Redis系列15:使用Stream實現訊息佇列(精講)
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 叢集模式
追求效能極致:Redis6.0的多執行緒模型
追求效能極致:使用者端快取帶來的革命
Redis系列8:Bitmap實現億萬級資料計算
Redis系列9:Geo 型別賦能億級地圖位置計算
Redis系列10:HyperLogLog實現海量資料基數統計
Redis系列11:記憶體淘汰策略
Redis系列12:Redis 的事務機制
Redis系列13:分散式鎖實現
Redis系列14:使用List實現訊息佇列
1 介紹
我們上一篇介紹瞭如何使用List實現訊息佇列麼,但是我們也看到很多侷限性,如下:
- 不支援訊息確認機制,沒有很好的ACK應答
- 不支援訊息回溯,無法排查問題和做訊息分析
- List遵循FIFO機制,所以存在訊息堆積的風險。
- 查詢效率低,作為線性結構,List中定位一個資料需要進行遍歷,O(N)的時間複雜度。
- 不存在消費組(Consumer Group)的概念,無法進行分組消費和批次消費
Redis中有三種訊息佇列模式:
| 名稱 | 簡要說明 |
|---|---|
| List | 不支援訊息確認機制(Ack),不支援訊息回朔 |
| pubSub | 不支援訊息確認機制(Ack),不支援訊息回朔,不支援訊息持久化 |
| stream | 支援訊息確認機制(Ack),支援訊息回朔,支援訊息持久化,支援訊息阻塞 |
可以看出,作為Redis 5.0 引入的專門為訊息佇列設計的資料型別,Stream 功能更加健全,更適合做訊息佇列分發。
Stream 可以包含 0個 到 n個元素的有序佇列,並根據ID的大小進行排序。
Stream型別訊息佇列的具備以下命令特點:
- 可以序列化生成訊息ID,方便索引、排序
- 訊息可回朔
- 支援Consumer Groups 消費組:多消費者訊息爭搶,加快消費速度
- 可以阻塞讀取訊息和非阻塞讀取訊息
- 沒有訊息漏讀風險
- 有ACK訊息確認機制,保證訊息至少被消費一次
- 支援多播模式:可以讓佇列從邏輯上分組進行隔離消費
這些特性,基本達到了一個訊息中介軟體的基本能力,比如:
- 類似 Kafka 的 Consumer Groups 的概念,它也具備了消費組的能力。
- 類似 Rocket MQ的持久化能力,以及高可用的檔案儲存機制,它也具備了訊息的持久化和主從複製機制,可以記錄存取位置,方便後續其他時間段繼續存取,避免資料丟失。
詳細的stream操作見官網檔案:https://redis.io/docs/data-types/streams-tutorial/
2 XADD 訊息寫入
即講訊息新增到佇列中,語法如下:
# 佇列名稱後面的佇列id如果用 * 號表示 ,這代表讓 Redis 為插入的訊息自動生成唯一 序列化ID,當然也可以自己指定。
# 後面可以包含多個鍵值對,代表多個訊息元素
XADD 佇列名稱 佇列id key1 value1 [key2 value2 ....]
註釋比較清楚,以下舉例說明:
> xadd stream_user * user_id 1 user_name brand age 18
"1680926230000-0"
不指配*,這可以直接指定順序Id
> XADD stream_user 0-1 user_name lili
0-1
> XADD stream_user 0-2 user_name brand
0-2
> XADD stream_user 0-* user_name candy
0-3
佇列的訊息ID 由兩部分組成:
- 毫秒級別的當前時間的時間戳;
- 順序編號。從 0 為起始值,用於區分同一時間內產生的多個ID,如果同一個時間戳內生成多ID,按序號順序增長,這種方式可解決順序識別和時間回撥問題。
通過這種時間戳 + 順序編號的模式,變成資料Append的模式,這種流式記性資料順序推播的方式符合MQ的基本消費邏輯,也為後面的有序性消費提供基本條件。
