慢 SQL 優化之索引的作用是什麼?
前言
本文針對 MySQL 資料庫的 InnoDB 儲存引擎,介紹其中索引的實現以及索引在慢 SQL 優化中的作用。
本文主要討論不同場景下索引生效與失效的原因。
慢SQL與索引的關係
慢SQL優化原則
資料庫也是應用,MySQL 作為一種磁碟資料庫,屬於典型的 IO 密集型應用,並且隨機 IO 比順序 IO 更昂貴。
真實的慢 SQL 往往會伴隨著大量的行掃描、臨時檔案排序,直接影響就是磁碟 IO 升高、CPU 使用率升高,正常 SQL 也變為了慢 SQL,對於應用來說就是大面積執行超時。
線上很多事故都與慢 SQL 有關,因此慢 SQL 治理已成為 DBA 與業務研發的共識。
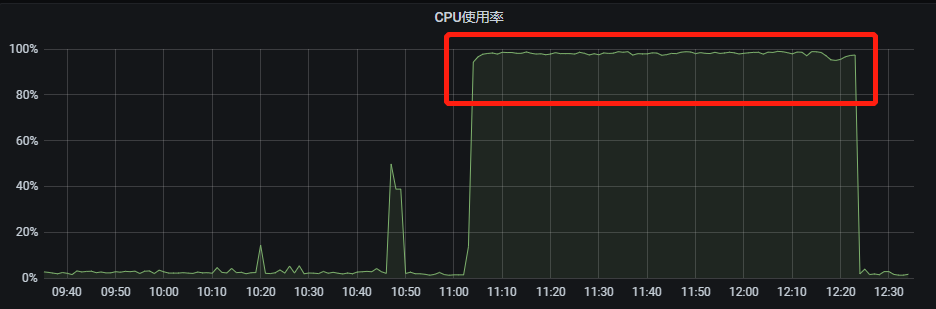
慢SQL的優化原則為:減少資料存取量與減少計算操作
減少存取量:
•建立合適的索引
•減少不必要存取的列
•使用覆蓋索引
•語句改寫
•資料結轉
減少計算操作:
•排序列加入索引
•適當的列冗餘
•SQL 拆分
•計算功能拆分
可以將慢 SQL 優化的方法分為三類:
•查詢優化
•索引優化
•庫表結構優化
其中索引是資料庫中用來提升效能的最常用工具。
可是,為什麼索引可以加快查詢,索引一定可以加快查詢嗎?
索引的作用
要回答這個問題,可以對比沒有索引與有索引時查詢操作的效能差異。
在此之前,首先介紹下查詢操作的處理流程。
查詢操作可以分為以下兩步:
•定位到記錄所在的頁
•從所在的頁中定位到具體的記錄
其中從頁中定位記錄的方法依賴每個頁面中建立的Page Directory(頁目錄),因此關鍵在於如何定位頁。
資料儲存在磁碟上,資料處理髮生在記憶體中,資料頁是磁碟與記憶體之間互動的基本單位,也是 MySQL 管理儲存空間的基本單位,大小預設為 16KB。
因此通常一次最少從磁碟中讀取 16KB 的內容到記憶體中,一次最少把記憶體中的 16KB 內容重新整理到磁碟中。
要理解索引的作用,需要首先明確沒有索引時如何定位頁。
沒有索引時,由於每個頁中的資料沒有規律,因此無法快速定位記錄所在的頁,只能從第一個頁沿雙向連結串列向後遍歷,也就是說需要遍歷所有資料頁依次判斷是否滿足查詢條件。
簡單來說,沒有索引時每次查詢都是全表掃描。
因此索引需要解決的主要問題就是實現每個資料頁中資料有規律,具體是保證下一個資料頁中使用者記錄的索引列值必須大於上一個頁中使用者記錄的索引列值。
索引是儲存引擎用於快速查詢的一種排序的資料結構。
有索引時,優化器首先基於成本自動選擇最優的執行計劃,然後基於索引的有序性可以通過掃描更少的資料頁定位到滿足條件的資料。
具體原因與索引的資料結構有關,下面基於索引的資料結構介紹常見的索引生效與索引失效的場景。
索引
索引的資料結構
索引是一種以空間換時間思想的具體實現,用於加速查詢。
MySQL 中由儲存引擎層實現索引,InnoDB 儲存引擎中基於 B+ 樹實現,因此每個索引都是一棵 B+ 樹。
索參照於組織頁,頁用於組織行記錄。在介紹索引的結構之前首先介紹頁的結構,如下圖所示。
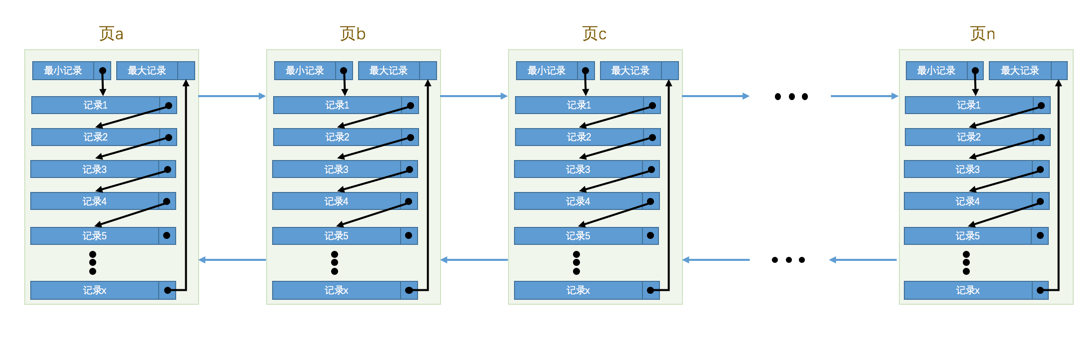
其中:
•每個資料頁中的記錄會按照主鍵值從小到大的順序組成一個單向連結串列,依賴行記錄的Page Header中next_record屬性實現,其中儲存下一條記錄相對於本條記錄的地址偏移量;
•資料頁之間組成一個雙向連結串列,依賴資料頁的File Header中FIL_PAGE_PREV和FIL_PAGE_NEXT屬性實現,其中儲存本頁的上一個和下一個頁的頁號。
多個頁通過樹進行組織,其中儲存使用者資料與目錄項。目錄項中儲存頁的使用者記錄中主鍵的最小值與頁號,從而保證下一個資料頁中使用者記錄的主鍵值大於上一個頁中使用者記錄的主鍵值。
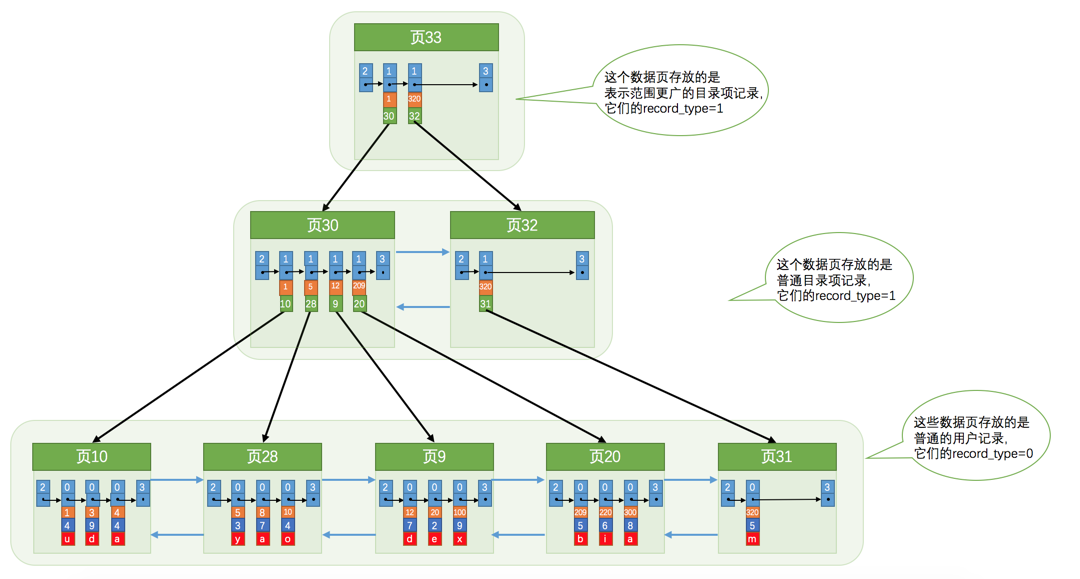
其中:
•使用者資料儲存在葉子節點,目錄項儲存在非葉子節點,每個節點中可能儲存多個頁;
•最上面的節點稱為根節點,根節點的地址儲存在記憶體的資料字典中;
•B+ 樹的深度一般控制在 3 層以內,因此定位到單條記錄不超過 3 次 IO。
因此,頁面和記錄是排好序的,就可以通過二分法來快速定位查詢。
有索引時,查詢操作變成了什麼樣呢?
•從 B+ 樹的根節點出發,一層一層向下搜尋目錄項,由於上層節點儲存的都是下層節點的最小值,因此可以快速定位到資料可能所在的頁;
•如果資料頁在快取池中,直接從記憶體中獲取,否則從磁碟載入到記憶體中;
•資料頁內部二分查詢定位滿足條件的記錄行。
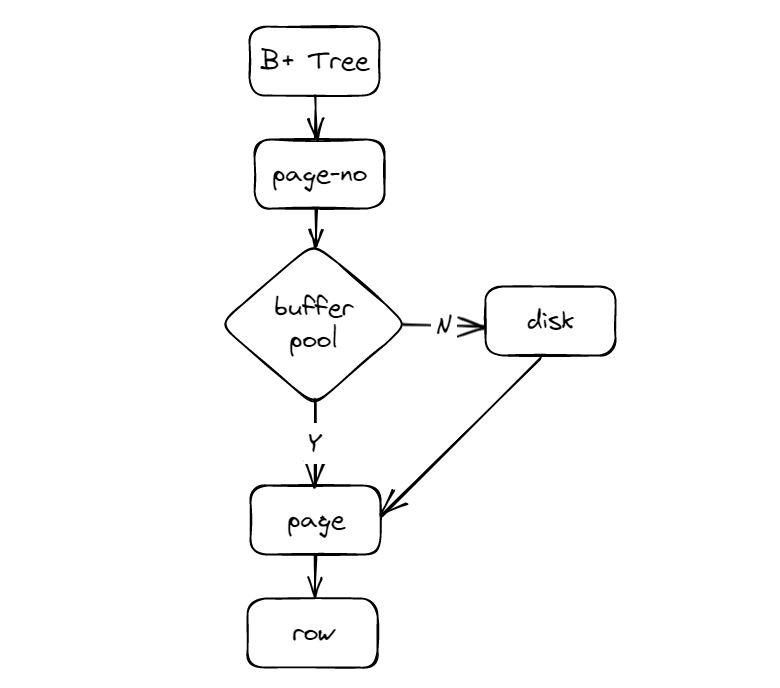
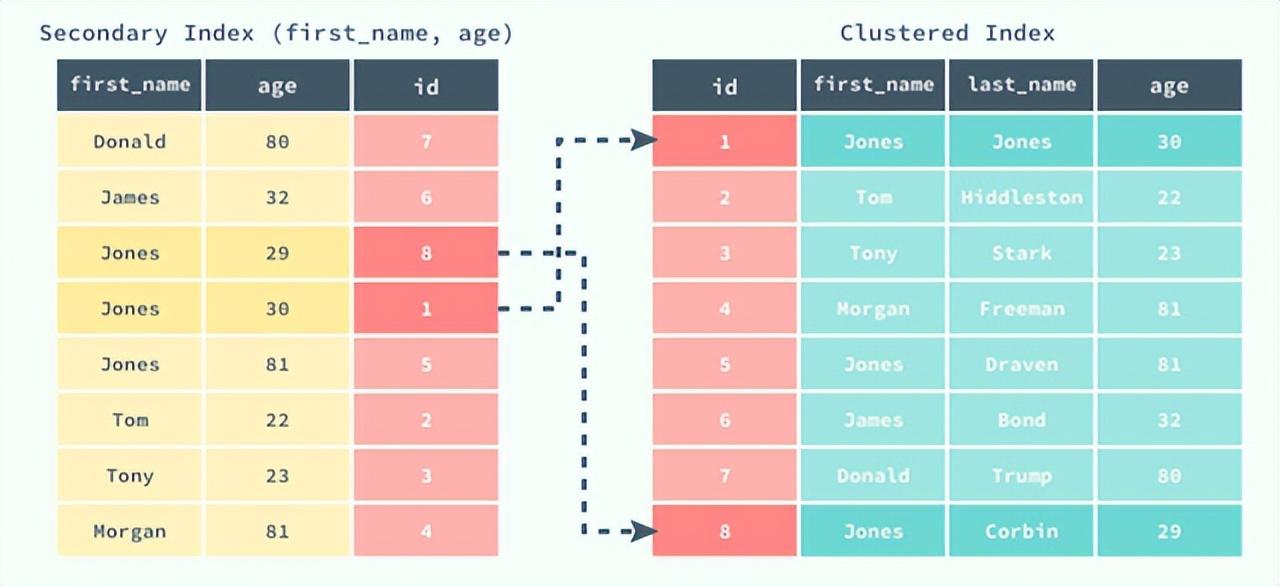
索引儲存的資料
索引中儲存的資料與索引的型別有關。
索引可以分為兩種型別:
•聚簇索引,主鍵索引。葉子節點中儲存主鍵值+對應的完整行記錄,目錄項中儲存主鍵最小值+頁號。InnoDB 屬於索引組織表,每張表都有聚簇索引,因此表必須有主鍵,表中行的物理順序與索引的邏輯順序相同;
