淺談 ByteHouse Projection 優化實踐
預聚合是 OLAP 系統中常用的一種優化手段,在通過在載入資料時就進行部分聚合計算,生成聚合後的中間表或檢視,從而在查詢時直接使用這些預先計算好的聚合結果,提高查詢效能,實現這種預聚合方法大多都使用物化檢視來實現。
Clickhouse 社群實現的 Projection 功能類似於物化檢視,原始的概念來源於 Vertica,在原始表資料載入時,根據聚合 SQL 定義的表示式,計算寫入資料的聚合資料與原始資料同步寫入儲存。在資料查詢的過程中,如果查詢 SQL 通過匹配分析可以通過聚合資料計算得到,直接查詢聚合資料減少計算開銷,大幅提升查詢效能。
Clickhouse Projection 是針對物化檢視現有問題,在查詢匹配,資料一致性上擴充套件了使用場景:
- 支援 normal projection,按照不同列進行資料重排,對於不同條件快速過濾資料
- 支援 aggregate projection, 使用聚合查詢在源表上直接定義出預聚合模型
- 查詢分析能根據查詢代價,自動選擇最優 Projection 進行查詢優化,無需改寫查詢
- projeciton 資料儲存於原始 part 目錄下,在任一時刻針對任一資料變換操作均提供一致性保證
- 維護簡單,不需另外定義新表,在原始表新增 projection 屬性
ByteHouse 是火山引擎基於 ClickHouse 研發的一款分析型資料庫產品,是同時支援實時和離線匯入的自助資料分析平臺,能夠對 PB 級海量資料進行高效分析。具備真實時分析、儲存-計算分離、多級資源隔離、雲上全託管服務四大特點,為了更好的相容社群的 projection 功能,擴充套件 projection 使用場景,ByteHouse 對 Projection 進行了匹配場景和架構上進行了優化。在 ByteHouse 商業客戶效能測試 projection 的效能測試,在 1.2 億條的實際生產資料集中進行測試,查詢並行能力提升 10~20 倍,下面從 projeciton 在優化器查詢改寫和基於 ByteHouse 框架改進兩個方面談一談目前的優化工作。
Projection 使用
為了提高 ByteHouse 對社群有很好的相容性,ByteHouse 保留了原有語法的支援,projection 操作分為建立,刪除,物化,刪除資料幾個操作。為了便於理解後面的優化使用行為分析系統例子作為分析的物件。
語法
-- 新增projection定義
ALTER TABLE [db].table ADD PROJECTION name ( SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY] )
-- 刪除projection定義並且刪除projection資料
ALTER TABLE [db].table DROP PROJECTION name
-- 物化原表的某個partition資料
ALTER TABLE [db.]table MATERIALIZE PROJECTION name IN PARTITION partition_name
-- 刪除projection資料但不刪除projection定義
ALTER TABLE [db.]table CLEAR PROJECTION name IN PARTITION partition_name
