【實踐篇】手把手教你落地DDD
1. 前言
常見的DDD實現架構有很多種,如經典四層架構、六邊形(介面卡埠)架構、整潔架構(Clean Architecture)、CQRS架構等。架構無優劣高下之分,只要熟練掌握就都是合適的架構。本文不會逐個去講解這些架構,感興趣的讀者可以自行去了解。
本文將帶領大家從日常的三層架構出發,精煉推匯出我們自己的應用架構,並且將這個應用架構實現為Maven Archetype,最後使用我們Archetype建立一個簡單的CMS專案作為本文的落地案例。
需要明確的是,本文只是給讀者介紹了DDD應用架構,還有許多概念沒有涉及,例如實體、值物件、聚合、領域事件等,如果讀者對完整落地DDD感興趣,可以到本文最後瞭解更多。
2. 應用架構演化
我們很多專案是基於三層架構的,其結構如圖:

我們說三層架構,為什麼還畫了一層 Model 呢?因為 Model 只是簡單的 Java Bean,裡面只有資料庫表對應的屬性,有的應用會將其單獨拎出來作為一個
Maven Module,但實際上可以合併到 DAO 層。
接下來我們開始對這個三層架構進行抽象精煉。
2.1 第一步、資料模型與DAO層合併
為什麼資料模型要與DAO層合併呢?
首先,資料模型是貧血模型,資料模型中不包含業務邏輯,只作為裝載模型屬性的容器;
其次,資料模型與資料庫表結構的欄位是一一對應的,資料模型最主要的應用場景就是DAO層用來進行 ORM,給 Service 層返回封裝好的資料模型,供Service 獲取模型屬性以執行業務;
最後,資料模型的 Class 或者屬性欄位上,通常帶有 ORM 框架的一些註解,跟DAO層聯絡非常緊密,可以認為資料模型就是DAO層拿來查詢或者持久化資料的,資料模型脫離了DAO層,意義不大。
2.2 第二步、Service層抽取業務邏輯
下面是一個常見的 Service 方法的虛擬碼,既有快取、資料庫的呼叫,也有實際的業務邏輯,整體過於臃腫,要進行單元測試更是無從下手。
public class Service {
@Transactional
public void bizLogic(Param param) {
checkParam(param);//校驗不通過則丟擲自定義的執行時異常
Data data = new Data();//或者是mapper.queryOne(param);
data.setId(param.getId());
if (condition1 == true) {
biz1 = biz1(param.getProperty1());
data.setProperty1(biz1);
} else {
biz1 = biz11(param.getProperty1());
data.setProperty1(biz1);
}
if (condition2 == true) {
biz2 = biz2(param.getProperty2());
data.setProperty2(biz2);
} else {
biz2 = biz22(param.getProperty2());
data.setProperty2(biz2);
}
//省略一堆set方法
mapper.updateXXXById(data);
}
}
這是典型的事務指令碼的程式碼:先做引數校驗,然後通過 biz1、biz2 等子方法做業務,並將其結果通過一堆 Set 方法設定到資料模型中,再將資料模型更新到資料庫。
由於所有的業務邏輯都在 Service 方法中,造成 Service 方法非常臃腫,Service 需要了解所有的業務規則,並且要清楚如何將基礎設施串起來。同樣的一條規則,例如if(condition1=true),很有可能在每個方法裡面都出現。
專業的事情就該讓專業的人幹,既然業務邏輯是跟具體的業務場景相關的,我們想辦法把業務邏輯提取出來,形成一個模型,讓這個模型的物件去執行具體的業務邏輯。這樣Service方法就不用再關心裡面的 if/else 業務規則,只需要通過業務模型執行業務邏輯,並提供基礎設施完成用例即可。
