go 實現ringbuffer以及ringbuffer使用場景介紹
ringbuffer因為它能複用緩衝空間,通常用於網路通訊連線的讀寫,雖然市面上已經有了go寫的諸多版本的ringbuffer元件,雖然諸多版本,實現ringbuffer的核心邏輯卻是不變的。但發現其內部提供的方法並不能滿足我當下的需求,所以還是自己造一個吧。
原始碼已經上傳到github
https://github.com/HobbyBear/ringbuffer
需求分析
我在基於epoll實現一個網路框架時,需要預先定義好的和使用者端的通訊協定,當從連線讀取資料時需要判讀當前連線是否擁有完整的協定(實際網路環境中可能完整的協定位元組只到達了部分),有才會將資料全部讀取出來,然後進行處理,否則就等待下次連線可讀時,再判斷連線是否具有完整的協定。
由於在讀取時需要先判斷當前連線是否有完整協定,所以讀取時不能移動讀指標的位置,因為萬一協定不完整的話,下次讀取還要從當前的讀指標位置開始讀取。
所以對於ringbuffer 元件我會實現一個peek方法
func (r *RingBuffer) Peek(readOffsetBack, n int) ([]byte, error)
peek方法兩個引數,n代表要讀取的位元組數, readOffsetBack 代表讀取是要在當前讀位置偏移的位元組數,因為在設計協定時,往往協定不是那麼簡單(可能是由多個固定長度的資料構成) ,比如下面這樣的協定格式。

完整的協定有三段構成,每段開頭都會有一個4位元組的大小代表每段的長度,在判斷協定是否完整時,就必須看著3段的資料是否都全部到達。 所以在判斷第二段資料是否完整時,會跳過前面3個位元組去判斷,此時readOffsetBack 將會是3。
此外我還需要一個通過分割符獲取位元組的方法,因為有時候協定不是固定長度的陣列了,而是通過某個分割符判斷某段協定是否結束,比如換行符。
func (r *RingBuffer) PeekBytes(readOffsetBack int, delim byte) ([]byte, error)
