Kafka的系統架構和API開發
系統架構
主題topic和分割區partition
- topic
Kafka中儲存資料的邏輯分類;你可以理解為資料庫中「表」的概念;比如,將app端紀錄檔、微信小程式端紀錄檔、業務庫訂單表資料分別放入不同的topic - partition分割區(提升kafka吞吐量)
topic中資料的具體管理單元; - 每個partition由一個kafka broker伺服器管理;
- 每個topic 可以劃分為多個partition,分佈到多個broker上管理;
- 每個partition都可以有多個副本;保證資料安全
分割區對於 kafka 叢集的好處是:實現topic資料的負載均衡。提高寫入、讀出的並行度,提高吞吐量。 - 分割區副本replica
每個topic的每個partition都可以設定多個副本(replica),以提高資料的可靠性;
每個partition的所有副本中,必有一個leader副本,其他的就是follower副本(observer副本);follower定期找leader同步最新的資料;對外提供服務只有leader; - 分割區follower
partition replica中的一個角色,它通過心跳通訊不斷從leader中拉取、複製資料(只負責備份)。
如果leader所在節點宕機,follower中會選舉出新的leader; - 訊息偏移量offset
partition內部每條訊息都會被分配一個遞增id(offset);通過offset可以快速定位到訊息的儲存位置;
kafka 只保證按一個partition中的訊息的順序,不保證一個 topic的整體(多個partition 間)的順序。
哪一個topic的哪一個分割區的哪一個偏移量,資料只能追加,不能被修改
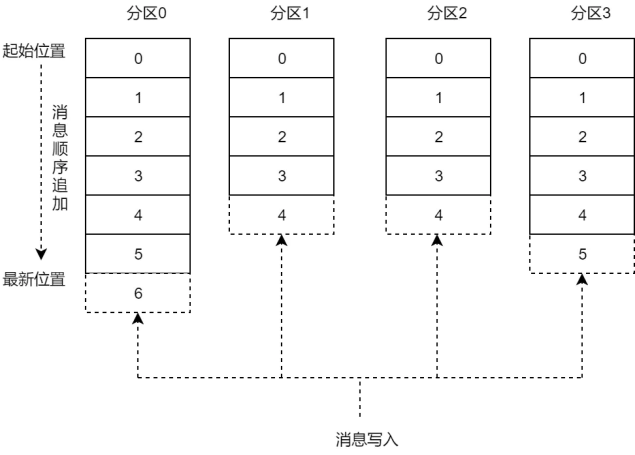
自我推導設計:
- kafka是用來存資料的;
- 現實世界資料有分類,所以儲存系統也應有資料分類管理功能,如mysql的表;kafka有topic;
- 如一個topic的資料全部交給一臺server儲存和管理, 則讀寫吞吐量有限, 所以, 一個topic的資料應該可以分成多個部分(partition)分別交給多臺server儲存和管理;
- 如一臺server宕機,這臺server負責的partition將不可用,所以,一個partition應有多個副本;
- 一個partition有多個副本,則副本間的資料一致性難以保證,因此要有一個leader統領讀寫;
- 一個leader萬一掛掉,則該partition又不可用,因此還要有leader的動態選舉機制;
- 叢集有哪些topic,topic有哪幾個分割區,server線上情況,等等元資訊和狀態資訊需要在叢集內部及使用者端之間共用,則引入了zookeeper;
- 使用者端在讀取資料時,往往需要知道自己所讀取到的位置,因而要引入訊息偏移量維護機制;
broker伺服器
一臺 kafka伺服器就是一個broker。一個kafka叢集由多個 broker 組成。
生產者producer
訊息生產者,就是向kafka broker發訊息的使用者端。
消費者consumer
- consumer :消費者,從kafka broker 取訊息的使用者端。
- consumer group:消費組,單個或多個consumer可以組成一個消費組。消費組是用來實現訊息的廣播(發給所有的 consumer)和單播(發給任意一個 consumer)的手段。
消費者可以對消費到的訊息位置(訊息偏移量)進行記錄;
老版本是記錄在zookeeper中;新版本是記錄在kafka中一個內建的topic中(__consumer_offsets)
資料儲存結構
在Kafka根目錄下的config/server.properties檔案中指定log.dirs=儲存紀錄檔檔案的目錄
物理儲存目錄結構: __consumer_offset
儲存目錄 名稱規範: topic名稱-分割區號
生產者生產的訊息會不斷追加到log檔案末尾,為防止log檔案過大導致資料定位效率低下,Kafka採取了分片和索引機制
- 每個partition的資料將分為多個segment儲存
- 每個segment對應兩個檔案:「.index"檔案和「.log"檔案。index和log檔案以當前segment的第一條訊息的offset命名。
index索引檔案中的資料為: 訊息offset -> log檔案中該訊息的物理偏移量位置;
Kafka 中的索引檔案以 稀疏索引(sparse index) 的方式構造訊息的索引,它並不保證每個訊息在索引檔案中都有對應的索引;每當寫入一定量(由 broker 端引數 log.index.interval.bytes 指定,預設值為 4096 ,即 4KB )的訊息時,偏移量索引檔案和時間戳索引檔案分別增加一個偏移量索引項和時間戳索引項,增大或減小 log.index.interval.bytes的值,對應地可以縮小或增加索引項的密度;
查詢指定偏移量時,使用二分查詢法來快速定位偏移量的位置。
訊息message儲存結構
在使用者端程式設計程式碼中,訊息的封裝類有兩種:ProducerRecord、ConsumerRecord;
簡單來說,kafka中的每個massage由一對key-value構成;
Kafka中的message格式經歷了3個版本的變化了:v0 、 v1 、 v2

各個欄位的含義介紹如下:
- crc:佔用4個位元組,主要用於校驗訊息的內容;
- magic:這個佔用1個位元組,主要用於標識紀錄檔格式版本號,此版本的magic值為1
- attributes:佔用1個位元組,這裡面儲存了訊息壓縮使用的編碼以及Timestamp型別。目前Kafka 支援 gzip、snappy 以及 lz4(0.8.2引入) 三種壓縮格式;[0,1,2]三位bit表示壓縮型別。[3]位表示時間戳型別(0,create time;1,append time),[4,5,6,7]位保留;
- key length:佔用4個位元組。主要標識 Key的內容的長度;
