新專案,不妨採用這種架構分層,很優雅!
大家好,我是飄渺。今天繼續更新DDD&微服務的系列文章。
在專欄開篇提到過DDD(Domain-Driven Design,領域驅動設計)學習起來較為複雜,一方面因為其自身涉及的概念頗多,另一方面,我們往往缺乏實戰經驗和明確的程式碼模型指導。今天,我們將專注於DDD的分層架構和實體模型,期望為大家落地DDD提供一些有益的參考。首先,讓我們回顧一下熟悉的MVC三層架構。
1. MVC 架構
在傳統應用程式中,我們通常採用經典的MVC(Model-View-Controller)架構進行開發,它將整體的系統分成了 Model(模型),View(檢視)和 Controller(控制器)三個層次,也就是將使用者檢視和業務處理隔離開,並且通過控制器連線起來,很好地實現了表現和邏輯的解耦,是一種標準的軟體分層架構。
在遵循此分層架構的開發過程中,我們通常會建立三個Maven Module:Controller、Service 和 Dao,它們分別對應表現層、邏輯層和資料存取層,如下圖所示:

(圖中多畫了一個Model層是因為 Model 通常只是簡單的 Java Bean,只包含資料庫表對應的屬性。有的應用會將其單獨抽取出來作為一個Maven Module,但實際上它可以合併到 DAO 層。)
1.1 MVC架構模型的不足
在業務邏輯較為簡單的應用中,MVC三層架構是一種簡潔高效的開發模式。然而,隨著業務邏輯的複雜性增加和程式碼量的增加,MVC架構可能會顯得捉襟見肘。其主要的不足可以總結如下:
- Service層職責過重:在MVC架構中,Service層常常被賦予處理複雜業務邏輯的任務。隨著業務邏輯的增長,Service層可能變得臃腫和複雜。業務邏輯有可能分散在各個Service類中,使得業務邏輯的組織和維護成為一項挑戰。
- 過於關注資料庫而忽視領域建模:雖然MVC的設計初衷是對資料、使用者介面和控制邏輯進行分離,但它在面對複雜業務場景時並未給予領域建模足夠的重視。這可能導致程式碼難以理解和擴充套件,因為程式碼更像是圍繞資料庫而不是業務需求進行設計。
- 邊界劃分不明確:在MVC架構中,頂層設計上的邊界劃分並沒有明確的規則,往往依賴於技術負責人的經驗。在大規模的團隊共同作業中,這可能導致職責不清晰、分工不明確等問題。
