資料治理核心保障資料質量監控開源專案Apache Griffin分享
@
概述
定義
Apache Griffin 官網地址 https://griffin.apache.org/ 原始碼release最新版本0.6.0
Apache Griffin 官網檔案地址 https://griffin.apache.org/docs/quickstart.html
Apache Griffin 原始碼地址 https://github.com/apache/griffin
Apache Griffin是一個開源的巨量資料資料質量解決方案,它支援批次處理和流模式兩種資料質量檢測方式,可以從不同維度(比如離線任務執行完畢後檢查源端和目標端的資料數量是否一致、源表的資料空值數量等)度量資料資產,從而提升資料的準確度、可信度。
Apache Griffin提供了一套定義良好的資料質量領域模型,涵蓋了一般情況下的大多數資料質量問題。它還定義了一組資料質量DSL來幫助使用者定義他們的質量標準。通過擴充套件DSL甚至可以在Apache Griffin中實現自定義的特定特性/功能。
資料質量(DQ)是物聯網、機器學習等許多資料消費者的關鍵標準,但如何確定「好」資料沒有標準協定。Apache Griffin是一個模型驅動的資料質量服務平臺,可以在其中按需檢查資料。它提供了一個標準流程來定義資料質量度量、執行和報告,允許跨多個資料系統進行這些檢查;當不信任自己的資料或者擔心資料會對關鍵決策產生負面影響時則可以使用Apache Griffin來確保資料質量。
Apache Griffin支援兩種型別的資料來源:
- batch資料:通過資料聯結器從Hadoop平臺收集資料。
