)
- 稍加微調訓練,能完成特定領域的語言任務(不必從頭開始)

Chat 對話(通過Finetuning實現)
因為預訓練是無人類的監督,因此通用模型不一定按照聊天形式返回文字,因為它的訓練素材包羅萬象,比如我說今天天氣差,它根據歷史的經驗:今天天氣差的表述方式有下面幾種,就會輸出這句話的不同的表述,而不是像聊天一樣跟我一起吐槽 。下面的OpenAI的GPT3模型對今天天氣差的輸出:

要讓GPT3像聊天一樣輸出,就需要有針對性的對它就行微調(fine-tuning)訓練,例如通過特定的問答結構的語料訓練:

能聊天之後,想要上線,就必須給模型上枷鎖,不能回答和人類價值觀不符的內容,否則資本主義的鐵拳也會降臨
OpenAI通過人工標註和強化訓練的方式提升ChatGPT回答質量並校正它的價值觀傾向,想要更多瞭解這塊內容,可以瞭解下ChatGPT背後的演演算法模型。

三、ChatGPT的應用
OpenAI官方給到了49個常見的ChatGPT應用場景:
https://openai.com/blog/chatgpt
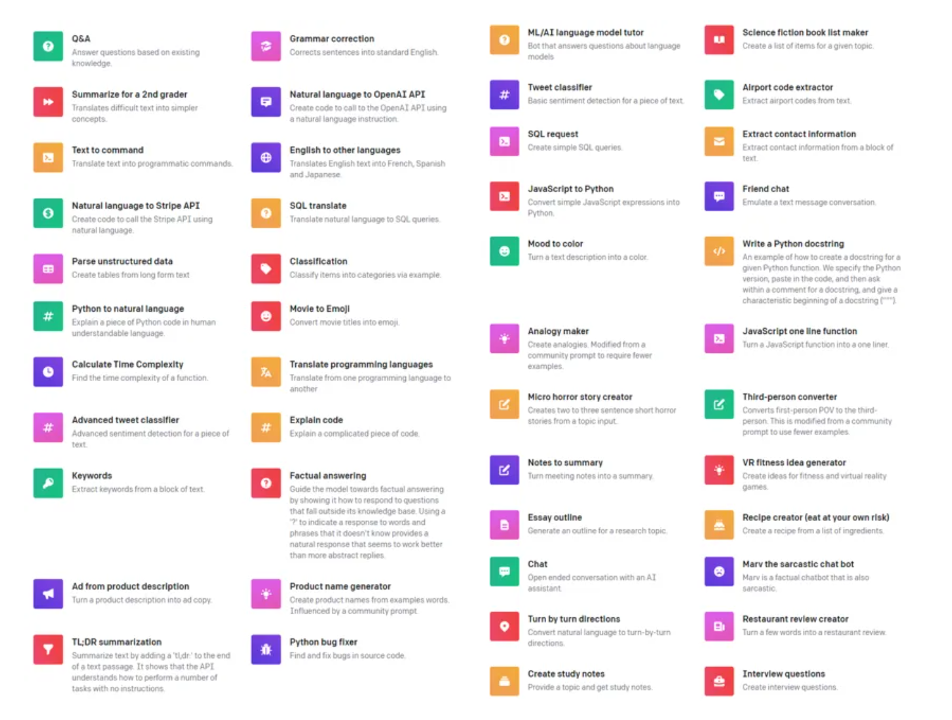
