萬字長文詳述ClickHouse在京喜達實時資料的探索與實踐
1 前言
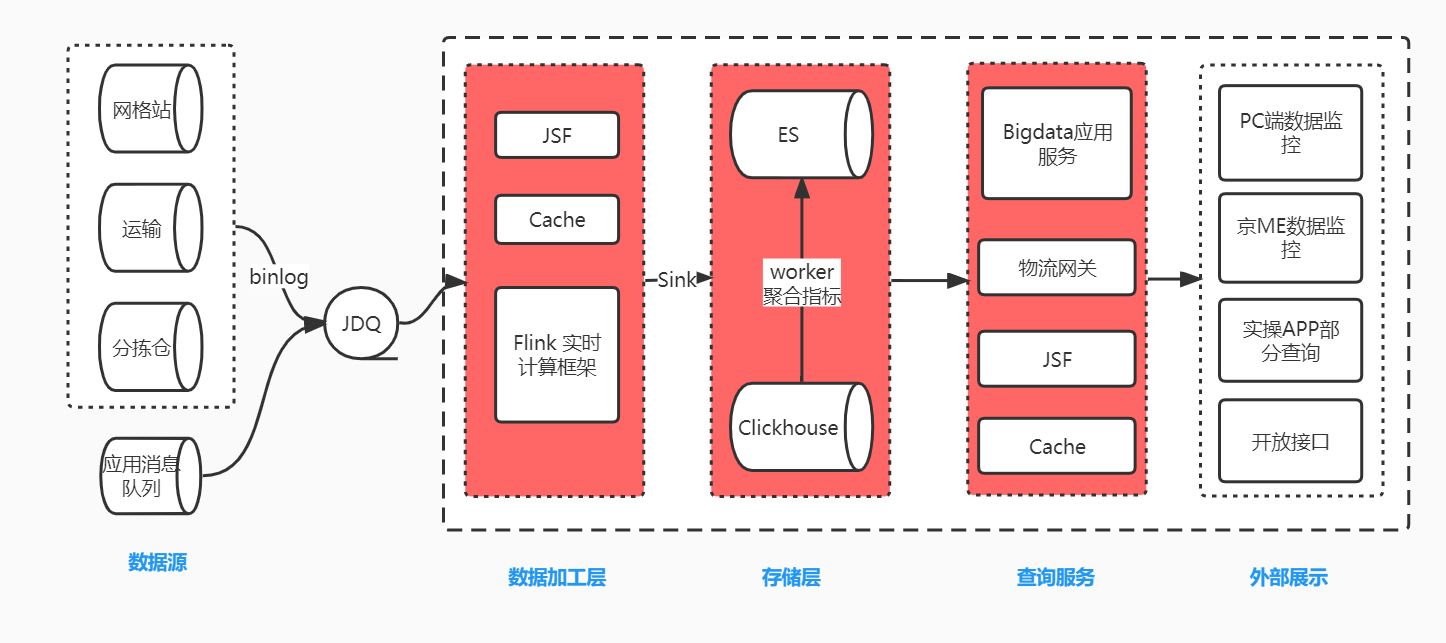
京喜達技術部在社群團購場景下采用JDQ+Flink+Elasticsearch架構來打造實時資料包表。隨著業務的發展 Elasticsearch開始暴露出一些弊端,不適合大批次的資料查詢,高頻次深度分頁匯出導致ES宕機、不能精確去重統計,多個欄位聚合計算時效能下降明顯。所以引入ClickHouse來處理這些弊端。
資料寫入鏈路是業務資料(binlog)經過處理轉換成固定格式的MQ訊息,Flink訂閱不同Topic來接收不同生產系統的表資料,進行關聯、計算、過濾、補充基礎資料等加工關聯彙總成寬表,最後將加工後的DataStream資料流雙寫入ES和ClickHouse。查詢服務通過JSF和物流閘道器對外暴露提供給外部進行展示,由於ClickHouse將所有計算能力都用在一次查詢上,所以不擅長高並行查詢。我們通過對部分實時聚合指標介面增加快取,或者定時任務查詢ClickHosue計算指標儲存到ES,部分指標不再實時查ClickHouse而是查ES中計算好的指標來抗住並行,並且這種方式能夠極大提高開發效率,易維護,能夠統一指標口徑。
在引入ClickHouse過程中經歷各種困難,耗費大量精力去探索並一一解決,在這裡記錄一下希望能夠給沒有接觸過ClickHouse的同學提供一些方向上的指引避免多走彎路,如果文中有錯誤也希望多包含給出指點,歡迎大家一起討論ClickHouse相關的話題。本文偏長但全是乾貨,請預留40~60分鐘進行閱讀。
2 遇到的問題
前文說到遇到了很多困難,下面這些遇到的問題是本文講述的重點內容。
- 我們該使用什麼表引擎
- Flink如何寫入到ClickHouse
- 查詢ClickHouse為什麼要比查詢ES慢1~2分鐘
- 寫入分散式表還是本地表
- 為什麼只有某個分片CPU使用率高
- 如何定位是哪些SQL在消耗CPU,這麼多慢SQL,我怎麼知道是哪個SQL引起的
- 找到了慢SQL,如何進行優化
- 如何抗住高並行、保證ClickHouse可用性
3 表引擎選擇與查詢方案
在選擇表引擎以及查詢方案之前,先把需求捋清楚。前言中說到我們是在Flink中構造寬表,在業務上會涉及到資料的更新的操作,會出現同一個業務單號多次寫入資料庫。ES的upsert支援這種需要覆蓋之前資料的操作,ClickHouse中沒有upsert,所以需要探索出能夠支援upsert的方案。帶著這個需求來看一下ClickHouse的表引擎以及查詢方案。
