【實戰分享】使用 Go 重構流式紀錄檔閘道器
專案背景
分享之前,先來簡單介紹下該專案在流式紀錄檔處理鏈路中所處的位置。
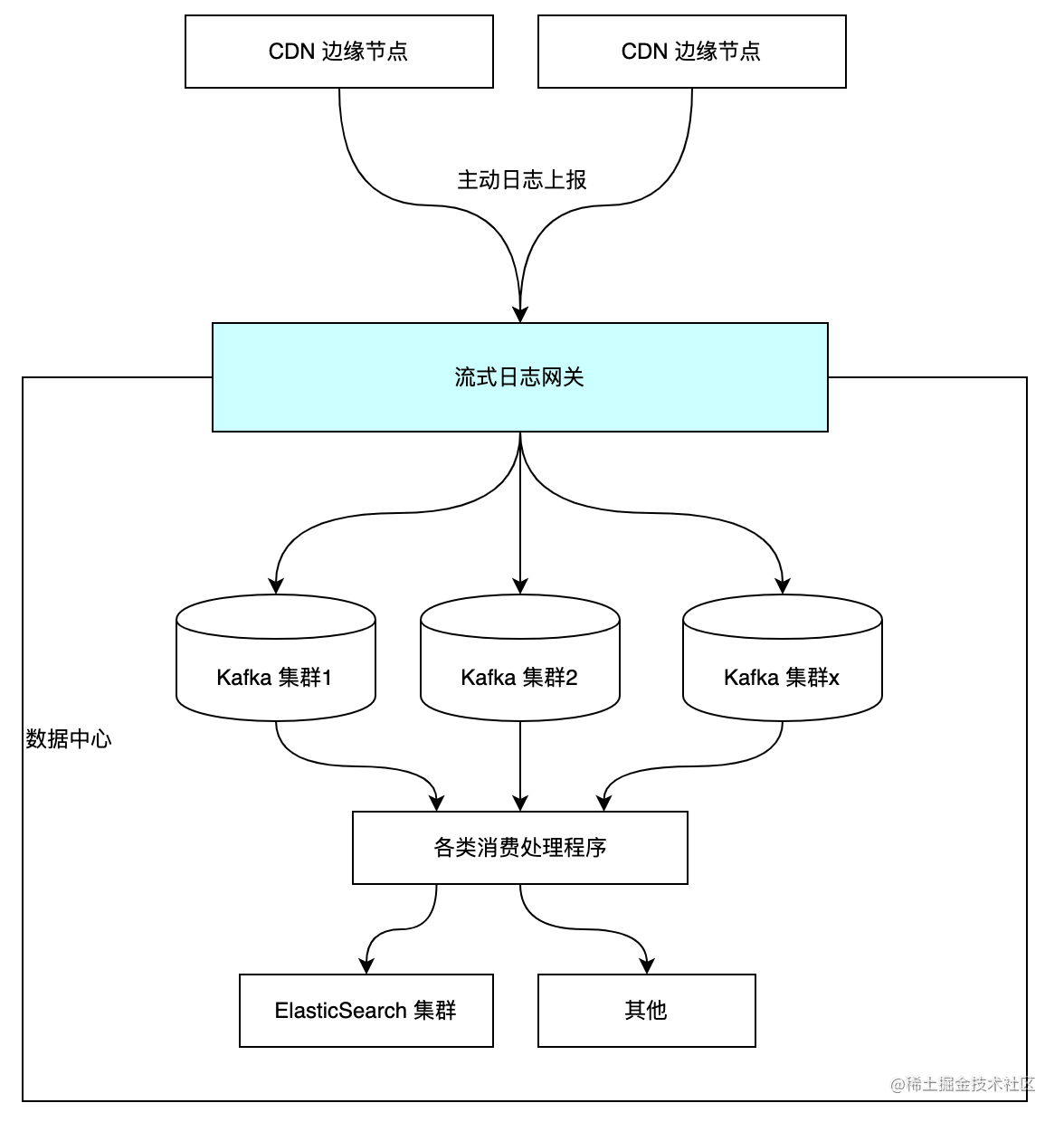
流式紀錄檔閘道器的主要功能是提供 HTTP 介面,接收 CDN 邊緣節點上報的各類紀錄檔(存取紀錄檔/報錯紀錄檔/計費紀錄檔等),將紀錄檔作預處理並分流到多個的 Kafka 叢集和 Topic 中。
越來越多的客戶要求提供實時紀錄檔支援,業務量的增加讓機器資源的消耗也與日俱增,最先暴露出了流式紀錄檔處理鏈路的一大瓶頸——頻寬資源。
可以通過給叢集擴充更多的機器來提升叢集總傳輸頻寬,但基於成本考量,重中之重是先優化閘道器程式。
舊版閘道器專案
專案代號 Chopper ,其基於另一個內部 OpenResty 專案框架來開發的。其亮點功能有:支援從 Consul 、Redis 等其他外部系統熱載入設定及動態生效;能夠載入 Lua 指令碼實現靈活的紀錄檔預處理能力。
其 Kafka 生產者使用者端基於 doujiang24/lua-resty-kafka 實現。經過實踐考驗,Chopper 的吞吐量是滿足現階段需求的。
存在的問題
1. 關鍵依賴庫的社群活躍度低
lua-resty-kafka 的社群活躍度較低,至今仍然處在實驗階段;而且它用作 Kafka 生產者使用者端目前沒有支援訊息壓縮功能,而這在其他語言實現的 Kafka 使用者端中都是標準的選項。
2. 記憶體使用不節制
單範例部署設定 4 核 8 G,僅少量請求存取後,記憶體佔用就穩定在 2G 而沒有釋放。
3. 組態檔可維護性差
實際線上用到 Consul 作為設定中心,採用篇幅很長的 JSON 格式組態檔,不利於運維。另外在 Consul 修改設定沒有回退功能,是一個高風險操作。
好在目前紀錄檔閘道器的功能並不複雜,所以我們決定重構它。
新專案啟動
眾所周知, Go 語言擁有獨特的高並行模型、較低的上手難度和豐富的第三方生態。而且我們小組成員都有 Go 專案的開發經驗,所以我們選擇使用基於 Go 語言的技術棧來重新構建 Chopper 專案,所以新專案命名為 chopper-go 。
需求梳理及概要設計
重新構建一個線上專案的基本原則是,功能上要完全相容,最好能夠實現線上服務的無縫升級替換。
原版核心模組的設計
Chopper 的核心功能是將接收到的 HTTP 請求分流到特定 Kafka 叢集及其 Topic 中。
一、HTTP 介面部分
只開放了唯一一個對外的 API ,功能很簡單:
請求方式:POST 請求路徑:/log/repo/{repo_name} 請求體: 多行紀錄檔,滿足 JSONL 格式(即每行一條 JSON ,多行按換行符 \n 分隔)。相應狀態碼:- 200:投遞成功。- 5xx:投遞失敗需要重試。引數解釋: - repo_name: 對應 repo 設定名稱。
二、業務設定部分
