基於飛槳paddlespeech訓練中文喚醒詞模型
飛槳Paddlespeech中的語音喚醒是基於hey_snips資料集做的。Hey_snips資料集是英文喚醒詞,對於中國人來說,最好是中文喚醒詞。經過一番嘗試,我發現它也能訓練中文喚醒詞,於是我決定訓練一箇中文喚醒詞模型。
要訓練中文喚醒詞模型,主要有如下工作要做:找資料集,做資料增強(augmentation),做標註,訓練和評估等。關於資料集,調研下來發現「你好米雅」這個資料集不錯。它不僅可以做聲紋識別,也可以做喚醒詞識別。它錄製人數較多,既近場拾音(44.1KHZ),又用了麥克風陣列遠場拾音(16kHZ),還有快速、正常語速、慢速等,極大地豐富了語料。難能可貴的是出品方希爾貝殼還出了一個補充資料集,全是「你好米雅」的相似發音,比如「你好呀」、「你好米」等。把這些作為負樣本加入訓練,會大大地降低說「你好米雅」相似詞的誤喚醒率。經過評估後我決定用「你好米雅」這個喚醒詞。因為「你好米雅」資料集只有喚醒詞語料,為了降低誤喚醒,我又把AIDataTang資料集中兩三秒左右的語料提取出來作為負樣本加入訓練。這樣整個資料集包括三部分:「你好米雅」的原始資料集,相似發音的補充資料集(作為負樣本)和AIDataTang資料集(作為負樣本)。先把「你好米雅」資料集中44.1k取樣的語料變成16K取樣的,再分別將三個資料集分成訓練集、驗證集、測試集三部分。資料集分好後,還需要做資料增強,目前主要用的是加噪。從NOISEX-92中選取10種典型噪聲,再結合各種SNR疊加到乾淨語音中形成帶噪語音。資料增強做好後又把資料集增大了好多,形成一個近300萬個wav的資料集。最後寫python程式碼按照paddlespeech裡規定的格式做了資料標註,得到了train.json/dev.json/test.json三個檔案。在json檔案中對於一個wav檔案的標註格式如下圖:

包括檔案的時長、檔案的路徑、id以及是否是喚醒詞等。
以上這些工作做好後就開始訓練和評估了,驗證集和測試集下的結果都不錯。又想試試真實錄音的wav的準確率如何,請了幾個人在辦公室環境下用手機錄了「你好米雅」的音訊,在得到的模型下去測試,結果讓我大失所望,識別率特別低。為什麼呢?測試集上的結果可挺好的呀。輸入模型的特徵是頻域的fbank,於是我就從頻譜上找差異。對比測試集裡能識別的和自己錄的不能識別的wav的頻譜,發現能識別的在7K HZ附近處做了低通濾波,而不能識別的卻沒有,具體見下圖:
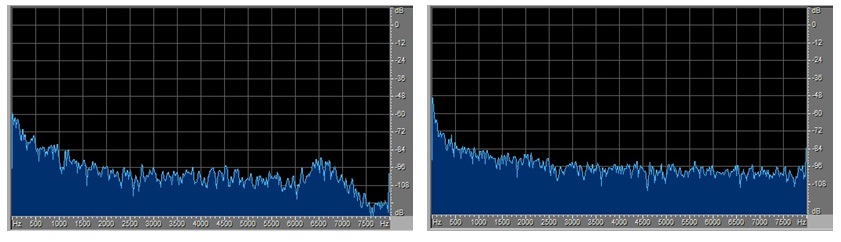
做了7k HZ低通濾波的能識別 沒做7k HZ低通濾波的不能識別
我試著將不能識別的也在7K HZ附近處做了低通濾波,再去做測試就能識別了。這樣自己錄的不能識別的原因就找到了:沒去做7K HZ附近的低通濾波。整個資料集是由3個子資料集(「你好米雅」資料集,「你好米雅」相似詞資料集,AIDATATANG資料集)組成的,前兩個是同一出品方且用相同的裝置錄的。我看了這三個子資料集的頻域特性,前兩個都在7K HZ附近處做了低通濾波,而AIDATATANG的沒有。這暴露了我在資料集準備上的一個錯誤:沒有做到訓練集/驗證集/測試集頻域特性上的一致。
原因找到了,對應的措施就是對原先的資料集做7k HZ處的低通濾波處理。為了再降低誤喚醒率,我又找來了cn-celeb資料集,因為這個裡面包含的場景更豐富,有singing/vlog/movie/entertainment等。把裡面幾秒左右的音訊都提取出來,先做7k HZ處的低通濾波處理,再把它們作為負樣本加入到資料集中。資料處理好後就又開始訓練了。一邊訓練模型,一邊請更多的人用手機錄「你好米雅」的喚醒詞音訊,還要對這些錄好的做7k HZ處的低通濾波處理。模型訓練好後在驗證集和測試集上的評估效果(喚醒率和誤喚醒率)都很好,再把自己錄的音訊在模型上跑,喚醒率跟在測試集上保持一致。同時還做了另外一個實驗,把測試集裡有喚醒詞且有噪聲的音訊提取出來組成一個新的測試集。先在這個集上看喚醒率,再對這個集上的音訊做降噪處理,再看喚醒率,發現喚醒率有一定程度的降低。這是模型沒有學習降噪演演算法的結果,模型不像人耳,降噪後聽起來更清晰未必能識別。通過這些實驗說明:要想在嵌入式裝置上語音喚醒效果好,得搞清楚特徵提權前有哪些前處理演演算法(降噪等)。語料最好是在這款嵌入式裝置上錄,如果沒有條件就要把語料過一下這些前處理演演算法後再拿去訓練和評估,也就是要讓模型學一下這些前處理演演算法。
現在的模型輸入特徵是80維的fbank,我又評估了一下維度改到40維後對喚醒效果的影響。評估下來發現喚醒率有0.2%左右的下降,誤喚醒率有0.3%左右的提升,在可接受的範圍內。好處是模型引數減少了1.6k(見下圖),推理時的運算量也有一定程度的減少。

目前用的是公開資料集裡的中文喚醒詞,通過實踐找到一些能提高喚醒率和降低誤喚醒率的方法。等做產品時用的資料集是私有的,把找到的方法用到模型訓練上,就能出一個效能不錯的語音喚醒方案。