輔助生成:低延遲文字生成的新方向
大型語言模型如今風靡一時,許多公司投入大量資源來擴充套件它們規模並解鎖新功能。然而,作為注意力持續時間不斷縮短的人類,我們並不喜歡大模型緩慢的響應時間。由於延遲對於良好的使用者體驗至關重要,人們通常使用較小的模型來完成任務,儘管它們的質量較低 (例如 程式碼補全任務)。
為什麼文字生成這麼慢?是什麼阻止你在不破產的情況下部署低延遲大型語言模型?在這篇博文中,我們將重新審視自迴歸文字生成的瓶頸,並介紹一種新的解碼方法來解決延遲問題。你會發現,通過使用我們的新的輔助生成方法,你可以將硬體中的延遲降低多達 10 倍!
理解文字生成延遲
文字生成的核心很容易理解。讓我們看看核心部分 (即 ML 模型),它的輸入包含一個文字序列,其中包括到目前為止生成的文字,以及其他特定於模型的元件 (例如 Whisper 還有一個音訊輸入)。該模型接受輸入並進行前向傳遞: 輸入被喂入模型並一層一層順序傳遞,直到預測出下一個 token 的非標準化對數概率 (也稱為 logits)。一個 token 可能包含整個詞、子詞,或者是單個字元,這取決於具體模型。如果你想深入瞭解文字生成的原理,GPT-2 插圖 是一個很好的參考。
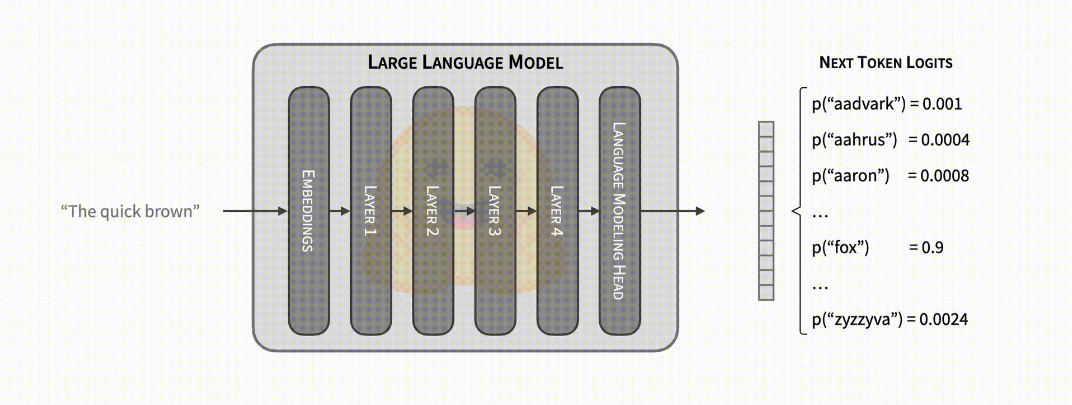
模型的前向傳遞提供了下一個 token 的概率,你可以自由操作 (例如,將不需要的單詞或序列的概率設定為 0)。文字生成的步驟就是從這些概率中選擇下一個 token。常見的策略包括選擇最有可能的 token (貪心解碼),或從它們的分佈中抽樣 (多項式抽樣)。在選擇了下一個 token 之後,我們將模型前向傳遞與下一個 token 迭代地連線起來,繼續生成文字。這個解釋只是解碼方法的冰山一角; 請參閱我們 關於文字生成的部落格 以進行深入探索。
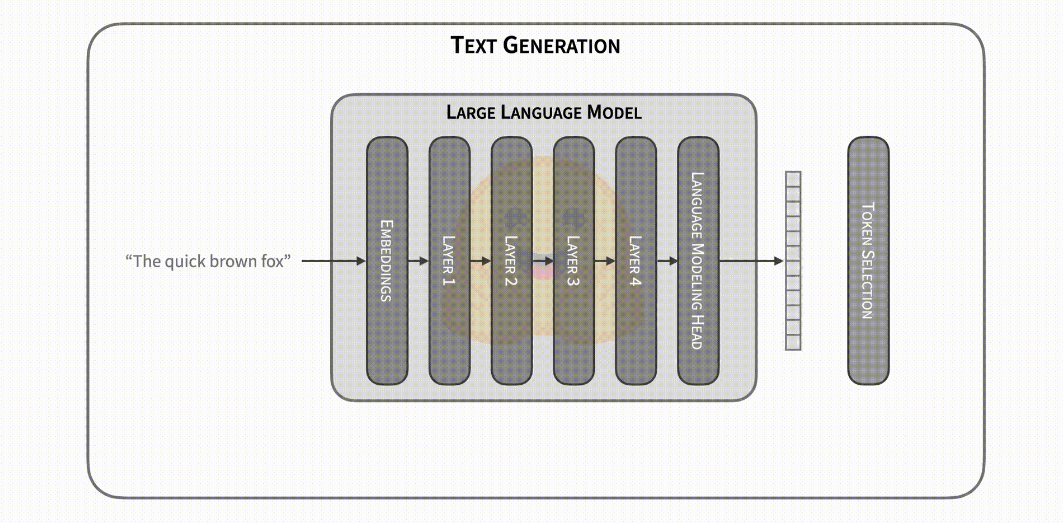
從上面的描述中可以看出,文字生成的延遲瓶頸很明顯: 執行大型模型的前向傳遞很慢,你可能需要依次執行數百次迭代。但讓我們深入探討一下: 為什麼前向傳遞速度慢?前向傳遞通常以矩陣乘法為主,通過查閱相應的 維基百科,你可以看出記憶體頻寬是此操作的限制 (例如,從 GPU RAM 到 GPU 計算核心)。換句話說, 前向傳遞的瓶頸來自將模型權過載入到裝置的計算核心中,而不是來自執行計算本身。
目前,你可以探索三個主要途徑來充分理解文字生成,所有這些途徑都用於解決模型前向傳遞的效能問題。首先,對於特定硬體的模型優化。例如,如果你的裝置可能與 Flash Attention 相容,你可以使用它通可以過重新排序操作或 INT8 量化 來加速注意力層,其減少了模型權重的大小。
