wireshark分析tcp傳輸之檔案上傳速率問題
在網路效能問題排查思路那一節裡,我提到了檢視系統網路瓶頸的方法以及排查丟包問題的手段。
但就此分析網路問題還不夠精細,有時網路資源並沒有達到瓶頸,或者並沒有丟包產生,但是網路傳輸速率就是很慢,或者有丟包產生,但無法知道丟包的詳細過程,無法知道整個tcp傳輸過程的具體情況。
如何更加精細的檢視網路包傳輸過程,答案就是抓包。
這一節我將用上傳檔案的抓包檔案舉例,用wireshark來分析tcp的傳輸過程以及檔案傳輸速率慢的問題。
概念模型
傳輸過程簡單的可概括為,三次握手,慢啟動,擁塞避免,快速恢復,四次揮手。三次握手,四次揮手的過程一般我們都比較熟,這裡我不會特別來講,著重來看下其他幾個階段。
其他幾個階段涉及到tcp裡的視窗概念,我們首先來分下。
滑動視窗
tcp的傳送和接收資料是一個滑動視窗的模型,在tcp協定裡,傳送資料的滑動視窗叫傳送視窗,接收資料的滑動視窗叫接收視窗。
傳送視窗大小受制於對端接收視窗的大小和擁塞視窗的大小。
傳送視窗大小 = min(對端的接收視窗,擁塞視窗)
擁塞視窗
tcp傳送視窗受對端接收視窗的大小能動態調整,這種情況在區域網裡面是可行的,但是在廣域網裡,資料傳輸過程中很有可能經過很多路由器或者交換機,如果中途裝置網路處理能力變差,即使對端接收視窗能力大依然會造成嚴重的丟包,此時傳送端即不應該繼續傳送封包。
所以,擁塞視窗產生了,它有著能夠動態感知網路擁塞情況來調整傳送視窗的功能。
如何衡量擁塞情況
當傳送重傳的時候即認為此時網路產生了擁塞的情況。重傳又分為快速重傳和超時重傳,擁塞視窗的大小會根據這兩種重傳方式做出不同的策略
超時重傳
封包在傳送資料到對端時,會收到一個ack標誌的封包回來,當在一定時間內,傳送端沒有收到對端的ack包,那麼傳送端就會認為封包丟掉了,會重新傳遞相同封包到對端。這樣的重傳叫做超時重傳。
快速重傳
每次都等到超時再重傳,會增大端與端的時延, 所以快速重傳認為如果收到對端三次重複的ack,那麼即認為包丟失了,然後將丟失的包馬上傳遞到對端,不用等超時定時器觸發。
對端重複ack是如何產生的?
tcp發包是一組一組的發往對端,如果一組當中某個包丟失了,對端接收到的是丟失後的包,那麼迴應的ack將會是丟包前最大的ack序號。