將業務邏輯抽象成模型,這樣的模型就是領域模型。
要操作領域模型,必須先獲得領域模型,但此時我們先不管領域模型怎麼得到,假設是通過loadDomain方法獲得的。通過 Service方法的入參,我們呼叫loadDomain方法得到一個模型,我們讓這個模型去做業務邏輯,最後執行的結果也都在模型裡,我們再將模型回寫資料庫。當然,怎麼寫資料庫的我們也先不管,假設是通過saveDomain方法。
Service層的方法經過抽取之後,將得到如下的虛擬碼:
public class Service {
public void bizLogic(Param param) {
//如果校驗不通過,則拋一個執行時異常
checkParam(param);
//載入模型
Domain domain = loadDomain(param);
//呼叫外部服務取值
SomeValue someValue=this.getSomeValueFromOtherService(param.getProperty2());
//模型自己去做業務邏輯,Service不關心模型內部的業務規則
domain.doBusinessLogic(param.getProperty1(), someValue);
//儲存模型
saveDomain(domain);
}
}
根據程式碼,我們已經將業務邏輯抽取出來了,領域相關的業務規則封閉在領域模型內部。此時 Service方法非常直觀,就是獲取模型、執行業務邏輯、儲存模型,再協調基礎設施完成其餘的操作。
抽取完領域模型後,我們工程的結構如下圖:

2.3 第三步、維護領域物件生命週期
在上一步中,loadDomain、saveDomain 這兩個方法還沒有得到討論,這兩個方法跟領域物件的生命週期息息相關。
關於領域物件的生命週期的詳細知識,讀者可以自行學習瞭解。
不管是 loadDomain 還是 saveDomain,我們一般都要依賴於資料庫,所以這兩個方法對應的邏輯,肯定是要跟 DAO 產生聯絡的。
儲存或者載入領域模型,我們可以抽象成一種元件,通過這種元件進行封裝模型載入、儲存的操作,這種元件就是Repository。
注意,Repository 是對載入或者儲存領域模型(這裡指的是聚合根,因為只有聚合根才會有Repository)的抽象,必須對上層遮蔽領域模型持久化的細節,因此其方法的入參或者出參,一定是基本資料型別或者領域模型,不能是資料庫表對應的資料模型。
以下是 Repository 的虛擬碼:
public interface DomainRepository {
void save(AggregateRoot root);
AggregateRoot load(EntityId id);
}
接下來我們要考慮在哪裡實現DomainRepository。既然 DomainRepository 與底層資料庫有關聯,但是我們現在 DAO 層並沒有引入 Domain 這個包,DAO 層自然無法提供 DomainRepository的實現,我們初步考慮是不是可以將 DomainRepository 實現在 Service 層。
但是,如果我們在 Service 中實現DomainRepository,勢必需要在 Service 層運算元據模型:查詢出來資料模型再封裝為領域模型、或者將領域模型轉為資料模型再通過ORM 儲存,這個過程不該是 Service 層關心的。
因此,我們決定在 DAO 層直接引入 Domain 包,並在 DAO 層提供 DomainRepository 介面的實現,DAO 層查詢出資料模型之後,封裝成領域模型供DomainRepository 返回。
這樣調整之後, DAO 層不再向 Service 返回資料模型,而是返回領域模型,這就隱藏了資料庫互動的細節,我們也把DAO層換個名字稱之為Repository。
現在,我們專案的架構圖是這樣的了:
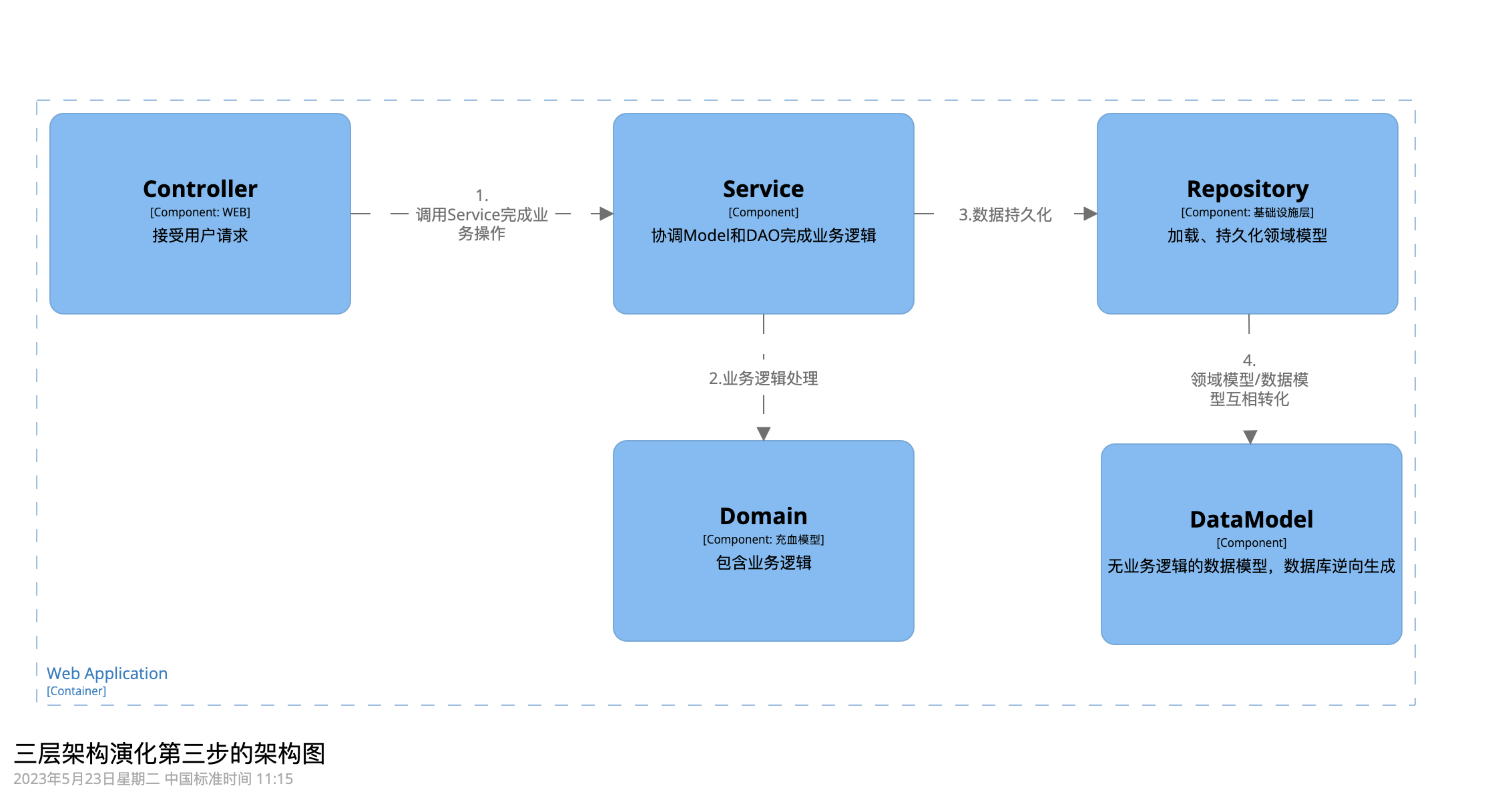