其次,如果你有並行文字生成需求,你可以對輸入進行批次處理,從而實現較小的延遲損失並大幅增加吞吐量。你可以將模型對於多個輸入平行計算,這意味著你將在大致相同的記憶體頻寬負擔情況下獲得了更多 token。批次處理的問題在於你需要額外的裝置記憶體 (或在某處解除安裝記憶體)。你可以看到像 FlexGen 這樣的專案以延遲為代價來優化吞吐量。
# Example showcasing the impact of batched generation. Measurement device: RTX3090
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2").to("cuda")
inputs = tokenizer(["Hello world"], return_tensors="pt").to("cuda")
def print_tokens_per_second(batch_size):
new_tokens = 100
cumulative_time = 0
# warmup
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
for _ in range(10):
start = time.time()
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
cumulative_time += time.time() - start
print(f"Tokens per second: {new_tokens * batch_size * 10 / cumulative_time:.1f}")
print_tokens_per_second(1) # Tokens per second: 418.3
print_tokens_per_second(64) # Tokens per second: 16266.2 (~39x more tokens per second)
最後,如果你有多個可用裝置,你可以使用 Tensor 並行 分配工作負載並獲得更低的延遲。使用 Tensor 並行,你可以將記憶體頻寬負擔分攤到多個裝置上,但除了在多個裝置執行計算的成本之外,你還需要考慮裝置間的通訊瓶頸。該方法的收益在很大程度上取決於模型大小: 對於可以輕鬆在單個消費級裝置上執行的模型,通常效果並不顯著。根據這篇 DeepSpeed 部落格,你會發現你可以將大小為 17B 的模型分佈在 4 個 GPU 上,從而將延遲減少 1.5 倍 (圖 7)。
這三種型別的改進可以串聯使用,從而產生 高通量解決方案。然而,在應用特定於硬體的優化後,降低延遲的方法有限——並且現有的方法很昂貴。讓我們接下來解決這個問題!
