1.5萬字+30張圖盤點索引常見的11個知識點
大家好,我是三友~~
今天來盤點一下關於MySQL索引常見的知識點
本來這篇文章我前兩個星期就打算寫了,提綱都列好了,但是後面我去追《漫長的季節》這部劇去了,這就花了一個週末的時間,再加上後面一些其它的事,導致沒來得及寫
不過不要緊,好飯不怕晚,雖遲但到,走起,開幹!
對了,本文主要是針對InnoDB儲存引擎進行講解。
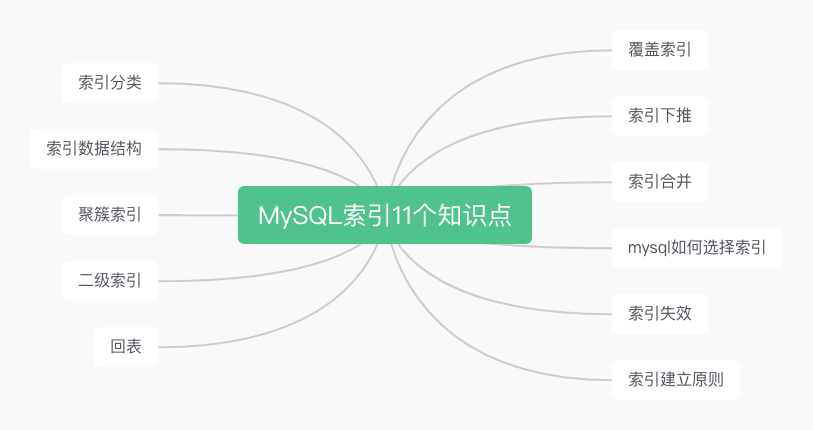
索引分類
索引的分類可以從不同的維度進行分類
1、按使用的資料結構劃分
B+樹索引 Hash索引 ...
2、按實際的物理儲存資料構劃分
聚簇索引 非聚簇索引(二級索引)
聚簇索引和非聚簇索引後面會著重說。
3、按索引特性劃分
主鍵索引 唯一索引 普通索引 全文索引 ...
4、按欄位個數劃分
單列索引 聯合索引
索引資料結構
準備
為了接下來文章更好地講解,這裡我準備了一張user表,接下來整篇文章的範例會以這張表來講解
CREATE TABLE `user` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(10) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Hash索引
Hash索引其實用的不多,最主要是因為最常見的儲存引擎InnoDB不支援顯示地建立Hash索引,只支援自適應Hash索引。
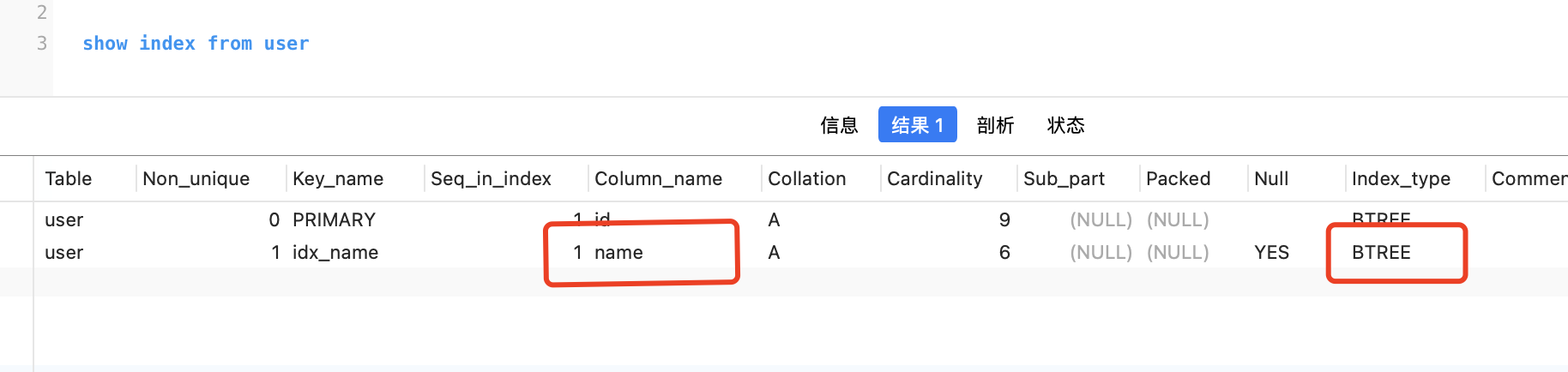
雖然可以使用sql語句在InnoDB顯示宣告Hash索引,但是其實是不生效的

對name欄位建立Hash索引,但是通過show index from 表名就會發現實際還是B+樹
在儲存引擎中,Memory引擎支援Hash索引
Hash索引其實有點像Java中的HashMap底層的資料結構,他也有很多的槽,存的也是鍵值對,鍵值為索引列,值為資料的這條資料的行指標,通過行指標就可以找到資料
假設現在user表用Memory儲存引擎,對name欄位建立Hash索引,表中插入三條資料
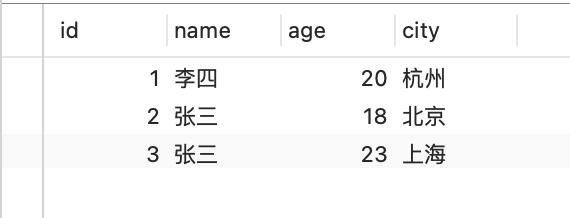
Hash索引會對索引列name的值進行Hash計算,然後找到對應的槽下面,如下圖所示
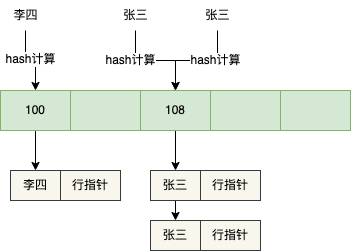
當遇到name欄位的Hash值相同時,也就是Hash衝突,就會形成一個連結串列,比如有name=張三有兩條資料,就會形成一個連結串列。
之後如果要查name=李四的資料,只需要對李四進行Hash計算,找到對應的槽,遍歷連結串列,取出name=李四對應的行指標,然後根據行指標去查詢對應的資料。
Hash索引優缺點
hash索引只能用於等值比較,所以查詢效率非常高 不支援範圍查詢,也不支援排序,因為索引列的分佈是無序的
B+樹
B+樹是mysql索引中用的最多的資料結構,這裡先不介紹,下一節會著重介紹。
除了Hash和B+樹之外,還有全文索引等其它索引,這裡就不討論了
聚簇索引
資料頁資料儲存
我們知道,我們插入表的資料其實最終都要持久化到磁碟上,InnoDB為了方便管理這些資料,提出了頁的概念,它會將資料劃分到多個頁中,每個頁大小預設是16KB,這個頁我們可以稱為資料頁。
當我們插入一條資料的時候,資料都會存在資料頁中,如下圖所示
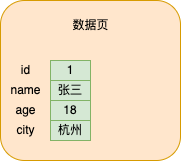
當資料不斷地插入資料頁中,資料會根據主鍵(沒有的話會自動生成)的大小進行排序,形成一個單向連結串列
資料頁中除了會儲存我們插入的資料之外,還會有一部分空間用來儲存額外的資訊,額外的資訊型別比較多,後面遇到一個說一個
單個資料頁的資料查詢
既然資料會存在資料頁中,那麼該如何從資料頁中去查資料呢?
