GPT-4多型大模型研究
1.概述
GPT-4是OpenAI最新的系統,能夠產生更安全和更有用的迴應。它是一個大型的多模態模型(接受影象和文字輸入,輸出文字),在各種專業和學術的基準測試中展現了人類水平的表現。例如,它在模擬的律師資格考試中得分位於前10%的考生之列;相比之下,GPT-3.5的得分位於後10%。
GPT-4是如何做到這一點的呢?它是如何超越前幾代的語言模型的呢?它又能為我們帶來什麼樣的好處和挑戰呢?本文將從以下幾個方面介紹GPT-4的特點、能力和應用。
2.內容
2.1 GPT-4特點
GPT-4是基於深度學習的方法,利用更多的資料和更多的計算來建立越來越複雜和能力強大的語言模型。它繼承了GPT、GPT-2和GPT-3的研究路徑,但也做了一些重要的改進和創新。
1. 創造力
GPT-4比以往任何時候都更具創造力和共同作業性。它可以生成、編輯和與使用者迭代進行創意和技術寫作任務,例如創作歌曲、編寫劇本或學習使用者的寫作風格。
例如,它可以根據一個簡單的提示,寫出一句話,其中每個單詞都要以字母表中的下一個字母開頭,從A到Z,而且不能重複任何字母。
2. 視覺輸入
GPT-4可以接受影象和文字輸入,這與僅文字輸入的設定相比,使使用者能夠指定任何視覺或語言任務。具體來說,它根據由文字和影象交錯組成的輸入生成文字輸出(自然語言、程式碼等)。
例如,它可以根據一張圖片和一些文字描述,生成一首詩。
