【爬蟲+資料淨化+視覺化】用Python分析「淄博燒烤「的評論資料
一、背景介紹
您好,我是@馬哥python說 ,一枚10年程式猿。
自從2023.3月以來,"淄博燒烤"現象持續佔領熱搜流量,體現了後疫情時代眾多網友對人間煙火氣的美好向往,本現象級事件存在一定的資料分析實踐意義。
我用Python爬取並分析了B站眾多網友的評論,並得出一系列分析結論。
二、爬蟲程式碼
2.1 展示爬取結果
首先,看下部分爬取資料:

爬取欄位含:視訊連結、評論頁碼、評論作者、評論時間、IP屬地、點贊數、評論內容。
2.2 爬蟲程式碼講解
匯入需要用到的庫:
import requests # 傳送請求
import pandas as pd # 儲存csv檔案
import os # 判斷檔案是否存在
import time
from time import sleep # 設定等待,防止反爬
import random # 生成亂數
定義一個請求頭:
# 請求頭
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更換cookie,否則location爬不到
'cookie': "需換成自己的cookie值",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
請求頭中的cookie是個很關鍵的引數,如果不設定cookie,會導致資料殘缺或無法爬取到資料。
那麼cookie如何獲取呢?開啟開發者模式,見下圖:

由於評論時間是個十位數:

所以開發一個函數用於轉換時間格式:
def trans_date(v_timestamp):
"""10位時間戳轉換為時間字串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
向B站傳送請求:
response = requests.get(url, headers=headers, ) # 傳送請求
接收到返回資料了,怎麼解析資料呢?看一下json資料結構:

0-19個評論,都存放在replies下面,replies又在data下面,所以,這樣解析資料:
data_list = response.json()['data']['replies'] # 解析評論資料
這樣,data_list裡面就是儲存的每條評論資料了。
接下來嗎,就是解析出每條評論裡的各個欄位了。
