GPT大模型下,如何實現網路自主防禦
GPT大模型下,如何實現網路自主防禦
近年來,隨著GPT大模型的出現,安全領域的攻防對抗變得更加激烈。RSAC2023人工智慧安全議題重點探討了人工智慧安全的最新發展,包括人工智慧合成器安全、安全機器學習以及如何利用滲透測試和強化學習技術來確保人工智慧模型的安全性和可靠性。
人工智慧合成器(AI Synthesizers)是一種新型的技術,它可以產生與人類相同的內容,GPT便是其代表技術。
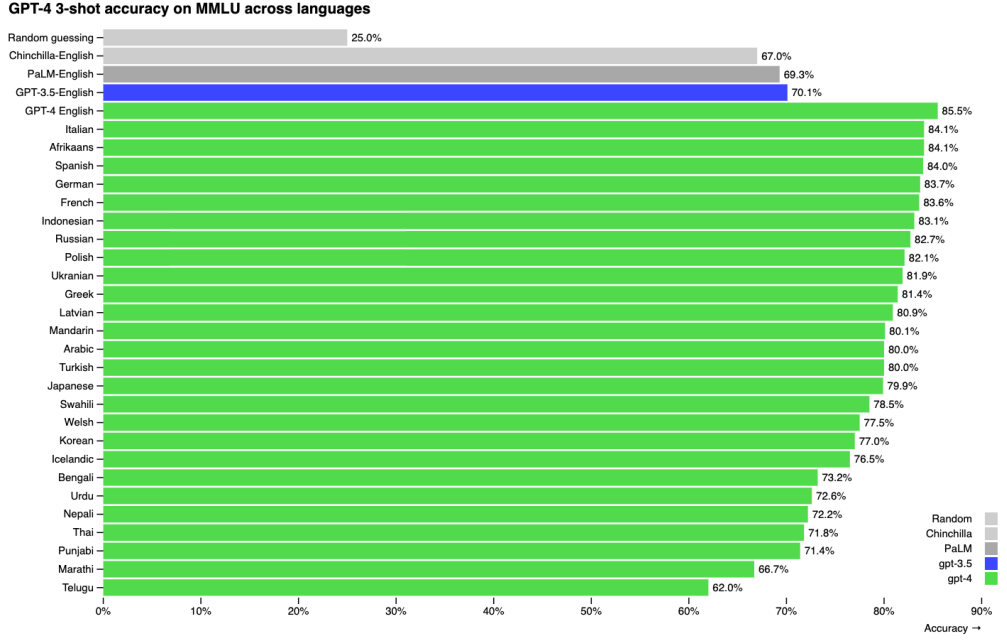
圖1-1 GPT4在MMLU(Massive Multitask Language Understanding,大規模多工語言理解)上的精度超越了GPT3.5
新型的技術總是會有一定的安全風險,對於人工智慧合成器來說也不例外。
伴隨社交媒體的普及,錯誤資訊、仇恨言論和欺詐等威脅資訊正在加劇,因此,檢測各種社交媒體平臺上的影響力活動變得尤為重要。同時由於GPT的出現,使得基於AI生成虛假內容的檢測變得更加困難。在《Russia's RT Leads Global Disinformation to Bypass Censorship on Ukraine》話題中,作者檢測到從2022年4月至今,俄羅斯RT社交媒體通過利用AI生成賬號在Telegram、Twitter和新興的平臺上發表了20多種語言的虛假資訊。
在《Security Implications of Artificial Intelligence Synthesizers》話題中,提到使用AI大模型的風險包括資料投毒、prompt注入、資料洩露、釣魚、程式碼合成等。

圖1-2 ChatGPT prompt注入範例
在《Pentesting AI How to Hunt a Robot》話題中,同樣提及了GPT大模型的注入攻擊和AI模型的後門植入。
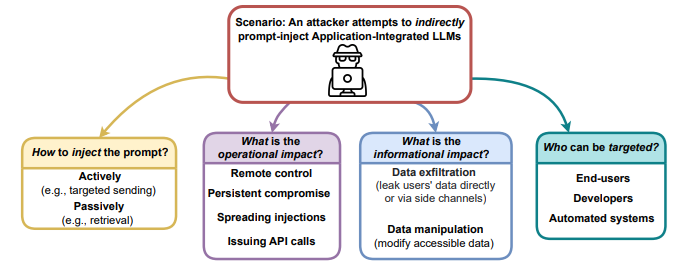
圖1-3 注入攻擊
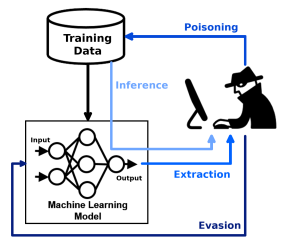
圖1-4 在AI模型中植入無法檢測的後門
在《Do Attackers Use Algorithms To Evade ML》話題中,探討了攻擊者是否使用演演算法規避ML(Machine Learning,機器學習)?答案是YES!