3. 更長的上下文
GPT-4能夠處理更長的上下文,這意味著它可以記住更多的資訊,並在不同的對話或任務中使用它。12
例如,它可以根據一個長達1000個單詞的文章摘要,生成一個完整的文章。
2.2 預測能力
GPT-4專案的一大重點是構建一個可預測擴充套件的深度學習堆疊。這個主要原因是,對於像GPT-4這樣的大型訓練,進行廣泛的訓練是不可行的特定型號的調整。為了解決這一問題,我們開發了基礎設施和優化方法在多個尺度上具有非常可預測的行為。這些改進使我們能夠可靠地從使用1000×–訓練的較小模型中預測GPT-4效能的某些方面10000×更少的計算。
1.損失預測
在機器學習和深度學習領域中,損失預測是指通過訓練模型來估計或預測模型的損失函數。損失函數是用於衡量模型在訓練過程中的效能和誤差的指標,通常用於優化模型的引數和權重。損失預測可以幫助開發者和研究人員評估模型的訓練進展和效果,以便根據預測的損失進行調整和改進模型的效能。
經過適當訓練的大型語言模型的最終損失被認為是冪的近似值用於訓練模型的計算量定律[41,42,2,14,15]。為了驗證我們優化基礎設施的可延伸性,我們預測GPT-4在內部程式碼庫(不是訓練集的一部分),通過擬合具有不可約損失項的比例定律:L(C) = aCb + c,來自使用相同方法訓練的模型但是使用最多比GPT-4少10000倍的計算。這個預測是在跑步後不久做出的