•非聚簇索引,二級索引,在非主鍵的其他列上建的索引。葉子節點中儲存索引列的值+對應的主鍵值,目錄項中儲存索引列最小值+對應的主鍵值+頁號。
介紹三個與索引效能相關的概念:
| 概念 | explain.extra |
|---|---|
| 覆蓋索引 | Using index |
| 回表 | Using where |
| 索引下推 | Using index condition |
•覆蓋索引,當二級索引中包含要查詢的所有欄位時,這個索引稱為覆蓋索引;
•回表,當二級索引中不包含要查詢的所有欄位時,就需要先通過二級索引查出主鍵索引,再通過主鍵索引查詢二級索引中沒有的其他列的資料,這個過程叫做回表;
•索引下推,用於優化使用二級索引從表中檢索行的實現。條件過濾可以下推到儲存引擎層進行,先由索引元組(index tuple)根據查詢條件進行過濾,滿足條件的前提下才回表,否則跳過,相當於延遲載入資料行,因此 ICP 可以降低迴表次數與 IO 次數。
正常情況下看不到二級索引中隱藏的主鍵,但實際上,如下所示檢視鎖資訊,顯示LOCK_DATA: '17118168721', 2,其中 2 就是二級索引中儲存的主鍵值。
ENGINE:INNODB
ENGINE_LOCK_ID:140123070938328:14:7:4:140122972537552
ENGINE_TRANSACTION_ID:2032566
THREAD_ID:157
EVENT_ID:44
OBJECT_SCHEMA: test_zk
OBJECT_NAME: t_lock_test
PARTITION_NAME:NULL
SUBPARTITION_NAME:NULL
INDEX_NAME: idx_uk_mobile
OBJECT_INSTANCE_BEGIN:140122972537552
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: GRANTED
LOCK_DATA:'17118168721',2
如下所示,工作中多次遇到研發建立二級索引時顯式指定主鍵,實際上是不需要的,二級索引末尾自動儲存主鍵。
alter table payable_unsettled
add index idx_seller_no_recno_id(seller_no, receipt_no,id) using BTREE;
因此二級索引+主鍵與聯合索引的相同點是依次排序,不同點是索引中儲存的資料不同。
索引生效的場景
等值查詢
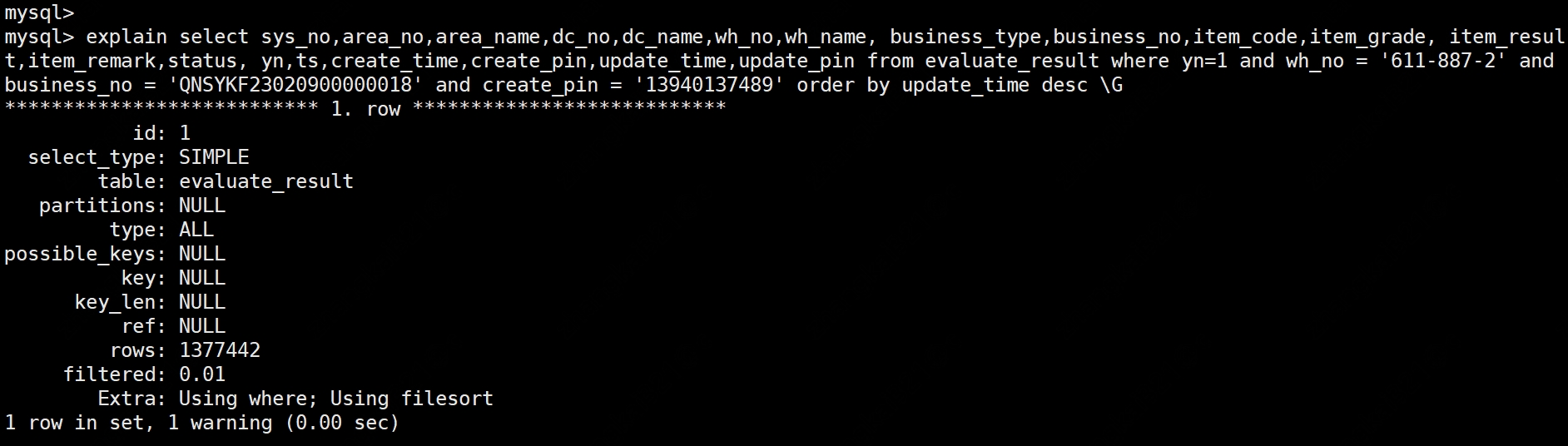
線上環境多次遇到表沒有建立二級索引,只有主鍵索引。
SQL
select sys_no,area_no,area_name,dc_no,dc_name,wh_no,wh_name, business_type,business_no,item_code,item_grade, item_result,item_remark,status, yn,ts,create_time,create_pin,update_time,update_pin
from
evaluate_result
where
yn =1
and wh_no ='611-887-2'
and business_no ='QNSYKF23020900000018'
and create_pin ='13940137489'
orderby
update_time desc;
# 執行用時
5 rows in set(7.311125 sec)
執行計劃,顯示全表掃描
表結構,顯示查詢欄位無索引
mysql>show create table evaluate_result \G
***************************1.row***************************
Table: evaluate_result
CreateTable:CREATE TABLE `evaluate_result`(
`sys_no` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '內部主鍵',
`wh_no` varchar(32) NOT NULL DEFAULT '' COMMENT'倉庫編碼',
`business_no` varchar(20) NOT NULL DEFAULT '' COMMENT'調研業務主鍵',
...
PRIMARY KEY(`sys_no`)
)ENGINE=InnoDB AUTO_INCREMENT=2007412 DEFAULT CHARSET=utf8 COMMENT='評價結果表'
1rowinset(0.00 sec)
優化方法:建立索引
alter table evaluate_result add index idx_wh_bus_no(wh_no,business_no);
執行計劃
***************************1.row***************************
id:1
select_type: SIMPLE
table: evaluate_result
