手記系列之六 ----- 分享個人使用kafka經驗
前言
本篇文章主要介紹的關於本人從剛工作到現在使用kafka的經驗,內容非常多,包含了kafka的常用命令,在生產環境中遇到的一些場景處理,kafka的一些web工具推薦等等。由於kafka這塊的記錄以及經驗是從我剛開始使用kafka,從2017年開始,可能裡面有些內容過時,請見諒。溫馨提醒,本文有3w多字,建議收藏觀看~
Kafka理論知識
kafka基本介紹
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。
Kafka 有如下特性:
-以時間複雜度為O(1)的方式提供訊息持久化能力,即使對TB級以上資料也能保證常數時間複雜度的存取效能。
-高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒100K條以上訊息的傳輸。
- 支援KafkaServer間的訊息分割區,及分散式消費,同時保證每個Partition內的訊息順序傳輸。
- 同時支援離線資料處理和實時資料處理。
- Scale out:支援線上水平擴充套件。
kafka的術語
- Broker:Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker。
-Topic:每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的訊息分開儲存,邏輯上一個Topic的訊息雖然儲存於一個或多個broker上但使用者只需指定訊息的Topic即可生產或消費資料而不必關心資料存於何處)
-Partition:Partition是物理上的概念,每個Topic包含一個或多個Partition。
- Producer:負責釋出訊息到Kafka broker。
- Consumer:訊息消費者,向Kafka broker讀取訊息的使用者端。
- Consumer Group:每個Consumer屬於一個特定的Consumer
Group(可為每個Consumer指定group name,若不指定group
name則屬於預設的group)。
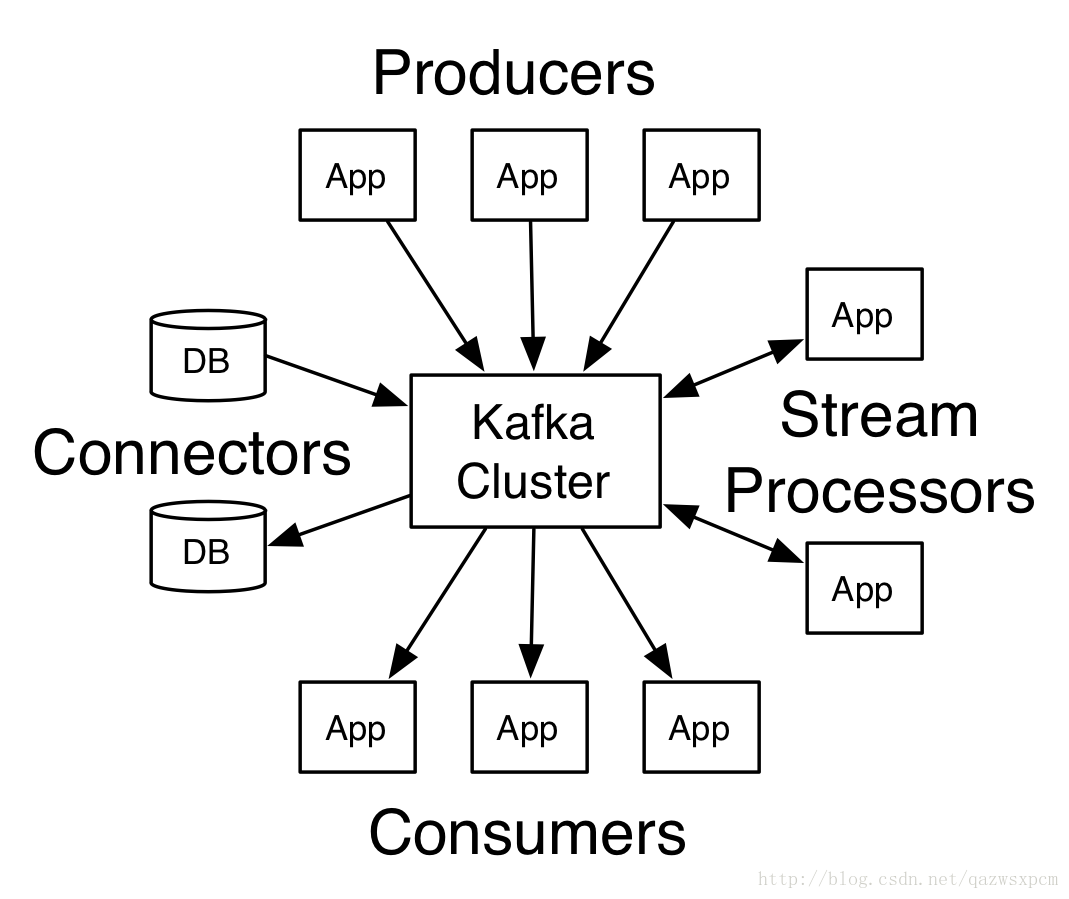
kafka核心Api
kafka有四個核心API
- 應用程式使用producer API釋出訊息到1個或多個topic中。
- 應用程式使用consumer API來訂閱一個或多個topic,並處理產生的訊息。
- 應用程式使用streams
API充當一個流處理器,從1個或多個topic消費輸入流,併產生一個輸出流到1個或多個topic,有效地將輸入流轉換到輸出流。
- connector
API允許構建或執行可重複使用的生產者或消費者,將topic連結到現有的應用程式或資料系統。
範例圖如下:
kafka面試問題
Kafka的用途有哪些?使用場景如何?
使用kafka的目的是為了解耦、非同步、削峰。
訊息系統: Kafka
和傳統的訊息系統(也稱作訊息中介軟體)都具備系統解耦、冗餘儲存、流量削峰、緩衝、非同步通訊、擴充套件性、可恢復性等功能。與此同時,Kafka
還提供了大多數訊息系統難以實現的訊息順序性保障及回溯消費的功能。
儲存系統: Kafka
把訊息持久化到磁碟,相比於其他基於記憶體儲存的系統而言,有效地降低了資料丟失的風險。也正是得益於
Kafka 的訊息持久化功能和多副本機制,我們可以把 Kafka
作為長期的資料儲存系統來使用,只需要把對應的資料保留策略設定為"永久"或啟用主題的紀錄檔壓縮功能即可。
流式處理平臺: Kafka
不僅為每個流行的流式處理框架提供了可靠的資料來源,還提供了一個完整的流式處理類庫,比如視窗、連線、變換和聚合等各類操作。
Kafka中的ISR、AR又代表什麼?ISR的伸縮又指什麼
分割區中的所有副本統稱為 AR(Assigned Replicas)。所有與 leader
副本保持一定程度同步的副本(包括 leader 副本在內)組成ISR(In-Sync
Replicas),ISR 集合是 AR 集合中的一個子集。
ISR的伸縮:
leader 副本負責維護和跟蹤 ISR 集合中所有 follower 副本的滯後狀態,當
follower 副本落後太多或失效時,leader 副本會把它從 ISR 集合中剔除。如果
OSR 集合中有 follower 副本"追上"了 leader 副本,那麼 leader 副本會把它從
OSR 集合轉移至 ISR 集合。預設情況下,當 leader 副本發生故障時,只有在
ISR 集合中的副本才有資格被選舉為新的 leader,而在 OSR
集合中的副本則沒有任何機會(不過這個原則也可以通過修改相應的引數設定來改變)。
replica.lag.time.max.ms : 這個引數的含義是 Follower 副本能夠落後 Leader
副本的最長時間間隔,當前預設值是 10 秒。
unclean.leader.election.enable:是否允許 Unclean 領導者選舉。開啟
Unclean 領導者選舉可能會造成資料丟失,但好處是,它使得分割區 Leader
副本一直存在,不至於停止對外提供服務,因此提升了高可用性。
Kafka中的HW、LEO、LSO、LW等分別代表什麼?
