OCR -- 文字檢測
百度飛槳(PaddlePaddle) - PP-OCRv3 文字檢測識別系統 預測部署簡介與總覽
百度飛槳(PaddlePaddle) - PP-OCRv3 文字檢測識別系統 Paddle Inference 模型推理(離線部署)
百度飛槳(PaddlePaddle) - PP-OCRv3 文字檢測識別系統 基於 Paddle Serving快速使用(服務化部署 - CentOS)
百度飛槳(PaddlePaddle) - PP-OCRv3 文字檢測識別系統 基於 Paddle Serving快速使用(服務化部署 - Docker)
PaddleOCR提供DB文字檢測演演算法,支援MobileNetV3、ResNet50_vd兩種骨幹網路,可以根據需要選擇相應的組態檔,啟動訓練。
本節以icdar15資料集、MobileNetV3作為骨幹網路的DB檢測模型(即超輕量模型使用的設定)為例,介紹如何完成PaddleOCR中文字檢測模型的訓練、評估與測試。
3.1 資料準備
本次實驗選取了場景文字檢測和識別(Scene Text Detection and Recognition)任務最知名和常用的資料集ICDAR2015。icdar2015資料集的示意圖如下圖所示:

圖 icdar2015資料集示意圖
該專案中已經下載了icdar2015資料集,存放在 /home/aistudio/data/data96799 中,可以執行如下指令完成資料集解壓,或者從連結中自行下載。
~/train_data/icdar2015/text_localization
└─ icdar_c4_train_imgs/ icdar資料集的訓練資料
└─ ch4_test_images/ icdar資料集的測試資料
└─ train_icdar2015_label.txt icdar資料集的訓練標註
└─ test_icdar2015_label.txt icdar資料集的測試標註
提供的標註檔案格式為:
" 影象檔名 json.dumps編碼的影象標註資訊"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]], ...}]
json.dumps編碼前的影象標註資訊是包含多個字典的list,字典中的points表示文字方塊的四個點的座標(x, y),從左上角的點開始順時針排列。 transcription中的欄位表示當前文字方塊的文字,在文字檢測任務中並不需要這個資訊。 如果您想在其他資料集上訓練PaddleOCR,可以按照上述形式構建標註檔案。
如果"transcription"欄位的文字為'*'或者'###',表示對應的標註可以被忽略掉,因此,如果沒有文字標籤,可以將transcription欄位設定為空字串。
3.2 資料預處理
訓練時對輸入圖片的格式、大小有一定的要求,同時,還需要根據標註資訊獲取閾值圖以及概率圖的真實標籤。所以,在資料輸入模型前,需要對資料進行預處理操作,使得圖片和標籤滿足網路訓練和預測的需要。另外,為了擴大訓練資料集、抑制過擬合,提升模型的泛化能力,還需要使用了幾種基礎的資料增廣方法。
本實驗的資料預處理共包括如下方法:
- 影象解碼:將影象轉為Numpy格式;
- 標籤解碼:解析txt檔案中的標籤資訊,並按統一格式進行儲存;
- 基礎資料增廣:包括:隨機水平翻轉、隨機旋轉,隨機縮放,隨機裁剪等;
- 獲取閾值圖示籤:使用擴張的方式獲取演演算法訓練需要的閾值圖示籤;
- 獲取概率圖示籤:使用收縮的方式獲取演演算法訓練需要的概率圖示籤;
- 歸一化:通過規範化手段,把神經網路每層中任意神經元的輸入值分佈改變成均值為0,方差為1的標準正太分佈,使得最優解的尋優過程明顯會變得平緩,訓練過程更容易收斂;
- 通道變換:影象的資料格式為[H, W, C](即高度、寬度和通道數),而神經網路使用的訓練資料的格式為[C, H, W],因此需要對影象資料重新排列,例如[224, 224, 3]變為[3, 224, 224];
影象解碼
從訓練資料的標註中讀取影象,演示DecodeImage類的使用方式。
原始碼位置:\ppocr\data\imaug\operators.py
import os
import matplotlib.pyplot as plt
from paddleocr.ppocr.data.imaug.operators import DecodeImage
label_path = "../train_data/icdar2015/text_localization/train_icdar2015_label.txt"
img_dir = "../train_data/icdar2015/text_localization/"
# 1. 讀取訓練標籤的第一條資料
f = open(label_path, "r")