partitions:NULL
type: ref
possible_keys: idx_wh_bus_no
key: idx_wh_bus_no
key_len:160
ref: const,const
rows:5
filtered:1.00
Extra:Using index condition;Using where;Using filesort
1rowinset,1 warning (0.00 sec)
# 執行用時
5 rows in set(0.01 sec)
其中:
•key_len: 160,表明聯合索引的兩個欄位都用到了,(32+20) * 3+2 * 2 = 160。
等值查詢索引生效的原因是相同值的資料組成單向連結串列,因此定位到滿足條件的 5 行資料需要掃描的行數從 1377442 行降低到 5 行。
範圍查詢
SQL
select
id
from
board_chute
where
status=1
and create_time <= date_sub(now(),interval 24 hour);
執行計劃,顯示全表掃描
***************************1.row***************************
id:1
select_type: SIMPLE
table: board_chute
partitions:NULL
type:ALL
possible_keys: idx_create_time
key:NULL
key_len:NULL
ref:NULL
rows:407632
filtered:5.00
Extra:Using where
1rowinset,1 warning (0.00 sec)
查詢欄位有索引,但是索引失效
KEY`idx_create_time`(`create_time`),
status 欄位的區分度
mysql> select status,count(*) from board_chute group by status;
+--------+----------+
| status | count(*) |
+--------+----------+
| 0 | 407317 |
| 1 | 4309 |
+--------+----------+
2 rows in set (0.17 sec)
因此範圍查詢索引失效的原因是檢視資料量大並且需要回表。
優化方法:建立聯合索引實現覆蓋索引
alter table board_chute add index idx_status_create_time(status, create_time);
執行計劃,顯示 Using index 表明用到了覆蓋索引,不需要回表。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: board_chute
partitions: NULL
type: range
possible_keys: idx_create_time,idx_status_create_time
key: idx_status_create_time
key_len: 8
ref: NULL
rows: 203816
filtered: 10.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
範圍查詢索引生效的原因是葉子節點中除了儲存索引,還儲存指向下個節點的指標,因此遍歷葉子節點就可以獲得範圍值。
因此建議使用 between and 代替 in,如select * from T where k in (1,2,3,4,5);對應 5 次樹的搜尋,而select * from T where k between 1 and 5;對應 1 次樹的搜尋。
假設索引基於雜湊表實現,可以通過雜湊函數將 key 值轉換成一個固定的地址,如果發生雜湊碰撞就在這個位置拉出一個連結串列。因此雜湊表的優點是插入操作的速度快,根據 key 直接往後追加即可。但由於雜湊函數的離散特性,經過雜湊函數處理後的 key 將失去原有的順序,所以雜湊表無法滿足範圍查詢,只適合等值查詢。
注意上述索引生效的場景並非絕對成立,需要回表的記錄越多,優化器越傾向於使用全表掃描,反之傾向於使用二級索引 + 回表的方式。
回表查詢成本高有兩點原因:
•需要使用到兩個 B+ 樹索引,一個二級索引,一個聚簇索引;
•存取二級索引使用順序 I/O,存取聚簇索引使用隨機 I/O。
因此有兩條建議:
•建議為區分度高的欄位建立索引,並且將區分度高的欄位優先放在聯合索引前面;
•建議優先使用覆蓋索引,必須要回表時也需要控制回表的記錄數,從而降低索引失效的風險。
索引失效的場景
違反最左匹配原則
SQL
select
count(*)
from
sort_cross_detail
where
yn =1
and org_id =3
and site_type =16
and site_code ='121671';
執行計劃,顯示全表掃描