ClickHouse有很多表引擎,表引擎決定了資料以什麼方式儲存,以什麼方式載入,以及資料表擁有什麼樣的特性。目前ClickHouse表引擎一共分為四個系列,分別是Log、MergeTree、Integration、Special。
- Log系列:適用於少量資料(小於一百萬行)的場景,不支援索引,所以對於範圍查詢效率不高。
- Integration系列:主要用於匯入外部資料到ClickHouse,或者在ClickHouse中直接操作外部資料,支援Kafka、HDFS、JDBC、Mysql等。
- Special系列:比如Memory將資料儲存在記憶體,重啟後會丟失資料,查詢效能極好,File直接將本地檔案作為資料儲存等大多是為了特定場景而客製化的。
- MergeTree系列:MergeTree家族自身擁有多種引擎的變種,其中MergeTree作為家族中最基礎的引擎提供主鍵索引、資料分割區、資料副本和資料取樣等能力並且支援極大量的資料寫入,家族中其他引擎在MergeTree引擎的基礎上各有所長。
Log、Special、Integration主要用於特殊用途,場景相對有限。其中最能體現ClickHouse效能特點的是MergeTree及其家族表引擎,也是官方主推的儲存引擎,幾乎支援所有ClickHouse核心功能,在生產環境的大部分場景中都會使用此係列的表引擎。我們的業務也不例外需要使用主鍵索引,日資料增量在2500多萬的增量,所以MergeTree系列是我們需要探索的目標。
MergeTree系列的表引擎是為插入大量資料而生,資料是以資料片段的形式一個接一個的快速寫入,ClickHouse為了避免資料片段過多會在後臺按照一定的規則進行合併形成新的段,相比在插入時不斷的修改已經儲存在磁碟的資料,這種插入後合併再合併的策略效率要高很多。這種資料片段反覆合併的特點,也正是MergeTree系列(合併樹家族)名稱的由來。為了避免形成過多的資料片段,需要進行批次寫入。MergeTree系列包含MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、SummingMergeTree、AggregatingMergeTree引擎,下面就介紹下這幾種引擎。
