MySQL uuid及其相關的一些簡單效能測試
運維同事匯入一批大約500萬左右的資料,耗時較久。他使用的是純SQL匯入,主鍵使用的是UUID,因為業務原因沒有使用自增ID。
因為是內網,不能遠端存取。
通過溝通,大致覺得有兩個原因,一是因為UUID作為主鍵,二是表欄位繁多,單行加起來接近10000的長度引起行溢位。
因為是臨時一次性任務,同事沒有做深糾,我在這裡簡單做一個驗證。
版本:5.7.19
引擎:innodb
uuid主鍵的影響
mysql自帶的UUID()函數簡單方便,不重複。但是它缺點也是眾所周知的。
-
UUID的返回值通常是隨機的,而InnoDB的表實質是以主鍵組織儲存的索引,插入新的記錄不是順序追加,而會往前插入,造成頁分裂,表的再平衡。在資料量越大的情況,效能影響越嚴重。
-
主鍵包含在每個二級索引中,過長的主鍵會浪費磁碟和記憶體的空間。
頁分裂
為什麼主鍵ID的順序這麼重要?
mysql innodb引擎資料結構為B+tree,查詢的時候二分查詢,這就要求資料是按順序儲存的。
而UUID是無序的,它作為主鍵在寫入的時候,就可能會頻繁的進行中間插入和頁分裂。頁分裂會造成已有的資料移位,類似於arraylist進行插入資料。
因此表資料越多,插入的效率就會越低。也會使得磁碟空間利用率降低。
除了UUID,其它還有兩種常見的ID生成法。
一是自增id,最簡單效率也最高,但不適合分散式唯一主鍵,和在一些敏感業務如訂單註冊使用者時,可能通過ID值會暴露一些商業祕密。
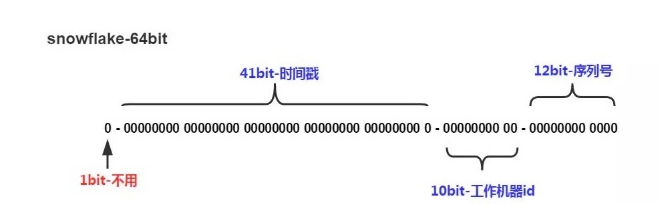
雪花演演算法
再一個是雪花演演算法,最常見的分散式ID生成演演算法。
可以看到它跟時間戳(毫秒級)和伺服器相關,通過12bit序列號區分同毫秒內產生的不同id。
因此能保證在單臺伺服器上的大致趨勢遞增。 在並行高的情況下不能保證完全遞增,因此需考慮到這一點。
它有時鐘回撥的問題,這裡不展開。
定量驗證
以上只是定性的判斷。
下面做一下定量的測試。