總的來說可以分為:
- 文案創作
- 提煉總結
- 程式碼編寫
- 語言美化/跨語言轉換
- 角色扮演
對於前端開發同學來說,最關注它的程式碼能力。正好在一個小程式轉taro重構的專案中體驗了ChatGPT的能力:
1. 能理解小程式模板語法,並轉換出ts的taro元件
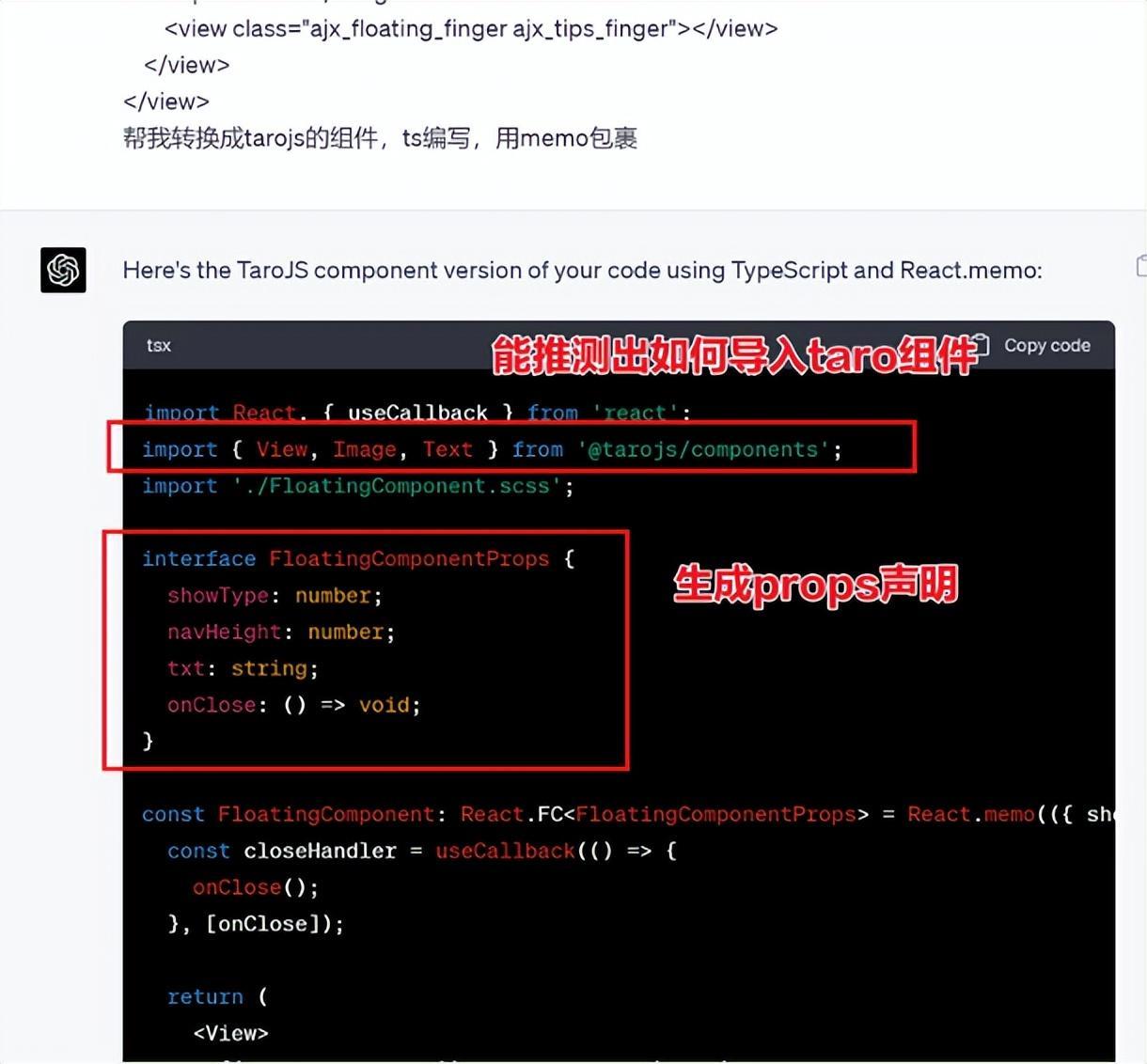
2. 理解小程式頁面邏輯,並修正props
小程式的頁面邏輯page.js是獨立於index.wxml的,在得到純wxml生成的taro元件後,把page.js的程式碼合併進去
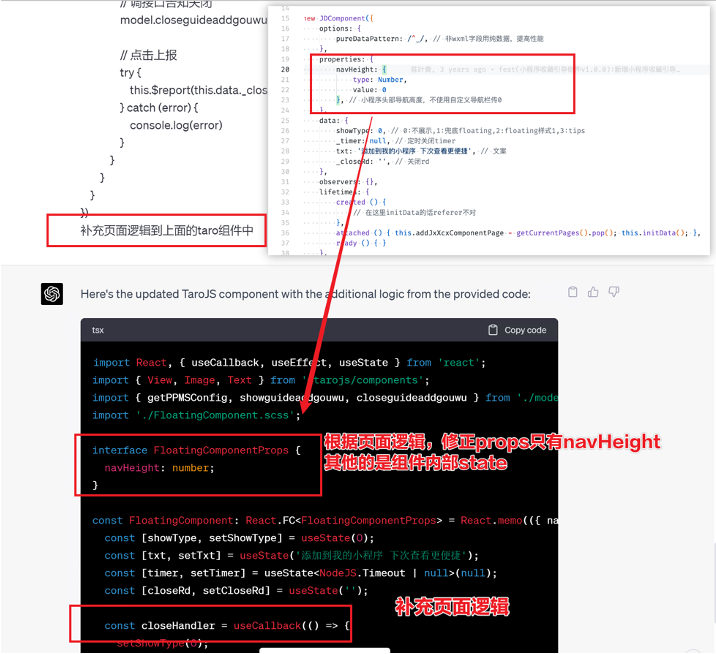
3. 可以補充知識,教它舉一反三特有的語法
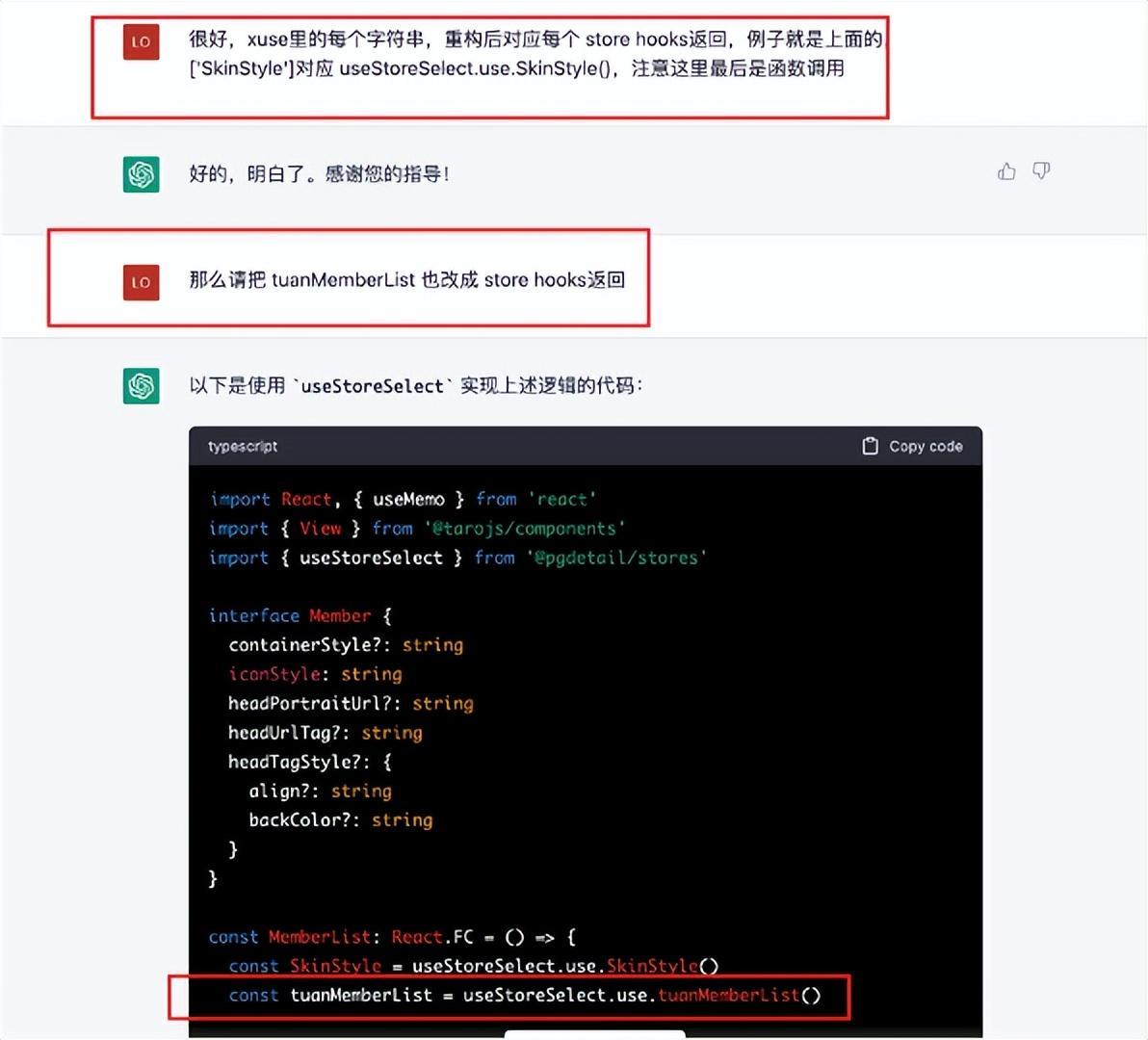
HiBox融合ChatGPT
這麼好的能力,應該如何沉澱呢?
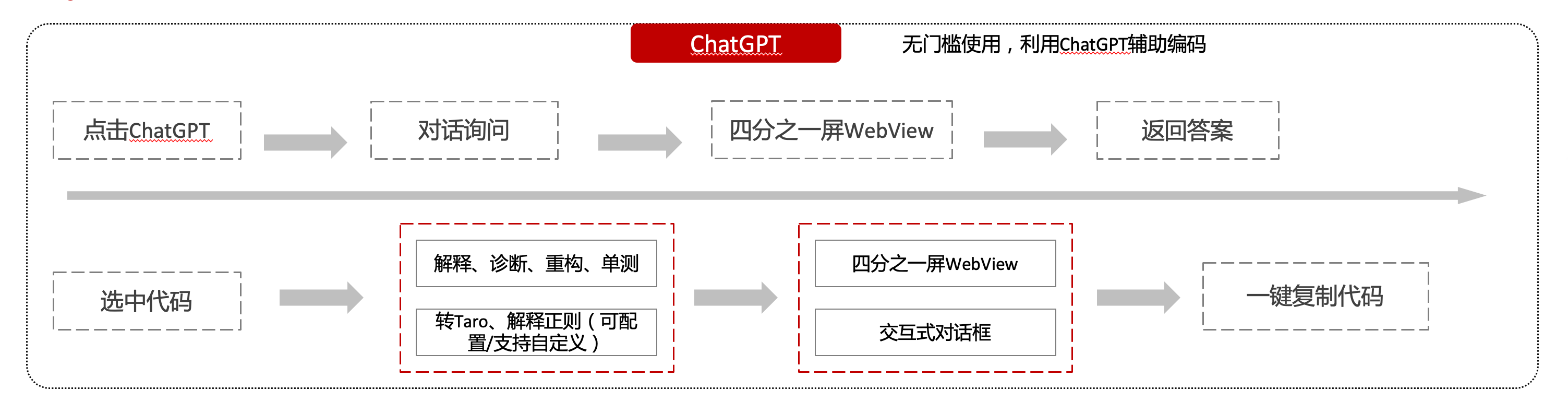
