教你1分鐘搞定2小時字幕
摘要:本文將介紹如何使用錄音檔案識別極速版給無字幕視訊自動生成字幕。
本文分享自華為雲社群《利用錄音檔案極速版為視訊生成字幕》,作者:戈兀。
引言
越來越多的人們使用抖音、B站等視訊app,記錄、分享日常生活,隨之網際網路上產生了大量的長、短視訊。字幕是影響視訊觀看體驗的重要因素。以日常分享為主的視訊創作者往往沒有時間為視訊製作字幕,在創作者發音不清楚的前提下,沒有字幕的視訊可能會讓觀眾困惑甚至產生理解偏差。而帶字幕的視訊讓觀眾有更好的觀看體驗,「一氣呵成」順暢地看完。
語音識別技術(Automatic Speech Recognition)是一種將人的語音轉換為文字的技術。隨著深度學習的發展,端到端語音識別技術也取得了巨大的突破。將原始的音訊資料,經過分幀、加窗、FFT等操作後,得到描述音訊在時、頻域資訊的梅爾特徵或是Fbank特徵。將特徵送入transformer等神經網路,輸出對應的文字資訊。此外,由大量文字訓練的語言模型(language model)能夠糾正語音識別輸出文字不通順的問題,改善閱讀體驗。而熱詞技術也被用來解決語音識別的領域適配問題,如同音不同字。
本文將介紹如何使用錄音檔案識別極速版給無字幕視訊自動生成字幕。
錄音檔案識別極速版採用同步介面,利用GPU加速模型的推理過程。對於兩個小時內的音、視訊檔,可以在1分鐘內返回識別結果,滿足準實時字幕、音訊質檢等對識別速度有要求的場景。感興趣的讀者可以點選錄音檔案識別極速版檔案,瞭解詳情。
注:本文同步釋出至華為雲AI Gallery Notebook,可以在AI Gallery上執行:利用錄音檔案極速版為視訊生成字幕
原理講解
給無字幕視訊生成字幕,就是從視訊中的提取音訊流,將音訊流送入錄音檔案識別極速版,得到識別文字,和對應的時間戳資訊。然後將其轉換為視訊字幕檔案格式,如srt檔案。得到srt字幕檔案後,在播放視訊時,載入字幕檔案,就可以看到字幕了。
因此,整個流程如下:
1、利用ffmpeg工具,從視訊中提取音訊流
2、設定適合的引數,使用錄音檔案識別極速版,催音訊檔進行識別
3、對識別結果,包括文字和時間戳資訊,進行處理,得到視訊字幕檔案
4、將命名相同的視訊檔與 srt 檔案放在同一目錄下,用播放器開啟,即可得到有字幕的視訊。或者利用ffmpeg,以硬字幕的形式,將字幕嵌入到視訊中。
注:SRT(SubRip 檔案格式)是以 SubRip 檔案格式儲存的簡單字幕檔案,擴充套件名為 .srt。每個字幕在 SRT 檔案中有四個部分:
- 指示字幕編號或位置的數位計數器;
- 字幕的開始和結束時間;
- 一行或多行的字幕文字;
- 表示字幕結束的空行。
程式碼開發
步驟一:提取音訊流
採用ffmpeg從視訊檔中提取音訊流,並儲存為音訊檔output.wav
ffmpeg -i input.mp4 -ar 16000 -ac 1 output.wav
-ar指定儲存音訊檔的取樣率,這裡16000表示1秒鐘,儲存16000個取樣點資料;-ac指定儲存音訊的通道數,這裡1表示儲存為單通道音訊。
步驟二:安裝語音識別python SDK
在安裝python3後,用pip安裝其他依賴依賴包
pip install setuptools
pip install requests
pip install websocket-client
下載最新版python sdk原始碼:https://sis-sdk-repository.obs.cn-north-1.myhuaweicloud.com/python/huaweicloud-python-sdk-sis-1.8.1.zip
進入下載的Python SDK目錄,在setup.py所在層目錄執行 python setup.py install 命令,完成SDK安裝。
步驟三:呼叫錄音檔案極速版
- 匯入依賴包
from huaweicloud_sis.client.flash_lasr_client import FlashLasrClient from huaweicloud_sis.bean.flash_lasr_request import FlashLasrRequest from huaweicloud_sis.exception.exceptions import ClientException from huaweicloud_sis.exception.exceptions import ServerException from huaweicloud_sis.bean.sis_config import SisConfig import json
- 初始化使用者端
config = SisConfig() config.set_connect_timeout(50) config.set_read_timeout(50) client = FlashLasrClient(ak=ak, sk=sk, region=region, project_id=project_id, sis_config=config)
- 構造請求
asr_request = FlashLasrRequest() asr_request.set_obs_bucket_name(obs_bucket_name) # 設定存放音訊的桶名,必選 asr_request.set_obs_object_key(obs_object_key) # 設定OBS桶中的物件的鍵值,必選 asr_request.set_audio_format(audio_format) # 音訊格式,必選 asr_request.set_property(property) # property,比如:chinese_16k_conversation asr_request.set_add_punc('yes') asr_request.set_digit_norm('no') asr_request.set_need_word_info('yes') asr_request.set_first_channel_only('yes')