儘管當前有聯合索引 idx_site_type(SUB_TYPE, THIRD_TYPE, SITE_TYPE ),但由於查詢條件中不包括 SUB_TYPE 欄位,因此違反最左匹配原則,導致索引失效。
當前查詢條件的多個欄位區分度由高到低為 site_code、org_id、site_type。

優化方法:site_code 欄位區分度很高,建立單列索引。
alter table sort_cross_detail add index `idx_site_code` (`SITE_CODE`);
執行計劃
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sort_cross_detail
partitions: NULL
type: ref
possible_keys: idx_site_code
key: idx_site_code
key_len: 99
ref: const
rows: 1336
filtered: 0.10
Extra: Using where
1 row in set, 1 warning (0.00 sec)
其中:
•使用聯合索引過程中可以通過執行計劃中的 key_len 欄位評估具體 SQL 使用到了聯合索引中的幾個欄位;
•聯合索引中頁面和記錄首先按照聯合索引前面的列排序,如果該列值相同,再按照聯合索引後邊的列排序。
違反最左匹配原則導致索引失效的原因是隻有當索引前面的列相同時,後面的列才有序。
下面結合 innodb_ruby 工具解析 InnoDB 資料檔案檢視記錄儲存的順序驗證聯合索引中索引前面的列不同時,後面的列可能無序。
準備測試資料。
mysql> show create table t_index \G
*************************** 1. row ***************************
Table: t_index
Create Table: CREATE TABLE `t_index` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> insert into t_index(age, name) values(8, "Tom"),(8, "David"), (10, "Andy");
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t_index;
+----+------+-------+
| id | age | name |
+----+------+-------+
| 2 | 8 | David |
| 1 | 8 | Tom |
| 3 | 10 | Andy |
+----+------+-------+
3 rows in set (0.00 sec)
mysql> explain select * from t_index \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_index
partitions: NULL
type: index
possible_keys: NULL
key: idx_age_name
key_len: 38
ref: NULL
rows: 3
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
其中:
•insert 時,三條記錄按照 name 欄位逆序;
•select 時,三條記錄按照聯合索引排序,並不是按照主鍵排序。
分別檢視索引以及索引中儲存的資料
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index space-indexes
id name root fseg fseg_id used allocated fill_factor
218 PRIMARY 3 internal 1 1 1 100.00%
218 PRIMARY 3 leaf 2 0 0 0.00%
219 idx_age_name 4 internal 3 1 1 100.00%
219 idx_age_name 4 leaf 4 0 0 0.00%
[root@exps-test3 data]#
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index -p 3 page-records
Record 127: (id=1) → (age=8, name="Tom")
Record 158: (id=2) → (age=8, name="David")
Record 191: (id=3) → (age=10, name="Andy")
[root@exps-test3 data]#
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index -p 4 page-records
Record 145: (age=8, name="David") → (id=2)
