泰褲辣!!!手摸手教學,如何訓練一個你的專屬AI歌姬~
最近在做AIGC的專案,不過是與圖片相關的,現在的模型效果可比前幾年圖片替換效果好多了。之前嘗試過用 faceswap 工具來進行人臉替換的,具體可以參看下我之前的這篇文章:https://blog.csdn.net/sinat_26918145/article/details/79591717
現代的模型對於圖生圖的支援效果已經非常好了,相信對於美術行業,這是一場影響很深遠的變革。也許我們正站在一個新的時代交叉路口,可能多年後回憶起當下的一瞬間,才後知後覺我們經歷了一段什麼樣的時代開端。
好了,回到主題,這一篇文章主要是介紹如何使用音訊模型,轉換成你想要的歌手聲音,得益於AI孫燕姿的火爆全網,讓我也迫切想嘗試一下 AIsong 歌曲轉換。
目前來說比較火的開源 SVC 主要有以下幾種:
- rvc: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- diff-svc: https://github.com/prophesier/diff-svc
- so-vits-svc: https://github.com/svc-develop-team/so-vits-svc
語音轉換的目標是將源語音轉換為目標語音,保持內容不變。提出了自監督表示學習用於語音轉換
離散內容編碼表示會丟失一些語言內容,導致發音不準確。為此,提出了通過預測離散單位分佈學習的軟語音單位。通過建模,軟語音單位捕捉更多的內容,提高了轉換語音的效果。
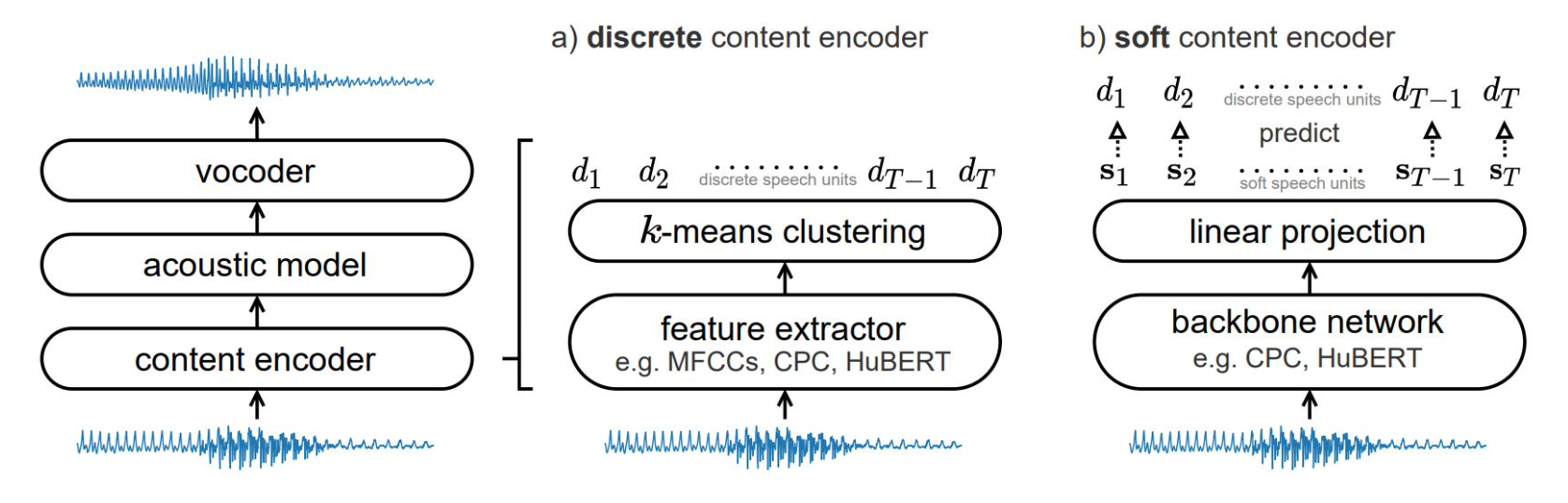
在語音轉換系統架構中,離散內容編碼主要包含兩個部分的實現:
- 離散內容編碼器:將音訊特徵聚類,生成一系列離散的語音單位序列
- 軟內容編碼器:被訓練用於預測離散語音單位
除此之外Acoustic model將離散/軟語音單位轉換為目標聲譜圖。 vocoder語音合成器將聲譜圖轉換為音訊波形。
廢話不多說,前期鋪墊了這麼多,我們下面直接開始操作~
一、前期準備
剛開始模型訓練前,我們需要蒐集大量的目標人物的音訊素材,如果是需要以你自己聲音為基礎的轉換模型,則需要錄製你自己的聲音。這裡的素材多少會直接影響到你模型訓練的質量,一般建議提供 100 分鐘以上的人聲素材。
如果不是自己的聲音,建議可以去網上搜集需要的人聲音訊。我這邊使用的是阿B上的視訊素材,這裡可以使用這裡推薦的工具(傳送門),直接下載對應的視訊or音訊,非常方便~
這裡我下載了差不多100分鐘的音訊
準備好音訊素材後,需要對音訊檔進行人聲和背景音的分離,因為背景音對於模型的訓練有干擾,單純的人聲可以讓模型的聲音效果和目標更擬合。這裡使用到的工具是 demucs