為視訊產生字幕檔案時,不僅需要文字,也需要文字對應的時間戳資訊。當一句話過長,螢幕無法完整顯示時,就需要對這句話進行切分。因此,僅僅根據每個句子的起始和截止時間,無法準確的確定切分後兩句話的起始和截止時間。因此我們需要字級別的時間資訊。而將need_word_info設定為‘yes’,就可以輸出字級別的時間戳資訊。如下:
"word_info": [ { "start_time": 590, "word": "哎", "end_time": 630 }, { "start_time": 830, "word": "大", "end_time": 870 }, { "start_time": 950, "word": "家", "end_time": 990 }, { "start_time": 1110, "word": "好", "end_time": 1150 }, ]
- 接下里傳送識別請求
result = client.get_flash_lasr_result(asr_request)
- 拿到帶有詳細時間戳資訊的識別結果result:
"result": { "score": 0.9358551502227783, "word_info": [ { "start_time": 590, "word": "哎", "end_time": 630 }, { "start_time": 830, "word": "大", "end_time": 870 }, { "start_time": 950, "word": "家", "end_time": 990 }, { "start_time": 1110, "word": "好", "end_time": 1150 }, { "start_time": 1750, "word": "我", "end_time": 1790 }, { "start_time": 1910, "word": "是", "end_time": 1950 }, { "start_time": 2070, "word": "你", "end_time": 2110 }, { "start_time": 2190, "word": "們", "end_time": 2230 }, { "start_time": 2350, "word": "的", "end_time": 2390 }, { "start_time": 2870, "word": "音", "end_time": 2910 }, { "start_time": 3030, "word": "樂", "end_time": 3070 }, { "start_time": 3190, "word": "老", "end_time": 3230 }, { "start_time": 3350, "word": "師", "end_time": 3390 }, { "start_time": 3590, "word": "康", "end_time": 3630 }, { "start_time": 3750, "word": "老", "end_time": 3790 }, { "start_time": 3950, "word": "師", "end_time": 3990 }, { "start_time": 4830, "word": "那", "end_time": 4870 }, { "start_time": 4990, "word": "麼", "end_time": 5030 }, { "start_time": 5350, "word": "這", "end_time": 5390 }, { "start_time": 5550, "word": "幾", "end_time": 5590 }, { "start_time": 5750, "word": "系", "end_time": 5790 }, { "start_time": 5870, "word": "列", "end_time": 5910 }, { "start_time": 6070, "word": "呢", "end_time": 6110 }, { "start_time": 6310, "word": "我", "end_time": 6350 }, { "start_time": 6390, "word": "們", "end_time": 6470 }, { "start_time": 6510, "word": "來", "end_time": 6550 }, { "start_time": 6670, "word": "到", "end_time": 6710 }, { "start_time": 6830, "word": "了", "end_time": 6870 }, { "start_time": 7430, "word": "發", "end_time": 7470 }, { "start_time": 7630, "word": "聲", "end_time": 7670 }, { "start_time": 7830, "word": "練", "end_time": 7870 }, { "start_time": 8030, "word": "習", "end_time": 8070 }, { "start_time": 8950, "word": "三", "end_time": 8990 }, { "start_time": 9190, "word": "十", "end_time": 9230 }, { "start_time": 9350, "word": "五", "end_time": 9390 }, { "start_time": 9470, "word": "講", "end_time": 9510 } ], "text": "哎,大家好,我是你們的音樂老師康老師。那麼這幾系列呢,我們來到了發聲練習三十五講。" }, "start_time": 510, "end_time": 9640 }
步驟四:將識別結果轉為srt字幕格式檔案
由於視訊播放介面的寬度有限,當一句話包含的文字數過多時,會存在一行放不下的問題。因此我們在生成srt檔案時,需要將文字數量過長的一句話切分為兩句話,分別在不同的時間段顯示。企切分後的第一句話的起始時間不變,截止時間為最後一個字的截止時間;第二句話的起始時間為第一個字的起始時間,截止時間不變。這樣就保證切分後兩句話的時間戳也是正確的,進而在合適的視訊幀中顯示正確的文字內容。
def json2srt(json_result): results = "" count = 1 max_word_in_line = 15 min_word_in_line = 3 punc = ["。", "?", "!", ","] segments = json_result['flash_result'][0]['sentences'] for i in range(len(segments)): current_result = segments[i] current_sentence = current_result["result"]["text"] if len(current_result["result"]["word_info"]) > max_word_in_line: srt_result = "" srt_result_len = 0 current_segment = "" cnt = 0 start = True for i in range(len(current_sentence)): if current_sentence[i] not in punc: if start: start_time = current_result["result"]["word_info"][cnt]['start_time'] start = False else: end_time = current_result["result"]["word_info"][cnt]['end_time'] current_segment += current_sentence[i] srt_result_len += 1 cnt += 1 else: if srt_result_len < min_word_in_line: srt_result += current_segment + current_sentence[i] current_segment = "" else: srt_result += current_segment + current_sentence[i] current_segment = "" start_time = time_format(start_time) end_time = time_format(end_time) if srt_result[-1] == ",": srt_result = srt_result[:-1] results += str(count) + "\n" + start_time + "-->" + end_time + "\n" + srt_result + "\n" + "\n" count += 1 start = True srt_result = "" else: start_time = time_format(current_result["start_time"]) end_time = time_format(current_result["end_time"]) if current_sentence[-1] == ",": current_sentence = current_sentence[:-1] results += str(count) + "\n" + start_time + "-->" + end_time + "\n" + current_sentence + "\n" + "\n" count += 1 return results
得到srt格式的字幕檔案
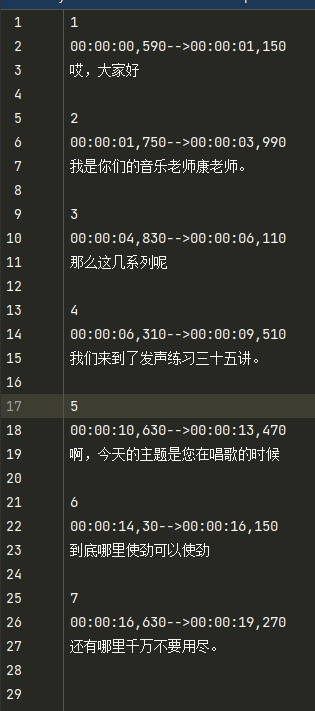
步驟五:播放視訊,載入字幕
修改檔名,保證srt檔案和原始視訊檔命名相同,然後用播放器播放視訊:
步驟六:使用ffmpeg給視訊新增硬字幕(可選)
ffmpeg -i input.mp4 -vf subtitles=subtitle.srt output_srt.mp4
注: 硬字幕是將字幕渲染到視訊的紋理上,然後將其編碼成獨立於視訊格式的一個完整視訊。硬字幕與視訊是一個整體,不能更改或刪除。