Record 127: (age=8, name="Tom") → (id=1)
Record 165: (age=10, name="Andy") → (id=3)
其中:
•主鍵與二級索引的根節點頁號分別是 3 與 4;
•檢視聚簇索引中儲存的記錄,按照主鍵排序;
•檢視二級索引中儲存的記錄,聯合索引中當 age 相同時,name 有序,age 不同時,name 無序。
上面提到,資料字典中儲存表的根節點的地址,具體是 INFORMATION_SCHEMA.INNODB_SYS_INDEXES 系統表的 space 與 page_no 欄位,分別儲存表空間 ID 與根節點頁號。
mysql> SELECT
tables.name, indexs.space, indexs.name, indexs.page_no
FROM
INFORMATION_SCHEMA.INNODB_SYS_TABLES as tables
inner join INFORMATION_SCHEMA.INNODB_SYS_INDEXES as indexs on tables.table_id = indexs.table_id
WHERE
tables.NAME = 'test_zk/t_index';
+-----------------+-------+--------------+---------+
| name | space | name | page_no |
+-----------------+-------+--------------+---------+
| test_zk/t_index | 106 | PRIMARY | 3 |
| test_zk/t_index | 106 | idx_age_name | 4 |
+-----------------+-------+--------------+---------+
2 rows in set (0.00 sec)
其中 test_zk/t_index 表有兩個索引,對應的根節點頁號分別等於 3 與 4,與上面資料檔案解析的結果一致。
order by limit
SQL,不建議使用 select *
select
*
from
waybill_order_added_value_report_detail goodsInfo
WHERE
goodsInfo.is_delete = 0
AND goodsInfo.org_no = '418'
AND goodsInfo.distribute_no = '636'
AND (
goodsInfo.company_code = 'EBU4418046542406'
OR goodsInfo.company_name = 'EBU4418046542406'
)
AND goodsInfo.network_type = 1
AND goodsInfo.should_operator_time >= concat('2022-05-01', ' 00:00:00')
AND goodsInfo.should_operator_time <= concat('2022-05-31', ' 23:59:59')
AND goodsInfo.uniform_status = 0
ORDER BY
goodsInfo.id DESC
LIMIT
0, 20 \G
# 執行用時
2 rows in set (1 min 9.71 sec)
執行計劃,主鍵全索引掃描,聯合索引失效
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: index
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: PRIMARY
key_len: 8
ref: NULL
rows: 16156
Extra: Using where
1 row in set (0.00 sec)
表結構與查詢條件
# 查詢條件
WHERE
goodsInfo.org_no = '418'
AND goodsInfo.distribute_no = '636'
AND goodsInfo.should_operator_time >= concat('2022-05-01', ' 00:00:00')
AND goodsInfo.should_operator_time <= concat('2022-05-31', ' 23:59:59')
# 索引
KEY `idx_org_dc_operator_time` (`org_no`,`distribute_no`,`should_operator_time`),
KEY `idx_operator_time_network` (`should_operator_time`,`network_type`)
將 limit 20 修改為 limit 30,SQL 如下所示。
select
*
from
waybill_order_added_value_report_detail goodsInfo
WHERE
...