在《Stay Ahead of Adversarial AI in OT ICS Environments Mitigating the Impact》中,針對OT(Operational Technology,運營技術)/ICS(Industrial Control System,工業控制系統)環境中可能面臨的惡意AI攻擊,最佳的預防措施是遵循主動規劃、強調安全,通過測試和加固ML系統來有效地實施防禦措施,在AI/ML的開發過程的幾個重要階段進行安全保護,使之能夠具備先進的抗對抗性攻擊效能。
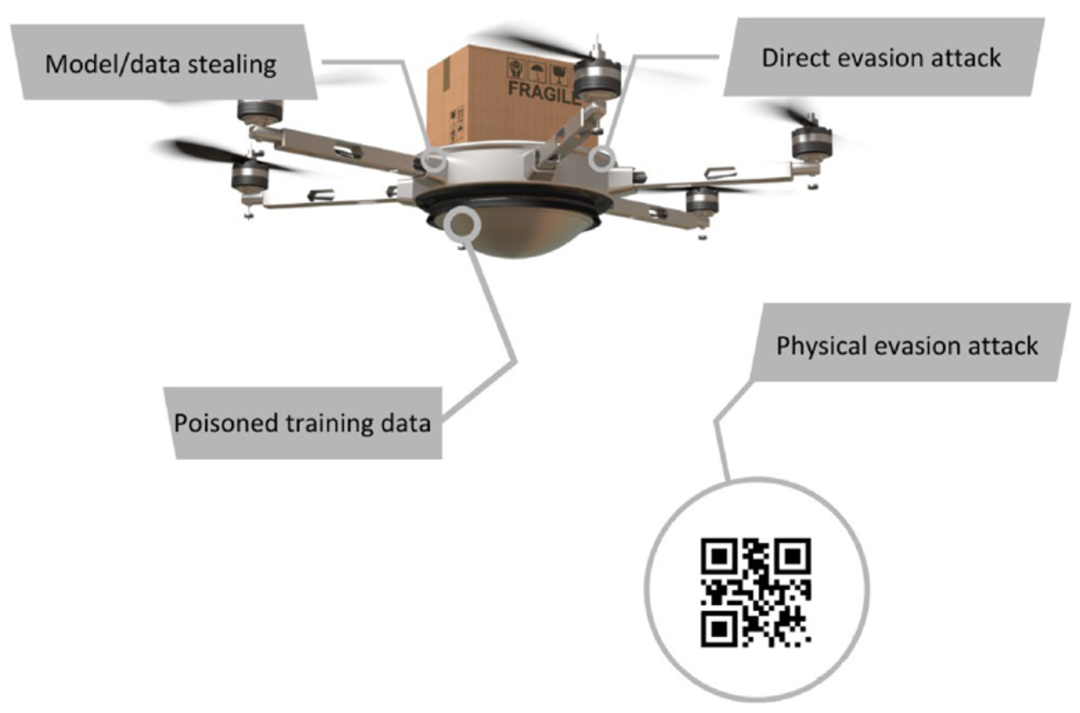
圖1-7 安全分析人員利用社交圖譜發現brazilianspring
為了簡化圖AI演演算法的應用,誕生了DS4N6這樣一個開源專案,旨在幫助資料科學家們更有效地進行資料科學實踐。它提供了一系列模組,允許資料科學家們以更簡單的方式去組織、管理和視覺化資料科學實踐。
在《Hunting Stealth Adversaries with Graphs AI》話題中,DS4N6提出了一種用來檢測隱蔽的橫移攻擊的圖AI演演算法,這就是基於圖資料結構的神經網路。

圖1-8 使用圖AI演演算法來檢測橫移攻擊
以智慧對抗智慧,利用強化學習實現網路自主防禦
隨著攻防對抗更加激烈,以智慧對抗智慧是數位化時代下的安全趨勢。
在《Reinforcement Learning for Autonomous Cyber Defense》話題中,專門探討了如何利用強化學習,實現自主網路防禦。作者提出網路防禦強化學習的目的是創造一個自主作用的代理(強化學習Agent),能夠做出一系列在不確定性場景下的安全決策。
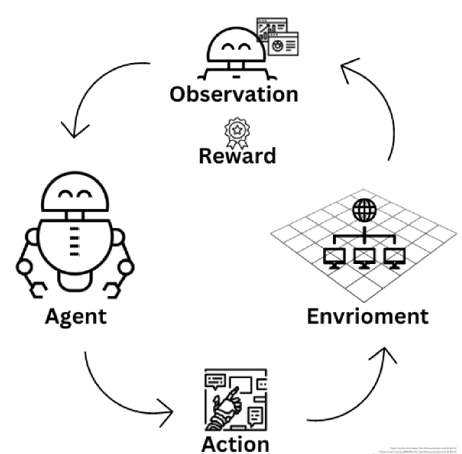
圖1-9 強化學習Agent

圖1-11 網路安全強化學習框架
其中,最受人關注的是CyberBattleSim,CyberBattleSim是微軟釋出的一個實驗研究平臺,用於研究自動代理在模擬抽象企業網路環境中的相互作用。該平臺提供了計算機網路和網路安全概念的高層抽象,其基於Python的Open AI Gym介面,可用於使用強化學習演演算法訓練自動代理。
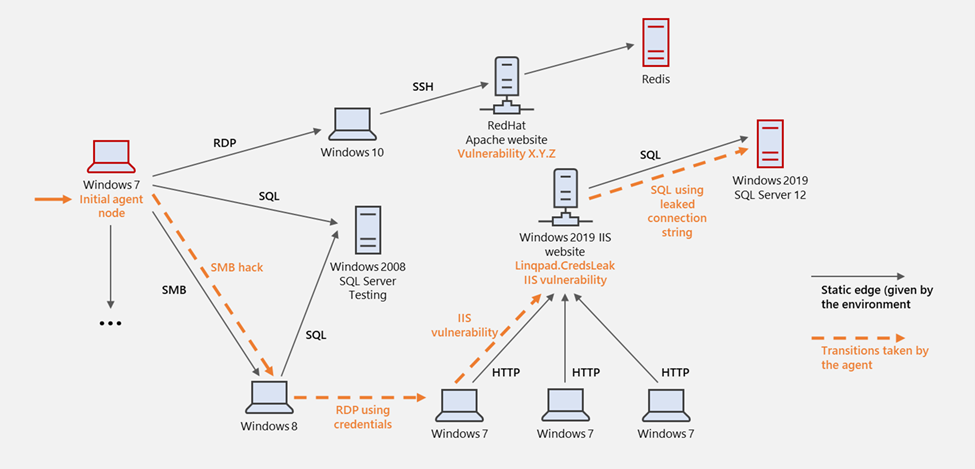