已啟動,沒有使用任何部分結果。擬合的比例定律預測了GPT-4的最終損失高精度,如下圖所示:
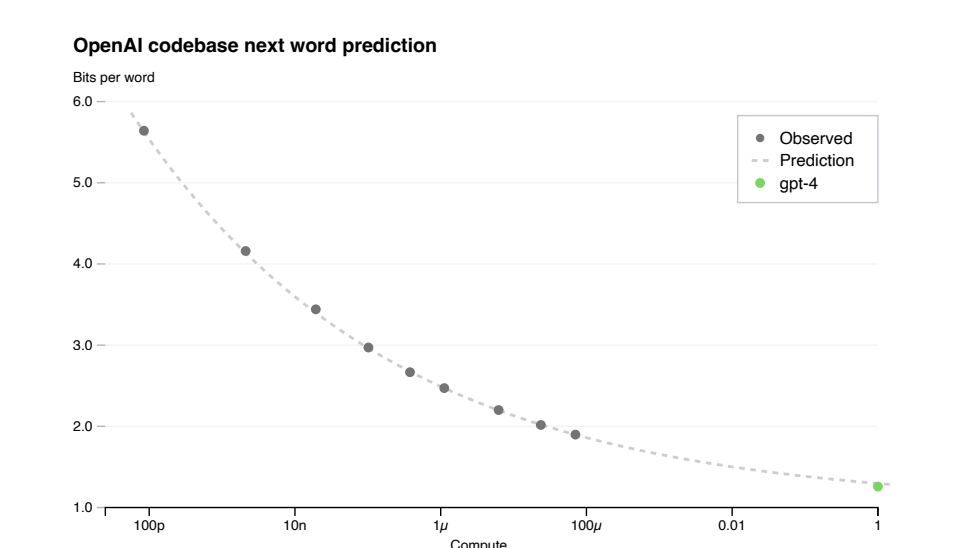
2. 能力擴充套件
在訓練之前對模型的能力有一種感覺可以改進關於對齊的決策,安全性和部署。除了預測最終損失外,我們還開發了預測方法更可解釋的能力度量。一個這樣的度量是人工評估資料集上的通過率[43],其測量合成不同複雜度的Python函數的能力。我們成功地通過從訓練的模型中推斷,預測人工評估資料集的一個子集的通過率最多可減少1000倍的計算量。對於人工評估中的單個問題,效能可能偶爾會隨著規模的擴大而惡化。
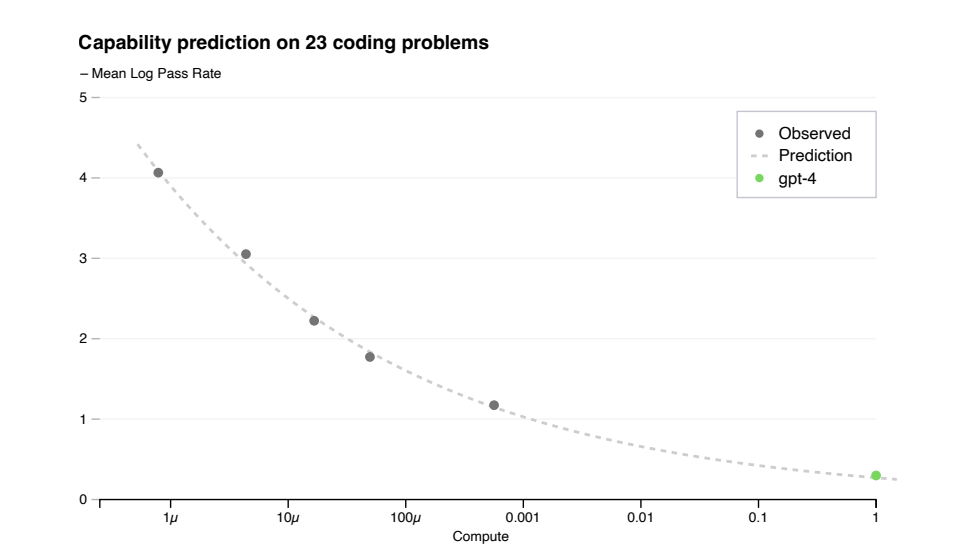
在公式Ep[log(pass_rate(C))] = a * C-k中,其中k和α是正常數,P是資料集中問題的子集。我們假設這種關係適用於該資料集中的所有問題。在實踐中,非常低的通過率是困難的
或者不可能估計,所以限制在問題P和模型M上,使得給定一些大的樣本預算,每個模型至少解決一次每個問題。在訓練完成之前,在人類評估上註冊了GPT-4效能的預測,使用
