kafka叢集是如何選擇leader,你知道嗎?
前言
kafka叢集是由多個broker節點組成,這裡麵包含了許多的知識點,以下的這些問題你都知道嗎?
- 你知道
topic的分割區leader是怎麼選舉的嗎? - 你知道
zookeeper中儲存了kafka的什麼資訊嗎?起到什麼做呢? - 你知道
kafka訊息檔案是怎麼儲存的嗎? - 如果
kafka中leader節點或者follower節點發生故障,訊息會丟失嗎?如何保證訊息的一致性和可靠性呢?
如果你對這些問題比較模糊的話,那麼很有必要看看本文,去了解以下kafka的核心設計,本文主要基於kafka3.x版本講解。
kafka broker核心機制
kafka叢集整體架構
kafka叢集是由多個kafka broker通過連同一個zookeeper組成,那麼他們是如何協同工作對外提供服務的呢?zookeeper中又儲存了什麼資訊呢?
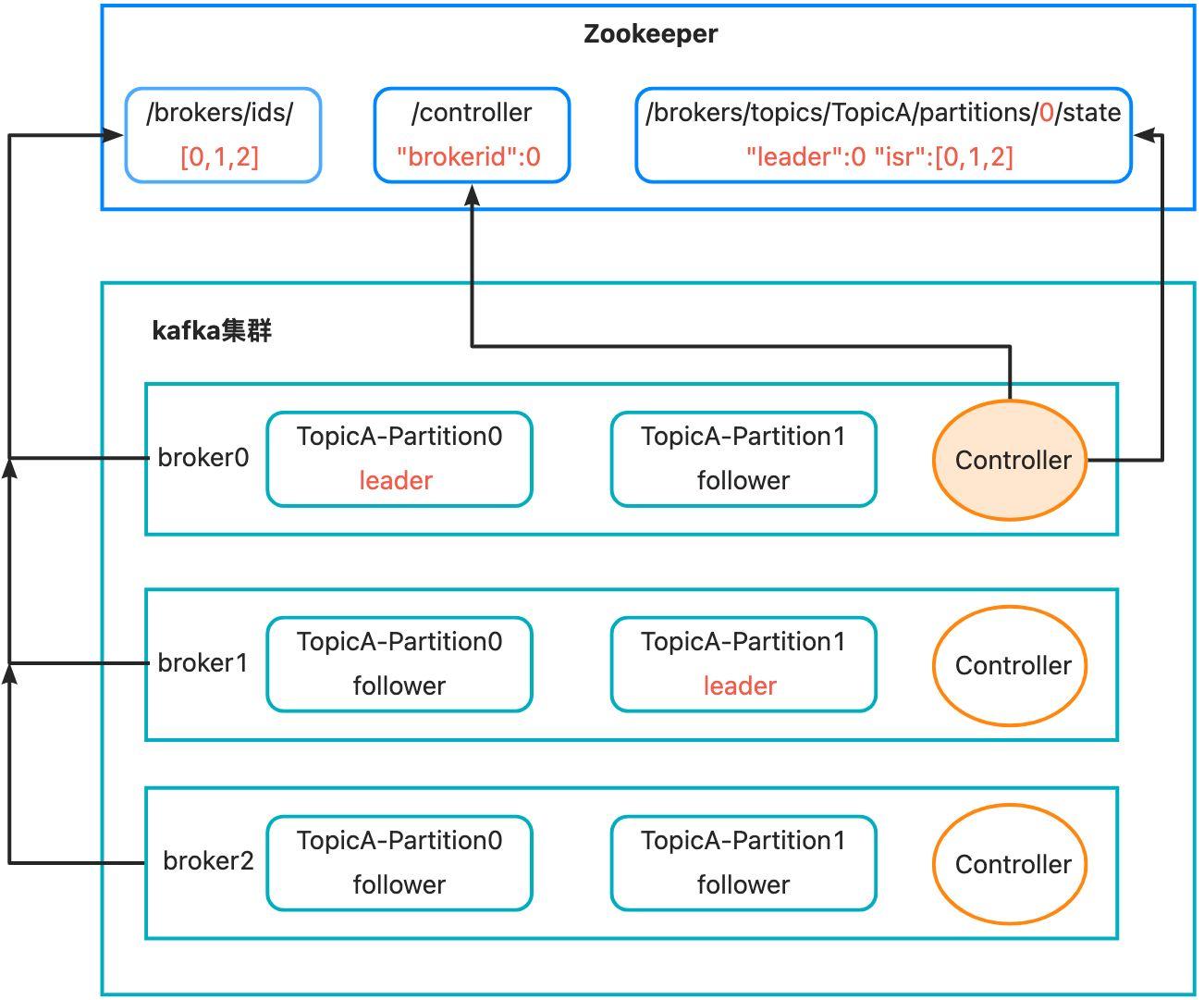
kafka broker啟動後,會在zookeeper的/brokers/ids路徑下注冊。- 同時,其中一個
broker會被選舉為控制器(Kafka Controller)。選舉規則也很簡單,誰先註冊到zookeeper中的/controller節點,誰就是控制器。Controller主要負責管理整個叢集中所有分割區和副本的狀態。 Kafka Controller會進行Leader選擇,比如上圖中針對TopicA中的0號分割區,選擇broker0作為Leader, 然後會將選擇的節點資訊註冊到zookeeper的/brokers/topics路徑下,記錄誰是Leader,有哪些伺服器可用。- 被選舉為
Leader的topic分割區提供對外的讀寫服務。為什麼只有Leader節點提供讀寫服務,而不是設計成主從方式,Follower提供讀服務呢?