3.1 MergeTree:合併樹
MergeTree支援所有ClickHouse SQL語法。大部分功能點和我們熟悉的MySQL是類似的,但是有些功能差異比較大,比如主鍵,MergeTree系列的主鍵並不用於去重,MySQL中一個表中不能存在兩條相同主鍵的資料,但是ClickHouse中是可以的。
下面建表語句中,定義了訂單號,商品數量,建立時間,更新時間。按照建立時間進行資料分割區,orderNo作為主鍵(primary key),orderNo也作為排序鍵(order by),預設情況下主鍵和排序鍵相同,大部分情況不需要再專門指定primary key,這個例子中指定只是為了說明下主鍵和排序鍵的關係。當然排序鍵可以與的主鍵欄位不同,但是主鍵必須為排序鍵的子集,例如主鍵(a,b), 排序鍵必須為(a,b, , ),並且組成主鍵的欄位必須在排序鍵欄位中的最左側。
CREATE TABLE test_MergeTree ( orderNo String, number Int16, createTime DateTime, updateTime DateTime) ENGINE = MergeTree()PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);insert into test_MergeTree values('1', '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00');insert into test_MergeTree values('1', '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');
注意這裡寫入的兩條資料主鍵orderNo都是1的兩條資料,這個場景是我們先建立訂單,再更新了訂單的商品數量為30和更新時間,此時業務實際訂單量為1,商品件量是30。
插入主鍵相同的資料不會產生衝突,並且查詢資料兩條相同主鍵的資料都存在。下圖是查詢結果,由於每次插入都會形成一個part,第一次insert生成了1609430400_1_1_0 資料分割區檔案,第二次insert生成了1609430400_2_2_0 資料分割區檔案,後臺還沒觸發合併,所以在clickhouse-client上的展示結果是分開兩個表格的(圖形化查詢工具DBeaver、DataGrip不能看出是兩個表格,可以通過docker搭建ClickHouse環境通過client方式執行語句,文末有搭建CK環境檔案)。