- streaming資料:可以連線到諸如Kafka之類的訊息系統來做近似實時資料分析。
為何要做資料質量監控
- 當資料從不同的資料來源流向不同的應用系統的時候,缺少端到端的統一檢視來追蹤資料沿襲(Data Lineage)。這也就導致了在識別和解決資料質量問題上要花費許多不必要的時間。
- 缺少一個實時的資料質量檢測系統。從資料資產(Data Asset)註冊,資料質量模型定義,資料質量結果視覺化、可監控,當檢測到問題時,可以及時發出警報。
- 缺乏一個共用平臺和API服務,讓每個專案組無需維護自己的軟硬體環境就能解決常見的資料質量問題。
基本概念
-
DQC:Data Quality Control,資料質量檢測/資料質量控制,一般稱為資料質量監控。
-
SLA:Service Level Agreement,也就是服務等級協定,指的是系統服務提供者(Provider)對客戶(Costomer)的一個服務承諾,通常稱為資料產出分級運維服務。
由定義可知,DQC關注資料口徑,負責資料準不準的監測,而SLA關注產出及時性和穩定性,這兩者有機結合共同保障了資料質量。在需求場景上DQC主要負責對資料資產質量和波動的監控,SLA主要負責對資料產出和任務排程結果和時長的監控。
特性
- 度量:精確度、完整性、及時性、唯一性、有效性、一致性。
- 異常監測:利用預先設定的規則,檢測出不符合預期的資料,提供不符合規則資料的下載。
- 異常告警:通過郵件或門戶報告資料質量問題。
- 視覺化監測:利用控制面板來展現資料質量的狀態。
- 實時性:可以實時進行資料質量檢測,能夠及時發現問題。
- 可延伸性:可用於多個資料系統倉庫的資料校驗。
- 自助服務:Griffin提供了一個簡潔易用的使用者介面,可以管理資料資產和資料質量規則;同時使用者可以通過控制面板檢視資料質量結果和自定義顯示內容。