接著,還需要提供一個更新讀位置的方法,因為一旦判斷是一個完整的協定後,我會將協定資料全部讀取出來,此時應該要更新讀指標的位置,以便下次讀取新的請求。
func (r *RingBuffer) AddReadPosition(n int)
n 便是代表需要將讀指標往後偏移的n個位元組。
ringbuffer 原理解析
接著,我們再來看看實際上ringbuffer的實現原理是什麼。
首先來看下一個ringbuffer應該有的屬性
type RingBuffer struct {
buf []byte
reader io.Reader
r int // 標記下次讀取開始的位置
unReadSize int // 緩衝區中未讀資料大小
}
buf 用作連線讀取的緩衝區,reader 代表了原連結,r代表讀取ringbuffer時應該從位元組陣列的哪個位置開始讀取,unReadSize 代表緩衝區當中還有多少資料沒有讀取,因為你可能一次性從reader裡讀取了很多資料到buf裡,但是上層應用只取buf裡的部分資料,剩餘的未讀資料就留在了buf裡,等待下次被應用層繼續讀取。
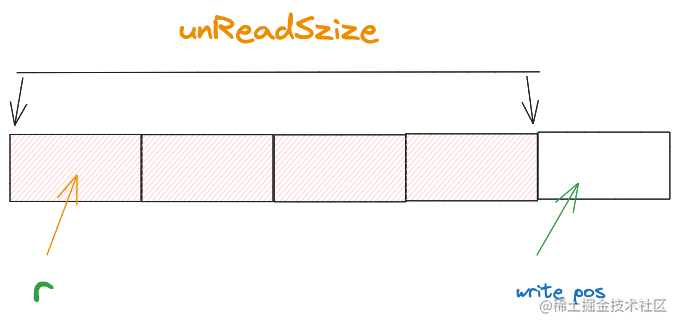
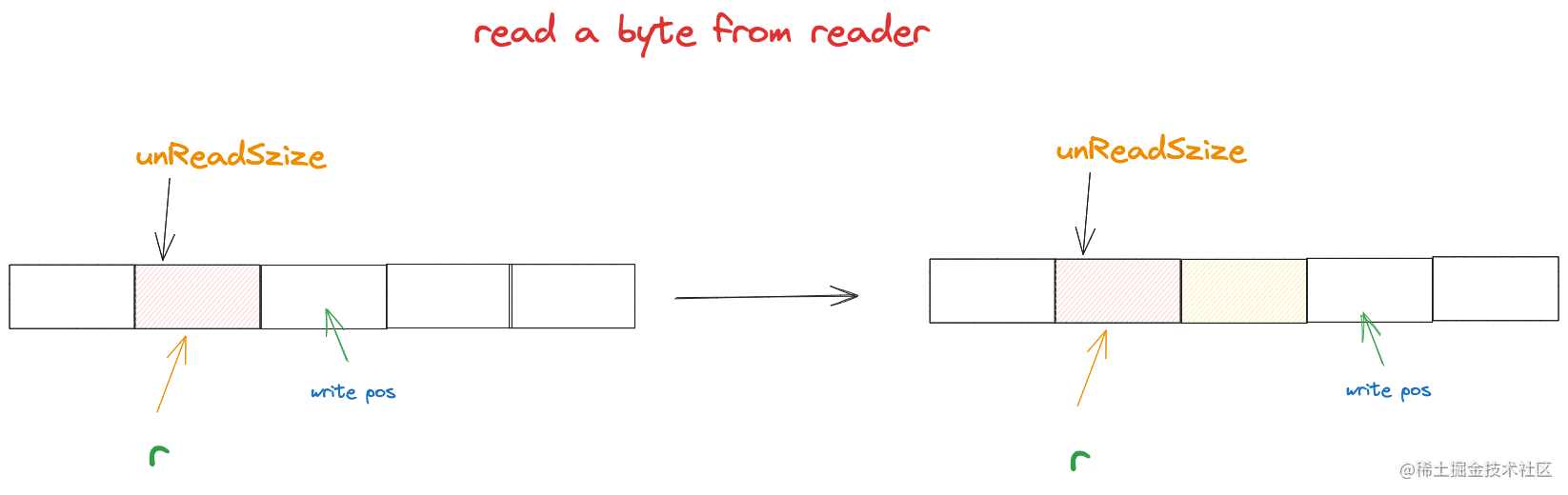
我們用一個5位元組的位元組陣列當做緩衝區, 首先從ringbuffer讀取資料時,由於ringbuffer內部沒有資料,所以需要從連線中讀取資料然後寫到ringbuffer裡。
如下圖所示:
假設ringBuffer規定每次向原網路連線讀取時 按4位元組讀取到緩衝區中(實際情況為了減少系統呼叫開銷,這個值會更多,儘可能會一次性讀取更多資料到緩衝區) write pos 指向的位置則代表從reader讀取的資料應該從哪個位置開始寫入到buf位元組陣列裡。
writePos = (r + unReadSize) % len(buf)
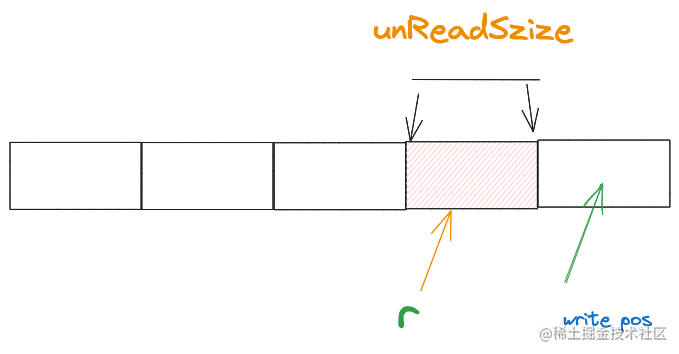
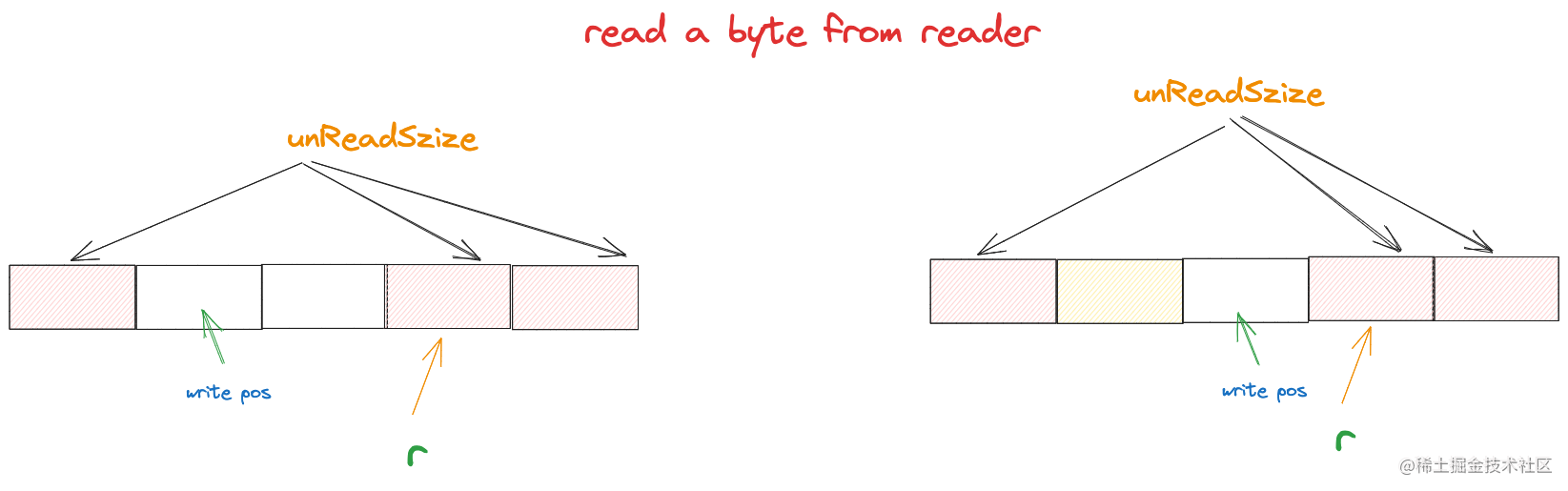
接著,上層應用唯讀取了3個位元組,緩衝區中的讀指標r和未讀空間就會變成下面這樣
