RWKV – transformer 與 RNN 的強強聯合
在 NLP (Natural Language Processing, 自然語言處理) 領域,ChatGPT 和其他的聊天機器人應用引起了極大的關注。每個社群為構建自己的應用,也都在持續地尋求強大、可靠的開源模型。自 Vaswani 等人於 2017 年首次提出 Attention Is All You Need 之後,基於 transformer 的強大的模型一直在不斷地湧現,它們在 NLP 相關任務上的表現遠遠超過基於 RNN (Recurrent Neural Networks, 遞迴神經網路) 的 SoTA 模型,甚至多數認為 RNN 已死。而本文將介紹一個集 RNN 和 transformer 兩者的優勢於一身的全新網路架構 –RWKV!現已在 HuggingFace transformers 庫中支援。
RWKV 專案概覽
RWKV 專案已經啟動,由 Bo Peng 主導、貢獻和維護。同時專案成員在官方 Discord 也開設了不同主題的討論頻道: 如效能 (RWKV.cpp、量化等),擴充套件性 (資料集收集和處理),相關研究 (chat 微調、多模態微調等)。該專案中訓練 RWKV 模型所需的 GPU 資源由 Stability AI 提供。
讀者可以加入 官方 discord 頻道 瞭解詳情或者參與討論。如想了解 RWKV 背後的思想,可以參考這兩篇博文:
- https://johanwind.github.io/2023/03/23/rwkv_overview.html
- https://johanwind.github.io/2023/03/23/rwkv_details.html
Transformer 與 RNN 架構對比
RNN 架構是最早廣泛用於處理序列資料的神經網路架構之一。與接收固定輸入尺寸的經典架構不同,RNN 接收當前時刻的 「token」(即資料流中的當前資料點) 和先前時刻的 「狀態」 作為輸入,通過網路預測輸出下一時刻的 「token」 和 「狀態」,同時輸出的 「狀態」 還能繼續用到後續的預測中去,一直到序列末尾。RNN 還可以用於不同的 「模式」,適用於多種不同的場景。參考 Andrej Karpathy 的部落格,RNN 可以用於: 一對一 (影象分類),一對多 (影象描述),多對一 (序列分類),多對多 (序列生成),等等。
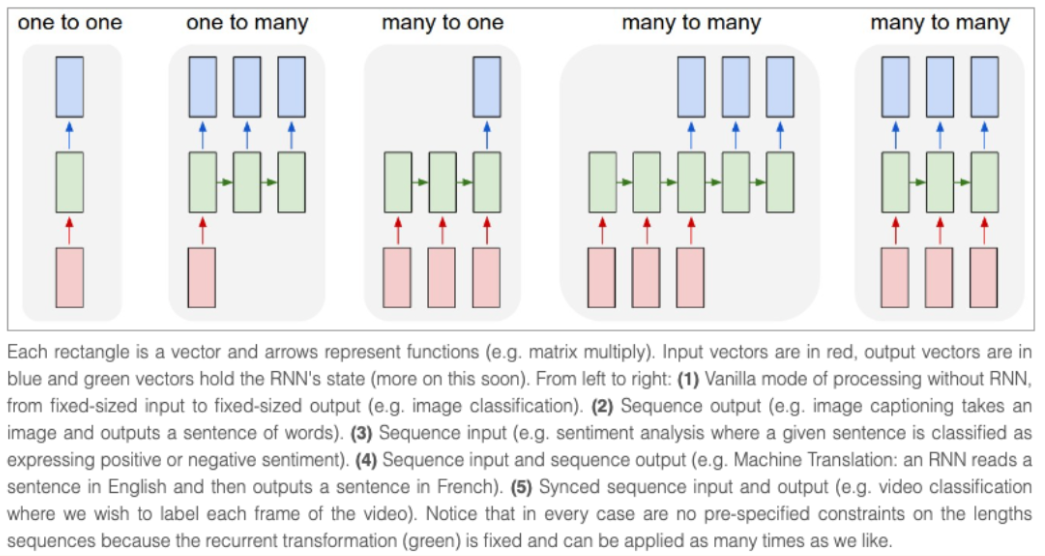
由於 RNN 在計算每一時刻的預測值時使用的都是同一組網路權重,因此 RNN 很難解決長距離序列資訊的記憶問題,這一定程度上也是訓練過程中梯度消失導致的。為解決這個問題,相繼有新的網路架構被提出,如 LSTM 或者 GRU,其中 transformer 是已被證實最有效的架構。
在 transformer 架構中,不同時刻的輸入 token 可以在 self-attention 模組中並行處理。首先 token 經過 Q、K、V 權重矩陣做線性變換投影到不同的空間,得到的 Q、K 矩陣用於計算注意力分數 (通過 softmax,如下圖所示),然後乘以 V 的隱狀態得到最終的隱狀態,這種架構設計可以有效緩解長距離序列問題,同時具有比 RNN 更快的訓練和推理速度。
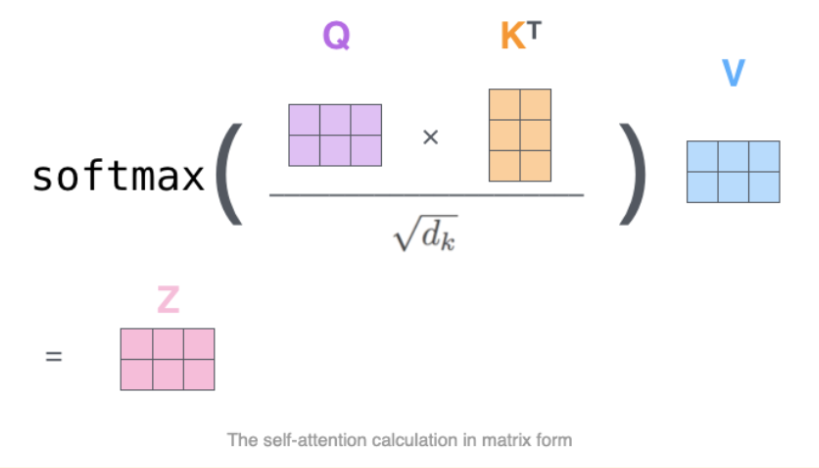

在訓練過程中,Transformer 架構相比於傳統的 RNN 和 CNN 有多個優勢,最突出的優勢是它能夠學到上下文特徵表達。不同於每次僅處理輸入序列中一個 token 的 RNN 和 CNN,transformer 可以單次處理整個輸入序列,這種特性也使得 transformer 可以很好地應對長距離序列 token 依賴問題,因此 transformer 在語言翻譯和問答等多種任務中表現非常亮眼。