ORDER BY
goodsInfo.id DESC
LIMIT
0, 30 \G
# 執行用時
2 rows in set (0.06 sec)
執行計劃顯示當改為 limit 30 時,聯合索引生效。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: range
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: idx_org_dc_operator_time
key_len: 132
ref: NULL
rows: 19024
Extra: Using index condition; Using where; Using filesort
1 row in set (0.00 sec)
可見,索引的選擇與 limit n 的 n 值也有關係。
從現象上看,當 limit n 的 n 值變大時,SQL的執行反倒有可能變快了。
實際上,這是 MySQL 低版本中的 bug #97001,優化器認為排序是個昂貴的操作,因此在執行 order by id limit 這條 SQL 時,為了避免排序,並且認為當 limit n 的 n 很小時,全表掃描可以很快執行完,因此選擇使用全表掃描,以避免額外的排序。
針對 MySQL 中 order by limit 或 group by limit 優化器選擇錯誤索引的場景,常見的優化方法有四種:
•強制索引,通過 hint 固化執行計劃,比如可以通過 force index 指定使用的索引,但是當條件發生變化時有可能失效,因此生產環境中不建議使用;
•prefer_ordering_index,5.7.33 中已修復該 bug,因此建議新申請時使用 5.7.33 及以上版本,存量低版本建議升級,建議優先使用該方法;
•聯合索引,建議在合適的欄位加聯合索引, 增強可選索引的區分度,讓優化器認為這種方式優於有序索引;
•order by (id+0),通過 trick 的方式欺騙優化器,由於 id 上進行了加法這種耗時操作,使優化器認為此時基於全表掃描的會更耗效能,因此選擇基於成本選擇的索引。
優化方法:order by (id+0)
select ...
ORDER BY goodsInfo.id+0 DESC
LIMIT 0, 20\G
執行計劃
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: range
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: idx_org_dc_operator_time
key_len: 132
ref: NULL
rows: 19024
Extra: Using index condition; Using where; Using filesort
1 row in set (0.00 sec)
order by limit 導致索引失效的原因是當查詢欄位與排序欄位不同時,如果使用查詢欄位的索引,排序欄位將無序。優化器認為排序操作昂貴,因此優先使用排序欄位的索引。
隱式轉換
欄位型別不一致或字元集不一致時自動隱式轉換將導致索引失效。
SQL
SELECT
id
FROM
base_operating_report
WHERE
yn = 1
and ec_code = 42
order by
inbound_time desc;
執行計劃,顯示索引失效全表掃描
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: base_operating_report
partitions: NULL
type: ALL
possible_keys: idx_ecCode_transferCode
key: NULL
key_len: NULL
ref: NULL
rows: 36524
filtered: 1.00
Extra: Using where; Using filesort
1 row in set, 3 warnings (0.00 sec)
檢視警告資訊,顯示隱式轉換導致索引失效
mysql> show warnings \G
*************************** 1. row ***************************
Level: Warning
Code: 1739
Message: Cannot use ref access on index 'idx_ecCode_transferCode' due to type or collation conversion on field 'ec_code'
*************************** 2. row ***************************
Level: Warning
Code: 1739
Message: Cannot use range access on index 'idx_ecCode_transferCode' due to type or collation conversion on field 'ec_code'
*************************** 3. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `dms_uat`.`base_operating_report`.`id` AS `id` from `dms_uat`.`base_operating_report` where ((`dms_uat`.`base_operating_report`.`yn` = 1) and (`dms_uat`.`base_operating_report`.`ec_code` = 42)) order by `dms_uat`.`base_operating_report`.`inbound_time` desc
3 rows in set (0.00 sec)
表結構
# 索引資訊
KEY `idx_ecCode_transferCode` (`ec_code`, `transfer_code`)
# 欄位型別
`ec_code` varchar(64) DEFAULT NULL COMMENT '倉庫編碼'
優化方法:將引數中的數值型別轉換成字串
SELECT
id
FROM
base_operating_report
WHERE
yn = 1
and ec_code = '42'
order by
inbound_time desc;
執行計劃,顯示索引生效。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: base_operating_report
partitions: NULL
type: ref
possible_keys: idx_ecCode_transferCode
key: idx_ecCode_transferCode
key_len: 195
ref: const
rows: 443
filtered: 10.00
