你沒見過的分庫分表原理解析和解決方案(一)
你沒見過的分庫分表原理解析和解決方案(一)
高並行三駕馬車:分庫分表、MQ、快取。今天給大家帶來的就是分庫分表的乾貨解決方案,哪怕你不用我的框架也可以從中聽到不一樣的結局方案和實現。
一款支援自動分表分庫的orm框架easy-query 幫助您解脫跨庫帶來的複雜業務程式碼,並且提供多種結局方案和自定義路由來實現比中介軟體更高效能的資料庫存取。
上篇文章簡單的帶大家瞭解了框架如何使用分片本章將會以理論為主加實踐的方式呈現不一樣的分表分庫。
介紹
分庫分表一直是老生常談的問題,市面上也有很多人侃侃而談,但是大部分的說辭都是一樣,甚至給不出一個實際的解決方案,本人經過多年的深耕在其他語言裡面多年的維護和實踐下來秉著happy coding的原則希望更多的人可以瞭解和認識到該框架並且給大家一個全新的針對分庫分表的認識。
我們也經常戲稱專案一開始就用了分庫分表結果上線沒多少資料,並且整個開發體驗來說非常繁瑣,對於業務而言也是極其不友好,大大拉長開發週期不說,bug也是更加容易產生,針對上述問題該框架給出了一個非常完美的實現來極大程度上的給使用者完美的體驗
分片儲存
分庫分表簡單的實現目前大部分框架已經都可以實現了,就是動態表名來實現分表下的簡單儲存,如果是分庫下面的那麼就使用動態資料來源來切換實現,如果是分庫加分表就用動態資料來源加動態表名來實現,聽上去是不是很完美,但是實際情況下你需要表寫非常繁多的業務程式碼,並且會讓整個開發精力全部集中在分庫分表下,針對後期的維護也是非常麻煩的一件事。
但是分庫分表的分片規則又是和具體業務耦合的所以合理的解耦分片路由是一件非常重要的事情。
插入
假設我們按訂單id進行分表儲存
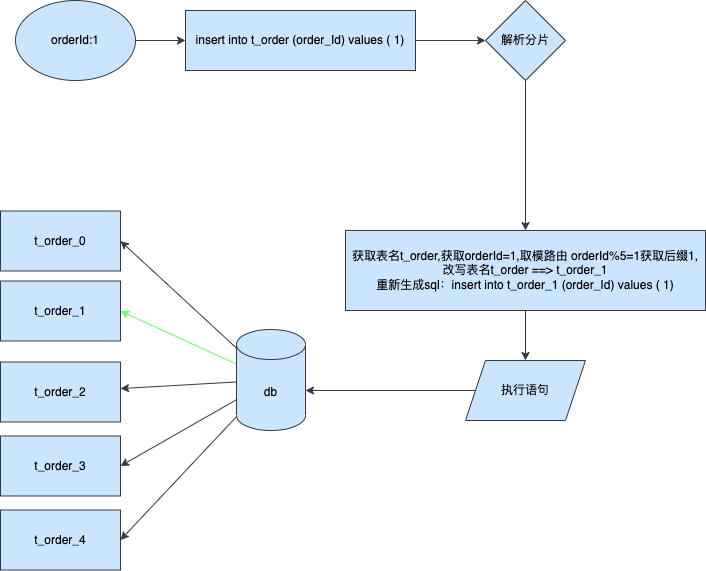
通過上述圖片我們可以很清晰的瞭解到分片插入的執行原理,通過攔截執行sql分析對應的值計算出所屬表名,然後改寫表名進行插入。該實現方法有一個弊端就是如果插入資料是increment的自增型別,那麼這種方法將不適合,因為自增主鍵只有在插入資料庫後才會正真的被確定是什麼值,可以通過攔截器設定自定義自增撥號器來實現偽自增,這樣也可以實現「自增」列。
更新刪除)
這邊假設我們也是按照訂單id進行分表更新
更新分片鍵
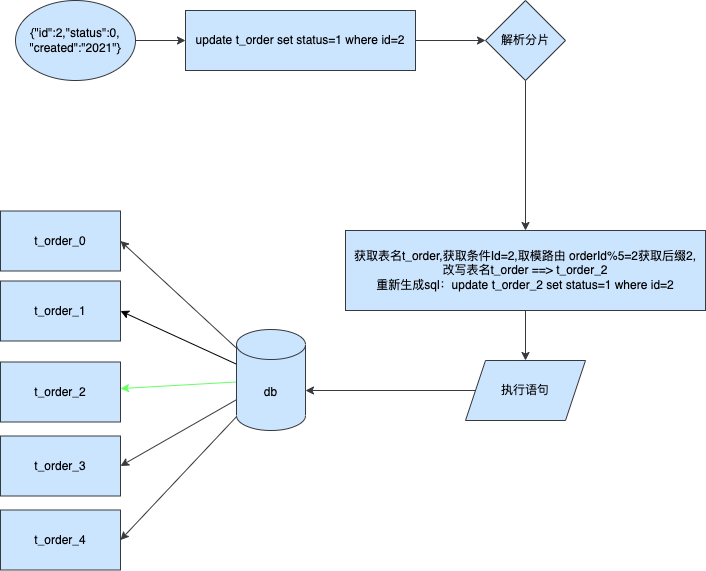
一模一樣的處理,將sql進行攔截後解析where和分片欄位id然後計算後將結果傳送到對應路由的表中進行執行。
那麼如果我們沒辦法進行路由確定呢,如果我們使用created欄位來更新的那麼會發生生呢