我們以評論內容這個欄位為例:
comment_list = [] # 評論內容空列表
# 迴圈爬取每一條評論資料
for a in data_list:
# 評論內容
comment = a['content']['message']
comment_list.append(comment)
其他欄位同理,不再贅述。
最後,把這些列表資料儲存到DataFrame裡面,再to_csv儲存到csv檔案,持久化儲存完成:
# 把列表拼裝為DataFrame資料
df = pd.DataFrame({
'視訊連結': 'https://www.bilibili.com/video/' + v_bid,
'評論頁碼': (i + 1),
'評論作者': user_list,
'評論時間': time_list,
'IP屬地': location_list,
'點贊數': like_list,
'評論內容': comment_list,
})
# 把評論資料儲存到csv檔案
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding='utf_8_sig',否則可能會產生亂碼問題!
下面,是主函數迴圈爬取部分程式碼:(支援多個視訊的迴圈爬取)
# 隨便找了幾個"淄博燒烤"相關的視訊ID
bid_list = ['BV1dT411p7Kd', 'BV1Ak4y1n7Zb', 'BV1BX4y1m7jP']
# 評論最大爬取頁(每頁20條評論)
max_page = 30
# 迴圈爬取這幾個視訊的評論
for bid in bid_list:
# 輸出檔名
outfile = 'b站評論_{}.csv'.format(now)
# 轉換aid
aid = bv2av(bid=bid)
# 爬取評論
get_comment(v_aid=aid, v_bid=bid)
三、視覺化程式碼
為了方便看效果,以下程式碼採用jupyter notebook進行演示。
3.1 讀取資料
用read_csv讀取剛才爬取的B站評論資料:
檢視前3行及資料形狀:

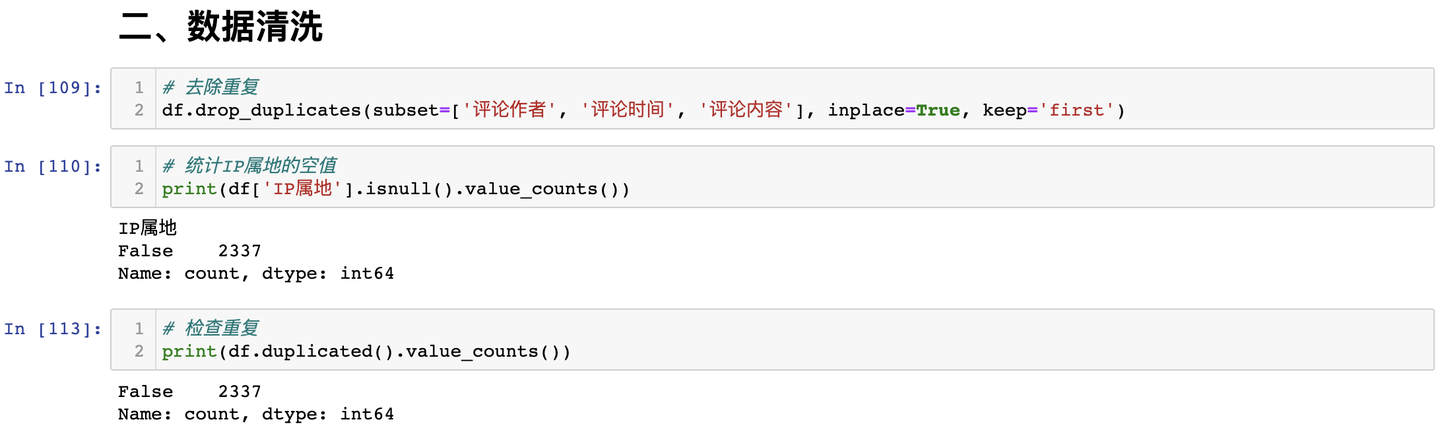
3.2 資料淨化
處理空值及重複值:
3.3 視覺化
3.3.1 IP屬地分析-柱形圖

結論:從柱形圖來看,山東位居首位,說明淄博燒烤也受到本地人大力支援,其次是四川、廣東等地討論熱度最高。