我們首先想到了VSCode外掛,剛好HiBox本身有登入態、自定義Webview、遠端設定化的能力,那就將ChatGPT整合到HiBox中(太酷啦),Node端接入ChatGPT的介面,通過Webview前端實現一個聊天窗,再通過設定系統整合常用的Prompt,這樣前端開發就能通過VSCode方便地用到ChatGPT的能力。整體結構如下:

資料來源方面,也從爬蟲版本ChatGPT,逐步切換到API代理服務中,代理服務接入GPT3.5的模型能力,整體體驗非常接近ChatGPT。代理服務檔案:
https://joyspace.jd.com/pages/yLnDY3B5UJ1rXP8UYrN6
HiBox的ChatGPT目前僅需erp登入即可免費使用,更多使用方式和安裝方式:HiBox快速開始
私域資料整合
在使用ChatGPT的過程中,也注意到2個問題:
- 公司敏感的程式碼和資訊不能傳給ChatGPT
- 特定領域的非敏感知識,比如水滴模板,ChatGPT沒學習過
首先想到的是,採用微調(fine-tuning)的方式,將私域資料資料整合到大語言模型(LLM)中,然後私有化部署在公司的伺服器上,這樣任意程式碼和檔案都可以傳送給它,我們嘗試了下面2種方式:
GPT3 fine-tuning