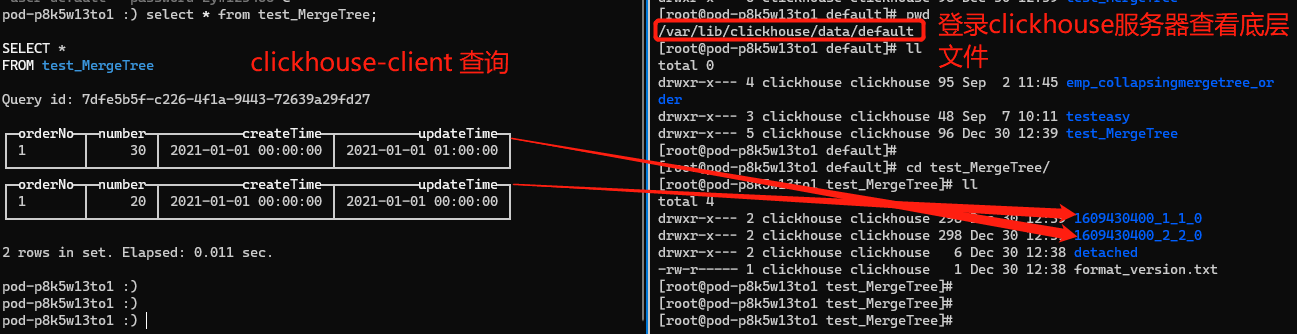
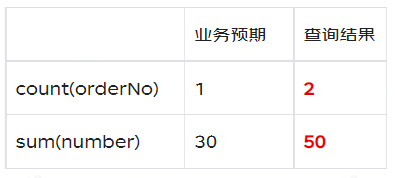
預期結果應該是number從20更新成30,updateTime也會更新成相應的值,同一個業務主鍵只存在一行資料,可是最終是保留了兩條。Clickhouse中的這種處理邏輯會導致我們查詢出來的資料是不正確的。比如去重統計訂單數量,count(orderNo),統計下單件數sum(number)。
下面嘗試將兩行資料進行合併。
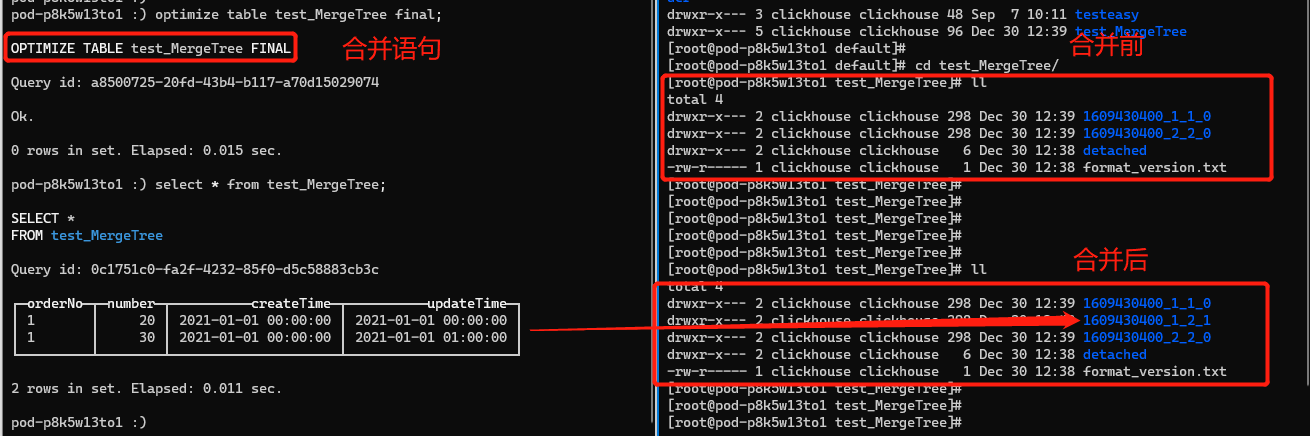
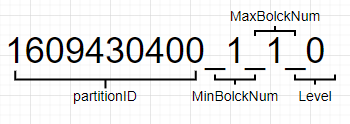
進行強制的分段合併後,還是有兩條資料,並不是我們預期的保留最後一條商品數量為30的資料。但是兩行資料合併到了一個表格中,其中的原因是1609430400_1_1_0,1609430400_2_2_0 的partitionID相同合併成了1609430400_1_2_1這一個檔案。合併完成後其中1609430400_1_1_0,1609430400_2_2_0會在一定時間(預設8min)後被後臺刪除。下圖是分割區檔案的命名規則,partitionID:1609430400 = 2021-01-01 00:00:00,MinBolckNum、MaxBolckNum:是最小資料塊最巨量資料塊,是一個整形自增的編號。Level:0可以理解為分割區合併過的次數,預設值是0,每次合併過後生成的新的分割區後會加1。
綜合上述,可以看出MergeTree雖然有主鍵,但並不是類似MySQL用來保持記錄唯一的去重作用,只是用來查詢加速,即使在手動合併之後,主鍵相同的資料行也仍舊存在,不能按業務單據去重導致count(orderNo),sum(number)拿到的結果是不正確的,不適用我們的需求。
3.2 ReplacingMergeTree:替換合併樹
