解碼器 | 基於 Transformers 的編碼器-解碼器模型
基於 transformer 的編碼器-解碼器模型是 表徵學習 和 模型架構 這兩個領域多年研究成果的結晶。本文簡要介紹了神經編碼器-解碼器模型的歷史,更多背景知識,建議讀者閱讀由 Sebastion Ruder 撰寫的這篇精彩 博文。此外,建議讀者對 自注意力 (self-attention) 架構 有一個基本瞭解,可以閱讀 Jay Alammar 的 這篇博文 複習一下原始 transformer 模型。
本文分 4 個部分:
- 背景 - 簡要回顧了神經編碼器-解碼器模型的歷史,重點關注基於 RNN 的模型。
- 編碼器-解碼器 - 闡述基於 transformer 的編碼器-解碼器模型,並闡述如何使用該模型進行推理。
- 編碼器 - 闡述模型的編碼器部分。
- 解碼器 - 闡述模型的解碼器部分。
每個部分都建立在前一部分的基礎上,但也可以單獨閱讀。這篇分享是最後一部分 解碼器。
解碼器
如 編碼器-解碼器 部分所述, 基於 transformer 的解碼器定義了給定上下文編碼序列條件下目標序列的條件概率分佈:
根據貝葉斯法則,在給定上下文編碼序列和每個目標變數的所有前驅目標向量的條件下,可將上述分佈分解為每個目標向量的條件分佈的乘積:
我們首先了解一下基於 transformer 的解碼器如何定義概率分佈。基於 transformer 的解碼器由很多 解碼器模組 堆疊而成,最後再加一個線性層 (即 「LM 頭」)。這些解碼器模組的堆疊將上下文相關的編碼序列 \(\mathbf{\overline{X}}_{1:n}\) 和每個目標向量的前驅輸入 \(\mathbf{Y}_{0:i-1}\) (這裡 \(\mathbf{y}_0\) 為 BOS) 對映為目標向量的編碼序列 \(\mathbf{\overline{Y} }_{0:i-1}\)。然後,「LM 頭」將目標向量的編碼序列 \(\mathbf{\overline{Y}}_{0:i-1}\) 對映到 logit 向量序列 \(\mathbf {L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n\), 而每個 logit 向量\(\mathbf{l}_i\) 的維度即為詞表的詞彙量。這樣,對於每個 \(i \in {1, \ldots, n}\),其在整個詞彙表上的概率分佈可以通過對 \(\mathbf{l}_i\) 取 softmax 獲得。公式如下:
「LM 頭」 即為詞嵌入矩陣的轉置, 即 \(\mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{ y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{T}\) \({}^1\)。直觀上來講,這意味著對於所有 \(i \in {0, \ldots, n - 1}\) 「LM 頭」 層會將 \(\mathbf{\overline{y }}_i\) 與詞彙表 \(\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\) 中的所有詞嵌入一一比較,輸出的 logit 向量 \(\mathbf{l}_{i+1}\) 即表示 \(\mathbf{\overline{y }}_i\) 與每個詞嵌入之間的相似度。Softmax 操作只是將相似度轉換為概率分佈。對於每個 \(i \in {1, \ldots, n}\),以下等式成立:
