南洋才女,德藝雙馨,孫燕姿本尊迴應AI孫燕姿(基於Sadtalker/Python3.10)
孫燕姿果然不愧是孫燕姿,不愧為南洋理工大學的高材生,近日她在個人官方媒體部落格上寫了一篇英文版的長文,正式迴應現在滿城風雨的「AI孫燕姿」現象,流行天后展示了超人一等的智識水平,行文優美,綿恆雋永,對AIGC藝術表現得極其剋制,又相當寬容,充滿了語言上的古典之美,表現出了「任彼如泰山壓頂,我只當清風拂面」的博大胸懷。
本次我們利用edge-tts和Sadtalker庫讓AI孫燕姿朗誦本尊的博文,讓流行天后念給你聽。
Sadtalker設定
之前我們曾經使用百度開源的PaddleGAN視覺效果模型中一個子模組Wav2lip實現了人物口型與輸入的歌詞語音同步,但Wav2lip的問題是虛擬人物的動態效果只能侷限在嘴脣附近,事實上,音訊和不同面部動作之間的連線是不同的,也就是說,雖然嘴脣運動與音訊的聯絡最強,但可以通過不同的頭部姿勢和眨眼來反作用於音訊。
和Wav2lip相比,SadTaker是一種通過隱式3D係數調變的風格化音訊驅動Talking頭部視訊生成的庫,一方面,它從音訊中生成逼真的運動係數(例如,頭部姿勢、嘴脣運動和眨眼),並單獨學習每個運動以減少不確定性。對於表達,通過從的僅嘴脣運動係數和重建的渲染三維人臉上的感知損失(脣讀損失,面部landmark loss)中提取係數,設計了一種新的音訊到表達係數網路。
對於程式化的頭部姿勢,通過學習給定姿勢的殘差,使用條件VAE來對多樣性和逼真的頭部運動進行建模。在生成逼真的3DMM係數後,通過一種新穎的3D感知人臉渲染來驅動源影象。並且通過源和驅動的無監督3D關鍵點生成扭曲場,並扭曲參考影象以生成最終視訊。
Sadtalker可以單獨設定,也可以作為Stable-Diffusion-Webui的外掛而存在,這裡推薦使用Stable-Diffusion外掛的形式,因為這樣Stable-Diffusion和Sadtalker可以共用一套WebUI的介面,更方便將Stable-Diffusion生成的圖片做成動態效果。
進入到Stable-Diffusion的專案目錄:
cd stable-diffusion-webui
啟動服務:
python3.10 webui.py
程式返回:
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Version: v1.3.0
Commit hash: 20ae71faa8ef035c31aa3a410b707d792c8203a3
Installing requirements
Launching Web UI with arguments: --xformers --opt-sdp-attention --api --lowvram
Loading weights [b4d453442a] from D:\work\stable-diffusion-webui\models\Stable-diffusion\protogenV22Anime_protogenV22.safetensors
load Sadtalker Checkpoints from D:\work\stable-diffusion-webui\extensions\SadTalker\checkpoints
Creating model from config: D:\work\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Running on local URL: http://127.0.0.1:7860
代表啟動成功,隨後http://localhost:7860
選擇外掛(Extensions)索引標籤
點選從url安裝,輸入外掛地址:github.com/Winfredy/SadTalker
安裝成功後,重啟WebUI介面。
接著需要手動下載相關的模型檔案:
https://pan.baidu.com/s/1nXuVNd0exUl37ISwWqbFGA?pwd=sadt
隨後將模型檔案放入專案的stable-diffusion-webui/extensions/SadTalker/checkpoints/目錄即可。
接著設定一下模型目錄的環境變數:
set SADTALKER_CHECKPOINTS=D:/stable-diffusion-webui/extensions/SadTalker/checkpoints/
至此,SadTalker就設定好了。
edge-tts音訊轉錄
之前的歌曲復刻是通過So-vits庫對原歌曲的音色進行替換和預測,也就是說需要原版的歌曲作為基礎資料。但目前的場景顯然有別於歌曲替換,我們首先需要將文字轉換為語音,才能替換音色。
這裡使用edge-tts庫進行文字轉語音操作:
import asyncio
import edge_tts
TEXT = '''
As my AI voice takes on a life of its own while I despair over my overhanging stomach and my children's every damn thing, I can't help but want to write something about it.
