資料庫系列:資料庫高可用及無失真擴容
1 背景
在大型網際網路場景中,資料庫的高可用性顯得尤為重要,為了保證穩定性,一般需要採用強化的架構模式,以保證資料層能夠提供持續有效的穩定支撐。
2 高可用架構的基本演進過程
2.1 基本的資料庫架構
每個服務對應一個儲存服務範例(基本是資料庫單範例模式),使用 IP+Port 進行連線和呼叫,這就是大家常見的資料庫直連。
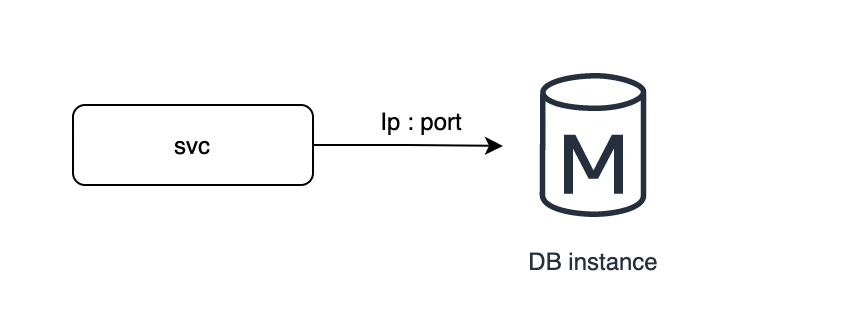
使用者計算服務(svc) 設定IP+埠指向資料庫範例地址,進行存取和操作。
2.1 Scale Up + Scale Out 模式
網際網路場景下,理論上存取量和資料量都是不斷膨脹的過程。隨著資料量的增大,資料庫一般要進行縱向(Scale Up)和 橫向(Scale Out) 的拆分,
分庫分表之後可能會將資料拆分到不同的資料庫範例,甚至不同的IDC上,這樣可以 降低資料量,提高執行效能的目的。詳細參考筆者這篇《MySQL全面瓦解28:分庫分表》。
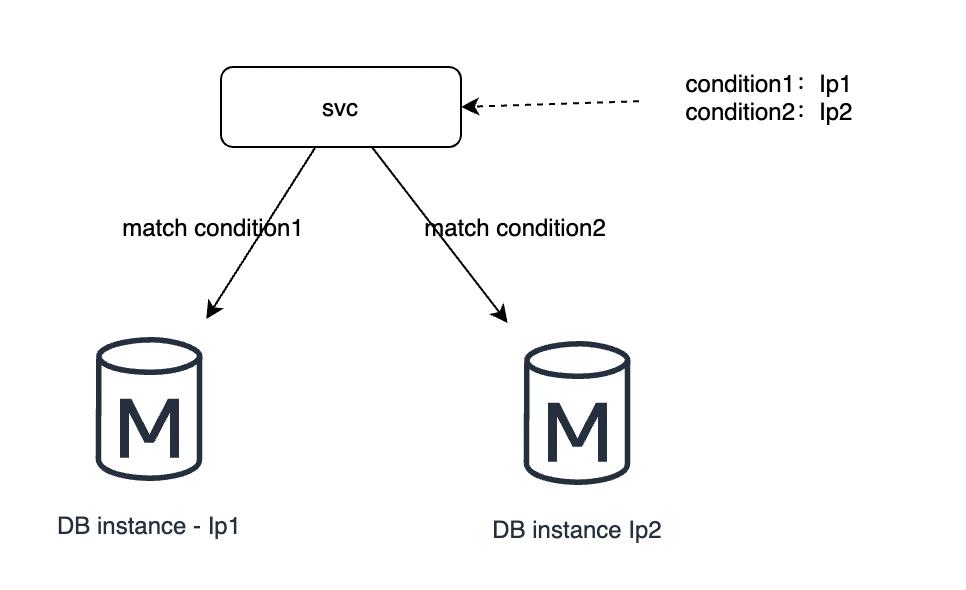
如上圖,庫表拆分之後,使用不同的條件可以路由到不同的IP,這樣來實現業務上的資料隔離,這種條件可以是使用者的角色,業務的類別,