範例
CREATE DATABASE IF NOT EXISTS tea_data;
建立原始資料表
CREATE TABLE tea_data.events(
app_id UInt32,
user_id UInt64,
event_type UInt64,
cost UInt64,
action_duration UInt64,
display_time UInt64,
event_date Date
) ENGINE = CnchMergeTree PARTITION BY toDate(event_date)
ORDER BY
(app_id, user_id, event_type);
建立projection前寫入2023-05-28分割區測試資料
INSERT INTO tea_data.events
SELECT
number / 100,
number % 10,
number % 3357,
number % 166,
number % 5,
number % 40,
'2023-05-28 05:11:55'
FROM system.numbers LIMIT 100000;
建立聚合projection
ALTER TABLE tea_data.events ADD PROJECTION agg_sum_proj_1
(
SELECT
app_id,
user_id,
event_date,
sum(action_duration)
GROUP BY app_id,
user_id, event_date
);
建立projection後寫入2023-05-29分割區測試資料
INSERT INTO tea_data.events
SELECT
number / 100,
number % 10,
number % 3357,
number % 166,
number % 5,
number % 40,
'2023-05-29 05:11:55'
FROM system.numbers LIMIT 100000;
Note:CnchMergeTree是Bytehouse特有的引擎
Query Optimizer 擴充套件 Projection 改寫
Bytehouse 優化器
ByteHouse 優化器為業界目前唯一的 ClickHouse 優化器方案。ByteHouse 優化器的能力簡單總結如下:
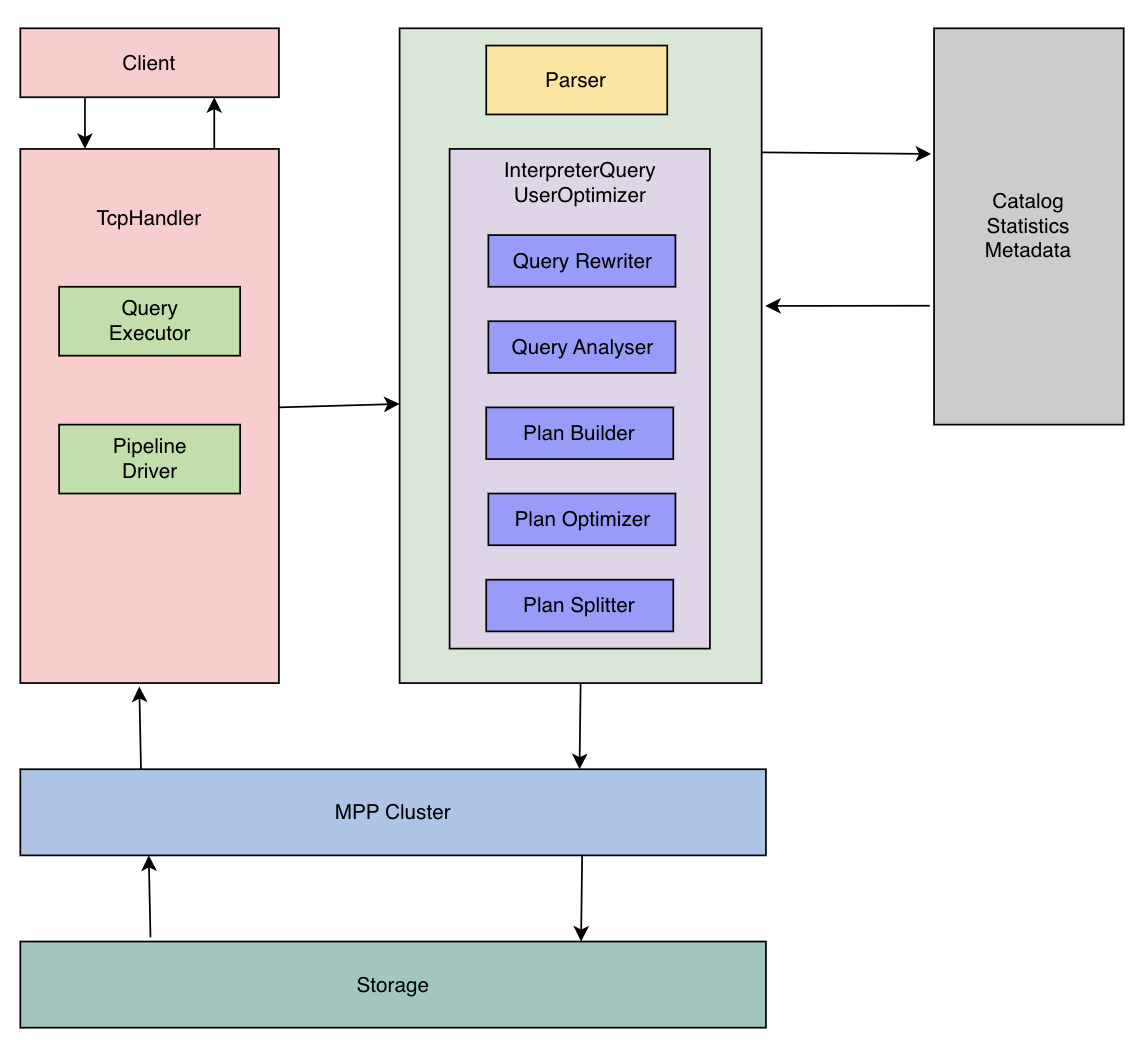
- RBO:支援:列裁剪、分割區裁剪、表示式簡化、子查詢解關聯、謂詞下推、冗餘運算元消除、Outer-JOIN 轉 INNER-JOIN、運算元下推儲存、分散式運算元拆分等常見的啟發式優化能力。
- CBO:基於 Cascade 搜尋方塊架,實現了高效的 Join 列舉演演算法,以及基於 Histogram 的代價估算,對 10 表全連線級別規模的 Join Reorder 問題,能夠全量列舉並尋求最優解,同時針對大於 10 表規模的 Join Reorder 支援啟發式列舉並尋求最優解。CBO 支援基於規則擴充套件搜尋空間,除了常見的 Join Reorder 問題以外,還支援 Outer-Join/Join Reorder,Magic Set Placement 等相關優化能力。