圖1-12 CyberBattleSim模擬橫移攻擊
針對以上橫移攻擊場景,攻擊者的目標是通過利用植入計算機節點中的漏洞來擁有網路的一部分資源。當攻擊者試圖在網路中傳播時,防禦代理會監視網路活動,並嘗試檢測發生的任何攻擊以減輕系統受到的影響,然後驅逐攻擊者。平臺提供了基本的隨機防禦,該防禦基於預定義的成功概率來檢測和減輕正在進行的攻擊。
結束語
隨著人工智慧合成器技術的發展,尤其是GPT大模型的出現,攻防對抗變得日益激烈。例如,利用人工智慧合成器生成錯誤資訊、仇恨言論和欺詐等威脅資訊正在加劇,使得檢測各種社交媒體平臺上的影響力活動變得尤為重要又極具挑戰,圖AI演演算法識別社群網路濫用和高階威脅就是一種有效的檢測手段。GPT大模型的注入攻擊和AI模型的後門植入,使得人工智慧滲透測試勢在必行,以降低人工智慧模型在潛在惡意程式碼方面的風險。智慧對抗智慧是數位化時代下的安全趨勢,利用強化學習實現網路自主防禦,是未來充滿挑戰而又值得期待的一個重要技術方向。
參考文獻
本文作者對如下RSAC議題進行了深度解讀,並參照了文中的圖片,圖片版權歸原作者所有。本文僅供參考和學習,不構成任何投資或其他建議。作者不承擔任何因使用本文所引起的直接或間接損失或法律責任。如有侵權,請聯絡作者刪除。
-
《Russia's RT Leads Global Disinformation to Bypass Censorship on Ukraine》
-
《Security Implications of Artificial Intelligence Synthesizers》
-
《Pentesting AI How to Hunt a Robot》
-
《Do Attackers Use Algorithms To Evade ML》
-
《Stay Ahead of Adversarial AI in OT ICS Environments Mitigating the Impact》
-
《Hardening AI ML Systems The Next Frontier of Cybersecurity》
-
《Detecting Influence Campaigns Across Social Media Platforms》
-
《Reinforcement Learning for AutonosCyber Defense》