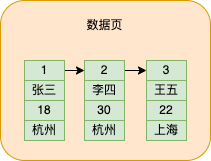
假設現在需要在資料頁中定位到id=2的這條記錄的資料,如何快速定位?
有一種笨辦法就是從頭開始順著連結串列遍歷就行了,判斷id是不是等於2,如果等於2就取出資料就行了。
雖然這種方法可行,但是如果一個資料頁儲存的資料多,幾十或者是幾百條資料,每次都這麼遍歷,不是太麻煩了
所以mysql想了一個好辦法,那就是給這些資料分組
假設資料頁中存了12條資料,那麼整個分組大致如下圖所示
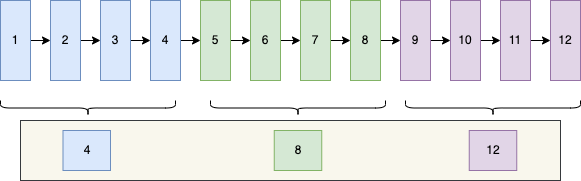
為了方便了,我這裡只標出了id值,省略了其它欄位的值
這裡我假設每4條資料算一個組,圖上就有3個組,組分好之後,mysql會取出每組中最大的id值,就是圖中的4、8、12,放在一起,在資料頁中找個位置存起來,這就是前面提到的資料頁儲存的額外資訊之一,被稱為頁目錄
假設此時要查詢id=6的資料之後,此時只需要從頁目錄中根據二分查詢,發現在4-8之間,由於4和8是他們所在分組的最大的id,那麼id=6肯定在8那個分組中,之後就會到id=8的那個分組中,遍歷每個資料,判斷id是不是等於6即可。
由於mysql規定每個組的資料條數大概為4~8條,所以肯定比遍歷整個資料頁的資料快的多
上面分組的情況實際上我做了一點簡化,但是不耽誤理解
多個資料頁中的資料查詢
當我們不斷的往表中插入資料的時候,資料佔用空間就會不斷變大,但是一個資料頁的大小是一定的,當一個資料頁存不下資料的時候,就會重新建立一個資料頁來儲存資料
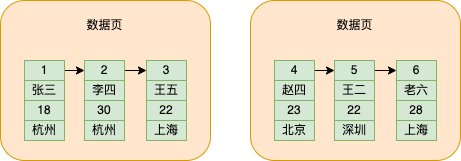
mysql為了區分每個頁,會為每個資料頁分配一個頁號,存在額外資訊的儲存空間中,同時額外資訊還會儲存當前資料頁的前一個和後一個資料頁的位置,從而形成資料頁之間的雙向連結串列
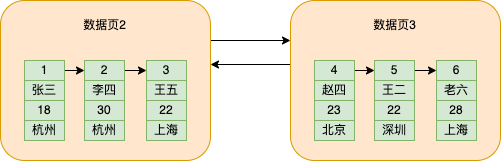
資料頁2的頁號就是2,資料頁3的頁號就是3,這裡我為了方便理解,就直接寫資料頁幾。
並且mysql規定,前一個資料頁的儲存資料id的最大值要小於後一個資料頁的儲存資料id的最小值,這樣就實現了資料在所有資料頁中按照id的大小排序。
現在,如果有多個資料頁,當我們需要查詢id=5的資料,怎麼辦呢?
當然還是可以用上面的笨辦法,那就是從第一個資料頁開始遍歷,然後遍歷每個資料頁中的資料,最終也可以找到id=5的資料。
但是你仔細想想,這個笨辦法就相當於全表掃描了呀,這肯定是不行的。
那麼怎麼優化呢?
mysql優化的思路其實跟前面單資料頁查詢資料的優化思路差不多
它會將每個資料頁中最小的id拿出來,單獨放到另一個資料頁中,這個資料頁不儲存我們實際插入的資料,只儲存最小的id和這個id所在資料頁的頁號,如圖所示
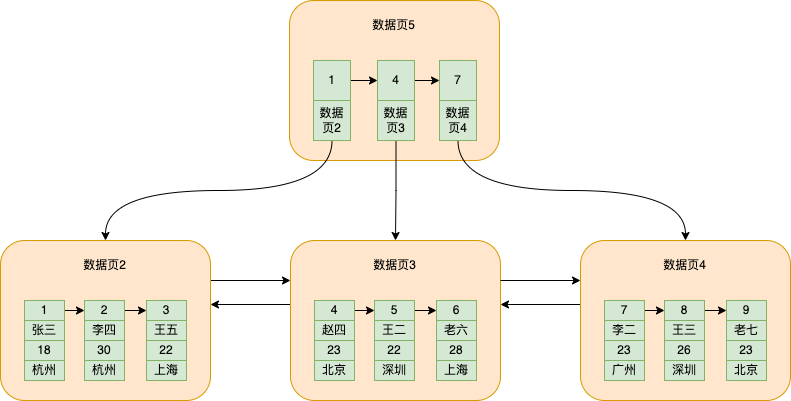
為了圖更加飽滿,我加了一個存放資料的資料頁4
此時資料頁5就是抽取出來的,存放了下面三個存放資料的資料頁的最小的id和對應的資料頁號