HW 是 High Watermark
的縮寫,俗稱高水位,它標識了一個特定的訊息偏移量(offset),消費者只能拉取到這個
offset 之前的訊息。
LSO是LogStartOffset,一般情況下,紀錄檔檔案的起始偏移量 logStartOffset
等於第一個紀錄檔分段的 baseOffset,但這並不是絕對的,logStartOffset
的值可以通過 DeleteRecordsRequest 請求(比如使用 KafkaAdminClient 的
deleteRecords()方法、使用 kafka-delete-records.sh
指令碼、紀錄檔的清理和截斷等操作進行修改。
如上圖所示,它代表一個紀錄檔檔案,這個紀錄檔檔案中有9條訊息,第一條訊息的
offset(LogStartOffset)為0,最後一條訊息的 offset 為8,offset
為9的訊息用虛線框表示,代表下一條待寫入的訊息。紀錄檔檔案的 HW
為6,表示消費者只能拉取到 offset 在0至5之間的訊息,而 offset
為6的訊息對消費者而言是不可見的。
LEO 是 Log End Offset 的縮寫,它標識當前紀錄檔檔案中下一條待寫入訊息的
offset,上圖中 offset 為9的位置即為當前紀錄檔檔案的 LEO,LEO
的大小相當於當前紀錄檔分割區中最後一條訊息的 offset 值加1。分割區 ISR
集合中的每個副本都會維護自身的 LEO,而 ISR 集合中最小的 LEO 即為分割區的
HW,對消費者而言只能消費 HW 之前的訊息。
LW 是 Low Watermark 的縮寫,俗稱"低水位",代表 AR 集合中最小的
logStartOffset
值。副本的拉取請求(FetchRequest,它有可能觸發新建紀錄檔分段而舊的被清理,進而導致
logStartOffset 的增加)和刪除訊息請求(DeleteRecordRequest)都有可能促使 LW
的增長。
Kafka中是怎麼體現訊息順序性的?
可以通過分割區策略體現訊息順序性。
分割區策略有輪詢策略、隨機策略、按訊息鍵保序策略。
按訊息鍵保序策略:一旦訊息被定義了 Key,那麼你就可以保證同一個 Key
的所有訊息都進入到相同的分割區裡面,由於每個分割區下的訊息處理都是有順序的,故這個策略被稱為按訊息鍵保序策略
Kafka中的分割區器、序列化器、攔截器是否瞭解?它們之間的處理順序是什麼?
序列化器:生產者需要用序列化器(Serializer)把物件轉換成位元組陣列才能通過網路傳送給
Kafka。而在對側,消費者需要用反序列化器(Deserializer)把從 Kafka
中收到的位元組陣列轉換成相應的物件。
分割區器:分割區器的作用就是為訊息分配分割區。如果訊息 ProducerRecord
中沒有指定 partition 欄位,那麼就需要依賴分割區器,根據 key 這個欄位來計算
partition 的值。
Kafka 一共有兩種攔截器:生產者攔截器和消費者攔截器。
生產者攔截器既可以用來在訊息傳送前做一些準備工作,比如按照某個規則過濾不符合要求的訊息、修改訊息的內容等,也可以用來在傳送回撥邏輯前做一些客製化化的需求,比如統計類工作。
消費者攔截器主要在消費到訊息或在提交消費位移時進行一些客製化化的操作。
訊息在通過 send() 方法發往 broker
的過程中,有可能需要經過攔截器(Interceptor)、序列化器(Serializer)和分割區器(Partitioner)的一系列作用之後才能被真正地發往
broker。攔截器(下一章會詳細介紹)一般不是必需的,而序列化器是必需的。訊息經過序列化之後就需要確定它發往的分割區,如果訊息
ProducerRecord 中指定了 partition 欄位,那麼就不需要分割區器的作用,因為
partition 代表的就是所要發往的分割區號。
處理順序 :攔截器->序列化器->分割區器
KafkaProducer 在將訊息序列化和計算分割區之前會呼叫生產者攔截器的 onSend()
方法來對訊息進行相應的客製化化操作。
然後生產者需要用序列化器(Serializer)把物件轉換成位元組陣列才能通過網路傳送給
Kafka。
最後可能會被髮往分割區器為訊息分配分割區。
Kafka生產者使用者端的整體結構是什麼樣子的?
整個生產者使用者端由兩個執行緒協調執行,這兩個執行緒分別為主執行緒和 Sender
執行緒(傳送執行緒)。
在主執行緒中由 KafkaProducer
建立訊息,然後通過可能的攔截器、序列化器和分割區器的作用之後快取到訊息累加器(RecordAccumulator,也稱為訊息收集器)中。
Sender 執行緒負責從 RecordAccumulator 中獲取訊息並將其傳送到 Kafka 中。
RecordAccumulator 主要用來快取訊息以便 Sender
執行緒可以批次傳送,進而減少網路傳輸的資源消耗以提升效能。
Kafka生產者使用者端中使用了幾個執行緒來處理?分別是什麼?
整個生產者使用者端由兩個執行緒協調執行,這兩個執行緒分別為主執行緒和 Sender
執行緒(傳送執行緒)。在主執行緒中由 KafkaProducer
建立訊息,然後通過可能的攔截器、序列化器和分割區器的作用之後快取到訊息累加器(RecordAccumulator,也稱為訊息收集器)中。Sender
執行緒負責從 RecordAccumulator 中獲取訊息並將其傳送到 Kafka 中。
Kafka的舊版Scala的消費者使用者端的設計有什麼缺陷?
老版本的 Consumer Group 把位移儲存在 ZooKeeper 中。Apache ZooKeeper
是一個分散式的協調服務架構,Kafka
重度依賴它實現各種各樣的協調管理。將位移儲存在 ZooKeeper
外部系統的做法,最顯而易見的好處就是減少了 Kafka Broker
端的狀態儲存開銷。
ZooKeeper 這類元框架其實並不適合進行頻繁的寫更新,而 Consumer Group
的位移更新卻是一個非常頻繁的操作。這種大吞吐量的寫操作會極大地拖慢
ZooKeeper 叢集的效能
"消費組中的消費者個數如果超過topic的分割區,那麼就會有消費者消費不到資料"這句話是否正確?如果正確,那麼有沒有什麼hack的手段?
一般來說如果消費者過多,出現了消費者的個數大於分割區個數的情況,就會有消費者分配不到任何分割區。
開發者可以繼承AbstractPartitionAssignor實現自定義消費策略,從而實現同一消費組內的任意消費者都可以消費訂閱主題的所有分割區:
消費者提交消費位移時提交的是當前消費到的最新訊息的offset還是offset+1?
在舊消費者使用者端中,消費位移是儲存在 ZooKeeper
中的。而在新消費者使用者端中,消費位移儲存在 Kafka
內部的主題__consumer_offsets 中。
當前消費者需要提交的消費位移是offset+1
有哪些情形會造成重複消費?
Rebalance
一個consumer正在消費一個分割區的一條訊息,還沒有消費完,發生了rebalance(加入了一個consumer),從而導致這條訊息沒有消費成功,rebalance後,另一個consumer又把這條訊息消費一遍。
消費者端手動提交
如果先消費訊息,再更新offset位置,導致訊息重複消費。
消費者端自動提交
設定offset為自動提交,關閉kafka時,如果在close之前,呼叫
consumer.unsubscribe() 則有可能部分offset沒提交,下次重啟會重複消費。
生產者端
生產者因為業務問題導致的宕機,在重啟之後可能資料會重發
那些情景下會造成訊息漏消費?
自動提交
設定offset為自動定時提交,當offset被自動定時提交時,資料還在記憶體中未處理,此時剛好把執行緒kill掉,那麼offset已經提交,但是資料未處理,導致這部分記憶體中的資料丟失。
生產者傳送訊息
傳送訊息設定的是fire-and-forget(發後即忘),它只管往 Kafka
中傳送訊息而並不關心訊息是否正確到達。不過在某些時候(比如發生不可重試異常時)會造成訊息的丟失。這種傳送方式的效能最高,可靠性也最差。
消費者端
先提交位移,但是訊息還沒消費完就宕機了,造成了訊息沒有被消費。自動位移提交同理
acks沒有設定為all
如果在broker還沒把訊息同步到其他broker的時候宕機了,那麼訊息將會丟失
KafkaConsumer是非執行緒安全的,那麼怎麼樣實現多執行緒消費?#
執行緒封閉,即為每個執行緒範例化一個 KafkaConsumer 物件
一個執行緒對應一個 KafkaConsumer
範例,我們可以稱之為消費執行緒。一個消費執行緒可以消費一個或多個分割區中的訊息,所有的消費執行緒都隸屬於同一個消費組。
消費者程式使用單或多執行緒獲取訊息,同時建立多個消費執行緒執行訊息處理邏輯。
獲取訊息的執行緒可以是一個,也可以是多個,每個執行緒維護專屬的 KafkaConsumer
範例,處理訊息則交由特定的執行緒池來做,從而實現訊息獲取與訊息處理的真正解耦。具體架構如下圖所示:
簡述消費者與消費組之間的關係
Consumer Group 下可以有一個或多個 Consumer
範例。這裡的範例可以是一個單獨的程序,也可以是同一程序下的執行緒。在實際場景中,使用程序更為常見一些。
Group ID 是一個字串,在一個 Kafka 叢集中,它標識唯一的一個 Consumer
Group。
Consumer Group 下所有範例訂閱的主題的單個分割區,只能分配給組內的某個
Consumer 範例消費。這個分割區當然也可以被其他的 Group 消費。
當你使用kafka-topics.sh建立(刪除)了一個topic之後,Kafka背後會執行什麼邏輯?