更新非分片鍵
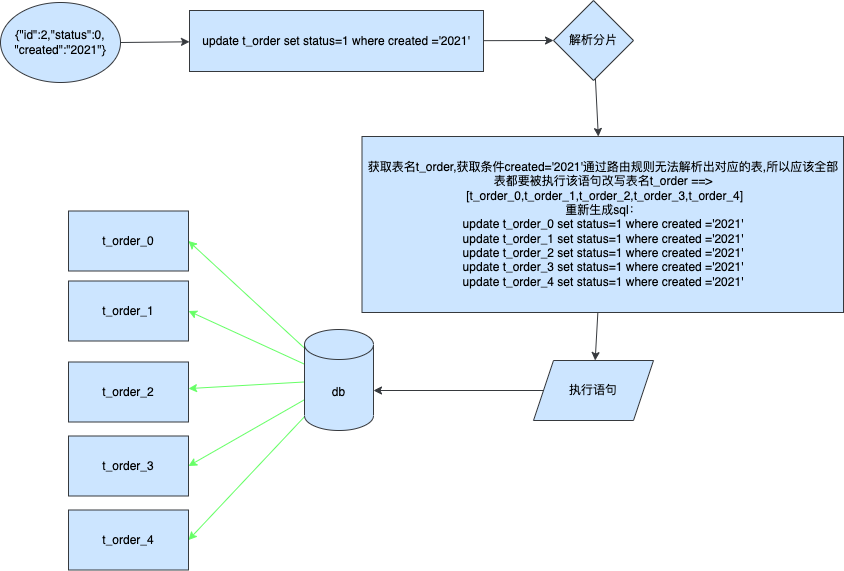
為了得到正確的結果需要將每條sql進行改寫分別傳送到對應的表中,然後將各自表的執行結果進行聚合返回最終受影響行數
分片查詢
眾所周知分庫分表的難點並不在如何儲存資料到對應的db,也不在於如何更新指定實體資料,因為他們都可以通過分片鍵的計算來重新路由,可以讓分片的操作降為單表操作,所以orm只需要支援動態表名那麼以上所有功能都是支援的,
但是實際情況缺是如果orm或者中介軟體只支援到了這個級別那麼對於稍微複雜一點的業務你必須要編寫大量的業務程式碼來實現業務需要的查詢,並且會浪費大量的重複工作和精力
單分片表查詢
加下來我來講解單分片表查詢,其實原理和上面的insert一樣
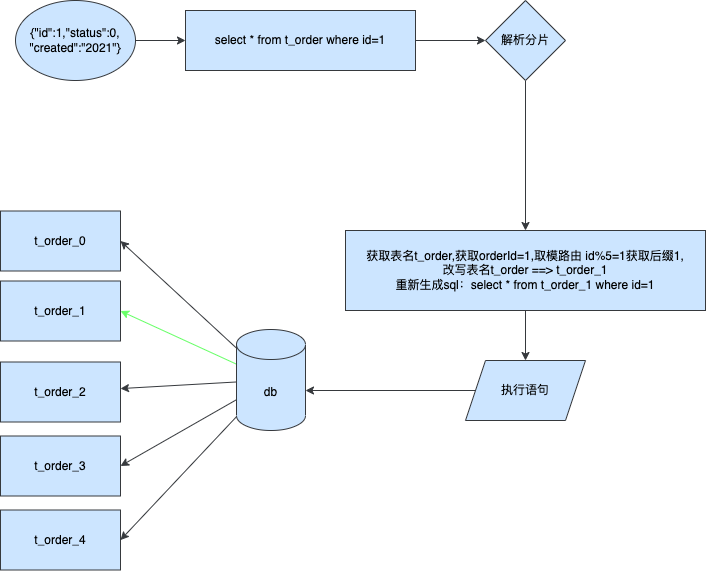
到這裡為止其實都是ok的並沒有什麼問題.但是如果我們的本次查詢需要跨分片呢比如跨兩個分片那麼應該如何處理
跨分片表查詢
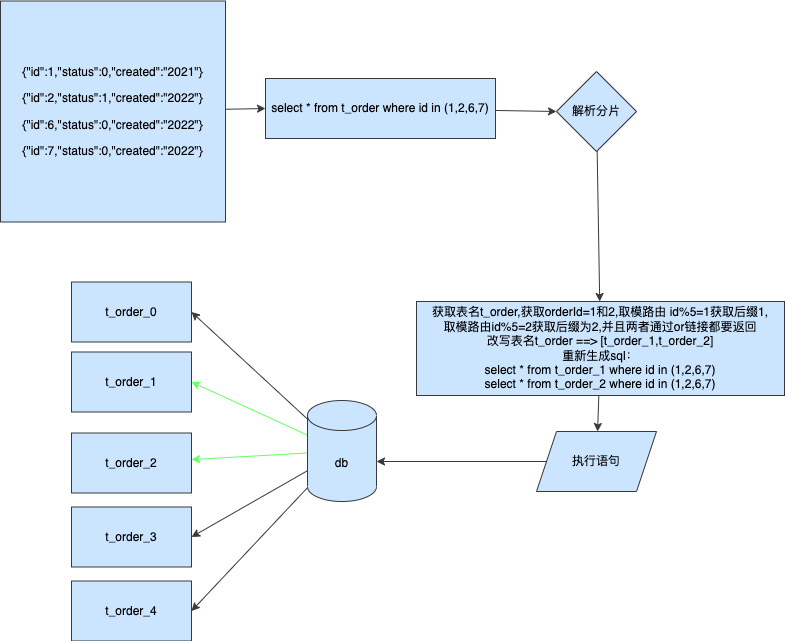
到這一步我們已經將對應的資料路由到對應的資料庫了,那麼我們應該如何獲取自己想要的結果呢
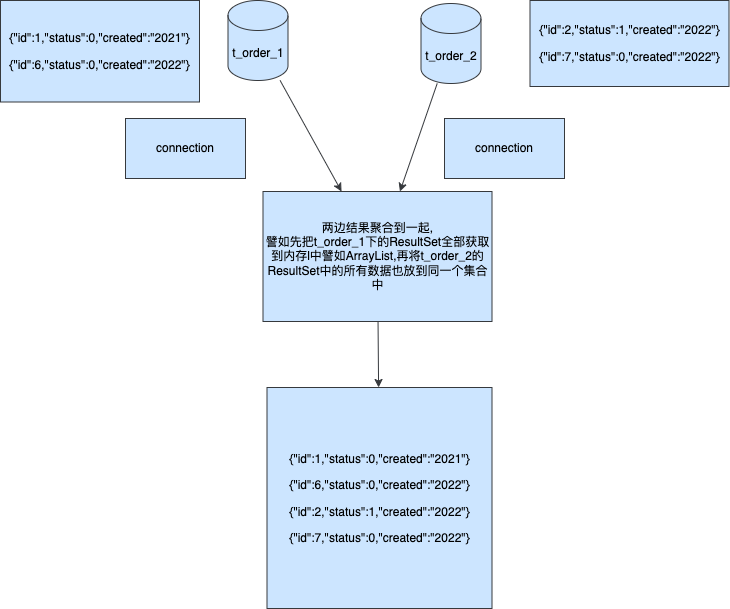
通過上圖我們可以瞭解到在跨分片的聚合下我們可以分表通過對a,b兩張表進行查詢可以並行可以序列,最終將結果匯聚到同一個集合那麼返回給使用者端就是一個完整的封包,並沒有缺少任何資料
跨分片排序
基於上述分片聚合方式我們清晰的瞭解到如何可以進行跨分片下降資料獲取到記憶體中,但是通過圖中結果可以清晰的瞭解到返回的資料並不像我們預期的那樣有序,那是因為各個節點下的所有資料都是僅遵循各自節點的資料庫排序而不受其他節點分片影響。
那麼如果我們對資料進行分片聚合+排序那麼又會是什麼樣的場景呢
方案一記憶體排序
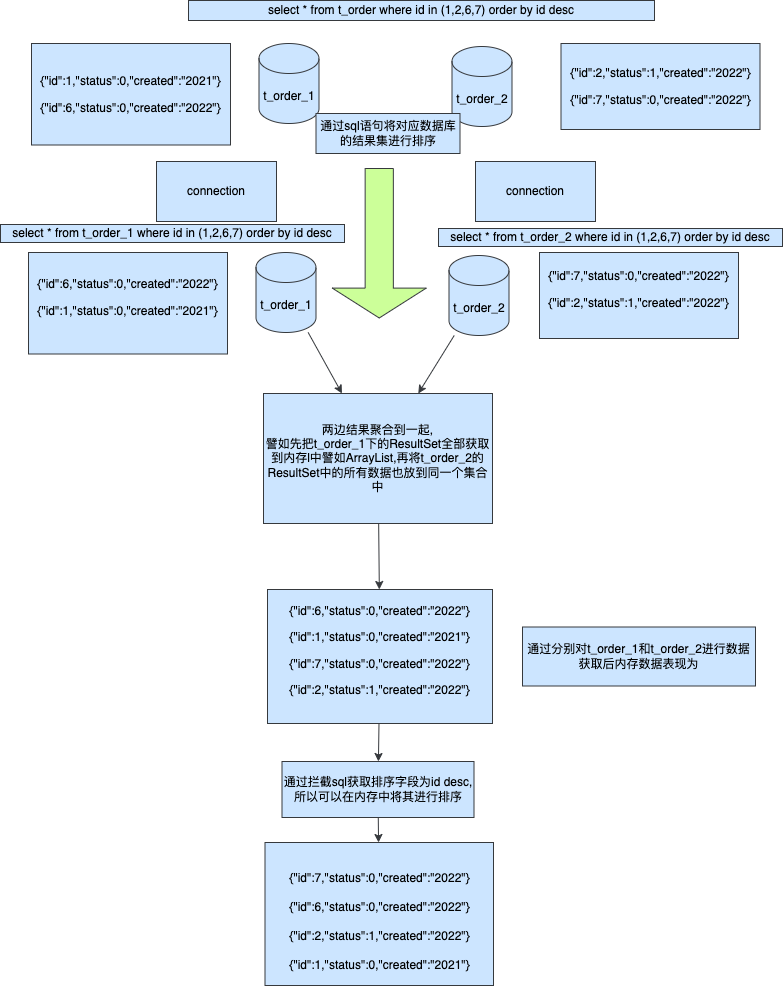
首先我們將執行sql分別路由到t_order_1和t_order_2兩張表,並且執行order by id desc將其資料id大的排在前面這樣可以保證單個Connection的ResultSet肯定是大的先被返回
所以在單個Connection下結果是正確的但是因為多個分片節點間沒有互動所以當取到記憶體中後資料依然是亂的,所以這邊需要對sql進行攔截獲取排序欄位並且將其在記憶體中的集合裡面實現,這樣我們就做到了和排序欄位一樣的返回結果
方案二流式排序