- key:佔用 N個位元組,儲存的是 key 的具體內容;
- value length:佔用4個位元組。主要標識 value 的內容的長度;
- value:value即是訊息的真實內容,在 Kafka 中這個也叫做payload。
API開發
準備: 建立專案並新增依賴
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
<!-- 依賴下載國內映象庫 -->
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<layout>default</layout>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
</repository>
</repositories>
<!-- maven外掛下載國內映象庫 -->
<pluginRepositories>
<pluginRepository>
<id>ali-plugin</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
</pluginRepository>
</pluginRepositories>
<build>
<plugins>
<!-- 指定編譯java的外掛 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 指定編譯scala的外掛 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<!-- 把依賴jar中的用到的類,提取到自己的jar中 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<!--下面是為了使用 mvn package命令,如果不加則使用mvn assembly-->
<executions>
<execution>
<id>make-assemble</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
生產者api
一個正常的生產邏輯需要具備以下幾個步驟
- 設定生產者引數及建立相應的生產者範例
- 構建待傳送的訊息
- 傳送訊息
- 關閉生產者範例
採用預設分割區方式將訊息雜湊的傳送到各個分割區當中
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerDemo {
public static void main(String[] args) throws InterruptedException {
/**
* 1.構建一個kafka的使用者端
* 2.建立一些待傳送的訊息,構建成kafka所需要的格式
* 3.呼叫kafka的api去傳送訊息
* 4.關閉kafka生產範例
*/
//1.建立kafka的物件,設定一些kafka的組態檔
//它裡面有一個泛型k,v
//要傳送資料的key
//要傳送的資料value
//他有一個隱含之意,就是kafka傳送的訊息,是一個key,value型別的資料,但是不是必須得,其實只需要傳送value的值就可以了
Properties pros = new Properties();
//指定kafka叢集的地址
pros.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092");
//指定key的序列化方式
pros.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//指定value的序列化方式
pros.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//ack模式,取值有0,1,-1(all),all是最慢但最安全的 伺服器應答生產者成功的策略
pros.put("acks", "all");
//這是kafka傳送資料失敗的重試次數,這個可能會造成傳送資料的亂序問題
pros.setProperty("retries", "3");
//資料傳送批次的大小 單位是位元組
pros.setProperty("batch.size", "10000");
//一次資料傳送請求所能傳送的最巨量資料量
pros.setProperty("max.request.size", "102400");
//訊息在緩衝區保留的時間,超過設定的值就會被提交到伺服器端
pros.put("linger.ms", 10000);
//整個Producer用到總記憶體的大小,如果緩衝區滿了會提交資料到伺服器端
//buffer.memory要大於batch.size,否則會報申請記憶體不足的錯誤
pros.put("buffer.memory", 10240);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(pros);
for (int i = 0; i < 1000; i++) {
//key value 0 --> doit32+-->+0
//key value 1 --> doit32+-->+1
//key value 2 --> doit32+-->+2
//2.建立一些待傳送的訊息,構建成kafka所需要的格式
ProducerRecord<String, String> record = new ProducerRecord<>("test01", i + "", "doit32-->" + i);
//3.呼叫kafka的api去傳送訊息
kafkaProducer.send(record);
Thread.sleep(100);
}
kafkaProducer.flush();
kafkaProducer.close();
}
}
對於properties設定的第二種寫法,相對來說不會出錯,簡單舉例:
public static void main(String[] args) {
Properties pros = new Properties();