- 為了保證資料的一致性,因為訊息同步延遲,可能導致消費者從不同節點讀取導致不一致。
- kafka設計目的是分散式紀錄檔系統,不是一個讀多寫少的場景,kafka的讀寫基本是對等的。
- 主從方式的話帶來設計上的複雜度。
kafka leader選舉機制
那麼問題來了,kafka中topic分割區是如何選擇leader的呢?為了更好的闡述,我們先來理解下面3個概念。
ISR:表示和Leader保持同步的Follower集合。如果Follower長時間未向Leader傳送通訊請求或同步資料,則該Follower將被踢出ISR。該時間閾值由replica.lag.time.max.ms引數設定,預設30s。Leader發生故障之後,就會從ISR中選舉新的Leader。OSR:表示Follower與Leader副本同步時,延遲過多的副本。AR: 指的是分割區中的所有副本,所以AR = ISR + OSR。
Kafka Controller選舉Leader的規則:在isr佇列中存活為前提,按照AR中排在前面的優先。例如ar[1,0,2], isr [1,0,2],那麼leader就會按照1,0,2的順序輪詢。而AR中的這個順序kafka會進行打散,分攤kafka broker的壓力。
當執行中的控制器突然宕機或意外終止時,Kafka 通過監聽zookeeper能夠快速地感知到,並立即啟用備用控制器來代替之前失敗的控制器。這個過程就被稱為 Failover,該過程是自動完成的,無需你手動干預。

開始的時候,Broker 0 是控制器。當 Broker 0 宕機後,ZooKeeper 通過`` Watch 機制感知到並刪除了 /controller 臨時節點。之後,所有存活的 Broker 開始競選新的控制器身份。Broker 3 最終贏得了選舉,成功地在 ZooKeeper 上重建了 /controller 節點。之後,Broker 3 會從 ZooKeeper 中讀取叢集後設資料資訊,並初始化到自己的快取中,後面就有Broker 3來接管選擇Leader的功能了。
Leader 和 Follower 故障處理機制
如果topic分割區的leader和follower發生了故障,那麼對於資料的一致性和可靠性會有什麼樣的影響呢?

LEO(Log End Offset):每個副本的最後一個offset,LEO就是最新的offset+ 1。HW(High Watermark):水位線,所有副本中最小的LEO,消費者只能看到這個水位線左邊的訊息,從而保證資料的一致性。
上圖所示,如果follower發生故障怎麼辦?
Follower發生故障後會被臨時踢出ISR佇列。- 這個期間
Leader和Follower繼續接收資料。 - 待該
Follower恢復後,Follower會讀取本地磁碟記錄的上次的HW,並將log檔案高於HW的部分擷取掉,從HW開始向Leader進行同步。 - 等該
Follower的LEO大於等於該Partition的HW,即Follower追上Leader之後,就可以重新加入ISR了。
如果leader發生故障怎麼辦?