在執行完指令碼之後,Kafka 會在 log.dir 或 log.dirs
引數所設定的目錄下建立相應的主題分割區,預設情況下這個目錄為/tmp/kafka-logs/。
在 ZooKeeper
的/brokers/topics/目錄下建立一個同名的實節點,該節點中記錄了該主題的分割區副本分配方案。範例如下:
[zk: localhost:2181/kafka(CONNECTED) 2] get
/brokers/topics/topic-create
{"version":1,"partitions":{"2":[1,2],"1":[0,1],"3":[2,1],"0":[2,0]}}
topic的分割區數可不可以增加?如果可以怎麼增加?如果不可以,那又是為什麼?
可以增加,使用 kafka-topics 指令碼,結合 --alter
引數來增加某個主題的分割區數,命令如下:
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter
--topic <topic_name> --partitions <新分割區數>
當分割區數增加時,就會觸發訂閱該主題的所有 Group 開啟 Rebalance。
首先,Rebalance 過程對 Consumer Group 消費過程有極大的影響。在 Rebalance
過程中,所有 Consumer 範例都會停止消費,等待 Rebalance 完成。這是
Rebalance 為人詬病的一個方面。
其次,目前 Rebalance 的設計是所有 Consumer
範例共同參與,全部重新分配所有分割區。其實更高效的做法是儘量減少分配方案的變動。
最後,Rebalance 實在是太慢了。
topic的分割區數可不可以減少?如果可以怎麼減少?如果不可以,那又是為什麼?
不支援,因為刪除的分割區中的訊息不好處理。如果直接儲存到現有分割區的尾部,訊息的時間戳就不會遞增,如此對於
Spark、Flink
這類需要訊息時間戳(事件時間)的元件將會受到影響;如果分散插入現有的分割區,那麼在訊息量很大的時候,內部的資料複製會佔用很大的資源,而且在複製期間,此主題的可用性又如何得到保障?與此同時,順序性問題、事務性問題,以及分割區和副本的狀態機切換問題都是不得不面對的。
建立topic時如何選擇合適的分割區數?副本數?
分割區
在 Kafka
中,效能與分割區數有著必然的關係,在設定分割區數時一般也需要考慮效能的因素。對不同的硬體而言,其對應的效能也會不太一樣。
可以使用Kafka 本身提供的用於生產者效能測試的 kafka-producer-
perf-test.sh 和用於消費者效能測試的
kafka-consumer-perf-test.sh來進行測試。
增加合適的分割區數可以在一定程度上提升整體吞吐量,但超過對應的閾值之後吞吐量不升反降。如果應用對吞吐量有一定程度上的要求,則建議在投入生產環境之前對同款硬體資源做一個完備的吞吐量相關的測試,以找到合適的分割區數閾值區間。
分割區數的多少還會影響系統的可用性。如果分割區數非常多,如果叢集中的某個
broker 節點宕機,那麼就會有大量的分割區需要同時進行 leader
角色切換,這個切換的過程會耗費一筆可觀的時間,並且在這個時間視窗內這些分割區也會變得不可用。
分割區數越多也會讓 Kafka
的正常啟動和關閉的耗時變得越長,與此同時,主題的分割區數越多不僅會增加紀錄檔清理的耗時,而且在被刪除時也會耗費更多的時間。
如何設定合理的分割區數量
可以遵循一定的步驟來嘗試確定分割區數:建立一個只有1個分割區的topic,然後測試這個topic的producer吞吐量和consumer吞吐量。假設它們的值分別是Tp和Tc,單位可以是MB/s。然後假設總的目標吞吐量是Tt,那麼分割區數 = Tt / max(Tp, Tc)
說明:Tp表示producer的吞吐量。測試producer通常是很容易的,因為它的邏輯非常簡單,就是直接傳送訊息到Kafka就好了。Tc表示consumer的吞吐量。測試Tc通常與應用的關係更大, 因為Tc的值取決於你拿到訊息之後執行什麼操作,因此Tc的測試通常也要麻煩一些。
副本
Producer在釋出訊息到某個Partition時,先通過ZooKeeper找到該Partition的Leader,然後無論該Topic的Replication Factor為多少(也即該Partition有多少個Replica),Producer只將該訊息傳送到該Partition的Leader。Leader會將該訊息寫入其本地Log。每個Follower都從Leader pull資料。這種方式上,Follower儲存的資料順序與Leader保持一致。
Kafka分配Replica的演演算法如下:
將所有Broker(假設共n個Broker)和待分配的Partition排序
將第i個Partition分配到第(imod n)個Broker上
將第i個Partition的第j個Replica分配到第((i + j) mode n)個Broker上
如何保證kafka的資料完整性
生產者不丟資料:
- 設定 acks=all,leader會等待所有的follower同步完成。這個確保訊息不會丟失,除非kafka叢集中所有機器掛掉。這是最強的可用性保證。
2.retries = max ,使用者端會在訊息傳送失敗時重新傳送,直到傳送成功為止。為0表示不重新傳送。
訊息佇列不丟資料:
1.replication.factor 也就是topic的副本數,必須大於1
2.min.insync.replicas 也要大於1,要求一個leader至少感知到有至少一個follower還跟自己保持聯絡
消費者不丟資料:
改為手動提交。
kafka設定引數
kafka設定引數
-
broker.id:broker的id,id是唯一的非負整數,叢集的broker.id不能重複。
-
log.dirs:kafka存放資料的路徑。可以是多個,多個使用逗號分隔即可。
-
port:server接受使用者端連線的埠,預設6667
-
zookeeper.connect:zookeeper叢集連線地址。
格式如:zookeeper.connect=server01:2181,server02:2181,server03:2181。
如果需要指定zookeeper叢集的路徑位置,可以:zookeeper.connect=server01:2181,server02:2181,server03:2181/kafka/cluster。這樣設定後,在啟動kafka叢集前,需要在zookeeper叢集建立這個路徑/kafka/cluster。 -
message.max.bytes:server可以接受的訊息最大尺寸。預設1000000。
重要的是,consumer和producer有關這個屬性的設定必須同步,否則producer釋出的訊息對consumer來說太大。 -
num.network.threads:server用來處理網路請求的執行緒數,預設3。
-
num.io.threads:server用來處理請求的I/O執行緒數。這個執行緒數至少等於磁碟的個數。
-
background.threads:用於後臺處理的執行緒數。例如檔案的刪除。預設4。
-
queued.max.requests:在網路執行緒停止讀取新請求之前,可以排隊等待I/O執行緒處理的最大請求個數。預設500。
-
host.name:broker的hostname
如果hostname已經設定的話,broker將只會繫結到這個地址上;如果沒有設定,它將繫結到所有介面,並行布一份到ZK -
advertised.host.name:如果設定,則就作為broker
的hostname發往producer、consumers以及其他brokers -
advertised.port:此埠將給與producers、consumers、以及其他brokers,它會在建立連線時用到;
它僅在實際埠和server需要繫結的埠不一樣時才需要設定。 -
socket.send.buffer.bytes:SO_SNDBUFF 快取大小,server進行socket
連線所用,預設100*1024。 -
socket.receive.buffer.bytes:SO_RCVBUFF快取大小,server進行socket連線時所用。預設100
* 1024。 -
socket.request.max.bytes:server允許的最大請求尺寸;這將避免server溢位,它應該小於Java
heap size。 -
num.partitions:如果建立topic時沒有給出劃分partitions個數,這個數位將是topic下partitions數目的預設數值。預設1。
-
log.segment.bytes:topic