只有培訓前的可用資訊。除了15個最難的人類評估問題外,其他問題都被分解了基於較小模型的效能,分為6個難度桶。在上圖中,表明由此產生的預測對此非常準確人類評估問題的子集,其中我們可以準確估計幾個較小問題的log(pass_rate)模型。對其他五個桶的預測幾乎同樣出色,主要的例外是GPT-4在最簡單的桶上表現不如我們的預測。
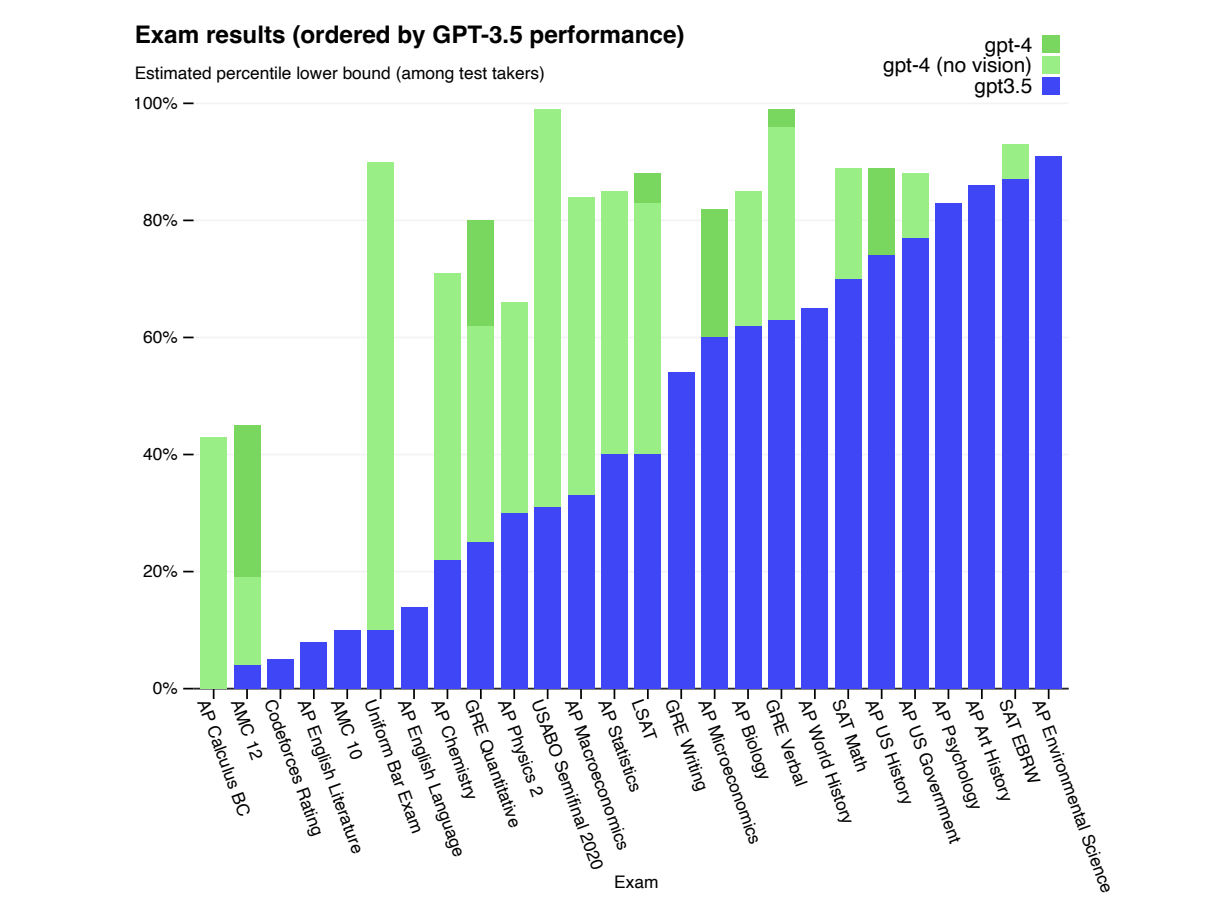
在各種基準測試中對GPT-4進行了測試,包括模擬最初為人類設計的考試。對於這些考試,沒有進行特定的訓練。模型在訓練過程中只接觸到了少數考試中的問題;對於每個考試,執行了一個去除了這些問題的變體,並報告其中較低的分數。相信這些結果是具有代表性的。
考試題目來自公開可獲取的資料。考試題目包括多項選擇題和自由回答題;為每種題型設計了單獨的提示,並且對於需要影象的問題,在輸入中包含了相應的影象。評估設定是基於驗證集上的效能設計的,並且在保留的測試考試上報告最終結果。
綜合分數是通過使用每個考試的公開可用方法,將多項選擇題和自由回答題的得分相結合得出的。估計並報告每個綜合分數所對應的百分位數。結果如下圖所示:
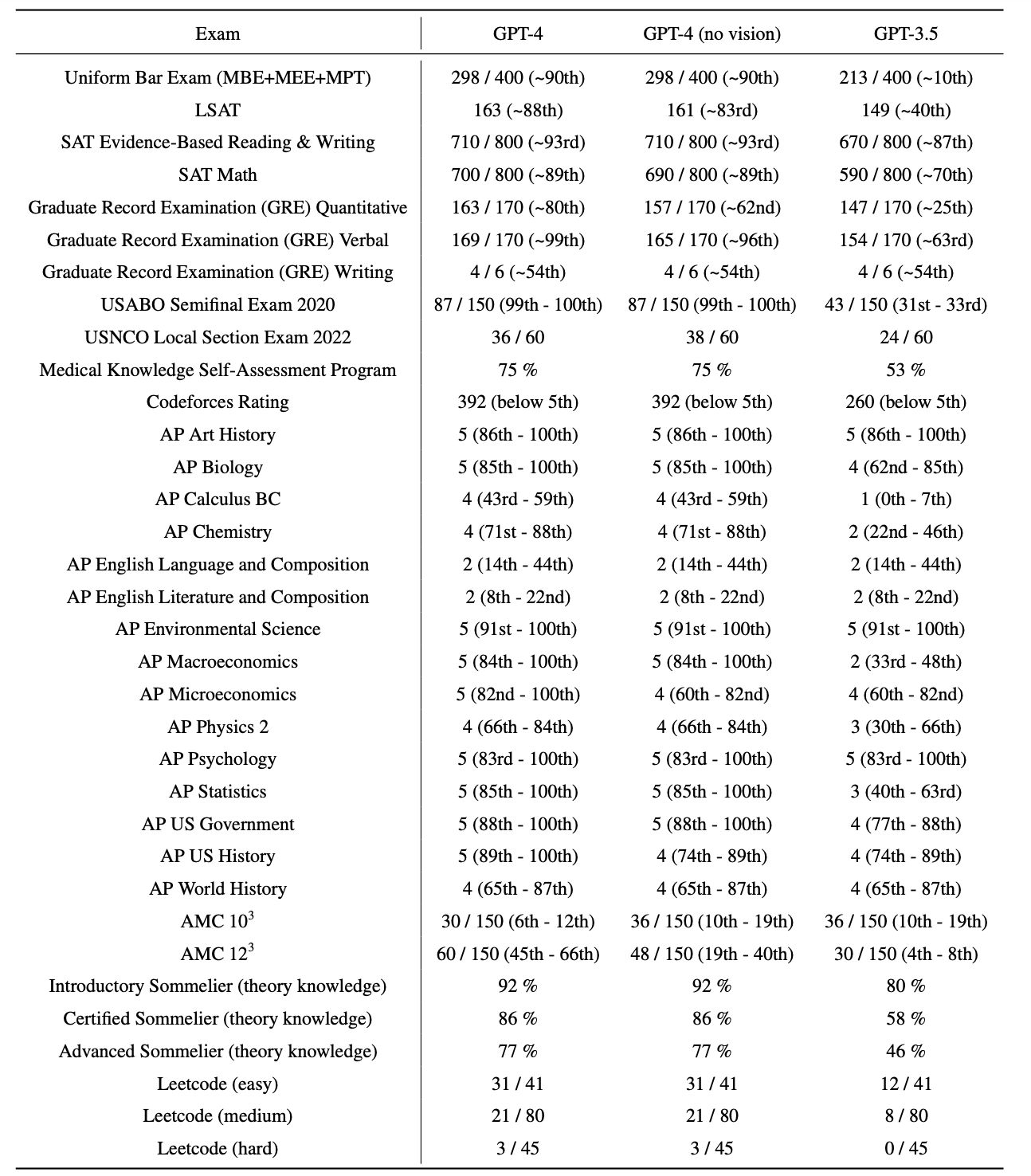
GPT-4在大部分專業和學術考試中展現出與人類水平相當的表現。值得注意的是,它在模擬的統一法律職業資格考試中取得了前10%的得分。
該模型在考試中的能力主要來源於預訓練過程,並且並未受到強化學習微調的顯著影響。在我們測試的多項選擇題中,基準GPT-4模型和經過強化學習微調的模型平均表現相當出色。