架構
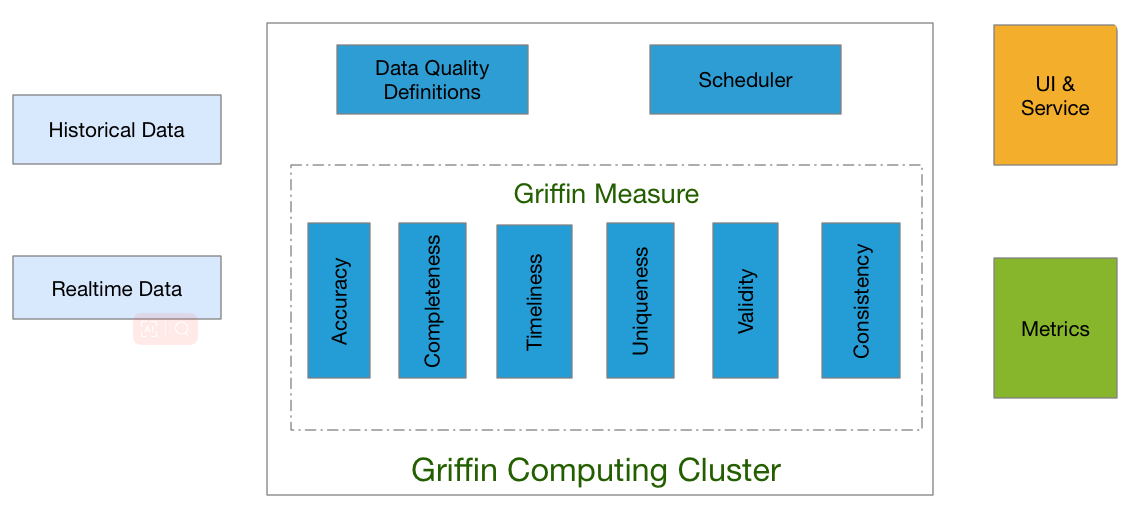
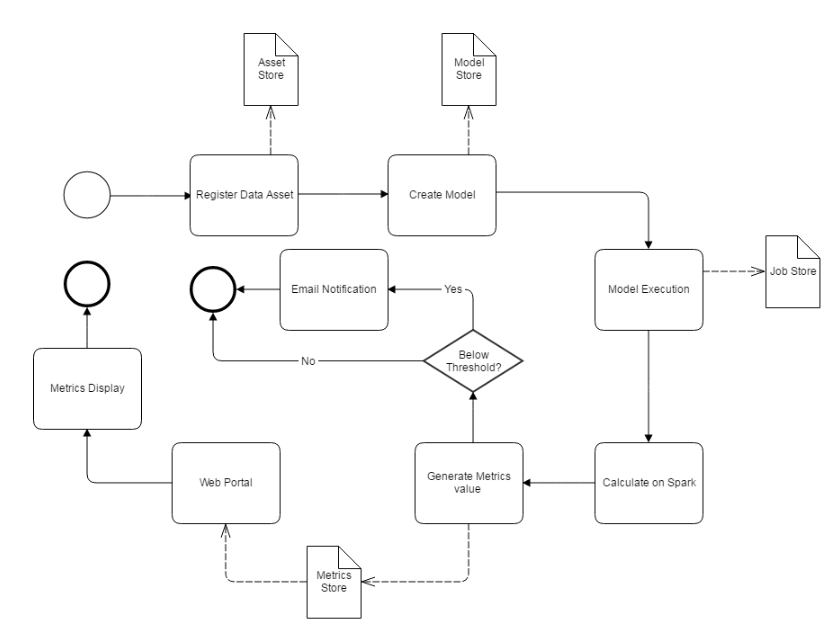
Apache Griffin通過3個步驟來處理資料質量問題,步驟如下:
- 定義資料質量:資料科學家/分析師定義他們的資料質量要求,如準確性、完整性、及時性、唯一性、有效性、一致性和分析等。
- 測量資料質量:源資料將被攝取到Apache Griffin計算叢集中,Apache Griffin將根據資料質量需求啟動資料質量測量。
- 度量結果:作為度量的資料質量報告將被傳送到指定的地方。
此外Apache Griffin還為使用者提供了一個前端層,使用者可以輕鬆地將任何新的資料質量需求裝載到Apache Griffin平臺中,並編寫全面的邏輯來定義他們的資料質量。
在Griffin的架構中,主要分為Define、Measure和Analyze三個部分
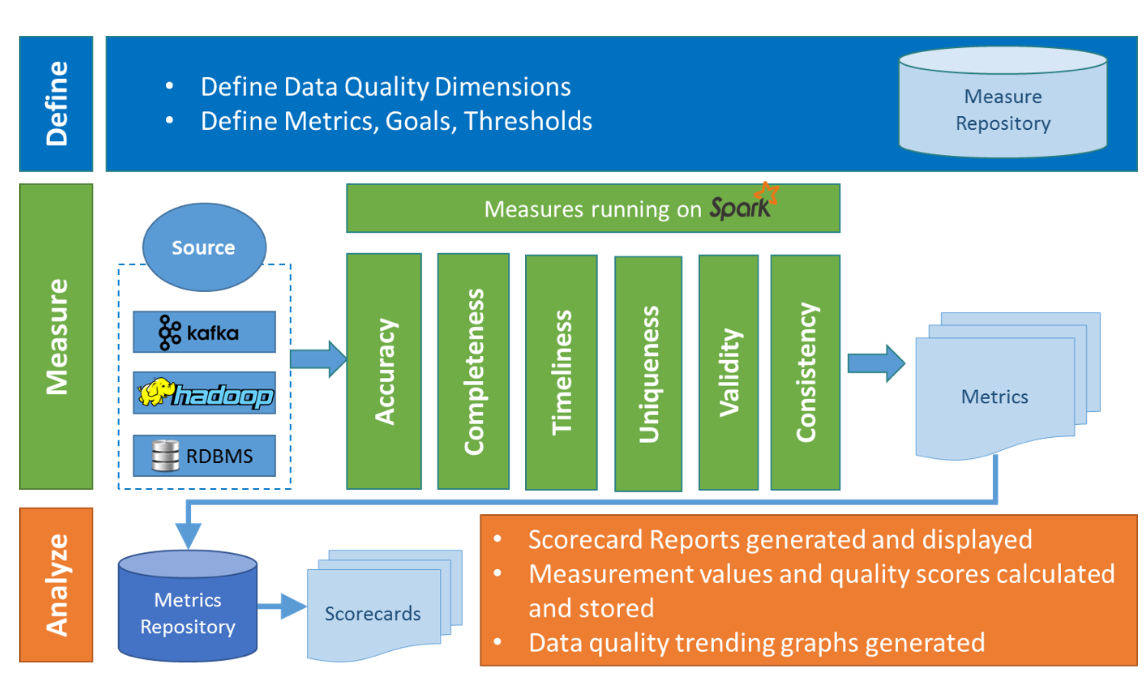
各部分的職責如下:
- Define:主要負責定義資料質量統計的維度,比如資料質量統計的時間跨度、統計的目標(源端和目標端的資料數量是否一致,資料來源裡某一欄位的非空的數量、不重複值的數量、最大值、最小值、top5的值數量等)。
- Measure:主要負責執行統計任務,生成統計結果。
- Analyze:主要負責儲存與展示統計結果。
安裝
Docker部署
Griffin docker映象是預先構建在docker hub上的,可以通過docker方式試用體驗Apache Griffin。
# 國外地址映象下載安裝
docker pull apachegriffin/griffin_spark2:0.3.0