partition的紀錄檔存放在某個目錄下諸多檔案中,這些檔案將partition的紀錄檔切分成一段一段的;這個屬性就是每個檔案的最大尺寸;當尺寸達到這個數值時,就會建立新檔案。此設定可以由每個topic基礎設定時進行覆蓋。預設1014*1024*1024 -
log.roll.hours:即使檔案沒有到達log.segment.bytes,只要檔案建立時間到達此屬性,就會建立新檔案。這個設定也可以有topic層面的設定進行覆蓋。預設24*7
-
log.cleanup.policy:log清除策略。預設delete。
-
log.retention.minutes和log.retention.hours:每個紀錄檔檔案刪除之前儲存的時間。預設資料儲存時間對所有topic都一樣。
-
log.retention.minutes 和 log.retention.bytes
都是用來設定刪除紀錄檔檔案的,無論哪個屬性已經溢位。這個屬性設定可以在topic基本設定時進行覆蓋。 -
log.retention.bytes:每個topic下每個partition儲存資料的總量。
注意,這是每個partitions的上限,因此這個數值乘以partitions的個數就是每個topic儲存的資料總量。如果log.retention.hours和log.retention.bytes都設定了,則超過了任何一個限制都會造成刪除一個段檔案。注意,這項設定可以由每個topic設定時進行覆蓋。 -
log.retention.check.interval.ms:檢查紀錄檔分段檔案的間隔時間,以確定是否檔案屬性是否到達刪除要求。預設5min。
-
log.cleaner.enable:當這個屬性設定為false時,一旦紀錄檔的儲存時間或者大小達到上限時,就會被刪除;如果設定為true,則當儲存屬性達到上限時,就會進行log
compaction。預設false。 -
log.cleaner.threads:進行紀錄檔壓縮的執行緒數。預設1。
-
log.cleaner.io.max.bytes.per.second:進行log compaction時,log
cleaner可以擁有的最大I/O數目。這項設定限制了cleaner,以避免干擾活動的請求服務。 -
log.cleaner.io.buffer.size:log
cleaner清除過程中針對紀錄檔進行索引化以及精簡化所用到的快取大小。最好設定大點,以提供充足的記憶體。預設500*1024*1024。 -
log.cleaner.io.buffer.load.factor:進行log cleaning時所需要的I/O
chunk尺寸。你不需要更改這項設定。預設512*1024。 -
log.cleaner.io.buffer.load.factor:log
cleaning中所使用的hash表的負載因子;你不需要更改這個選項。預設0.9 -
log.cleaner.backoff.ms:進行紀錄檔是否清理檢查的時間間隔,預設15000。
-
log.cleaner.min.cleanable.ratio:這項設定控制log
compactor試圖清理紀錄檔的頻率(假定log compaction是開啟的)。預設避免清理壓縮超過50%的紀錄檔。這個比率繫結了備份紀錄檔所消耗的最大空間(50%的紀錄檔備份時壓縮率為50%)。更高的比率則意味著浪費消耗更少,也就可以更有效的清理更多的空間。這項設定在每個topic設定中可以覆蓋。 -
log.cleaner.delete.retention.ms:儲存時間;儲存壓縮紀錄檔的最長時間;也是使用者端消費訊息的最長時間,與log.retention.minutes的區別在於一個控制未壓縮資料,一個控制壓縮後的資料;會被topic建立時的指定時間覆蓋。
-
log.index.size.max.bytes:每個log
segment的最大尺寸。注意,如果log尺寸達到這個數值,即使尺寸沒有超過log.segment.bytes限制,也需要產生新的log
segment。預設10*1024*1024。 -
log.index.interval.bytes:當執行一次fetch後,需要一定的空間掃描最近的offset,設定的越大越好,一般使用預設值就可以。預設4096。
-
log.flush.interval.messages:log檔案"sync"到磁碟之前累積的訊息條數。
因為磁碟IO操作是一個慢操作,但又是一個"資料可靠性"的必要手段,所以檢查是否需要固化到硬碟的時間間隔。需要在"資料可靠性"與"效能"之間做必要的權衡,如果此值過大,將會導致每次"發sync"的時間過長(IO阻塞),如果此值過小,將會導致"fsync"的時間較長(IO阻塞),導致"發sync"的次數較多,這也就意味著整體的client請求有一定的延遲,物理server故障,將會導致沒有fsync的訊息丟失。 -
log.flush.scheduler.interval.ms:檢查是否需要fsync的時間間隔。預設Long.MaxValue
-
log.flush.interval.ms:僅僅通過interval來控制訊息的磁碟寫入時機,是不足的,這個數用來控制"fsync"的時間間隔,如果訊息量始終沒有達到固化到磁碟的訊息數,但是離上次磁碟同步的時間間隔達到閾值,也將觸發磁碟同步。
-
log.delete.delay.ms:檔案在索引中清除後的保留時間,一般不需要修改。預設60000。
-
auto.create.topics.enable:是否允許自動建立topic。如果是true,則produce或者fetch
不存在的topic時,會自動建立這個topic。否則需要使用命令列建立topic。預設true。 -
controller.socket.timeout.ms:partition管理控制器進行備份時,socket的超時時間。預設30000。
-
controller.message.queue.size:controller-to-broker-channles的buffer尺寸,預設Int.MaxValue。
-
default.replication.factor:預裝置份份數,僅指自動建立的topics。預設1。
-
replica.lag.time.max.ms:如果一個follower在這個時間內沒有傳送fetch請求,leader將從ISR重移除這個follower,並認為這個follower已經掛了,預設10000。
-
replica.lag.max.messages:如果一個replica沒有備份的條數超過這個數值,則leader將移除這個follower,並認為這個follower已經掛了,預設4000。
-
replica.socket.timeout.ms:leader
備份資料時的socket網路請求的超時時間,預設30*1000 -
replica.socket.receive.buffer.bytes:備份時向leader傳送網路請求時的socket
receive buffer。預設64*1024。 -
replica.fetch.max.bytes:備份時每次fetch的最大值。預設1024*1024。
-
replica.fetch.max.bytes:leader發出備份請求時,資料到達leader的最長等待時間。預設500。
-
replica.fetch.min.bytes:備份時每次fetch之後迴應的最小尺寸。預設1。
-
num.replica.fetchers:從leader備份資料的執行緒數。預設1。
-
replica.high.watermark.checkpoint.interval.ms:每個replica檢查是否將最高水位進行固化的頻率。預設5000.
-
fetch.purgatory.purge.interval.requests:fetch
請求清除時的清除間隔,預設1000 -
producer.purgatory.purge.interval.requests:producer請求清除時的清除間隔,預設1000
-
zookeeper.session.timeout.ms:zookeeper對談超時時間。預設6000
-
zookeeper.connection.timeout.ms:使用者端等待和zookeeper建立連線的最大時間。預設6000
-
zookeeper.sync.time.ms:zk follower落後於zk leader的最長時間。預設2000
-
controlled.shutdown.enable:是否能夠控制broker的關閉。如果能夠,broker將可以移動所有leaders到其他的broker上,在關閉之前。這減少了不可用性在關機過程中。預設true。
-
controlled.shutdown.max.retries:在執行不徹底的關機之前,可以成功執行關機的命令數。預設3.