每一類業務抽象為一個 repo 設定。Repo 設定由三部分構成:constraint、processor、kafka。constraint 是一個物件,可以設定對紀錄檔欄位的一些約束條件,不滿足條件的紀錄檔會被丟棄。processor 是一個列表,可以組合多個處理模組,程式將按順序依次對請求中的每條紀錄檔進行處理。實現瞭如下幾種 processor 型別:
- decoder , 設定原始資料按哪種格式反序列化到 Lua table ,但只實現了 JSON decoder。
- splitter,設定分隔紀錄檔欄位的字元。
- assigner,設定一組欄位名對映關係,需要與 spliter 配合。
- executer, 設定額外的 lua 指令碼名稱,通過動態載入其他 lua 指令碼實現更靈活的處理邏輯。
kafka 是一個物件,可以設定當前業務相關聯的 Kafka 叢集名,預設投遞的 Topic ,以及生產者使用者端的工作模式(同步或者非同步)。
新版本的改動HTTP
介面沿用原先的設計,在業務設定部分做了一些改動:
- processor 改名為 executers ,實現幾個通用功能的紀錄檔處理模組,方便組合使用。
- kafka 設定中關聯的不再是叢集名,而是 Kafka 生產者使用者端的設定標籤。
- 原先儲存 kafka 叢集連線設定資訊的設定塊,改為儲存 kafka 生產者使用者端的設定塊,統一在一個設定塊區域初始化所有用到的 kafka 生產者使用者端。
一點妥協(做減法)
為了縮短新專案的開發週期,對原始專案的一些不太重要的特性我們做了一些取捨。
取消動態指令碼功能
Go 是靜態語言沒有 Lua 動態語言那麼靈活,要載入執行動態指令碼有一定的實現難度,且紀錄檔處理效能沒有保障。線上只有極少數業務在 processor 中設定了 executor,且這些 executor 的 Lua 指令碼實現相近,完全可以抽取出通用的程式碼。
不支援外部設定中心
為了讓釋出和回退有記錄可回溯,從 Consul 等設定中心熱載入服務設定的功能我們也去掉了。利用好容器平臺的金絲雀釋出功能,就能將服務更新的影響降到最低。
不支援複雜的路由重寫
OpenResty 專案內建 Nginx 可以利用 Nginx 強大的設定實現豐富的路由 rewrite 功能,就具體使用場景而言,我們只需要簡單的路由對映即可。況且更復雜的需求也可以由上一級閘道器完成。
選擇合適的開源庫
Web 框架的選擇
使用 Go 開發 Web 應用很快捷。我們參考瞭如下文章:
- 《超全的 Go Http 路由框架效能比較》(https://colobu.com/2016/03/23/Go-HTTP-request-router-and-web-framework-benchmark/ )
- 《iris真的是最快的路由框架嗎?》(https://colobu.com/2016/04/01/Is-iris-the-fastest-golang-router-library/)
- https://github.com/kataras/server-benchmarks