- 單元測試困難:在MVC架構中,Service層通常以事務指令碼的方式進行開發,並且往往耦合了各種中介軟體操作,如資料庫、快取、訊息佇列等。這種耦合使得單元測試變得困難,因為要在沒有這些中介軟體的情況下執行測試可能需要大量的模擬或存根程式碼。
在深入探討MVC架構之後,我們將進入今天的主題:DDD的分層架構模型。
2. DDD的架構模型
在DDD中,通常將應用程式分為四個層次,分別為使用者介面層(Interface Layer),應用層(Application Layer), 領域層(Domain Layer),基礎設施層(Infrastructure Layer),每個層次承擔著各自的職責和作用。分層模型如下圖所示:
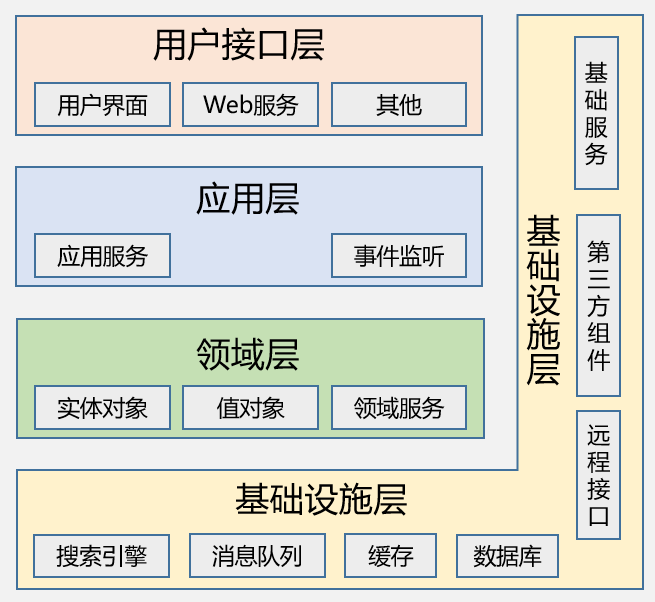
- 介面層(Interface Layer):負責處理與外部系統的互動,包括UI、Web API、RPC介面等。它會接收使用者或外部系統的請求,然後呼叫應用層的服務來處理這些請求,最後將處理結果返回給使用者或外部系統。
- 應用層(Application Layer):承擔協調領域層和基礎設施層的職責,實現具體的業務邏輯。它呼叫領域層的領域服務和基礎設施層的基礎服務,完成業務邏輯的實現。
- 領域層(Domain Layer):該層包含了業務領域的所有元素,如實體、值物件、領域服務、聚合、工廠和領域事件等。這一層的主要職責是實現業務領域的核心邏輯。
- 基礎設施層(Infrastructure Layer):主要提供通用的技術能力,如資料持久化、快取、訊息傳輸等基礎設施服務。它可被其他三層呼叫,提供各種必要的技術服務。
在這四層中,呼叫關係通常是單向依賴的,即上層依賴下層,下層並不依賴上層。例如,介面層依賴應用層,應用層依賴領域層,領域層依賴基礎設施層。但值得注意的是,儘管基礎設施層在物理結構上可能位於最底層,但在DDD的分層模型中,它位於最外層,為內部各層提供技術服務。

2.1 依賴反轉原則
依賴反轉原則(Dependency Inversion Principle, DIP)是一種有效的設計原則,有助於減小模組間的耦合度,提高系統的擴充套件性和可維護性。依賴反轉原則的核心思想是:高層模組不應直接依賴低層模組,它們都應該依賴抽象。抽象不應該依賴具體的實現,而具體的實現應當依賴於抽象。