我們還對預訓練的基準GPT-4模型進行了傳統基準測試,這些測試旨在評估語言模型。對於每個基準測試,我們對出現在訓練集中的測試資料進行了汙染檢查。在評估GPT-4時,我們使用了少樣本提示的方法。
GPT-4在很大程度上超越了現有的語言模型,以及以往的最先進系統(SOTA),這些系統通常需要針對特定基準測試進行調整或額外的訓練方案。如下圖所示:
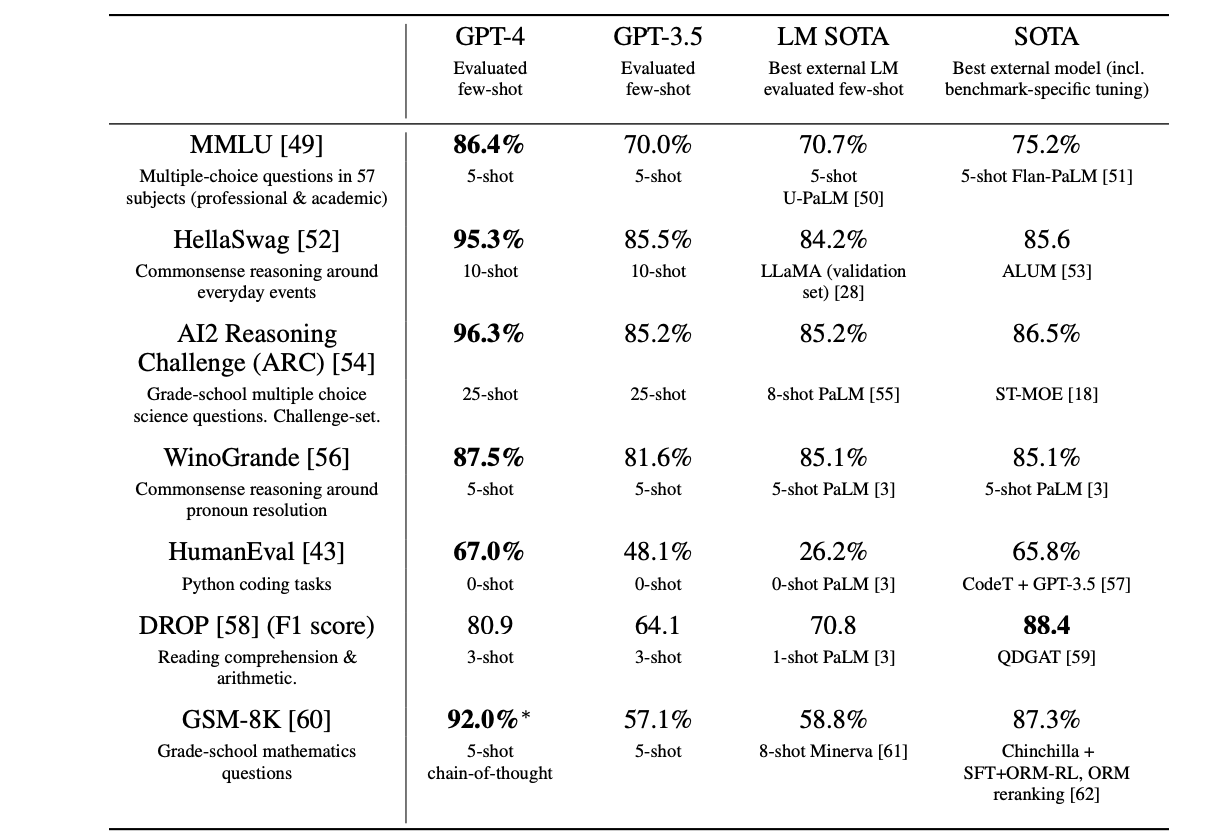
GPT-4在學術基準測試中的表現。將GPT-4與最先進的基準測試專用訓練模型(SOTA)以及少樣本評估中最好的語言模型(LM)進行了比較。在所有基準測試中,GPT-4表現優於現有的語言模型,並在除了DROP資料集之外的所有資料集上超越了基準測試專用訓練的SOTA模型。在GPT-4的預訓練資料中包含了部分訓練集,並在評估時使用了思維鏈式提示。對於多項選擇題,向模型展示了所有答案(ABCD),並要求它選擇答案的字母,類似於人類解決這類問題的方式。
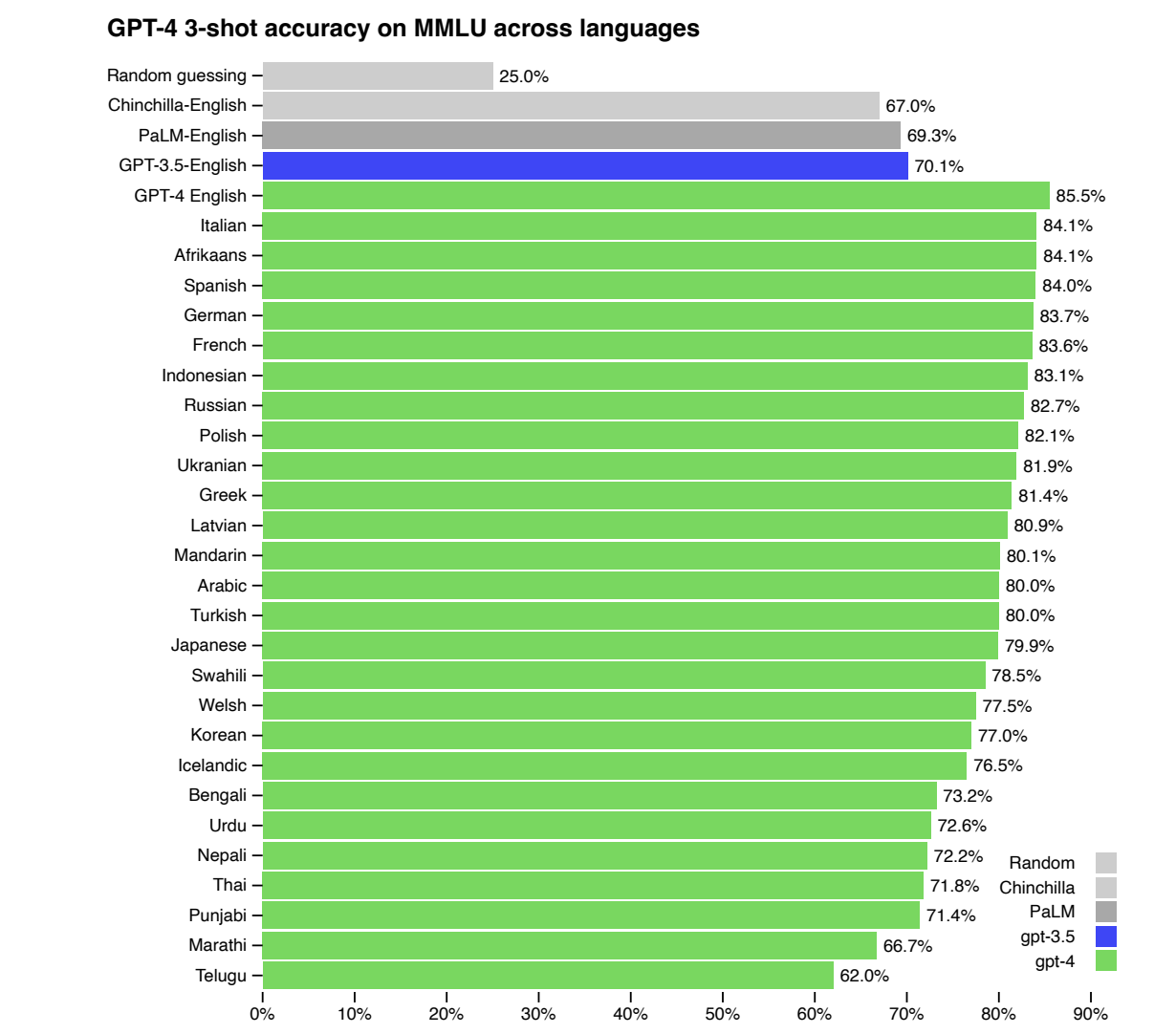
許多現有的機器學習基準測試都是用英語編寫的。為了初步瞭解GPT-4在其他語言上的能力,使用Azure Translate將包含57個科目的MMLU基準測試(一套多項選擇題)翻譯成了多種語言。在測試的大多數語言中,包括拉脫維亞語、威爾士語和斯瓦希里語等資源較少的語言,GPT-4在英語表現方面優於GPT 3.5和現有的語言模型。