本文驗證自增id,雪花演演算法ID,以及uuid作為主鍵3種情況,往3張空表插入500萬條資料,每個批次10萬,共50個批次。
StopWatch stopWatch = new StopWatch();
stopWatch.start("準備資料階段");
int count = 500 * 10000 ;
List<TUser> list = new ArrayList<>(count);
ExecutorService executorService = Executors.newFixedThreadPool(100);
List<TUser> finalList = list;
Semaphore semaphore = new Semaphore(100);
for (int i = 0; i < count; i++) {
executorService.submit(new Runnable() {
@SneakyThrows
@Override
public void run() {
semaphore.acquire();
TUser user = new TUser();
// 雪花演演算法ID
user.setId(SnowflakeIdUtil.snowflakeId());
user.setName(testService.getRandomName());
// UUID
user.setId(UUID.randomUUID().toString());
finalList.add(user);
semaphore.release();
}
}).get();
}
stopWatch.stop();
System.out.println("開始寫入");
List<Time> times = new ArrayList<>();
stopWatch.start("寫入資料階段");
List<TUser> subList = new ArrayList<>(100000);
for (int i = 1; i <= count; i++) {
TUser user = finalList.get(i-1);
subList.add(user);
if (i % 100000 == 0) {
// finalList.remove(user);
long start = System.currentTimeMillis();
tUserDao.insertBatch(subList);
long time = System.currentTimeMillis() - start;
times.add(new Time(time));
subList.clear();
log.info("寫入一次" + i);
}
}
stopWatch.stop();
System.out.println(stopWatch.prettyPrint());
// 將每個批次耗時列印出來,放入excel生成圖表
times.stream().map(e -> e.getTime()).forEach(System.out::println);
總耗時情況
UU ID:414321ms
雪花ID 167748ms
自增ID 75829ms
將最後每個批次耗時的集合列印出來,放到Excel中,生成圖表。
縱座標表示耗時,單位ms
橫座標表示寫入批次
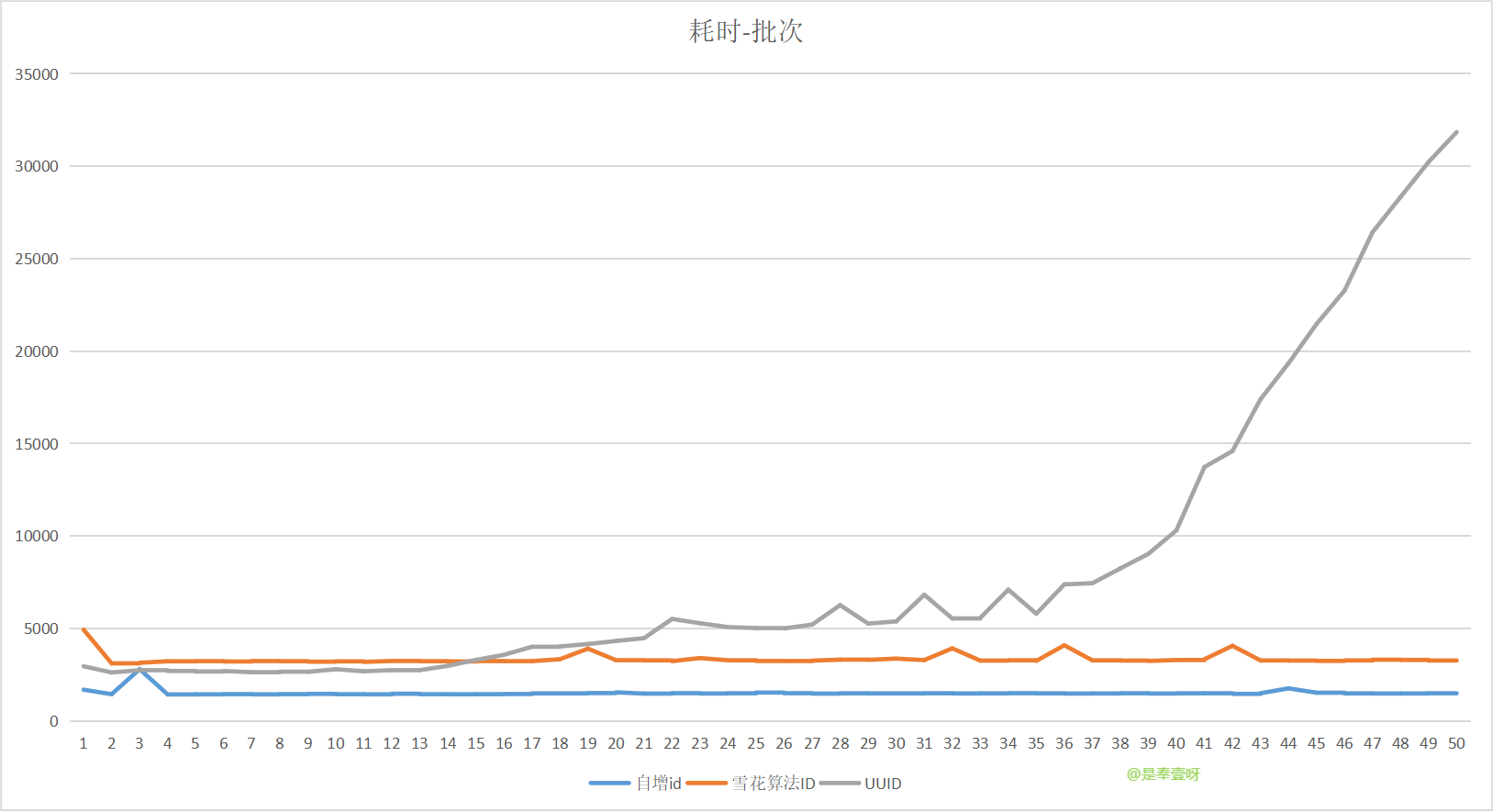
可以明顯的觀察到,使用UUID作為主鍵,在表資料量在350萬以後,耗時上升極快,效能呈指數級下降。
同時自增ID效率高於雪花演演算法ID,都很穩定。
這是在行資料量極小(<50)的情況下。
在行大小> 8000,在頁16KB至少兩行資料的情況下,也必然會發生行溢位。這裡再看看測試情況。
行溢位情況
MySQL單行資料最大能儲存65535位元組的資料,InnoDB的頁為16KB,即16384位元組,當行的實際儲存長度超過16384/2的長度時,就會行溢位。
為什麼是/2,因為頁至少需要儲存兩行資料。
為什麼單頁至少儲存兩行資料,如果為1,B+tree就退化為了連結串列。
