Hive執行計劃之一文讀懂Hive執行計劃
概述
Hive的執行計劃描述了一個hiveSQL語句的具體執行步驟,通過執行計劃解讀可以瞭解hiveSQL語句被解析器轉換為相應程式語言的執行邏輯。通過執行邏輯可以知曉HiveSQL執行流程,進而對流程進行優化,實現更優的資料查詢處理。
同樣,通過執行計劃,還可以瞭解到哪些不一樣的SQL邏輯其實是等價的,哪些看似一樣的邏輯其實是執行代價完全不一樣。
如果說Hive優化是一堵技術路上的高牆,那麼關於Hive執行計劃,就是爬上這堵高牆的一架梯子。
不同版本的Hive會採用不同的方式生成的執行計劃。主要區別就是基於規則生成hive執行計劃,和基於成本代價來生成執行計劃。而hive早期版本是基於規則生成執行計劃,在Hive0.14及之後的版本都是基於成本代價來生成執行計劃,這主要是整合了Apache Calcite。Apache Calcite具體可以檢視官網介紹。
兩種方式的優劣顯而易見,基於規則生成執行計劃,作為使用方來說,叢集的環境,資料量的大小完全不一樣,同樣的規則邏輯,執行起來差異巨大,因此會對開發者有更高的優化要求。Hive基於成本代價來生成執行計劃,這種方式能夠結合Hive後設資料資訊和Hive執行過程收集到的各類儲存統計資訊推測出一個更合理的執行計劃。也就是說Hive本身已經為我們的SQL語句做了一輪優化了,可以預見的將來,Hive還會具備更多的優化能力。
Hive執行計劃是一個預估的執行計劃,只有在SQL實際執行後才會獲取到真正的執行計劃,而一些關係型資料庫中,會提供真實的SQL執行計劃。如SQLserver和Oracle等。
1.hive執行計劃的檢視
Hive提供的執行計劃使用語法如下:
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
- EXPLAIN:檢視執行計劃的基本資訊;
- EXTENDED:加上 extended 可以輸出有關計劃的額外擴充套件資訊。這些通常是物理資訊,例如檔名等;
- CBO:可以選擇使用Calcite優化器不同成本模型生成計劃。CBO 從 hive 4.0.0 版本開始支援;
- AST:輸出查詢的抽象語法樹。AST 在hive 2.1.0 版本刪除了,存在bug,轉儲AST可能會導致OOM錯誤,將在4.0.0版本修復;
- DEPENDENCY:dependency在EXPLAIN語句中使用會產生有關計劃中輸入的依賴資訊。包含表和分割區資訊等;
- AUTHORIZATION:顯示SQL操作相關許可權的資訊;
- LOCKS:這對於瞭解系統將獲得哪些鎖以執行指定的查詢很有用。LOCKS 從 hive 3.2.0 開始支援;
- VECTORIZATION:檢視SQL的向量化描述資訊;
- ANALYZE:用實際的行數註釋計劃。從 Hive 2.2.0 開始支援;
以上內容重點關注explain,explain extend,explain dependency,explain authorization,explain vectorization。
2.學會檢視Hive執行計劃的基本資訊
一個HIVE查詢被轉換為一個由一個或多個stage組成的序列(有向無環圖DAG)。這些stage可以是MapReduce stage,也可以是負責後設資料儲存的stage,也可以是負責檔案系統的操作(比如移動和重新命名)的stage。
在查詢SQL語句前加上關鍵字explain用來檢視執行計劃的基本資訊。
可以看如下範例的執行計劃結果解析:
範例SQL
-- 本文預設使用mr計算引擎
explain
-- 統計年齡小於30歲各個年齡裡,暱稱裡帶「小」的人數
select age,count(0) as num from temp.user_info_all where ymd = '20230505'
and age < 30 and nick like '%小%'
group by age;
執行計劃:
# 描述任務之間stage的依賴關係
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
# 每個stage詳細資訊
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: user_info_all
Statistics: Num rows: 32634295 Data size: 783223080 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((age < 30) and (nick like '%小%')) (type: boolean)
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: age (type: bigint)
outputColumnNames: age
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count(0)
keys: age (type: bigint)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: bigint)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 2719524 Data size: 65268576 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 2719524 Data size: 65268576 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