2 XREAD 訊息閱讀
即講訊息從佇列中讀取出來(消費),語法如下:
# COUNT:指的是對於每個Steam流中最多讀取幾個元素;
# BLOCK:當設定時阻塞讀取,佇列中沒有訊息即阻塞等待, 單位是ms,0 表示無限等待,類似MQ中的訂閱,等待新訊息出現。
# key:表示stream的名稱
# ID:訊息 id,讀取訊息的時候可以指定Id,並且指定某個Id的第一條甚至第n條開始讀取,圖中0-0 則表示從佇列Id為0的佇列的第1個元素開始讀取。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
註釋比較清楚,以下舉例說明:
XREAD COUNT 1 BLOCK 0 STREAMS stream_user 0-0
1) 1) "stream_user"
2) 1) 1) "1680926230000-0"
2) 1) "user_name"
2) "brand"
3) "age"
4) "18"
如何順序性消費:我們每次讀取之後都會返回訊息Id和序號,比如上面的 1680926230000-0,所以在下一次呼叫的時候,可以用上一次返回的ID序號作為引數,就可以從指定位置上進行消費。
問題:XREAD之後資料並沒有刪除,所以沒記住讀取的位置,下次可能重複閱讀,造成重複消費。所以需要消費確認機制(即ACK)。
3 消費者組模式(Consumer Group)
訊息佇列很重要的一個能力就是分組消費(Consumer Group),無論是Kafka 還是 RabbitMQ。他允許佇列從邏輯上進行分組來保證隔離消費。
這是典型的多播模,如下圖所示:
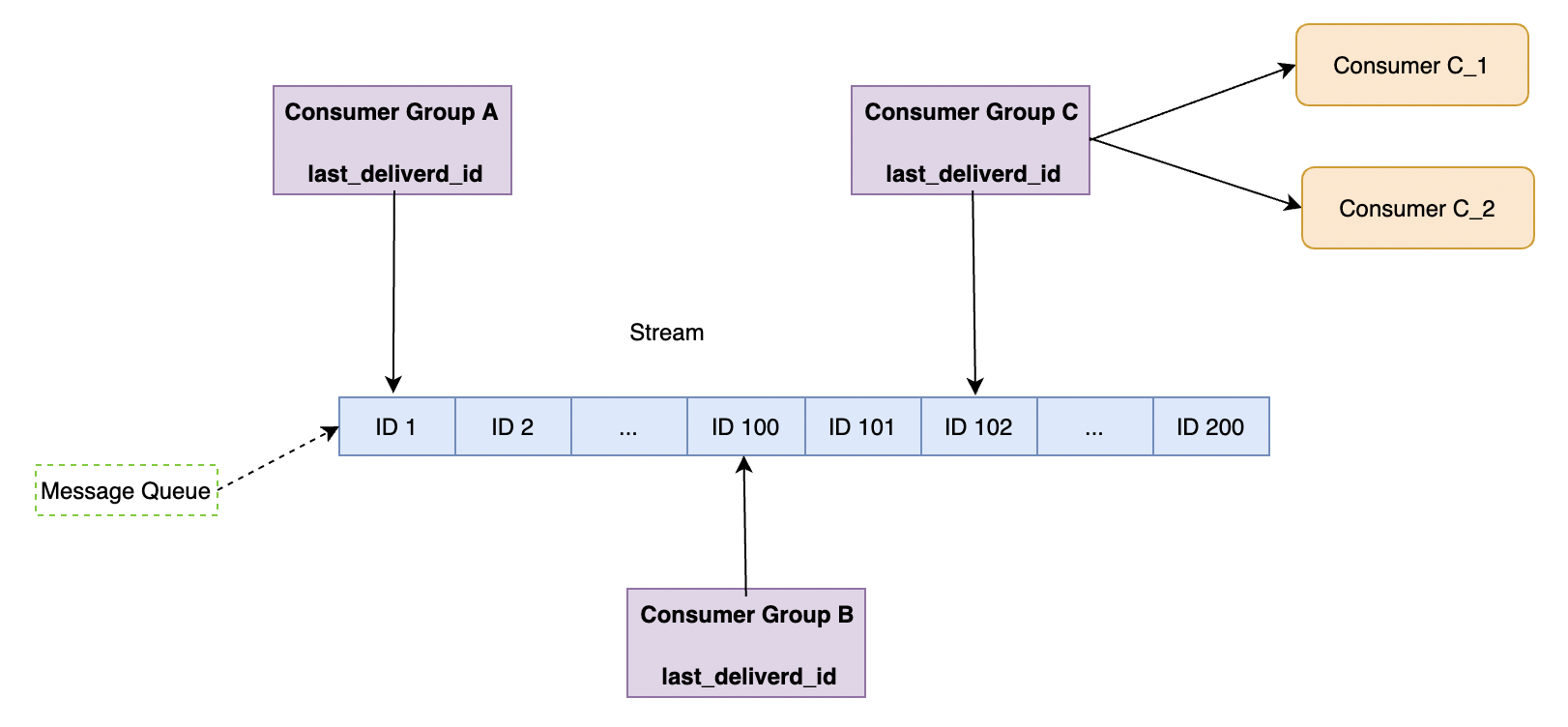
它有如下特點:
- Redis Stream 實際結構是一個鏈式的佇列,一個訊息由訊息Id和訊息內容組成,訊息Id具有唯一性;
- 消費組的狀態是獨立的,像圖中的GroupA、GroupB、GroupC,Stream 訊息可以被這幾個組消費;
- 同時一個消費者組可以有多個消費者,但是他們的競選關係,任意消費者消費之後就會導致
last_deliverd_id偏移,這樣避免了重複消費。 - 每個消費者都攜帶pending_ids 變數,記錄讀取但還未消費(未被ack)的訊息,來保證訊息有且僅有一次被消費。
消費組實現的訊息佇列主要有3類指令,如下:
- XGROUP:用於建立消費群組,包括登出和其他管理職能。
- XREADGROUP:消費者群組,通過這些組從流中有序讀取資料。
- XACK:通過該命令,消費者將處理的完的訊息標記為已正確完成。
3.1 寫入佇列資料
咱們先做一下資料準備,建立佇列,並往裡面寫入一些資料,如下:
> xadd stream_user * user_id 1 user_name brand age 18
"1681126033000-0"
> xadd stream_user * user_id 2 user_name jay age 19
"1681126222000-0"
> xadd stream_user * user_id 3 user_name candy age 20
"1681126235000-0"
> xadd stream_user * user_id 4 user_name lili age 21
"1681126251000-0"
> xadd stream_user * user_id 5 user_name hanry age 22
"1681126263000-0"
3.2 建立消費者群組
這個的做法就是在佇列中建立消費者組,然後指定消費的位置。
語法如下:
# stream_name:佇列名稱
# consumer_group:消費者組
# msgIdStartIndex:訊息Id開始位置
# msgIdStartIndex:訊息Id結束位置
xgroup create stream_name consumer_group msgIdStartIndex-msgIdStartIndex