Extra: Using index condition; Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
隱式轉換導致索引失效的原因是欄位上有函數,而函數並不一定是單調函數,因此會破壞索引本身的有序性。
IN
SQL
select
IFNULL(count(DISTINCT (awi.id)), 0)
from
tc_attorney_waybill_info awi
where
awi.is_delete = 0
and awi.cur_transit_center_code in (
'2008' , '2052' , '2053' , '2054' , '2055' , '2056' , '2057' , '2058' , '2059' , '2061' , '2064' , '2069' , '2079' , '2084' , '2085' , '2094' , '2171' , '2201' , '2202' , '2207' , '2216' , '2258' , '2292' , '2301' , '2311' , '2324' , '2332' , '2334' , '2336' , '2349' , '2354' , '2355' , '2359' , '2367' , '2369' , '2373' , '2381' , '2385'
)
and awi.send_time >= '2022-10-20 00:00:00'
and awi.send_time <= '2022-11-18 23:59:59'
and awi.split_send_package_times > 0
and awi.first_split_type = 1;
# 執行用時
1 rows in set (1.309 sec)
執行計劃,顯示索引失效全表掃描
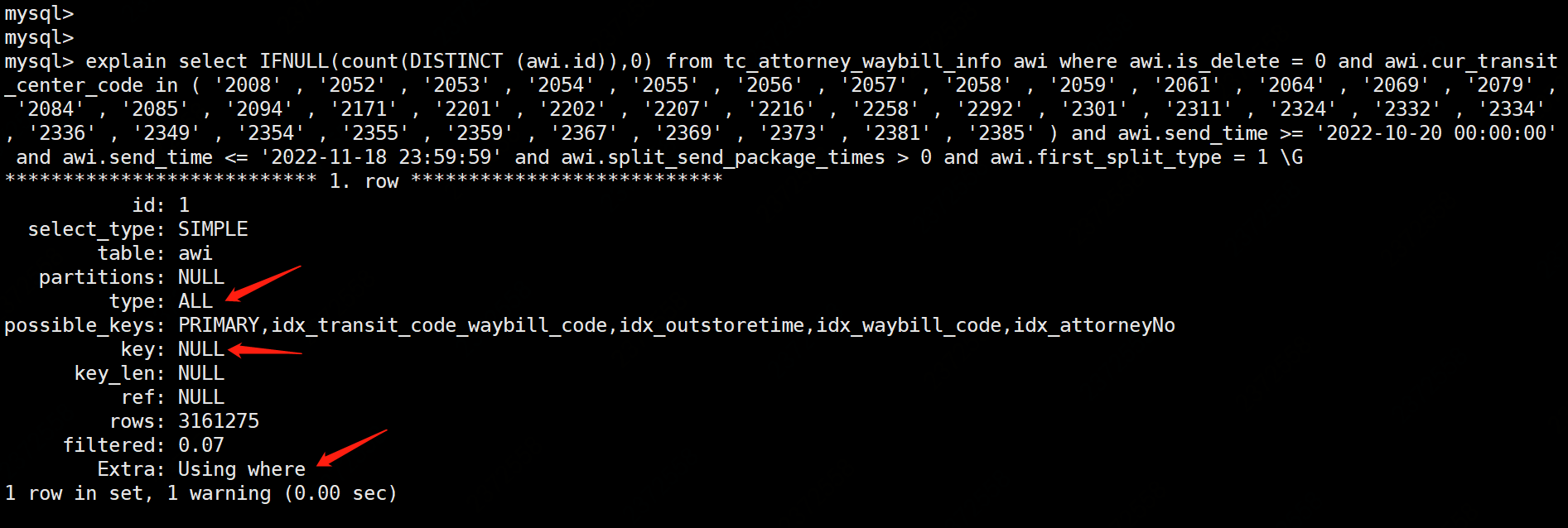
trace,顯示當前的索引中全表掃描的成本最低,因此索引失效。
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_transit_code_waybill_code",
"ranges": [
"2008 <= cur_transit_center_code <= 2008",
"2052 <= cur_transit_center_code <= 2052",
"2053 <= cur_transit_center_code <= 2053",
"2054 <= cur_transit_center_code <= 2054",
"2055 <= cur_transit_center_code <= 2055",
"2056 <= cur_transit_center_code <= 2056",
"2057 <= cur_transit_center_code <= 2057",
"2058 <= cur_transit_center_code <= 2058",
"2059 <= cur_transit_center_code <= 2059",
"2061 <= cur_transit_center_code <= 2061",
"2064 <= cur_transit_center_code <= 2064",
"2069 <= cur_transit_center_code <= 2069",
"2079 <= cur_transit_center_code <= 2079",
"2084 <= cur_transit_center_code <= 2084",
"2085 <= cur_transit_center_code <= 2085",
"2094 <= cur_transit_center_code <= 2094",
"2171 <= cur_transit_center_code <= 2171",
"2201 <= cur_transit_center_code <= 2201",
"2202 <= cur_transit_center_code <= 2202",
"2207 <= cur_transit_center_code <= 2207",
"2216 <= cur_transit_center_code <= 2216",
"2258 <= cur_transit_center_code <= 2258",
"2292 <= cur_transit_center_code <= 2292",
"2301 <= cur_transit_center_code <= 2301",
"2311 <= cur_transit_center_code <= 2311",
"2324 <= cur_transit_center_code <= 2324",
"2332 <= cur_transit_center_code <= 2332",
"2334 <= cur_transit_center_code <= 2334",
"2336 <= cur_transit_center_code <= 2336",
"2349 <= cur_transit_center_code <= 2349",
"2354 <= cur_transit_center_code <= 2354",
"2355 <= cur_transit_center_code <= 2355",
"2359 <= cur_transit_center_code <= 2359",
"2367 <= cur_transit_center_code <= 2367",
"2369 <= cur_transit_center_code <= 2369",
"2373 <= cur_transit_center_code <= 2373",
"2381 <= cur_transit_center_code <= 2381",
"2385 <= cur_transit_center_code <= 2385"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1328061,
"cost": 1.59e6,
"chosen": false,
"cause": "cost"
},
{
"index": "idx_outstoretime",
"ranges": [
"0x99ae280000 <= send_time <= 0x99ae657efb"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1597295,
"cost": 1.92e6,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`tc_attorney_waybill_info` `awi`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 3194590,
"access_type": "scan",
"resulting_rows": 3.19e6,
"cost": 677027,
"chosen": true
}
]
},
優化方法:
•建立一個更多查詢欄位的聯合索引,減少回表次數;