- 分散式計劃優化:面向分散式 MPP 資料庫,生成分散式查詢計劃,並且和 CBO 結合在一起。相對業界主流實現:分為兩個階段,首先尋求最優的單機版計劃,然後將其分散式化。我們的方案則是將這兩個階段融合在一起,在整個 CBO 尋求最優解的過程中,會結合分散式計劃的訴求,從代價的角度選擇最優的分散式計劃。對於 Join/Aggregate 的還支援 Partition 屬性展開。
- 高階優化能力:實現了 Dynamic Filter pushdown、單表物化檢視改寫、基於代價的 CTE (公共表示式共用)。
藉助 bytehouse 優化器強大的能力,針對 projection 原有實現的幾點侷限性做了優化,下面我們先來看一下社群在 projection 改寫的具體實現。
社群 Projection
改寫實現在非優化器執行模式下,對原始表的聚合查詢可通過 aggregate projection 加速,即讀取 projection 中的預聚合資料而不是原始資料。計算支援了 normal partition 和 projection partition 的混合查詢,如果一個 partition 的 projection 還沒物化,可以使用原始資料進行計算。
具體改寫執行邏輯:
- 計劃階段
- 將原查詢計劃和已有 projection 進行匹配篩選能滿足查詢要求的 projection candidates;
- 基於最小的 mark 讀取數選擇最優的 projection candidate;
- 對原查詢計劃中的 ActionDAG 進行改寫和摺疊,之後用於 projection part 資料的後續計算;
- 將當前資料處理階段提升到 WithMergeableState;
- 執行階段
- MergeTreeDataSelectExecutor 會將 aggregate 之前的計算進行拆分:對於 normal part,使用原查詢計劃進行計算;對於 projection part,使用改寫後 ActionDAG 構造 QueryPipeline;
- 將兩份資料合併,用於 aggregate 之後的計算。
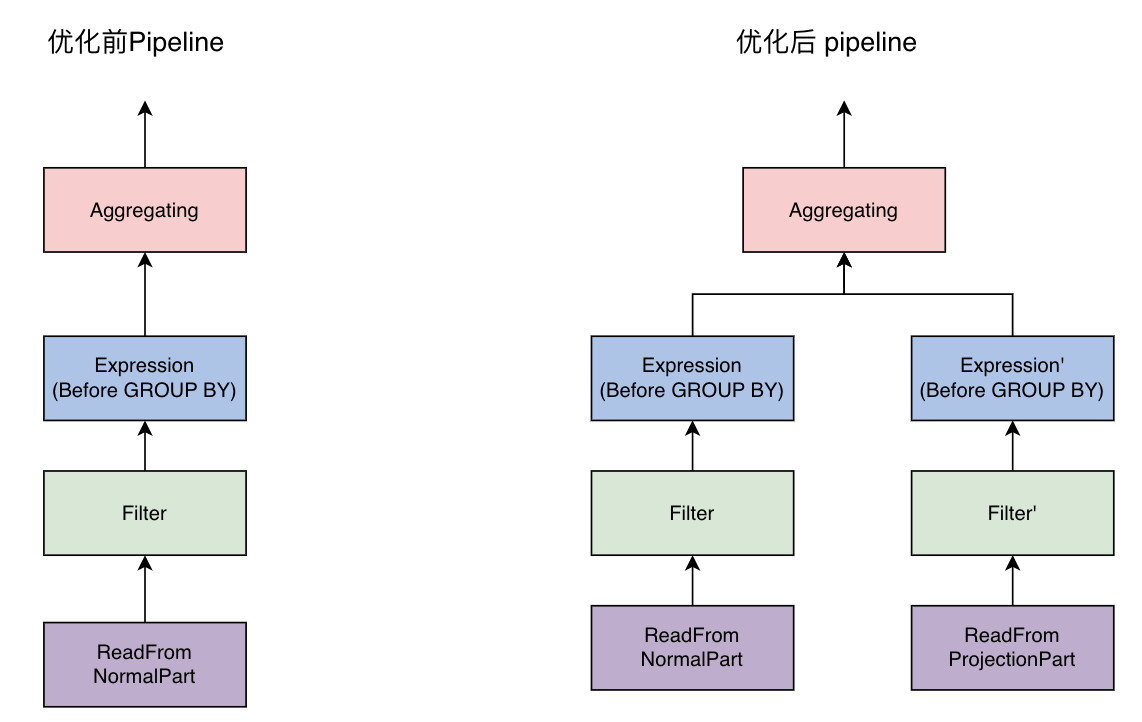
Bytehouse 優化器改寫實現
優化器會將查詢切分為不同的 plan segment 分發到 worker 節點並行執行,segment 之間通過 exchange 交換資料,在 plan segment 內部根據 query plan 構建 pipeline 執行,以下面簡單聚合查詢為例,說明優化器如何匹配 projection。
Q1:
SELECT
app_id,
user_id,
sum(action_duration)
FROM tea_data.eventsWHERE event_date = '2023-05-29'
GROUP BY
app_id,
user_id
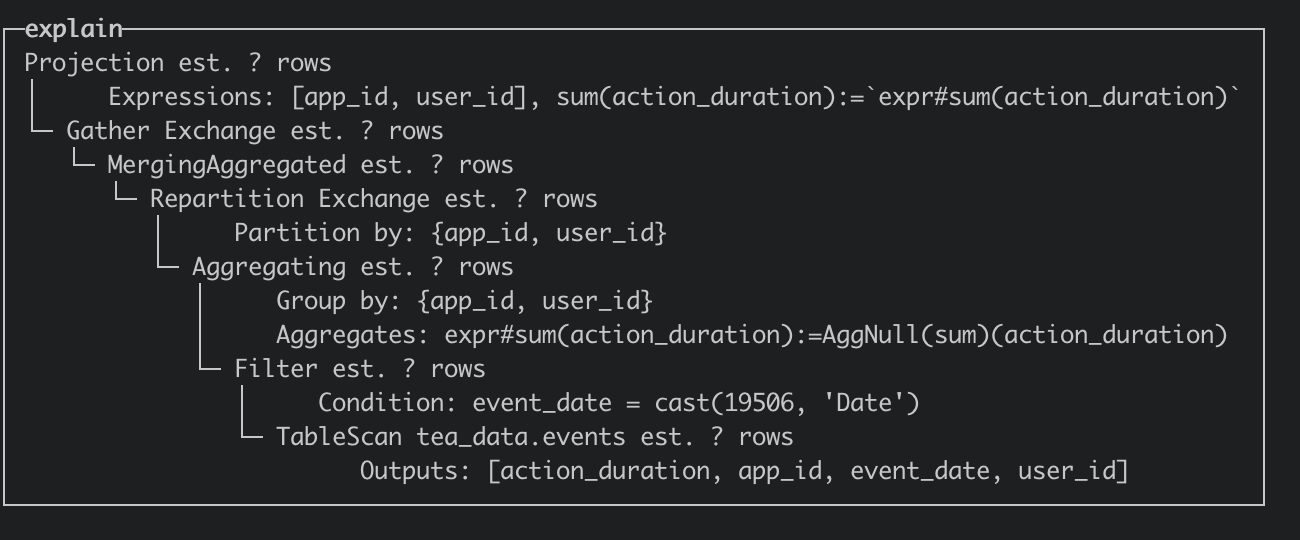
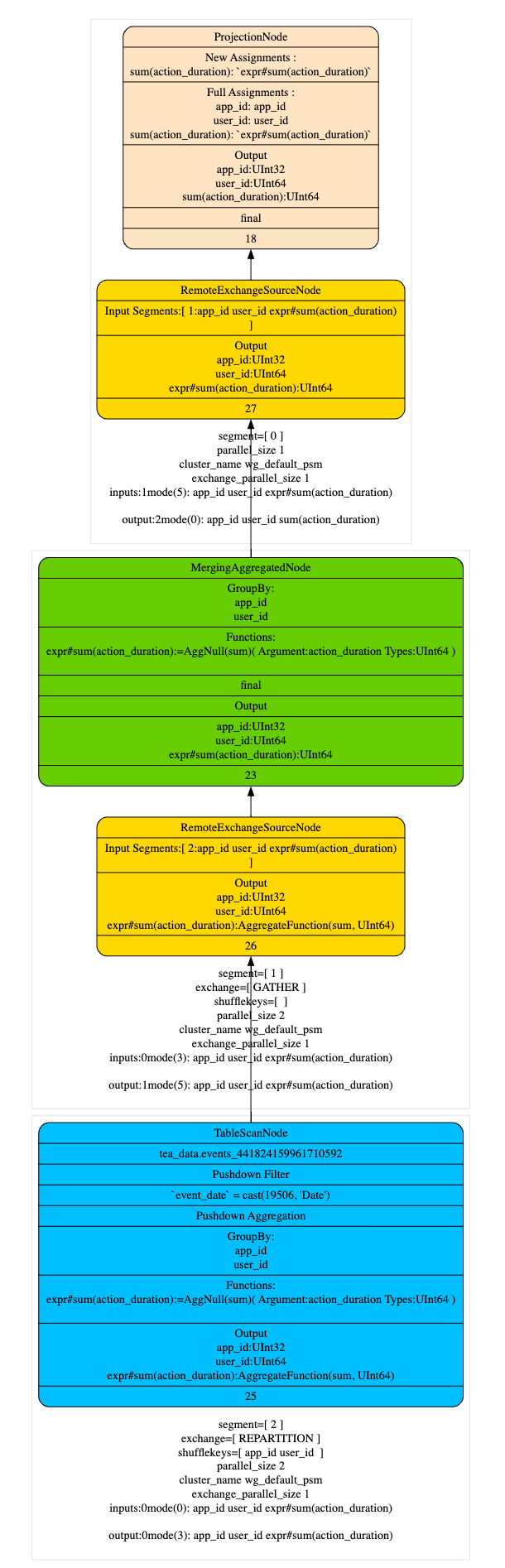
在執行計劃階段優化器儘量的將 TableScan 上層的 Partial Aggregation Step,Projection 和 Filter 下推到 TableScan 中,在將 plan segment 傳送到 worker 節點後,在根據查詢代價選擇合適 projection 進行匹配改寫,從下面的執行計劃上看,命中 projection 會在 table scan 中直接讀取 AggregateFunction(sum, UInt64)的 state 資料,相比於沒有命中 projection 的執行計劃減少了 AggregaingNode 的聚合運算。