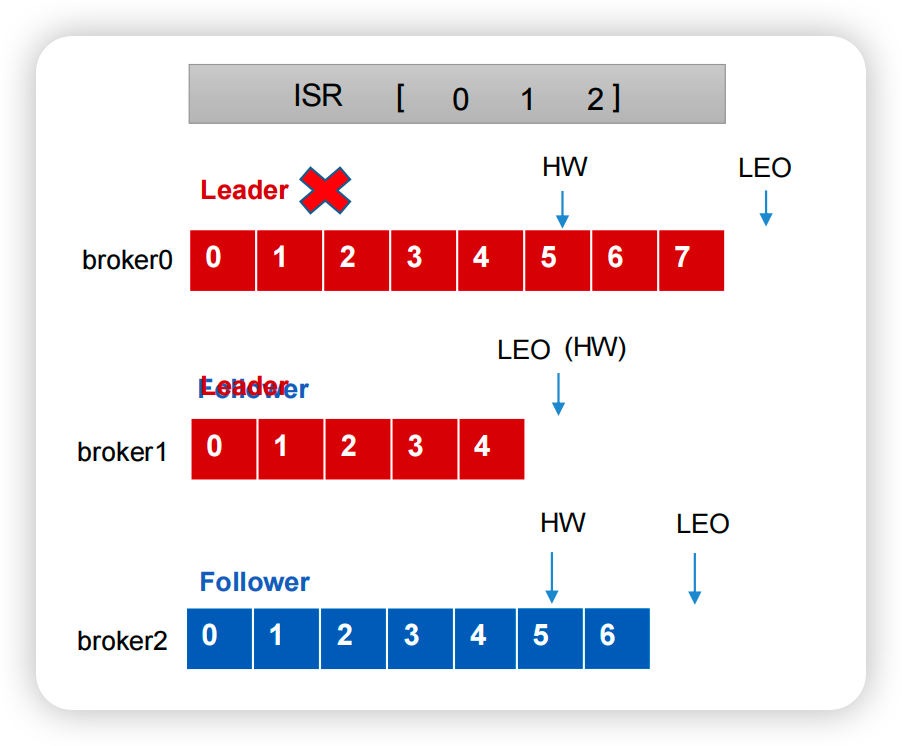
Leader發生故障之後,會從ISR中選出一個新的Leader- 為保證多個副本之間的資料一致性,其餘的
Follower會先將各自的log檔案高於HW的部分截掉,然後從新的Leader同步資料。
所以為了讓kafka broker保證訊息的可靠性和一致性,我們要做如下的設定:
- 設定 生產者
producer的設定acks=all或者-1。leader在返回確認或錯誤響應之前,會等待所有副本收到悄息,需要配合min.insync.replicas設定使用。這樣就意味著leader和follower的LEO對齊。 - 設定
topic的設定replication.factor>=3副本大於3個,並且min.insync.replicas>=2表示至少兩個副本應答。 - 設定
broker設定unclean.leader.election.enable=false,預設也是false,表示不對落後leader很多的follower也就是非ISR佇列中的副本選擇為Leader, 這樣可以避免資料丟失和資料 不一致,但是可用性會降低。
Leader Partition 負載平衡
正常情況下,Kafka本身會自動把Leader Partition均勻分散在各個機器上,來保證每臺機器的讀寫吞吐量都是均勻的。但是如果某些broker宕機,會導致Leader Partition過於集中在其他少部分幾臺broker上,這會導致少數幾臺broker的讀寫請求壓力過高,其他宕機的broker重啟之後都是follower partition,讀寫請求很低,造成叢集負載不均衡。那麼該如何負載平衡呢?
- 自動負載均衡
通過broker設定設定自動負載均衡。
auto.leader.rebalance.enable:預設是true。 自動Leader Partition平衡。生產環境中,leader重選舉的代價比較大,可能會帶來效能影響,建議設定為 false 關閉。leader.imbalance.per.broker.percentage:預設是10%。每個broker允許的不平衡的leader的比率。如果每個broker超過了這個值,控制器會觸發leader的平衡。leader.imbalance.check.interval.seconds:預設值300秒。檢查leader負載是否平衡的間隔時間。
- 手動負載均衡
- 對所有
topic進行負載均衡
./bin/kafka-preferred-replica-election.sh --zookeeper hadoop16:2181,hadoop17:2181,hadoop18:2181/kafka08
- 對指定
topic負載均衡
cat topicPartitionList.json
{
"partitions":
[
{"topic":"test.example","partition": "0"}
]
}
./bin/kafka-preferred-replica-election.sh --zookeeper hadoop16:2181,hadoop17:2181,hadoop18:2181/kafka08 --path-to-json-file topicPartitionList.json
kafka的儲存機制
kafka訊息最終會儲存到磁碟檔案中,那麼是如何儲存的呢?清理策略是什麼呢?