MergeTree雖然有主鍵,但是不能對相同主鍵的資料進行去重,我們的業務場景不能有重複資料。ClickHouse提供了ReplacingMergeTree引擎用來去重,能夠在合併分割區時刪除重複的資料。我理解的去重分兩個方面,一個是物理去重,就是重複的資料直接被刪除掉,另一個是查詢去重,不處理物理資料,但是查詢結果是已經將重複資料過濾掉的。
範例如下,ReplacingMergeTree建表方法和MergeTree沒有特別大的差異,只是ENGINE 由MergeTree更改為ReplacingMergeTree([ver]),其中ver是版本列,是一個選填項,官網給出支援的型別是UInt ,Date或者DateTime,但是我試驗Int型別也是可以支援的(ClickHouse 20.8.11)。ReplacingMergeTree在資料合併時物理資料去重,去重策略如下。
- 如果ver版本列未指定,相同主鍵行中保留最後插入的一行。
- 如果ver版本列已經指定,下面範例就指定了version列為版本列,去重是將會保留version值最大的一行,與資料插入順序無關。
CREATE TABLE test_ReplacingMergeTree ( orderNo String, version Int16, number Int16, createTime DateTime, updateTime DateTime) ENGINE = ReplacingMergeTree(version)PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);1) insert into test_ReplacingMergeTree values('1', 1, '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00');2) insert into test_ReplacingMergeTree values('1', 2, '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');3) insert into test_ReplacingMergeTree values('1', 3, '30', '2021-01-02 00:00:00', '2021-01-01 01:00:00');-- final方式去重select * from test_ReplacingMergeTree