由於資料模型屬於貧血模型,自身沒有業務邏輯,並且只有Repository這個包會用到,因此我們將之合併到Repository中,接下來不再單獨列舉。
2.4 第四步、泛化抽象
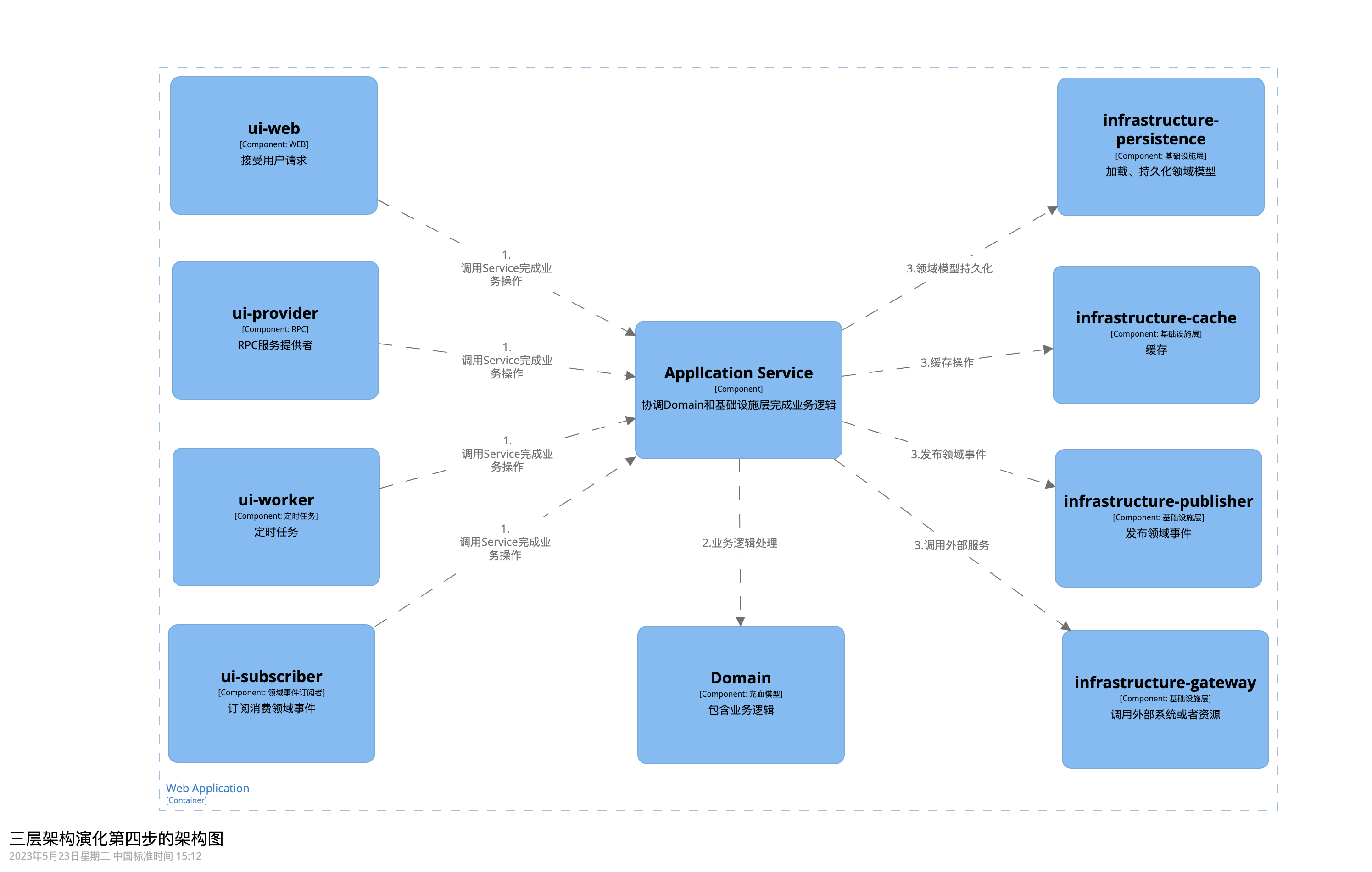
在第三步中,我們的架構圖已經跟經典四層架構非常相似了,我們再對某些層進行泛化抽象。
- Infrastructure
Repository 倉儲層其實屬於基礎設施層,只不過其職責是持久化和載入聚合,所以,我們將 Repository層改名為 infrastructure-persistence,可以理解為基礎設施層持久化包。
之所以採取這種 infrastructure-XXX 的格式進行命名,是由於 Infrastructure 可能會有很多的包,分別提供不同的基礎設施支援。
例如:一般的專案,還有可能需要引入快取,我們就可以再加一個包,名字叫infrastructure-cache。
對於外部的呼叫,DDD中有防腐層的概念,將外部模型通過防腐層進行隔離,避免汙染本地上下文的領域模型。我們使用入口(Gateway)來封裝對外部系統或資源的存取(詳細見《企業應用架構模式》,18.1入口(Gateway)),因此將對外呼叫這一層稱之為infrastructure-gateway。
注意:Infrastructure 層的門面介面都應先在Domain 層定義,其方法的入參、出參,都應該是領域模型(實體、值物件)或者基本型別。
- User Interface
Controller 層其實就是使用者介面層,即 User Interface 層,我們在專案簡稱 ui。當然了可能很多開發者會覺得叫UI好像很彆扭,認為 UI就是 UI 設計師設計的圖形介面。
Controller 層的名字有很多,有的叫 Rest,有的叫 Resource,考慮到我們這一層不只是有 Rest 介面,還可能還有一系列 Web相關的攔截器,所以我一般稱之為 Web。因此,我們將其改名為 ui-web,即使用者介面層的 Web 包。
同樣,我們可能會有很多的使用者介面,但是他們通過不同的協定對外提供服務,因而被劃分到不同的包中。
我們如果有對外提供的 RPC服務,那麼其服務實現類所在的包就可以命名為 ui-provider。
有時候引入某個中介軟體會同時增加 Infrastructure 和 User Interface。
例如,如果引入 Kafka 就需要考慮一下,如果是給 Service 層提供呼叫的,例如邏輯執行完傳送訊息通知下游,那麼我們再加一個包infrastructure-publisher;如果是消費 Kafka 的訊息,然後呼叫 Service 層執行業務邏輯的,那麼就可以命名為 ui-subscriber。
- Application
至此,Service 層目前已經沒有業務邏輯了,業務邏輯都在 Domain 層去執行了,Service 只是協調領域模型、基礎設施層完成業務邏輯。
所以,我們把 Service 層改名為 Application Service 層。
經過第四步的抽象,其架構圖為:
2.5 第五步、完整的包結構
我們繼續對第四步中出現的包進行整理,此時還需要考慮一個問題,我們的啟動類應該放在哪裡?
由於有很多的 User Interface,所以啟動類放在任意一個User Interface中都不合適,放置在Application Service中也不合適,因此,啟動類應該存放在單獨的模組中。又因為 application這個名字被應用層佔用了,所以將啟動類所在的模組命名為 launcher,一個專案可以存在多個launcher,按需參照User Interface。
加入啟動包,我們就得到了完整的 maven 包結構。
包結構如圖所示:

至此,DDD 專案的整體結構基本講完了。
2.6 精煉後的思考
在經過前面五步精煉得到這個架構圖中,經典四層架構的四層都出現了,而且長得跟六邊形架構也很像。這是為什麼呢?