- Q1 查詢計劃(optimizer_projection_support=0)
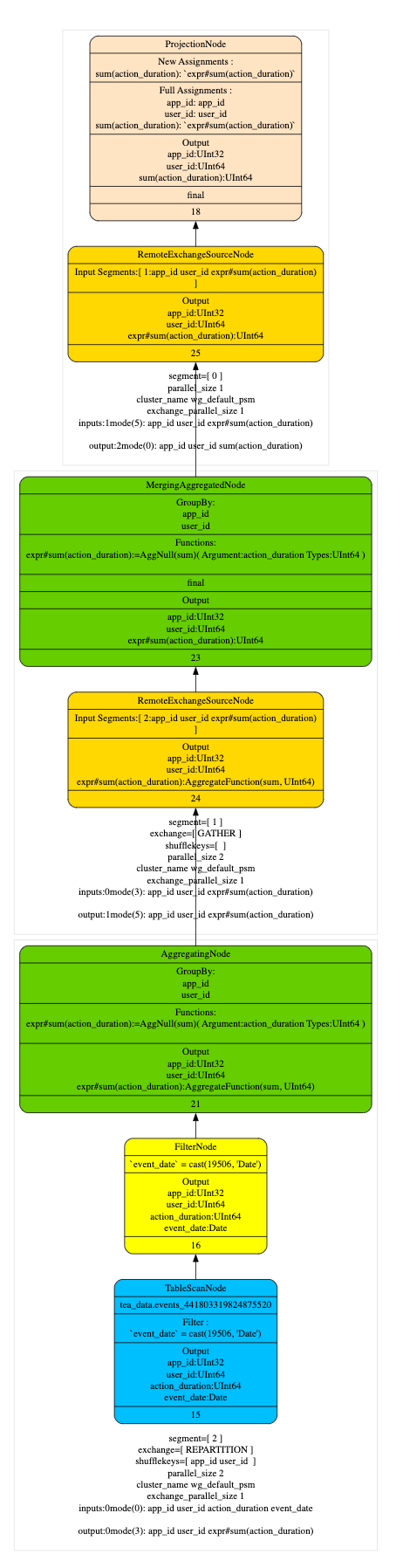
- Q1 查詢計劃(optimizer_projection_support=1)
混合讀取 Projection
Projection 在建立之後不支援更新 schema,只能建立新的 projection,但是在一些對於 projection schema 變更需求頻繁業務場景下,需要同一個查詢既能夠讀取舊 projection 也能讀取新 projection,所以在匹配時需要從 partition 維度進行匹配而不是從 projection 定義的維度進行匹配,混合讀取不同 projection 的資料,這樣會使查詢更加靈活,更好的適應業務場景,下面舉個具體的範例:
建立新的projection
ALTER TABLE tea_data.events ADD PROJECTION agg_sum_proj_2
(
SELECT
app_id,
sum(action_duration),
sum(cost)
GROUP BY app_id
);
寫入2023-05-30的資料
INSERT INTO tea_data.events
SELECT
number / 10,
number % 100,
number % 23,
number % 3434,
number % 23,
number % 55,
'2023-05-30 04:12:43'
FROM system.numbers LIMIT 100000;
執行查詢
Q2:
SELECT
app_id,
sum(action_duration)
FROM tea_data.events
WHERE event_date >= '2023-05-28'
GROUP BY app_id
- Q2 執行計劃
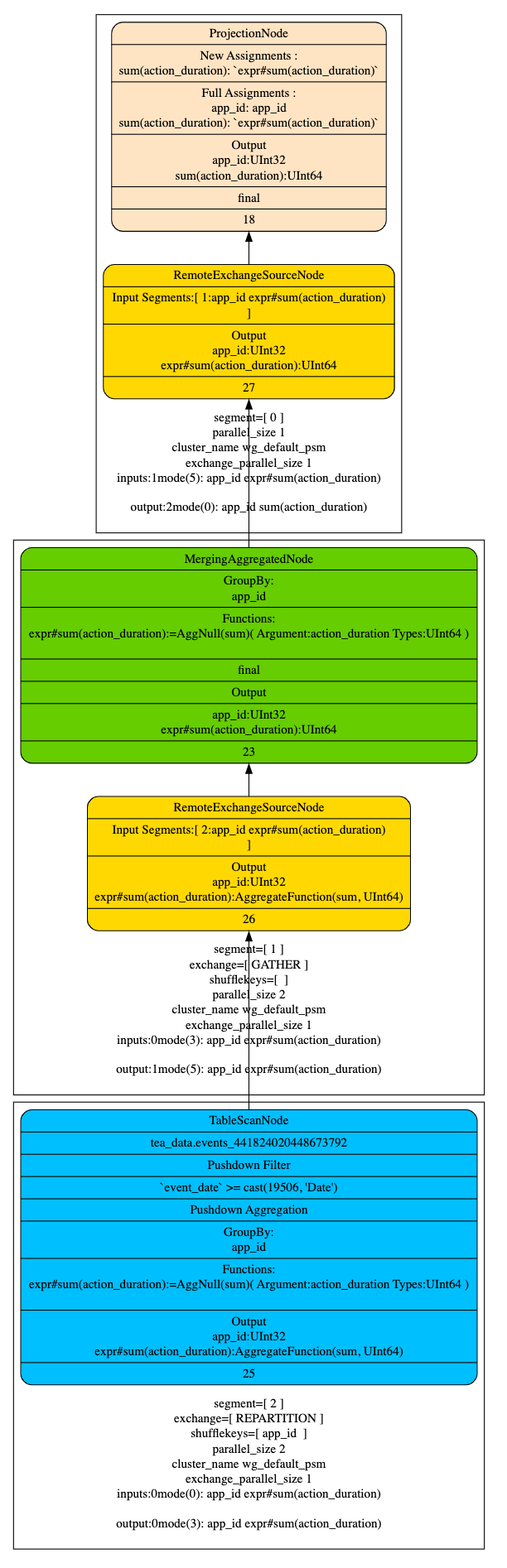
- 按照 partition 來匹配 projection
查詢過濾條件 WHERE event_date >= '2023-05-28' 會讀取是三個分割區的資料, 並且 agg_sum_proj_1, agg_sum_proj_2 都滿足 Q2 的查詢條件,所以 table scan 會讀取 2023-05-28 的原始資料,2023-05-29 會讀取 agg_sum_proj_1 的資料,2023-05-30 由於 agg_sum_proj_2 相對於 agg_sum_proj_1 的資料聚合度更高,讀取代價較小,選擇讀取 agg_sum_proj_2 的資料,混合讀取不同 projection 的資料。

原始表 Schema 更新
當對原始表新增新欄位(維度或指標 ),對應 projection 不包含這些欄位,這時候為了利用 projection 一般情況下需要刪除 projection 重新做物化,比較浪費資源,如果優化器匹配演演算法能正確處理不存在預設欄位,並使用預設值參與計算就可以解決這個問題。