3.3.2 評論時間分析-折線圖
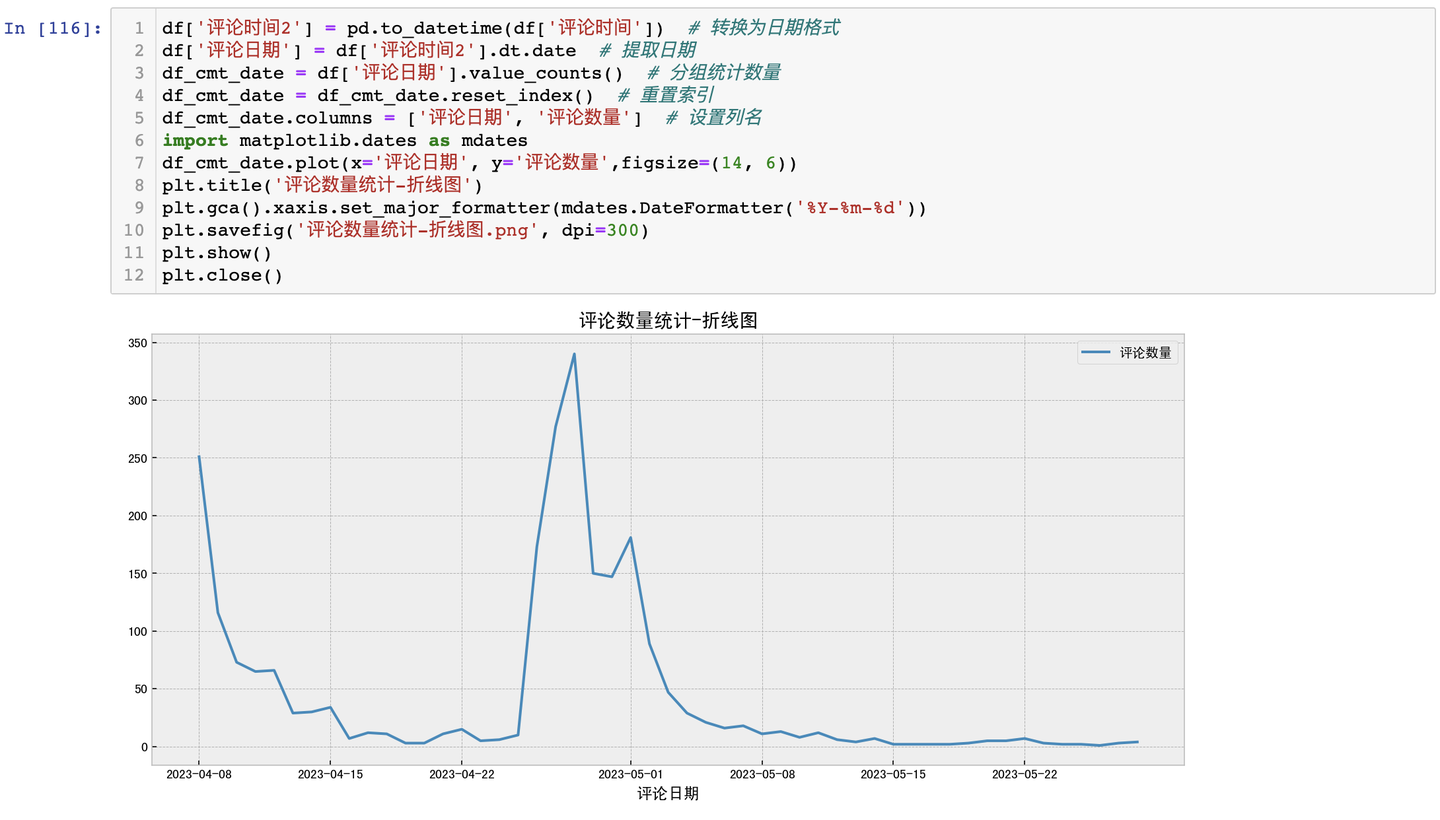
結論:從折線圖來看,4月26日左右達到討論熱度頂峰,其次是5月1號即五一勞動節假期第一天,大量網友的"進淄趕烤"也製造了新的討論熱度。
3.3.3 點贊數分佈-箱線圖
由於點贊數大部分為0或個位數情況,個別點贊數到達成千上萬,箱線圖展示效果不佳,因此,僅提取點贊數<10的資料繪製箱線圖。
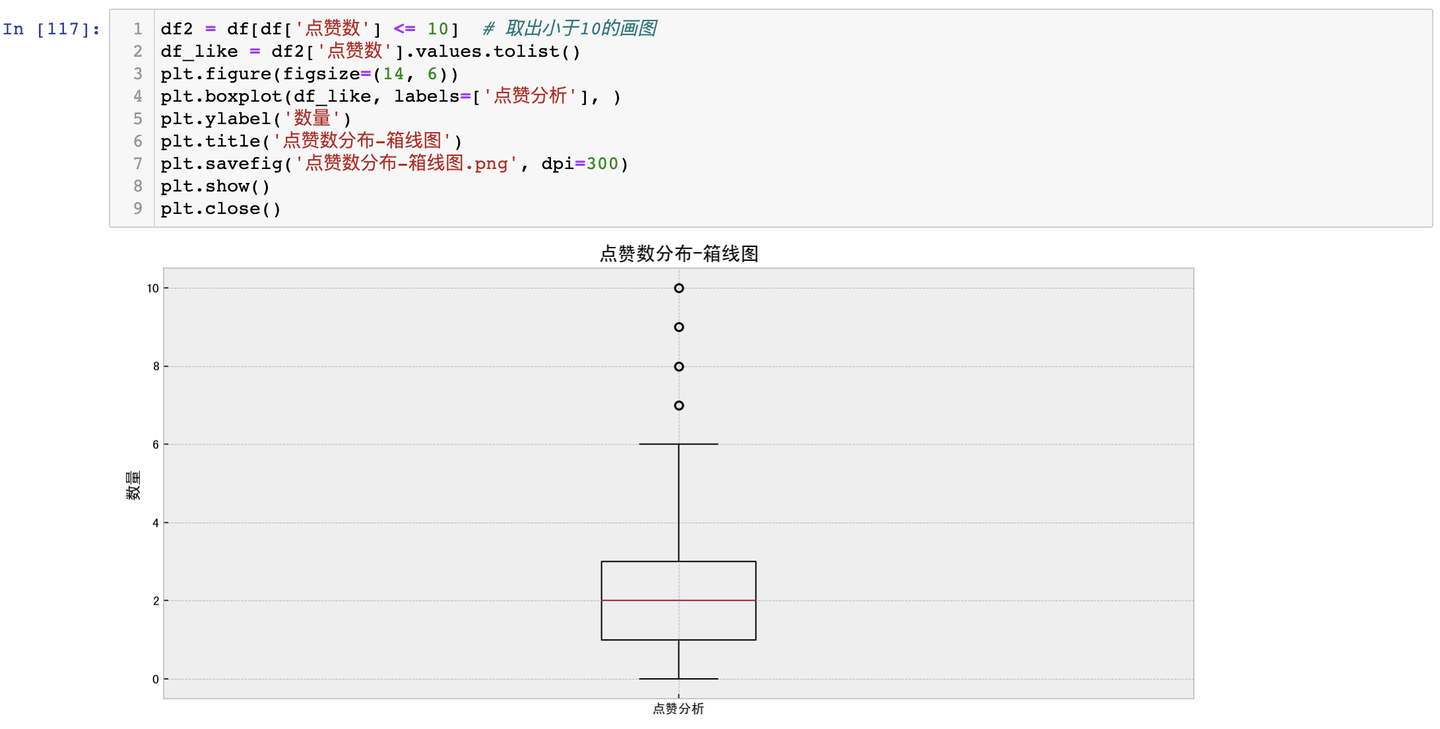
結論:從箱線圖來看,去除超過10個點贊數評論資料之後,大部分評論集中在0-3個點贊之間,也就是隻有少量評論引起網友的點贊共鳴和認可。
3.3.4 評論內容-情感分佈餅圖
針對中文評論資料,採用snownlp開發情感判定函數:
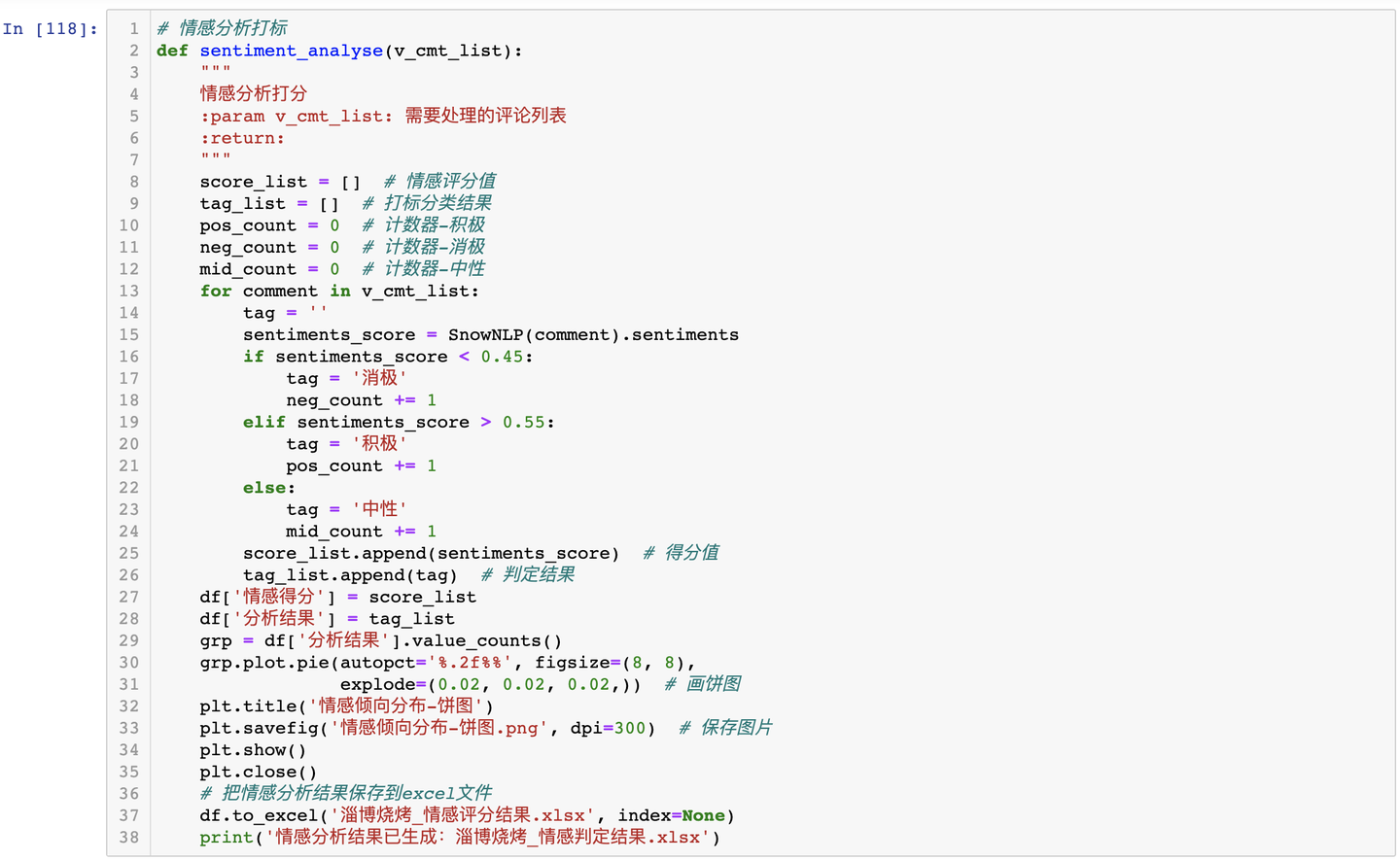
情感分佈餅圖,如下:
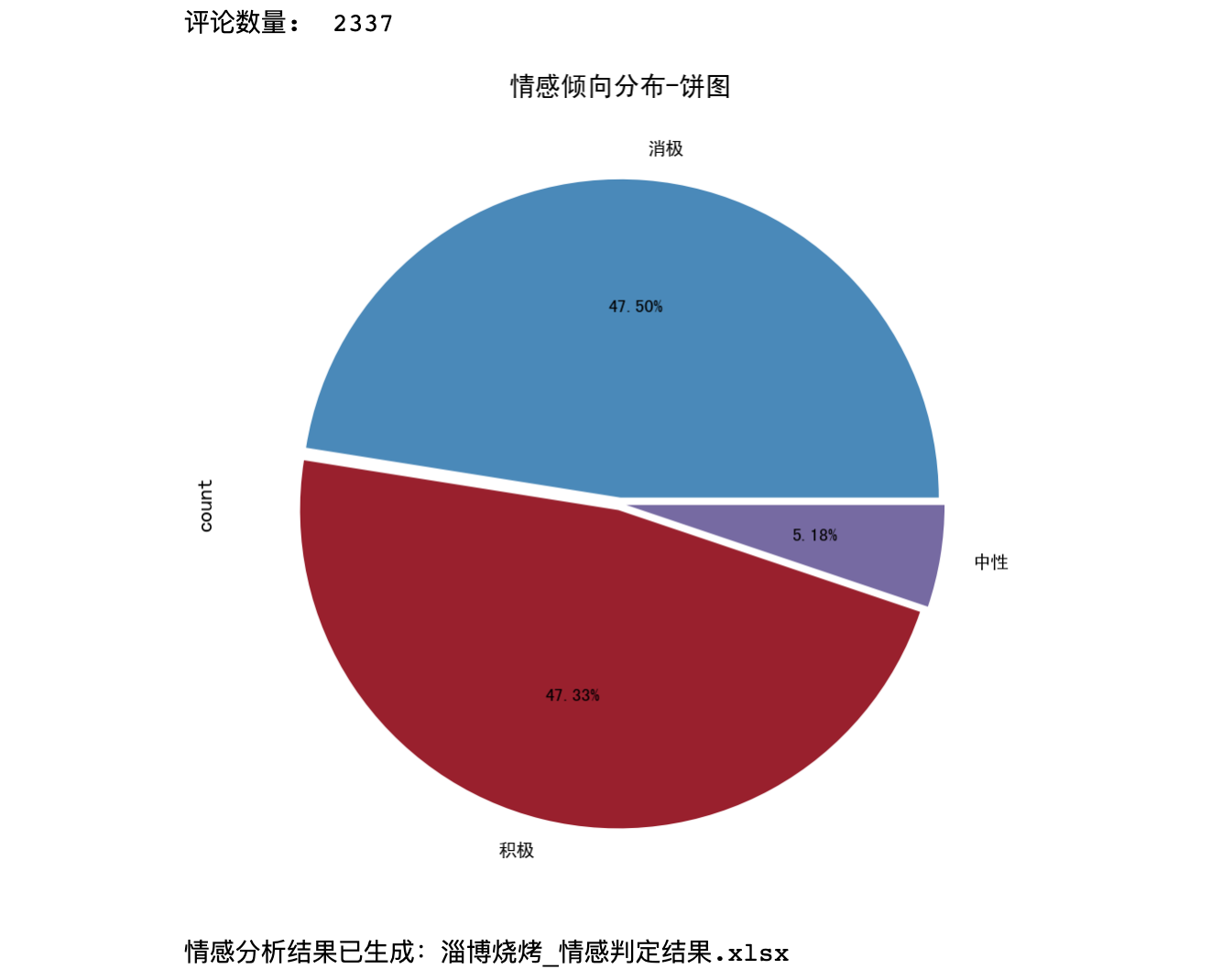
結論:從餅圖來看,積極和消極分別佔比不到一半,說明廣大網友在認可淄博燒烤現象的同時,也有大量負面討論存在,比如討論燒烤的價格略高、住宿條件欠佳、環境汙染等負面話題。