docker pull apachegriffin/elasticsearch
docker pull apachegriffin/kafka
docker pull zookeeper:3.5
# 中國地址映象下載安裝
docker pull registry.docker-cn.com/apachegriffin/griffin_spark2:0.3.0
docker pull registry.docker-cn.com/apachegriffin/elasticsearch
docker pull registry.docker-cn.com/apachegriffin/kafka
docker pull zookeeper:3.5
docker映像是Apache Griffin環境映像,各映象包含內容如下:
- apachegriffin/griffin_spark2:該映象包含mysql、hadoop、 hive、 spark、 livy、Apache Griffin服務、Apache Griffin度量,以及一些準備好的demo資料,它作為一個單節點spark叢集,提供spark引擎和Apache Griffin服務。
- apachegriffin/elasticsearch:此映象基於官方的elasticsearch,新增了一些設定以啟用cors請求,為指標持久化提供elasticsearch服務。
- apachegriffin/kafka:此映象包含kafka 0.8,以及一些演示流資料,以流模式提供流資料來源。
- zookeeper:3.5:此映象為官方zookeeper,以串流媒體模式提供zookeeper服務。
Docker 映象批次處理使用
- 下載獲取原始碼中docker/compose/docker-compose-batch.yml檔案,Griffin原始碼目錄主要包括griffin-doc、measure、service和ui四個模組
- griffin-doc負責存放Griffin的檔案
- measure採用scala語言編寫,負責與spark互動,執行統計任務
- service採用java的SpringBoot作為服務實現,負責給ui模組提供互動所需的restful api,儲存統計任務,展示統計結果。
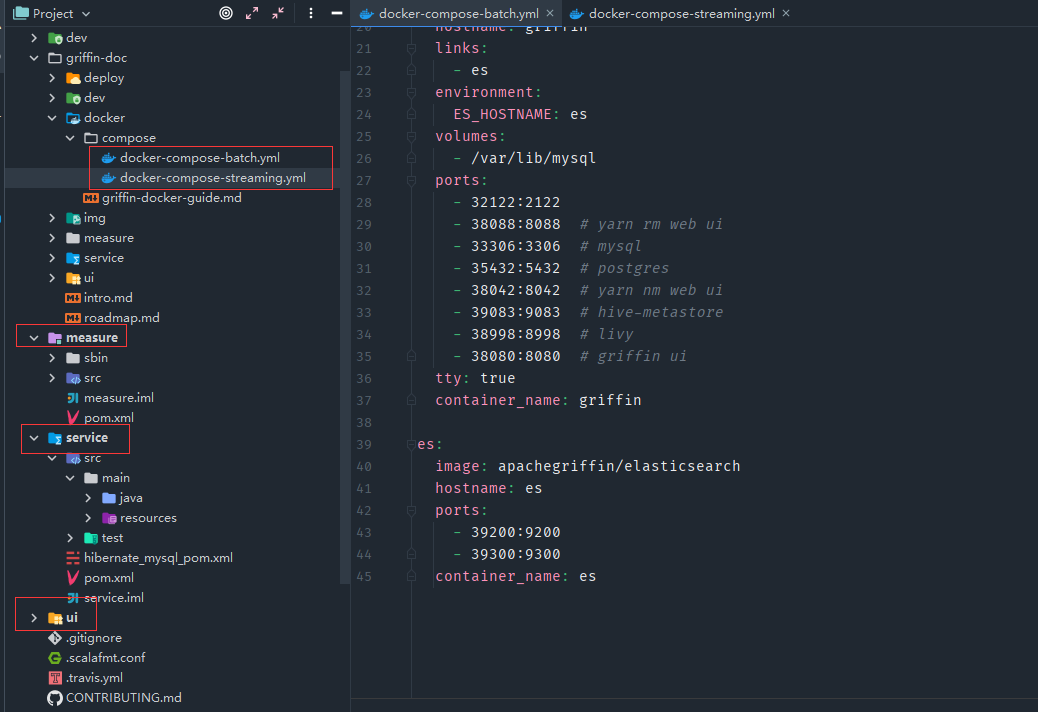
- 通過docker-compose啟動
# 啟動
docker-compose -f docker-compose-batch.yml up -d
# 檢視容器
docker container ls

- 可以通過使用任何http使用者端來嘗試Apache Griffin api,這裡以postman為例,官方原始碼中準備了兩個postman的json組態檔。
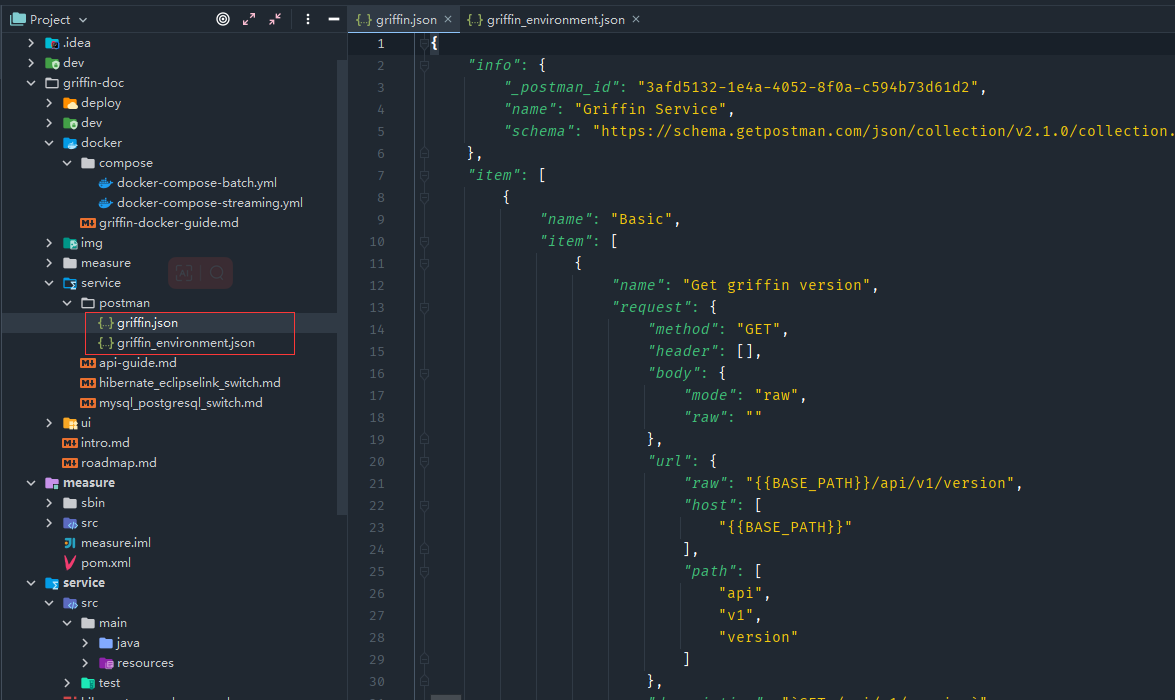
在postman以檔案匯入上面兩個json組態檔,在Griffin Environment設定BASE_PATH環境變數,埠為上面docker容器暴露的38080
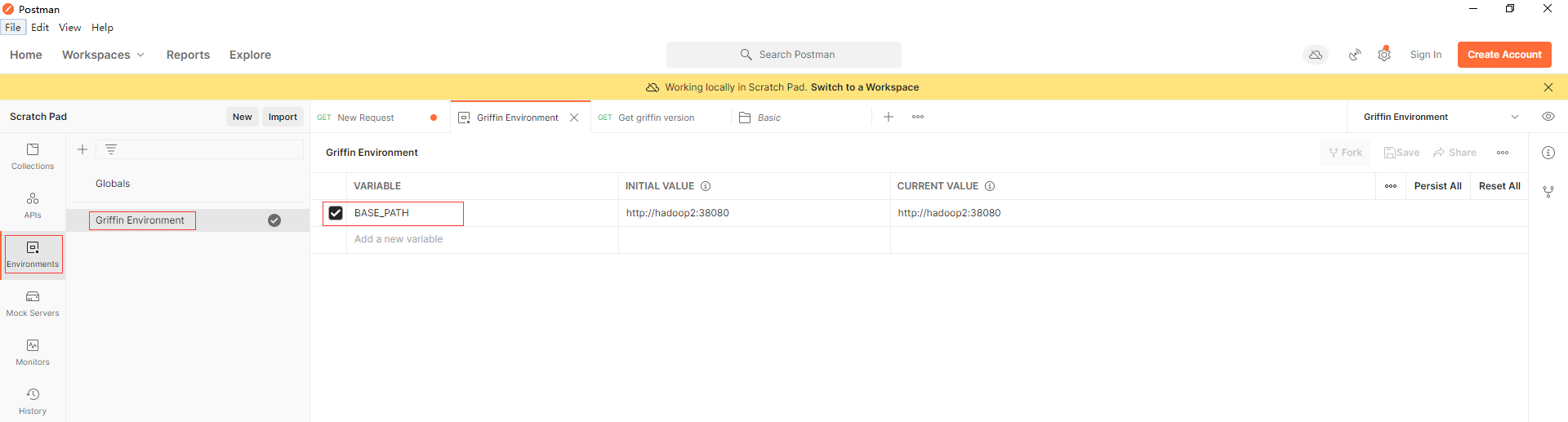
先通過呼叫api (Basic -> Get griffin version)以確保Apache Griffin服務已經啟動。
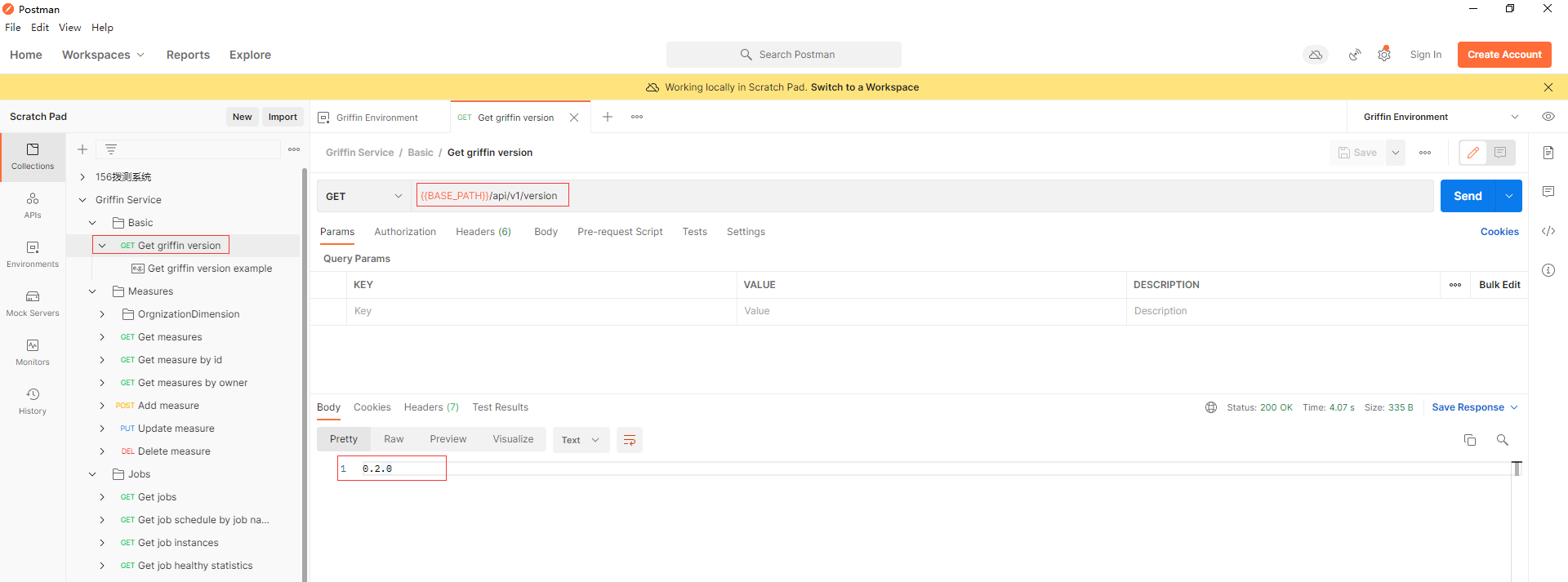