安裝:
pip install -U demucs
分離人聲和背景音
demucs "音訊檔地址" -o "輸出檔案目錄" -n mdx_extra --two-stems=vocals
生成後輸出檔案目錄有兩個檔案,一個是人聲,一個是背景音

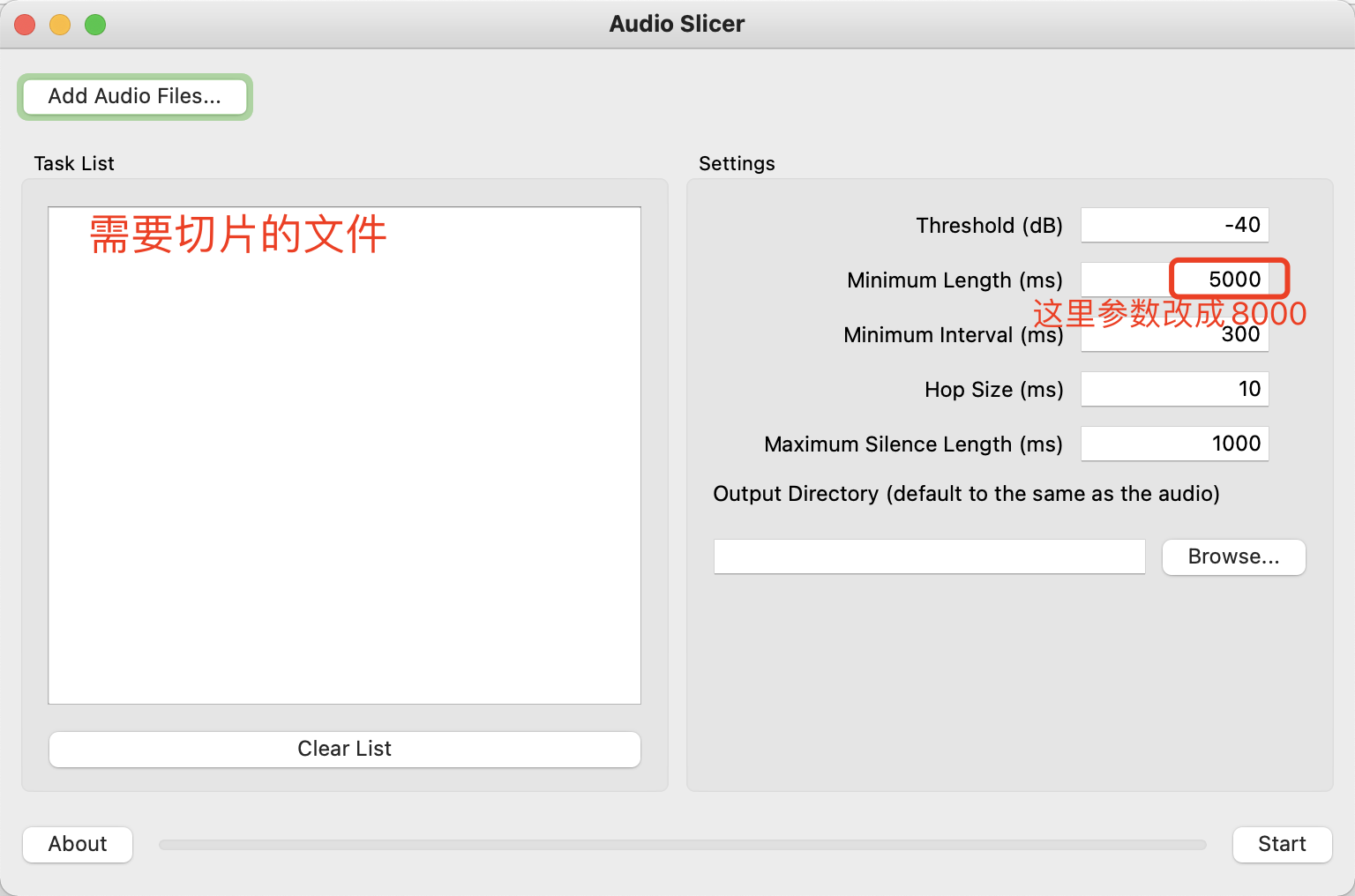
把所有的音訊檔都進行人聲分離後,接下來就要對音訊進行切片處理了,因為人聲素材檔案的大小過大會影響模型訓練的速度,所以我們還需要對其切片,將它變成一個比較小的人聲切片檔案。這裡使用的工具是 audio-slicer
https://github.com/openvpi/audio-slicer
git clone https://github.com/flutydeer/audio-slicer.git cd ./audio-slicer pip install -r requirements.txt python ./slicer-gui.py
二、模型訓練
模型訓練主要是使用的是 https://github.com/svc-develop-team/so-vits-svc/tree/4.1-Stable