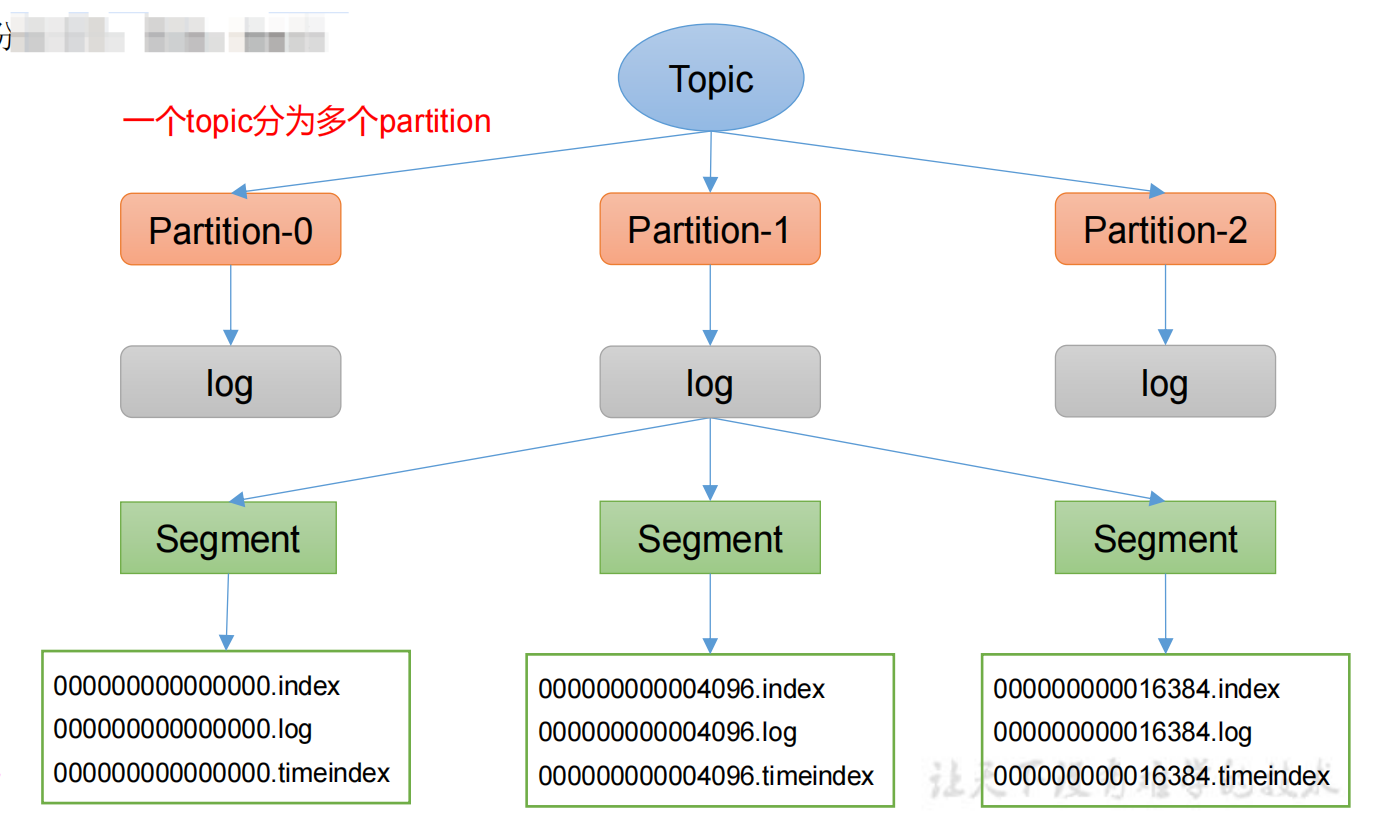
一個topic分為多個partition,每個partition對應於一個log檔案,為防止log檔案過大導致資料定位效率低下,Kafka採取了分片和索引機制,每個partition分為多個segment。每個segment包括:「.index」檔案、「.log」檔案和.timeindex等檔案,Producer生產的資料會被不斷追加到該log檔案末端。

上圖中t1即為一個topic的名稱,而「t1-0/t1-1」則表明這個目錄是t1這個topic的哪個partition。

kafka中的索引檔案以稀疏索引(sparseindex)的方式構造訊息的索引,如下圖所示:

1.根據目標offset定位segment檔案
2.找到小於等於目標offset的最大offset對應的索引項
3.定位到log檔案
4.向下遍歷找到目標Record
注意:index為稀疏索引,大約每往log檔案寫入4kb資料,會往index檔案寫入一條索引。通過引數log.index.interval.bytes控制,預設4kb。
那kafka中磁碟檔案儲存多久呢?