- 通過api Measures -> Add measure新增一個精度度量,在Apache Griffin中建立一個度量。
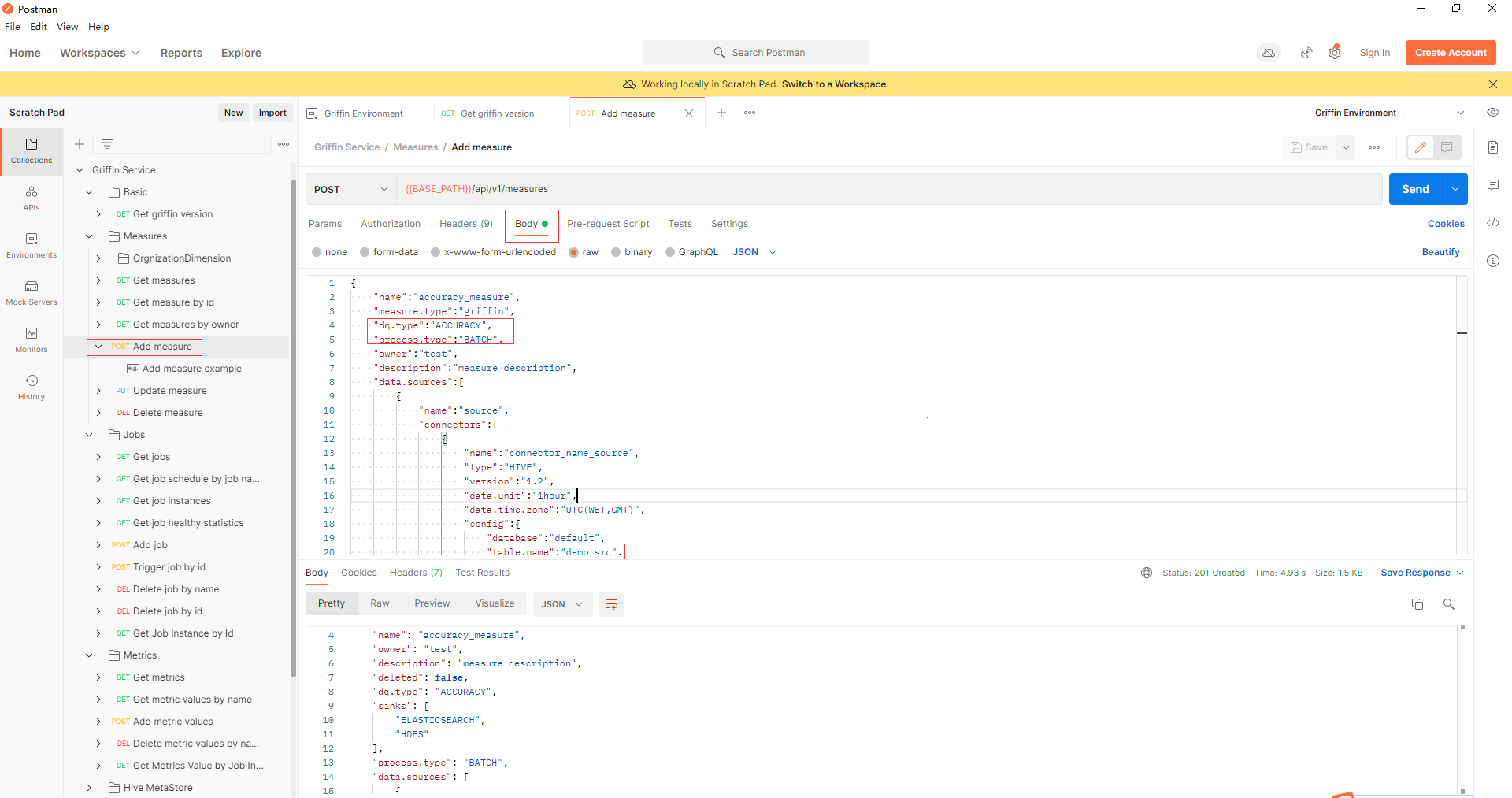
- 通過api jobs -> Add job新增一個作業來排程一個作業來執行度量。在本例中,排程間隔為4分鐘,measure.id填寫為上一步返回的id值。
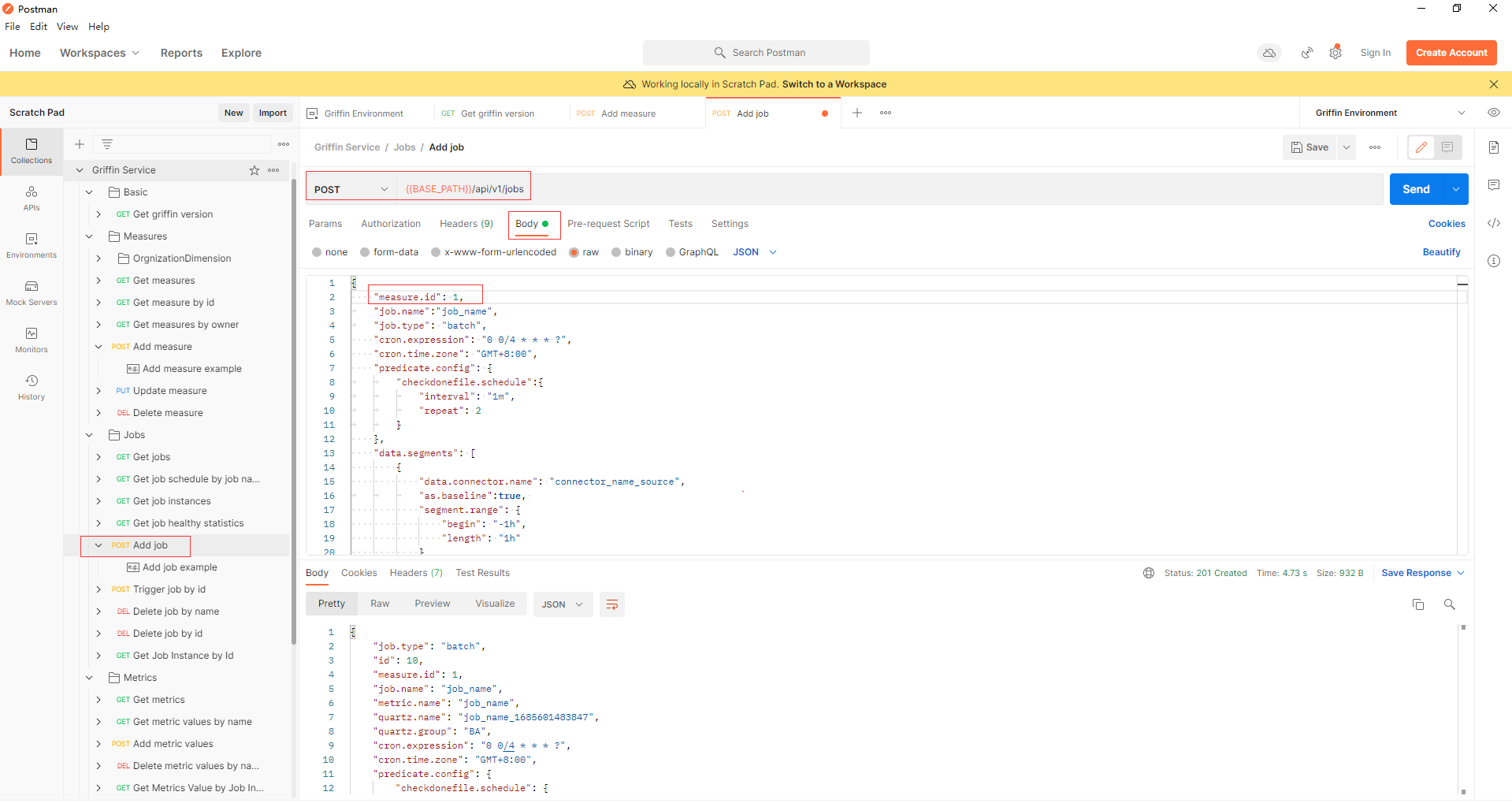
- 幾分鐘後,可以從elasticsearch獲得度量
curl -XGET 'hadoop2:39200/griffin/accuracy/_search?pretty&filter_path=hits.hits._source' -d '{"query":{"match_all":{}}, "sort": [{"tmst": {"order": "asc"}}]}'
{
"hits" : {
"hits" : [
{
"_source" : {
"name" : "metricName",
"tmst" : 1509599811123,
"value" : {
"__tmst" : 1509599811123,
"miss" : 11,
"total" : 125000,
"matched" : 124989
}
}
},
{
"_source" : {
"name" : "metricName",
"tmst" : 1509599811123,
"value" : {
"__tmst" : 1509599811123,
"miss" : 11,
"total" : 125000,
"matched" : 124989
}
}
}
]
}
}