如果此時上層應用還想再讀取3個位元組,那麼ringbuffer就必須再向reader讀取位元組填充到緩衝區上,我們假設這次向reader索取3個位元組。緩衝區的空間就會變成下面這樣
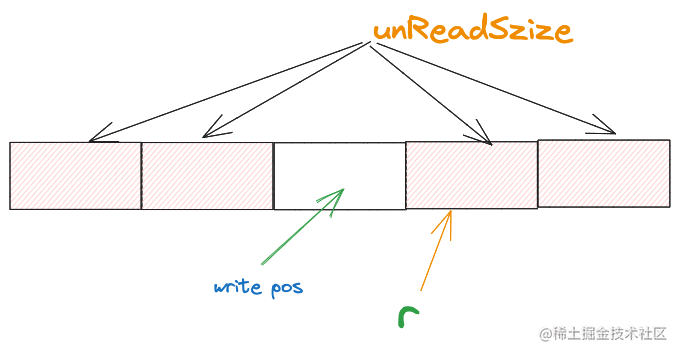
此時已經複用了首次向reader讀取資料時佔據的緩衝空間了。
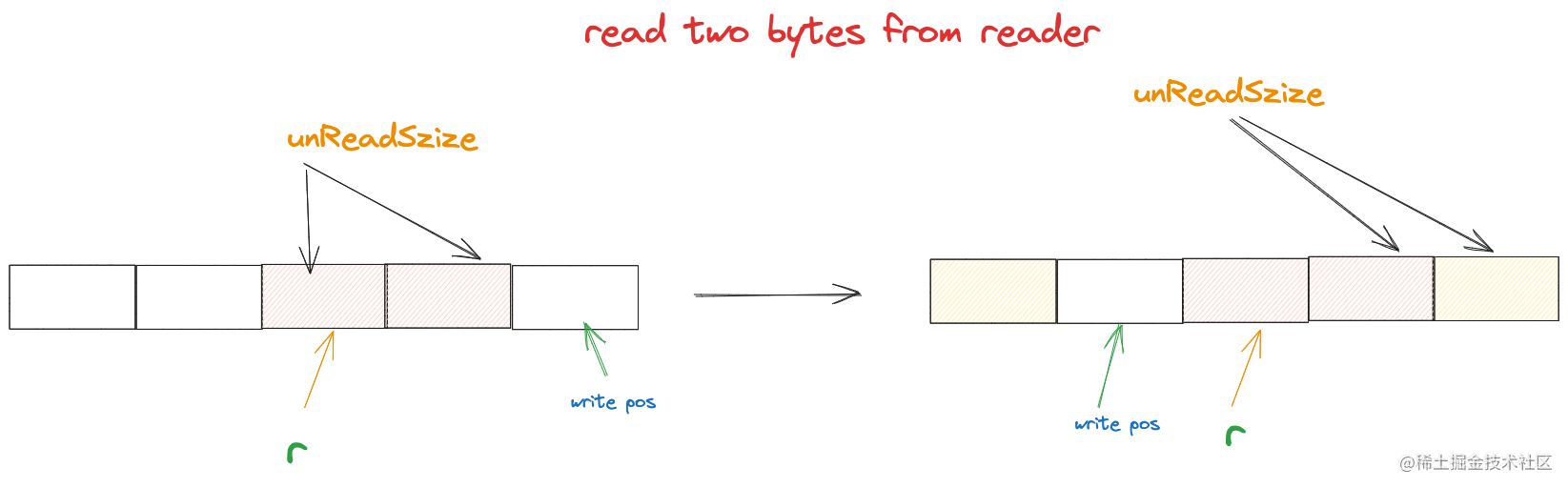
當填充上位元組後,應用層繼續讀取3個位元組,那麼ringBuffer會變成這樣
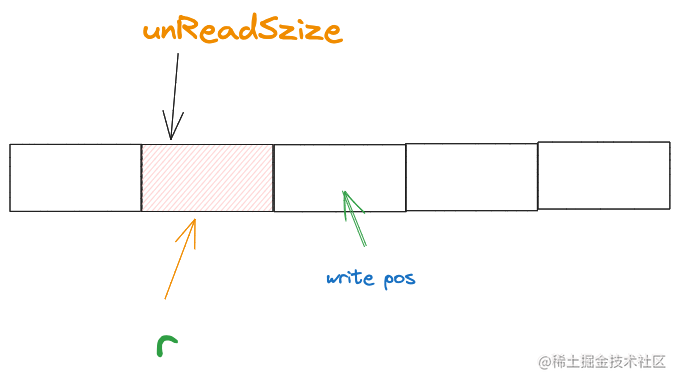
讀指標又指向了陣列的開頭了,可以得出讀指標的計算公式
r = (r + n)% len(buf)
ringBuffer 程式碼解析
有了前面的演示後,再來看程式碼就比較容易了。用peek 方法舉例進行分析,
func (r *RingBuffer) Peek(readOffsetBack, n int) ([]byte, error) {
// 由於目前實現的ringBuffer還不具備自動擴容,所以不支援讀取的位元組數大於緩衝區的長度
if n > len(r.buf) {
return nil, fmt.Errorf("the unReadSize is over range the buffer len")
}
peek:
if n <= r.UnReadSize()-readOffsetBack {
// 說明緩衝區中的未讀位元組數有足夠長的n個位元組,從buf緩衝區直接讀取
readPos := (r.r + readOffsetBack) % len(r.buf)
return r.dataByPos(readPos, (r.r+readOffsetBack+n-1)%len(r.buf)), nil
}
// 說明緩衝區中未讀位元組數不夠n個位元組那麼長,還需要從reader裡讀取資料到緩衝區中
err := r.fill()
if err != nil {
return nil, err
}
goto peek
}