甚至直接對資料取模或者hash,只要確保連結到對應的資料庫上即可。這邊舉個例子:(value % 2 == 0) = condition1,(value % 2 == 1) = condition2
。
2.3 主從或主主 + Keepalived 架構
以上只是解決了資料庫大容量的問題,將資料庫的風險降低,效能提升。並沒有實質的解決可用性問題,如果其中一個資料庫範例出現故障,
依然會造成大面積的不可用。
在網際網路架構中,比較常見的一種方式就是,使用 雙主或者主從同步 + keepalived + vip的模式來保證儲存層的好可用性:
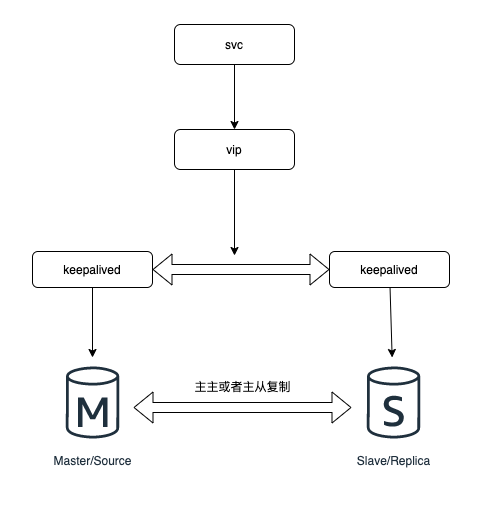
如上圖,兩個庫(主主或者主從)使用相同的虛擬IP,當主庫掛掉的時候,虛ip自動轉移到另一個主庫(或者轉移到從庫上,並將從庫切為主庫),這個切換過程對業務應該是透明無感的,也不會造成使用上的異常,以此保證資料庫的高可用性。
2.4 分片分庫模式下的高可用性
可以繼續從2.3演化出分片分庫模式下的高可用架構,如下:
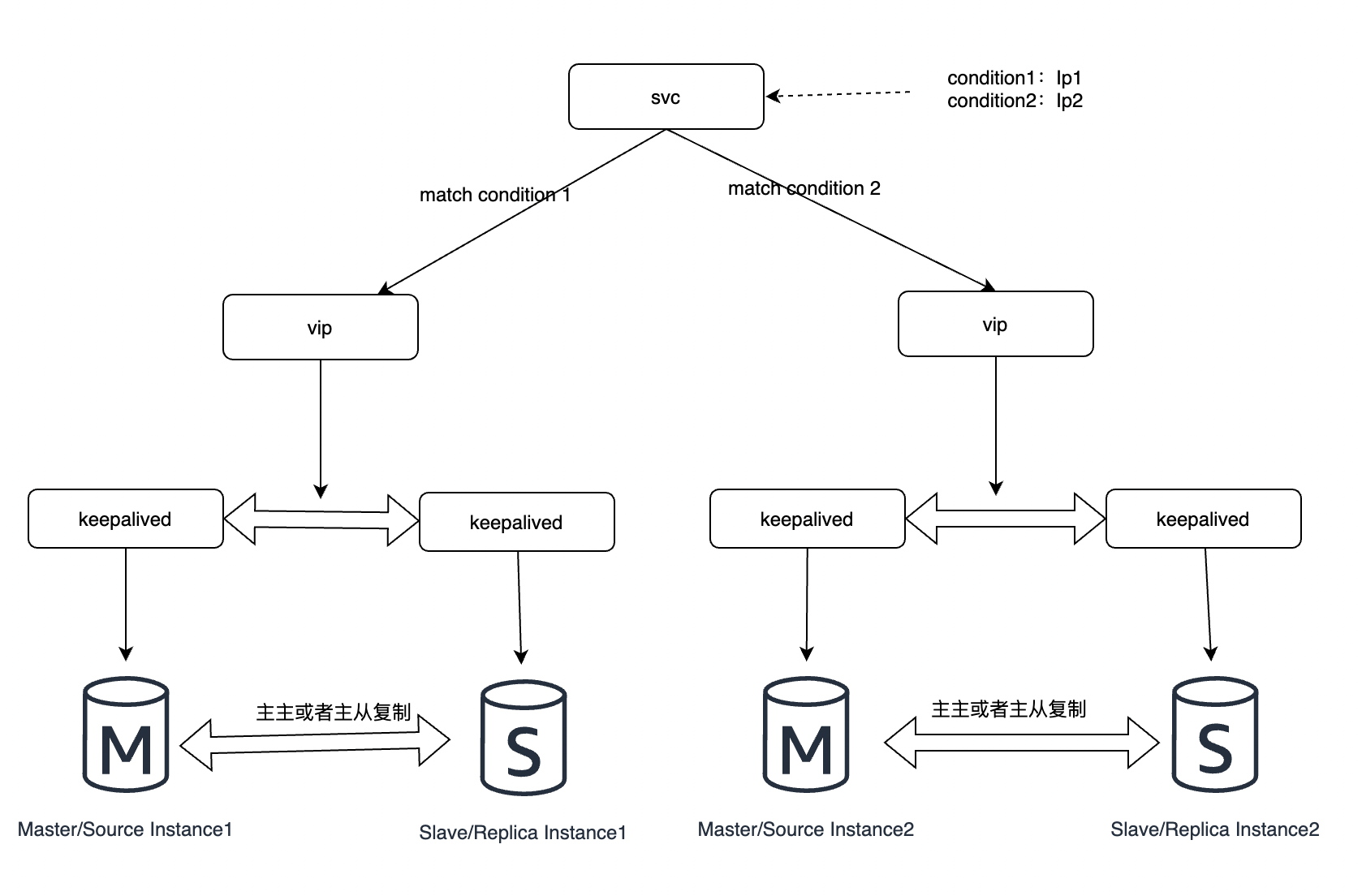
如果資料庫繼續膨脹,流量繼續擴充套件,還可以繼續擴容,找到最恰當的分片模式。
2.5 其他常見的高可用模式