你可以在自己的顯示卡上訓練,也可以在雲端上進行鍛鍊。因為我本機電腦的顯示卡不行,所以使用雲端的伺服器來進行訓練。參考了很多教學,感覺很多博主都推薦 AutoDL 這個平臺,所以我們也使用這個,避免走彎路~
這裡租用一臺 v100 的算力伺服器
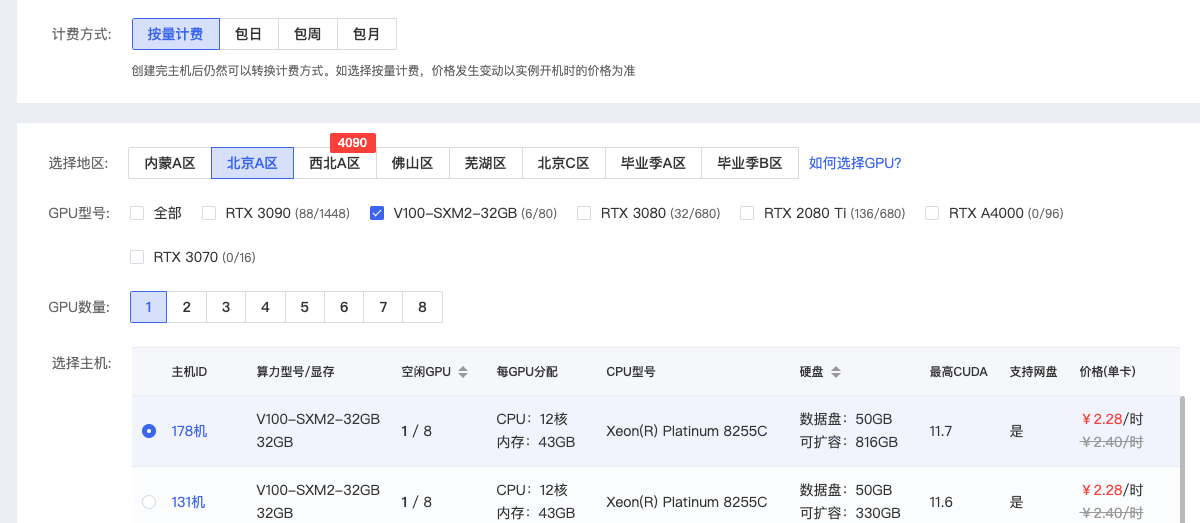
映象這裡選擇:
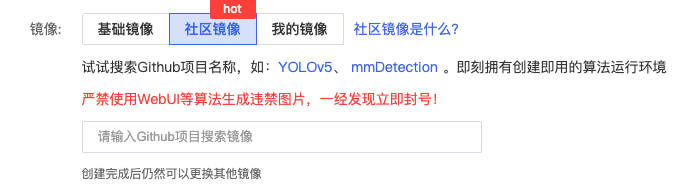
選擇 v3 或者 v4 模型都可以
買完之後進入控制檯,接下來就是使用網路硬碟把我們處理過的人聲素材匯入到範例容器中

點選「AutoPanel」進入控制檯
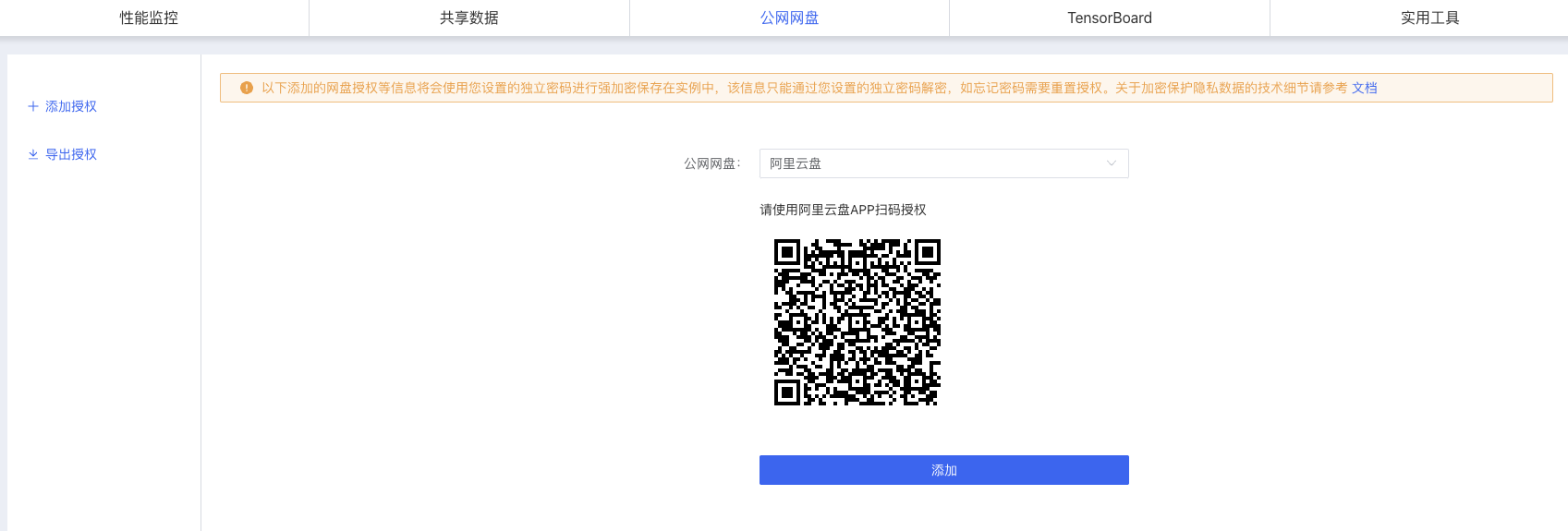

可以先把訓練資料上傳到阿里雲,在這裡用阿里雲app掃碼登入。對需要上傳到容器內的訓練集資料夾,點選下載,然後就可以自動同步到容器內的這個資料夾目錄裡的,整個過程耗時會稍微久一點。
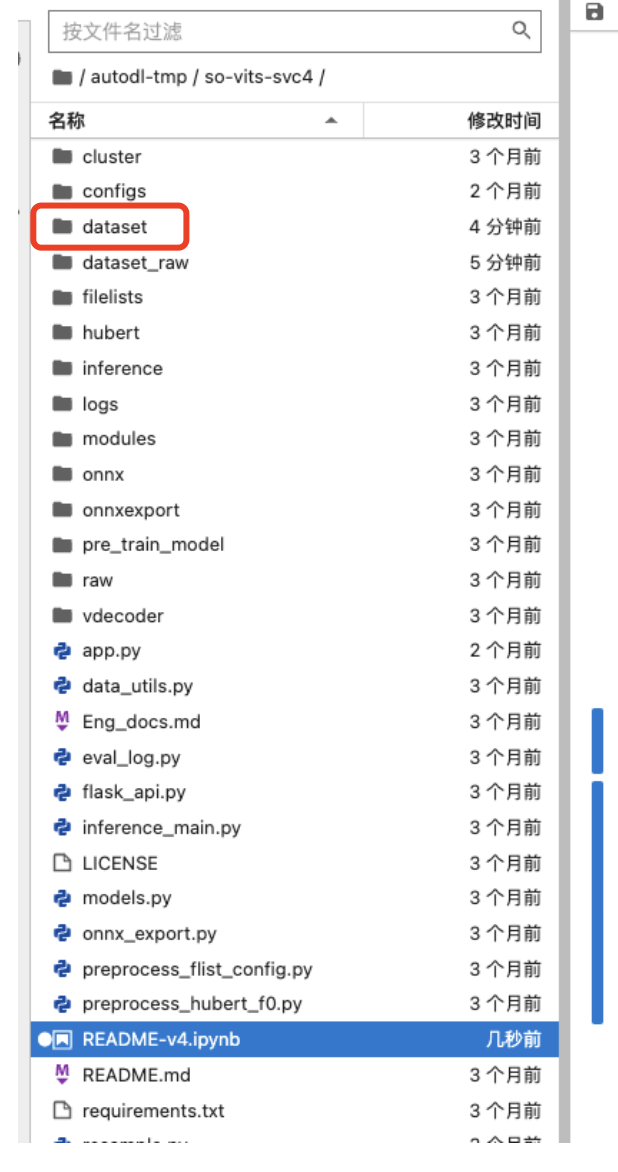
至此,我們的資料集就全部準備好了,下面就準備訓練了。
二、模型訓練
回到我們的控制檯,點選 JupyterLab 進入容器內