如果此時查詢id=5的資料就很方便了,大致分為以下幾個步驟:
從資料頁5直接根據二分查詢,發現在4-7之間 由於4和7是所在資料頁最小的id,那麼此時id=5的資料必在id=4的資料頁上(因為id=7的資料頁最小的id就是7), 接下來就到id=4對應的資料頁2的頁號找到資料頁2 之後再根據前面提到的根據資料的主鍵id從單個資料頁查詢的流程查詢資料
這樣就實現了根據主鍵id到在多個資料頁之間查詢資料
聚簇索引
隨著資料量不斷增多,儲存資料的資料頁不斷變多,資料頁5的資料就會越來越多,但是每個資料頁預設就16k,所以資料頁5也會分裂出多個資料頁的情況,如下圖
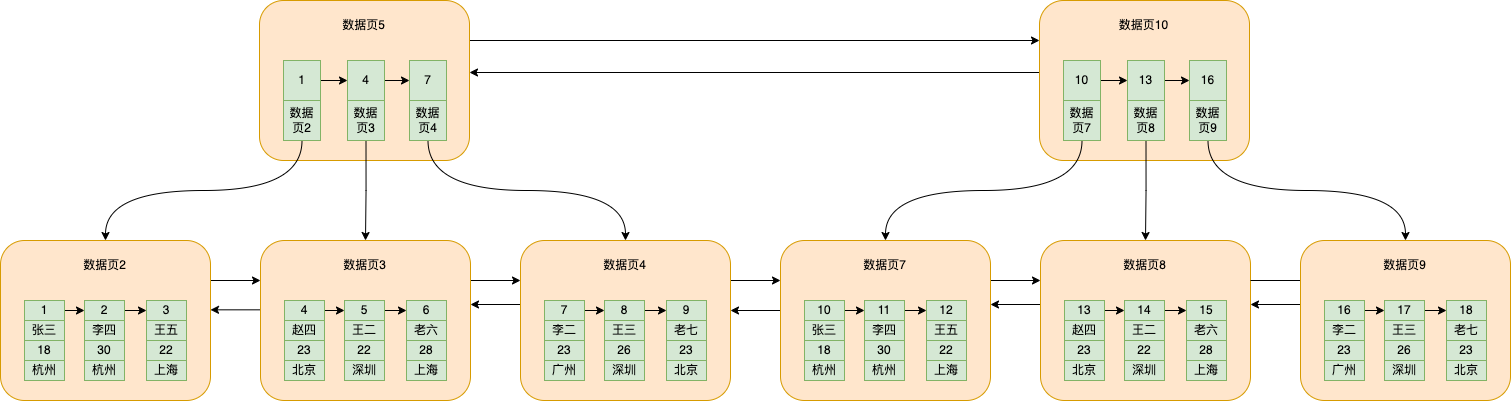
資料頁10的作用就跟資料頁5是一樣的
此時如還要查詢id=5的資料,那麼應該去資料頁5進行二分查詢呢還是去資料頁10進行二分查詢呢?
笨辦法就是遍歷,但是真沒必要,mysql會去抽取資料頁5和資料頁10儲存的最小的資料的id和對應的資料頁號,單獨拎出來放到一個資料頁中,如下圖
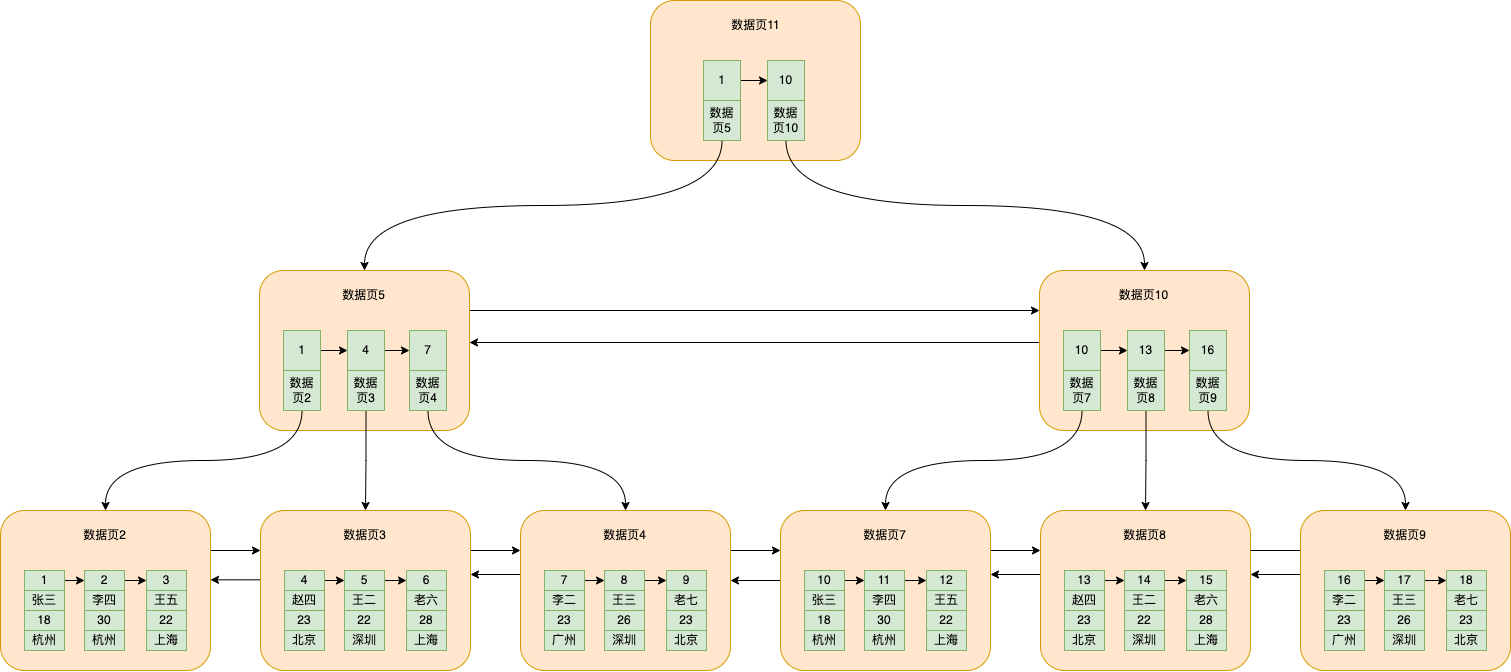
資料頁11就是新抽取的資料頁,儲存了id=1和對應的資料頁5的頁號以及數id=10和對應的資料頁10的頁號
而這就是B+樹。
一般來說,mysql資料庫的B+樹一般三層就可以放下幾千萬條資料
此時查詢id=5的資料,大致分為以下幾個步驟:
從資料頁11根據二分查詢定位到id=5對應資料頁5 再到資料頁5根據id=5二分查詢定位到資料頁3 再到資料頁3根據id=5查詢資料,具體的邏輯前面也提到很多次了
這樣就能成功查詢到資料了
而這種葉子節點儲存實際插入的資料的B+樹就被稱為聚簇索引,非葉子節點儲存的就是記錄的id和對應的資料頁號。
所以對於InnoDB儲存引擎來說,資料本身就儲存在一顆B+樹中。
二級索引
二級索引也被稱為非聚簇索引,本身也就是一顆B+樹,一個二級索引對應一顆B+樹,但是二級索引B+樹儲存的資料跟聚簇索引不一樣。
聚簇索引前面也說了,葉子節點存的就是我們插入到資料庫的資料,非葉子節點存的就是資料的主鍵id和對應的資料頁號。
而二級索引葉子節點存的是索引列的資料和對應的主鍵id,非葉子節點除了索引列的資料和id之外,還會存資料頁的頁號。
前面提到的資料頁,其實真正是叫索引頁,因為葉子節點存的是實際表的資料,所以我就叫資料頁了,接下來因為真正要講到索引了,所以我就將二級索引的頁稱為索引頁,你知道是同一個,但是儲存的資料不一樣就可以了。
單列索引
假設,我們現在對name欄位加了一個普通非唯一索引,那麼name就是索引列,同時name這個索引也就是單列索引
此時如果往表中插入三條資料,那麼name索引的葉子節點存的資料就如下圖所示
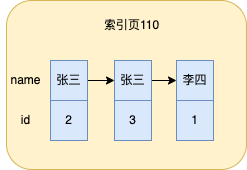
mysql會根據name欄位的值進行排序,這裡我假設張三排在李四前面,當索引列的值相同時,就會根據id排序,所以索引實際上已經根據索引列的值排好序了。
這裡肯定有小夥伴疑問,name欄位儲存的中文也可以排序麼?