ALTER TABLE tea_data.events ADD COLUMN device_id String after event_type;
ALTER TABLE tea_data.events ADD COLUMN stay_time UInt64 after device_id;
執行查詢
Q3:
SELECT
app_id,
device_id,
sum(action_duration),
max(stay_time)
FROM tea_data.events
WHERE event_date >= '2023-05-28'
GROUP BY app_id,device_id
- Q3 執行計劃
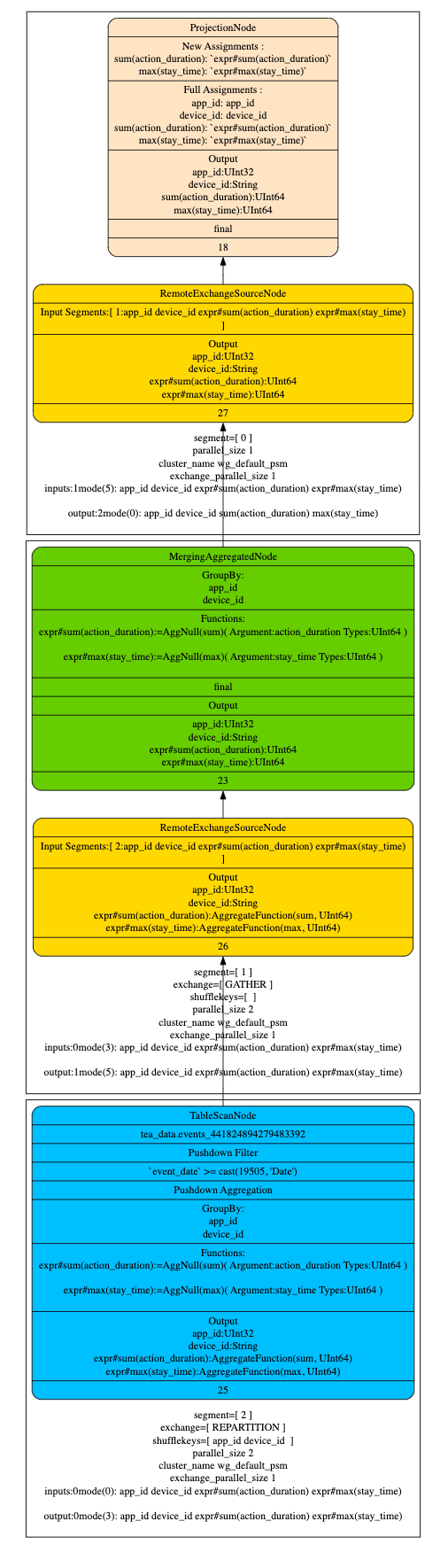
- 預設值參與計算
從查詢計劃可以看出,即使 agg_sum_proj_1 和 agg_sum_proj_2 並不包含新增的維度欄位 device_id,指標欄位 stay_time, 仍然可以命中原始的 partiton 的 projection,並且使用預設值來參與計算,這樣可以利用舊的 projection 進行查詢加速。
Bytehouse Projection 實現
Projection 是按照 Bytehouse 的存算分離架構進行設計的,Projecton 資料由分散式儲存統一進行管理,而針對 projection 的查詢和計算則在無狀態的計算節點上進行。相比於社群版,Bytehouse Projection 實現了以下優勢:
- 對於 Projection 資料的儲存節點和計算節點可以獨立擴充套件,即可以根據不同業務對於 Projection 的使用需求,增加儲存或者計算節點。
- 當進行 Projection 查詢時,可以根據不同 Projection 的資料查詢量來分配計算節點的資源,從而實現資源的隔離和優化,提高查詢效率。
- Projection 的後設資料儲存十分輕量,在業務資料急劇變化的時候,計算節點可以做到業務無感知擴縮容,無需額外的 Projection 資料遷移。

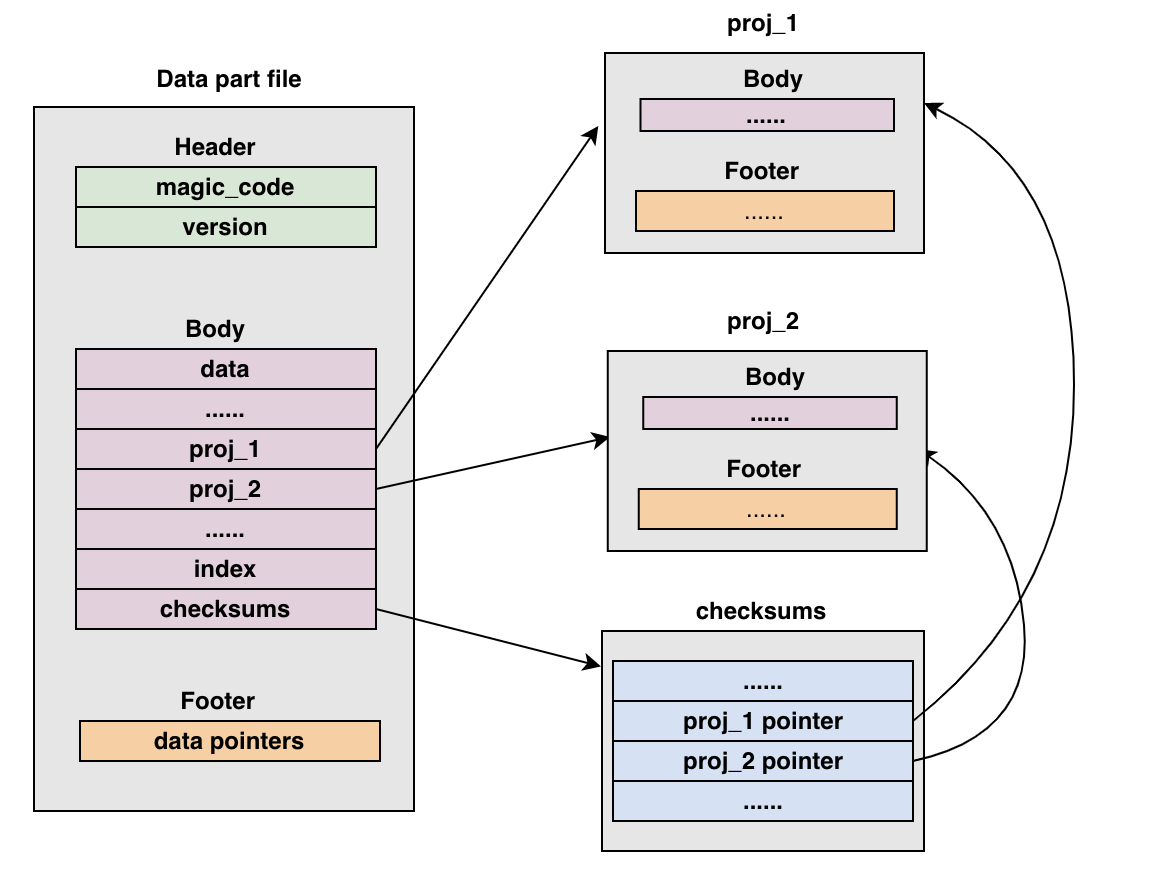
Projection 資料儲存
在 Bytehouse 中,多個 projections 資料與 data 資料儲存在一個共用儲存檔案中。檔案的外部資料對 projections 內部的內容沒有感知,相當於一個黑盒。當需要讀取某個 projection 時,通過 checksums 裡面儲存的 projection 指標,定位到特定 projection 位置,完成 projection 資料解析與載入。
Write 操作
Projection 寫入分為兩部分,先在本地做資料寫入,產生 part 檔案儲存在 worker 節點本地,然後通過 dumpAndCommitCnchParts 將資料 dump 到遠端共用儲存。
- 寫入本地
通過 writeTempPart()將 block 寫入本地,當寫完原始 part 後,迴圈通過方法 addProjectionPart()將每一個 projection 寫入 part 資料夾,並新增到 new_part 中進行管理。 - dump 到遠端儲存
dumpCnchParts()的時候,按照上述的儲存格式,寫入完原始 part 中的 bin 和 mark 資料後,迴圈將每一個 projection 資料夾中的資料寫入到共用儲存檔案中,並記錄位置和大小到 checksums,如下:
寫入 header
寫入 data
寫入 projections
寫入 Primary index
寫入 Checksums
寫入 Metainfo
寫入 Unique Key Index
寫入 data footger
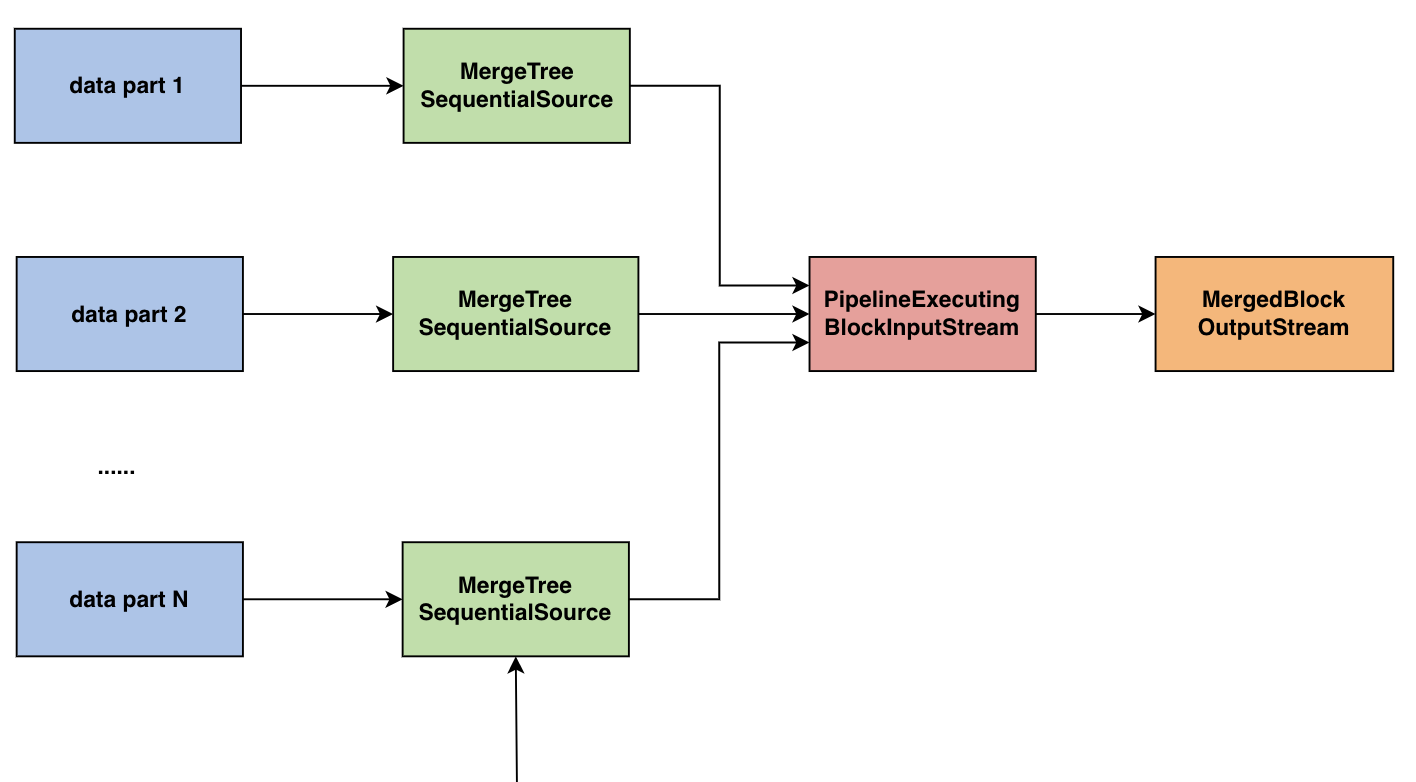
Merge 操作
隨著時間的推移,針對同一個 partition 會存在越來越多的 parts,而 parts 越多查詢過濾時的代價就會越大。因此,Bytehouse 在後臺程序中會 merge 同一個 partition 的 parts 組成更大的 part,從而減少 part 的數量提高查詢的效率。
- 對於每一個要 merge 的 part
對於 part 中的每一列,快取對應的 segments 到本地
建立 MergeTreeReaderStreamWithSegmentCache,通過遠端檔案 buffer 或者本地 segments 的 buffer 初始化 - 通過 MergingSortedTransform 或 AggregatingSortedTransform 等將 sources 融合成 PipelineExecutingBlockInputStream
- 建立 MergedBlockOutputStream
- 對於 projection,進行如下操作
- 建立每一個 projection 的讀取流,本地快取 buffer 或者遠端檔案 buffer
- 原始表 merge 過程,對 parts 中的 projections 進行 merge
- 通過 dumper 將新的完整 part 儲存到遠端
Mutate 操作
Bytehouse 採用 MVCC 的方式,針對 mutate 涉及的列,新增一個 delta part 版本儲存此次 mutate 涉及到的列。相應地,我們在 mutate 的時候,構造 projection 的 mutate 操作的 inputstream,將 mutate 後的 projection 和原始表資料一起寫到同一個 delta part 中。
- 在 MutationsInterpreter 裡面,通過 InterpreterSelectQuery(mutation_ast)獲取 BlockInputStream
- projection 通過 block 和 InterpreterSelectQuery(projection.ast)重新構建
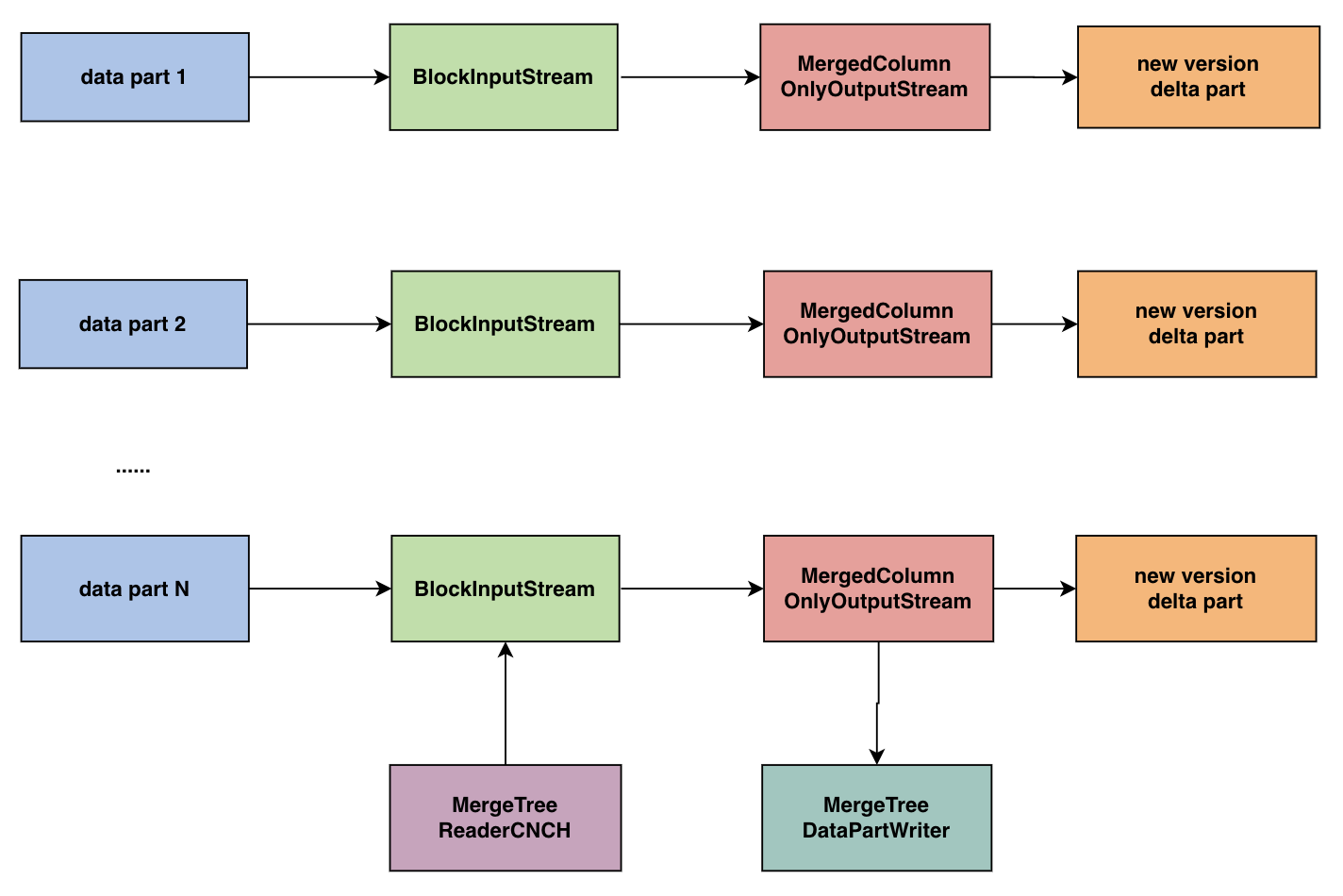
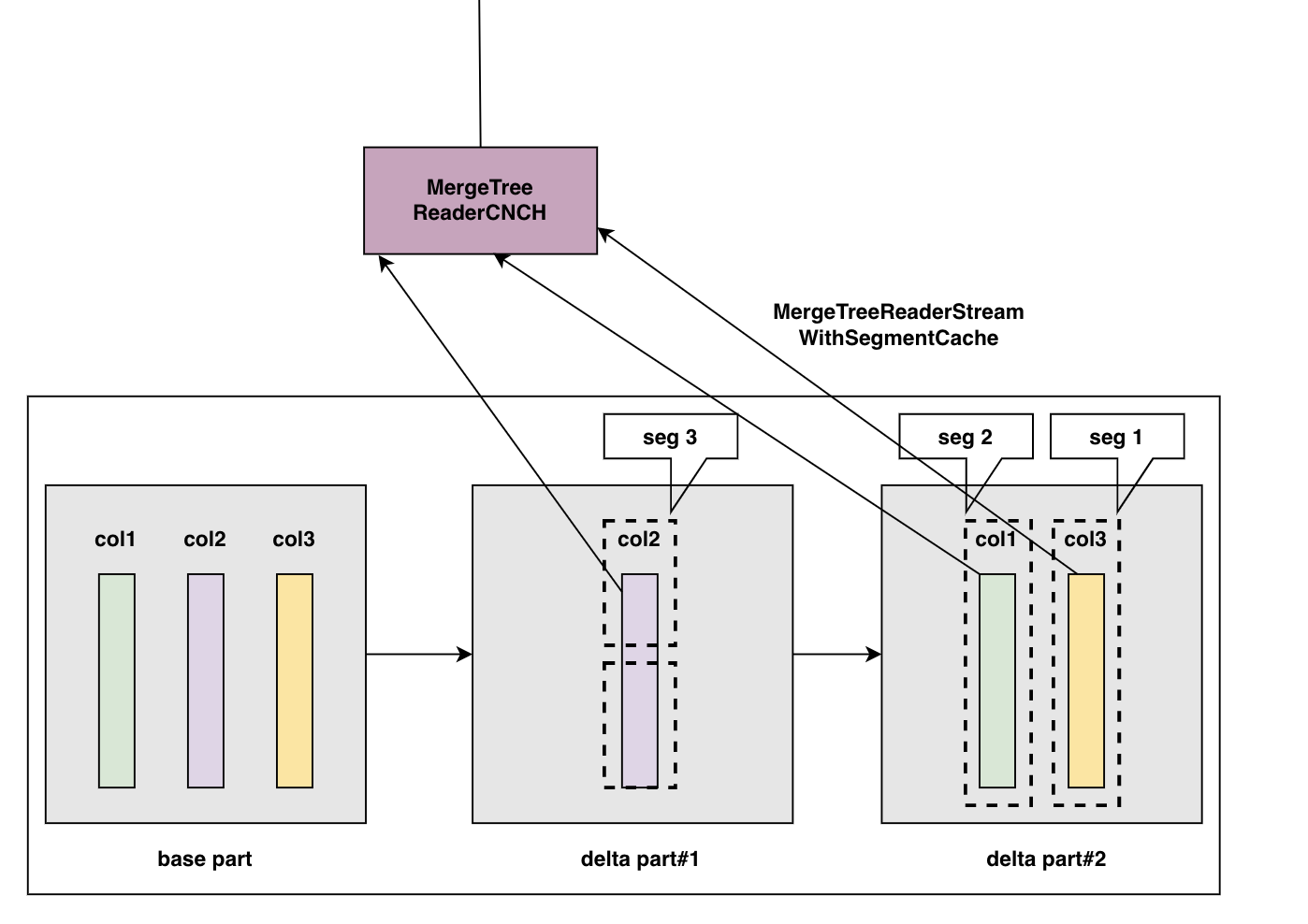
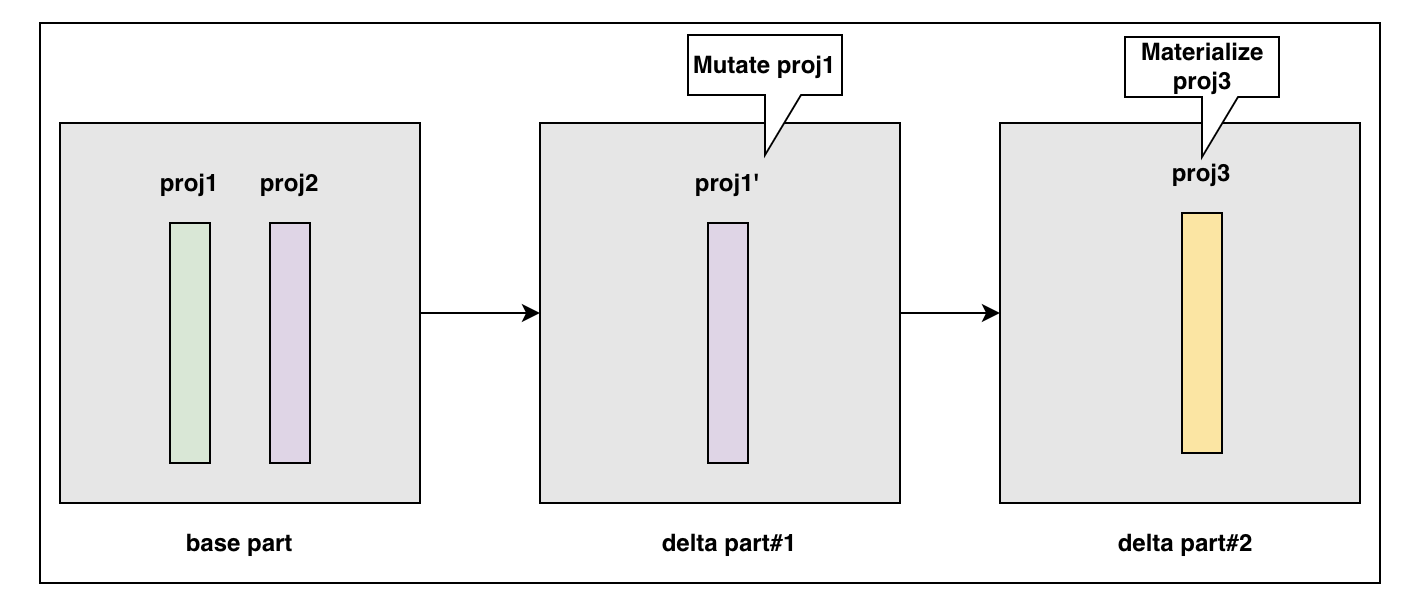
Materialize 物化操作
如下圖所示,根據 Bytehouse 的 part 管理方式,針對 mutate 操作或新增物化操作,我們為 part 生成新的 delta part,在下圖 part 中,它所管理的三個 projections 由 base part 中的 proj2,delta part#1 中的 proj1',以及 delta part#2 中的 proj3 共同構成。當 parts 載入完成後,delta part#2 會儲存 base part 中的 proj2 的指標和 delta part#1 中的 proj1'指標,以及自身的 proj3 指標,對上層提供統一的存取服務。