其實,不管是經典四層架構、還是六邊形架構,亦或者整潔架構,都是對系統應用的描述,也許描述的側重點不一樣,但是描述的是同一個事物。既然描述的是同一個事物,長得像才是理所當然的,不可能只是換一個描述方式,系統就從根本上發生了改變。
對於任何一個應用,都可以看成「輸入-處理-輸出」的過程。
「輸入」環節:通過某種協定對外暴露領域的能力,這些協定可能是 REST、可能是 RPC、可能是 MQ 的訂閱者,也可能是WebSocket,也可能是一些任務排程的 Task;
」處理「環節:處理環節是整個應用的核心,代表了應用具備的核心能力,是應用的價值所在,應用在這個環節執行業務邏輯,貧血模型由Service執行業務處理,充血模型則是由模型進行業務處理。
「輸出」環節,業務邏輯執行完成之後將結果輸出到外部。
不管我們採用的什麼架構,其描述的應用的核心都是這個過程,不必生搬硬套非得用什麼應用架構。
正如《金剛經》所言:一切有為法,如夢幻泡影,如露亦如電,應作如是觀;凡所有相,皆是虛妄;若見諸相非相,即見如來。
3. ddd-archetype
3.1 Maven Archetype介紹
Maven Archetype是一個Maven外掛,可以幫助開發人員快速建立專案的基礎結構,大大減少開發人員在建立專案時所需的時間和精力,並且可以確保專案結構的一致性和可重用性,從而提高程式碼質量和可維護性。