下列幾款 Star 較多的 Go Web 框架都能滿足我們需求:
- kataras/iris
- gin-gonic/gin
- go-chi/chi
- labstack/echo
他們效能都很好,最終我們選擇了 Gin 。原因是用得多比較熟,而且檔案看著舒服。
Kafka 生產者使用者端的選擇
社群中熱度最高的幾款 Go Kafka 使用者端庫:
- segmentio/kafka-go
- Shopify/sarama
- confluentinc/confluent-kafka-go
實際上三款使用者端庫我們在歷史專案中都使用過,其中 kafka-go 的 API 是三者中最簡潔易用的,我們的多個消費端程式都是基於它實現的。
但是在 chopper-go 中僅需要用到生產者使用者端,我們沒有選擇 kafka-go 。那是因為我們做了一些基準測試(https://github.com/sko00o/benchmark-kafka-go-clients ),發現 kafka-go 的生產者使用者端存在效能風險:啟用 async 模式時儘管訊息傳送特別快,但是記憶體佔用也增長特別快。通過閱讀原始碼我也找到了原因並向官方提了 issue(<https://github.com/segmentio/kafka-go/issues/819) ,但是作者覺得這設計沒毛病,所以就不了了之了。
最終我們選擇 sarama ,一方面是效能很穩定,另一方面是它開放的> API 較多,但是用起來確實有點費勁。
測試框架的選擇
程式的可靠性,一定需要測試來保證。除了編寫小模組中編寫單元從測試,我們對整個紀錄檔閘道器服務還要做整合測試。整合測試涉及到一些外部服務依賴,此專案中主要的外部依賴是 Kafka 和 Zookeeper。
利用 Docker 可以很方便的拉起測試環境,我們注意到了兩款可以用來在 Go test 中編寫整合測試的庫:
- ory/dockertest
- testcontainers/testcontainers-go
使用下來,我們最終選擇了 testcontainers-go,簡單介紹下原因:
在編寫整合測試時,我們需要有個等待機制來確保依賴服務的容器是否準備就緒,並以此控制測試流程,以及測試結束後需要把測試開啟的臨時容器都清理乾淨。
testcontainers-go 的設計要優於 dockertest 。testcontainers-go 提供一個 wait 子包,可以設定多種等待策略來確保依賴服務就緒,以及測試結束時它會呼叫一個特殊的名為 Ryuk 的容器來確保測試容器都被關閉。相對而言,dockertest 要簡陋不少。
需要注意的是,在 CI 環境執行整合測試都需要確保 ci-runner 支援 DinD ,否則執行 go test 會失敗。
專案開發
專案開發過程中基本按照需求來實現沒有太多難點。這裡分享踩到的幾個坑。
迴圈中變數的參照問題