我們將上述結果拆分看,先從最外層開始,包含兩個大的部分:
-
stage dependencies: 各個stage之間的依賴性
-
stage plan: 各個stage的執行計劃
先看第一部分 stage dependencies ,包含兩個 stage,Stage-1 是根stage,說明這是開始的stage,Stage-0 依賴 Stage-1,Stage-1執行完成後執行Stage-0。
一些Hive執行邏輯的視覺化工具頁面就是利用該語句資訊繪畫出Hive執行流程圖以及相關進度資訊。
再看第二部分 stage plan,裡面有一個 Map Reduce,一個MR的執行計劃分為兩個部分:
- Map Operator Tree: MAP端的執行計劃樹
- Reduce Operator Tree: Reduce端的執行計劃樹
這兩個執行計劃樹裡面包含這條sql語句的 operator:
map端Map Operator Tree資訊解讀:
-
TableScan 對關鍵字alias宣告的結果集進行表掃描操作。
alias: 表名稱
Statistics: 表統計資訊,包含表中資料條數,資料大小等
-
Filter Operator:過濾操作,表示在之前的表掃描結果集上進行資料過濾。
predicate:過濾資料時使用的謂詞(過濾條件),如sql語句中的and age < 30,則此處顯示(age < 30),什麼是謂詞,以及優化點,可以詳細看之前一篇文章謂詞下推。
Statistics:過濾後資料條數和大小。
-
Select Operator: 對列進行投影,即篩選列,選取操作。
expressions:篩選的列名稱及列型別
outputColumnNames:輸出的列名稱
Statistics:篩選列後表統計資訊,包含表中資料條數,資料大小等。
-
Group By Operator:分組聚合操作。
aggregations:顯示聚合函數資訊,這裡使用
count(0)。keys:表示分組的列,如果沒有分組,則沒有此欄位。
mode:聚合模式,值有 hash:隨機聚合;mergepartial:合併部分聚合結果;final:最終聚合
outputColumnNames:聚合之後輸出列名,_col0對應的是age列, _col1對應的是count(0)列。
Statistics: 表統計資訊,包含分組聚合之後的資料條數,資料大小。
-
Reduce Output Operator:輸出到reduce操作結果集資訊。
key expressions:MR計算引擎,在map和reduce階段的輸出都是key-value形式,這裡描述的是map端輸出的鍵使用的是哪個資料列。_col0對應的是age列。
sort order:值為空不排序;值為 + 正序排序,值為 - 倒序排序;值為 +- 排序的列為兩列,第一列為正序,第二列為倒序,以此類推多值排序。
Map-reduce partition columns:表示Map階段輸出到Reduce階段的分割區列,在HiveSQL中,可以用distribute by指定分割區的列。這裡預設為_col0對應的是age列。
Statistics:輸出結果集的統計資訊。
value expressions:對應key expressions,這裡是value值欄位。_col1對應的是count(0)列。
接下來是reduce階段Reduce Operator Tree,出現和map階段關鍵詞一樣的,其含義是一致的,羅列一下map階段未出現的關鍵詞。
-
File Output Operator:檔案輸出操作。
compressed:表示輸出結果是否進行壓縮,true壓縮,false不壓縮。
-
table:表示當前操作表的資訊。
input format:輸入檔案型別。
output format:輸出檔案型別。
serde:讀取表資料的序列化和反序列化方式。
Stage-0的操作資訊。
-
Fetch Operator:使用者端獲取資料操作。
limit:值為-1標識不限制條數,其他值為限制的條數。
-
Processor Tree:處理器樹
ListSink:資料展示。
3.執行計劃步驟操作過程
可以根據上述執行計劃通過流程圖來描述一下hiveSQL的執行邏輯過程。
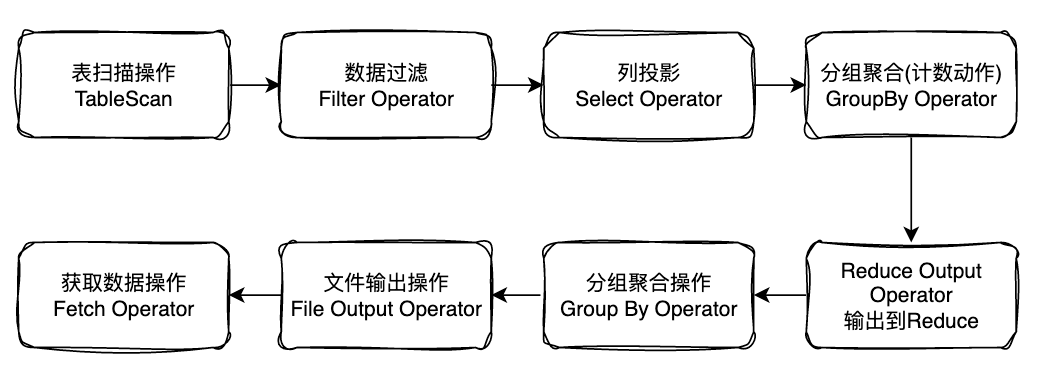
通過上圖可以很清晰的瞭解一個hiveSQL的執行邏輯過程,便於理解hive資料流轉過程。
4.explain extended
explain extended可以檢視explain的擴充套件資訊,主要包含三個部分內容:
- 抽象語法樹(Abstract Syntax Tree,AST):是SQL轉換成MR或其他計算引擎的任務中的一個重要過程。AST 在HIVE-13533中從 explain extended 中刪除 ,並在HIVE-15932 中恢復為單獨的命令 。
- 作業的依賴關係圖,同explain展現內容。
- 每個作業的詳細資訊,即Stage Plans,相比explain多了表設定資訊,表檔案儲存路徑等。具體可以通過以下命令進行檢視比對。不作列舉了。
explain extended
-- 統計年齡小於30歲各個年齡裡,暱稱裡帶「小」的人數
select age,count(0) as num from temp.user_info_all where ymd = '20230505'
and age < 30 and nick like '%小%'
group by age;
下一期:Hive執行計劃之hive依賴及許可權查詢和常見使用場景
按例,歡迎點選此處關注我的個人公眾號,交流更多知識。
後臺回覆關鍵字 hive,隨機贈送一本魯邊備註版珍藏巨量資料書籍。