重新回顧語言模型解碼器的正向傳播
上文我們講到,每個模型前向傳遞都會產生下一個 token 的概率,但這實際上是一個不完整的描述。在文字生成期間,典型的迭代包括模型接收最新生成的 token 作為輸入,加上所有其他先前輸入的快取內部計算,再返回下一個 token 得概率。快取用於避免冗餘計算,從而實現更快的前向傳遞,但它不是強制性的 (並且可以設定部分使用)。禁用快取時,輸入包含到目前為止生成的整個 token 序列,輸出包含 _所有位置_的下一個 token 對應的概率分佈!如果輸入由前 N 個 token 組成,則第 N 個位置的輸出對應於其下一個 token 的概率分佈,並且該概率分佈忽略了序列中的所有後續 token。在貪心解碼的特殊情況下,如果你將生成的序列作為輸入傳遞並將 argmax 運運算元應用於生成的概率,你將獲得生成的序列。
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
inputs = tok(["The"], return_tensors="pt")
generated = model.generate(**inputs, do_sample=False, max_new_tokens=10)
forward_confirmation = model(generated).logits.argmax(-1)
# We exclude the opposing tips from each sequence: the forward pass returns
# the logits for the next token, so it is shifted by one position.
print(generated[:-1].tolist() == forward_confirmation[1:].tolist()) # True
這意味著你可以將模型前向傳遞用於不同的目的: 除了提供一些 token 來預測下一個標記外,你還可以將序列傳遞給模型並檢查模型是否會生成相同的序列 (或部分相同序列)。
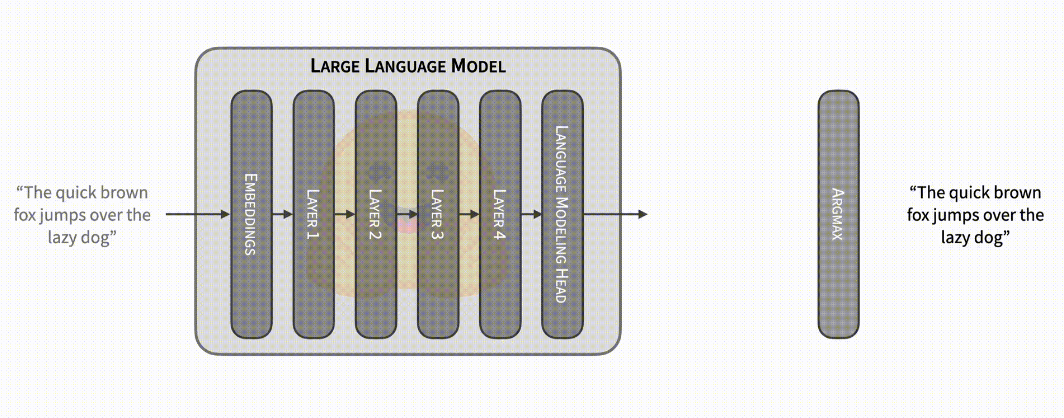
(請存取閱讀原文檢視動態演示)
讓我們想象,你可以存取一個神奇的無延遲的預測輔助模型,該模型針對任何給定輸入生成與你的模型相同的序列。順便說一句,這個模型不能直接用,只能輔助你的生成程式。使用上述屬性,你可以使用此輔助模型獲取候選輸出 token,然後使用你的模型進行前向傳遞以確認它們的正確性。在這個烏托邦式的場景中,文字生成的延遲將從 O(n) 減少到 O(1),其中生成的 token 數量為 n。對於需要多次迭代生成的過程,我們談論的是其數量級。
