文盤Rust -- tokio繫結cpu實踐
2023-06-05 15:02:30
tokio 是 rust 生態中流行的非同步執行時框架。在實際生產中我們如果希望 tokio 應用程式與特定的 cpu core 繫結該怎麼處理呢?這次我們來聊聊這個話題。
首先我們先寫一段簡單的多工程式。
use tokio::runtime;
pub fn main() {
let rt = runtime::Builder::new_multi_thread()
.enable_all()
.build()
.unwrap();
rt.block_on(async {
for i in 0..8 {
println!("num {}", i);
tokio::spawn(async move {
loop {
let mut sum: i32 = 0;
for i in 0..100000000 {
sum = sum.overflowing_add(i).0;
}
println!("sum {}", sum);
}
});
}
});
}
程式非常簡單,首先構造一個tokio runtime 環境,然後派生多個 tokio 並行,每個並行執行一個無限迴圈做overflowing_add。overflowing_add函數返回一個加法的元組以及一個表示是否會發生算術溢位的布林值。如果會發生溢位,那麼將返回包裝好的值。然後取元祖的第一個元素列印。
這個程式執行在 Ubuntu 20 OS,4 core cpu。通過nmon的監控如下:
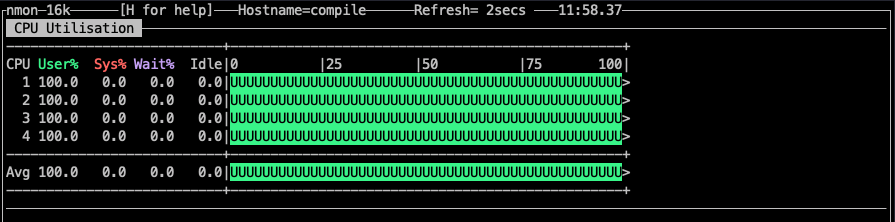
可以看到每個 core 都有負載。
要想把負載繫結在某一 core 上,需要使用core_affinity_rs。core_affinity_rs是一個用於管理CPU親和力的Rust crate。目前支援Linux、Mac OSX和Windows。官方宣稱支援多平臺,本人只做了linux 作業系統的測試。
我們把程式碼修改一下:
use tokio::runtime;
pub fn main() {
let core_ids = core_affinity::get_core_ids().unwrap();
println!("core num {}", core_ids.len());
let core_id = core_ids[1];
let rt = runtime::Builder::new_multi_thread()
.on_thread_start(move || {
core_affinity::set_for_current(core_id.clone());
})
.enable_all()
.build()
.unwrap();
rt.block_on(async {
for i in 0..8 {
println!("num {}", i);
tokio::spawn(async move {
loop {
let mut sum: i32 = 0;
for i in 0..100000000 {
sum = sum.overflowing_add(i).0;
}
println!("sum {}", sum);
}
});
}
});
}
在構建多執行緒runtime時,在on_thread_start 設定cpu親和。可以看到負載被繫結到了指定的core上。
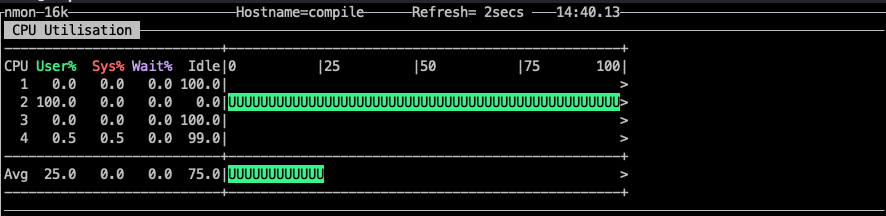
上面的程式碼只是把負載繫結到了一個core上,那麼要繫結多個核怎麼辦呢?
我們看看下面的程式碼
pub fn main() {
let core_ids = core_affinity::get_core_ids().unwrap();
println!("core num {}", core_ids.len());
let rt = runtime::Builder::new_multi_thread()
.enable_all()
.build()
.unwrap();
let mut idx = 2;
rt.block_on(async {
for i in 0..8 {
println!("num {}", i);
let core_id = core_ids[idx];
if idx.eq(&(core_ids.len() - 1)) {
idx = 2;
} else {
idx += 1;
}
tokio::spawn(async move {
let res = core_affinity::set_for_current(core_id);
println!("{}", res);
loop {
let mut sum: i32 = 0;
for i in 0..100000000 {
sum = sum.overflowing_add(i).0;
}
println!("sum {}", sum);
}
});
}
});
}
程式碼需要把所有負載綁在 core3和core4上。原理是在派生任務中加入 core_affinity 設定.通過調整idx,將派生並行平均繫結在指定的core上。程式碼執行的監控如下圖。
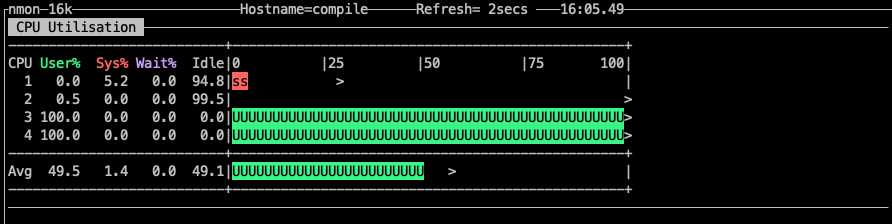
本期關於cpu親和的話題就聊到這兒,下期見
作者:京東科技 賈世聞
來源:京東雲開發者社群