Worker 端磁碟快取
目前,CNCH 中針對不同資料設計了不同的快取型別
- DiskCacheSegment:管理 bin 和 mark 資料
- ChecksumsDiskCacheSegment:管理 checksums 資料
- PrimaryIndexDiskCacheSegment:管理主鍵索引資料BitMapIndexDiskCacheSegment:管理 bitmap 索引資料
針對 Projection 中的資料,分別通過上述的 DiskCache,ChecksumsDiskCache 和 PrimaryIndexDiskCache 對 bin,mark,checksums 以及索引進行快取。
另外,為了加快 Projection 資料的載入過程,我們新增了 MetaInfoDiskCacheSegment 用於快取 Projection 相關的後設資料資訊。
實際案例分析
某真實使用者場景的資料集,我們利用它對 Projection 效能進行了測試。
該資料集約 1.2 億條,包含 projection 約 240G 大小,測試機器 80CPU(s) / 376G Mem,設定如下:
- SET allow_experimental_projection_optimization = 1
- use_uncompressed_cache = true
- max_threads = 1
- log_level = error
- 開啟 Projection 查詢並行度 80,關閉 Projection 查詢並行度為 30
測試結果
開啟 Projection 後,針對 1.2 億條的資料集,查詢效能提升 10~20 倍。

表結構
CREATE TABLE user.trades(
`type` UInt8,
`status` UInt64,
`block_hash` String,
`sequence_number` UInt64,
`block_timestamp` DateTime,
`transaction_hash` String,
`transaction_index` UInt32,
`from_address` String,
`to_address` String,
`value` String,
`input` String,
`nonce` UInt64,
`contract_address` String,
`gas` UInt64,
`gas_price` UInt64,
`gas_used` UInt64,
`effective_gas_price` UInt64,
`cumulative_gas_used` UInt64,
`max_fee_per_gas` UInt64,
`max_priority_fee_per_gas` UInt64,
`r` String,
`s` String,
`v` UInt64,
`logs_count` UInt32,
PROJECTION tx_from_address_hit
(
SELECT *
ORDER BY from_address
),
PROJECTION tx_to_address_hit (