peek方法的大致邏輯是首先判斷要讀取的n個位元組能不能從緩衝區buf裡直接讀取,如果能則直接返回,如果不能,則需要從reader裡繼續讀取資料,直到buf緩衝區資料夠n個位元組那麼長。
dataByPos 方法是根據傳入的元素位置,從buf中讀取在這個位置區間內的資料。
// dataByPos 返回索引值在start和end之間的資料,閉區間
func (r *RingBuffer) dataByPos(start int, end int) []byte {
// 因為環形緩衝區原因,所以末位置索引值有可能小於開始位置索引
if end < start {
return append(r.buf[start:], r.buf[:end+1]...)
}
return r.buf[start : end+1]
}
fill() 方法則是從reader中讀取資料到buf裡。
fill 情況分析
reader填充新資料到buf後,未讀空間未跨越buf末尾
當從reader讀取完資料後,如果 end := r.r + r.unReadSize + readBytes end指向了未讀空間的末尾,如果沒有超過buf的長度,那麼將資料複製到buf裡的邏輯很簡單,直接在當前write pos的位置追加讀取到的位元組就行。
// 此時writePos 沒有超過 len(buf)
writePos = (r + unReadSize)
未讀 空間 本來就 已經從頭覆蓋
當未讀空間本來就重新覆蓋了buf頭部,和上面類似,這種情況也是直接在write pos 位置追加資料即可。
未讀空間未跨越buf末尾,當從reader追加資料到buf後發現需要覆蓋buf頭部
這種情況需要將讀取的資料一部分覆蓋到buf的末尾
writePos := (r.r + r.unReadSize) % len(r.buf)
n := copy(r.buf[writePos:], buf[:readBytes])
一部分覆蓋到buf的頭部
end := r.r + r.unReadSize + readBytes
copy(r.buf[:end%len(r.buf)], buf[len(r.buf)-writePos:])