Docker 映象流處理使用
- 下載獲取原始碼中docker/compose/docker-compose-streaming.yml檔案。
- 通過docker-compose啟動
# 啟動
docker-compose -f docker-compose-streaming.yml up -d
# 檢視容器
docker container ls
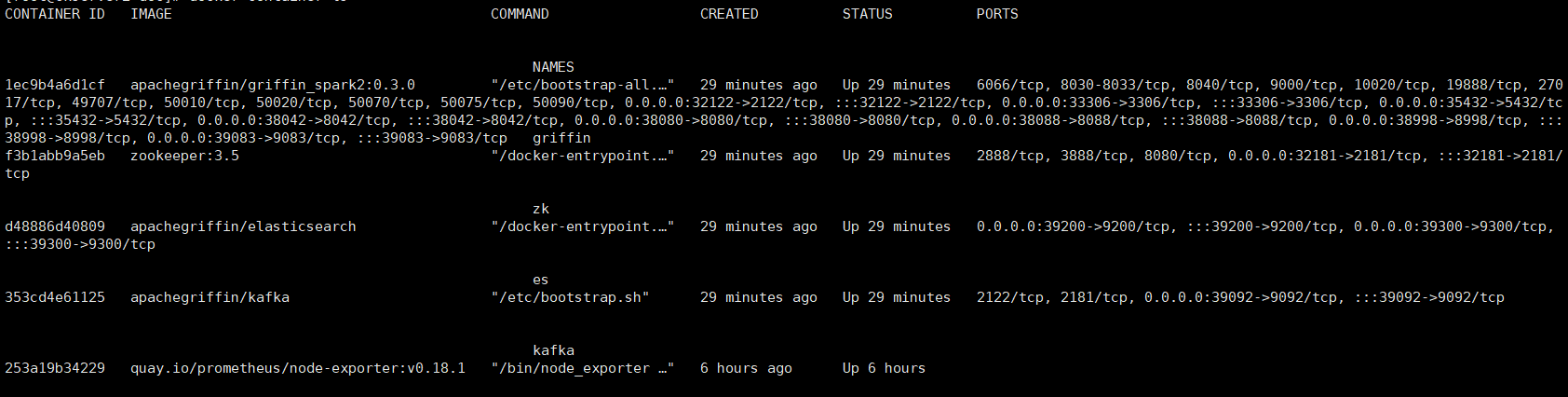
- 執行流測試
# 進入griffin容器
docker exec -it griffin bash
# 切換到measure目錄
cd ~/measure
# 執行指令碼進行流精度測量
./streaming-accu.sh
# 跟蹤紀錄檔
tail -f streaming-accu.log
- 執行流分析測量
# 先殺死上面進行程序
kill -9 `ps -ef | awk '/griffin-measure/{print $2}'`
# 然後清除上次流作業的檢查點目錄和其他相關目錄
./clear.sh
# 執行指令碼進行流分析度量
./streaming-prof.sh
# 跟蹤紀錄檔
tail -f streaming-prof.log
UI介面操作
- 存取UI http://hadoop2:38080,預設使用者密碼為griffin/griffin

- 總體業務流程
- 當前docker映象中預設有建立兩個資料資產demo_src和demo_tgt可供測試。
# 進入griffin容器
docker exec -it griffin bash
# 進入hive命令列
hive
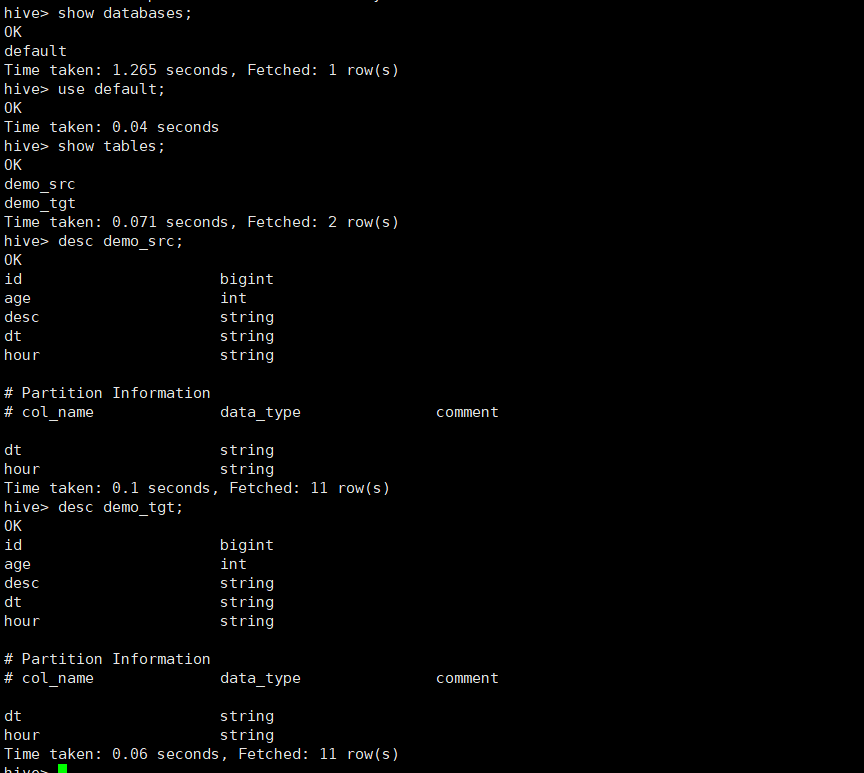