-
controlled.shutdown.retry.backoff.ms:在關機之間的backoff時間。預設5000
-
auto.leader.rebalance.enable:如果這是true,控制者將會自動平衡brokers對於partitions的leadership。預設true。
-
leader.imbalance.per.broker.percentage:每個broker所允許的leader最大不平衡比率,預設10。
-
leader.imbalance.check.interval.seconds:檢查leader不平衡的頻率,預設300
-
offset.metadata.max.bytes:允許使用者端儲存他們offsets的最大個數。預設4096
-
max.connections.per.ip:每個ip地址上每個broker可以被連線的最大數目。預設Int.MaxValue。
-
max.connections.per.ip.overrides:每個ip或者hostname預設的連線的最大覆蓋。
-
connections.max.idle.ms:空連線的超時限制,預設600000
-
log.roll.jitter.{ms,hours}:從logRollTimeMillis抽離的jitter最大數目。預設0
-
num.recovery.threads.per.data.dir:每個資料目錄用來紀錄檔恢復的執行緒數目。預設1。
-
unclean.leader.election.enable:指明瞭是否能夠使不在ISR中replicas設定用來作為leader。預設true
-
delete.topic.enable:能夠刪除topic,預設false。
-
offsets.topic.num.partitions:預設50。
由於部署後更改不受支援,因此建議使用更高的設定來進行生產(例如100-200)。 -
offsets.topic.retention.minutes:存在時間超過這個時間限制的offsets都將被標記為待刪除。預設1440。
-
offsets.retention.check.interval.ms:offset管理器檢查陳舊offsets的頻率。預設600000。
-
offsets.topic.replication.factor:topic的offset的備份份數。建議設定更高的數位保證更高的可用性。預設3
-
offset.topic.segment.bytes:offsets topic的segment尺寸。預設104857600
-
offsets.load.buffer.size:這項設定與批次尺寸相關,當從offsets
segment中讀取時使用。預設5242880 -
offsets.commit.required.acks:在offset
commit可以接受之前,需要設定確認的數目,一般不需要更改。預設-1。
kafka生產者設定引數
-
boostrap.servers:用於建立與kafka叢集連線的host/port組。
資料將會在所有servers上均衡載入,不管哪些server是指定用於bootstrapping。
這個列表格式:host1:port1,host2:port2,... -
acks:此設定實際上代表了資料備份的可用性。
-
acks=0:
設定為0表示producer不需要等待任何確認收到的資訊。副本將立即加到socket
buffer並認為已經傳送。沒有任何保障可以保證此種情況下server已經成功接收資料,同時重試設定不會發生作用 -
acks=1:
這意味著至少要等待leader已經成功將資料寫入本地log,但是並沒有等待所有follower是否成功寫入。這種情況下,如果follower沒有成功備份資料,而此時leader又掛掉,則訊息會丟失。 -
acks=all:
這意味著leader需要等待所有備份都成功寫入紀錄檔,這種策略會保證只要有一個備份存活就不會丟失資料。這是最強的保證。 -
buffer.memory:producer可以用來快取資料的記憶體大小。如果資料產生速度大於向broker傳送的速度,producer會阻塞或者丟擲異常,以"block.on.buffer.full"來表明。
-
compression.type:producer用於壓縮資料的壓縮型別。預設是無壓縮。正確的選項值是none、gzip、snappy。壓縮最好用於批次處理,批次處理訊息越多,壓縮效能越好。
-
retries:設定大於0的值將使使用者端重新傳送任何資料,一旦這些資料傳送失敗。注意,這些重試與使用者端接收到傳送錯誤時的重試沒有什麼不同。允許重試將潛在的改變資料的順序,如果這兩個訊息記錄都是傳送到同一個partition,則第一個訊息失敗第二個傳送成功,則第二條訊息會比第一條訊息出現要早。
-
batch.size:producer將試圖批次處理訊息記錄,以減少請求次數。這將改善client與server之間的效能。這項設定控制預設的批次處理訊息位元組數。
-
client.id:當向server發出請求時,這個字串會傳送給server。目的是能夠追蹤請求源頭,以此來允許ip/port許可列表之外的一些應用可以傳送資訊。這項應用可以設定任意字串,因為沒有任何功能性的目的,除了記錄和跟蹤。
-
linger.ms:producer組將會彙總任何在請求與傳送之間到達的訊息記錄一個單獨批次的請求。通常來說,這隻有在記錄產生速度大於傳送速度的時候才能發生。
-
max.request.size:請求的最大位元組數。這也是對最大記錄尺寸的有效覆蓋。注意:server具有自己對訊息記錄尺寸的覆蓋,這些尺寸和這個設定不同。此項設定將會限制producer每次批次傳送請求的數目,以防發出巨量的請求。
-
receive.buffer.bytes:TCP receive快取大小,當閱讀資料時使用。
-
send.buffer.bytes:TCP send快取大小,當傳送資料時使用。
-
timeout.ms:此設定選項控制server等待來自followers的確認的最大時間。如果確認的請求數目在此時間內沒有實現,則會返回一個錯誤。這個超時限制是以server端度量的,沒有包含請求的網路延遲。
-
block.on.buffer.full:當我們記憶體快取用盡時,必須停止接收新訊息記錄或者丟擲錯誤。
預設情況下,這個設定為真,然而某些阻塞可能不值得期待,因此立即丟擲錯誤更好。設定為false則會這樣:producer會丟擲一個異常錯誤:BufferExhaustedException,
如果記錄已經傳送同時快取已滿。 -
metadata.fetch.timeout.ms:是指我們所獲取的一些元素據的第一個時間資料。元素據包含:topic,host,partitions。此項設定是指當等待元素據fetch成功完成所需要的時間,否則會丟擲異常給使用者端。
-
metadata.max.age.ms:以微秒為單位的時間,是在我們強制更新metadata的時間間隔。即使我們沒有看到任何partition
leadership改變。 -
metric.reporters:類的列表,用於衡量指標。實現MetricReporter介面,將允許增加一些類,這些類在新的衡量指標產生時就會改變。JmxReporter總會包含用於註冊JMX統計
-
metrics.num.samples:用於維護metrics的樣本數。
-
metrics.sample.window.ms:metrics系統維護可設定的樣本數量,在一個可修正的window
size。這項設定設定了視窗大小,例如。我們可能在30s的期間維護兩個樣本。當一個視窗推出後,我們會擦除並重寫最老的視窗。 -
recoonect.backoff.ms:連線失敗時,當我們重新連線時的等待時間。這避免了使用者端反覆重連。
-
retry.backoff.ms:在試圖重試失敗的produce請求之前的等待時間。避免陷入傳送-失敗的死迴圈中。
kafka消費者設定引數
-
group.id:用來唯一標識consumer程序所在組的字串,如果設定同樣的group
id,表示這些processes都是屬於同一個consumer group。 -
zookeeper.connect:指定zookeeper的連線的字串,格式是hostname:port,
hostname:port... -
consumer.id:不需要設定,一般自動產生
-
socket.timeout.ms:網路請求的超時限制。真實的超時限制是max.fetch.wait+socket.timeout.ms。預設3000
-
socket.receive.buffer.bytes:socket用於接收網路請求的快取大小。預設64*1024。
-
fetch.message.max.bytes:每次fetch請求中,針對每次fetch訊息的最大位元組數。預設1024*1024
這些位元組將會督導用於每個partition的記憶體中,因此,此設定將會控制consumer所使用的memory大小。
這個fetch請求尺寸必須至少和server允許的最大訊息尺寸相等,否則,producer可能傳送的訊息尺寸大於consumer所能消耗的尺寸。 -
num.consumer.fetchers:用於fetch資料的fetcher執行緒數。預設1
-
auto.commit.enable:如果為真,consumer所fetch的訊息的offset將會自動的同步到zookeeper。這項提交的offset將在程序掛掉時,由新的consumer使用。預設true。
-
auto.commit.interval.ms:consumer向zookeeper提交offset的頻率,單位是秒。預設60*1000。
-
queued.max.message.chunks:用於快取訊息的最大數目,每個chunk必須和fetch.message.max.bytes相同。預設2。
-
rebalance.max.retries:當新的consumer加入到consumer
group時,consumers集合試圖重新平衡分配到每個consumer的partitions數目。如果consumers集合改變了,當分配正在執行時,這個重新平衡會失敗並重入。預設4 -
fetch.min.bytes:每次fetch請求時,server應該返回的最小位元組數。如果沒有足夠的資料返回,請求會等待,直到足夠的資料才會返回。
-
fetch.wait.max.ms:如果沒有足夠的資料能夠滿足fetch.min.bytes,則此項設定是指在應答fetch請求之前,server會阻塞的最大時間。預設100
-
rebalance.backoff.ms:在重試reblance之前backoff時間。預設2000
-