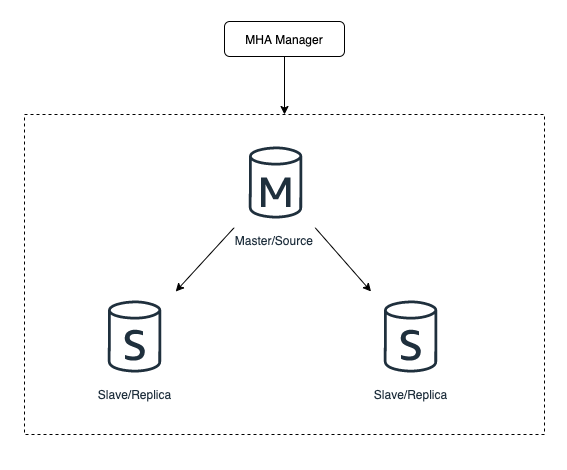
2.5.1 MHA
MHA(Master High Avaliable) 是一款 MySQL 開源高可用程式,MHA 在監測到主範例無響應後,會自動將同步最靠前(即資料偏移量最少)的 Slave 提升為 Master,然後其他所有的 Slave 重新指向新 Master。架構模式如下:
2.5.2 PXC
PXC(Percona XtraDB Cluster)是一種開源的 MySQL 高可用解決方案。它將 Percona Server、Percona XtraBackup 與 Galera 庫整合在一起,以實現多主複製的 MySQL 叢集。
缺點是隻支援InnoDB引擎模式,且多主資料同步必然會有效能損耗、同步延遲和資料差異風險。
另外,這種多主同步模式具有典型的木桶效應,系統的吞吐被最差的節點左右。
架構如下:
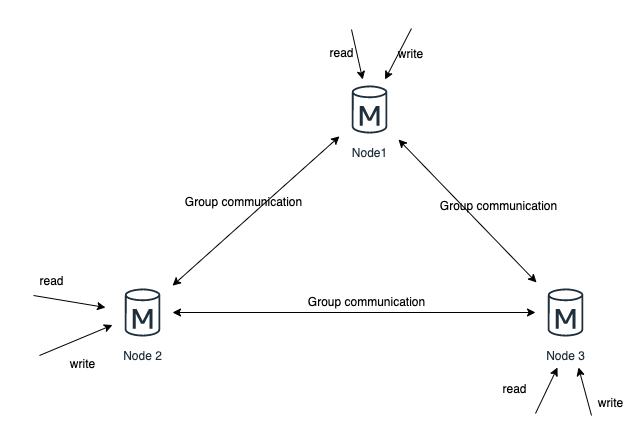
2.5.3 MGR/InnoDB Cluster
MySQL 5.7 退出了高可用的的模式 MGR(MySQL Group Replication),他具備了多節點資料寫入和強一致性的特點,這一點跟與 PXC 相似。同時採用Group Communication System(GCS協定)進行資料同步來保證訊息的原子性。