下面是具體實現範例,為佇列 stream_user 建立了消費組1(consumer_group1)和 消費組2(consumer_group2):
> xgroup create stream_user consumer_group1 0-0
OK
> xgroup create stream_user consumer_group2 0-0
OK
3.3 讀取消費組資訊
消費佇列訊息的語法如下:
# groupName: 消費者群組名
# consumerName: 消費者名稱
# COUNT number: count 消費個數
# BLOCK ms: 阻塞時間,如果為 0 則代表無線阻塞
# streamName: 佇列名稱
# id: 訊息消費ID
# []:代表可選引數
# `>`:放在命令引數的最後面,表示從尚未被消費的訊息開始讀取;
XREADGROUP GROUP groupName consumerName [COUNT number] [BLOCK ms] STREAMS streamName [stream ...] id [id ...]
實現範例:消費組 consumer_group1 的消費者 consumer1 從 stream_user 中以阻塞的方式讀取一條訊息:
XREADGROUP GROUP consumer_group1 consumer1 COUNT 1 BLOCK 0 STREAMS stream_user >
1) 1) "stream_user"
2) 1) 1) "1681126033000-0"
2) 1) "user_id"
2) "1"
3) "user_name"
4) "brand"
5) "age"
6) "18"
這邊需要主意的是,同一個消費組內,訊息只能單次消費,如果被消費組內消費過了,就不會被同組的其他消費組讀取到。
如下:
XREADGROUP GROUP consumer_group1 consumer2 COUNT 1 BLOCK 0 STREAMS stream_user >
1) 1) "stream_user"
2) 1) 1) "1681126222000-0"
2) 1) "user_id"
2) "2"
3) "user_name"
4) "jay"
5) "age"
6) "19"
上面 user_name 為 brand 的資料已經被consumer1消費了,所以consumer2 就讀不到了,只能讀取到下一條 user_name 為 jay 的資料。
多個消費者可以達到流量分攤的目的,為大業務流量的場景做負載和分流。如下圖,多個消費者相對平均的進行訊息消費。
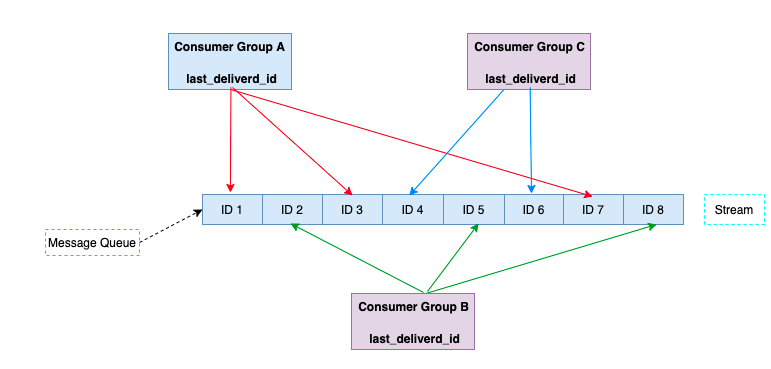
3.4 XPENDING 檢查已讀取但未ACK的資料
有時候會出現這種情況,就是消費者組或者消費者發生了故障,甚至整個消費者都故障重啟了,那麼如何避免訊息丟失呢,那就是將讀取到的但是還沒消費的資料進行暫存。
Redis在Stream內部實現了一個待決佇列(pending List),消費者讀取之後且沒有進行ACK的資料都儲存在這裡。
這種情況就是:
- 消費者使用
XREADGROUP讀取訊息 - 讀取完成之後,發生故障或者異常,沒有給 Stream 傳送
XACK命令,訊息依然保留在Stream 的 pending List中。
比如檢視 stream_user 中的 消費組 consumer_group1 中各個消費者已讀取未確認的訊息資訊:
XPENDING stream_user consumer_group1
1) (integer) 2 # 未確認訊息條數
2) "1681126235000-0" # consumer_group1 消費組中所有消費者讀取的最小ID
3) "1681126251000-0" # consumer_group1 消費組中所有消費者讀取的最大ID