refresh.leader.backoff.ms:在試圖確定某個partition的leader是否失去他的leader地位之前,需要等待的backoff時間。預設200
-
auto.offset.reset:zookeeper中沒有初始化的offset時,如果offset是以下值的迴應:
-
lastest:自動復位offset為lastest的offset
-
earliest:自動復位offset為earliest的offset
-
none:向consumer丟擲異常
-
consumer.timeout.ms:如果沒有訊息可用,即使等待特定的時間之後也沒有,則丟擲超時異常
-
exclude.internal.topics:是否將內部topics的訊息暴露給consumer。預設true。
-
paritition.assignment.strategy:選擇向consumer
流分配partitions的策略,可選值:range,roundrobin。預設range。 -
client.id:是使用者特定的字串,用來在每次請求中幫助跟蹤呼叫。它應該可以邏輯上確認產生這個請求的應用。
-
zookeeper.session.timeout.ms:zookeeper 對談的超時限制。預設6000
如果consumer在這段時間內沒有向zookeeper傳送心跳資訊,則它會被認為掛掉了,並且reblance將會產生 -
zookeeper.connection.timeout.ms:使用者端在建立通zookeeper連線中的最大等待時間。預設6000
-
zookeeper.sync.time.ms:ZK follower可以落後ZK leader的最大時間。預設1000
-
offsets.storage:用於存放offsets的地點:
zookeeper或者kafka。預設zookeeper。 -
offset.channel.backoff.ms:重新連線offsets
channel或者是重試失敗的offset的fetch/commit請求的backoff時間。預設1000 -
offsets.channel.socket.timeout.ms:當讀取offset的fetch/commit請求迴應的socket
超時限制。此超時限制是被consumerMetadata請求用來請求offset管理。預設10000。 -
offsets.commit.max.retries:重試offset
commit的次數。這個重試只應用於offset commits在shut-down之間。預設5。 -
dual.commit.enabled:如果使用"kafka"作為offsets.storage,你可以二次提交offset到zookeeper(還有一次是提交到kafka)。
在zookeeper-based的offset storage到kafka-based的offset
storage遷移時,這是必須的。對任意給定的consumer
group來說,比較安全的建議是當完成遷移之後就關閉這個選項 -
partition.assignment.strategy:在"range"和"roundrobin"策略之間選擇一種作為分配partitions給consumer
資料流的策略。
迴圈的partition分配器分配所有可用的partitions以及所有可用consumer執行緒。它會將partition迴圈的分配到consumer執行緒上。如果所有consumer範例的訂閱都是確定的,則partitions的劃分是確定的分佈。
迴圈分配策略只有在以下條件滿足時才可以:(1)每個topic在每個consumer實力上都有同樣數量的資料流。(2)訂閱的topic的集合對於consumer
group中每個consumer範例來說都是確定的
kafka ack容錯機制(應答機制)
在Producer(生產者)向kafka叢集傳送訊息,kafka叢集會在接受完訊息後,給出應答,成功或失敗,如果失敗,producer(生產者)會再次傳送,直到成功為止。
producer(生產者)傳送資料給kafka叢集,kafka叢集反饋有3種模式:
-
0:producer(生產者)不會等待kafka叢集傳送ack,producer(生產者)傳送完訊息就算成功。
-
1:producer(生產者)等待kafka叢集的leader接受到訊息後,傳送ack。producer(生產者)接收到ack,表示訊息傳送成功。
-
-1:producer(生產者)等待kafka叢集所有包含分割區的follower都同步訊息成功後,傳送ack。producer(生產者)接受到ack,表示訊息傳送成功。
kafka segment
在Kafka檔案儲存中,同一個topic下有多個不同partition,每個partition為一個目錄,partiton命名規則為topic名稱+有序序號,第一個partiton序號從0開始,序號最大值為partitions數量減1。
每個partion(目錄)相當於一個巨型檔案被平均分配到多個大小相等segment(段)資料檔案中。但每個段segment
file訊息數量不一定相等,這種特性方便old segment
file快速被刪除。預設保留7天的資料。
每個partiton只需要支援順序讀寫就行了,segment檔案生命週期由伺服器端設定引數決定。(什麼時候建立,什麼時候刪除)
資料有序性:只有在一個partition分割區內,資料才是有序的。
Segment file組成:由2大部分組成,分別為i**ndex file**和data
file,此2個檔案一一對應,成對出現,字尾".index"和".log"分別表示為segment索引檔案、資料檔案。(在目前最新版本,又新增了另外的約束)。
Segment檔案命名規則:partion全域性的第一個segment從0開始,後續每個segment檔名為上一個segment檔案最後一條訊息的offset值。數值最大為64位元long大小,19位數位字元長度,沒有數位用0填充。
索引檔案儲存大量後設資料,資料檔案儲存大量訊息,索引檔案中後設資料指向對應資料檔案中message的物理偏移地址。
segment機制的作用:
- 可以通過索引快速找到訊息所在的位置。
用於超過kafka設定的預設時間,清除比較方便。
kafka從零開始使用
這裡之前寫過一些kafka使用的文章,這裡就不在複製到此文章上面來了,以免文章內容太多太多了。
kafka安裝
文章:
kafka的視覺化軟體
kafka-eagle
地址:https://github.com/smartloli/kafka-eagle
下載之後解壓
需要設定環境
Windows環境
KE_HOME = D:\\kafka_eagle\\kafka-eagle-web-1.2.3
LINUX環境
export KE_HOME=/home/jars/kafka_eagle/kafka-eagle-web-1.2.3
設定mysql,執行ke.sql
指令碼,然後在D:\kafka_eagle\kafka-eagle-web-1.2.0\conf
中修改system-config.properties 組態檔
zookeeper 服務的設定地址,支援多個叢集,多個用逗號隔開
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=192.169.0.23:2181,192.169.0.24:2181,192.169.0.25:2181
cluster2.zk.list=192.169.2.156:2181,192.169.2.98:2181,192.169.2.188:2181
然後設定mysql服務的地址
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
設定完成之後,在切換到/bin目錄下,windows雙擊ke.bat ,linux輸入 ke.sh
start,啟動程式,然後在瀏覽器輸入ip:port/ke
進入登入介面,輸入ke資料庫中的ke_users設定的使用者名稱和密碼,即可檢視。
kafka-manager
地址:https://github.com/yahoo/kafka-manager
下載編譯
git clone https://github.com/yahoo/kafka-manager
cd kafka-manager
sbt clean distcd target/
編譯完成之後,解壓該檔案
在 conf/application.properties路徑下找到 kafka-manager.zkhosts 設定,新增zookeeper的地址,如果是多個,用逗號隔開。
kafka-manager.zkhosts = master:2181,slave1:2181,slave2:2181
修改完成之後,就可以進行啟動了。
kafka-manager 預設的埠是9000,我們可以通過 -Dhttp.port來指定埠。
nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8765 &
啟動成功之後,在瀏覽器輸入地址即可進行存取了。
Kafka Tool(offset Explorer)
Offset Explorer(以前稱為Kafka Tool)是一個用於管理和使用Apache Kafka ®叢集的GUI應用程式。它提供了一個直觀的使用者介面,允許人們快速檢視其中的物件 一個 Kafka 叢集以及儲存在叢集主題中的訊息。它包含面向開發人員和管理員的功能。一些主要功能包括
- 快速檢視所有 Kafka 叢集,包括其代理、主題和使用者
- 檢視分割區中的訊息內容並新增新訊息
- 檢視消費者的偏移量,包括 Apache Storm Kafka 噴口消費者
- 以漂亮的列印格式顯示 JSON、XML 和 Avro 訊息
- 新增和刪除主題以及其他管理功能
- 將分割區中的單個訊息儲存到本地硬碟機
- 編寫自己的外掛,允許您檢視自定義資料格式
- Offset Explorer 可在 Windows、Linux 和 Mac OS 上執行
demo程式碼
文章:
程式碼地址:
https://github.com/xuwujing/kafka-study
https://github.com/xuwujing/java-study/tree/master/src/main/java/com/pancm/mq/kafka
kafka生產環境問題排查和解決方案
這裡主要是記錄在使用kafka的時候遇到的一些生產環境問題和解決方案,有的可能不是問題,而是需求,有的問題解決方案按照現在來說不完美,畢竟很多時候,快速解決才是第一要素。總之這些就按照我之前的筆記記錄進行分享吧,如有更好的思路或者解決辦法,歡迎提出!