總結一下,為了對目標向量序列 \(\mathbf{Y}_{1: m}\) 的條件分佈建模,先在目標向量 \(\mathbf{Y}_{1: m-1}\) 前面加上特殊的 \(\text{BOS}\) 向量 ( 即 \(\mathbf{y}_0\)),並將其與上下文相關的編碼序列 \(\mathbf{\overline{X}}_{1:n}\) 一起對映到 logit 向量序列 \(\mathbf{L}_{1:m}\)。然後,使用 softmax 操作將每個 logit 目標向量 \(\mathbf{l}_i\) 轉換為目標向量 \(\mathbf{y}_i\) 的條件概率分佈。最後,將所有目標向量的條件概率 \(\mathbf{y}_1, \ldots, \mathbf{y}_m\) 相乘得到完整目標向量序列的條件概率:
與基於 transformer 的編碼器不同,在基於 transformer 的解碼器中,其輸出向量 \(\mathbf{\overline{y}}_{i-1}\) 應該能很好地表徵 下一個 目標向量 (即 \(\mathbf{y}_i\)),而不是輸入向量本身 (即 \(\mathbf{y}_{i-1}\))。此外,輸出向量 \(\mathbf{\overline{y}}_{i-1}\) 應基於編碼器的整個輸出序列 \(\mathbf{\overline{X}}_{1:n}\)。為了滿足這些要求,每個解碼器塊都包含一個 單向自注意層,緊接著是一個 交叉注意層,最後是兩個前饋層\({}^2\)。單向自注意層將其每個輸入向量 \(\mathbf{y'}_j\) 僅與其前驅輸入向量 \(\mathbf{y'}_i\) (其中 \(i \le j\),且 \(j \in {1, \ldots, n}\)) 相關聯,來模擬下一個目標向量的概率分佈。交叉注意層將其每個輸入向量 \(\mathbf{y''}_j\) 與編碼器輸出的所有向量 \(\mathbf{\overline{X}}_{1:n}\) 相關聯,來根據編碼器輸入預測下一個目標向量的概率分佈。
好,我們仍以英語到德語翻譯為例視覺化一下 基於 transformer 的解碼器。
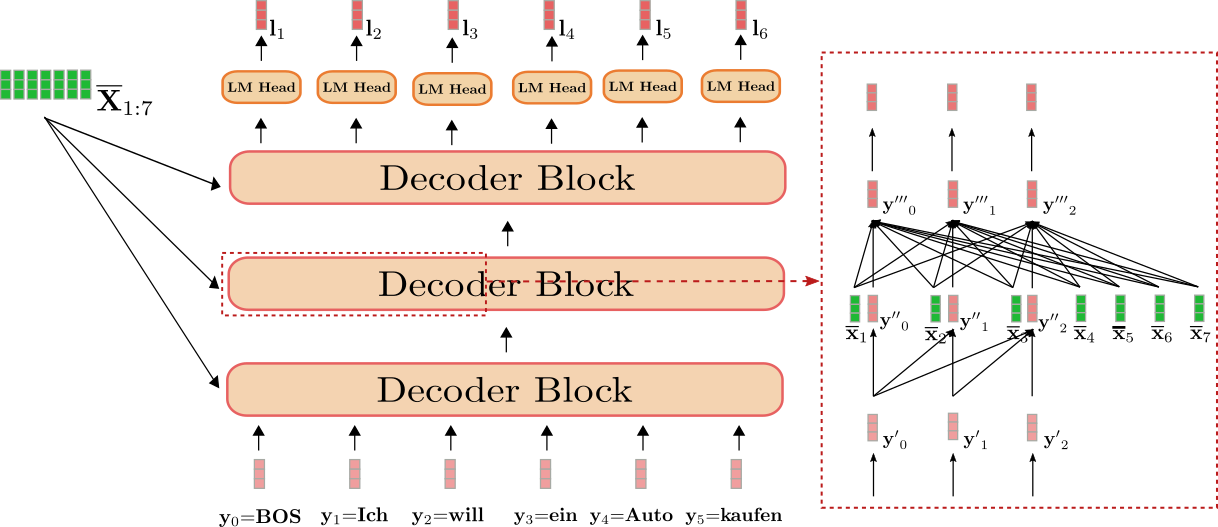
我們可以看到解碼器將 \(\mathbf{Y}_{0:5}\): 「BOS」、「Ich」、「will」、「ein」、「Auto」、「kaufen」 (圖中以淺紅色顯示) 和 「I」、「want」、「to」、「buy」、「a」、「car」、「EOS」 ( 即 \(\mathbf{\overline{X}}_{1:7}\) (圖中以深綠色顯示)) 對映到 logit 向量 \(\mathbf{L}_{1:6}\) (圖中以深紅色顯示)。
因此,對每個 \(\mathbf{l}_1、\mathbf{l}_2、\ldots、\mathbf{l}_6\) 使用 softmax 操作可以定義下列條件概率分佈:
\[p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}), \]\[\ldots, \]\[p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) \]
總條件概率如下:
其可表示為以下乘積形式:
圖右側的紅框顯示了前三個目標向量 \(\mathbf{y}_0\)、\(\mathbf{y}_1\)、 \(\mathbf{y}_2\) 在一個解碼器模組中的行為。下半部分說明了單向自注意機制,中間說明了交叉注意機制。我們首先關注單向自注意力。
與雙向自注意一樣,在單向自注意中, query 向量 \(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\) (如下圖紫色所示), key 向量 \(\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}\) (如下圖橙色所示),和 value 向量 \(\mathbf{v }_0, \ldots, \mathbf{v}_{m-1}\) (如下圖藍色所示) 均由輸入向量 \(\mathbf{y'}_0, \ldots, \mathbf{ y'}_{m-1}\) (如下圖淺紅色所示) 對映而來。然而,在單向自注意力中,每個 query 向量 \(\mathbf{q}_i\) 僅 與當前及之前的 key 向量進行比較 (即 \(\mathbf{k}_0 , \ldots, \mathbf{k}_i\)) 並生成各自的 注意力權重 。這可以防止輸出向量 \(\mathbf{y''}_j\) (如下圖深紅色所示) 包含未來向量 (\(\mathbf{y}_i\),其中 \(i > j\) 且 \(j \in {0, \ldots, m - 1 }\)) 的任何資訊 。與雙向自注意力的情況一樣,得到的注意力權重會乘以它們各自的 value 向量並加權求和。
我們將單向自注意力總結如下:
請注意, key 和 value 向量的索引範圍都是 \(0:i\) 而不是 \(0: m-1\),\(0: m-1\) 是雙向自注意力中 key 向量的索引範圍。
下圖顯示了上例中輸入向量 \(\mathbf{y'}_1\) 的單向自注意力。
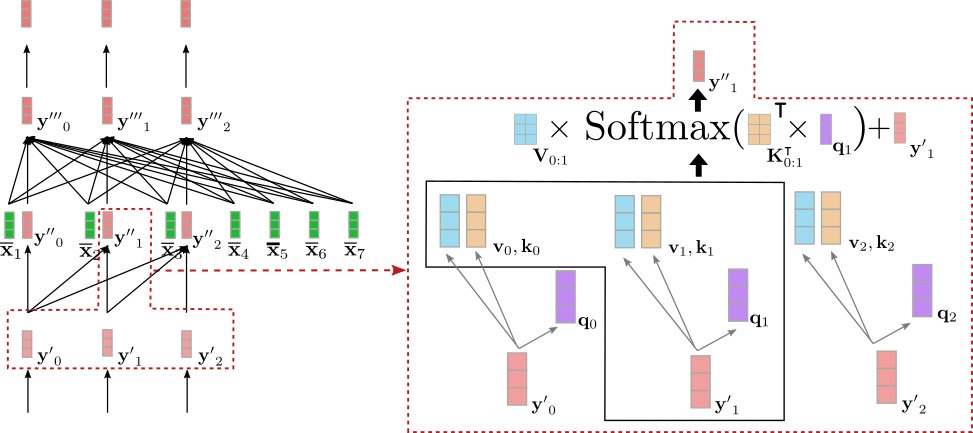
可以看出 \(\mathbf{y''}_1\) 只依賴於 \(\mathbf{y'}_0\) 和 \(\mathbf{y'}_1\)。因此,單詞 「Ich」 的向量表徵 ( 即 \(\mathbf{y'}_1\)) 僅與其自身及 「BOS」 目標向量 ( 即 \(\mathbf{y'}_0\)) 相關聯,而 不 與 「will」 的向量表徵 ( 即 \(\mathbf{y'}_2\)) 相關聯。
