Apache Hudi 1.x 版本重磅功能展望與討論
Apache Hudi 社群正在對Apache Hudi 1.x版本功能進行討論,歡迎感興趣同學參與討論,PR連結:https://github.com/apache/hudi/pull/8679/files
摘要
此 RFC 提議對 Hudi 中的事務資料庫層進行令人興奮和強大的重構,以推動未來幾年整個社群的持續創新。 在過去的幾年裡,社群成長(https://git-contributor.com/?chart=contributorOverTime&repo=apache/hudi)) 超過 6 倍的貢獻者,這個 RFC 是圍繞核心願景澄清和調整社群的絕佳機會。 此 RFC 旨在作為此討論的起點,然後徵求反饋、接受新想法並共同作業建立共識,以實現有影響力的 Hudi 1.X 願景,然後提煉出構成第一個版本——Hudi 1.0 的內容。
專案狀態
眾所周知,Hudi 最初於 2016 年在 Uber 建立,用於解決 大規模資料攝取](https://www.uber.com/blog/uber-big-data-platform/)) 和 [增量資料處理] ](https://www.uber.com/blog/ubers-lakehouse-architecture/)) 問題,後來 捐贈](https://www.uber.com/blog/apache-hudi/)) 給 ASF。自 2020 年作為頂級 Apache 專案畢業以來,社群在 [流資料湖願景](https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform),通過在一組強大的平臺元件之上進行增量處理,使資料湖更加實時和高效。最新的 0.13 彙集了幾個顯著的功能來增強增量資料管道,包括 [RFC-51 Change Data Capture](https://github.com/apache/hudi/blob/master/rfc/rfc-51/rfc- 51.md),更高階的索引技術consistent hash indexes](https://github.com/apache/hudi/blob/master/rfc/rfc-42/rfc-42.md)) 和諸如 早期衝突檢測](https://github.com/apache/hudi/blob/master/rfc/rfc-56/rfc-56.md)) 之類的創新。
如今 Hudi 使用者](https://hudi.apache.org/powered-by)) 能夠使用 Hudi 作為資料湖平臺解決終端用例,該平臺在可互操作的開放儲存格式之上提供大量自動化。使用者可以從檔案/流系統/資料庫中增量攝取,並將該資料插入/更新/刪除到 Hudi 表中,並提供多種高效能索引選擇。由於記錄級後設資料和增量/CDC 查詢等核心設計選擇,藉助強大的流處理支援,使用者能夠始終如一地將攝取的資料連結到下游管道,近年來在 Apache Spark、Apache Flink 和 Kafka Connect 等框架中。 Hudi 表格服務會自動處理這些攝取和派生的資料,以管理表格簿記、後設資料和儲存佈局的不同方面。最後,Hudi 對不同目錄的廣泛支援和跨各種查詢引擎的廣泛整合意味著 Hudi 表也可以「批次」處理老式風格或從互動式查詢引擎存取。
未來的機會