當行溢位的時候,會將大欄位資料存放在頁型別為Uncompress BLOB頁中,在當前頁就會對大欄位建立一個參照,類假於二級索引。
所以設定測試表name長度大於大約16384/2的時候,就會發生行溢位現象。
行溢位時,3種不同ID的表現
測試程式碼跟上面類似。
再準備3張空表。
欄位型別varchar,長度10000,user.setName()設定實際長度大於8000。
這次只寫入50萬條資料,每批次1萬條資料,共50個批次。
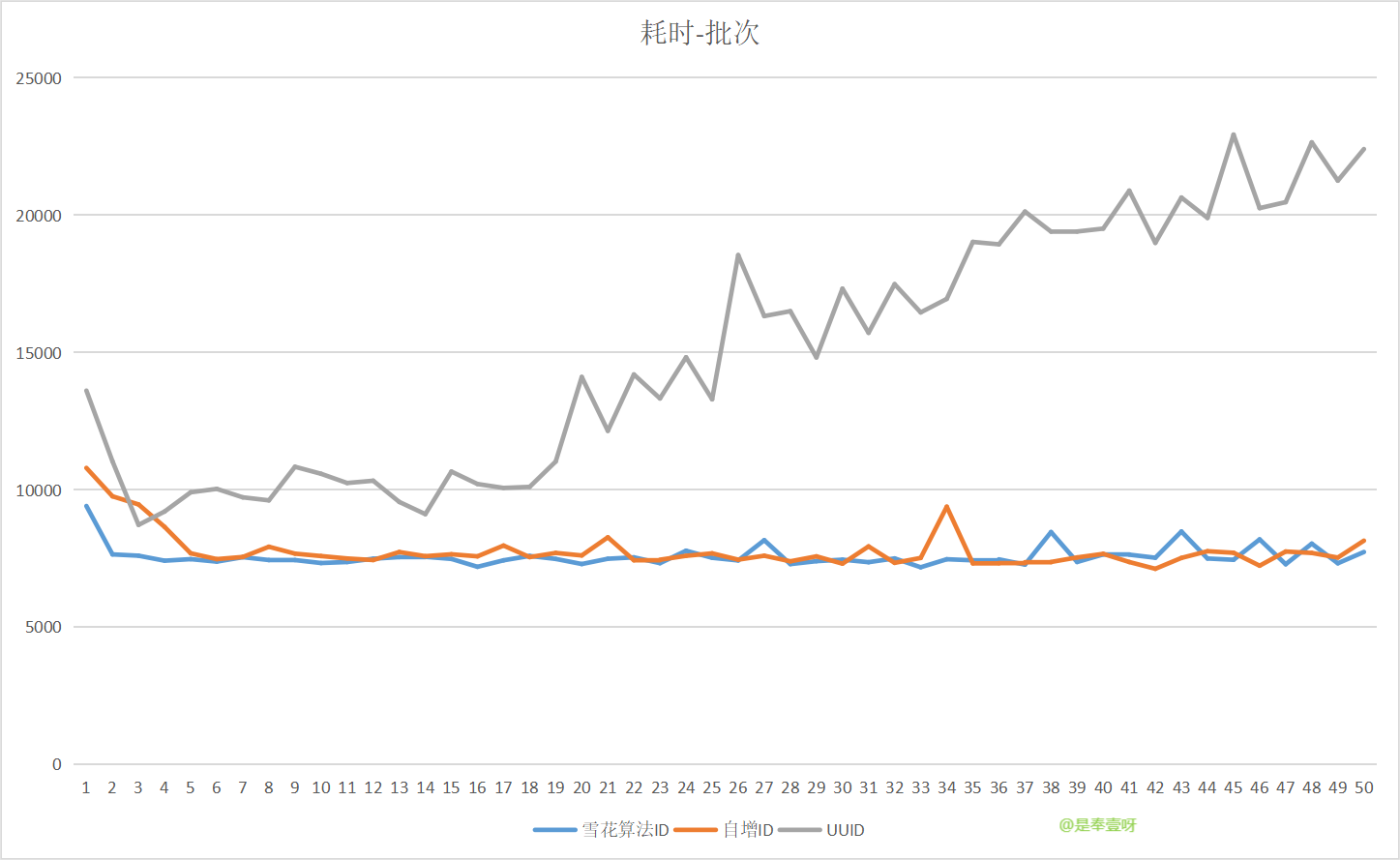
這次uuid在寫入30萬條記錄後,耗時開始明顯上升。
以上是行溢位的情況下,UUID,雪花演演算法,自增ID等 3種ID的寫入效能情況。
uuid在溢位和不溢位下的表現
下面來測試一下,使用UUID在行溢位和不溢位的兩種情況下寫入效能情況。
再新建兩張表,t_user_uuid_long,此表name欄位長度100000,最終寫入字元長度9995
t_user_uuid_short,此表name欄位長度8000,最終寫入字元長度7995
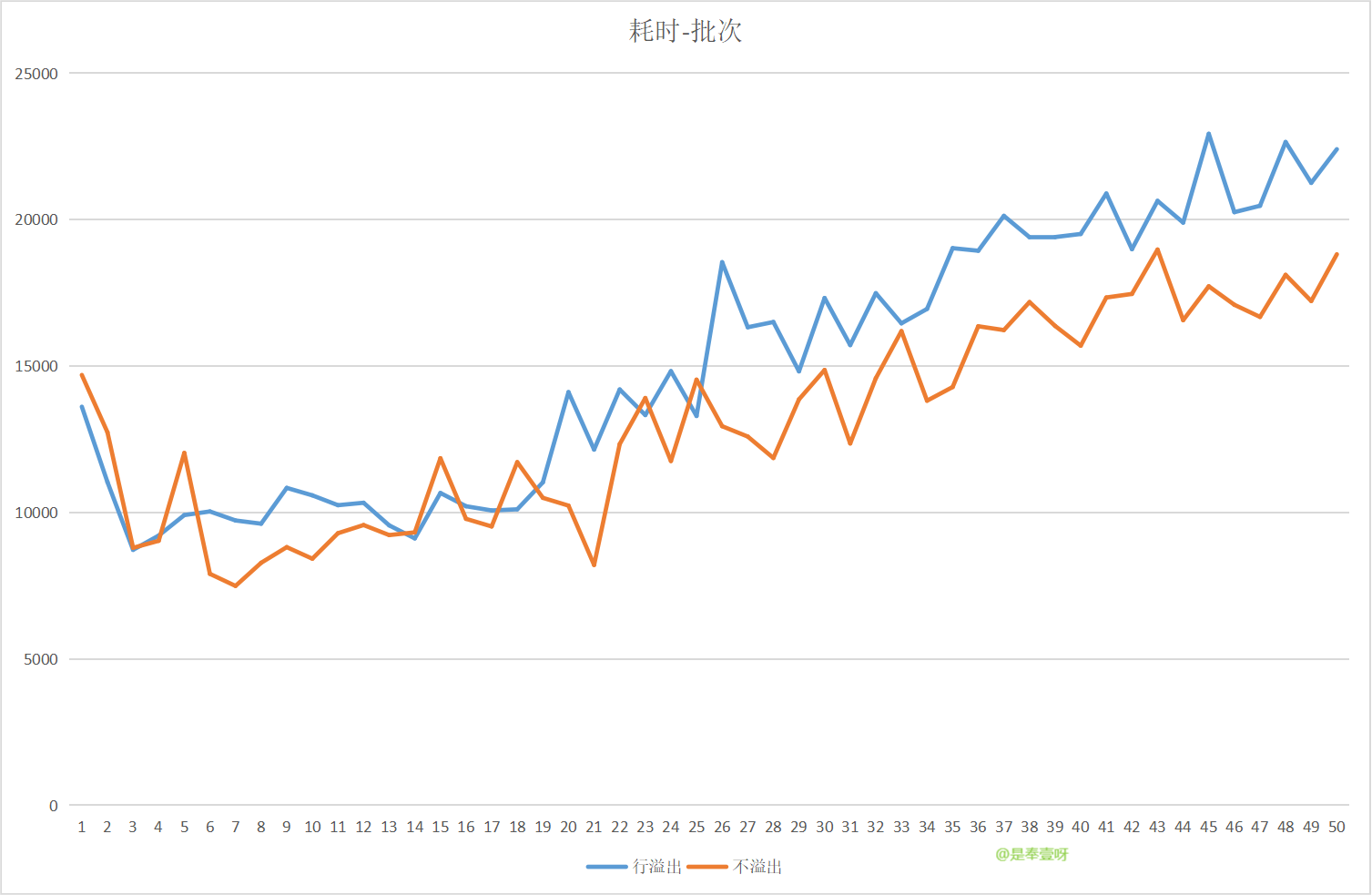
寫入耗時曲線大致相當,看不出明顯差距。
但是讀的差距非常明顯!
因為t_user_uuid_long 中的name欄位發生了行溢位,。。。。。select的時候需要跨頁提取資料,類似於做了1次回表,而且回表還是跨頁的。
select id,name from t_user_uuid_short order by id asc limit 1000
耗時0.145s
select id,name from t_user_uuid_long order by id asc limit 1000
耗時4.153s,效能相差接近30倍。
小結
以上測試結果只是在測試機上的粗糙測試結果,不是基準測試,只做參考。
測試結果表明,運維同事的慢操作可能受UUID影響 ,但大欄位對寫入的影響並不明顯。
不過大欄位對讀取的效能影響明顯。