final;-- argMax方式去重select argMax(orderNo,version) as orderNo, argMax(number,version) as number,argMax(createTime,version),argMax(updateTime,version) from test_ReplacingMergeTree;
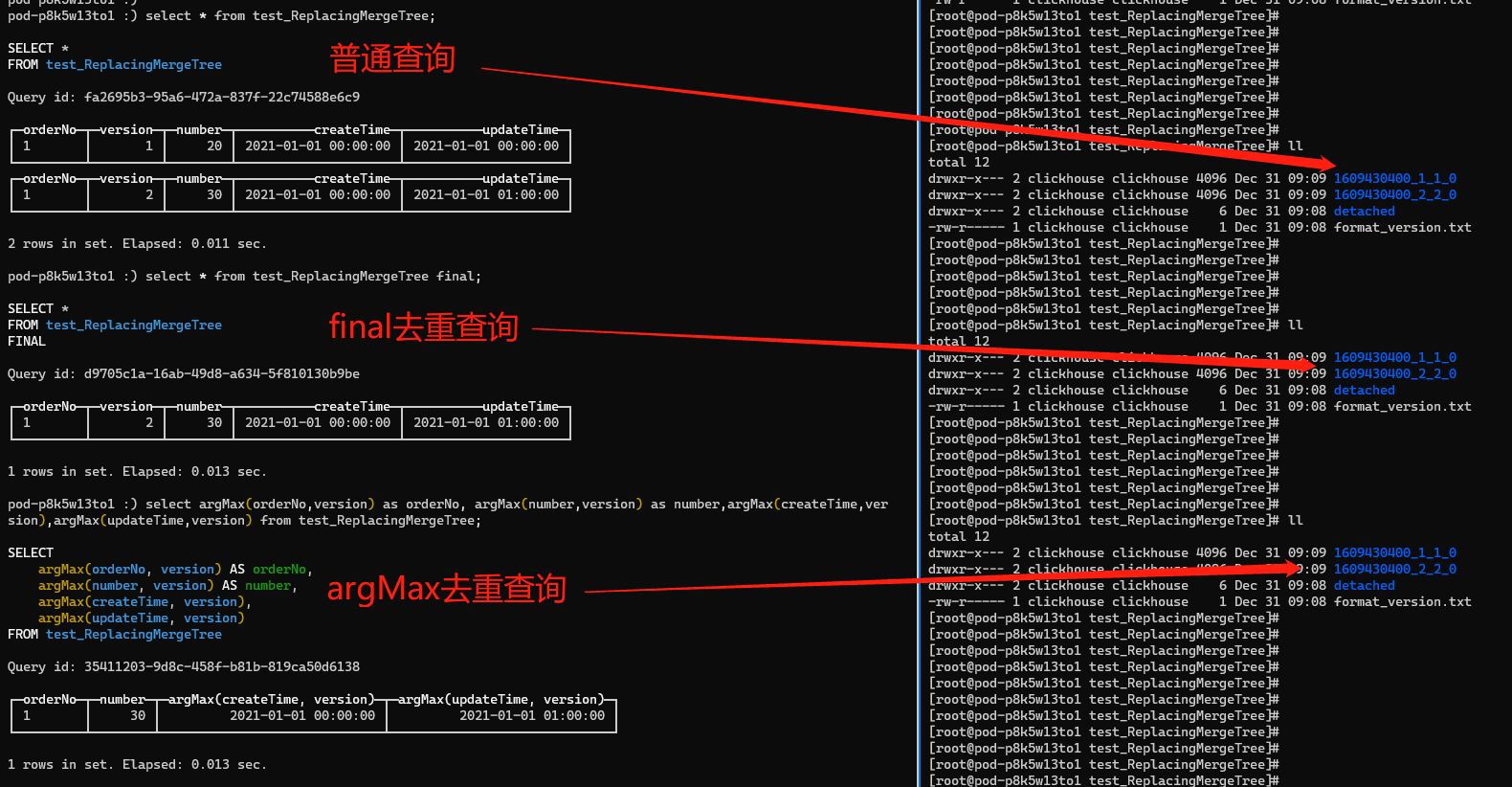
下圖是在執行完前兩條insert語句後進行三次查詢的結果,三種方式查詢均未對物理儲存的資料產生影響,final、argMax方式只是查詢結果是去重的。
- 普通查詢:查詢結果未去重,物理資料未去重(未合併分割區檔案)
- final去重查詢:查詢結果已去重,物理資料未去重(未合併分割區檔案)
- argMax去重查詢:查詢結果已去重,物理資料未去重(未合併分割區檔案)
其中final和argMax查詢方式都過濾掉了重複資料。我們的範例都是基於本地表做的操作,final和argMax在結果上沒有差異,但是如果基於分散式表進行試驗,兩條資料落在了不同資料分片(注意這裡不是資料分割區),那麼final和argMax的結果將會產生差異。final的結果將是未去重的,原因是final只能對本地表做去重查詢,不能對跨分片的資料進行去重查詢,但是argMax的結果是去重的。argMax是通過比較第二引數version的大小,來取出我們要查詢的最新資料來達到過濾掉重複資料的目的,其原理是將每個Shard的資料摟到同一個Shard的記憶體中進行比較計算,所以支援跨分片的去重。
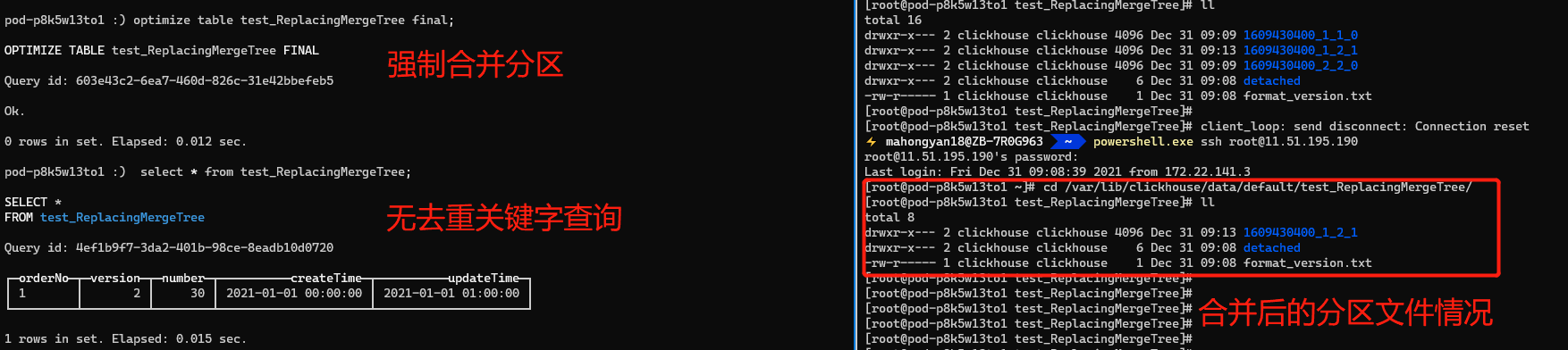
由於後臺的合併是在不確定時間執行的,執行合併命令,然後再使用普通查詢,發現結果已經是去重後的資料,version=2,number=30 是我們想保留的資料。
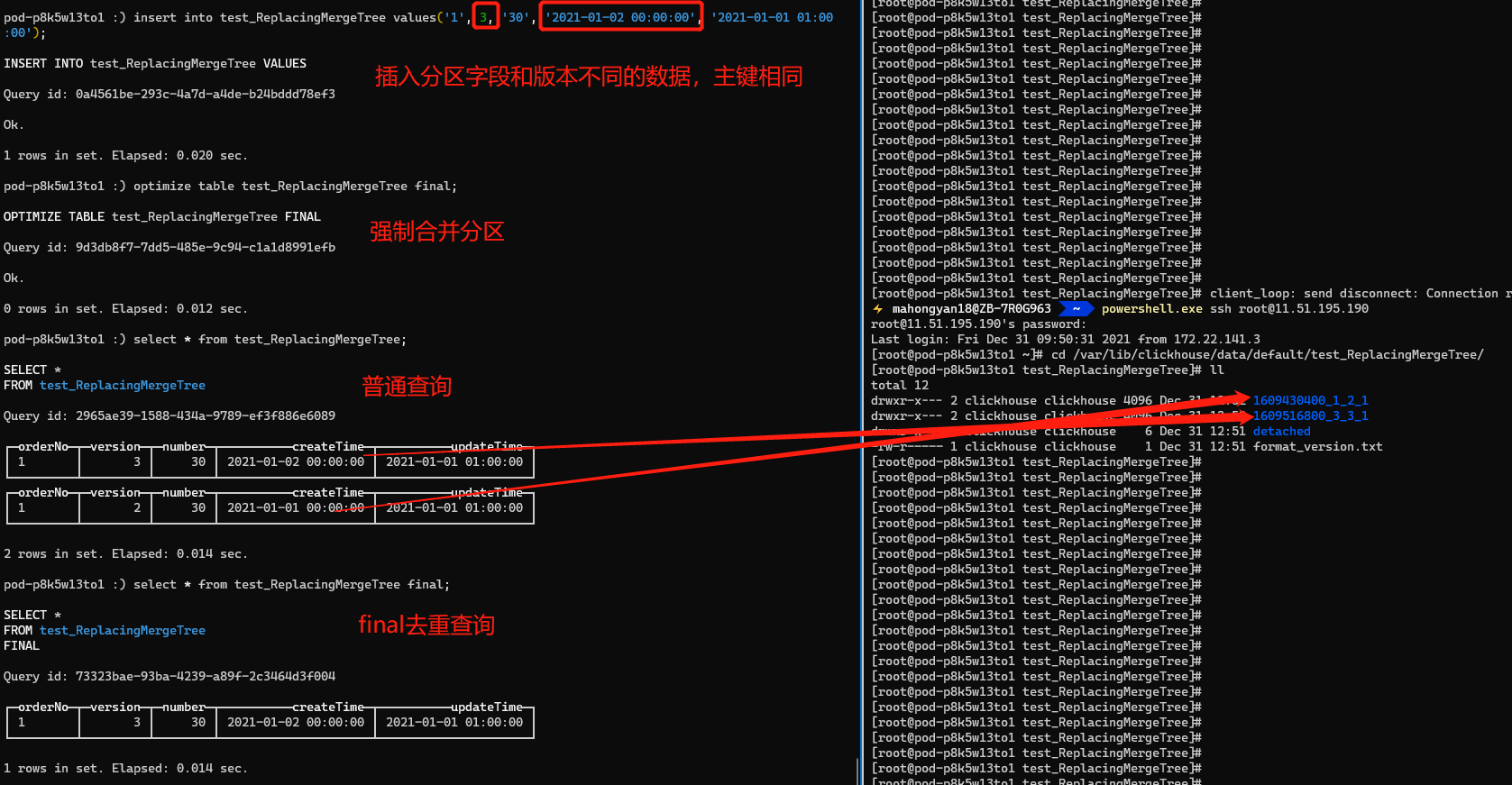
執行第三條insert語句,第三條的主鍵和前兩條一致,但是分割區欄位createTime欄位不同,前兩條是2021-01-01 00:00:00,第三條是2021-01-02 00:00:00,如果按照上述的理解,在強制合併會後將會保留version = 3的這條資料。