pros.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux01:9092,linux02:9092,linux03:9092");
pros.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pros.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
}
消費者Api
一個正常的消費邏輯需要具備以下幾個步驟:
- 設定消費者使用者端引數及建立相應的消費者範例;
- 訂閱主題topic;
- 拉取訊息並消費;
- 定期向__consumer_offsets主題提交消費位移offset;
- 關閉消費者範例
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.record.TimestampType;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Optional;
import java.util.Properties;
public class ConsumerDemo {
public static void main(String[] args) {
//1.建立kafka的消費者物件,附帶著把組態檔搞定
Properties props = new Properties();
//props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"linux01:9092,linux02:9092,linux03:9092");
//props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 定義kakfa 服務的地址,不需要將所有broker指定上
// props.put("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092");
// 制定consumer group
props.put("group.id", "g3");
// 是否自動提交offset __consumer_offset 有多少分割區 50
props.put("enable.auto.commit", "true");
// 自動提交offset的時間間隔 -- 這玩意設定的大小怎麼控制
props.put("auto.commit.interval.ms", "5000"); //50000 1000
// key的反序列化類
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value的反序列化類
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 如果沒有消費偏移量記錄,則自動重設為起始offset:latest, earliest, none
props.put("auto.offset.reset","earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2.訂閱主題(確定需要消費哪一個或者多個主題)
consumer.subscribe(Arrays.asList("test02"));
//3.開始從topic中獲取資料
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
//這是資料所屬的哪一個topic
String topic = record.topic();
//該條資料的偏移量
long offset = record.offset();
//這條資料是哪一個分割區的
int partition = record.partition();
//這條資料記錄的時間戳,但是這個時間戳有兩個型別
long timestamp = record.timestamp();
//上面時間戳的型別,這個型別有兩個,一個是CreateTime(這條資料建立的時間), LogAppendTime(這條資料往紀錄檔裡面追加的時間)
TimestampType timestampType = record.timestampType();
//這個資料key的值
String key = record.key();
//這條資料value的值
String value = record.value();
//分割區leader的紀元
Optional<Integer> integer = record.leaderEpoch();
//key的長度
int keySize = record.serializedKeySize();
//value的長度
int valueSize = record.serializedValueSize();
//資料的頭部資訊
Headers headers = record.headers();
// for (Header header : headers) {
// String hKey = header.key();
// byte[] hValue = header.value();
// String valueString = new String(hValue);
// System.out.println("header的key值 = " + hKey + "header的value的值 = "+ valueString);
// }
System.out.printf("topic = %s ,offset = %d, partition = %d, timestampType = %s ,timestamp = %d , key = %s , value = %s ,leader的紀元 = %d , key序列化的長度 = %d ,value 序列化的長度 = %d \r\n" ,