現在再來看fill的原始碼就比較容易理解了。
func (r *RingBuffer) fill() error {
if r.unReadSize == len(r.buf) {
// 當未讀資料填滿buf後 ,就應該等待上層應用把未讀資料讀取一部分再來填充緩衝區
return fmt.Errorf("the unReadSize is over range the buffer len")
}
// batchFetchBytes 為每次向reader裡讀取多少個位元組,如果此時buf的剩餘空間比batchFetchBytes小,則應該只向reader讀取剩餘空間的位元組數
readLen := int(math.Min(float64(r.batchFetchBytes), float64(len(r.buf)-r.unReadSize)))
buf := make([]byte, readLen)
readBytes, err := r.reader.Read(buf)
if readBytes > 0 {
// 檢視讀取readBytes個位元組後,未讀空間有沒有超過buf末尾指標,如果超過了,在複製資料時需要特殊處理
end := r.r + r.unReadSize + readBytes
if end < len(r.buf) {
// 沒有超過末尾指標,直接將資料copy到writePos後面
copy(r.buf[r.r+r.unReadSize:], buf[:readBytes])
} else {
// 超過了末尾指標,有兩種情況,看下圖分析
writePos := (r.r + r.unReadSize) % len(r.buf)
n := copy(r.buf[writePos:], buf[:readBytes])
if n < readBytes {
copy(r.buf[:end%len(r.buf)], buf[len(r.buf)-writePos:])
}
}
r.unReadSize += readBytes
return nil
}
if err != nil {
return err
}
return nil
}