MGC需要使用到InnoDB Cluster模式,才能實現真正的高可用,高可用架構圖參考下面:
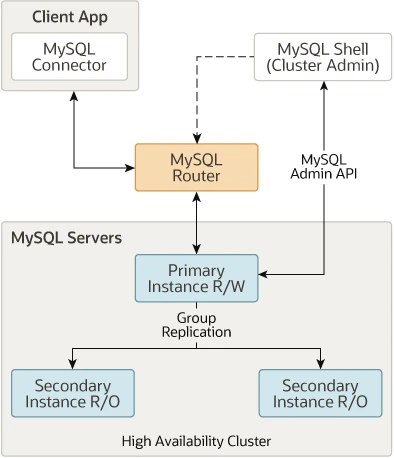
備註:圖片來自官網,就不再畫了。
2.6 高可用模式下的平滑擴容
網際網路大流量場景下我們經常會發現儲存層容易出現瓶頸,這個時候就需要擴容。
相對於停服擴容來說,無失真、透明、平滑的資料庫擴容才是我們實際追求的目標。
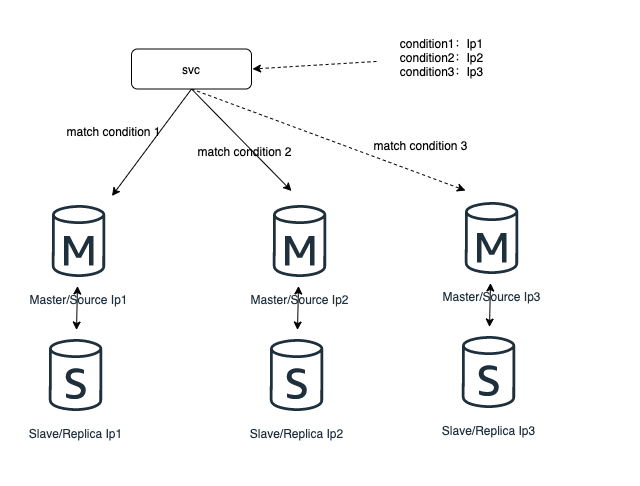
步驟如下:
- 增加資料庫分片3,進行資料架構初始化和資料同步
- 增加資料庫主從設定,將2個庫的資料庫設定,改為3個庫的資料庫設定,並注意舊庫與新庫的對映關係。
- 服務層 reload(重新載入)設定,完成擴容工作。
- 刪除分片之後的冗餘資料,必要的話進行資料庫縮容。
- 服務層根據條件對映到不同的資料庫範例中。
3 總結
資料庫儲存層實現可用性有很多種辦法。除了最基本的 主從/主主 + Keepalived 架構 之外,還有 MHA 、 PXC 、MGR/InnoDB Cluster 等,後面我們一一拆解。
實現高可用,意味著後續的遷移、擴容、業務調整,都應該是可以平滑的,對業務無感的。