topic,offset,partition,timestampType + "",timestamp,key,value,integer.get(),keySize,valueSize);
}
}
//4.關閉消費者物件
// consumer.close();
}
}
subscribe訂閱主題
// subscribe有如下過載方法:
public void subscribe(Collection<String> topics,ConsumerRebalanceListener listener)
public void subscribe(Collection<String> topics)
public void subscribe(Pattern pattern, ConsumerRebalanceListener listener)
public void subscribe(Pattern pattern)
// 1.指定集合方式訂閱主題
consumer.subscribe(Arrays.asList(topicl ));
// 2.正則方式訂閱主題
// 如果消費者採用的是正規表示式的方式(subscribe(Pattern))訂閱, 在之後的過程中,如果有人又建立了新的主題,並且主題名字與正表示式相匹配,那麼這個消費者就可以消費到新新增的主題中的訊息。
// 如果應用程式需要消費多個主題,並且可以處理不同的型別,那麼這種訂閱方式就很有效。
// 正規表示式的方式訂閱
consumer.subscribe(Pattern.compile ("topic.*" ));
// 利用正規表示式訂閱主題,可實現動態訂閱
assign訂閱主題
消費者不僅可以通過 KafkaConsumer.subscribe() 方法訂閱主題,還可直接訂閱某些主題的指定分割區;
在 KafkaConsumer 中提供了 assign() 方法來實現這些功能,此方法的具體定義如下:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.record.TimestampType;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Optional;
import java.util.Properties;
public class ConsumerDemo1 {
public static void main(String[] args) {
//1.建立kafka的消費者物件,附帶著把組態檔搞定
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"linux01:9092,linux02:9092,linux03:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"doit01");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2.訂閱主題(確定需要消費哪一個或者多個主題)
// consumer.subscribe(Arrays.asList("test03"));
// consumer.poll(Duration.ofMillis(Integer.MAX_VALUE));
// //我現在想手動指定,我需要從哪邊開始消費
// //如果用subscribe去訂閱主題的時候,他內部會給這個消費者組來一個自動再均衡
// consumer.seek(new TopicPartition("test03",0),2);
TopicPartition tp01 = new TopicPartition("test03", 0);
//他就是手動去訂閱主題和partition,有了這個就不需要再去訂閱subscribe主題了,手動指定以後,他的內部就不會再來自動均衡了
consumer.assign(Arrays.asList(tp01)); // 手動訂閱指定主題的指定分割區的指定位置
consumer.seek(new TopicPartition("test03",0),2);
//3.開始從topic中獲取資料
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
//這是資料所屬的哪一個topic
String topic = record.topic();
//該條資料的偏移量
long offset = record.offset();
//這條資料是哪一個分割區的
int partition = record.partition();
//這條資料記錄的時間戳,但是這個時間戳有兩個型別
long timestamp = record.timestamp();
//上面時間戳的型別,這個型別有兩個,一個是CreateTime(這條資料建立的時間), LogAppendTime(這條資料往紀錄檔裡面追加的時間)
TimestampType timestampType = record.timestampType();
//這個資料key的值
String key = record.key();
//這條資料value的值
String value = record.value();
//分割區leader的紀元
Optional<Integer> integer = record.leaderEpoch();
//key的長度
int keySize = record.serializedKeySize();
//value的長度
int valueSize = record.serializedValueSize();
//資料的頭部資訊
Headers headers = record.headers();
// for (Header header : headers) {
// String hKey = header.key();
// byte[] hValue = header.value();
// String valueString = new String(hValue);