我們在介紹DDD應用架構時,對專案的結構進行了介紹。我們將專案分為多個Maven Module,如果每個專案都手工建立一次,是比較繁瑣的工作,也不利專案結構的統一。
我們使用Maven Archetype建立DDD專案初始化的腳手架,使其在初始化時完整實現上文第五步的應用架構。
3.2 ddd-archetype的使用
3.2.1 專案介紹
ddd-archetype是一個Maven Archetype的原型工程,我們將其克隆到本地之後,可以安裝為Maven Archetype,幫助我們快速建立DDD專案腳手架。
專案連結:
https://github.com/feiniaojin/ddd-archetype
3.2.2 安裝過程
以下將以IDEA為例展示ddd-archetype的安裝使用過程,主要過程是:
克隆專案-->archetype:create-from-project-->install-->archetype:crawl
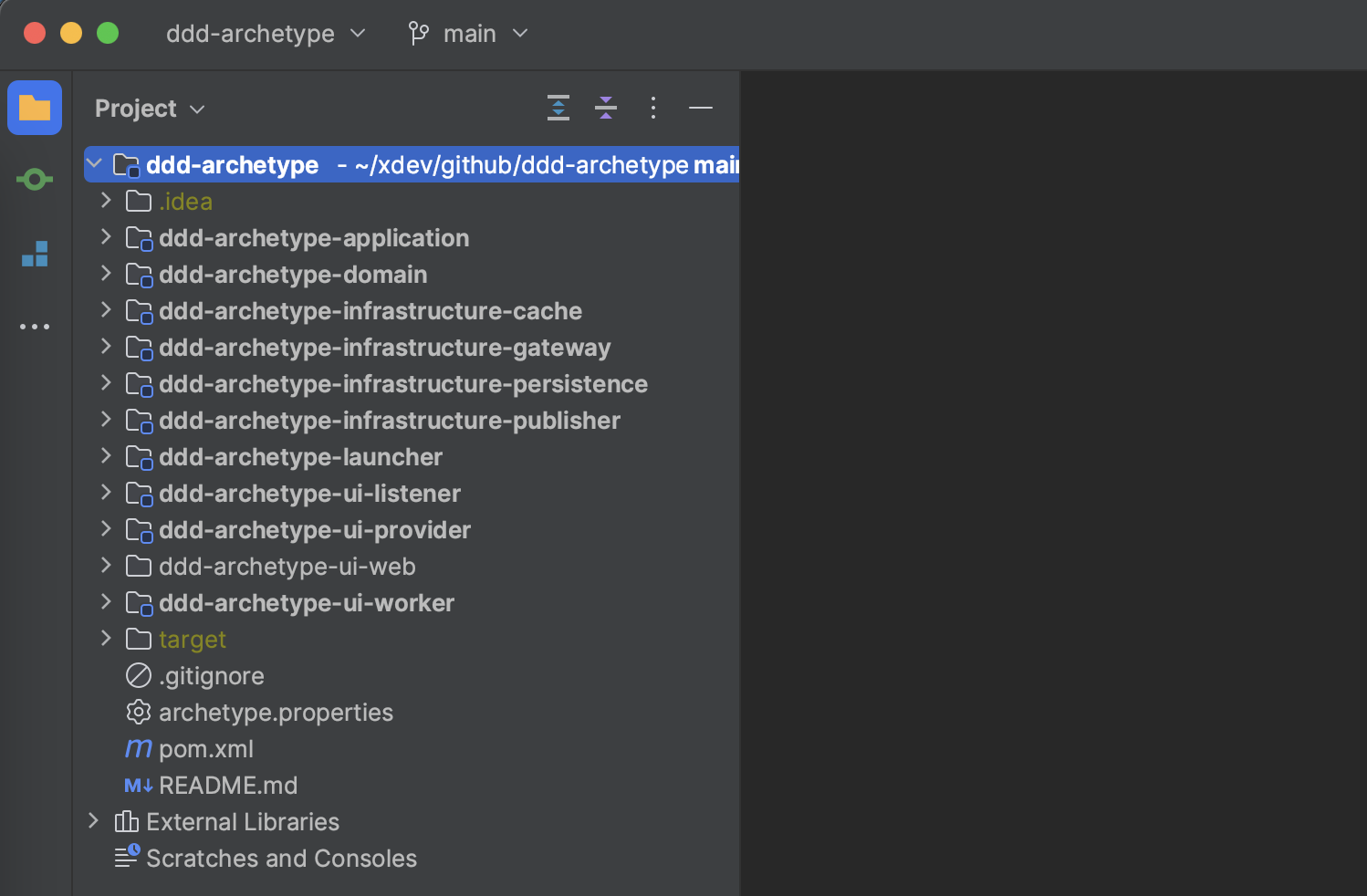
3.2.3 克隆專案
將專案克隆到本地:
git clone https://github.com/feiniaojin/ddd-archetype.git