先介紹一些kafka的常用命令
kafka常用命令
官方檔案: http://kafka.apache.org/quickstart
1.啟動和關閉kafka
bin/kafka-server-start.sh config/server.properties \>\>/dev/null 2\>&1 &
bin/kafka-server-stop.sh
zookeeper啟動命令:
./zookeeper-server-start.sh -daemon
../config/zookeeper.properties
kafka啟用命令:
./kafka-server-start.sh -daemon
../config/server.properties
2.檢視kafka叢集中的訊息佇列和具體佇列
檢視叢集所有的topic
kafka-topics.sh \--zookeeper master:2181,slave1:2181,slave2:2181 \--list
檢視一個topic的資訊
kafka-topics.sh \--zookeeper master:2181 \--describe \--topic
1004_INSERT
檢視kafka consumer消費的offset
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker \--zookeeper
master:2181 \--group groupB \--topic KAFKA_TEST
在kafka中查詢資料
./kafka-console-consumer.sh \--zookeeper 172.16.253.91:2181 \--topic
MO_RVOK \--from-beginning \| grep -c \'13339309600\'
3.建立Topic
partitions指定topic分割區數,replication-factor指定topic每個分割區的副本數
kafka-topics.sh \--zookeeper master:2181 \--create \--topic t_test
\--partitions 30 \--replication-factor 1
4.生產資料和消費資料
kafka-console-producer.sh \--broker-list master:9092 \--topic t_test
Ctrl+D 退出
kafka-console-consumer.sh \--zookeeper master:2181 \--topic t_test
\--from-beginning
kafka-console-consumer.sh \--bootstrap-server localhost:9092 \--topic
t_test \--from-beginning
--from-beginning 是表示從頭開始消費
Ctrl+C 退出
5.kafka的刪除命令
1.kafka命令刪除
kafka-topics.sh \--delete \--zookeeper
master:2181,slave1:2181,slave2:2181 \--topic test
注:如果出現 This will have no impact if delete.topic.enable is not set
to true. 表示沒有徹底的刪除,而是把topic標記為:marked for deletion
。可以在server.properties中設定delete.topic.enable=true 來刪除。
2.進入zk刪除
zkCli.sh -server master:2181,slave1:2181,slave2:2181
找到topic所在的目錄:ls /brokers/topics
找到要刪除的topic,執行命令:rmr /brokers/topics/【topic
name】即可,此時topic被徹底刪除。
進入/admin/delete_topics目錄下,找到刪除的topic,刪除對應的資訊。
6.新增分割區
kafka-topics.sh \--alter \--topic INSERT_TEST1 \--zookeeper master:2181
\--partitions 15
7.檢視消費組
檢視所有
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--list
檢視某一個消費組
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--describe
\--group groupT
8.檢視offset的值
最小值:
kafka-run-class.sh kafka.tools.GetOffsetShell \--broker-list master:9092
-topic KAFKA_TEST \--time -2
最大值:
kafka-run-class.sh kafka.tools.GetOffsetShell \--broker-list master:9092
-topic KAFKA_TEST \--time -1
9,檢視kafka紀錄檔檔案中某一個topic佔用的空間
du -lh --max-depth=1 TEST*
遇到的問題
offset下標丟失問題
kafka版本:V1.0
因為某種原因,kafka叢集中的topic資料有一段時間(一天左右)沒有被消費,再次消費的時候,所有的消費程式讀取的offset是從頭開始消費,產生了大量重複資料。
問題原因:offset的過期時間惹的禍,offsets.retention.minutes這個過期時間在kafka低版本的預設設定時間是1天,如果超過1天沒有消費,那麼offset就會過期清理,因此導致資料重複消費。在2.0之後的版本這個預設值就設定為了7天。
解決辦法:
臨時解決辦法,根據程式最近列印的紀錄檔內容,找到最後消費的offset值,然後批次更改kafka叢集的offset。
kafka 的offset偏移量更改
首先通過下面的命令檢視當前消費組的消費情況:
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--group groupA
\--describe
current-offset 和 log-end-offset還有 lag
,分別為當前偏移量,結束的偏移量,落後的偏移量。
然後進行offset更改
這是一個範例,offset(所有分割區)更改為100之後
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--group groupA
\--topic KAFKA_TEST2 \--execute \--reset-offsets \--to-offset 100
--group 代表你的消費者分組
--topic 代表你消費的主題
--execute 代表支援復位偏移
--reset-offsets 代表要進行偏移操作
--to-offset 代表你要偏移到哪個位置,是long型別數值,只能比前面查詢出來的小
還一種臨時方案,就是更改程式碼,指定kafka的分割區和offset,從指定點開始消費!對應的程式碼範例也在上述貼出的github連結中。
最終解決辦法:將offset的過期時間值(offsets.retention.minutes)設定調大。
Kafka增加節點資料重新分配
背景:為了緩解之前kafka叢集服務的壓力,需要新增kafka節點,並且對資料進行重新分配。
解決方案:利用kafka自身的分割區重新分配原理進行資料重新分配。需要提前將新增的kafka節點新增到zookeeper叢集中,可以在zookeeper裡面通過ls /brokers/ids 檢視節點名稱。
1,建立檔案
建立一個topics-to-move.json的檔案,檔案中編輯如下引數,多個topic用逗號隔開。
{\"topics\": \[{\"topic\": \"t1\"},{\"topic\": \"t2\"}\],\"version\":1}
命令範例:
touch topics-to-move.json
vim topics-to-move.json
2,獲取建議資料遷移文字
在${kakfa}/bin 目錄下輸入如下命令,檔案和命令可以放在同一級。
命令範例:
./kafka-reassign-partitions.sh \--zookeeper 192.168.124.111:2181
\--topics-to-move-json-file topics-to-move.json \--broker-list
\"111,112,113,114\" \--generate
broker-list
後面的數位就是kafka每個節點的名稱,需要填寫kafka所有叢集的節點名稱。
執行完畢之後,複製Proposed partition reassignment configuration
下的文字到一個新的json檔案中,命名為reality.json。
3,執行重新分配任務
執行如下命令即可。
./kafka-reassign-partitions.sh \--zookeeper 192.168.124.111:2181
\--reassignment-json-file reality.json \--execute
出現successfully表示執行成功完畢
檢視執行的任務進度,輸入以下命令即可:
kafka-reassign-partitions.sh \--zookeeper ip:host,ip:host,ip:host
\--reassignment-json-file reality.json \--verify
kafka叢集同步
背景:因機房問題,需要將kafka叢集進行遷移,並且保證資料同步。
解決方案:使用MirrorMaker進行同步。
1.介紹
MirrorMaker是為解決Kafka跨叢集同步、建立映象叢集而存在的。下圖展示了其工作原理。該工具消費源叢集訊息然後將資料又一次推播到目標叢集。
2.使用
這裡分為兩個kafka叢集,名稱為源kafka叢集和目標kafka叢集,我們是要把源kafka叢集的資料同步到目標kafka叢集中,可以指定全部的topic或部分的topic進行同步。
其中同步的topic的名稱須一致,需提前建立好,分割區數和副本可以不一致!
主要參數說明:
1\. --consumer.config:消費端相關組態檔
2\. --producer.config:生產端相關組態檔
3\. --num.streams: consumer的執行緒數 預設1
4\. --num.producers: producer的執行緒數 預設1
5\. --blacklist: 不需要同步topic的黑名單,支援Java正規表示式
6.--whitelist:需要同步topic的白名單,符合java正規表示式形式
7\. -queue.size:consumer和producer之間快取的queue size,預設10000
在源kafka叢集建立consumer.config和producer.config檔案,然後設定如下資訊:
consumer.config設定
bootstrap.servers=192.169.2.144:9092
group.id=MW-MirrorMaker
auto.commit.enable=true
auto.commit.interval.ms=1000
fetch.min.bytes=6553600
auto.offset.reset = earliest
max.poll.records = 1000
producer.config設定
bootstrap.servers=192.169.2.249:9092
retries = 3
acks = all
batch.size = 16384
producer.type=sync
batch.num.messages=1000
其中 consumer.config的
bootstrap.servers是源kafka叢集的地址,producer.config是目標kafka的地址,可以填寫多個,用逗號隔開!