kafka 中預設的紀錄檔儲存時間為 7 天,可以通過調整如下引數修改儲存時間。
log.retention.hours,最低優先順序小時,預設 7 天。log.retention.minutes,分鐘。log.retention.ms,最高優先順序毫秒。log.retention.check.interval.ms,負責設定檢查週期,預設 5 分鐘。
kafka broker重要引數
前面講解了kafka broker中的核心機制,我們再來看下重要的設定引數。
首先來說下kafka伺服器端設定屬性Update Mode的作用:

read-only。被標記為read-only的引數和原來的引數行為一樣,只有重啟Broker,才能令修改生效。per-broker。被標記為 per-broker 的引數屬於動態引數,修改它之後,無需重啟就會在對應的broker上生效。cluster-wide。被標記為cluster-wide的引數也屬於動態引數,修改它之後,會在整個叢集範圍內生效,也就是說,對所有broker都生效。也可以為具體的broker修改cluster-wide引數。
Broker重要引數
| 引數名稱 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 長時間未向 Leader 傳送通訊請求或同步資料,則該 Follower 將被踢出 ISR。該時間閾值,預設 30s。 |
| auto.leader.rebalance.enable | 預設是 true。 自動 Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 預設是 10%。每個 broker 允許的不平衡的 leader的比率。如果每個 broker 超過了這個值,控制器會觸發 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 預設值 300 秒。檢查 leader 負載是否平衡的間隔時間。 |
| log.segment.bytes | Kafka 中 log 紀錄檔是分成一塊塊儲存的,此設定是指 log 紀錄檔劃分 成塊的大小,預設值 1G。 |
| log.index.interval.bytes | 預設 4kb,kafka 裡面每當寫入了 4kb 大小的紀錄檔(.log),然後就往 index 檔案裡面記錄一個索引。 |
| log.retention.hours | Kafka 中資料儲存的時間,預設 7 天。 |
| log.retention.minutes | Kafka 中資料儲存的時間,分鐘級別,預設關閉。 |
| log.retention.ms | Kafka 中資料儲存的時間,毫秒級別,預設關閉。 |
| log.retention.check.interval.ms | 檢查資料是否儲存超時的間隔,預設是 5 分鐘。 |
| log.retention.bytes | 預設等於-1,表示無窮大。超過設定的所有紀錄檔總大小,刪除最早的 segment。 |
| log.cleanup.policy | 預設是 delete,表示所有資料啟用刪除策略;如果設定值為 compact,表示所有資料啟用壓縮策略。 |
| num.io.threads | 預設是 8。負責寫磁碟的執行緒數。整個引數值要佔總核數的 50%。 |
| num.replica.fetchers | 副本拉取執行緒數,這個引數佔總核數的 50%的 1/3 |
| num.network.threads | 預設是 3。資料傳輸執行緒數,這個引數佔總核數的50%的 2/3 。 |
| log.flush.interval.messages | 強制頁快取刷寫到磁碟的條數,預設是 long 的最大值,9223372036854775807。一般不建議修改,交給系統自己管理。 |
| log.flush.interval.ms | 每隔多久,刷資料到磁碟,預設是 null。一般不建議修改,交給系統自己管理。 |
總結
Kafka叢集的分割區多副本架構是 Kafka 可靠性保證的核心,把訊息寫入多個副本可以使 Kafka 在發生崩潰時仍能保證訊息的永續性。本文圍繞這樣的核心架構講解了其中的一些核心機制,包括Leader的選舉、訊息的儲存機制等等。
歡迎關注個人公眾號【JAVA旭陽】交流學習
本文來自部落格園,作者:JAVA旭陽,轉載請註明原文連結:https://www.cnblogs.com/alvinscript/p/17442726.html