在測試中發現,Kafka 生產者沒有按期望把訊息投遞到指定的 Kafka 叢集。
經過排查到如下程式碼:
func New(cfg Config) (*Manager, error) {
var newProducers = make(NewProducerFuncs)
for name, kCfg := range cfg.Mapping {
newProducers[name] = func() (kafka.Producer, error) { return kafka.New(kCfg) }
}
// 略
}
其作用是將設定每個 Kafka 生產者設定先儲存為一個函數閉包,待後續初始化 repo 的時候再初始化生產者使用者端。
經驗豐富的同學可以發現,for 迴圈的 kCfg 變數其實是指向迭代物件的地址,整個迴圈下來所有的函數閉包中用到的 kCfg 都指向 cfg.Mapping 的最後一個迭代值。
解決辦法很簡單,先做一遍變數拷貝即可:
func New(cfg Config) (*Manager, error) {
var newProducers = make(NewProducerFuncs)
for name, kCfg := range cfg.Mapping {
newProducers[name] = func() (kafka.Producer, error) { return kafka.New(kCfg) }
}
// 略
}
這是個挺容易碰到的問題,參考 https://colobu.com/2022/10/04/redefining-for-loop-variable-semantics/
Go 也有可能在未來將回圈變數的語意從 per-loop 改成 per-iteration。
Sarama 使用者端的一點坑
對於重要的紀錄檔資料,我們希望在 HTTP 請求返回時明確反饋是否成功寫入 Kafka 。那麼最好將 Kafka 生產者使用者端設定為同步模式。
而同步模式的生產者要提高吞吐量,批次傳送是必不可少的。
批次傳送的設定位於 sarama.Config.Producer.Flush
cfg := sarama.NewConfig()
// 單次請求中訊息數量的絕對上限
cfg.Producer.Flush.MaxMessages = batchMaxMsgs
// 能夠觸發請求發出的訊息數量閾值
cfg.Producer.Flush.Messages = batchMsgs
// 能夠觸發請求發出的訊息位元組大小閾值
cfg.Producer.Flush.Bytes = batchBytes
// 批次請求的觸發間隔時間
cfg.Producer.Flush.Frequency = batchTimeout
實踐中發現,如果設定了 Flush.Bytes 而沒有設定Flush.Frequency 就存在問題。如果訊息大小始終未達閾值就不會觸發批次請求,故 HTTP 請求就會阻塞直到使用者端請求超時。