// System.out.println("header的key值 = " + hKey + "header的value的值 = "+ valueString);
// }
System.out.printf("topic = %s ,offset = %d, partition = %d, timestampType = %s ,timestamp = %d , key = %s , value = %s ,leader的紀元 = %d , key序列化的長度 = %d ,value 序列化的長度 = %d \r\n" ,
topic,offset,partition,timestampType + "",timestamp,key,value,integer.get(),keySize,valueSize);
}
}
//4.關閉消費者物件
// consumer.close();
}
}
這個方法只接受引數partitions,用來指定需要訂閱的分割區集合。範例如下:
consumer.assign(Arrays.asList(new TopicPartition ("tpc_1" , 0),new TopicPartition(「tpc_2」,1))) ;
subscribe與assign的區別
- 通過subscribe()方法訂閱主題具有消費者自動再均衡功能 ;
在多個消費者的情況下可以根據分割區分配策略來自動分配各個消費者與分割區的關係。當消費組的消費者增加或減少時,分割區分配關係會自動調整,以實現消費負載均衡及故障自動轉移。
- assign() 方法訂閱分割區時,是不具備消費者自動均衡的功能的;
其實這一點從assign方法引數可以看出端倪,兩種型別subscribe()都有ConsumerRebalanceListener型別引數的方法,而assign()方法卻沒有。
取消訂閱
可以使用KafkaConsumer中的unsubscribe()方法採取消主題的訂閱,這個方法既可以取消通過 subscribe( Collection)方式實現的訂閱;
也可以取消通過subscribe(Pattem)方式實現的訂閱,還可以取消通過assign( Collection)方式實現的訂閱。
consumer.unsubscribe();
// 如果將subscribe(Collection )或assign(Collection)集合引數設定為空集合,作用與unsubscribe()方法相同
// 如下範例中三行程式碼的效果相同:
consumer.unsubscribe();
consumer.subscribe(new ArrayList<String>()) ;
consumer.assign(new ArrayList<TopicPartition>());
訊息的消費模式
Kafka中的消費是基於拉取模式的。
訊息的消費一般有兩種模式:推播模式和拉取模式。推模式是伺服器端主動將訊息推播給消費者,而拉模式是消費者主動向伺服器端發起請求來拉取訊息。
public class ConsumerRecord<K, V> {
public static final long NO_TIMESTAMP = RecordBatch.NO_TIMESTAMP;
public static final int NULL_SIZE = -1;
public static final int NULL_CHECKSUM = -1;
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final int serializedKeySize;
private final int serializedValueSize;
private final Headers headers;
private final K key;
private final V value;
private volatile Long checksum;
}
- topic partition 這兩個屬性分別代表訊息所屬主題的名稱和所在分割區的編號。
- offset 表示訊息在所屬分割區的偏移量。
- timestamp 表示時間戳,與此對應的timestampType 表示時間戳的型別。
- timestampType 有兩種型別 CreateTime 和LogAppendTime ,分別代表訊息建立的時間戳和訊息追加到紀錄檔的時間戳。
- headers 表示訊息的頭部內容。
- key value 分別表示訊息的鍵和訊息的值,一般業務應用要讀取的就是value ;
- serializedKeySize、serializedValueSize分別表示key、value 經過序列化之後的大小,如果 key 為空,則 serializedKeySize 值為 -1,同樣,如果value為空,則serializedValueSize 的值也會為 -1;
- checksum 是CRC32的校驗值。
/**
* 訂閱與消費方式2
*/
TopicPartition tp1 = new TopicPartition("x", 0);
TopicPartition tp2 = new TopicPartition("y", 0);
TopicPartition tp3 = new TopicPartition("z", 0);
List<TopicPartition> tps = Arrays.asList(tp1, tp2, tp3);
consumer.assign(tps);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition tp : tps) {
List<ConsumerRecord<String, String>> rList = records.records(tp);
for (ConsumerRecord<String, String> r : rList) {
r.topic();
r.partition();
r.offset();
r.value();
//do something to process record.