向現實邁出一步,我們假設輔助模型失去了它的預測屬性。根據你的模型,現在它是一個無延遲模型,但它會弄錯一些候選 token。由於任務的自迴歸性質,一旦輔助模型得到一個錯誤的 token,所有後續候選 token 都必須無效。但是,你可以使用模型更正錯誤 token 並反覆重複此過程後再次查詢輔助模型。即使輔助模型失敗了幾個 token,文字生成的延遲也會比原始形式小得多。
顯然,世界上沒有無延遲的輔助模型。然而,找到一個近似於模型的文字生成輸出的其它模型相對容易,例如經過類似訓練的相同架構的較小版本模型通常符合此需求。當模型大小的差異變得顯著時,使用較小的模型作為輔助模型的成本在跳過幾個前向傳遞後就顯得無關緊要了!現在,你瞭解了 _ 輔助生成 _ 的核心。
使用輔助模型的貪心解碼
輔助生成是一種平衡行為。你希望輔助模型快速生成候選序列,同時儘可能準確。如果輔助模型的質量很差,你將承擔使用輔助模型的成本,而收益卻很少甚至沒有。另一方面,優化候選序列的質量可能意味著使用更慢的輔助模型,從而導致網路減速。雖然我們無法為你自動選擇輔助模型,但我們包含了一個額外的要求和一個啟發式方法,以確保模型與輔助模型一起花費的時間保持在可控範圍內。
首先,我們要求輔助模型必須具有與你的模型完全相同的分詞器。如果沒有此要求,則必須新增昂貴的 token 解碼和重新編碼步驟。此外,這些額外的步驟必須在 CPU 上進行,這反過來可能增加了裝置間資料傳輸。能夠快速地使用輔助模型對於輔助生成的好處是至關重要的。
最後,啟發式。至此,你可能已經注意到電影盜夢空間和輔助生成之間的相似之處——畢竟你是在文字生成中執行文字生成。每個候選 token 有一個輔助模型前向傳播,我們知道前向傳播是昂貴的。雖然你無法提前知道輔助模型將獲得的 token 數量,但你可以跟蹤此資訊並使用它來限制向輔助模型請求的候選 token 數量——輸出的某些部分比其它一些部分更容易被預計。
總結一下,這是我們最初實現的輔助生成的迴圈 (程式碼):
- 使用貪心解碼與輔助模型生成一定數量的
候選 token。當第一次呼叫輔助生成時,生成的候選 token的數量被初始化為5。 - 使用我們的模型,對
候選 token進行前向計算,獲得每個 token 對應的概率。 - 使用 token 選擇方法 (使用
.argmax()進行貪心搜尋或使用.multinomial()用於取樣方法) 來從概率中選取next_tokens。 - 比較步驟 3 中選擇的
next_tokens和候選 token中相同的 token 數量。請注意,我們需要從左到右進行比較, 在第一次不匹配後,後續所有候選 token都無效。5. 使用步驟 4 得到的匹配數量將候選 token分割。也就是,將輸入 tokens 加上剛剛驗證得到的正確的 tokens。 - 調整下一次迭代中生成的
候選 token的數量 —— 使用啟發式方法,如果步驟 3 中所有 token 都匹配,則候選 token的長度增加2,否則減少1。
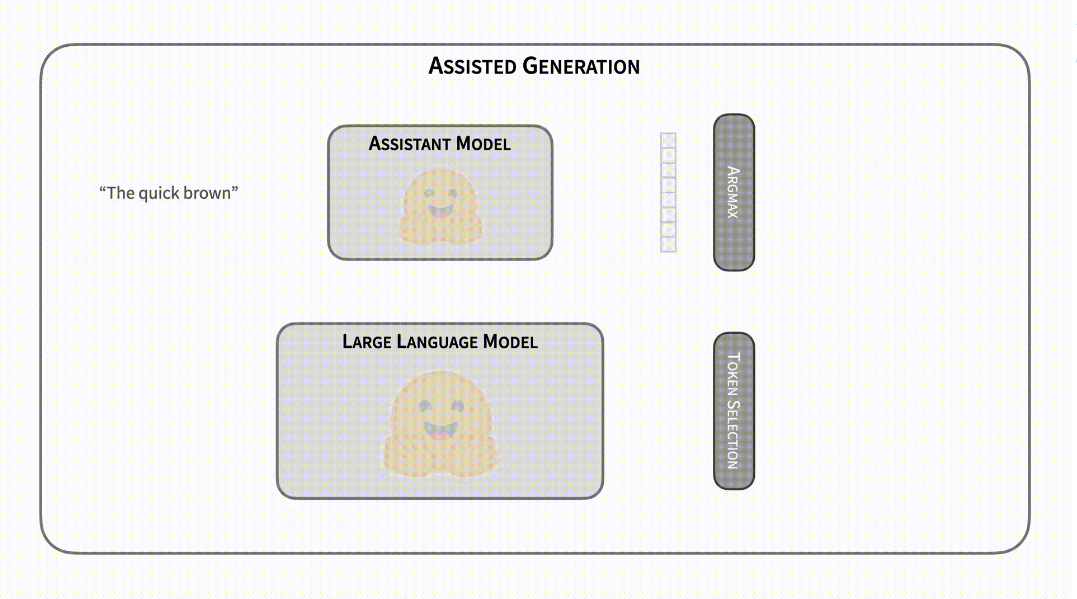
(請存取閱讀原文檢視動態演示)
我們在