一是通過OpenAI官網提到的GPT3的fine-tuning介面,將私域資料傳給OpenAI,OpenAI在他們的伺服器裡微調訓練,然後部署在OpenAI的伺服器中,整個過程是黑盒。

ChatGLM-6B fine-tuning
二是用清華開源的ChatGLM-6B作為基礎模型,在公司的九數平臺上申請GPU機器,將私域資料通過LORA的方式微調得到LORA權重,然後自己部署,整個過程完全私有化。
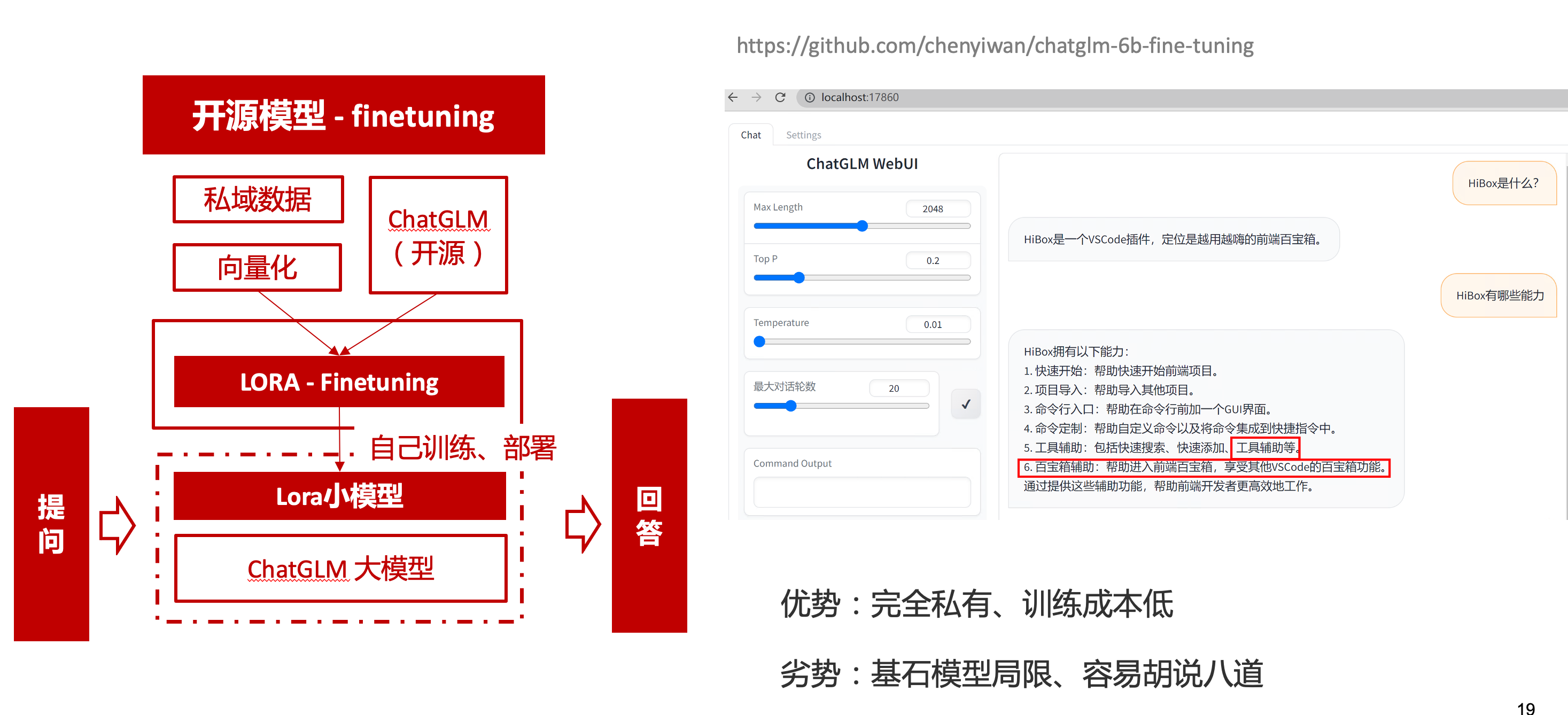
GPT3.5 langChain
上面的兩種方式總的來說,部署後的推理效果都很難達到GPT3.5-API的效果,因此我們最後嘗試了embedding外掛知識庫的方式。使用開源的langchain處理檔案切割、向量化儲存、向量化匹配等。資料還是會暴露給OpenAI。
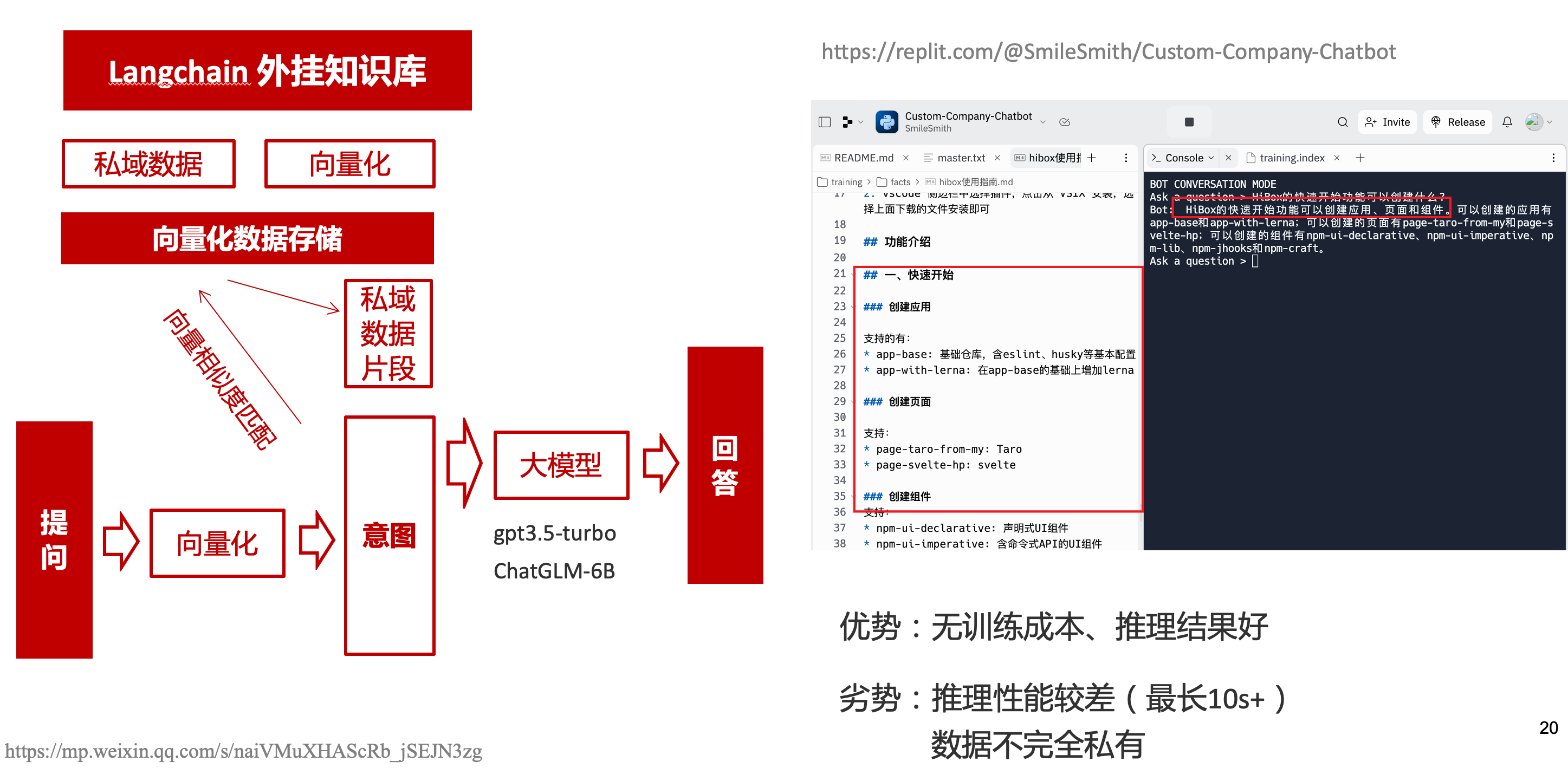
四、LLM現狀和展望
LLM大爆發
其實在20年GPT3出來之後,機器學習的大部分頭部都意識到了這條路線的可行性,積極地在跟進了:
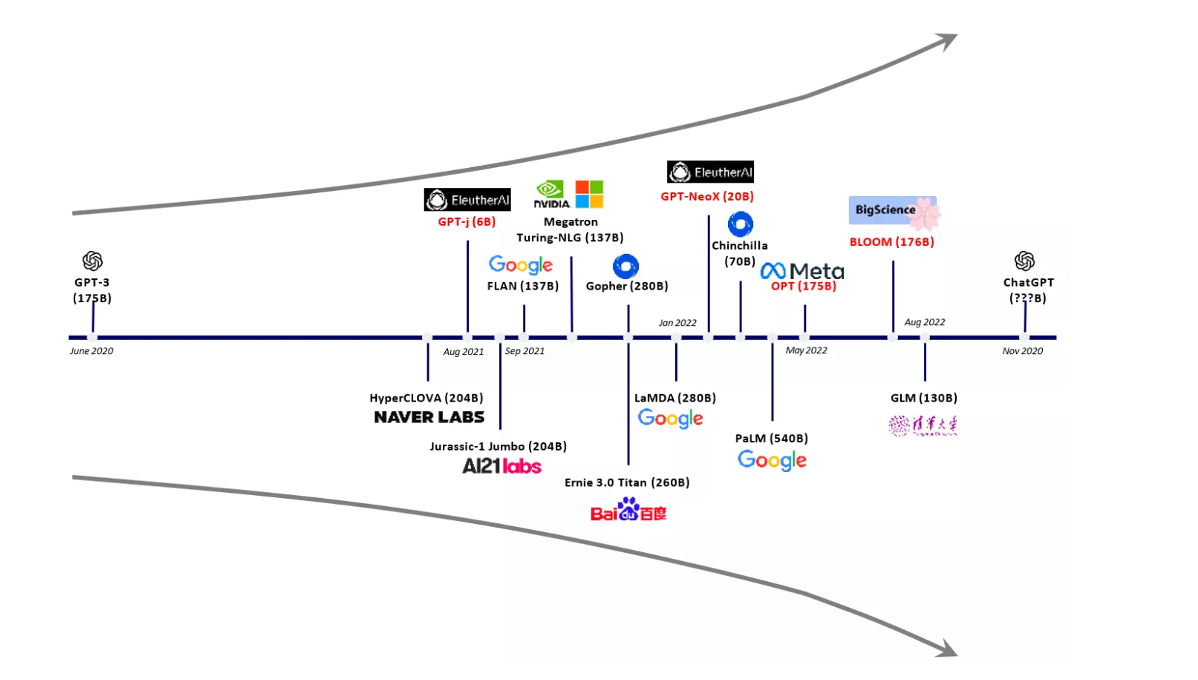