3.3.5 評論內容-詞雲圖
由於評論內容中存在很多"啊"、"的"、"了"等無意義的干擾詞,影響高頻詞的提取,因此,採用哈工大停用詞表作為停用詞詞典,對干擾詞進行遮蔽:

然後,繪製詞雲圖:

結論:從詞雲圖來看,"淄博"、"燒烤"、"山東"、"好吃"、"城市"、"好"、"物價"等正面詞彙字型較大,體現出眾多網友對以「淄博燒烤」為代表的後疫情時代人間煙火的美好向往。
四、技術總結
「淄博燒烤」案例完整開發流程:
- requests爬蟲
- json解析
- pandas儲存csv
- pandas資料淨化
- snownlp情感分析
- matplotlib視覺化,含:
1)IP屬地分析-柱形圖Bar
2)評論時間分析-折線圖Line
3)點贊數分佈-箱線圖Boxplot
4)評論內容-情感分佈餅圖Pie
5)評論內容-詞雲圖WordCloud
五、演示視訊
程式碼演示視訊:https://www.bilibili.com/video/BV18s4y1B71z
六、完整原始碼
完整原始碼:【爬蟲+資料淨化+視覺化分析】輿情分析"淄博燒烤"的B站評論
我是 @馬哥python說 ,持續分享python原始碼乾貨中!