•縮小查詢的時間範圍,因為查詢的資料量比較大,而且用到的欄位比較多,導致回表成本高。
IN 導致索引失效的原因是符合條件的資料量過大導致回表成本高於全表掃描。
分組欄位無索引
提數,建立唯一鍵之前分組查詢是否有重複資料。
SQL
select
operate_id,
waybill_code,
private_call_id
from
tos_resource.courier_call_out_record_0
group by
operate_id,
waybill_code,
private_call_id
having
count(*) > 1;
執行計劃,顯示全表掃描
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: courier_call_out_record_0
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1470107
filtered: 100.00
Extra: Using temporary; Using filesort
1 row in set, 1 warning (0.01 sec)
分組欄位無聯合索引,有兩個索引覆蓋三個分組欄位,因此索引無法使用。
KEY `courier_call_out_record_0_operate_id_IDX` (`operate_id`,`waybill_code`),
KEY `courier_call_out_recourd_0_waybill_code` (`waybill_code`)
優化方法:給分組欄位建立聯合索引
alter table courier_call_out_record_0
add index `courier_call_out_record_0_composite_key` (`operate_id`,`waybill_code`,`private_call_id`);
執行計劃
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: courier_call_out_record_0
partitions: NULL
type: index
possible_keys: courier_call_out_record_0_composite_key
key: courier_call_out_record_0_composite_key
key_len: 907
ref: NULL
rows: 2230391
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
分組欄位無聯合索引導致全表掃描的原因是分組時需要先排序,因此只有當分組欄位在同一個索引中時才可以保證有序。
索引的優缺點
索引的代價
通過以上分析可以發現索引不是萬能的,實際上有時候索引甚至會有副作用。
建立索引的代價可以分為兩類:
•空間代價,索引需要佔用磁碟空間,並且刪除索引並不會立即釋放空間,因此無法通過刪除索引的方式降低磁碟使用率;
•時間代價,有的時候會發現建立索引後導致寫入變慢,原因是每次資料寫入後還需要對該記錄按照索引排序。因此經常更新的列不建議建立索引。
可見,索引的優點是可以加快查詢速度,缺點是佔用記憶體與磁碟空間,同時減慢了插入與更新操作的速度。
因此,B+ Tree 適用於讀多寫少的業務場景,相對應的 LSM-Tree 適用於寫多讀少的業務場景,原因是每次資料寫入對應一條紀錄檔追加寫入磁碟檔案,用順序 IO 代替了隨機 IO。
索引使用的建議
關於索引的使用有以下幾點建議:
•建議給區分度高的欄位建立索引;
•建議刪除冗餘索引,否則優化器可能使用 index_merge 導致選擇到錯誤的索引;
•不建議使用強制索引,比如當資料量或統計資訊發生變化時,強制索引不一定最優。
下面測試下與索引相關的兩個操作:
•如果 SQL 中強制指定已刪除的索引,SQL 執行會報錯嗎?
•如果刪除欄位,索引也會自動刪除嗎?
準備資料
mysql> create table t_index_drop like t_index;
Query OK, 0 rows affected (0.02 sec)
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
如果 SQL 中強制指定已刪除的索引,SQL 將直接報錯,生產環境中遇到過相關案例。
mysql> alter table t_index_drop drop index idx_age_name;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from t_index_drop force index(idx_age_name);
ERROR 1176 (42000): Key 'idx_age_name' doesn't exist in table 't_index_drop'
如果刪除欄位,索引也會自動刪除。
mysql> alter table t_index_drop add index idx_age(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> alter table t_index_drop drop column age;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
基於優化器選擇索引有可能選錯索引導致效能下降,而使用強制索引可能導致 SQL 執行直接報錯。
結論
慢SQL的優化原則是減少資料存取量與減少計算操作,其中索引是資料庫中用來提升效能的最常用工具。
索引是一種用於快速查詢的一種排序的資料結構,基於以空間換時間的思想實現。
MySQL 中由儲存引擎層實現索引,InnoDB 儲存引擎中基於 B+ 樹實現,因此每個索引都是一棵 B+ 樹。
索參照於組織頁,頁用於組織行記錄。
其中:
•每個資料頁中的記錄會按照主鍵值從小到大的順序組成一個單向連結串列,依賴行記錄的Page Header中next_record屬性實現,其中儲存下一條記錄相對於本條記錄的地址偏移量;
•資料頁之間組成一個雙向連結串列,依賴資料頁的File Header中FIL_PAGE_PREV和FIL_PAGE_NEXT屬性實現,其中儲存本頁的上一個和下一個頁的頁號。
查詢操作可以分為以下兩步:
•定位到記錄所在的頁
•從所在的頁中定位到具體的記錄
對比沒有索引與有索引時查詢操作的效能差異:
•沒有索引時每次查詢都是全表掃描;
•有索引時從 B+ 樹的根節點出發,一層一層向下搜尋目錄項,由於上層節點儲存的都是下層節點的最小值,因此可以快速定位到資料可能所在的頁。
關於索引失效的場景總結以下兩點:
•索引的本質是有序的資料結構,因此破壞索引有序性的操作都有可能導致索引失效或部分生效;
•回表成本較高,因此優先使用覆蓋索引,必須要回表時也需要控制回表的記錄數,從而降低索引失效的風險。
參考教學
•《MySQL 是怎樣執行的:從根兒上理解 MySQL》
•MySQL工具之innodb_ruby:探究InnoDB儲存結構的利器
•你管這破玩意叫B+樹?
作者:京東物流 張凱
來源:京東雲開發者社群