在 DDD 的四層架構中,領域層是核心,是業務的抽象化,不應直接依賴其他任何層。這意味著領域層的業務物件應該與其他層(如基礎設施層)解耦,而不是直接依賴於具體的資料庫存取技術、訊息佇列技術等。但在實際執行時,領域層的物件需要通過基礎設施層來實現資料的持久化、訊息的傳送等。
為了解決這個問題,我們可以使用依賴翻轉原則。在領域層,我們定義一些介面(如倉儲介面),用於宣告領域物件需要的服務,具體的實現則由基礎設施層完成。在基礎設施層,我們實現這些介面,並將實現類注入到領域層的物件中。這樣,領域層的物件就可以通過這些介面與基礎設施層進行互動,而不需要直接依賴於基礎設施層。
2.2 DDD四層架構的優勢
在複雜的業務場景下,採用DDD的四層架構模型可以有效地解決使用MVC架構可能出現的問題:
- 職責分離:在DDD的設計中,我們嘗試將業務邏輯封裝到領域物件(如實體、值物件和領域服務)中。這樣可以降低應用層(原MVC中的Service層)的複雜性,同時使得業務邏輯更加集中和清晰,易於維護和擴充套件。
- 領域建模:DDD的核心理念在於通過建立富有內涵的領域模型來更真實地反映業務需求和業務規則,從而提高程式碼的靈活性,使其更容易適應業務的變化。
- 明確的邊界劃分:DDD通過邊界上下文(Bounded Context)的概念,對系統進行明確的邊界劃分。每個邊界上下文都有自己的領域模型和業務邏輯,使得大規模團隊共同作業更加清晰、高效。
- 易於測試:由於業務邏輯封裝在領域物件中,我們可以直接對這些領域物件進行單元測試。同時,基礎設施層(如資料庫、快取和訊息佇列)被抽象為介面,我們可以使用模擬物件(Mock Object)進行測試,避免了直接與真實中介軟體的互動,大大提升了測試的靈活性和便利性。
接下來看看如何在程式碼中遵循DDD的分層架構。
3. 如何實現DDD分層架構
為了遵循DDD的分層架構,在程式碼實現時有兩種實現方法。
第一種是在模組中通過包進行隔離,即在模組中建立4個不同的程式碼包,分別對應領域層(Domain Layer)、應用層(Application Layer)、基礎設施層(Infrastructure Layer)和使用者介面層(User Interface Layer)。這種方法的優點是結構簡單,易於理解和維護。但缺點是各層之間的依賴關係可能不夠明確,容易導致程式碼耦合。
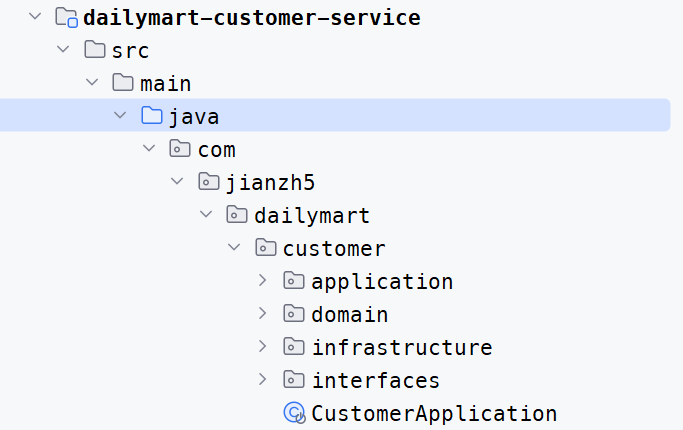