答案是可以的,並且mysql支援很多種排序規則,我們在建資料庫或者是建表的時候等都可以指定排序規則,並且後面文章涉及到的字串排序都是我隨便排的,實際情況可能不一樣。
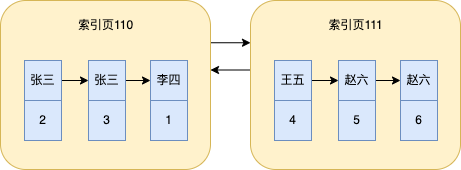
對於單個索引列資料查詢也是跟前面說的聚簇索引一樣,也會對資料分組,之後可以根據二分查詢在單個索引列來查詢資料。
當資料不斷增多,一個索引頁儲存不下資料的時候,也會用多個索引頁來儲存,並且索引頁直接也會形成雙向連結串列
當索引頁不斷增多是,為了方便在不同索引頁中查詢資料,也就會抽取一個索引頁,除了存頁中id,同時也會儲存這個id對應的索引列的值
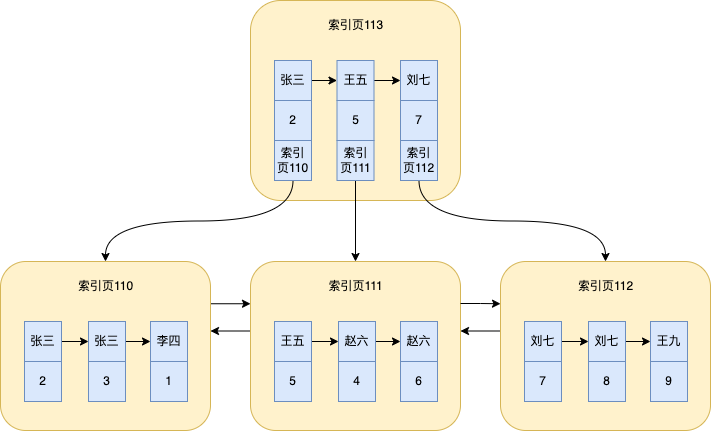
當資料越來越多越來越多,還會抽取,也會形成三層的一個B+樹,這裡我就不畫了。
聯合索引
除了單列索引,聯合索引其實也是一樣的,只不過索引頁存的資料就多了一些索引列
比如,在name和age上建立一個聯合索引,此時單個索引頁就如圖所示
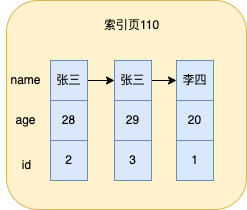
先以name排序,name相同時再以age排序,如果再有其它列,依次類推,最後再以id排序。
相比於只有name一個欄位的索引來說,索引頁就多存了一個索引列。
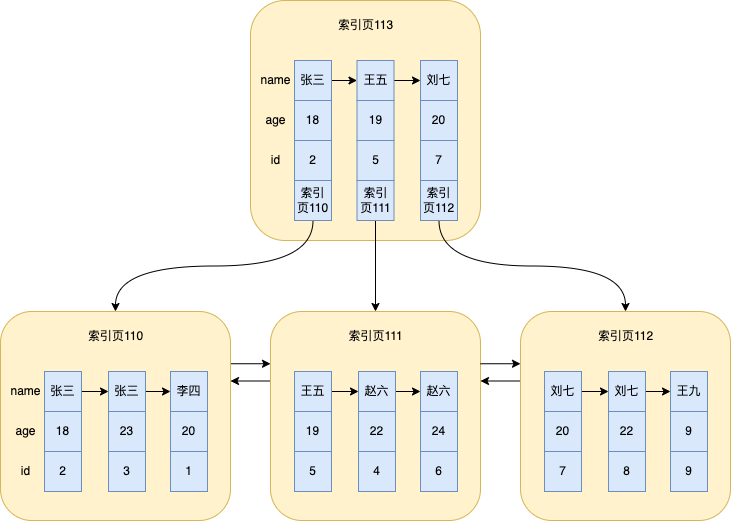
最後形成的B+樹簡化為如下圖
小結
其實從上面的分析可以看出,聚簇索引和非聚簇索引主要區別有以下幾點
聚簇索引的葉子節點存的是所有列的值,非聚簇索引的葉子節點只存了索引列的值和主鍵id 聚簇索引的資料是按照id排序,非聚簇索引的資料是按照索引列排序 聚簇索引的非葉子節點存的是主鍵id和頁號,非聚簇索引的非葉子節點存的是索引列、主鍵id、頁號
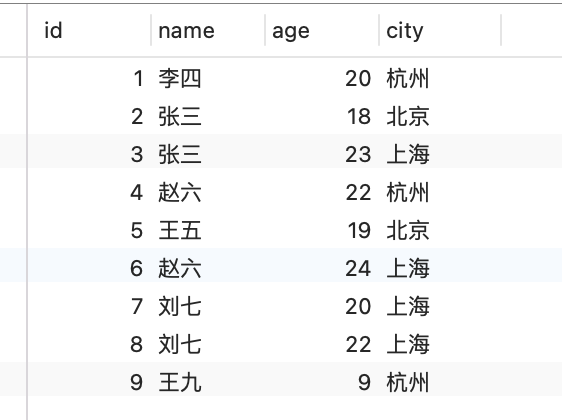
由於後面這個索引樹會經常用到,為了你方便比較,所以我根據上面索引樹的資料在表中插入了對應的資料,sql在文末
實際情況下索引B+樹可能並不是按照我圖中畫出來的那樣排序,但不耽誤理解。
回表
講完二級索引,接下來講一講如何使用二級索引查詢資料。
這裡假設對name欄位建立了一個索引,並且表裡就存了上面範例中的幾條資料,這裡我再把圖拿過來
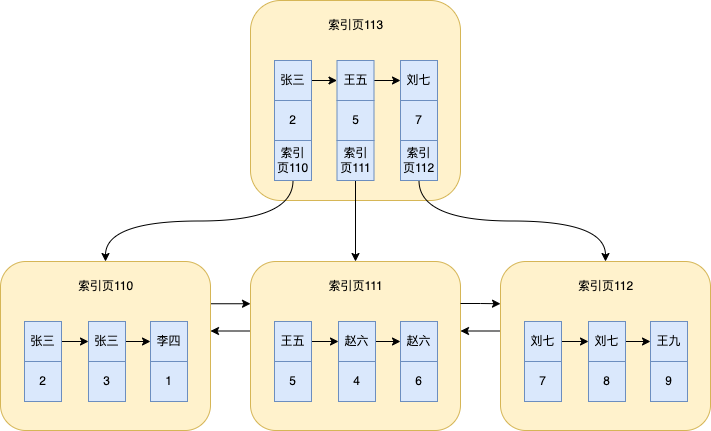
那麼對於下面這條sql應該如何執行?