My fans have officially switched sides and accepted that I am indeed 冷門歌手 while my AI persona is the current hot property. I mean really, how do you fight with someone who is putting out new albums in the time span of minutes.
Whether it is ChatGPT or AI or whatever name you want to call it, this "thing" is now capable of mimicking and/or conjuring, unique and complicated content by processing a gazillion chunks of information while piecing and putting together in a most coherent manner the task being asked at hand. Wait a minute, isn't that what humans do? The very task that we have always convinced ourselves; that the formation of thought or opinion is not replicable by robots, the very idea that this is beyond their league, is now the looming thing that will threaten thousands of human conjured jobs. Legal, medical, accountancy, and currently, singing a song.
You will protest, well I can tell the difference, there is no emotion or variance in tone/breath or whatever technical jargon you can come up with. Sorry to say, I suspect that this would be a very short term response.
Ironically, in no time at all, no human will be able to rise above that. No human will be able to have access to this amount of information AND make the right calls OR make the right mistakes (ok mayyyybe I'm jumping ahead). This new technology will be able to churn out what exactly EVERYTHING EVERYONE needs. As indie or as warped or as psychotic as you can get, there's probably a unique content that could be created just for you. You are not special you are already predictable and also unfortunately malleable.
At this point, I feel like a popcorn eater with the best seat in the theatre. (Sidenote: Quite possibly in this case no tech is able to predict what it's like to be me, except when this is published then ok it's free for all). It's like watching that movie that changed alot of our lives Everything Everywhere All At Once, except in this case, I don't think it will be the idea of love that will save the day.
In this boundless sea of existence, where anything is possible, where nothing matters, I think it will be purity of thought, that being exactly who you are will be enough.
With this I fare thee well.
'''
VOICE = "en-HK-YanNeural"
OUTPUT_FILE = "./test_en1.mp3"
async def _main() -> None:
communicate = edge_tts.Communicate(TEXT, VOICE)
await communicate.save(OUTPUT_FILE)
if __name__ == "__main__":
asyncio.run(_main())
音訊使用英文版本的女聲:en-HK-YanNeural,關於edge-tts,請移步:口播神器,基於Edge,微軟TTS(text-to-speech)文字轉語音免費開源庫edge-tts語音合成實踐(Python3.10),這裡不再贅述。
隨後再將音訊檔的音色替換為AI孫燕姿的音色即可:AI天后,線上飆歌,人工智慧AI孫燕姿模型應用實踐,復刻《遙遠的歌》,原唱晴子(Python3.10)。
本地推理和爆視訊記憶體問題
準備好生成的圖片以及音訊檔後,就可以在本地進行推理操作了,存取 localhost:7860
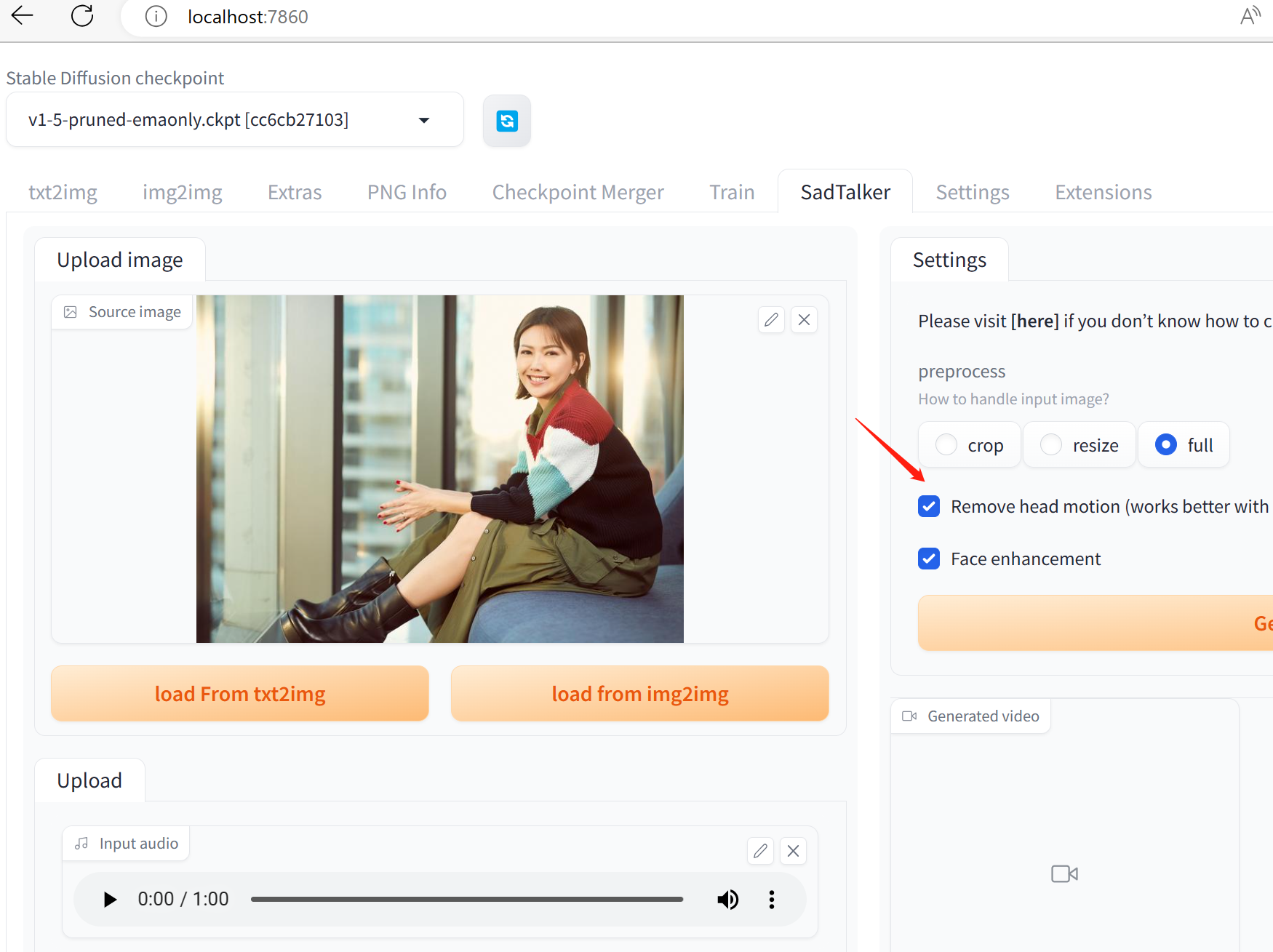
這裡輸入引數選擇full,如此會保留整個圖片區域,否則只保留頭部部分。
生成效果:

SadTalker會根據音訊檔生成對應的口型和表情。
這裡需要注意的是,音訊檔只支援MP3或者wav。
除此以外,推理過程中Pytorch庫可能會報這個錯誤:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 6.00 GiB total capacity; 5.38 GiB already allocated; 0 bytes free; 5.38 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
這就是所謂的"爆視訊記憶體問題"。
一般情況下,是因為當前GPU的視訊記憶體不夠了所導致的,可以考慮縮小torch分片檔案的體積:
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:60
如果音訊檔實在過大,也可以通過ffmpeg對音訊檔切片操作,分多次進行推理:
ffmpeg -ss 00:00:00 -i test_en.wav -to 00:30:00 -c copy test_en_01.wav
藉此,就解決了推理過程中的爆視訊記憶體問題。
結語
和Wav2Lip相比,SadTalker(Stylized Audio-Driven Talking-head)提供了更加細微的面部運動細節(如眼睛眨動)等等,可謂是細緻入微,鉅細靡遺,當然隨之而來的是模型數量和推理成本以及推理時間的增加,但顯然,這些都是值得的。