我們一直在 0.x 版本中新增新功能,但我們也可以將 Hudi 的核心變成更通用的湖資料庫體驗。 作為 lakehouse 的第一個實現(我們稱之為「交易資料湖」或「流資料湖」,分別是倉庫使用者和資料工程師的語言),我們根據當時的生態系統做了一些保守的選擇。 然而,重新審視這些選擇很重要,以便看看它們是否仍然有效。
- 深度查詢引擎整合: 當時 Presto、Spark、Flink、Trino 和 Hive 等查詢引擎擅長查詢列式資料檔案,但很難整合到其中。 隨著時間的推移,我們期望清晰的 API 抽象圍繞 parquet/orc 讀取路徑中的索引/後設資料/錶快照,像 Hudi 這樣的專案可以利用這些路徑輕鬆利用像 Velox/PrestoDB 這樣的創新。 然而大多數引擎更喜歡單獨的整合——這導致 Hudi 維護自己的 Spark 資料來源,Presto 和 Trino 聯結器。 然而現在這為在查詢計劃和執行期間充分利用 Hudi 的多模式索引功能提供了機會。
- 廣義資料模型: 雖然 Hudi 支援主鍵,但我們專注於更新 Hudi 表,就好像它們是鍵值儲存一樣,而 SQL 查詢在上面執行,保持不變並且無感知。 當時根據生態系統的位置推廣對主鍵的支援還為時過早,因為生態系統仍在執行大批次 MR 作業。 如今,Apache Spark 和 Apache Flink 等效能更高的高階引擎具有成熟的可延伸 SQL 支援,可以支援 Hudi 表的通用關係資料模型。
- 有伺服器和無伺服器:資料湖歷來都是關於定期或按需觸發的作業。 儘管許多後設資料擴充套件挑戰可以通過精心設計的元伺服器來解決(類似於現代雲倉庫所做的),社群一直對除了資料目錄或 Hive 元伺服器之外的長期執行服務猶豫不決。 事實上我們的時間線伺服器由於社群缺乏共識工作停滯不前。 然而隨著並行控制等需求的發展,出現了圍繞開放格式的這些問題的專有解決方案。 現在可能是時候通過採用混合架構來為社群轉向真正開放的解決方案了,在該架構中,我們為表後設資料使用伺服器元件,同時為資料保留無伺服器。
- 除了結構化資料:即使我們解決了有關在 parquet/avro/orc 中攝取、儲存、管理和轉換資料的挑戰,仍然有大多數其他資料無法從這些功能中受益。 使用 Hudi 的 HFile 表進行 ML 模型服務是一個新興的用例,使用者希望以低成本、輕量級的方式直接從湖儲存中提供計算資料。 通常,非結構化資料,如 JSON 和 blob類似的影象必須使用某種結構進行偽建模,從而導致效能或可管理性不佳。 隨著近年來 AI/ML 的迅速崛起,像 Hudi 這樣的專案缺乏對複雜、非結構化、大 blob 的支援,只會讓資料碎片化在湖泊中。為此,我們需要支援所有主要的影象、視訊和 ML/AI 格式,並在索引、變互斥或捕獲變化方面具有相同深度的功能。
- 更強大的自我管理:Hudi 在開源資料湖管理方面提供了當今最廣泛的功能集,從攝取資料到優化資料以及自動化各種簿記活動以自動管理表資料和後設資料。 看到社群如何使用這個管理層來提升他們的資料湖體驗令人印象深刻。
但是,我們有很多功能要新增,例如,反向流資料到其他系統或快照管理](https://github.com/apache/hudi/pull/6576/files))或[診斷報告器](https://github.com/apache/hudi/pull/6600)或跨地域邏輯複製或記錄級 生存時間管理](https://github.com/apache/hudi/pull/8062))