GPT-4在跟隨使用者意圖方面大大提高了效能。在一個由5,214個提示提交給ChatGPT和OpenAI API 的資料集上,GPT-4生成的回覆在70.2%的提示上優於GPT 3.5生成的回覆。
官方開源了OpenAI Evals,這是用於建立和執行評估模型(如GPT-4)基準測試的框架,可以逐個樣本檢查效能。Evals與現有的基準測試相容,並可用於跟蹤模型在部署中的效能。官方計劃逐步增加這些基準測試的多樣性,以代表更廣泛的失效模式和更困難的任務。
3.侷限性
儘管具備強大的能力,GPT-4仍然存在與之前的GPT模型相似的限制。最重要的是,它仍然不是完全可靠的(會出現"產生幻覺"的事實和推理錯誤)。在使用語言模型的輸出時,特別是在高風險環境下,需要格外謹慎,確保採用符合特定應用需求的確切協定(例如人工稽核、附加上下文的基礎支撐,或完全避免高風險使用)。
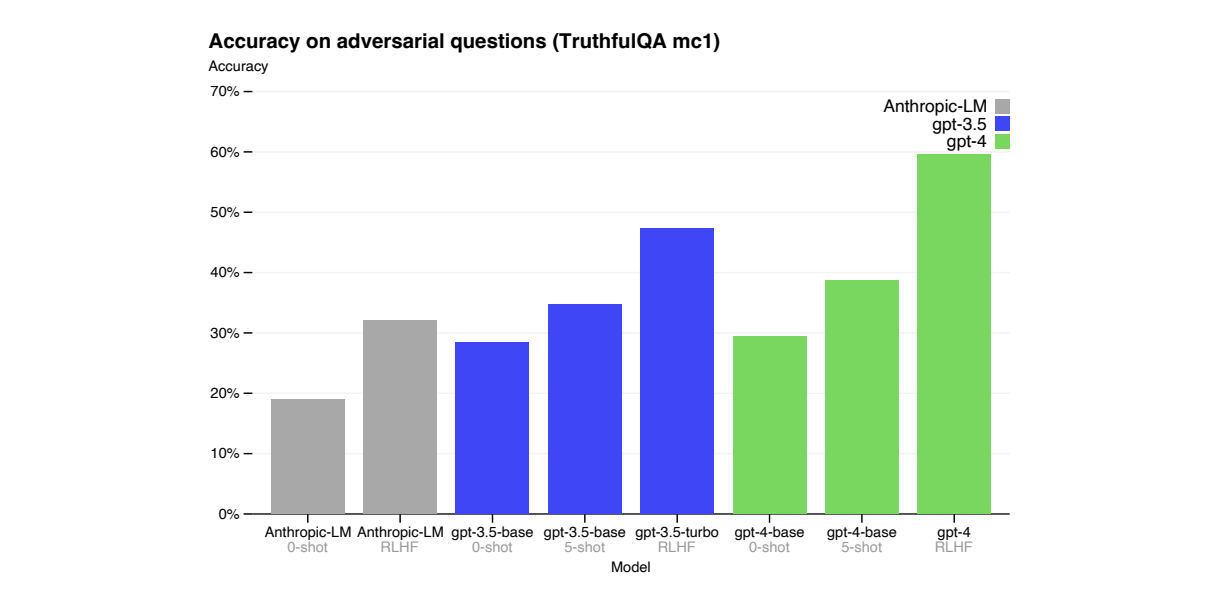
相對於之前的GPT-3.5模型(通過持續迭代不斷改進),GPT-4在幻覺現象方面顯著減少。在官方內部經過對抗設計的真實性評估中,GPT-4相對於我們最新的GPT-3.5模型得分提高了19個百分點。