直接使用主分支即可,然後使用IDEA開啟該專案
3.2.4 archetype:create-from-project
設定開啟IDEA的run/debug configurations視窗,如下:
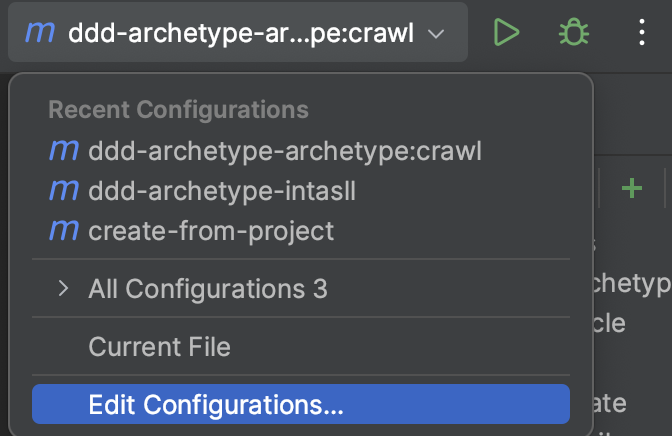
選擇add new configurations,彈出以下視窗:

其中,上圖中1~4各個標識的值為:
標識1 - 選擇"+"號;
標識2 - 選擇"Maven";
標識3 - 命令為:
archetype:create-from-project -Darchetype.properties=archetype.properties
注意,在IDEA中新增的命令預設不需要加mvn
標識4 - 選擇ddd-archetype的根目錄
以上設定完成後,點選執行該命令。
3.2.5 install
上一步執行完成且無報錯之後,設定install命令。
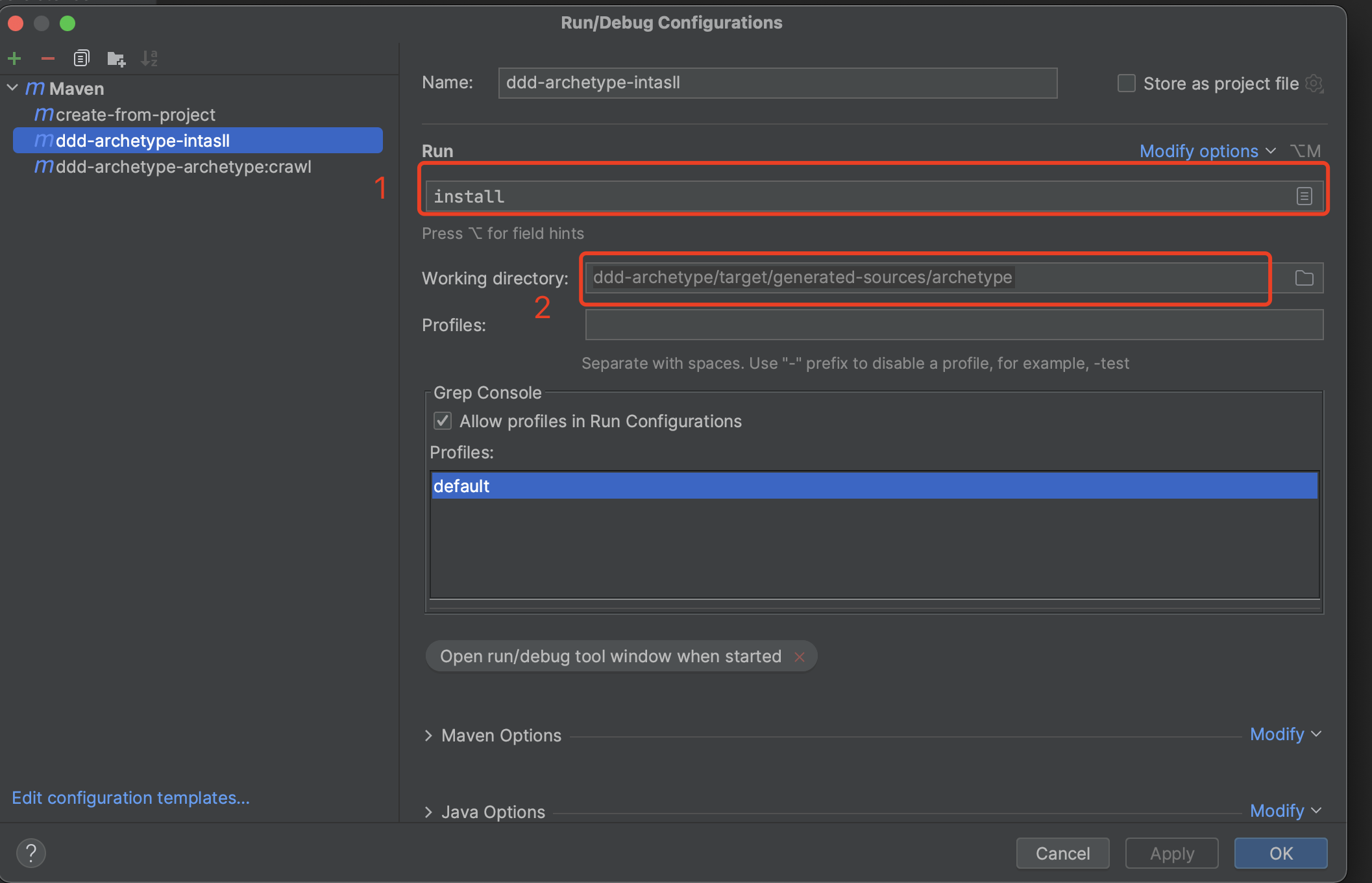
其中,上圖中1~2各個標識的值為:
標識1 - 值為install;
標識2 - 值為上一步執行的結果,路徑為:
ddd-archetype/target/generated-sources/archetype