這裡專門講下百度,據公開可靠的檔案,百度早在2019年就推出了Ernie(對標谷歌Bard,Ernie和bard在動畫Muppet中是1對兄弟),確實是國內最早接入LLM的玩家。百度走的和谷歌一樣,是BERT的完形填空的路線,因為在2018~2019年的時間點,GPT一代剛剛問世,第一代的GPT對比各方面都不如BERT,再加上百度和谷歌一樣在搜尋引擎方面沉澱較多,因此選擇的路線是BERT。

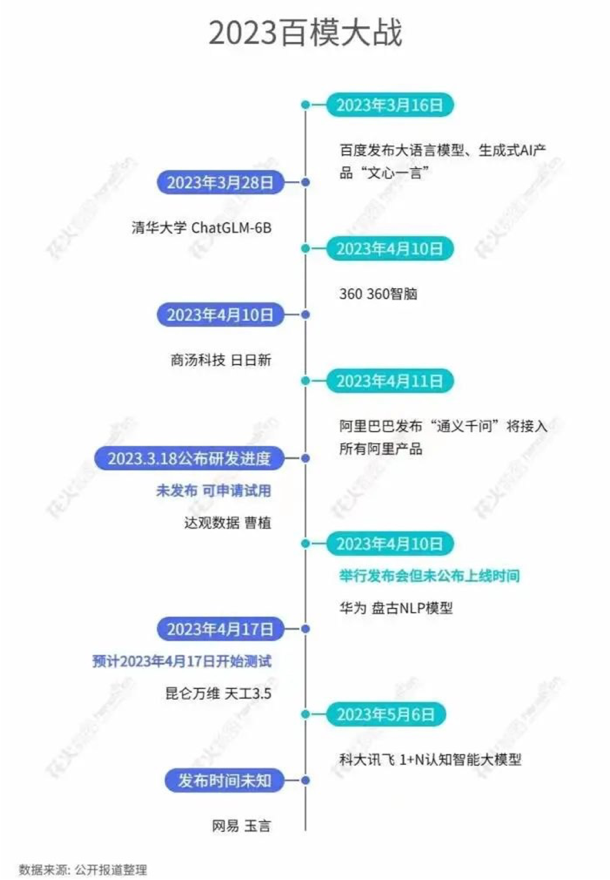
近期羊駝系列和國內大語言模型也在大爆發:
LLM應用現狀&趨勢
平臺化
LLM的角色扮演能力可能是下個人機互動變革的關鍵點,OpenAI也推出了Plugin模型,通過外掛,使用者可以通過一句自然語言聊天就買一張機票,搜尋想看的文章。有人說這是類似AppStore釋出的IPhone時刻:

自驅動、能力整合
類似Auto-GPT,langchain等,通過約定特性的模板,可以讓ChatGPT返回執行特定命令的文字,例如和ChatGPT約定如果要搜尋的時候,返回[search: 搜尋內容],然後在使用者端通過正則匹配 /[search:(.*?)]/,拿到對應的內容執行搜尋,再將結果返回給ChatGPT整理最終答案。
