如何科學地利用MTTR優化軟體交付流程?
谷歌提出的衡量 DevOps 質量的 DORA 指標讓 MTTR(平均恢復時間) 名聲大振。在本文中,你將瞭解到 MTTR 的作用、為什麼它對行業研究很有用、你可能被它誤導的原因以及如何避免 MTTR 產生的弊端。
MTTR 究竟是在測量什麼?
MTTR 指平均恢復時間,既是 Mean Time to Recovery,有時也是 Mean Time to Restore。它是指在發生故障後使系統恢復執行所需的時間,它是 DORA 指標的一部分,目前已經成為軟體交付效能的標準。
當你的所有 DORA 指標都表現良好,那麼就會擁有快速交付的高質量軟體、更滿意的員工,從而在所處的行業中取得競爭優勢。
如何計算 MTTR
收集 MTTR 需要收集每個故障從開始到結束的持續時間,然後將這些時間相加,並用總數除以數量。一些團隊會對所有事件進行排序,並選擇中間值來計算恢復時間的中位數。
軟體交付過程會影響恢復時間,尤其是:
- 軟體架構
- 檔案
- 可觀測性
- 部署流水線效能
當你可以快速恢復,事件的影響就會降低,客戶也會更滿意。因此,企業應該檢查和調整流程以快速恢復並降低風險。
為什麼 MTTR 對行業研究很有用?
DevOps 研究和評估(DORA)將調查作為研究方法的一部分。需要各類資料和效能水平不同的企業對問題進行回答。DORA quick check 將 MTTR 問題表述為:
對於您開發的主要應用程式或服務,當發生影響使用者的服務事件或故障(例如,計劃外中斷、服務受損)時,通常需要多長時間才能恢復服務?
- 超過6個月
- 1-6個月之間
- 1周到1個月之間
- 1天到1周之間
- 小於1天
- 小於1個小時
大多數從事軟體交付工作的人對故障持續時間都有大概的感覺,因此在調查中使用寬泛的選項可以讓人們很容易選擇答案。研究人員利用這些資訊來尋找資料中的效能組,他們還尋找各種實踐之間的關係以及對業務成果的影響,並利用這些發現搭建 DevOps 結構方程模型。
為什麼 MTTR 資料可能誤導你的團隊?
雖然 MTTR 在研究中對效能組有幫助,但這並不是你在團隊中使用故障資訊的方式。你應該利用這些資訊從服務中斷中學習,並改進今後的處理方式。最終目標並不是與其他團隊或組織進行攀比。
如果要持續優化軟體開發和交付流程,只關注平均數可能忽略了一些重要訊號。因此需要更細化的資訊來了解故障處理的情況,並找到其原因。
Verica 事件資料庫(VOID)包含了由近600個組織共用的超過10000個事件,他們在 VOID 報告中分析了這些事件。在2022年的報告中對 MTTR 做出如下評論:
MTTR 不是衡量複雜軟體系統可靠性的可行指標,原因有很多,其中突出的原因是其存在潛在的差異性。
當資料量很大時,平均數所帶來的差異性會變得平緩,但一般而言企業的故障頻率不太可能會達到每月數千起(即在這個數量級才使平均數有效)。如果事件數量較少,平均數則成為一個不穩定的指標。甚至儘管在事件管理方面有所改進,但平均數依舊在增加。
VOID 資料庫還發現,大多數事件在2小時內得到解決,但存在一些長尾資料導致平均值被推高或推低,進而無法代表客戶看待系統可靠性的方式。
組織可以通過排除異常值來消除這種差異性,但那樣就會隱藏一些有價值的資訊。因此需要一個更好的方法使用這些資料來改善整個流程。
恢復時長的用武之地
與其把事件恢復時間壓縮成一個平均數,不如把每個持續時間繪製在圖表上。使用散點圖或箱線圖(Box-and-whisker chart),在不失真實性的情況下將持續時間視覺化。這可以顯示趨勢和異常值,這比平均數更有價值。
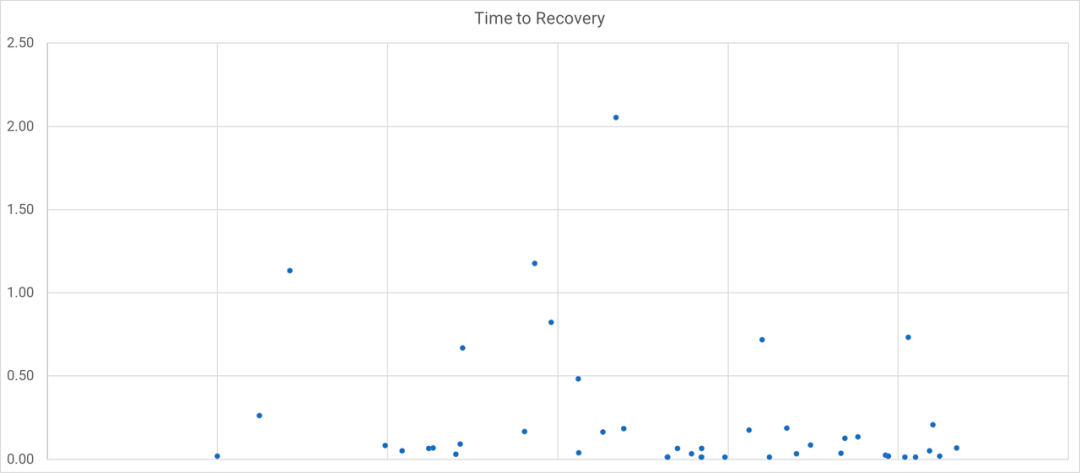
你現在可以清晰地瞭解修復時長的趨勢,看看是否隨著時間的推移而改善。還可以識別出異常值,並充分討論如何更好地處理它們,進而利用它們來改善事件管理和系統穩定性。
如果事件需要程式碼修復,恢復時間取決於部署流水線的效能。能夠快速、安全地部署軟體新版本也有助於進行事件管理。另外,引入監控和告警工具有助於幫助企業在影響客戶之前發現問題。
明確事件的定義
要獲取大部分事件持續時間的資料,你需要對此有統一的定義:
- 什麼是事件
- 什麼是開始時間
- 什麼是結束時間
對於事件,企業內部需要有一個清晰、一致的定義。它應該包括當系統可以優雅地處理一個故障時,組織是否將其算作一個事件。例如,團隊可以認為只有對客戶產生影響的故障才是事件。