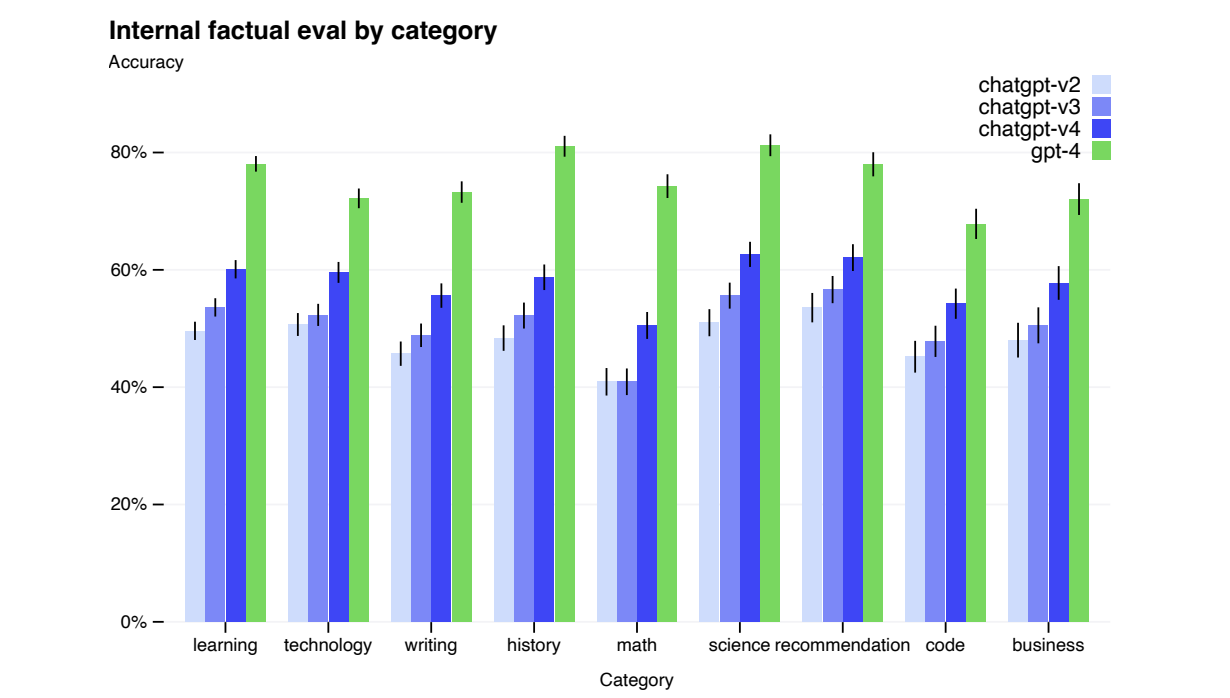
GPT-4在公共基準測試如TruthfulQA 上取得了進展,該測試評估模型將事實與對抗性選擇的一組錯誤陳述分開的能力。這些問題與統計上具有吸引力的錯誤答案配對。GPT-4基礎模型在這個任務上只比GPT-3.5略好一些;然而,在RLHF後訓練後,我們觀察到相對於GPT-3.5有了很大的改進。
GPT-4通常缺乏對其預訓練資料在2021年9月之後發生的事件的瞭解,並且不會從自身經驗中學習。它有時會出現簡單的推理錯誤,這些錯誤似乎與在如此多領域中表現出的能力不符,或者過於輕信使用者明顯錯誤的陳述。它在處理艱難問題時可能會與人類一樣失敗,例如在其生成的程式碼中引入安全漏洞。
當GPT-4可能會犯錯時,它在預測時也可能會自信地出錯,沒有注意雙重檢查工作。有趣的是,預訓練模型的校準性非常高(它對一組樣本的正確性估計與實際正確性的比例相當),但它的錯誤是系統性的,這意味著它可能在某些方面過於自信。
總之,儘管GPT-4在許多基準測試上取得了進展,但它仍然存在一些限制和挑戰,需要在使用過程中謹慎對待其輸出,並結合特定應用的需求採取相應的驗證和處理方法。
4.風險和安全改進措施
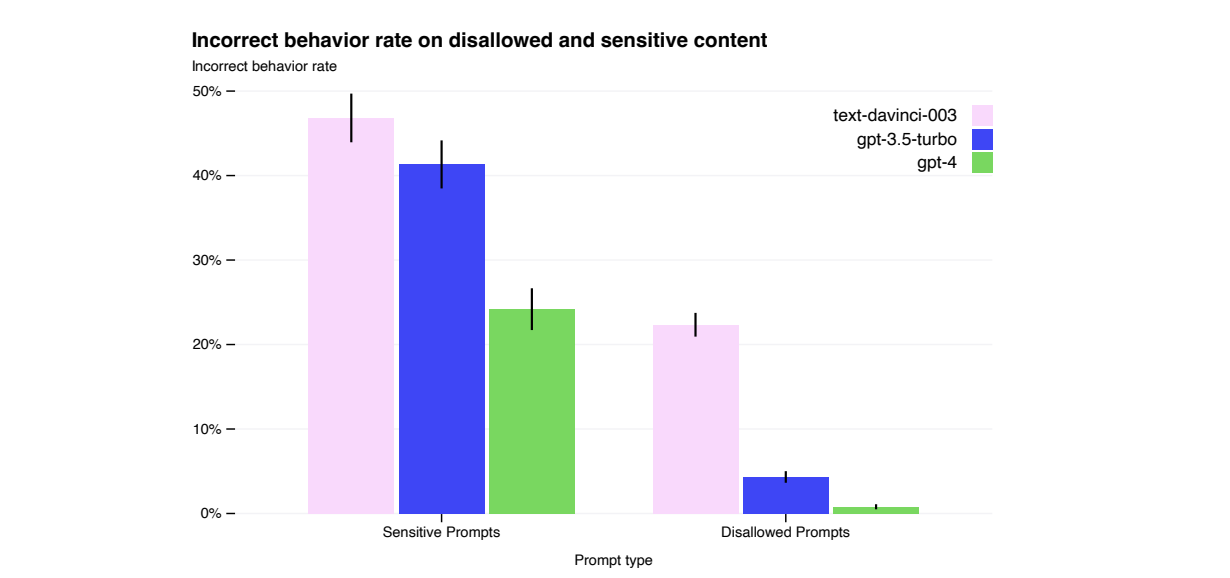