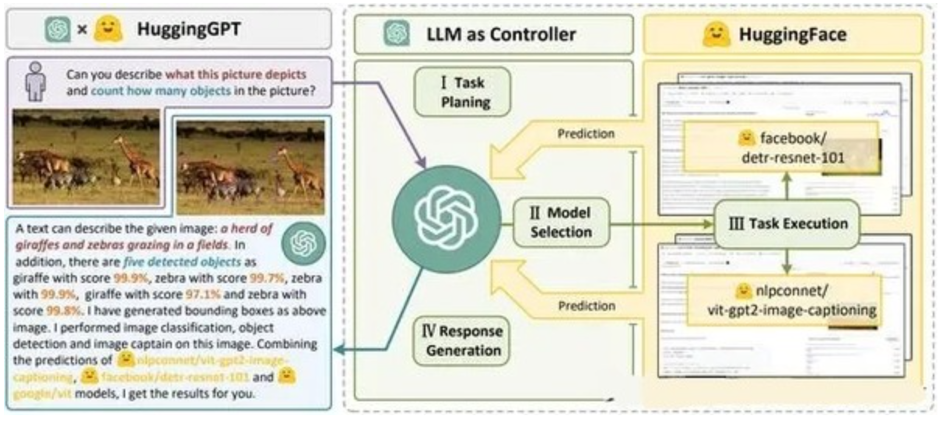
虛擬一個例子:
1. user: 深圳明天的天氣怎麼樣?
2. chatgpt(觸發知識限制2021年,返回約定的搜尋格式):[search:2023年4月27日的深圳天氣]
3. user接收到正則匹配觸發搜尋,開啟無頭瀏覽器搜尋百度並取第1條結果:2023年4月27日星期四深圳天氣:多雲,北風,風向角度:0°風力1-2級,風速:3km/h,全天氣溫22℃~27℃,氣壓值:1006,降雨量:0.0mm,相對溼度:84%,能見度:25km,紫外線指數:4, 日照...
4. user(將搜尋的內容連帶問題第二次發給ChatGPT): 深圳明天的天氣怎麼樣?可參考的資料:2023年4月27日星期四深圳天氣:多雲,北風,風向角度:0°風力1-2級,風速:3km/h,全天氣溫22℃~27℃,氣壓值:1006,降雨量:0.0mm,相對溼度:84%,能見度:25km,紫外線指數:4, 日照...