大部分orm到這邊就為止了,畢竟已經實現了完美的節點處理,但是我們來看他需要消耗的效能事多少,假設我們分片命中2個節點,每個節點各自返回2條資料,我們對於整個ResultSet的遍歷將是每個連結都是2那麼就是4次,然後在記憶體中在進行排序如果效能差一點還需要多次所以這個是相對比較浪費效能的,因為如果我們有1000條資料返回那麼記憶體中的排序是很高效的但是這個也是我們這次需要講解的更加高效的排序處理流式排序
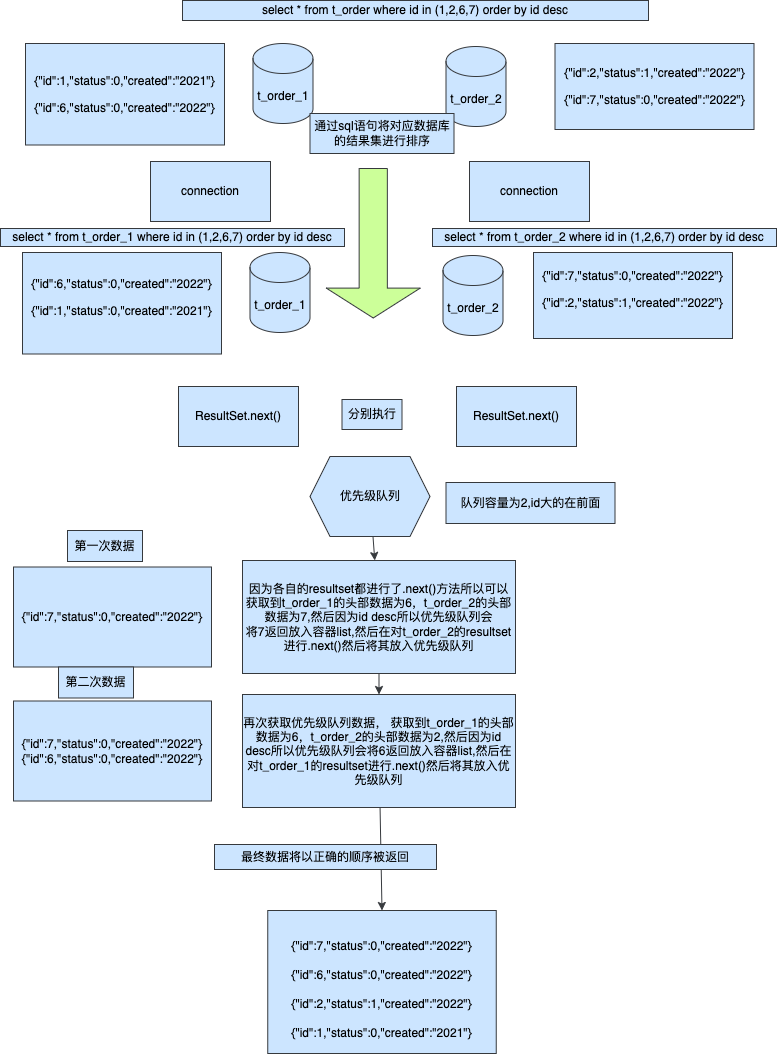
相較於記憶體排序這種方式十分複雜並且繁瑣,而且對於使用者也很不好理解,但是如果你獲取的資料是分頁,那麼記憶體排序進行獲取結果將會變得非常危險,有可能導致記憶體資料過大從而導致程式崩潰
無order欄位
到這邊不要以為跨分片聚合已經結束了因為當你的sql查詢order by了一個select不存在的欄位,那麼上述兩種排序方式都將無法使用,因為程式獲取到的結果集並沒有排序欄位,這個時候一般我們會改寫sql讓其select的時候必須要帶上對應的order by欄位這樣就可以保證我們資料的正確返回
以下兩個問題因為涉及到過多內容本章節無法呈現所以將會在下一章給出具體解決方案
跨分片分組
如果我們程式遇到了這個那麼我們該如何處理呢
跨分片分頁
業務中常常需要的跨分片分頁我們該如何解決,easy-query又如何處理這種情況,如果跨的分片過多我們又該怎麼辦,
- 如何解決深分頁問題
- 如何解決流式瀑布問題
- 如何進行分頁快取高效獲取問題
接下來將在下篇文章中一一解答近
最後
我這邊將演示easy-query在本次分片理論中的實際應用
這次採用h2資料庫作為演示
CREATE TABLE IF NOT EXISTS `t_order_0`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_1`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_2`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_3`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_4`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
安裝maven依賴