同步啟動命令範例:
nohup ../bin/kafka-mirror-maker.sh \--consumer.config consumer.config
\--num.streams 10 \--producer.config producer.config ---num.producers 10
\--whitelist \"MT_RVOK_TEST9\" \>/dev/null 2\>&1 &
可以使用jps在程序中查詢得到,檢視具體同步資訊可以檢視kafka消費組的offset得到。

3.測試
用程式往 MT_RVOK_TEST9
先往源kafka(192.169.2.144:9092)傳送10000條資料,然後啟動同步命令,檢視目標kafka叢集(192.169.2.249:9092),同步成功!

內外網kafka穿透(網閘)
背景:因為傳輸原因,需要kafka能夠在內外網傳輸,通過網閘。
解決方案:
1.網閘kafka內外網傳輸必要條件
1.網閘內外網可用,且網閘開放的埠和kakfa開放的埠必須一致,比如kafka預設是9092,那麼網閘開放的埠也是9092;
2.網閘開放埠,必須雙向資料同步,不能只單向傳輸,網閘和外網以及kakfa內網之間互信;
3.kafka設定需要新增額外設定引數,server.properties核心設定如下:
listeners=PLAINTEXT://kafka-cluster:9092
advertised.listeners=PLAINTEXT://kafka-cluster:9092
1.kafka服務、內網存取服務、外網存取服務,均需設定ip和域名對映。linux在/etc/hosts檔案中,新增ip和域名對映關係,內網存取,則ip為kafka內網的ip,外網存取則ip為網閘的ip;
內網存取kafka的檔案設定範例:
192.168.0.1 kafka-cluster
外網Windows的host檔案設定範例:
100.100.100.100 kafka-cluster
2.測試步驟
1.依次啟動zookeeper和kafka服務,可以使用jps命令檢視是否啟動;
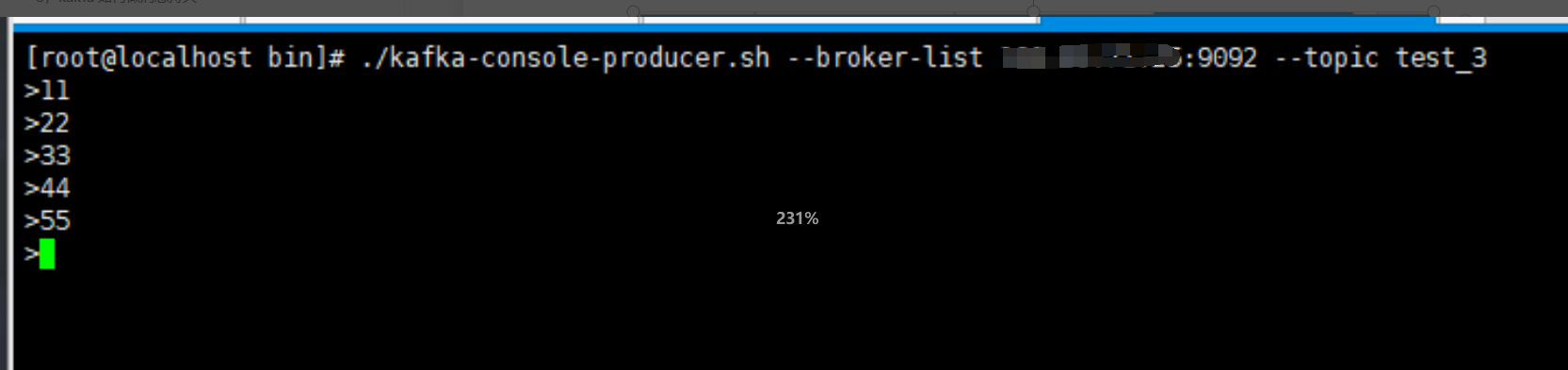
1.使用如下命令在kakfa的bin目錄下進行生產和消費測試:
生產命令
./kafka-console-producer.sh --broker-list 192.168.0.1:9092 --topic test_3
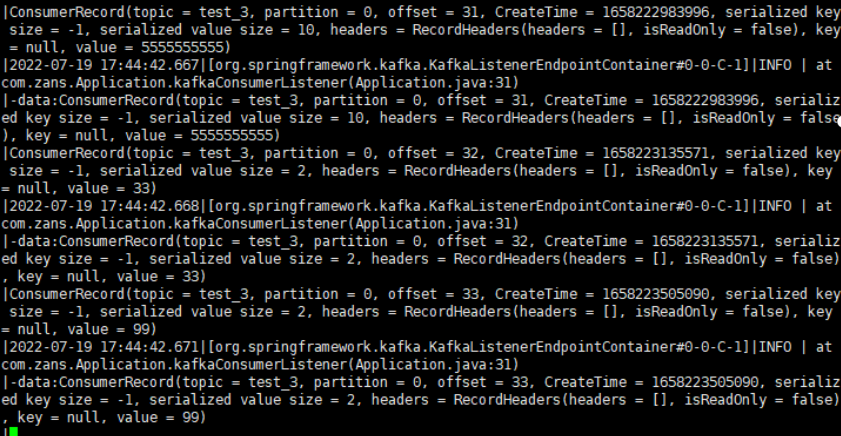
消費命令:
./kafka-console-consumer.sh --bootstrap-server 192.168.0.1:9092 --topic test_3
範例:
在生產的使用者端隨意資料資料,檢視消費端是否有資料消費

1.在外網使用kafka消費程式進行測試
資料消費成功範例:
其他問題
kafka資料丟失:
一般來說分為傳送訊息丟失和消費丟失,區別方式可以用kafka命令進行消費判斷,如果是傳送訊息丟失,那麼一般是設定或網路問題;如果是消費訊息丟失,多半是自動提交或無事務;找到資料來源頭解決就行,組態檔更改設定,可參考上面我發出的設定,自動提交改成手動提交,入庫失敗不提交。
kafka重複消費:
要麼是重複傳送,要麼是消費之後未提交且進行過重啟,要麼是更換了消費組(group),還有就是offset重置了這種。可根據原因對症下藥解決即可,解決辦法可參考本文上述範例。
kafka訊息積壓(堵塞):
生產的訊息速度遠遠大於消費的速度,導致訊息積壓。
常見情況一、分割區設定不合理,分割區個數太少,比如預設分割區5個,導致消費執行緒最多隻有5個,可選辦法有增加分割區,然後在增加消費執行緒;
常見情況二、消費端處理過於耗時,拿到訊息之後,遲遲未提交,導致消費速率太慢,可選辦法有將耗時處理方法抽出,比如在進行一次非同步處理,確保拿到kafka訊息到入庫這塊效率;
常見情況三、IO問題或kafka叢集問題,寬頻升級或叢集擴容。
不常見問題、設定設定問題,一般而言,kafka的設定除了必要的設定,大部分設定是不用更改,若資料量實在太大,需要調優,則可根據官方提供的設定進行偵錯。
其他
本以為寫這種型別文章不太耗時,沒想到一看又是凌晨了,整理筆記、文字排版還是真的有點費時,後續在更新一下linux的就結束這個系列吧。至於其他的各種知識有空的就在其他的篇章系列繼續更新吧~
手記系列
記載個人從剛開始工作到現在各種雜談筆記、問題彙總、經驗累積的系列。
- 手記系列之一 ----- 關於微信公眾號和小程式的開發流程
- 手記系列之二 ----- 關於IDEA的一些使用方法經驗
- 手記系列之三 ----- 關於使用Nginx的一些使用方法和經驗
- 手記系列之四 ----- 關於使用MySql的經驗
- 手記系列之五 ----- SQL使用經驗分享
一首很帶感的動漫鋼琴曲~
原創不易,如果感覺不錯,希望給個推薦!您的支援是我寫作的最大動力!
版權宣告:
作者:虛無境
部落格園出處:http://www.cnblogs.com/xuwujing
CSDN出處:http://blog.csdn.net/qazwsxpcm
個人部落格出處:https://xuwujing.github.io/