select * from `user` where name = '趙六';
由於查詢條件是name = '趙六',所以會走name索引
整個過程大致分為以下幾個步驟:
從最上面那層索引頁開始二分查詢,我們圖中就是索引頁113,如果索引頁113上面還有一層,就從上面一層二分查詢 在索引頁113查詢到 趙六在王五和劉七之間,之後到王五對應的索引頁111上去查詢趙六在索引頁111找到 趙六的第一條記錄,也就是id=4的那條由於是 select *,還要查其它欄位,此時就會根據id=4到聚簇索引中查詢其它欄位資料,這個查詢過程前面說了很多次了,這個根據id=4到聚簇索引中查詢資料的過程就被稱為回表由於是非唯一索引,所以 趙六這個值可能會有重複,所以接著就會在索引頁111順著連結串列繼續遍歷,如果name還是趙六,那麼還會根據id值進行回表,如此重複,一直這麼遍歷,直至name不再等於趙六為止,對於圖示,其實就是兩條資料
從上面的二級索引的查詢資料過程分析,就明白了回表的意思,就是先從二級索引根據查詢條件欄位值查詢對應的主鍵id,之後根據id再到聚簇索引查詢其它欄位的值。
覆蓋索引
上一節說當執行select * from user where name = '趙六';這條sql的時候,會先從索引頁中查出來name = '趙六';對應的主鍵id,之後再回表,到聚簇索引中查詢其它欄位的值。
那麼當執行下面這條sql,又會怎樣呢?
select id from `user` where name = '趙六';
這次查詢欄位從select *變成select id,查詢條件不變,所以也會走name索引
所以還是跟前面一樣了,先從索引頁中查出來name = '趙六';對應的主鍵id之後,驚訝的發現,sql中需要查詢欄位的id值已經查到了,那次此時壓根就不需要回表了,已經查到id了,還回什麼表。
而這種需要查詢的欄位都在索引列中的情況就被稱為覆蓋索引,索引列覆蓋了查詢欄位的意思。
當使用覆蓋索引時會減少回表的次數,這樣查詢速度更快,效能更高。
所以,在日常開發中,儘量不要select * ,需要什麼查什麼,如果出現覆蓋索引的情況,查詢會快很多。
索引下推
假設現在對錶建立了一個name和age的聯合索引,為了方便理解,我把前面的圖再拿過來
接下來要執行如下的sql
select * from `user` where name > '王五' and age > 22;
在MySQL5.6(不包括5.6)之前,整個sql大致執行步驟如下:
先根據二分查詢,定位到 name > '王五'的第一條資料,也就是id=4的那個趙六之後就會根據id=4進行回表操作,到聚簇索引中查詢id=4其它欄位的資料,然後判斷資料中的age是否大於22,是的話就說明是我們需要查詢的資料,否則就不是 之後順著連結串列,繼續遍歷,然後找到一條記錄就回一次表,然後判斷age,如此反覆下去,直至結束
所以對於圖上所示,整個搜尋過程會經歷5次回表操作,兩個趙六,兩個劉七,一個王九,最後符合條件的也就是id=6的趙六那條資料,其餘age不符和。
雖然這麼執行沒什麼問題,但是不知有沒有發現其實沒必要進行那麼多次回表,因為光從上面的索引圖示就可以看出,符合name > '王五' and age > 22的資料就id=6的趙六那條資料
所以在MySQL5.6之後,對上面的age > 22判斷邏輯進行了優化
前面還是一樣,定位查詢到id=4的那個趙六,之後就不回表來判斷age了,因為索引列有age的值了,那麼直接根據索引中age判斷是否大於22,如果大於的話,再回表查詢剩餘的欄位資料(因為是select *),然後再順序連結串列遍歷,直至結束