第二種實現方法是建立4個不同的Maven Module層,每個Module分別對應領域層、應用層、基礎設施層和使用者介面層。這種方法的優點是各層之間的依賴關係更加明確,有利於降低耦合度和提高程式碼的可重用性。同時,這種方法也有助於團隊成員更好地理解和遵循DDD的分層架構。然而,這種方法可能會導致專案結構變得複雜,增加了專案的維護成本。
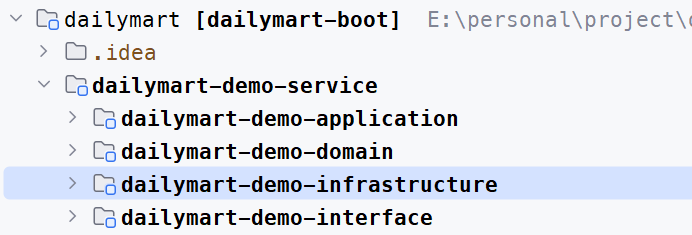
在實際專案中,可以根據專案規模、團隊成員的熟悉程度以及專案需求來選擇合適的實現方法。對於較小規模的專案,可以採用第一種方法,通過包進行隔離。而對於較大規模的專案,建議採用第二種方法,使用Maven Module層進行隔離,以便更好地管理和維護程式碼。無論採用哪種方法,關鍵在於確保各層之間的職責分明,遵循DDD的原則和最佳實踐。
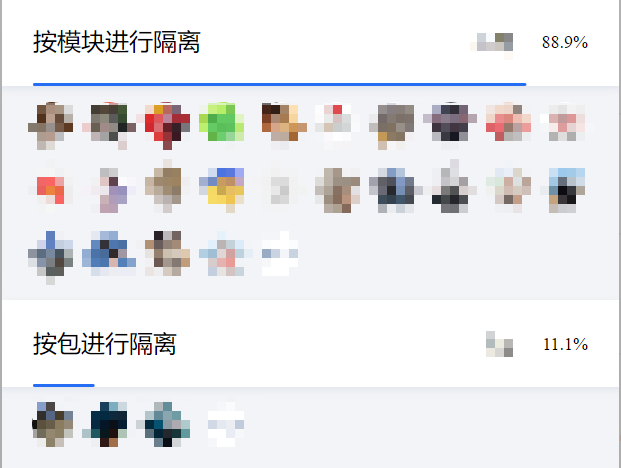
在DailyMart專案中,我最初打算採用第一種方法,通過包進行隔離。然而,在微信群中進行投票後,發現近90%的人選擇了第二種方法。作為一個傾聽粉絲意見的博主,我決定採納大家的建議。因此,DailyMart將採用Maven Module層隔離的方式進行編碼實踐。
4. DDD中的資料模型
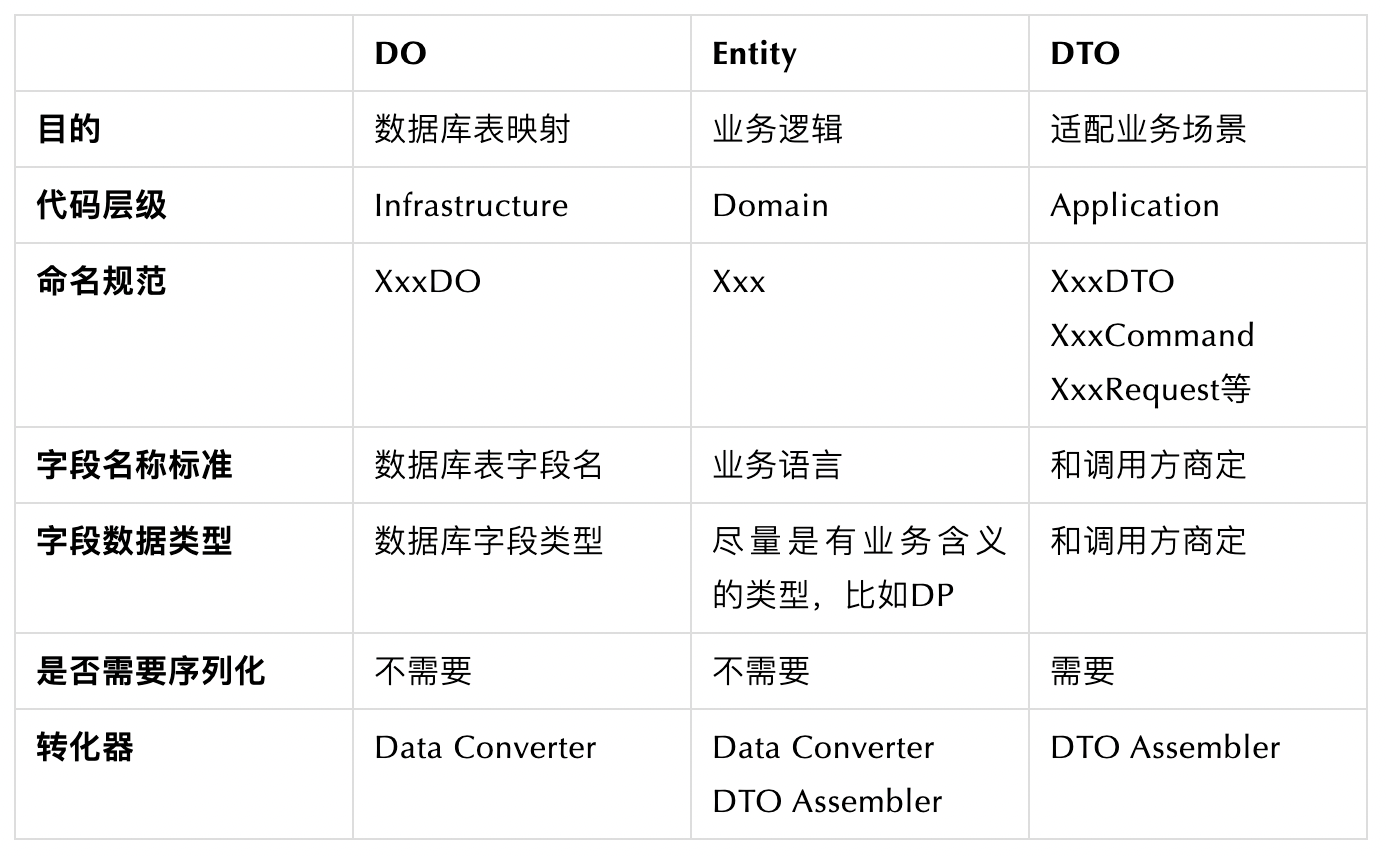
在DDD中,我們採用特定的模型來對映和處理不同的領域概念和責任,常見的有三種資料模型:實體物件(Entity)、資料物件(Data Object,DO)和資料傳輸物件(Data Transfer Object,DTO)。這些模型在DDD中有著明確的角色和使用場景:
- Entity(實體物件): 實體物件代表業務領域中的核心概念,其欄位和方法應與業務語言保持一致,與持久化方式無關。這意味著實體和資料物件可能具有完全不同的欄位命名、欄位型別,甚至巢狀關係。實體的生命週期應僅存在於記憶體中,無需可序列化和可持久化。
- Data Object (DO、資料物件): DO可能是我們在日常工作中最常見的資料模型。在DDD規範中,資料物件不能包含業務邏輯,並且位於基礎設施層,僅負責與資料庫進行互動,通常與資料庫的物理表一一對應。