慢啟動階段
連線建立後,每次收到一個ack,那麼擁塞視窗能傳送的最大MSS(一個tcp包最大傳送的位元組數)就會翻倍。當最大傳送資料到達ssthresh,就會進入擁塞避免階段。
擁塞避免
每過一個RTT(往返延時) ,擁塞視窗就會新增一個MSS大小。當碰到擁塞時,傳輸又會進入慢啟動或者快速恢復階段。那麼如何衡量擁塞,當發生重傳時即認為傳送了擁塞。
快速恢復
快速恢復是為了避免每次碰到擁塞時,就進入慢啟動階段,讓傳輸效率極劇降低這種情況出現。所以快速恢復採用遇到快速重傳時,讓擁塞視窗減半,然後MSS增長方式採用和擁塞避免階段一樣的低斜率線性增長的方式。然後當遇到超時重傳時,整個傳輸過程依然會進入慢啟動階段。

tcp stream graphs 分析tcp傳輸過程
慢啟動階段
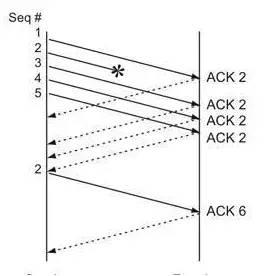
慢啟動階段的特點,單位時間內,發包的數量在呈現指數級的增長。wireshark 可以通過tcp 時序圖 Stevens來看到這種增長的變化。x軸是時間,y軸是包的序列號。

為什麼慢啟動之後會有比之前seq num 還低的點出現
因為發生了重傳,傳送的是之前發過的封包。可以看到這第一波慢啟動之後,又出現了好幾次斜率比較陡的曲線,說明整個傳輸過程又經歷了幾次慢啟動的過程,經過抓包,在5s到7.5s的這段期間,發生了大量的超時重傳。

擁塞對傳輸速率的影響
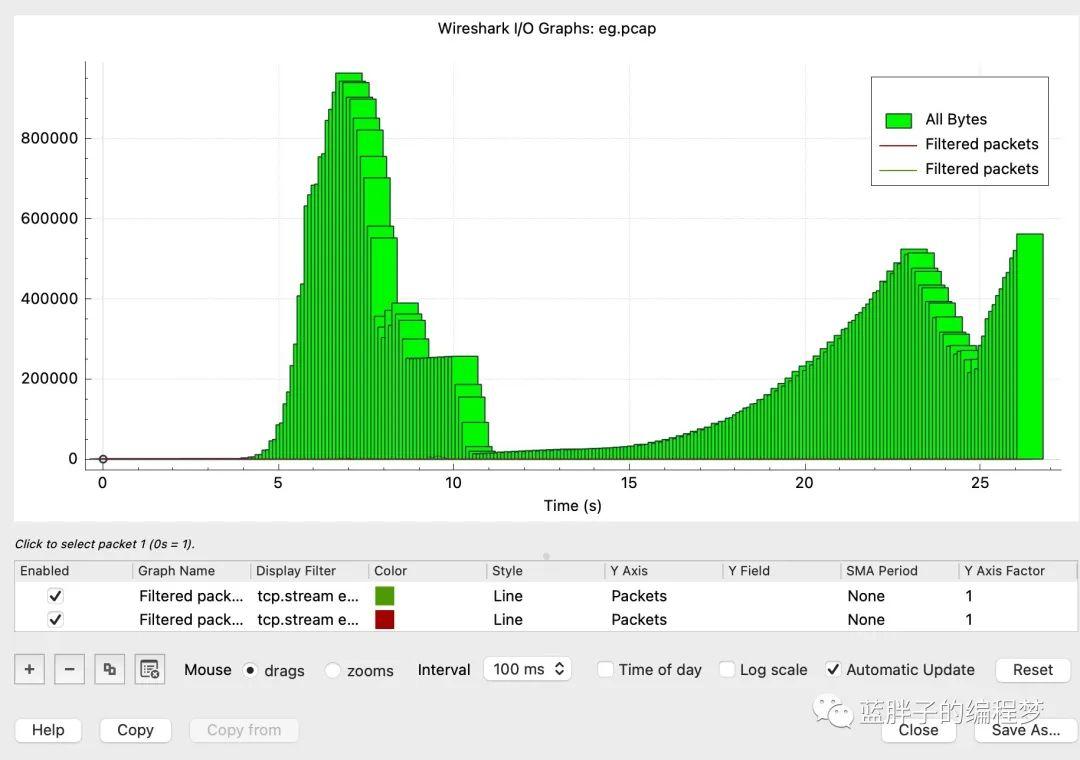
io graph 檢視整個過程的傳輸速率。
以100ms的間隔去看整個過程傳輸速率變化,可以看到在擁塞發生之前,傳輸速率呈指數級別的上漲,在好幾次超時重傳後,傳輸速率直至降低到0以後又開始了指數級別的上漲,雖然斜率沒有第一次那麼急速,但依然是指數級別,所以可以認為實際上是在經歷慢啟動階段。
在第二個波峰之後,又經過了一次傳輸速率的下降,沒有第一次下降那麼陡峭,然後速率呈現固定斜率的上漲趨勢,這和快速恢復階段的特定極其相似,可能整個tcp傳輸就是在進行快速恢復階段。
傳輸速率除了擁塞帶來的影響,還有接收視窗大小也會影響,接收視窗太小,傳輸速率也會提升不上去。
那麼如何肯定這裡傳輸速率的下降不是接收視窗的影響呢?