4) 1) 1) "consumer1"
2) "1"
2) 1) "consumer2"
2) "1"
3.5 訊息消費完成之後確認(ACK)
正如3.4中所說的相關內容消費完之後,需要 ACK 通知 Streams,然後Stream除訊息。否則就會造成訊息變成待決佇列中,可能造成重複消費的情況。
執行命令語法如下:
# XACK stream_name group_name ID [ID ...]
# stream_name:佇列名稱
# group_name:消費組名稱
# ID:消費ID,可多選
XACK stream_user consumer_group1 1681126235000-0 1681126251000-0
(integer) 2
ack的本意就是對消費完成的訊息進行確認,業務處理沒有問題之後進行一個check的過程,代表這個訊息已經被消費完了。流程如下:
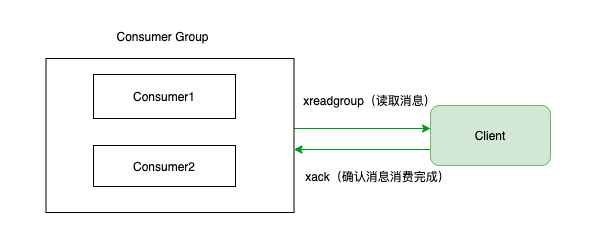
4 使用Redission實現Stream佇列能力
4.1 新增maven依賴 和 設定基本連線
# maven資訊
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.8</version>
</dependency>
# 基本設定
spring:
application:
name: redission_test
redis:
host: x.x.x.x
port: 6379
ssl: false
password: xxxx.xxxx
4.2 Java程式實現
@Slf4j
@Service
public class StreamQueueService {
@Autowired
private RedissonClient redissonClient;
/**
* 生產訊息內容
*
* @param msg
* @return
*/
@Override
public void produceMsg(String msg) {
RStream<String, String> stream = redissonClient.getStream("stream_user");
stream.add("user_id", "1");
stream.add("user_name", "brand");
stream.add("age", "18");
}
/**
* 消費訊息內容
*/
@Override
public void consumeMessage() {
// 根據佇列名稱獲取訊息佇列
RStream<String, String> stream = redissonClient.getStream("stream_user");
// 建立消費者小組
stream.createGroup("consumer_group1", StreamMessageId.ALL);
// 消費者讀取訊息
Map<StreamMessageId, Map<String, String>> msgs
= stream.readGroup("consumer_group1", "consumer1");
for (Map.Entry<StreamMessageId, Map<String, String>> entry : msgs.entrySet()) {
Map<String, String> msg = entry.getValue();
log.info(msg);
// todo:處理訊息的業務邏輯程式碼
stream.ack("consumer_group1", entry.getKey());
}
}
}
5 總結
相對List,Stream的能力有比較大的提升:
- 支援訊息確認機制(ACK應答確認)
- 支援訊息回溯,方便排查問題和做訊息分析
- 存在消費組(Consumer Group)的概念,可以進行分組消費和批次消費,可以負載多個消費範例