所以在設定引數的讀取上,我們把這兩個設定項做了關聯,只有設定了 Flush.Frequency 才能讓 Flush.Bytes 的設定生效。
專案上線
容器平臺上的灰度技巧
原本圖方便我們的路由轉發規則設定的是全部路由直接轉給同一組 Chopper 範例。
前面介紹了,每一個業務對應一個 repo,也就對應一個獨立的請求路徑。如果要灰度新的服務,需要對不同業務單獨灰度,所以我們需要將不同業務的流量去分開。
好在容器平臺的 k8s-ingress 使用的是 APISIX 作為接入閘道器,其路由匹配的優先順序是:絕對匹配 > 字首匹配。
只需要針對特定業務增加一條絕對匹配規則,就可以分離出特定業務的流量。
舉個例子:原本的轉發規則是:/* -> workers-0
我們新建一條轉發規則:/log/repo/cdn-access -> workers-1
workers-0 和 workers-1 兩組服務的設定完全相同。
然後我們對 workers-1 這組服務灰度釋出新版程式。
逐步擴大
每灰度一條路由,我們可以從監控 Dashboard 上觀察 HTTP 請求是否有異常,觀察 Kafka 對應的 topic 的寫入速率是否有異常抖動。
一旦觀測到異常,立即停止灰度,然後檢查程式執行紀錄檔,修正問題後重新開始灰度。
如果無異常,則逐步擴大灰度比例,直到完成服務更新。
總結起來就是灰度、觀測、回退、修改迴圈推進,確保升級對每個業務都無感知。
完成釋出
對比伺服器端資源佔用情況
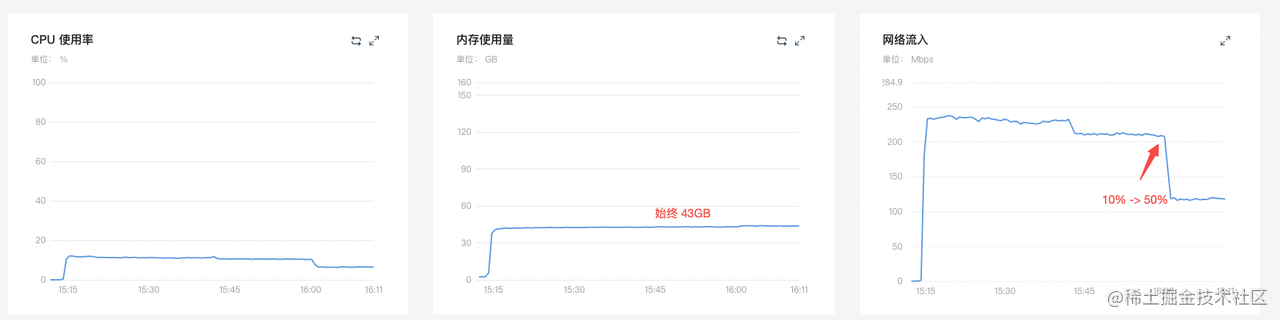
舊版 chopper (4C8G x 20) 灰度比例
10% -> 50%
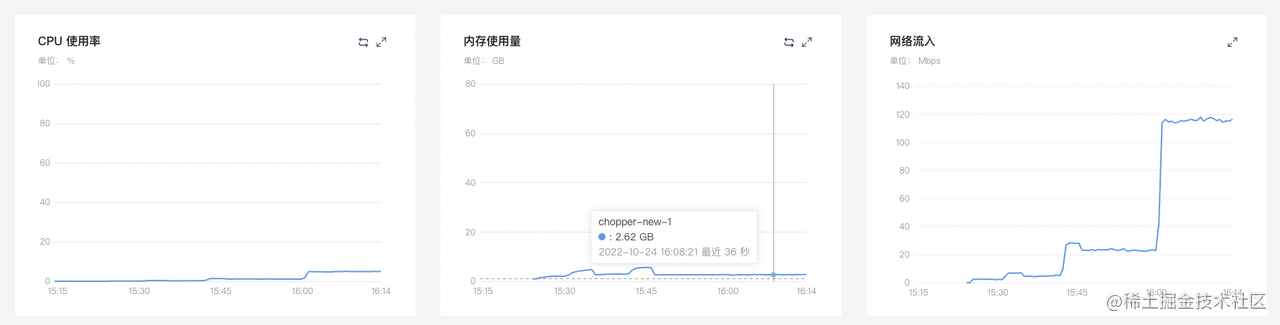
chopper-go (4C4G x 20)
10% -> 50%
50% -> 100%
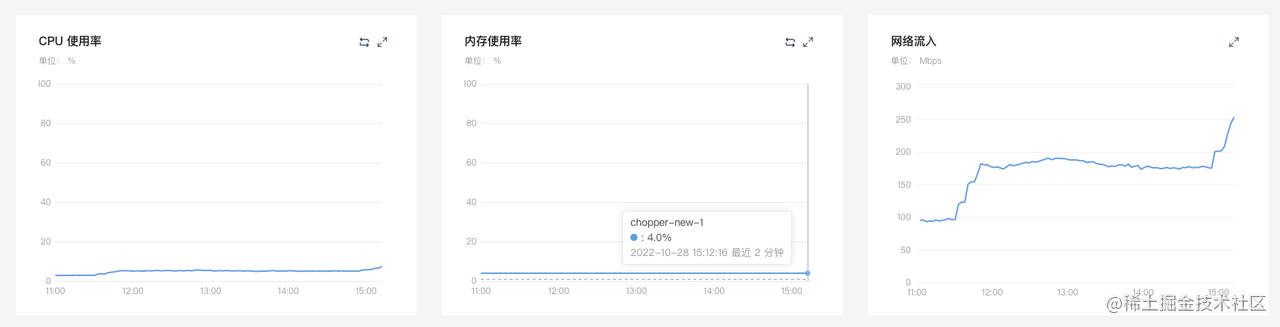
結論:新版紀錄檔閘道器的記憶體和 CPU 的資源使用都有顯著降低。
伺服器端程式的資源佔用情況
舊版 chopper 的 Kafka 使用者端不支援訊息壓縮,chopper-go 釋出中就設定了 Kafka 生產者訊息的功能。壓縮演演算法選擇 lz4 ,觀察兩組消費服務的資源實用率的變化:消費服務0
- 記憶體使用率 27% -> 40%
- 網路流入 253Mbps -> 180Mbps
消費服務1
- 記憶體使用率 28% -> 39%
- 網路流入 380Mbps -> 267Mbps
結論:開啟訊息壓縮功能後,消費範例的記憶體使用率普遍有增長,但內網傳輸頻寬佔用降低約 30%
更新計劃
重構後的流式紀錄檔閘道器,尚有許多可優化空間,例如:
- 採用更節省頻寬的紀錄檔傳輸格式;
- 進一步細化 Kafka topic 的分流粒度;
- 紀錄檔訊息處理階段多級處理執行器之間增加快取提高欄位存取速度等等。
在豐富開源生態的加持下,該專案的優化迭代也將有條不紊地進行。