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-h2</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-api4j</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.199</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
建立實體物件對應資料庫
@Data
@Table(value = "t_order",shardingInitializer = H2OrderShardingInitializer.class)
public class H2Order {
@Column(primaryKey = true)
@ShardingTableKey
private Integer id;
private Integer status;
private String created;
}
// 分片初始化器
public class H2OrderShardingInitializer extends AbstractShardingTableModInitializer<H2Order> {
@Override
protected int mod() {
return 5;//模5
}
@Override
protected int tailLength() {
return 1;//表字尾長度1位
}
}
//分片路由規則
public class H2OrderRule extends AbstractModTableRule<H2Order> {
@Override
protected int mod() {
return 5;
}
@Override
protected int tailLength() {
return 1;
}
}
建立datasource和easyquery
orderShardingDataSource=DataSourceFactory.getDataSource("dsorder","h2-dsorder.sql");
EasyQueryClient easyQueryClientOrder = EasyQueryBootstrapper.defaultBuilderConfiguration()
.setDefaultDataSource(orderShardingDataSource)
.optionConfigure(op -> {
op.setMaxShardingQueryLimit(10);
op.setDefaultDataSourceName("ds2020");
op.setDefaultDataSourceMergePoolSize(20);
})
.build();
EasyQuery easyQueryOrder = new DefaultEasyQuery(easyQueryClientOrder);
QueryRuntimeContext runtimeContext = easyQueryOrder.getRuntimeContext();
QueryConfiguration queryConfiguration = runtimeContext.getQueryConfiguration();
queryConfiguration.applyShardingInitializer(new H2OrderShardingInitializer());//新增分片初始化器
TableRouteManager tableRouteManager = runtimeContext.getTableRouteManager();
tableRouteManager.addRouteRule(new H2OrderRule());//新增分片路由規則
插入程式碼
ArrayList<H2Order> h2Orders = new ArrayList<>();
for (int i = 0; i < 100; i++) {
H2Order h2Order = new H2Order();
h2Order.setId(i);
h2Order.setStatus(i%3);
h2Order.setCreated(String.valueOf(i));
h2Orders.add(h2Order);
}
easyQueryOrder.insertable(h2Orders).executeRows();
==> main, name:ds2020, Preparing: INSERT INTO t_order_3 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 0(Integer),0(Integer),0(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_4 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 1(Integer),1(Integer),1(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_0 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 2(Integer),2(Integer),2(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_1 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 3(Integer),0(Integer),3(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_2 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 4(Integer),1(Integer),4(String)
.....省略
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.toList();
Assert.assertEquals(4,list.size());
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 1(ms)
<== Total: 4
``
通過上述sql展示我們可以清晰的看到哪個執行緒執行了哪個資料來源(分片下會不一樣),執行了什麼sql,最終執行消耗多少時間引數是多少,一共返回多少條資料
分片排序
```java
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.orderByDesc(o->o.column(H2Order::getId))
.toList();
Assert.assertEquals(4,list.size());
Assert.assertEquals(7,(int)list.get(0).getId());
Assert.assertEquals(6,(int)list.get(1).getId());
Assert.assertEquals(2,(int)list.get(2).getId());
Assert.assertEquals(1,(int)list.get(3).getId());
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 0(ms)
<== Total: 4
最後的最後
附上原始碼地址,原始碼中有檔案和對應的qq群,如果決定有用請點選star謝謝大家了