對於開始時間和結束時間也是一樣的。是在導致事件發生的條件首次出現時開始計時,還是在問題對客戶可見時開始計時?根據定義,甚至可能出現負的事件持續時間,即在故障影響到客戶之前就解決了它。
就事件的定義和如何衡量其持續時間達成一致,使你的衡量標準更具可比性。當長期使用 DORA 指標時,它們可能不再能激發你進行下一步改進。你可以用 SPACE 框架設計一個新的衡量系統。
使用 SPACE 框架來衡量事件響應
你可以通過 SPACE 框架來全面瞭解事件響應和管理,其將測量結果分為5個類別:
- 滿意度和幸福感(Satisfaction and wellbeing)
- 表現(Performance)
- 活躍度(Activity)
- 溝通與共同作業(Communication and collaboration)
- 效率與流程(Efficiency and flow)
企業不必一次性採用所有指標。SPACE 框架建議至少在3個維度上進行測量,如果能涵蓋個人、團隊和系統層面則更好。最終目標是建議一套合理的測量方法來幫助企業改進流程。
滿意度和幸福感
定性調查在這裡最有效,可以調查事件管理者,看他們對事件發生後恢復的滿意程度:
- 事件管理流程
- On-call 排期
- 在事件發生期間升級或存取專家以提供幫助的難易程度
還可以去檢視相關資料以確定 On-call 排期的合理性:
- 當地時間幾點電話響起
表現
使用以下指標可以衡量事件管理表現:
- 系統是否按照其可靠性目標執行
- 事故條件和察覺到事故發生之前的時長
- 解決事故所需的時間
活躍度
事件活躍度並不僅僅是事件數量,其他指標也可以納入參考。大部分資料其實已經在你的現有系統之中:
- 監控工具發出的告警數量
- 事件發生的數量
- 同時發生事件的數量
溝通與共同作業
資訊透明對事件管理至關重要。你應該把這個維度納入事件測量策略中。擁有高質量的溝通將減少解決故障所需的時間,可以衡量以下指標:
- 每個事件所牽涉的人員數量
- 每個事件涉及多少個不同的團隊
- 為處理一個事件建群的數量
- 檢視事件報告的次數(或給予積極評價,或在其他事件中提到它)
效率及流程
當採用效率和流程的指標時,就會發現系統中的浪費。如果反覆「踢皮球」,那麼處理事件的進度就會停滯不前,解決時間更長。以下指標可以幫你發現瘟疫:
- 重新分配事件的頻率
- 每個事件嘗試緩解的次數
SPACE 框架總結
當需要獲得各種洞察並改進系統時,團隊應該自由構建並根據實際情況調整指標。企業可能會發現從滿意度、溝通和效率這3類指標開始是有幫助的,因為通過測量這些指標並對相關情況進行優化會帶來立竿見影的效果。
如果你已經對客戶進行調查,不妨問問他們如何為你的系統可靠性評分。
SPACE 框架提供了一種構建衡量體系的方法,它可以直接對事件管理產生影響。
不囿於數位,解決問題才是硬道理
衡量相關指標可以通過明確的資料來幫助團隊做出調整。如果沒有數位,可能會把一個實際發生很頻繁的事件當作一次性事件處理。
儘管數位發揮了作用,但它們只能告訴你問題所在,而無法解決它。因此,不要囿於數位,充分利用事件覆盤和 review 來研究如何優化企業中的事件管理。
數位並不能推動持續改進,但它可以消除討論中的偏見和邏輯謬誤,以幫助團隊處理好眼前的現實問題。
團隊應該形成在事件發生後立刻對其進行復盤,以防止迴歸到日常工作之後缺少了上下文環境而無法正確分析出事件發生的原因。
對於根本原因的分析要謹慎,因為軟體系統發生事故很少只有單一的原因,它通常是幾個因素共同促成的。根本原因分析側重於最接近事件的人,而不是更廣泛的系統性問題。另外,需要進行事件後的 review,詳細說明發生的一切以及您為減輕和解決它所做的工作。
事件覆盤的成果可以提供給處理未來事件的人使用,有助於縮短解決時間。
安全是吸取事故教訓的能力,而不是沒有故障,事故覆盤是最佳的學習機會。
—— Adrian Cockcroft
導致事故發生的原因從來不是單個員工,而是整個工作系統。如果有人登入伺服器,不小心選擇了「關閉」而不是「登出」導致伺服器關閉,這本質上是系統的故障——為什麼不隱藏「關閉」選項?為什麼他們需要直接存取伺服器?我們可以用 runbook 來做這個嗎?
定期 review 來複盤最近的事件,可以在冷靜理智的情況下找到模式並思考改進方式。從事件中學習比圍繞恢復時間制定目標更重要。
參考連結:
https://octopus.com/blog/how-to-measure-mean-time-to-resolve