}
}
}
指定位移消費
有些時候,我們需要一種更細粒度的掌控,可以讓我們從特定的位移處開始拉取訊息,而 KafkaConsumer 中的seek()方法正好提供了這個功能,讓我們可以追前消費或回溯消費。
seek()方法的具體定義如下:
// seek都是和assign這個方法一起用 指定消費位置
public void seek(TopicPartiton partition,long offset)
程式碼範例:
public class ConsumerDemo3指定偏移量消費 {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"g002");
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"doit01:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
// 是否自動提交消費位移
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
// 限制一次poll拉取到的資料量的最大值
props.setProperty(ConsumerConfig.FETCH_MAX_BYTES_CONFIG,"10240000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// assign方式訂閱doit27-1的兩個分割區
TopicPartition tp0 = new TopicPartition("doit27-1", 0);
TopicPartition tp1 = new TopicPartition("doit27-1", 1);
consumer.assign(Arrays.asList(tp0,tp1));
// 指定分割區0,從offset:800開始消費 ; 分割區1,從offset:650開始消費
consumer.seek(tp0,200);
consumer.seek(tp1,250);
// 開始拉取訊息
while(true){
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofMillis(3000));
for (ConsumerRecord<String, String> rec : poll) {
System.out.println(rec.partition()+","+rec.key()+","+rec.value()+","+rec.offset());
}
}
}
}
自動提交消費者偏移量
Kafka中預設的消費位移的提交方式是自動提交,這個由消費者使用者端引數enable.auto.commit 設定,預設值為 true 。當然這個預設的自動提交不是每消費一條訊息就提交一次,而是定期提交,這個定期的週期時間由使用者端引數 auto.commit.interval.ms設定,預設值為5秒,此引數生效的前提是 enable. auto.commit 引數為 true。
在預設的方式下,消費者每隔5秒會將拉取到的每個分割區中最大的訊息位移進行提交。自動位移提交的動作是在 poll() 方法的邏輯裡完成的,在每次真正向伺服器端發起拉取請求之前會檢查是否可以進行位移提交,如果可以,那麼就會提交上一次輪詢的位移。
Kafka 消費的程式設計邏輯中位移提交是一大難點,自動提交消費位移的方式非常簡便,它免去了複雜的位移提交邏輯,讓編碼更簡潔。但隨之而來的是重複消費和訊息丟失的問題。
- 重複消費
假設剛剛提交完一次消費位移,然後拉取一批訊息進行消費,在下一次自動提交消費位移之前,消費者崩潰了,那麼又得從上一次位移提交的地方重新開始消費,這樣便發生了重複消費的現象(對於再均衡的情況同樣適用)。我們可以通過減小位移提交的時間間隔來減小重複訊息的視窗大小,但這樣並不能避免重複消費的傳送,而且也會使位移提交更加頻繁。
- 丟失訊息
按照一般思維邏輯而言,自動提交是延時提交,重複消費可以理解,那麼訊息丟失又是在什麼情形下會發生的呢?
拉取執行緒不斷地拉取訊息並存入本地快取,比如在BlockingQueue 中,另一個處理執行緒從快取中讀取訊息並進行相應的邏輯處理。設目前進行到了第 y+l 次拉取,以及第m次位移提交的時候,也就是 x+6 之前的位移己經確認提交了,處理執行緒卻還正在處理x+3的訊息;此時如果處理執行緒發生了異常,待其恢復之後會從第m次位移提交處,也就是 x+6 的位置開始拉取訊息,那麼 x+3至x+6 之間的訊息就沒有得到相應的處理,這樣便發生訊息丟失的現象。
手動提交消費者偏移量(呼叫kafka api)
自動位移提交的方式在正常情況下不會發生訊息丟失或重複消費的現象,但是在程式設計的世界裡異常無可避免;同時,自動位移提交也無法做到精確的位移管理。在 Kafka中還提供了手動位移提交的方式,這樣可以使得開發人員對消費位移的管理控制更加靈活。
很多時候並不是說拉取到訊息就算消費完成,而是需要將訊息寫入資料庫、寫入本地快取,或者是更加複雜的業務處理。在這些場景下,所有的業務處理完成才能認為訊息被成功消費;
手動的提交方式可以讓開發人員根據程式的邏輯在合適的時機進行位移提交。開啟手動提交功能的前提是消費者使用者端引數 enable.auto.commit 設定為false ,範例如下:
props.put(ConsumerConf.ENABLE_AUTO_COMMIT_CONFIG, false);
手動提交可以細分為同步提交和非同步提交,對應於 KafkaConsumer 中的 commitSync()和
commitAsync()兩種型別的方法。
同步提交的方式
commitSync()方法的定義如下:
/**
* 手動提交offset
*/
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> r : records) {
//do something to process record.
}
consumer.commitSync();
}
對於採用 commitSync()的無參方法,它提交消費位移的頻率和拉取批次訊息、處理批次訊息的頻率是一樣的,如果想尋求更細粒度的、更精準的提交,那麼就需要使用commitSync()的另一個有參方法,具體定義如下:
public void commitSync(final Map<TopicPartition,OffsetAndMetadata> offsets)
範例程式碼如下:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> r : records) {
long offset = r.offset();
//do something to process record.
TopicPartition topicPartition = new TopicPartition(r.topic(), r.partition());
consumer.commitSync(Collections.singletonMap(topicPartition,new OffsetAndMetadata(offset+1)));
}
}
提交的偏移量 = 消費完的record的偏移量 + 1
因為,__consumer_offsets中記錄的消費偏移量,代表的是,消費者下一次要讀取的位置!!!