通過領域專家進行對抗性測試:GPT-4與較小的語言模型存在類似的風險,例如生成有害建議、錯誤的程式碼或不準確的資訊。然而,GPT-4的額外功能導致了新的風險面。為了瞭解這些風險的程度,官方請來了領域專家,對GPT-4進行了廣泛的測試和評估,以識別潛在的問題和風險。這有助於更好地理解模型的弱點和改進的方向。
模型輔助的安全流程:為了提高GPT-4的安全性,開發了一種模型輔助的安全流程。這個流程結合了人工稽核和自動化工具,以檢測模型生成的內容中可能存在的問題和風險。目標是及早發現和糾正潛在的安全問題,並確保模型生成的輸出對使用者和社會有益。
安全度量指標的改進:相比之前的模型,在安全度量指標方面取得了改進。通過對GPT-4生成的樣本進行人工稽核和自動化檢測,提高了對生成內容中潛在問題和風險的識別能力。目標是降低模型生成有害或誤導性內容的概率,並確保其對使用者和社會的影響是正面的。
5.總結
GPT-4它是一個大型多模態模型,在專業和學術基準測試中表現出人類水平的效能,超越現有語言模型,在多種語言中展現出改進的能力,為構建廣泛有用且安全的AI系統邁出重要一步。
郵箱:[email protected]
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka並不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),方便管理員稽核,謝謝!