進入 JupyterLab 後,開啟專案內的 README-v4.ipynb ,可以看到模型作者很細緻的將模型訓練每一步都做成了視覺化操作的命令步驟解析。第一步就是我們的訓練集從 /dataset 資料夾目錄,搬運到 /dataset_raw。只需要滑鼠點選模型作者第一步 [1]: 所標識的python命令,然後點選執行按鈕即可,這個點選後需要小小等待一會,它開始執行時命令下面會有相關的輸出提示。
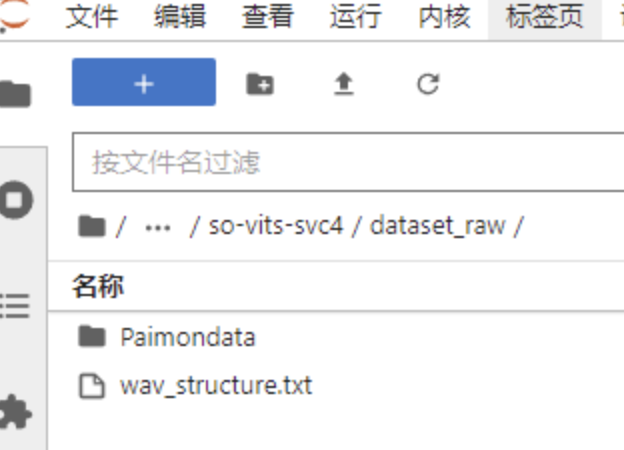
在此資料夾目錄下,資料集就安放正確了。比如你訓練資料集的資料夾名稱是 Paimondata 則會在此目錄下生成一個同樣的目錄,其實你可以直接把資料集匯入到這裡也行,不用網路硬碟。
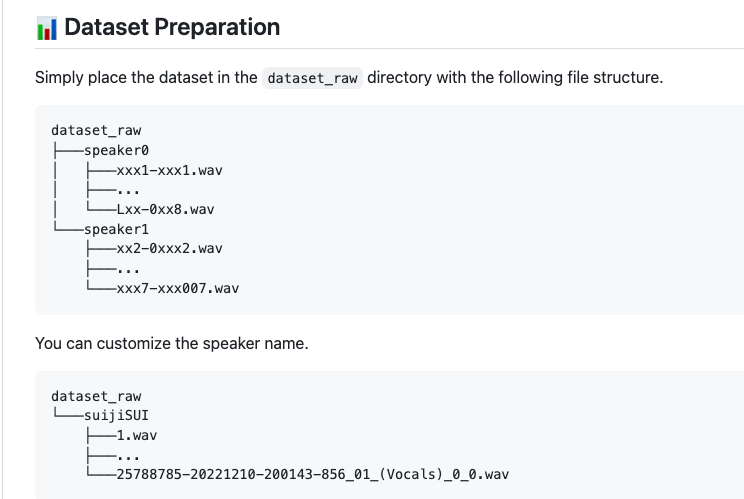
在檔案中也清楚的說明了,資料夾名稱就是你訓練的人聲名字,可以放多個你想要訓練的聲音目標
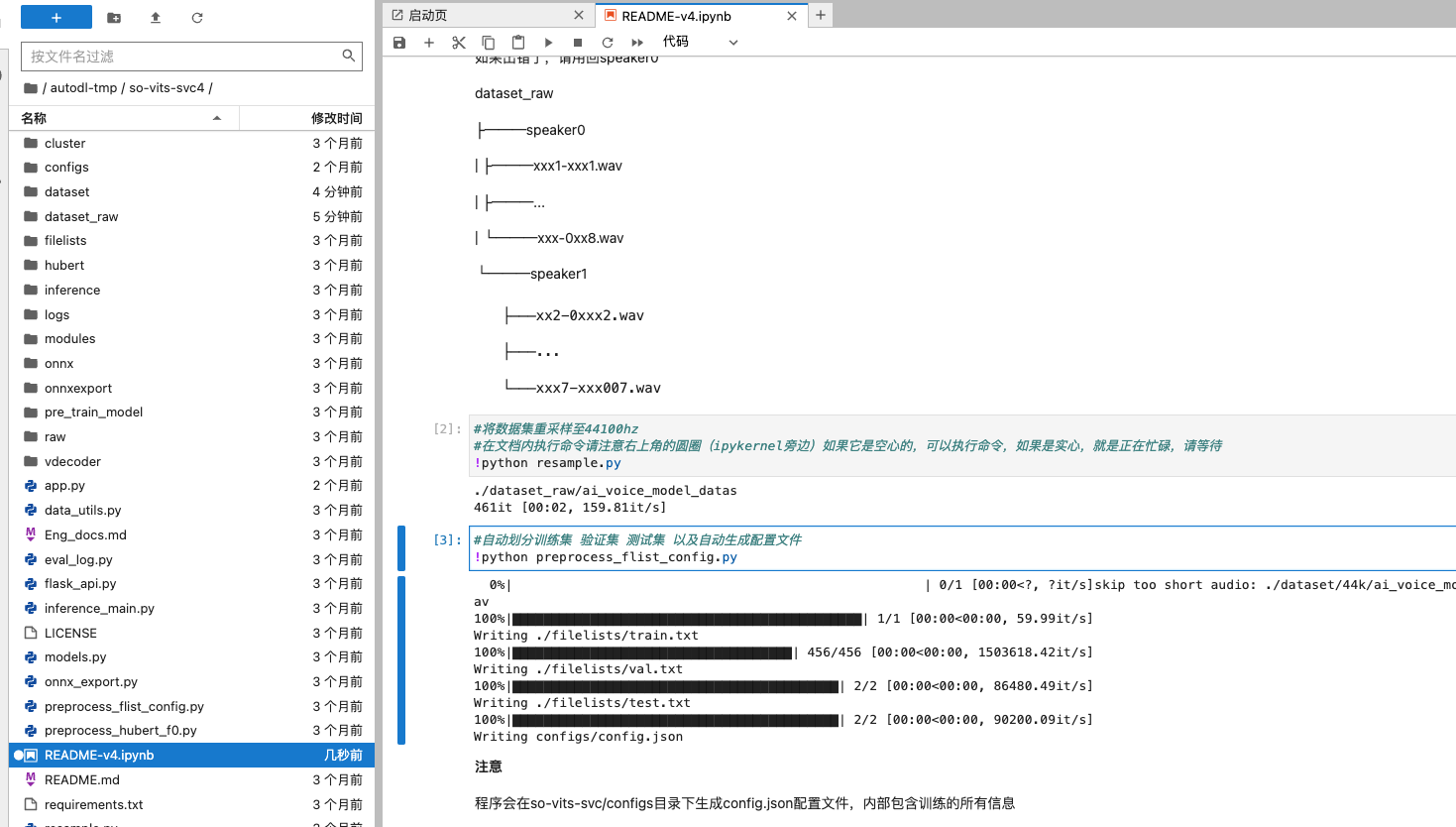
第二步就是對資料集進行取樣至 44100hz。第三步則是進行自動劃分訓練集。這兩部分也是一樣,按執行按鈕執行。
接下來就是對組態檔 /config/config.json 檔案進行設定,編輯後進行修改:把 "learning_rate"改成 0.0004,把 "batch_size"改成24,把 "keep_ckpts"改成10,然後按Ctrl+S儲存!!!