install設定完成之後,點選執行。
3.2.6 archetype:crawl
install執行完成且無報錯,接著設定archetype:crawl命令。
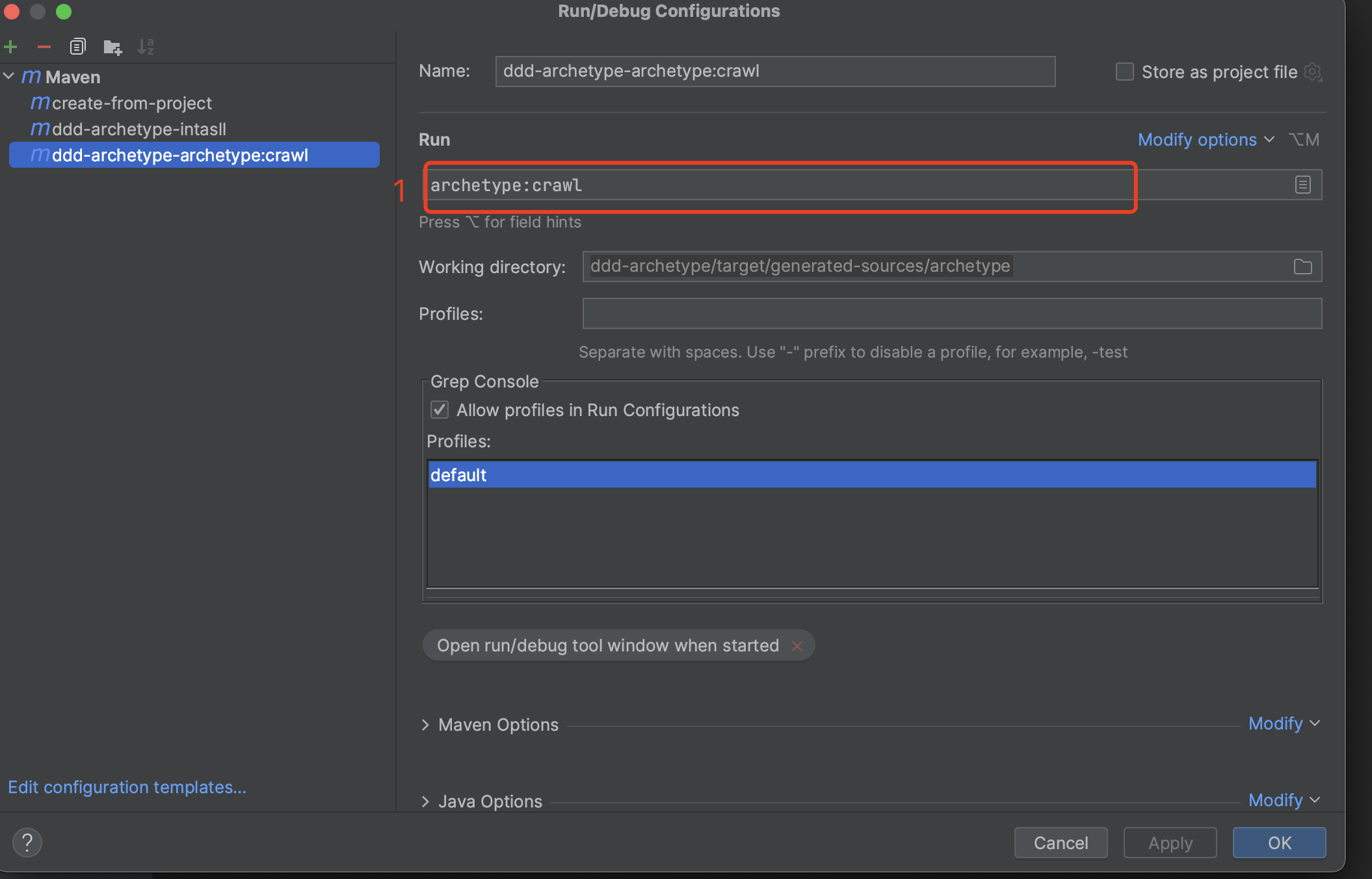
其中,標識1中的值為:
archetype:crawl
設定完成,點選執行即可。
3.3 使用ddd-archetype初始化專案
- 建立專案時,點選
manage catalogs:

- 將原生的maven私服中的
archetype-catalog.xml加入到catalogs中:
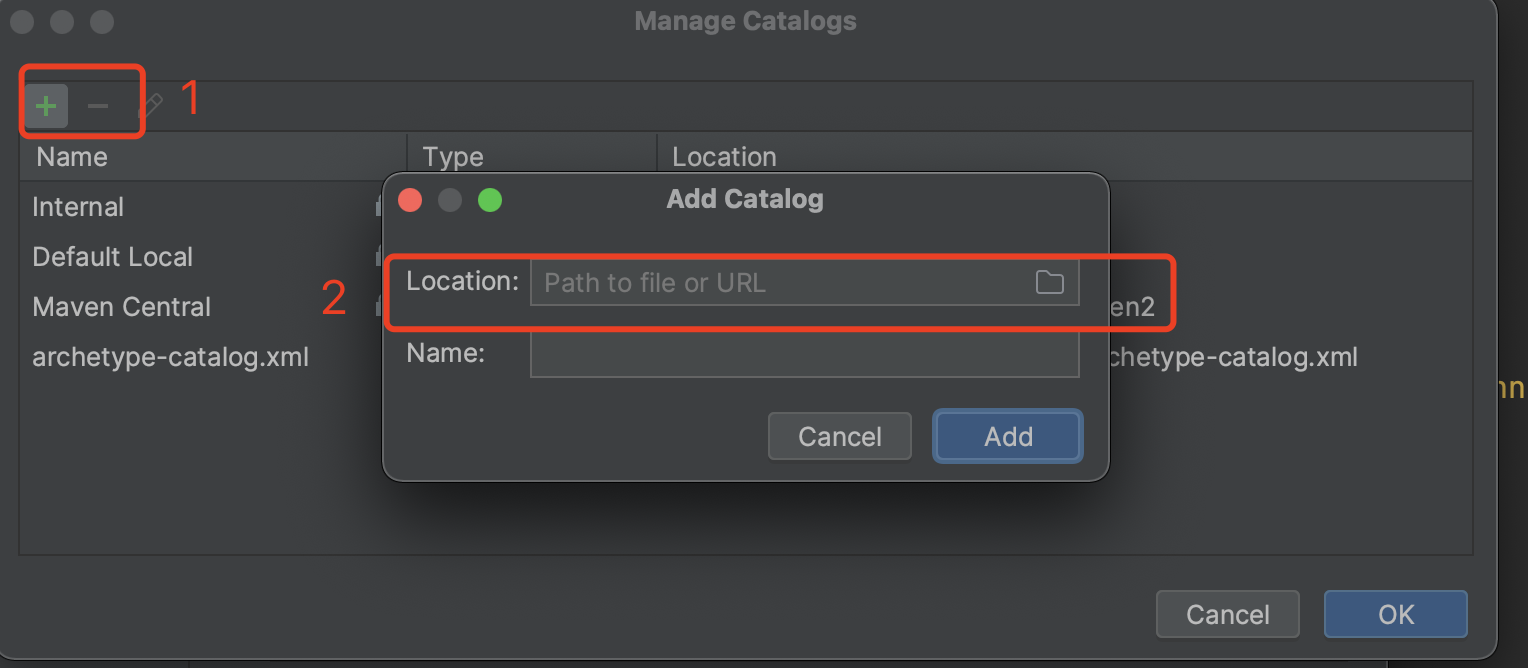
新增成功,如下:
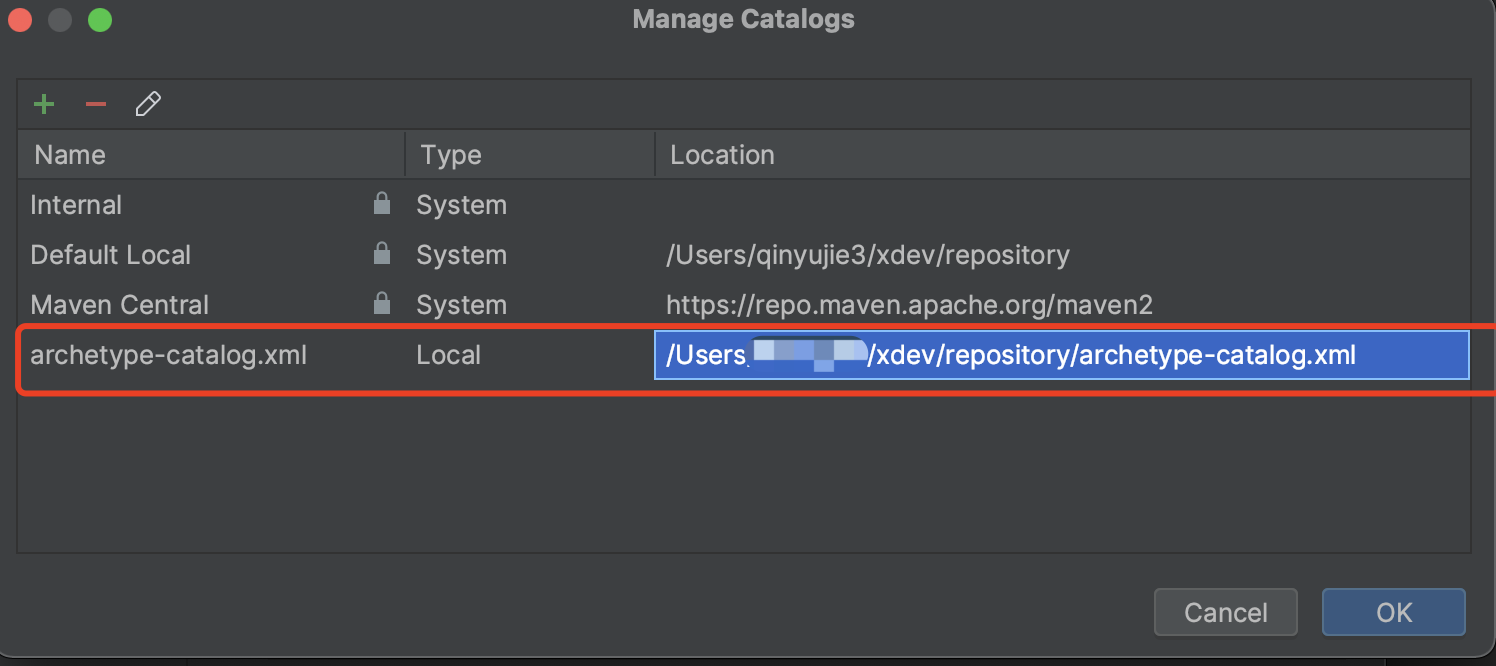
- 建立專案時,選擇本地archetype-catalog,並且選擇
ddd-archetype,填入專案資訊並建立專案:

- 專案建立完成後:
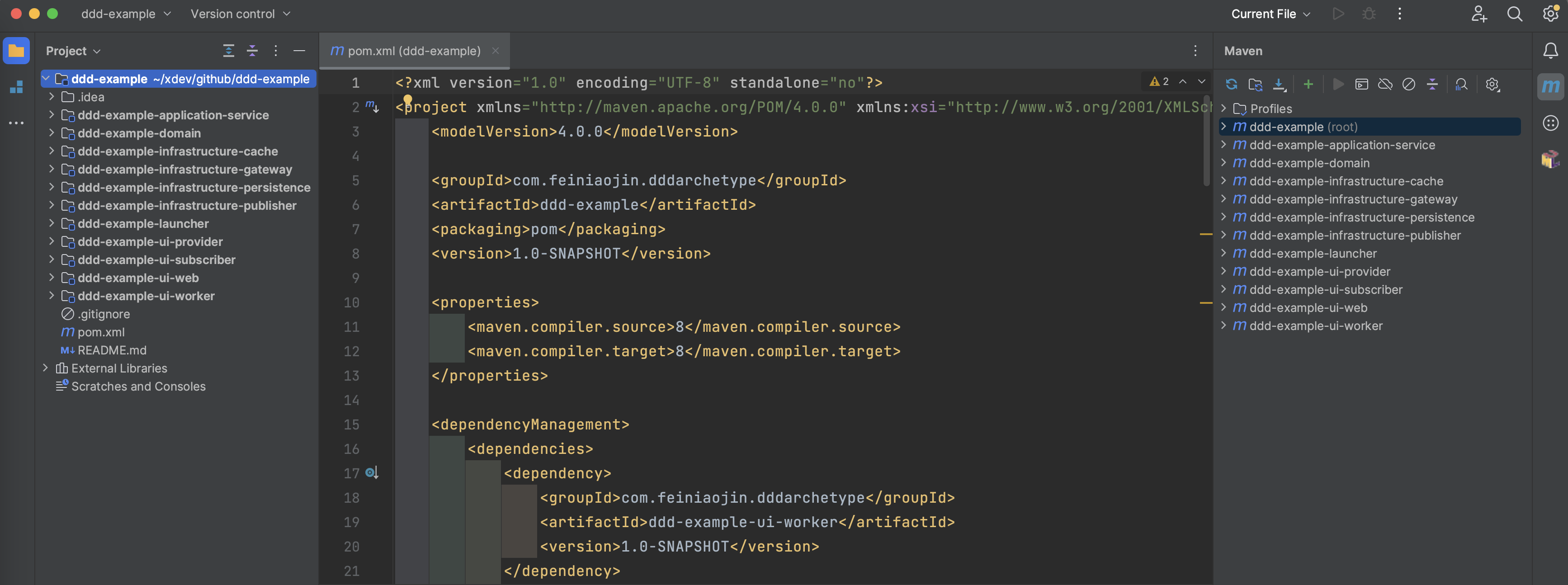
4. 程式碼案例
本文提供了配套的程式碼案例,該案例使用DDD和本文的應用架構實現了簡單的CMS系統。案例專案採用前後端分離的方式,因此有後端和前端兩個程式碼庫。
4.1 後端