所以這樣優化之後,回表次數就成1了,相比於前面的5次,大大減少了回表的次數。
而這個優化,就被稱為索引下推,就是為了減少回表的次數。
之所以這個優化叫索引下推,其實是跟判斷
age > 22邏輯執行的地方有關,這裡就不過多贅述了。
索引合併
索引合併(index merge)是從MySQL5.1開始引入的索引優化機制,在之前的MySQL版本中,一條sql多個查詢條件只能使用一個索引,但是引入了索引合併機制之後,MySQL在某些特殊的情況下會掃描多個索引,然後將掃描結果進行合併
結果合併會為下面三種情況:
取交集(intersect) 取並集(union) 排序後取並集(sort-union)
為了不耽誤演示,刪除之前所有的索引,然後為name和age各自分別建立一個二級索引idx_name和idx_age
取交集(intersect)
當執行下面這條sql就會出現取交集的情況
select * from `user` where name = '趙六' and age= 22;
檢視執行計劃
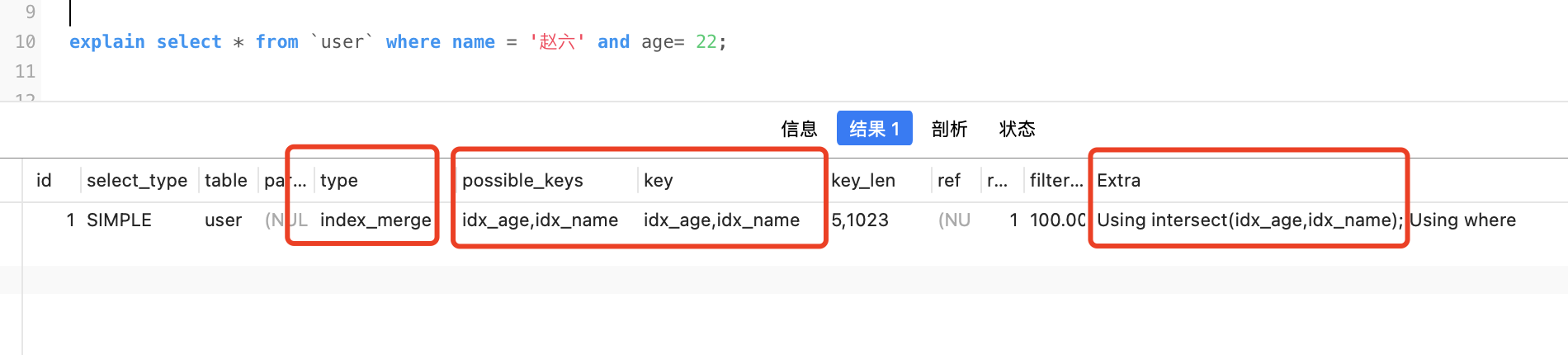
type是index_merge,並且possible_key和key都是idx_name和idx_age,說明使用了索引合併,並且Extra有Using intersect(idx_age,idx_name),intersect就是交集的意思。
整個過程大致是這樣的,分別根據idx_name和idx_age取出對應的主鍵id,之後將主鍵id取交集,那麼這部分交集的id一定同時滿足查詢name = '趙六' and age= 22的查詢條件(仔細想想),之後再根據交集的id回表
不過要想使用取交集的聯合索引,需要滿足各自索引查出來的主鍵id是排好序的,這是為了方便可以快速的取交集
比如下面這條sql就無法使用聯合索引
select * from `user` where name = '趙六' and age > 22;
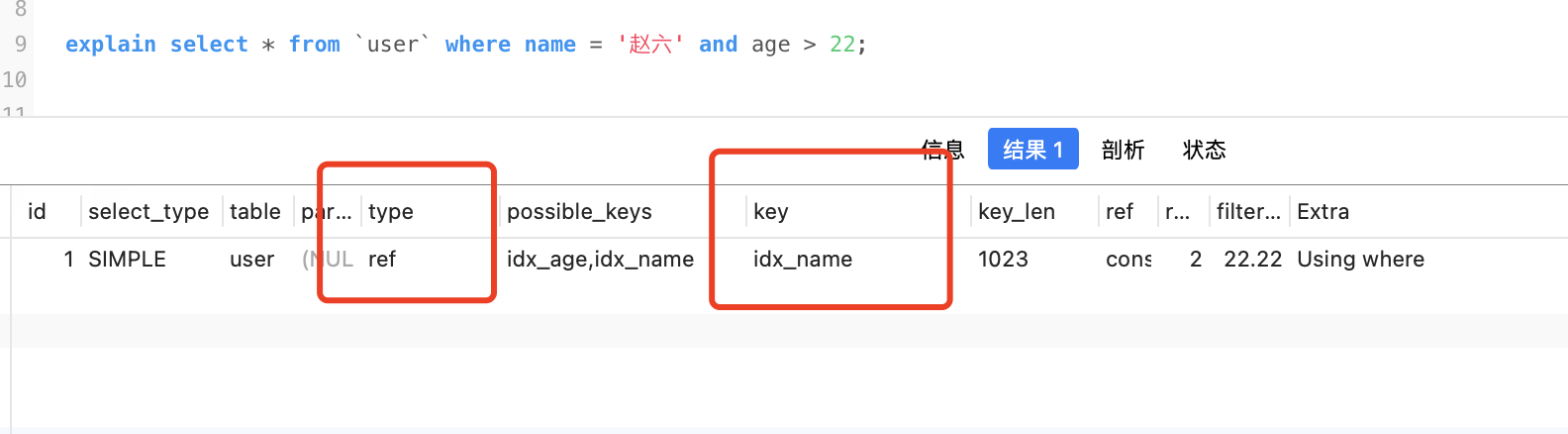
只能用name這個索引,因為age > 22查出來的id是無序的,前面在講索引的時候有說過索引列的排序規則
由此可以看出,使用聯合索引條件還是比較苛刻的。
取並集(union)
取並集就是將前面例子中的and換成or
select * from `user` where name = '趙六' or age = 22;
前面執行的情況都一樣,根據條件到各自的索引上去查,之後對查詢的id取並集去重,之後再回表
同樣地,取並集也要求各自索引查出來的主鍵id是排好序的,如果查詢條件換成age > 22時就無法使用取並集的索引合併
select * from `user` where name = '趙六' or age > 22;
排序後取並集(sort-union)
雖然取並集要求各自索引查出來的主鍵id是排好序的,但是如果遇到沒排好序的情況,mysql會自動對這種情況進行優化,會先對主鍵id排序,然後再取並集,這種情況就叫 排序後取並集(sort-union)。
比如上面提到的無法直接取並集的sql就符合排序後取並集(sort-union)這種情況
select * from `user` where name = '趙六' or age > 22;
mysql如何選擇索引
在日常生產中,一個表可能會存在多個索引,那麼mysql在執行sql的時候是如何去判斷該走哪個索引,或者是全表掃描呢?