SELECT *
ORDER BY to_address
),
PROJECTION tx_sequence_number_hit (
SELECT *
ORDER BY sequence_number
),
PROJECTION tx_transaction_hash_hit (
SELECT *
ORDER BY transaction_hash
)
)
ENGINE=CnchMergeTree()
PRIMARY KEY (transaction_hash, from_address, to_address)
ORDER BY (transaction_hash, from_address, to_address)
PARTITION BY toDate(toStartOfMonth(`block_timestamp`));
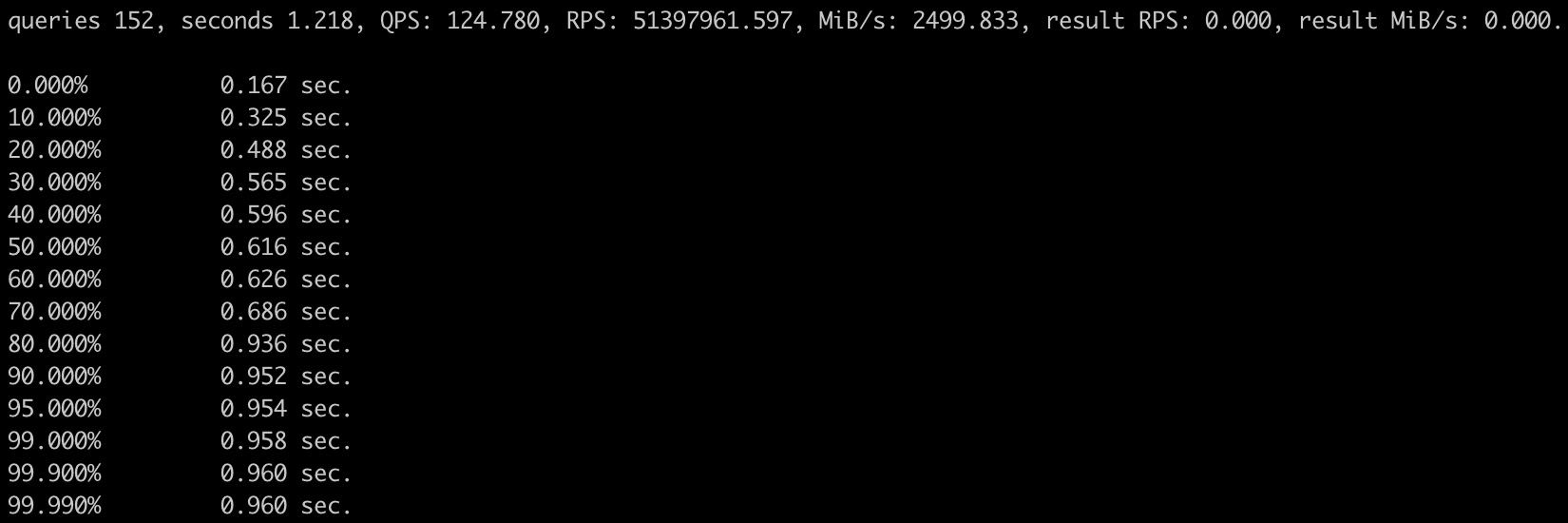
開啟Projection
Q1
WITH tx AS ( SELECT * FROM user.trades WHERE from_address = '0x9686cd65a0e998699faf938879fb' ORDER BY sequence_number DESC,transaction_index DESC UNION ALL SELECT * FROM user.trades WHERE to_address = '0x9686cd65a0e998699faf938879fb' ORDER BY sequence_number DESC, transaction_index DESC ) SELECT * FROM tx LIMIT 100;
Q2

with tx as (select sequence_number, transaction_index, transaction_hash, input from user.trades where from_address = '0xdb03b11f5666d0e51934b43bd' order by sequence_number desc,transaction_index desc UNION ALL select sequence_number, transaction_index, transaction_hash, input from user.trades where to_address = '0xdb03b11f5666d0e51934b43bd' order by sequence_number desc, transaction_index desc) select sequence_number, transaction_hash, substring(input,1,8) as func_sign from tx order by sequence_number desc, transaction_index desc limit 100 settings max_threads = 1, allow_experimental_projection_optimization = 1, use_uncompressed_cache = true;
關閉 Projection
Q1
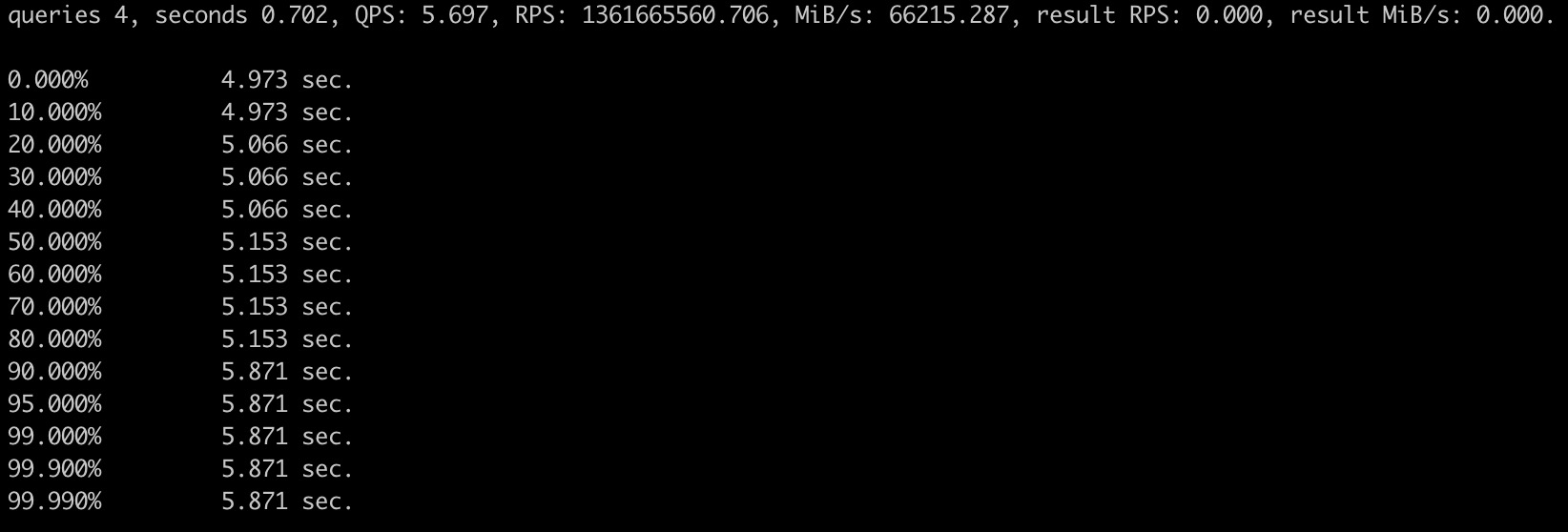
Q2