- DTO(資料傳輸物件): 資料傳輸物件主要用作介面層和應用層之間傳遞資料,例如CQRS模式中的命令(Command)、查詢(Query)、事件(Event)以及請求(Request)和響應(Response)。DTO的重要性在於它能夠適配不同的業務場景需要的引數,從而避免業務物件變成龐大而複雜的"萬能"物件。
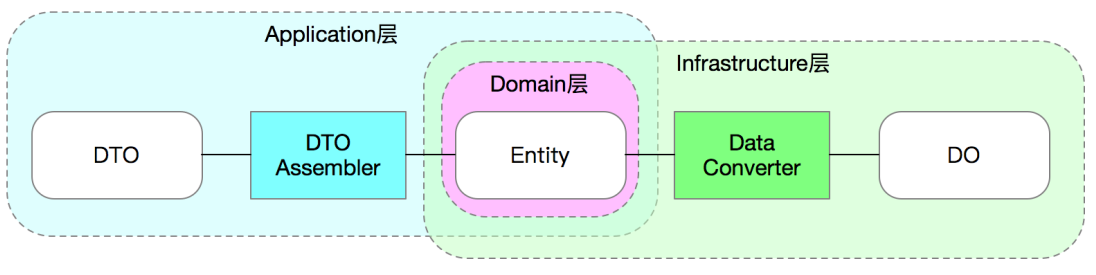
在DDD中,這三種資料物件在很多場景下需要相互轉換,例如:
-
Entity <-> DTO:在應用層返回資料時,需要將實體物件轉換成DTO,這一般通過一個名為
DTO Assembler的轉換器來完成。 -
Entity <-> DO:在基礎設施層的Repository實現時,我們需要將實體轉換為DO以儲存到資料庫。同樣地,查詢資料時需要將DO轉換回實體。這通常通過一個名為
Data Converter的轉換器來完成。
當然,不管是Entity轉DTO,還是Entity轉DO,都會有一定的開銷,無論是程式碼量還是執行時的操作來看。手寫轉換程式碼容易出錯,而使用反射技術雖然可以減少程式碼量,但可能會導致顯著的效能損耗。這裡給用Java的同學推薦MapStruct這個庫,MapStruct在編譯時生成程式碼,只需通過介面定義和註解設定就能生成相應的程式碼。由於生成的程式碼是直接賦值,所以效能損耗可以忽略不計。
在SpringBoot老鳥系列中我推薦大家使用 Orika 進行物件轉換,理由是隻需要編寫少量程式碼。但是在DDD中不同物件都有嚴格的程式碼層級,並且一般會引入專門的Assembler和Converter轉換器,既然程式碼量省不了,必然要選擇效能最高的元件。
各種轉換器的效能對比:Performance of Java Mapping Frameworks | Baeldung
5. 小結
本篇文章詳細介紹了DDD的分層架構,並詳細解釋瞭如何在專案程式碼中實現這種分層架構。同時,還詳細DDD中三種常用的資料物件:資料物件(DO)、實體(Entity)和資料傳輸物件(DTO)。這三種資料物件的區別可以通過下圖進行精煉總結:
至此,我們已經深入解析了DDD中的核心概念。同時,我們的DailyMart商城系統已完成所有的前期準備,現在已經準備好進入實際的編碼階段。在接下來的章節中,我們將從實現註冊流程開始,逐步探索如何在實際專案中應用DDD。
最後,歡迎關注公眾號 Java日知錄 ,獲取最新的文章和原始碼更新。