第一,tcp 時序圖 Stevens找到對應速率下降的時間點附近在發生大量的超時重傳,說明有大量丟包,進而說明網路狀況不好。
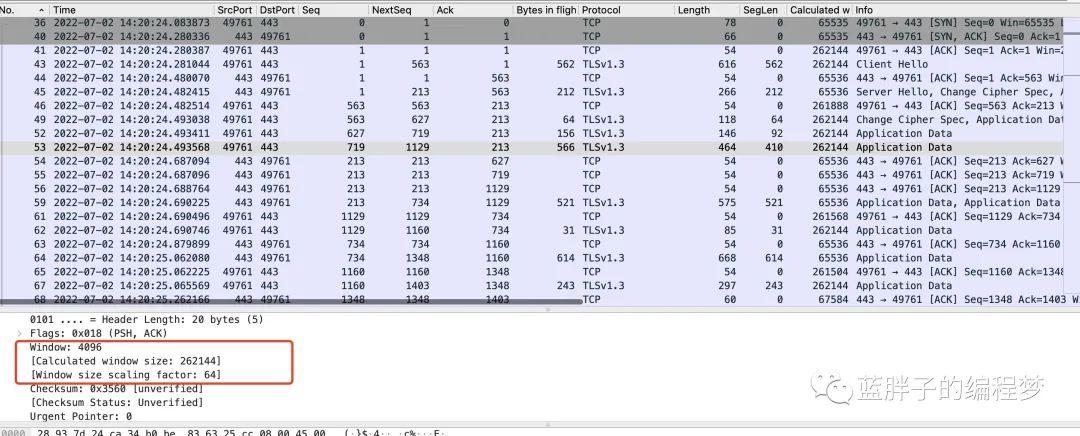
第二,可以通過wireshark window scaling 去看接收視窗隨時間的變化情況。

綠色代表接收視窗的大小,藍色的點叫 bytes out 也就是在途資料(指已經傳送但是還未被確認的資料。在途資料越多,說明傳送端傳送的資料就越多,整個過程,接收視窗在達到4M的時候就基本不變了。
傳送端傳送資料只是在差不多5s的時候達到了接收視窗的瓶頸,但由於網路擁塞,傳送端發現之前發的包丟了,所以沒有繼續傳送新的資料。而舊的封包在慢慢ack過程中,所以bytes out變小了。
並且後續,傳送的資料量大小都遠遠小於接收視窗的大小。如果接收視窗是瓶頸,在5s後,整個圖應該是 bytes out和接收視窗處於一條基本重合的水平直線上,這裡顯然不是這樣。
深入思考 如果接收視窗如果是瓶頸,該如何辦?
接收視窗大小受什麼影響?
TCP接收視窗的大小在Linux系統中取決於TCP receive buffer的大小,而TCP receive buffer的大小預設由核心根據系統可用記憶體的情況和核心引數net.ipv4.tcp_rmem動態調節。
同時,不是TCP receive buffer的大小就等於TCP接收視窗的大小。有bytes/2^tcp_adv_win_scale的大小分配給應用。如果net.ipv4.tcp_adv_win_scale的大小為2,表示有1/4的TCP buffer給應用,TCP把其餘的3/4給TCP接視窗。
在tcp報文裡,留給視窗的表示式只有16位元,這樣導致,tcp的視窗最大隻能表示64kb,所以在tcp視窗大於64kb時 需要利用TCP Options的Window scale欄位。在系統核心引數設定裡,對應的就是net.ipv4.tcp_window_scaling引數,這個引數會將window欄位乘以2的scale次方作為實際視窗大小。
這個欄位在握手的時候會告訴對方。
所以如果接收視窗是瓶頸,那麼可以調大接收方的receive buffer 以及tcp_window_scaling引數。
總結
這一節 主要用了 tcp stream graphs 宏觀的去分析了檔案上傳時tcp的傳輸過程,wireshark提供的高階功能,這一節只是冰山一角,希望能拋磚引玉。
我認為,網路抓包無處不在,其實隨手就可以抓取上網瀏覽的包去進行分析,然後通過wireshark把包傳輸過程的表現都用理論知識找到對應的解釋,不斷深挖下去,便會融會貫通。