-
建立度量標準
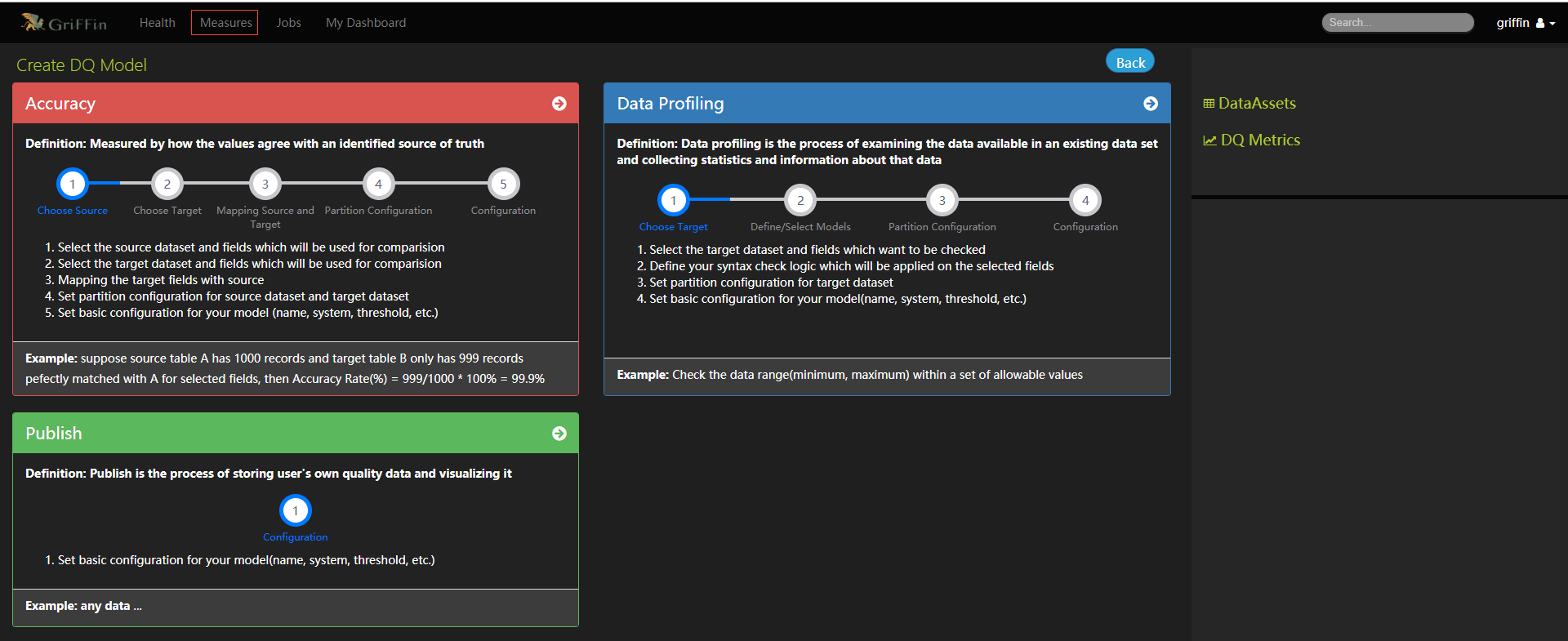
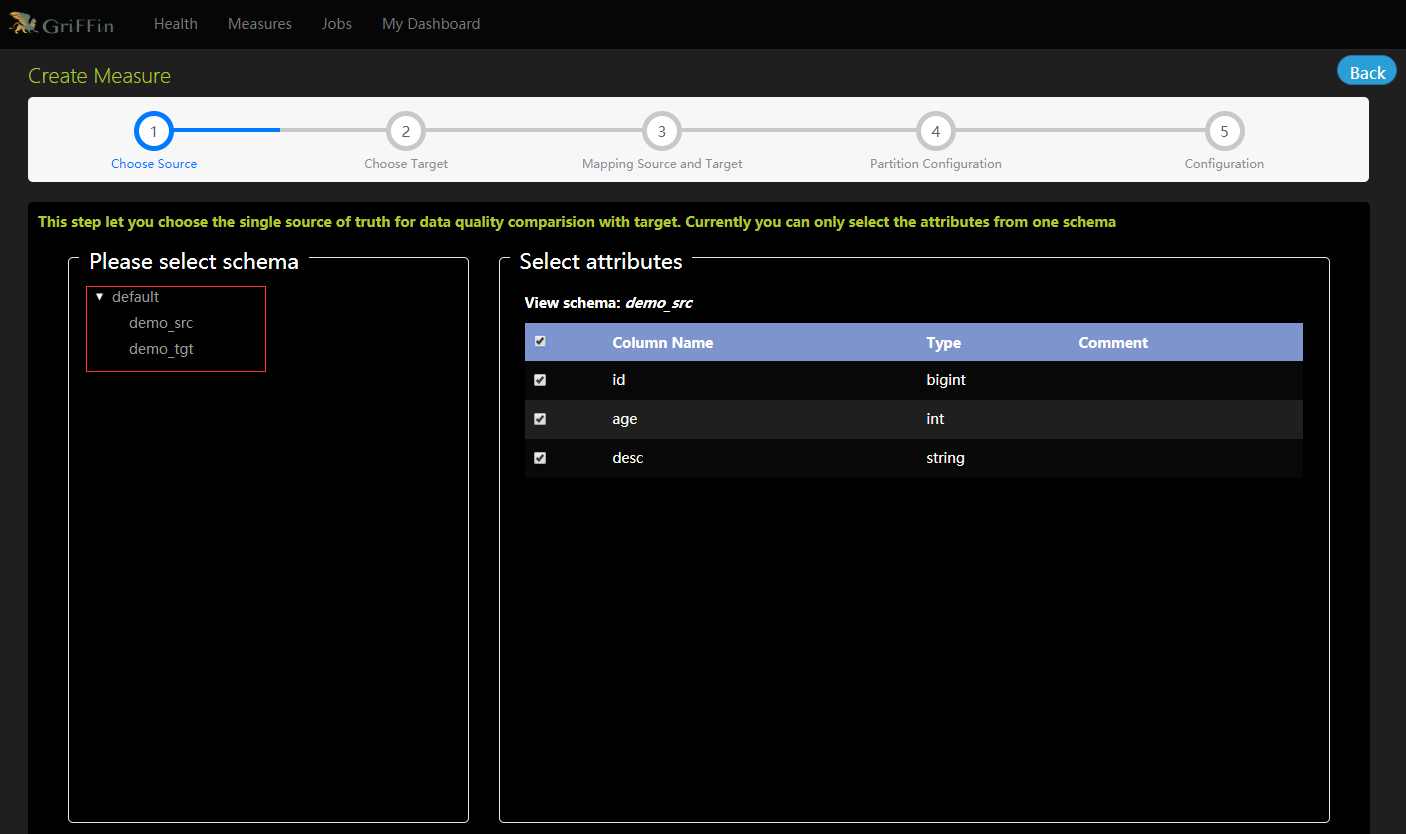
- 選擇資料來源,單一的真實來源與目標進行資料質量比較,目前只能從一個模式中選擇屬性。
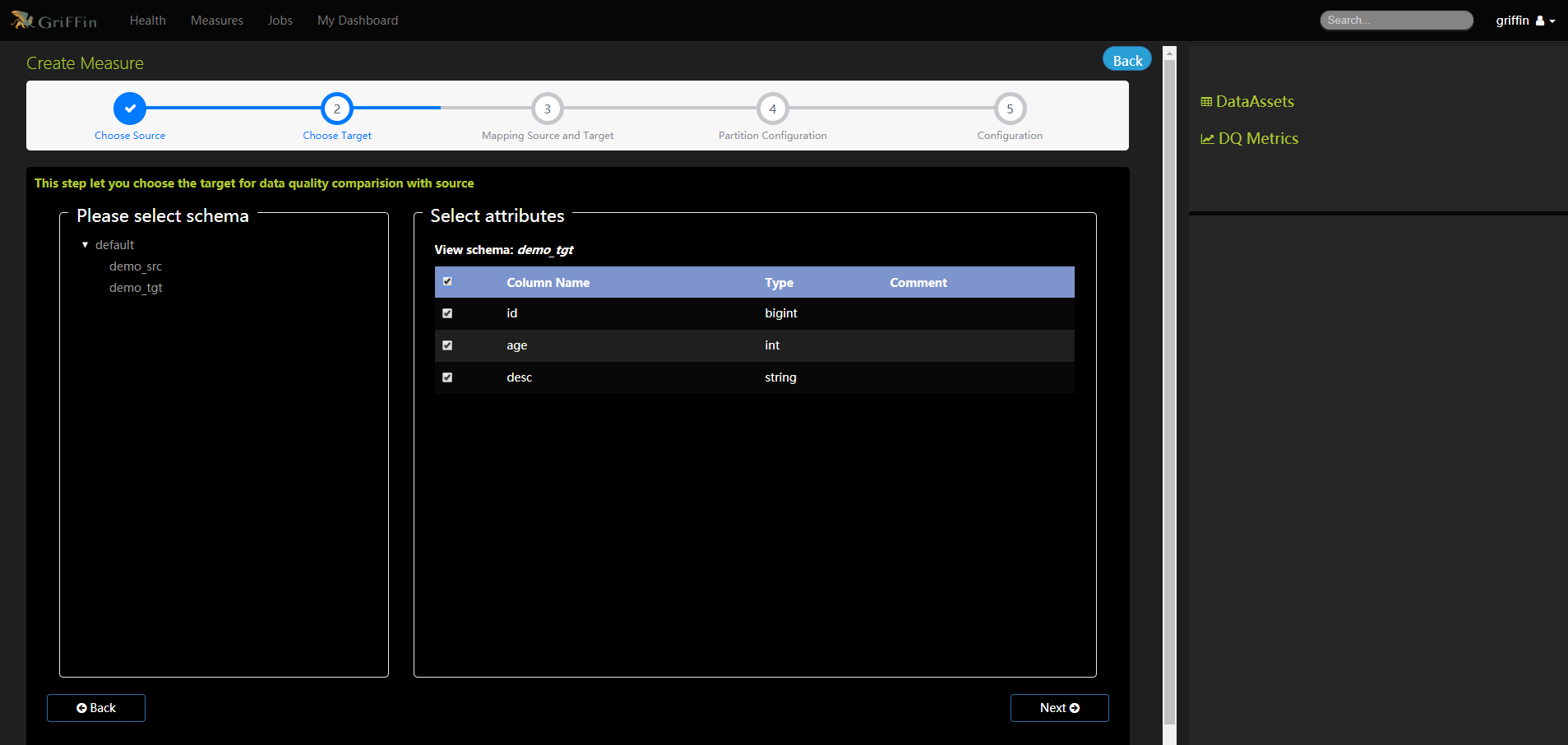
- 選擇目標,以便與源進行資料質量比較。
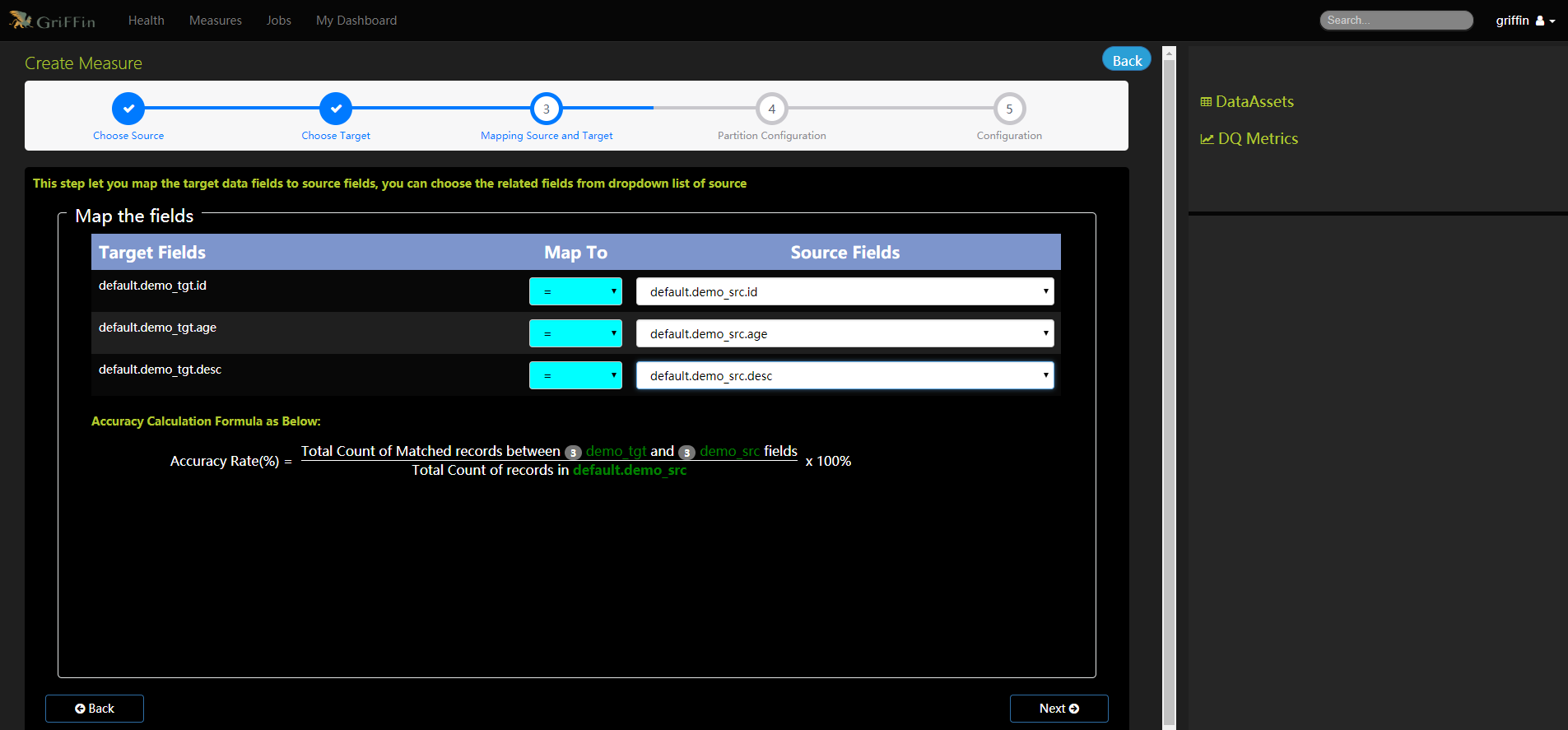
- 將目標資料欄位對映到源欄位
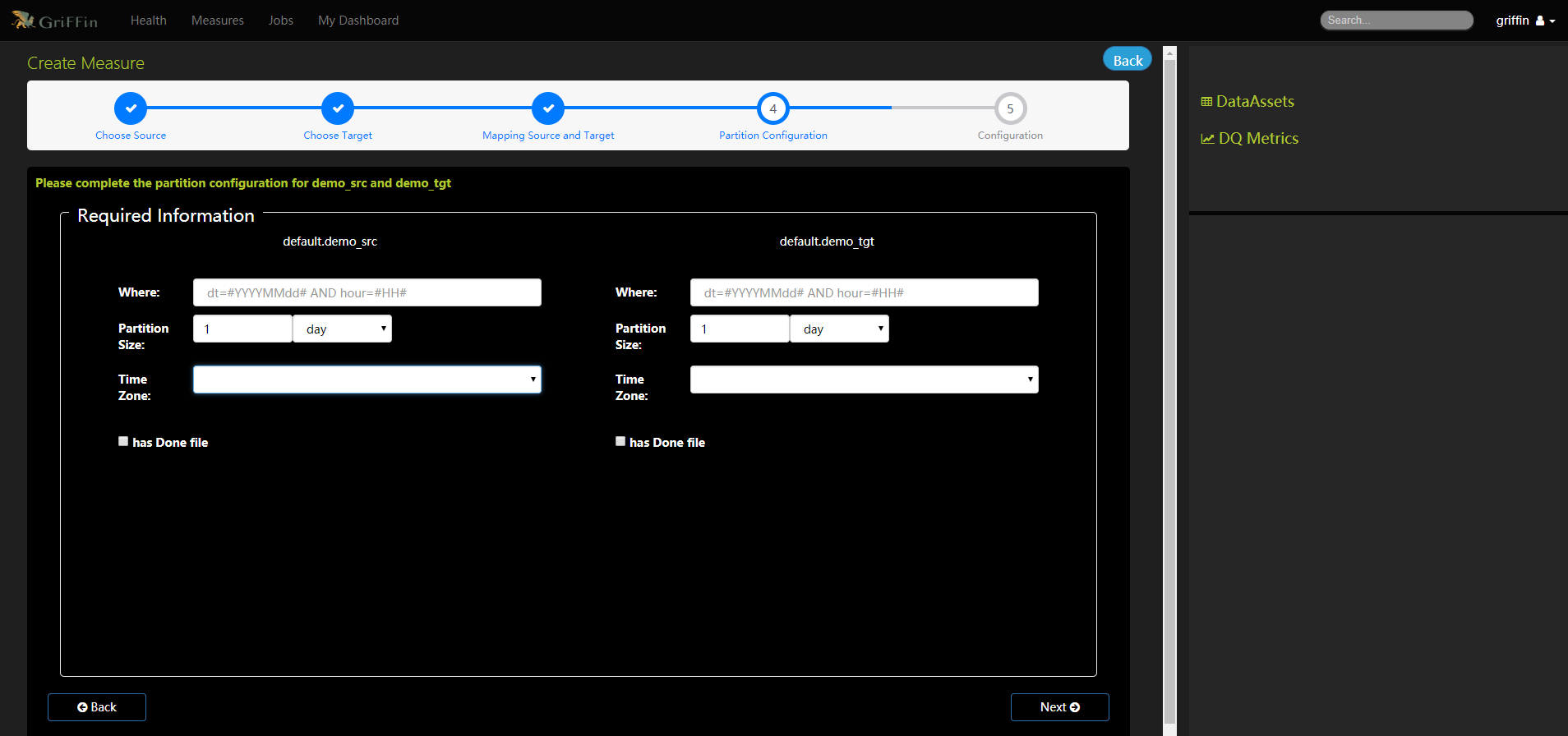
- 完成demo_src和demo_tgt的分割區設定
- 填寫度量的必要資訊
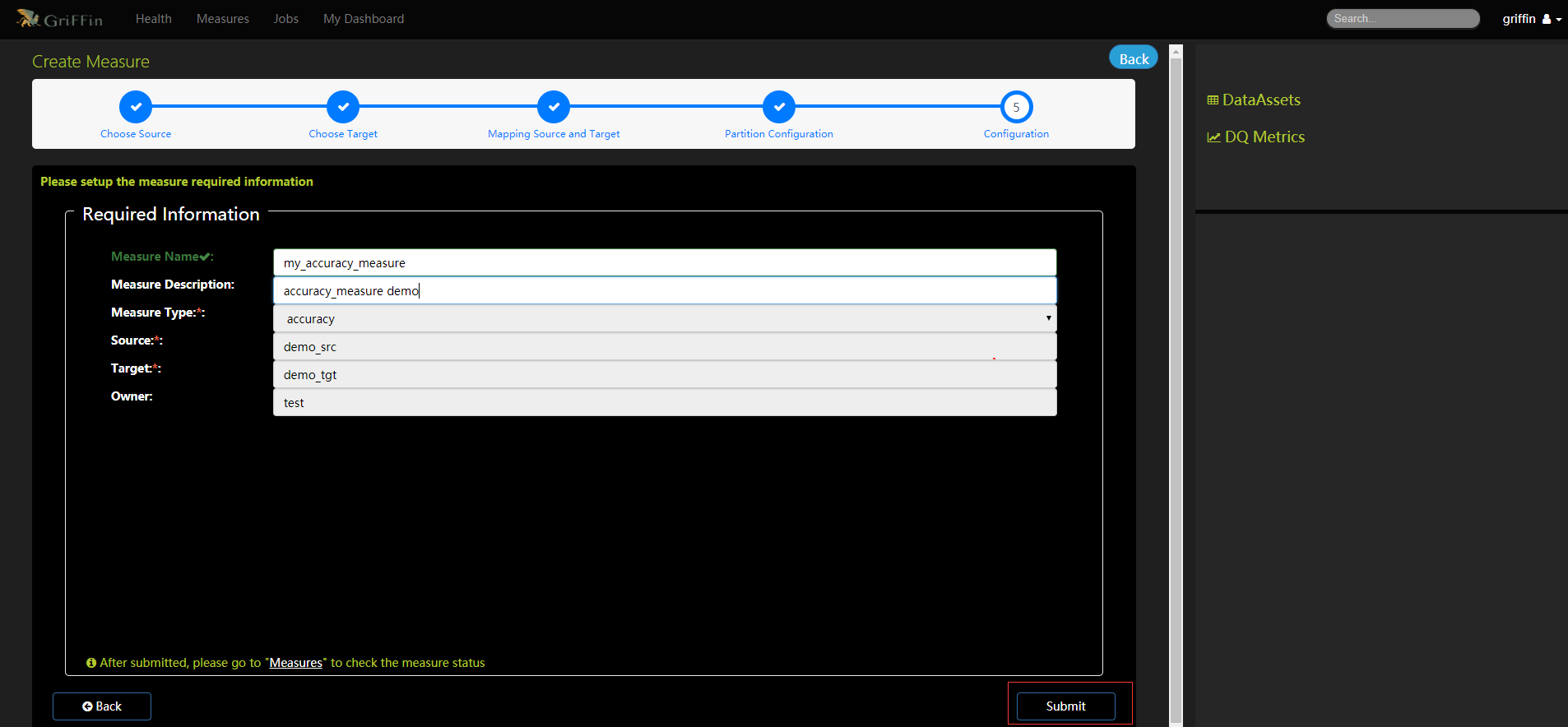
- 確保度量設定並儲存
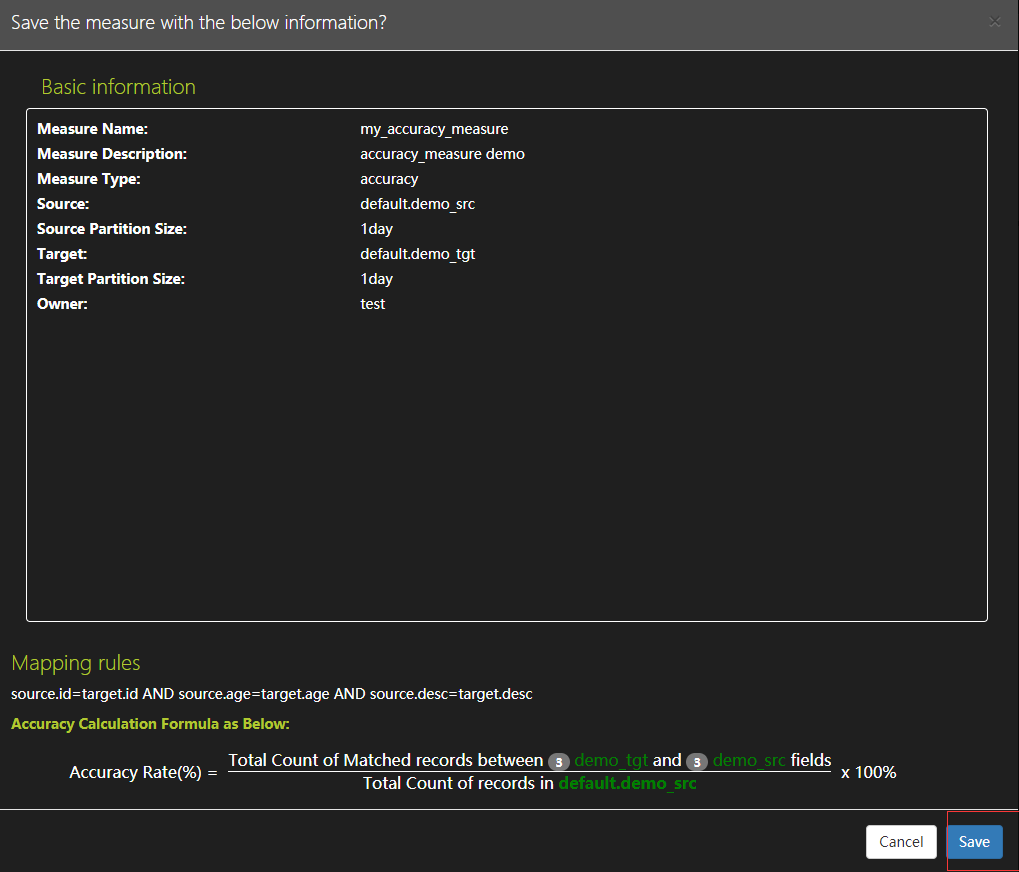
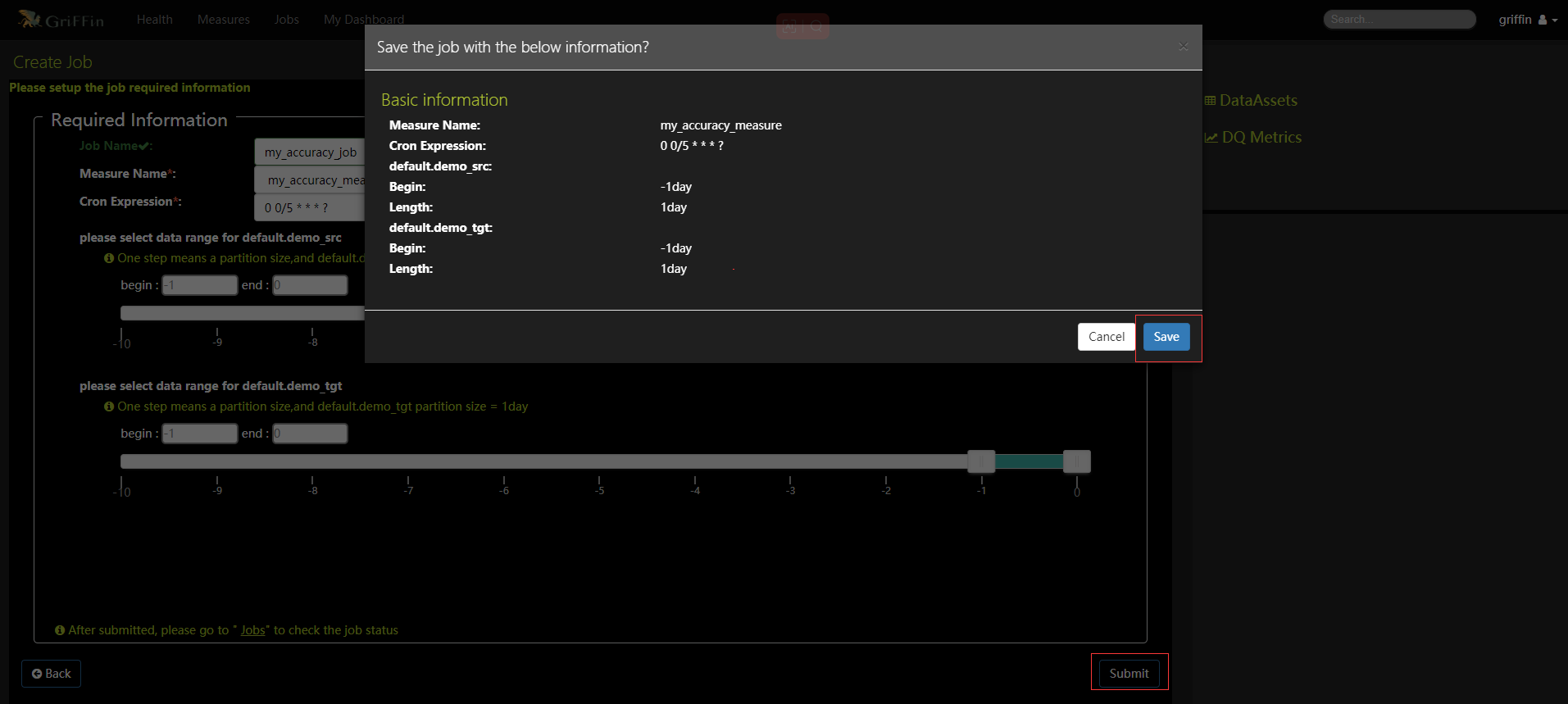
-
建立作業來定期處理度量,度量名稱選擇上面my_accuracy_measure,設定每五分鐘執行任務,點選提交按鈕確認資訊再點選儲存按鈕
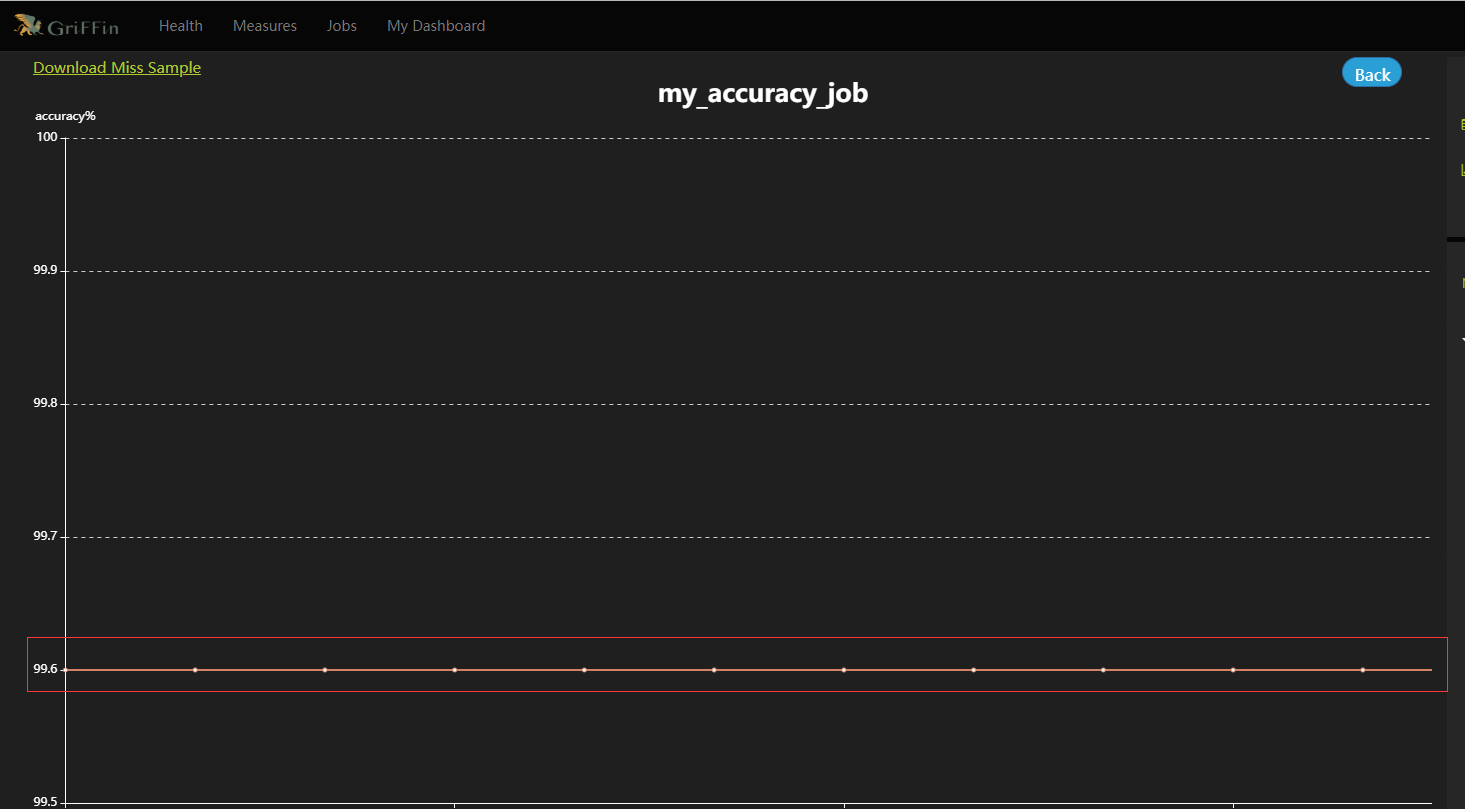
- 熱圖和儀表板將顯示度量的資料圖。資料驗證度量和分析任務都已設定完成,還可根據指標設定郵件告警等監控資訊,等過一段時間後就可以在控制面板上監控的資料質量了。可以在Jobs中檢視某個job的Metric視覺化展示,也可以直接檢視DQ Metrics和My Dashboard。
- 本人部落格網站IT小神 www.itxiaoshen.com