learning_rate和batch_size這兩個引數可以理解為訓練速度和訓練質量,因為我們用的V100 32G顯示卡,這塊直接固定死數值就可以,keep_ckpts是儲存多少個模型,因為聲音模型訓練是不會自動停止的,每幾千步就會給你儲存一個模型,所以我們可以讓他自動儲存最新的10個模型讓我們來選一個最好的。
接著需要生成 hubert 和 f0,這裡是後面推理的時候新增的輔助選項,為了修飾推理出來的音訊更加順滑
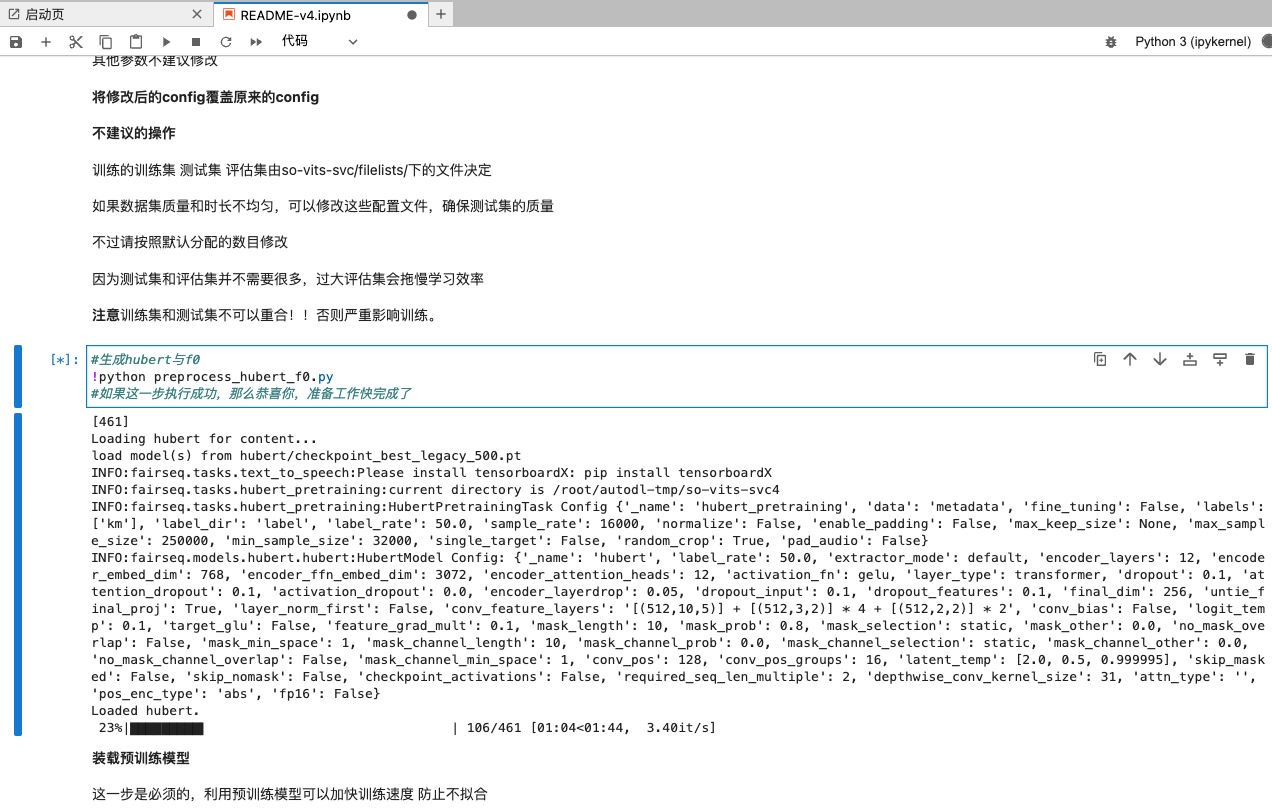
如果你是第一次訓練,則無需進行清理,直接跳到訓練這一步就行了,不過在訓練這裡,按照檔案註釋的,使用終端來進行訓練命令的執行。
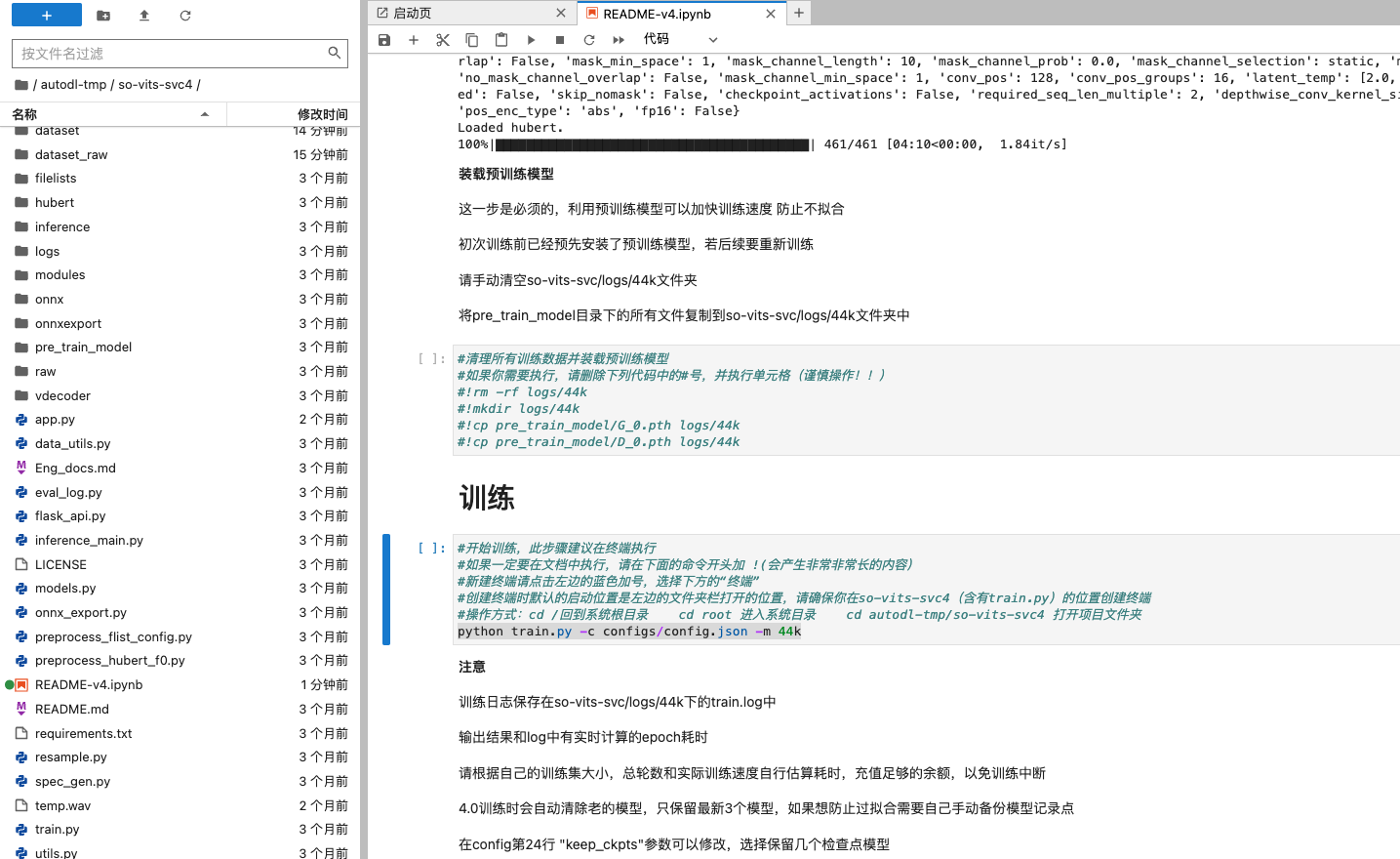
注意一下,這裡需要在專案的當前目錄才能執行,如果不是專案目錄可以
cd ~/autodl-tmp/so-vite-svc
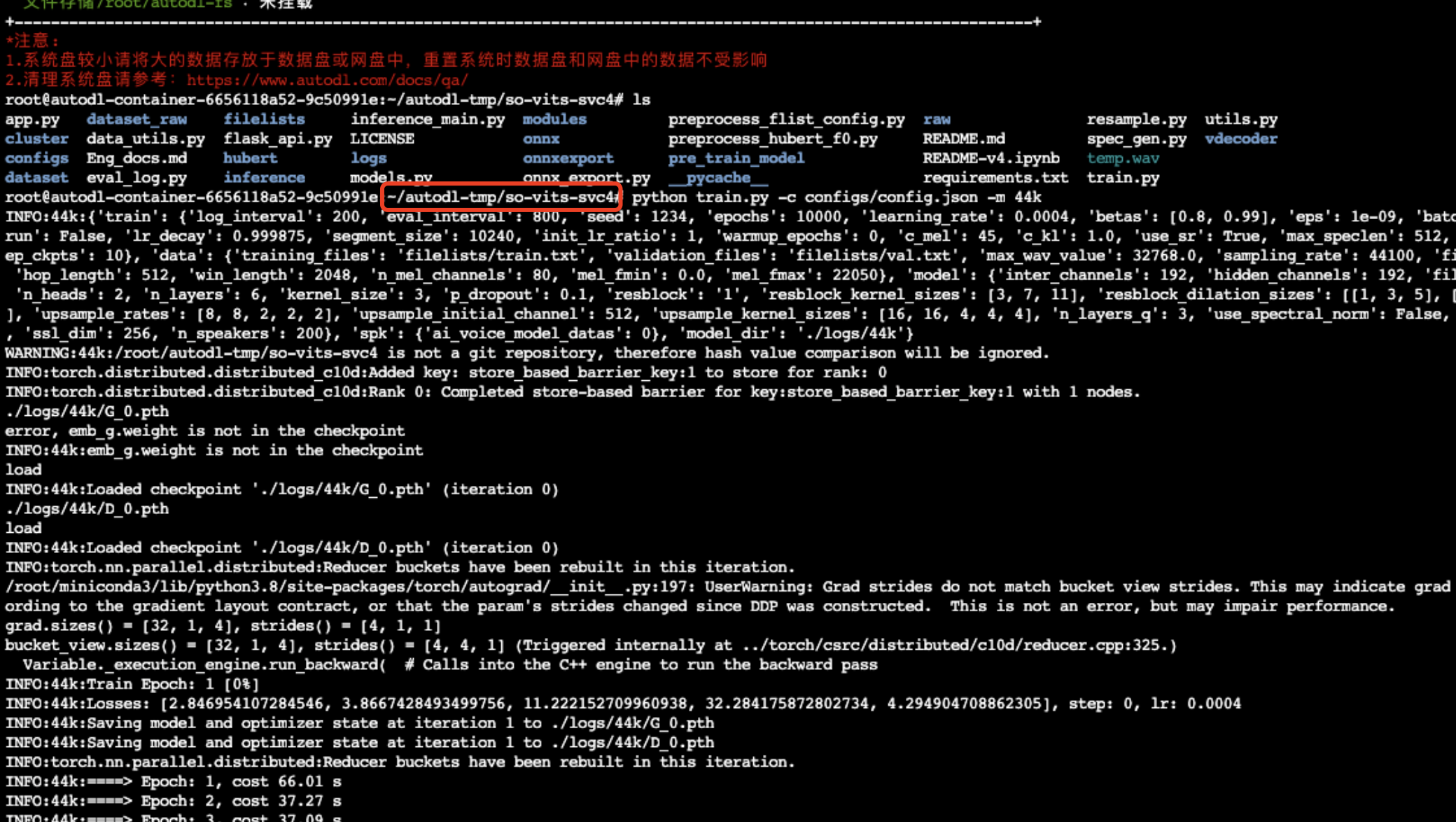