在推理過程中,RNN 架構在推理速度和記憶體效率方面會具有一些優勢。例如計算簡單 (只需矩陣 - 向量運算) 、記憶體友好 (記憶體不會隨著推理階段的進行而增加),速度穩定 (與上下文視窗長度一致,因為 RNN 只關注當前時刻的 token 和狀態)。
RWKV 架構
RWKV 的靈感來自於 Apple 公司的 Attention Free Transformer。RWKV 該架構經過精心簡化和優化,可以轉換為 RNN。除此此外,為使 RWKV 效能媲美 GPT,還額外使用了許多技巧,例如 TokenShift 和 SmallInitEmb (使用的完整技巧列表在 官方 GitHub 倉庫的 README 中 說明)。對於 RWKV 的訓練,現有的專案倉庫可以將引數量擴充套件到 14B,並且迭代修了 RWKV-4 的一些訓練問題,例如數值不穩定性等。
RWKV 是 RNN 和 Transformer 的強強聯合
如何把 transformer 和 RNN 優勢結合起來?基於 transformer 的模型的主要缺點是,在接收超出上下文長度預設值的輸入時,推理結果可能會出現潛在的風險,因為注意力分數是針對訓練時的預設值來同時計算整個序列的。
RNN 本身支援非常長的上下文長度。即使在訓練時接收的上下文長度有限,RNN 也可以通過精心的編碼,來得到數百萬長度的推理結果。目前,RWKV 模型使用上下文長度上為 8192 ( ctx8192) 和 ctx1024 時的訓練速度和記憶體需求均相同。
傳統 RNN 模型的主要缺陷,以及 RWKV 是如何避免的:
- 傳統的 RNN 模型無法利用很長距離的上下文資訊 (LSTM 用作語言模型時也只能有效處理約 100 個 token),而 RWKV 可以處理數千個甚至更多的 token,如下圖所示:
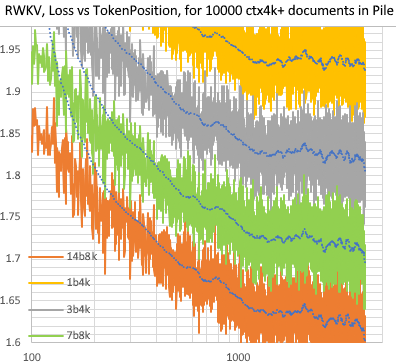
- 傳統的 RNN 模型無法並行訓練,而 RWKV 更像一個 「線性 GPT」,因此比 GPT 訓練得更快。
通過將這兩個優勢強強聯合,希望 RWKV 可以實現 「1 + 1 > 2」 的效果。
RWKV 注意力公式
RWKV 模型架構與經典的 transformer 模型架構非常相似 (例如也包含 embedding 層、Layer Normalization、用於預測下一 token 的因果語言模型頭、以及多個完全相同的網路層等),唯一的區別在於注意力層,它與傳統的 transformer 模型架構完全不同,因此 RWKV 的注意力計算公式也不一樣。
本文不會對注意力層過多的介紹,這裡推薦一篇 Johan Sokrates Wind 的博文,裡面有對注意力層的分數計算公式等更全面的解釋。
現有檢查點
純語言模型: RWKV-4 模型
大多數採用 RWKV 架構的語言模型引數量範圍從 170M 到 14B 不等。 據 RWKV 概述博文 介紹,這些模型已經在 Pile 資料集上完成訓練,並進行了多項不同的基準測試,取得了與其他 SoTA 模型表現相當的效能結果。

指令微調/Chat 版: RWKV-4 Raven
Bo 還訓練了 RWKV 架構的 「chat」 版本: RWKV-4 Raven 模型。RWKV-4 Raven 是一個在 Pile 資料集上預訓練的模型,並在 ALPACA、CodeAlpaca、Guanaco、GPT4All、ShareGPT 等上進行了微調。RWKV-4 Raven 模型有多個版本,如不同語言 (僅英文、英文 + 中文 + 日文、英文 + 日文等) 和不同大小 (1.5B 引數、7B 引數、14B 引數) 等。
所有 HF 版的模型都可以在 Hugging Face Hub 的 RWKV 社群主頁 找到。