非同步提交方式
非同步提交的方式( commitAsync())在執行的時候消費者執行緒不會被阻塞;可能在提交消費位移的結果還未返回之前就開始了新一次的拉取。非同步提交可以讓消費者的效能得到一定的增強。 commitAsync方法有一個不同的過載方法,具體定義如下
/**
* 非同步提交offset
*/
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> r : records) {
long offset = r.offset();
//do something to process record.
TopicPartition topicPartition = new TopicPartition(r.topic(), r.partition());
consumer.commitSync(Collections.singletonMap(topicPartition,new OffsetAndMetadata(offset+1)));
consumer.commitAsync(Collections.singletonMap(topicPartition, new OffsetAndMetadata(offset + 1)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if(e == null ){
System.out.println(map);
}else{
System.out.println("error commit offset");
}
}
});
}
}
手動提交位移(時機的選擇)
- 資料處理完成之前先提交偏移量
可能會發生漏處理的現象(資料丟失)反過來說,這種方式實現了: at most once的資料處理(傳遞)語意
- 資料處理完成之後再提交偏移量
可能會發生重複處理的現象(資料重複)反過來說,這種方式實現了: at least once的資料處理(傳遞)語意當然,資料處理(傳遞)的理想語意是: exactly once(精確一次)Kafka也能做到exactly once(基於kafka的事務機制)
程式碼範例:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.sql.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collection;
import java.util.Properties;
public class CommitOffsetByMyself {
public static void main(String[] args) throws SQLException {
//獲取mysql的連線物件
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/football", "root", "123456");
connection.setAutoCommit(false);
PreparedStatement pps = connection.prepareStatement("insert into user values (?,?,?)");
PreparedStatement pps_offset = connection.prepareStatement("insert into offset values (?,?) on duplicate key update offset = ?");
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux01:9092,linux02:9092,linux03:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//設定手動提交偏移量引數,需要將自動提交給關掉
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
//設定從哪裡開始消費
// props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
//設定組id
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group001");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
//訂閱主題
consumer.subscribe(Arrays.asList("kafka2mysql"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
for (TopicPartition topicPartition : collection) {
try {
PreparedStatement get_offset = connection.prepareStatement("select offset from offset where topic_partition = ?");
String topic = topicPartition.topic();
int partition = topicPartition.partition();
get_offset.setString(1, topic + "_" + partition);
ResultSet resultSet = get_offset.executeQuery();
if (resultSet.next()){
int offset = resultSet.getInt(1);
System.out.println("發生了再均衡,被分配了分割區消費權,並且查到了目標分割區的偏移量"+partition+" , "+offset);
//拿到了offset後就可以定位消費了
consumer.seek(new TopicPartition(topic, partition), offset);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
});
//拉去資料後寫入到mysql
while (true) {
try {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
String data = record.value();
String[] arr = data.split(",");
String id = arr[0];
String name = arr[1];
String age = arr[2];
pps.setInt(1, Integer.parseInt(id));
pps.setString(2, name);
pps.setInt(3, Integer.parseInt(age));
pps.execute();
//埋個異常,看看是不是真的是這樣
// if (Integer.parseInt(id) == 5) {
// throw new SQLException();
// }
long offset = record.offset();
int partition = record.partition();
String topic = record.topic();
pps_offset.setString(1, topic + "_" + partition);
pps_offset.setInt(2, (int) offset + 1);
pps_offset.setInt(3, (int) offset + 1);
pps_offset.execute();
//提交jdbc事務
connection.commit();
}
} catch (Exception e) {
connection.rollback();
}
}
}
}
消費者提交偏移量方式的總結
consumer的消費位移提交方式:
- 全自動
- auto.offset.commit = true
- 定時提交到consumer_offsets
- 半自動
- auto.offset.commit = false;
- 然後手動觸發提交 consumer.commitSync();
- 提交到consumer_offsets
- 全手動
- auto.offset.commit = false;
- 寫自己的程式碼去把消費位移儲存到你自己的地方mysql/zk/redis/
- 提交到自己所涉及的儲存;初始化時也需要自己去從自定義儲存中查詢到消費位移