mysql在選擇索引的時候會根據索引的使用成本來判斷
一條sql執行的成本大致分為兩塊
IO成本,因為這些頁都是在磁碟的,要想去判斷首先得載入到記憶體,MySQL規定載入一個頁的成本為1.0
CPU成本,除了IO成本之外,還有條件判斷的成本,也就是CPU成本。比如前面舉的例子,你得判斷載入的資料
name = '趙六'符不符合條件,MySQL規定每判斷一條資料花費的成本為0.2
全表掃描成本計算
對於全表掃描來說,成本計算大致如下
mysql會對錶進行資料統計,這個統計是大概,不是特別準,通過show table status like '表名'可以檢視統計資料
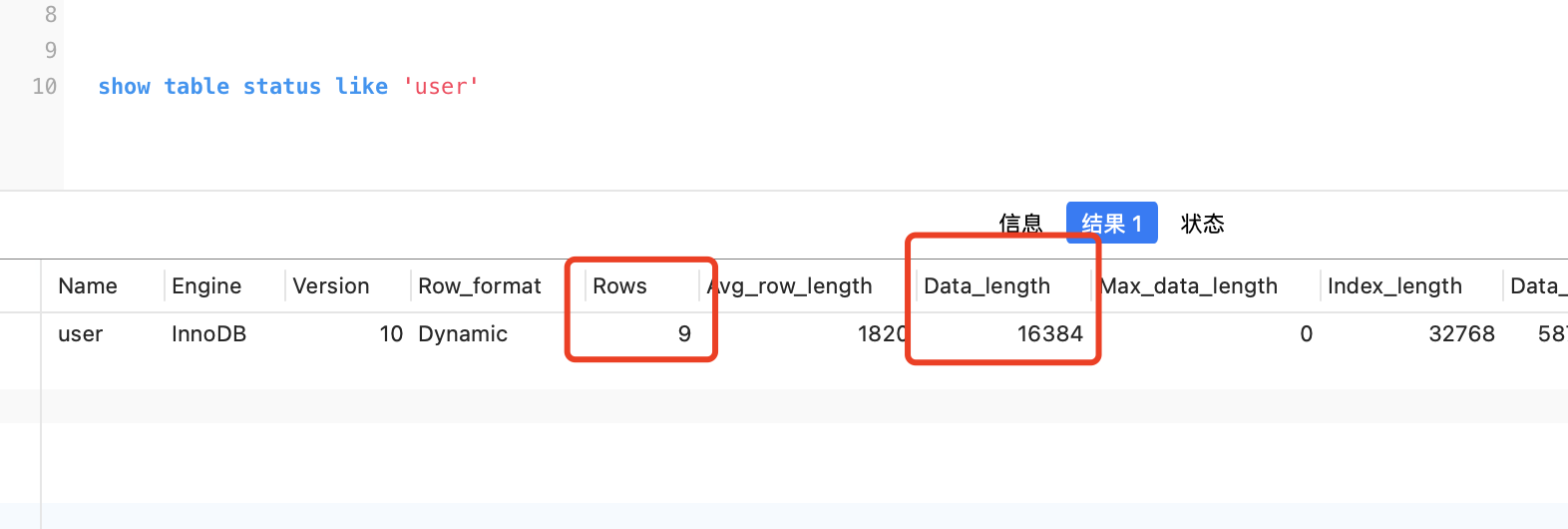
比如這個表大致有多少條資料rows,以及聚簇索引所佔的位元組數data_length,由於預設是16kb,所以就可以計算出(data_length/1024/16)大概有多少個資料頁。
所以全表掃描的成本就這麼計算了
rows * 0.2 + data_length/1024/16 * 1.0
二級索引+回表成本計算
二級索引+回表成本計算比較複雜,他的成本資料依賴兩部分掃描區間個數和回表次數
為了方便描述掃描區間,這裡我再把上面的圖拿上來
select * from `user` where name = '趙六';
對著圖看!
查詢條件name = '趙六'就會產生一個掃描區間,從id=4的趙六掃描到id=6的趙六
又比如假設查詢條件為name > '趙六',此時就會產生一個從id=7的劉七開始直到資料結束(id=9的王九)的掃描區間
又比如假設查詢條件為name < '李四' and name > '趙六',此時就會產生兩個掃描區間,從id=2的張三到id=3的張三算一個,從id=7的劉七開始直到資料結束算另一個
所以掃描區間的意思就是符合查詢條件的記錄區間
二級索引計算成本的時候,mysq規定讀取一個區間的成本跟讀取一個頁的IO成本是一樣的,都是1.0
區間有了之後,就會根據統計資料估計在這些區間大致有多少條資料,因為要讀寫這些資料,那麼讀取成本大致就是 條數 * 0.2
所以走二級索引的成本就是 區間個數 * 1.0 + 條數 * 0.2
之後這些資料需要回表(如果需要的話),mysql規定每次回表也跟讀取一個頁的IO成本是一樣,也是1.0
回表的時候需要對從聚簇索引查出來的資料進行剩餘查詢條件的判斷,就是CPU成本,大致為 條數 * 0.2
所以回表的成本大致為 條數 * 1.0 + 條數 * 0.2
所以二級索引+回表的大致成本為 區間個數 * 1.0 + 條數 * 0.2 + 條數 * 1.0 + 條數 * 0.2
當索引的成本和全表掃描的成本都計算完成之後,mysql會選擇成本最低的索引來執行
mysql對上述成本計算結果還會微調,但是微調的值特別小,所以這裡我就省略了,並且這裡也只是大致介紹了成本計算的規則,實際情況會更復雜,比如連表查詢等等,有感興趣的小夥伴查閱相關的資料
小結
總的來說,這一節主要是讓你明白一件事,mysql在選擇索引的時候,會根據統計資料和成本計算的規則來計算使用每個索引的成本,然後選擇使用最低成本的索引來執行查詢
索引失效
在日常開發中,肯定或多或少都遇到過索引失效的問題,這裡我總結一下幾種常見的索引失效的場景
為了方便解釋,這裡我再把圖拿過來
不符和最左字首匹配原則
當不符和最左字首匹配原則的時候會導致索引失效
比如like以%開頭,索引失效或者是聯合索引沒走第一個索引列。
比如name和age的聯合索引,當執行select * from user where name > '王五' and age > 22;時,那麼如果要走索引的話,此時就需要掃描整個索引,因為索引列是先以name欄位排序,再以age欄位排序的,對於age來說,在整個索引中來說是無序的,從圖中也可以看出 18、23...9,無序,所以無法根據二分查詢定位到age > 22是從哪個索引頁開始的,
所以走索引的話要掃描整個索引,一個一個判斷,最後還要回表,這就很耗效能,不如直接掃描聚簇索引,也就是全表掃描來的痛快。
索引列進行了計算
當對索引進行表示式計算或者使用函數時也會導致索引失效
這個主要是因為索引中儲存的是索引欄位是原始值,從上面畫的圖可以看出來,當經過函數計算後的值,也就沒辦法走索引了
隱式轉換
當索引列發生了隱式轉換可能會導致索引失效
舉個例子,mysql規定,當字串跟數位比較時,會把字串先轉成數位再比較,至於字串怎麼轉成數位,mysql有自己的規則
比如說,當我執行了下面這條sql時就會發生隱式轉換
select * from `user` where name = 9527;
name欄位是個varchar型別,9527,沒加引號,是數位,mysql根據規則會把name欄位的值先轉換成數位,再與9527比較,此時由於name欄位發生了轉換,所以索引失效了
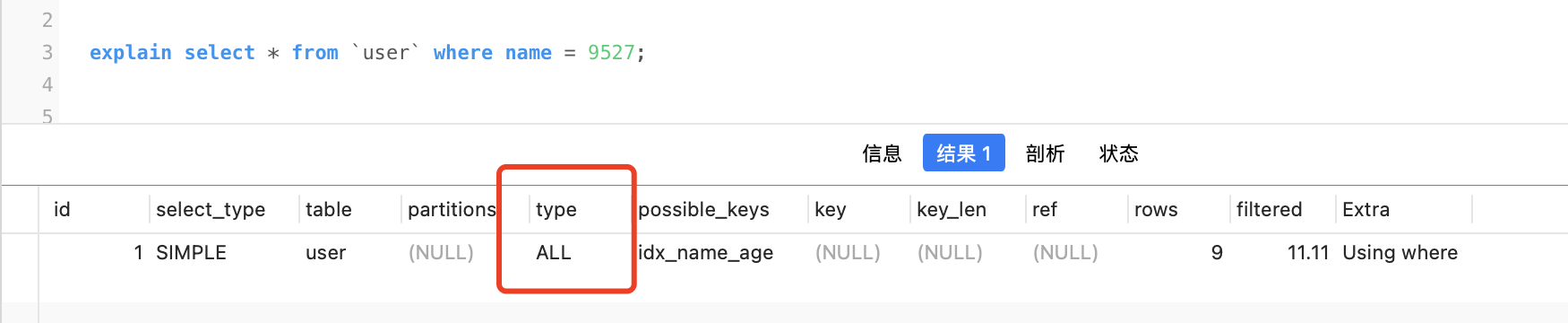
ALL說明沒走索引,失效了。
但是假設現在對age建立一個索引,執行下面這條sql
select * from `user` where age = '22';
此時age索引就不會失效,主要是因為前面說的那句話:
當字串跟數位比較時,會把字串先轉成數位再比較
於是'22'會被隱式轉成數位,之後再跟age比較,此時age欄位並沒有發生隱式轉換,所以不會失效。
所以說,隱式轉換可能會導致索引失效。
mysql統計資料誤差較大
mysql統計資料誤差較大也可能會導致索引失效,因為前面也說了,mysql會根據統計資料來計算使用索引的成本,這樣一旦統計資料誤差較大,那麼計算出來的成本誤差就大,就可能出現實際走索引的成本小但是計算出來的是走索引的成本大,導致索引失效
當出現這種情況時,可以執行analyze table 表名這條sql,mysql就會重新統計這些資料,索引就可以重新生效了
索引建立原則
單個表索引數量不宜過多
從上面分析我們知道,每個索引都對應一顆B+樹,並且葉子節點儲存了索引列全量的資料,一旦索引數量多,那麼就會佔有大量磁碟空間 同時前面也提到,在查詢之前會對索引成本進行計算,一旦索引多,計算的次數就多,也可能會浪費效能
經常出現在where後的欄位應該建立索引
這個就不用說了,索引就是為了加快速度,如果沒有合適索引,就會全表掃描,對於InnoDB來說,全表掃描就是從聚簇索引的第一個葉子節點開始,順著連結串列一個一個判斷資料服不服合查詢條件
order by、group by後欄位可建立索引
比如下面這條sql
select * from `user` where name = '趙六' order by age asc;
查詢name = '趙六'並且根據age排序,name和age聯合索引
你可能記不清索樹了,我把那個索引樹拿過來
此時對著索引樹你可以發現,當name = '趙六'時,age已經排好序了(前面介紹索引的說了排序規則),所以就可以使用age索引列進行排序。
頻繁更新的欄位不宜建索引
因為索引需要保證按照索引列的值進行排序,所以一旦索引欄位資料頻繁更新,那麼為了保證索引的順序,就得頻繁挪動索引列在索引頁中的位置
比如name和age聯合索引
此時把id=9這條資料的name從王九改成趙六,那麼此時就把這條更改後的資料在索引頁上移到王五和id=4的趙六之間,因為name相同時,得保證順序性,同時要按照age排序,id=9的age為9,最小,那麼排在最前。
所以頻繁更新的欄位建索引就會增加維護索引的成本。
選擇區分度高的欄位做索引
這個是因為,如果區分度低,那麼索引效果不好。
舉個例子,假設現在有個性別欄位sex,非男即女,如果對sex建索引,假設男排在女之前,那麼索引頁的資料排列大致如下:
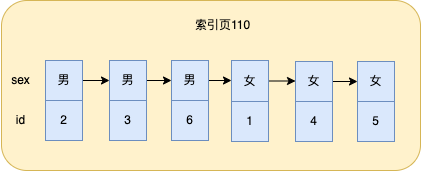
這裡我畫了6條資料,假設有10w條資料那麼也是這繼續排,男在前,女子在後。
此時如果走sex索引,查詢sex=男的資料,假設男女資料對半,那麼就掃描的記錄就有5w,之後如果要回表,那麼根據成本計算規則發現成本是巨大的,那麼此時還不如直接全表掃描來的痛快。
所以要選擇區分度高的欄位做索引
總結
到這,本文就結束了,這裡回顧一下本文講的內容
首先主要是講了聚簇索引和非聚簇索引,隨後講了MySQL對於一些常見查詢的優化,比如覆蓋索引,索引下推,都是為了減少回表次數,從而減少帶來的效能消耗,再後面就提到MySQL是如何選擇索引的,最後介紹了索引失效的場景和索引建立的原則。
最後希望本文對你有所幫助!
最後的最後,表資料sql如下
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (1, '李四', 20, '杭州');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (2, '張三', 18, '北京');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (3, '張三', 23, '上海');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (4, '趙六', 22, '杭州');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (5, '王五', 19, '北京');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (6, '趙六', 24, '上海');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (7, '劉七', 20, '上海');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (8, '劉七', 22, '上海');
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (9, '王九', 9, '杭州');
參考:
[1].《MySQL是怎樣執行的》
[2].https://blog.csdn.net/weixin_44953658/article/details/127878350
往期熱門文章推薦
掃碼或者搜尋關注公眾號 三友的java日記 ,及時乾貨不錯過,公眾號致力於通過畫圖加上通俗易懂的語言講解技術,讓技術更加容易學習,回覆 面試 即可獲得一套面試真題。