後端專案使用本文的ddd-archetype建立,實現了部分CMS的功能,並落地部分DDD的概念。
GitHub連結:https://github.com/feiniaojin/ddd-example-cms
實現的DDD概念有:實體、值物件、聚合根、Factory、Repository、CQRS。
技術棧:
- Spring Boot
- H2記憶體資料庫
- Spring Data JDBC
無外部中介軟體依賴 ,clone到本地即可編譯執行,非常方便。
4.2 前端
前端專案基於vue-element-admin開發,詳細安裝方式見程式碼庫的README。
GitHub連結:https://github.com/feiniaojin/ddd-example-cms-front
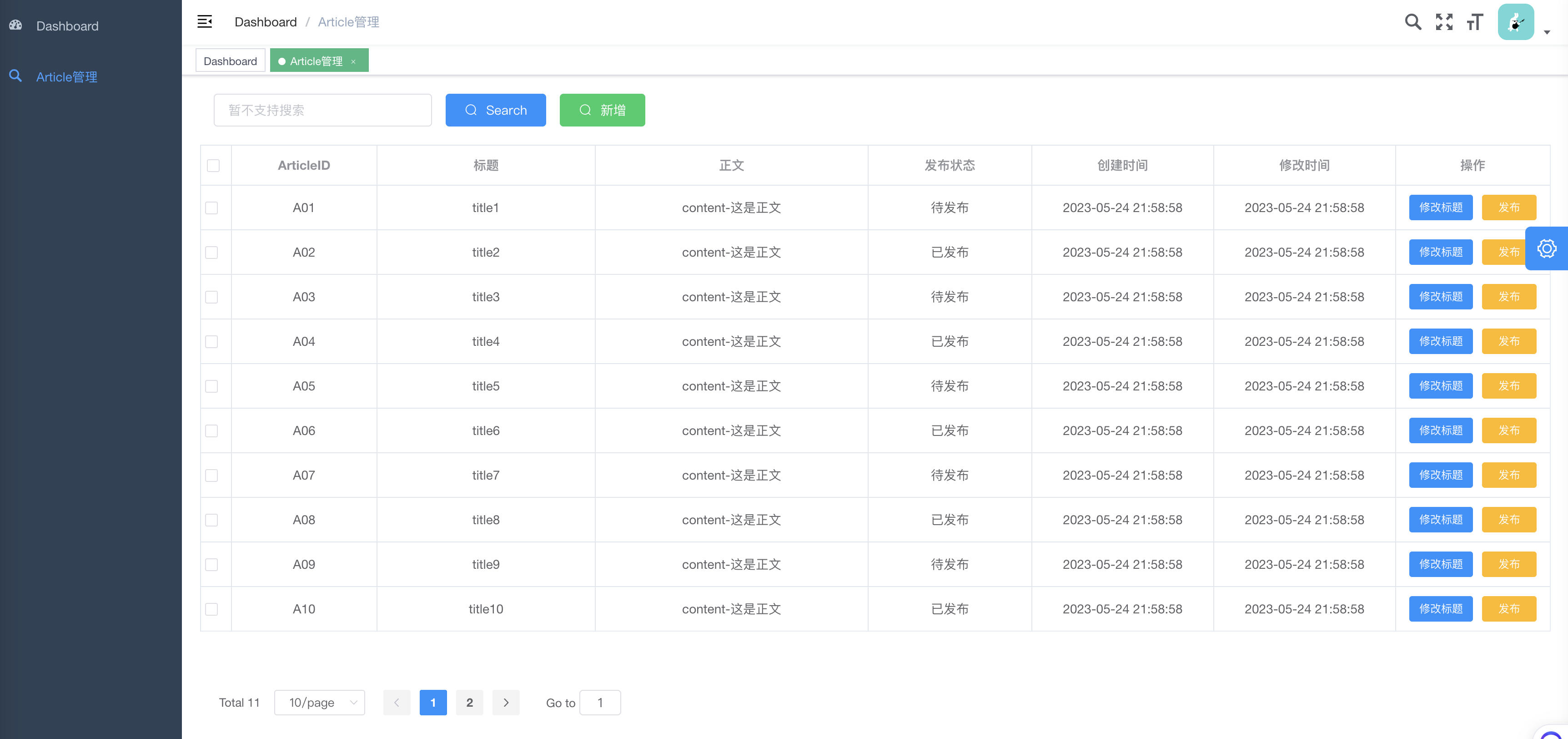
4.3 執行截圖
5. 總結以及進一步學習
本文通過對貧血三層架構進行精煉,推匯出適合我們落地的應用架構,並且將之實現為Maven Archetype以應用到實際開發,然而應用架構只是落地DDD的一個知識點,要完整落地DDD還必須體系化地掌握限界上下文、上下文對映、充血模型、實體、值物件、領域服務、Factory、Repository等知識點。
作者:京東物流 覃玉傑
內容來源:京東雲開發者社群