那麼,為什麼解碼器使用單向自注意力而不是雙向自注意力這件事很重要呢?如前所述,基於 transformer 的解碼器定義了從輸入向量序列 \(\mathbf{Y}_{0: m-1}\) 到其 下一個 解碼器輸入的 logit 向量的對映,即 \(\mathbf{L}_{1:m}\)。舉個例子,輸入向量 \(\mathbf{y}_1\) = 「Ich」 會對映到 logit 向量 \(\mathbf{l}_2\),並用於預測下一個輸入向量 \(\mathbf{y}_2\)。因此,如果 \(\mathbf{y'}_1\) 可以獲取後續輸入向量 \(\mathbf{Y'}_{2:5}\)的資訊,解碼器將會簡單地複製向量 「will」 的向量表徵 ( 即 \(\mathbf{y'}_2\)) 作為其輸出 \(\mathbf{y''}_1\),並就這樣一直傳播到最後一層,所以最終的輸出向量 \(\mathbf{\overline{y}}_1\) 基本上就只對應於 \(\mathbf{y}_2\) 的向量表徵,並沒有起到預測的作用。
這顯然是不對的,因為這樣的話,基於 transformer 的解碼器永遠不會學到在給定所有前驅詞的情況下預測下一個詞,而只是對所有 \(i \in {1, \ldots, m }\),通過網路將目標向量 \(\mathbf{y}_i\) 複製到 \(\mathbf {\overline{y}}_{i-1}\)。以下一個目標變數本身為條件去定義下一個目標向量,即從 \(p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{ X}})\) 中預測 \(\mathbf{y}_i\), 顯然是不對的。因此,單向自注意力架構允許我們定義一個 因果的 概率分佈,這對有效建模下一個目標向量的條件分佈而言是必要的。
太棒了!現在我們可以轉到連線編碼器和解碼器的層 - 交叉注意力 機制!
交叉注意層將兩個向量序列作為輸入: 單向自注意層的輸出 \(\mathbf{Y''}_{0: m-1}\) 和編碼器的輸出 \(\mathbf{\overline{X}}_{1:n}\)。與自注意力層一樣, query 向量 \(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\) 是上一層輸出向量 \(\mathbf{Y''}_{0: m-1}\) 的投影。而 key 和 value 向量 \(\mathbf{k}_0, \ldots, \mathbf{k}_{n-1}\)、\(\mathbf{v}_0, \ldots, \mathbf {v}_{n-1}\) 是編碼器輸出向量 \(\mathbf{\overline{X}}_{1:n}\) 的投影。定義完 key 、value 和 query 向量後,將 query 向量 \(\mathbf{q}_i\) 與 所有 key 向量進行比較,並用各自的得分對相應的 value 向量進行加權求和。這個過程與 雙向 自注意力對所有 \(i \in {0, \ldots, m-1}\) 求 \(\mathbf{y'''}_i\) 是一樣的。交叉注意力可以概括如下:
注意,key 和 value 向量的索引範圍是 \(1:n\),對應於編碼器輸入向量的數目。
我們用上例中輸入向量 \(\mathbf{y''}_1\) 來圖解一下交叉注意力機制。
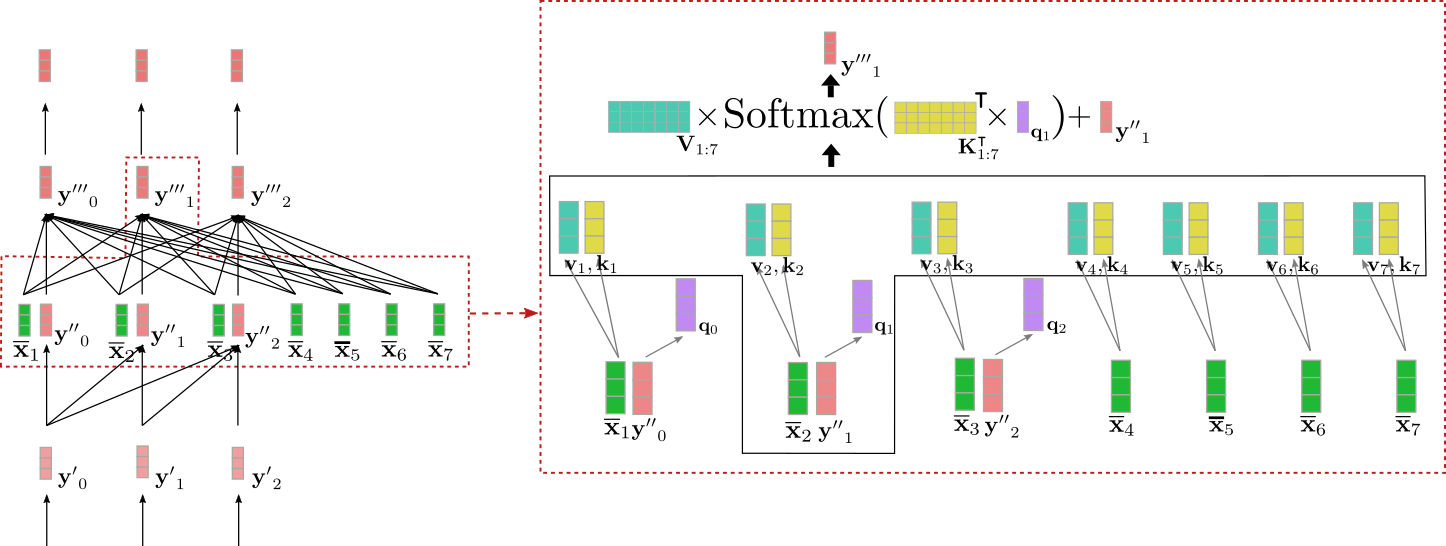