5. chatgpt(根據問題和上下文,輸出人類語言的表達): 深圳明天的天氣還可以,整體多雲為主,氣溫22℃~27℃
多模態
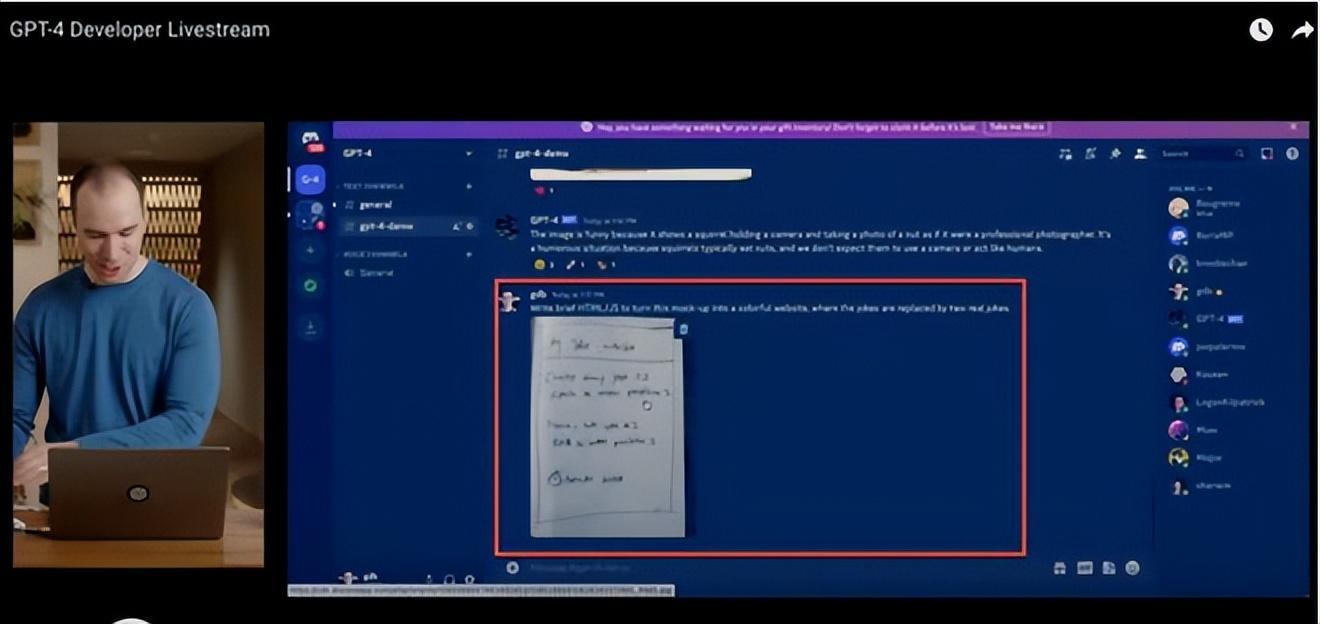
4月份釋出的GPT4已經具備影象識別的能力,下面的Case是主持人用一致設計稿草圖生成前端頁面的過程。經典「前端已死」時刻:
LLM的侷限
雖然我們看到ChatGPT的技術強大,但是也要審慎看待它的侷限,它本質上是個基於歷史資料的經驗主義的模仿人類的文字輸出函數。
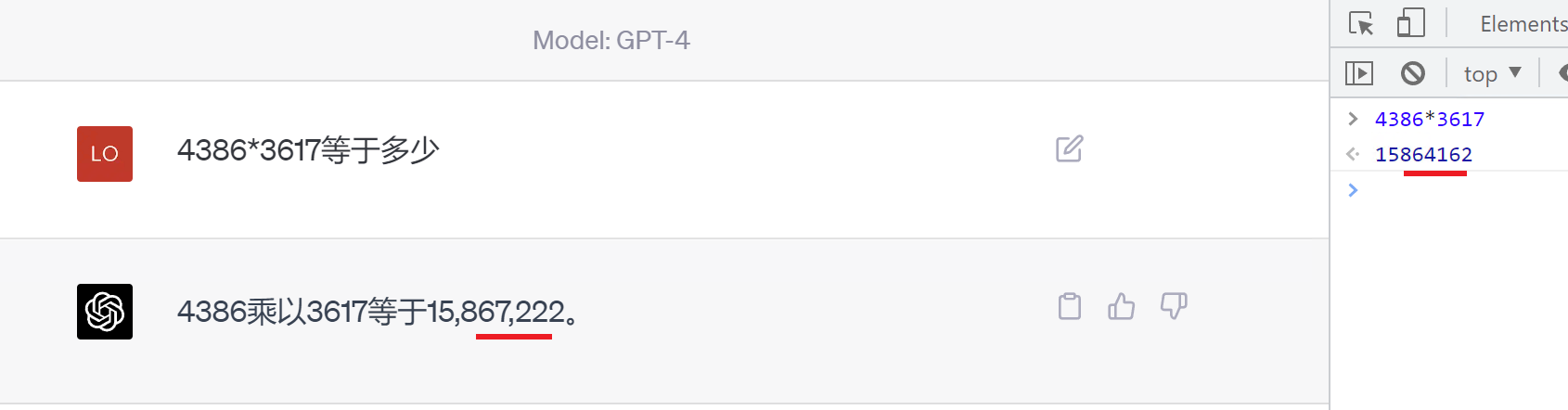
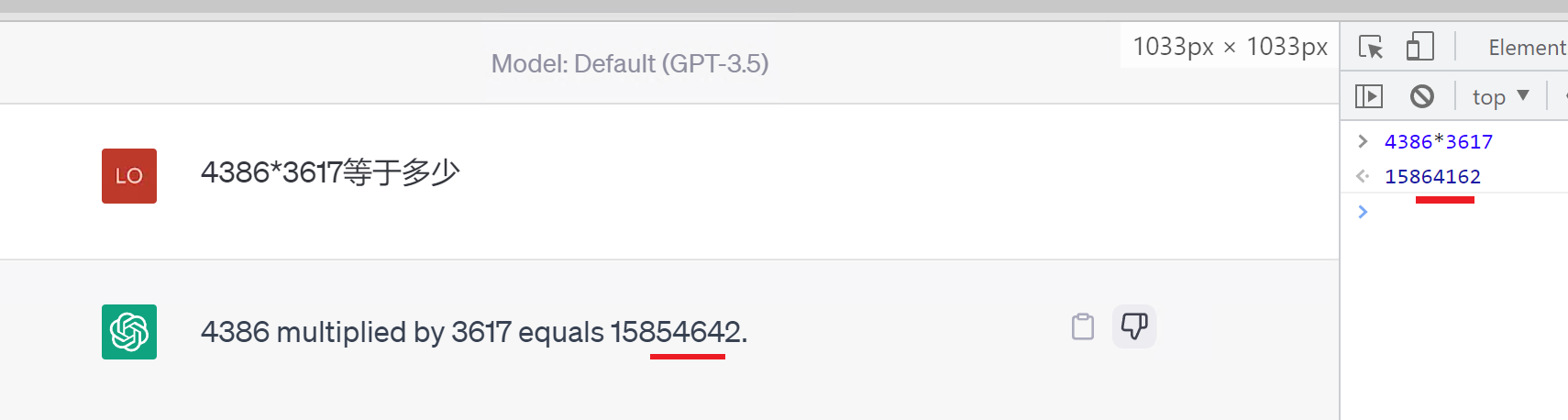
例如,ChatGPT完全做不了4位元數的乘法運算,它大概率會根據6乘和7等於這2塊關鍵資訊,得到答案是以2結尾,根據4和乘以3這2塊關鍵資訊,得到答案是以1開頭,而中間的隨機性完全收斂不到正確的答案,不管是ChatGPT和GPT4都是一樣的情況:
再比如問它特別小眾、普通人也容易錯的專業領域知識,它也會根據大部分普通人的錯誤答案輸出錯誤答案:
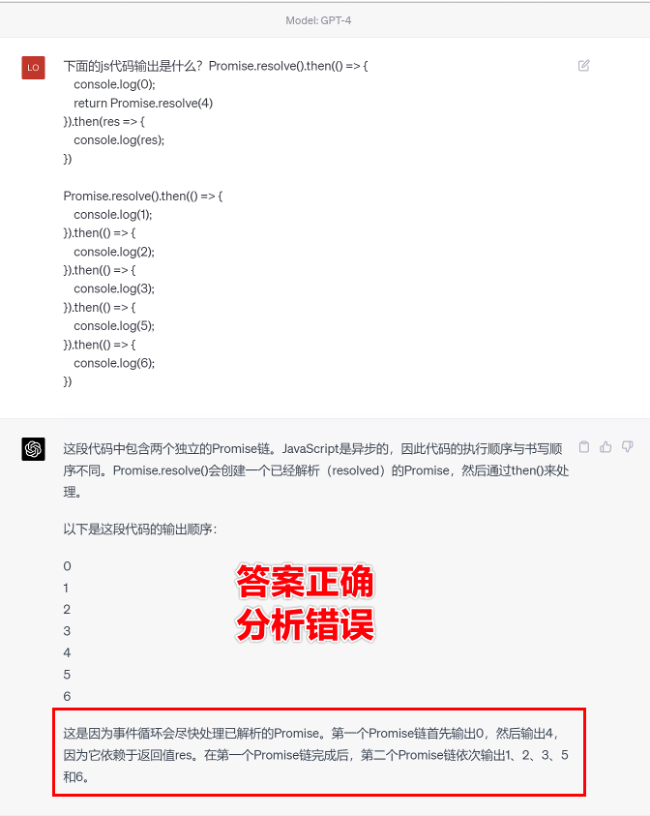
比如在V8 Promise原始碼全面解讀,其實你對Promise一無所知文章中一個很奇葩的題目,下面的程式碼會列印什麼?
Promise.resolve().then(() => {
console.log(0);
return Promise.resolve(4)
}).then(res => {
console.log(res);
})
Promise.resolve().then(() => {
console.log(1);
}).then(() => {
console.log(2);
}).then(() => {
console.log(3);
}).then(() => {
console.log(5);
}).then(() => {
console.log(6);
})
大部分人都會回答:0、1、4、2、3、5、6
GPT3.5的回答:0、1、4、2、3、5、6
GPT4的回答:0、1、2、3、4、5、6
只有GPT-4的回答正確,但是即使它的回答正確,它的具體分析也是錯誤,因為它可能在某個場景學習過類似答案,但是它並不「理解」,後面的分析內容也是大部分人容易錯的分析
結尾
最後用流浪地球2中周喆直的臺詞做個結尾。
對於AI的到來,我們戰略上不要高估它,AI本身有它的侷限性,保持樂觀,前端沒那麼容易死;戰術重視和關注它的發展,嘗試在我們的工作生活中應用,技術變革的浪潮不會隨個人的意志變化。

通宵趕稿,碼字不易,看到這裡同學幫忙點個贊吧 Thanks♪(・ω・)ノ
作者:京東零售 陳隆德
內容來源:京東雲開發者社群