出現紀錄檔後就說明開始訓練了,可以看到每訓練200步,train.log 紀錄檔就記錄相關的紀錄檔,也就是控制檯中的輸出。沒當800步的時候就會儲存一個模型,工程會預設儲存最新的十個模型,模型目錄如下
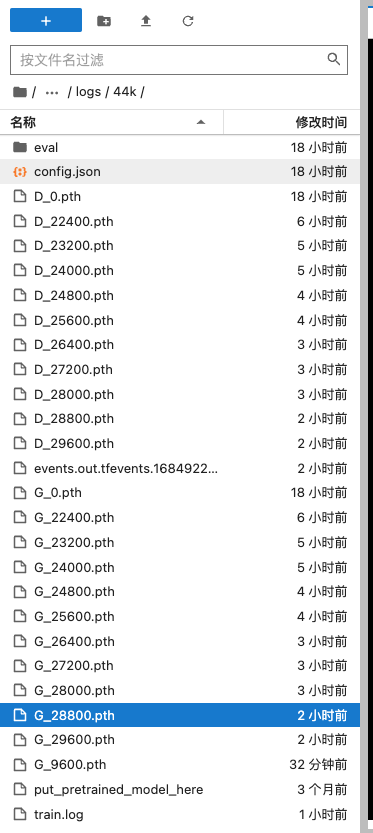
然後我們可以等待它的模型了,一般達到10000步的時候效果會比較好一些,這個過程差不多五個小時,這時候咱們可以去吃飯喝茶遛彎幹別的事情了,哪怕關掉電腦都行,訓練命令並不會因為與 autodl 的網頁連線中斷而停止,所以不用擔心。
三、聲音推理
python inference_main.py -m "logs/44k/G_{模型編號}.pth" -c "configs/config.json" -n {raw目錄下需要轉換的人聲檔名} -t 0 -s {上面你資料訓練集的資料夾名稱也就是檔案裡的speaker name}
關於推理引數,檔案有很詳細的描述
#用指令碼推理 !python inference_main.py #推理結果會存放在so-vits-svc/results資料夾 #如果不編輯推理指令碼,引數直接附加在上面的指令後 #如 !python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json"... #每個引數需要用""括起來 #必填引數 #-m, --model_path:模型路徑。 #-c, --config_path:組態檔路徑。 #-n, --clean_names:wav 檔名列表,放在 raw 資料夾下。 #-t, --trans:音高調整,支援正負(半音)。 #-s, --spk_list:合成目標說話人名稱。 #可填引數 #-a, --auto_predict_f0:語音轉換自動預測音高,轉換歌聲時不要開啟這個會嚴重跑調。 #-cm, --cluster_model_path:聚類模型路徑,如果沒有訓練聚類則隨便填。 #-cr, --cluster_infer_ratio:聚類方案佔比,範圍 0-1,若沒有訓練聚類模型則填 0 即可。
所有的推理產出都在 result 資料夾中
最後的最後讓我們一起來聽一下成片吧~~~
連結: https://pan.baidu.com/s/1lwCvlZc91UYmPmtICksLIQ 提取碼: dezw