Hudi 1.X
鑑於我們更像是一個資料庫問題來處理 Hudi,因此 Hudi 有許多構成資料庫的構建塊也就不足為奇了。 從開創性的資料庫系統架構論文(參見第 4 頁)中繪製基線,我們可以看到 Hudi 如何構成針對湖優化的資料庫的下半部分,具有多個查詢引擎層 - SQL、程式設計存取、專門用於 ML /AI、實時分析和其他引擎處於領先地位。 下面的主要區域直接對映了我們如何跟蹤 Hudi 路線圖。 我們將看到我們如何專門針對資料湖的規模和湖工作負載的特徵調整這些元件。
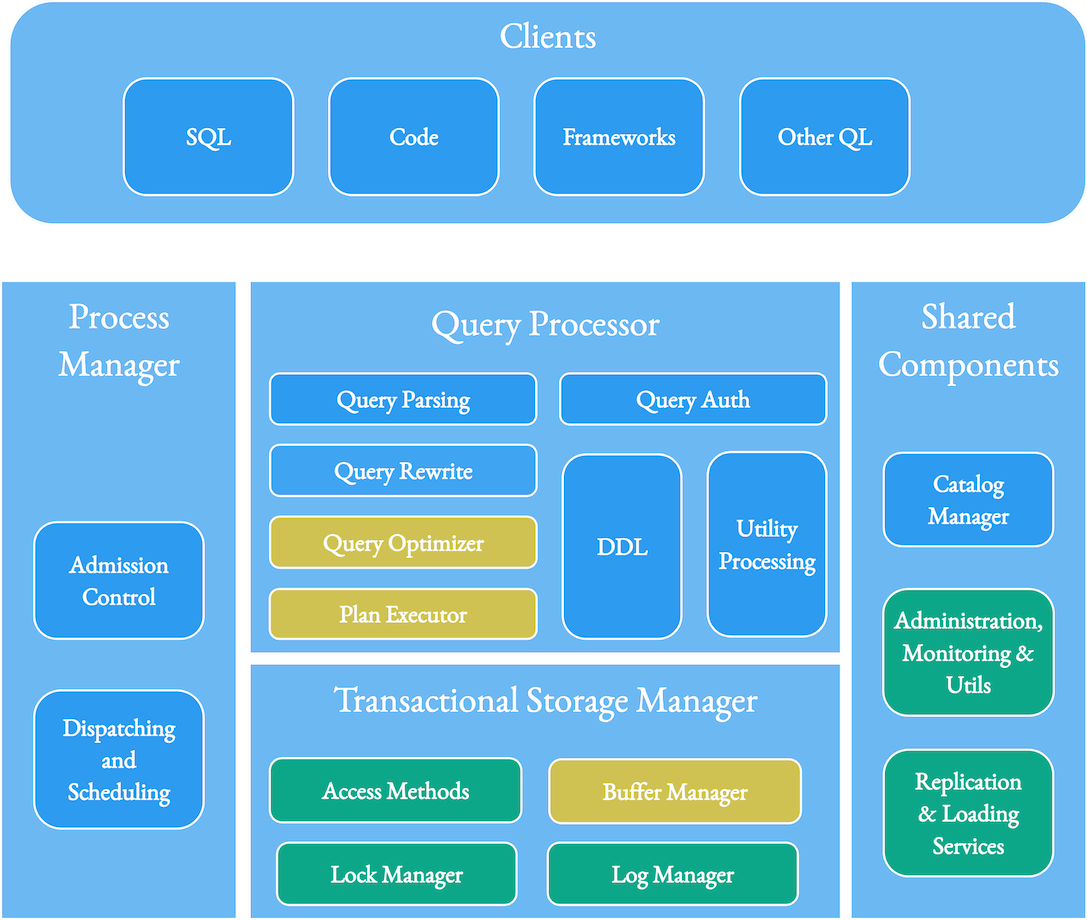
突出顯示現有(綠色)和新(黃色)Hudi 元件以及外部元件(藍色)的參考圖。
資料庫中的紀錄檔管理器元件有助於組織紀錄檔,以便在崩潰期間恢復資料庫等。 在事務層,Hudi 實現了將資料組織到檔案組和檔案切片中的方法,並將修改表狀態的事件儲存在時間軸中。 Hudi 還使用標記檔案跟蹤進行中的事務以實現有效回滾。 由於該湖儲存的資料比典型的運算元據庫或資料倉儲多得多,同時需要更長的記錄版本跟蹤,因此 Hudi 生成了記錄級後設資料,可以很好地壓縮以幫助更改資料捕獲或增量查詢等功能,有效地將資料本身視為紀錄檔 . 未來我們希望繼續完善 Hudi 的資料組織,提供可延伸的、無限的時間線和資料歷史、時間旅行寫入、儲存聯邦等功能。
鎖管理器元件有助於在資料庫中實現並行控制機制。 Hudi 附帶了幾個外部鎖管理器,儘管我們最終希望通過我們今天僅提供時間線後設資料的元伺服器來簡化這一點。 這篇論文(第 81 頁)描述了資料庫中常見的並行控制技術之間的權衡:2Phase Locking(沒有中央事務管理器很難實現)、OCC(在沒有爭用的情況下工作良好,在爭用時效率很差)和 MVCC(收益率 高吞吐量,但在某些情況下放鬆了可序列化性)。 Hudi 在並行寫入器之間實現了 OCC,同時為寫入器和表服務提供了基於 MVCC 的並行,以避免它們之間的任何阻塞。 退一步,我們需要問問自己,如果我們正在構建一個 OLTP 關聯式資料庫,以避免盲目地將適用於它們的相同並行控制技術應用到寫入湖的高吞吐量管道/作業的陷阱。 Hudi 並不是非常傾向於 OCC ,並鼓勵通過輸入流序列化更新/刪除/插入,以避免 OCC 對快速變化的表或流式工作負載造成效能損失。 即使我們實施了早期衝突檢測等技術來改進 OCC,此 RFC 也建議 Hudi 應該追求更通用的基於非阻塞 MVCC 的並行控制,同時為簡單和批次附加的用例保留 OCC。
存取方法元件包括索引、後設資料和儲存佈局組織技術,這些技術暴露給資料庫的讀/寫。 去年我們新增了多模態索引,支援基於MVCC的非同步建索引,建索引時不阻塞寫者,建完後仍與表資料保持一致。 到目前為止,我們的重點一直更狹隘地針對使用索引技術來提高寫入效能,而查詢則受益於檔案和列統計後設資料以進行規劃。 未來我們希望支援在寫入和查詢中統一使用各種索引型別,以便可以在 Hudi 的索引之上高效地規劃、優化和執行查詢。 由於 Hudi 的聯結器適用於 Presto、Spark 和 Trino 等流行的開源引擎,現在這成為可能。 已經新增了新的二級索引方案和內建索引函數的建議,以索引從列派生的值。