我們可以看到 query 向量 \(\mathbf{q}_1\)(紫色)源自 \(\mathbf{y''}_1\)(紅色),因此其依賴於單詞 "Ich" 的向量表徵。然後將 query 向量 \(\mathbf{q}_1\) 與對應的 key 向量 \(\mathbf{k}_1, \ldots, \mathbf{k}_7\)(黃色)進行比較,這裡的 key 向量對應於編碼器對其輸入 \(\mathbf{X}_{1:n}\) = "I want to buy a car EOS" 的上下文相關向量表徵。這將 "Ich" 的向量表徵與所有編碼器輸入向量直接關聯起來。最後,將注意力權重乘以 value 向量 \(\mathbf{v}_1, \ldots, \mathbf{v}_7\)(青綠色)並加上輸入向量 \(\mathbf{y''}_1\) 最終得到輸出向量 \(\mathbf{y'''}_1\)(深紅色)。
所以,直觀而言,到底發生了什麼?每個輸出向量 \(\mathbf{y'''}_i\) 是由所有從編碼器來的 value 向量(\(\mathbf{v}_{1}, \ldots, \mathbf{v}_7\) )的加權和與輸入向量本身 \(\mathbf{y''}_i\) 相加而得(參見上圖所示的公式)。其關鍵思想是: 來自解碼器的 \(\mathbf{q}_i\) 的 query 投影與 來自編碼器的 \(\mathbf{k}_j\) 越相關,其對應的 \(\mathbf{v}_j\) 對輸出的影響越大。
酷!現在我們可以看到這種架構的每個輸出向量 \(\mathbf{y'''}_i\) 取決於其來自編碼器的輸入向量 \(\mathbf{\overline{X}}_{1 :n}\) 及其自身的輸入向量 \(\mathbf{y''}_i\)。這裡有一個重要的點,在該架構中,雖然輸出向量 \(\mathbf{y'''}_i\) 依賴來自編碼器的輸入向量 \(\mathbf{\overline{X}}_{1:n}\),但其完全獨立於該向量的數量 \(n\)。所有生成 key 向量 \(\mathbf{k}_1, \ldots, \mathbf{k}_n\) 和 value 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_n $ 的投影矩陣 \(\mathbf{W}^{\text{cross}}_{k}\) 和 \(\mathbf{W}^{\text{cross}}_{v}\) 都是與 \(n\) 無關的,所有 \(n\) 共用同一個投影矩陣。且對每個 \(\mathbf{y'''}_i\),所有 value 向量 \(\mathbf{v}_1, \ldots, \mathbf{v}_n\) 被加權求和至一個向量。至此,關於為什麼基於 transformer 的解碼器沒有遠端依賴問題而基於 RNN 的解碼器有這一問題的答案已經很顯然了。因為每個解碼器 logit 向量 直接 依賴於每個編碼後的輸出向量,因此比較第一個編碼輸出向量和最後一個解碼器 logit 向量只需一次操作,而不像 RNN 需要很多次。
總而言之,單向自注意力層負責基於當前及之前的所有解碼器輸入向量建模每個輸出向量,而交叉注意力層則負責進一步基於編碼器的所有輸入向量建模每個輸出向量。