lines = f.readlines()
# 2. 取第一條資料
line = lines[0]
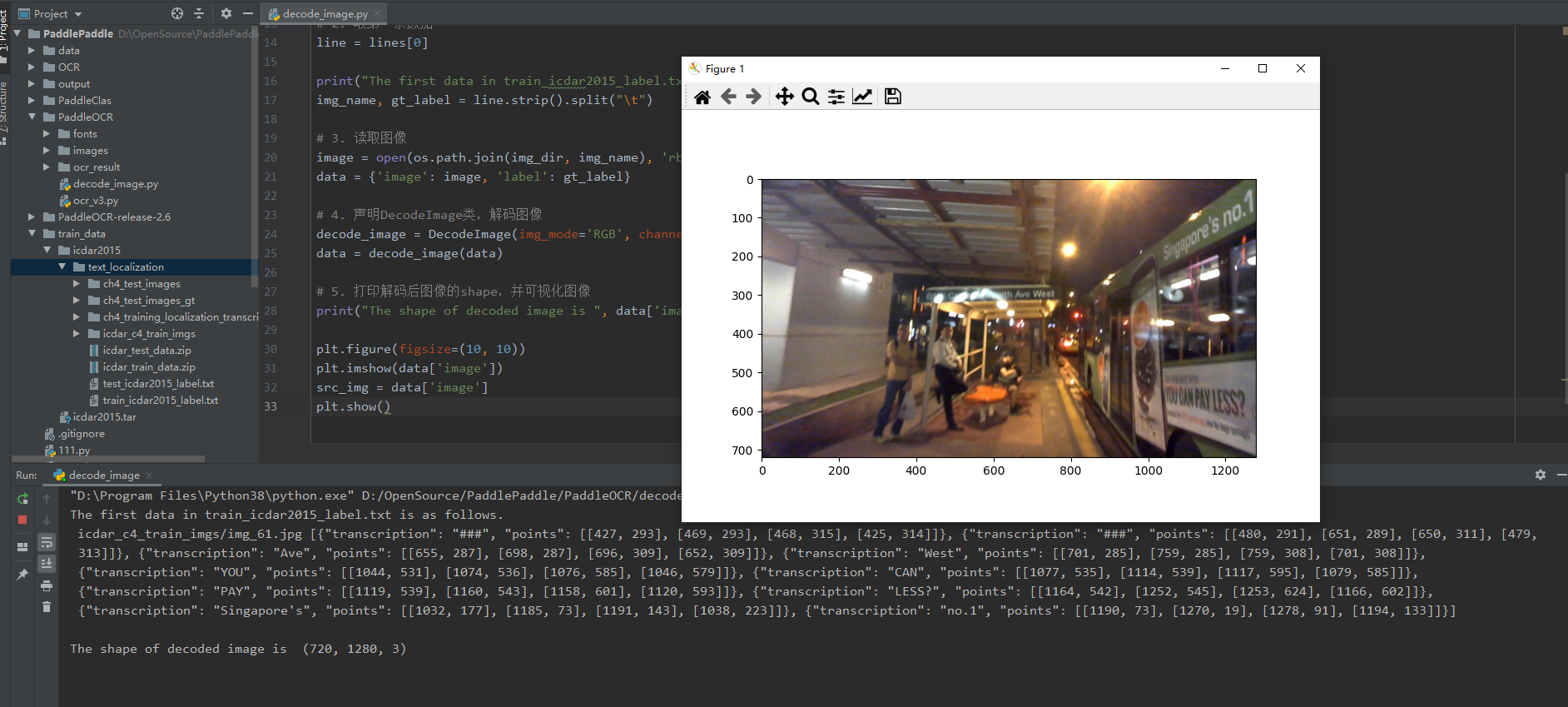
print("The first data in train_icdar2015_label.txt is as follows.\n", line)
img_name, gt_label = line.strip().split("\t")
# 3. 讀取影象
image = open(os.path.join(img_dir, img_name), 'rb').read()
data = {'image': image, 'label': gt_label}
# 4. 宣告DecodeImage類,解碼影象
decode_image = DecodeImage(img_mode='RGB', channel_first=False)
data = decode_image(data)
# 5. 列印解碼後影象的shape,並視覺化影象
print("The shape of decoded image is ", data['image'].shape)
plt.figure(figsize=(10, 10))
plt.imshow(data['image'])
src_img = data['image']
plt.show()
標籤解碼
解析txt檔案中的標籤資訊,並按統一格式進行儲存;
原始碼位置:ppocr/data/imaug/label_ops.py
import os
from paddleocr.ppocr.data.imaug.label_ops import DetLabelEncode
label_path = "../train_data/icdar2015/text_localization/train_icdar2015_label.txt"
img_dir = "../train_data/icdar2015/text_localization/"
# 1. 讀取訓練標籤的第一條資料
f = open(label_path, "r")
lines = f.readlines()
# 2. 取第一條資料
line = lines[0]
print("The first data in train_icdar2015_label.txt is as follows.\n", line)
img_name, gt_label = line.strip().split("\t")
# 3. 讀取影象
image = open(os.path.join(img_dir, img_name), 'rb').read()
data = {'image': image, 'label': gt_label}
# 1. 宣告標籤解碼的類
decode_label = DetLabelEncode()
# 2. 列印解碼前的標籤
print("The label before decode are: ", data['label'])
data = decode_label(data)
print("\n")
# 4. 列印解碼後的標籤
print("The polygon after decode are: ", data['polys'])
print("The text after decode are: ", data['texts'])
基礎資料增廣
資料增廣是提高模型訓練精度,增加模型泛化性的常用方法,文字檢測常用的資料增廣包括隨機水平翻轉、隨機旋轉、隨機縮放以及隨機裁剪等等。
隨機水平翻轉、隨機旋轉、隨機縮放的程式碼實現參考程式碼。隨機裁剪的資料增廣程式碼實現參考程式碼。
獲取閾值圖示籤
使用擴張的方式獲取演演算法訓練需要的閾值圖示籤;
原始碼位置:ppocr/data/imaug/make_border_map.py
# 從PaddleOCR中import MakeBorderMap
from ppocr.data.imaug.make_border_map import MakeBorderMap
# 1. 宣告MakeBorderMap函數
generate_text_border = MakeBorderMap()
# 2. 根據解碼後的輸入資料計算bordermap資訊
data = generate_text_border(data)
# 3. 閾值圖視覺化
plt.figure(figsize=(10, 10))
plt.imshow(src_img)
text_border_map = data['threshold_map']
plt.figure(figsize=(10, 10))
plt.imshow(text_border_map)