緩衝區管理器元件管理髒儲存塊並快取資料以加快查詢響應速度。 在 Hudi 的上下文中,我們希望讓我們現在期待已久的列式快取服務煥發生機,該服務可以透明地位於湖儲存和查詢引擎之間,同時瞭解事務邊界和記錄突變。 RUM 猜想詳細介紹了設計平衡讀取、更新和記憶體成本的系統的權衡。 我們這裡的基本想法是優化讀取(從快取中提供更快的查詢)和更新(通過不斷壓縮記憶體來分攤 MoR 合併成本)成本,同時將快取/記憶體成本新增到系統中。 目前,這個想法可能有很多候選設計,我們需要一個單獨的設計/RFC 來實現它們。
共用元件包括複製、載入和各種實用程式,以及目錄或後設資料伺服器。 大多數資料庫隱藏了底層格式/儲存的複雜性,為使用者提供了許多資料管理工具。 Hudi 也不例外,Hudi 擁有久經考驗的批次和連續資料載入實用程式(deltastreamer、flinkstreamer 工具以及 Kafka Connect Sink)、一套全面的表服務(清理、歸檔、壓縮、叢集、索引……)、admin CLI 等等。 社群一直致力於開發新的伺服器元件,例如元伺服器,它可以擴充套件為使用高階資料結構(例如區域對映/間隔樹)或表服務管理器來索引表後設資料,以集中管理 Hudi 表。 我們很樂意朝著擁有一組水平可延伸、高度可用的元伺服器的方向發展,這些元伺服器可以提供這些功能以及一些鎖管理功能。 另一個有趣的方向是反向載入器/流資料實用程式,它也可以將資料從 Hudi 移出到其他外部儲存系統中。
總而言之我們提出 Hudi 1.x 作為 Hudi 的重新構想,作為湖的事務資料庫,具有多語言永續性,將 Hudi 資料湖的抽象和平臺化水平提高到更高。
Hudi 1.0 釋出
本節概述了第一個 1.0 版本目標和可能必須進行的前端載入更改。 此 RFC 徵求社群的更多反饋和貢獻,以擴大範圍或在 1.0 版本中為使用者提供更多價值。
簡而言之,我們提出 Hudi 1.0 嘗試並實現以下目標。
- 合併對格式的所有/任何更改 - 時間線、紀錄檔、後設資料表...
- 跨表後設資料、快照、索引/後設資料表、主鍵生成、記錄合併等建立新的 API(如果有的話)
- 將內部程式碼分層/抽象到位 - 例如 HoodieData、檔案組讀取器/寫入器、儲存...
- 以設定保護的安全方式登陸所有主要的、傑出的 "needle mover" PR
- 整合 Spark/Flink/Presto 的部分/全部現有索引,並驗證預期的功能和效能提升。
所有更改都應向後相容,並且不需要重寫現有表中的基本/鑲木地板檔案。 但是,從 0.x 版本遷移到 1.0 版本時,可能需要完全壓縮紀錄檔或計劃停機時間以重寫時間線或重建後設資料表。
該 RFC 將通過對 Hudi 不同部分的具體更改進行擴充套件。 請注意此 RFC 僅用於識別這些領域,對於影響儲存格式、向後相容性或新公共 API 的任何更改,應給出單獨的 RFC。
推出/採用計劃
我們建議 1.0 的執行在下面的三個版本系列中完成。
- alpha(2023 年 7 月):所有格式更改均已落地,內部程式碼分層/抽象工作,主要未完成的 PR 已安全落地。 0.X 表可以無縫升級,核心 Hudi 寫入/查詢流程經過認證。
- beta(2023 年 8 月):新增了新的 API,更改了程式碼路徑以使用新的 API,索引整合了效能/功能資格。
- Generally available(2023 年 9 月):在一般釋出之前由社群進行規模測試、壓力測試和生產強化。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