為了驗證我們對該理論的理解,我們繼續上面編碼器部分的程式碼,完成解碼器部分。
\({}^1\) 詞嵌入矩陣 \(\mathbf{W}_{\text{emb}}\) 為每個輸入詞提供唯一的 上下文無關 向量表示。這個矩陣通常也被用作 「LM 頭」,此時 「LM 頭」可以很好地完成「編碼向量到 logit」 的對映。
\({}^2\) 與編碼器部分一樣,本文不會詳細解釋前饋層在基於 transformer 的模型中的作用。Yun 等 (2017) 的工作認為前饋層對於將每個上下文相關向量 \(\mathbf{x'}_i\) 對映到所需的輸出空間至關重要,僅靠自注意力層無法完成。這裡應該注意,每個輸出詞元 \(\mathbf{x'}\) 對應的前饋層是相同的。有關更多詳細資訊,建議讀者閱讀論文。
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))
輸出:
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True
我們首先比較解碼器詞嵌入層的輸出維度 embeddings(decoder_input_ids) (對應於 \(\mathbf{Y}_{0: 4}\),這裡 <pad> 對應於 BOS 且 "Ich will das" 被分為 4 個詞) 和 lm_logits (對應於 \(\mathbf{L}_{1:5}\)) 的維度。此外,我們還通過解碼器將單詞序列 「<pad> Ich will ein」 和其輕微改編版 「<pad> Ich will das」 與 encoder_output_vectors 一起傳遞給解碼器,以檢查對應於 「Ich」 的第二個 lm_logit 在僅改變輸入序列中的最後一個單詞 (「ein」 -> 「das」) 時是否會有所不同。
正如預期的那樣,解碼器輸入詞嵌入和 lm_logits 的輸出, 即 \(\mathbf{Y}_{0: 4}\) 和 \(\mathbf{L}_{ 1:5}\) 的最後一個維度不同。雖然序列長度相同 (=5),但解碼器輸入詞嵌入的維度對應於 model.config.hidden_size,而 lm_logit 的維數對應於詞彙表大小 model.config.vocab_size。其次,可以注意到,當將最後一個單詞從 「ein」 變為 「das」,\(\mathbf{l}_1 = \text{「Ich」}\) 的輸出向量的值不變。鑑於我們已經理解了單向自注意力,這就不足為奇了。
最後一點, 自迴歸 模型,如 GPT2,與刪除了交叉注意力層的 基於 transformer 的解碼器模型架構是相同的,因為純自迴歸模型不依賴任何編碼器的輸出。因此,自迴歸模型本質上與 自編碼 模型相同,只是用單向注意力代替了雙向注意力。這些模型還可以在大量開放域文字資料上進行預訓練,以在自然語言生成 (NLG) 任務中表現出令人印象深刻的效能。在 Radford 等 (2019) 的工作中,作者表明預訓練的 GPT2 模型無需太多微調即可在多種 NLG 任務上取得達到 SOTA 或接近 SOTA 的結果。你可以在 此處 獲取所有