我們執行普通查詢之後發現,version = 1和2的資料做了合併去重,保留了2,但是version=3的還是存在的,這其中的原因ReplacingMergeTree是已分割區為單位刪除重複資料。前兩個insert的分割區欄位createTime欄位相同,partitionID相同,所以都合併到了1609430400_1_2_1分割區檔案,而第三條insert與前兩條不一致,不能合併到一個分割區檔案,不能做到物理去重。最後通過final去重查詢發現可以支援查詢去重,argMax也是一樣的效果未作展示。
ReplacingMergeTree具有如下特點
- 使用主鍵作為判斷重複資料的唯一鍵,支援插入相同主鍵資料。
- 在合併分割區的時候會觸發刪除重複資料的邏輯。但是合併的時機不確定,所以在查詢的時候可能會有重複資料,但是最終會去重。可以手動呼叫optimize,但是會引發對資料大量的讀寫,不建議生產使用。
- 以資料分割區為單位刪除重複資料,當分割區合併時,同一分割區內的重複資料會被刪除,不同分割區的重複資料不會被刪除。
- 可以通過final,argMax方式做查詢去重,這種方式無論有沒有做過資料合併,都可以得到正確的查詢結果。
ReplacingMergeTree最佳使用方案
- 普通select查詢:對時效不高的離線查詢可以採用ClickHouse自動合併配合,但是需要保證同一業務單據落在同一個資料分割區,分散式表也需要保證在同一個分片(Shard),這是一種最高效,最節省計算資源的查詢方式。
- final方式查詢:對於實時查詢可以使用final,final是本地去重,需要保證同一主鍵資料落在同一個分片(Shard),但是不需要落在同一個資料分割區,這種方式效率次之,但是與普通select相比會消耗一些效能,如果where條件對主鍵索引,二級索引,分割區欄位命中的比較好的話效率也可以完全可以使用。
- argMax方式查詢:對於實時查詢可以使用argMax,argMax的使用要求最低,咋查都能去重,但是由於它的實現方式,效率會低很多,也很消耗效能,不建議使用。後面9.4.3會配合壓測資料與final進行對比。
上述的三種使用方案中其中ReplacingMergeTree配合final方式查詢,是符合我們需求的。
3.3 CollapsingMergeTree/VersionedCollapsingMergeTree:摺疊合併樹
摺疊合併樹不再通過範例來進行說明。可參考官網範例。
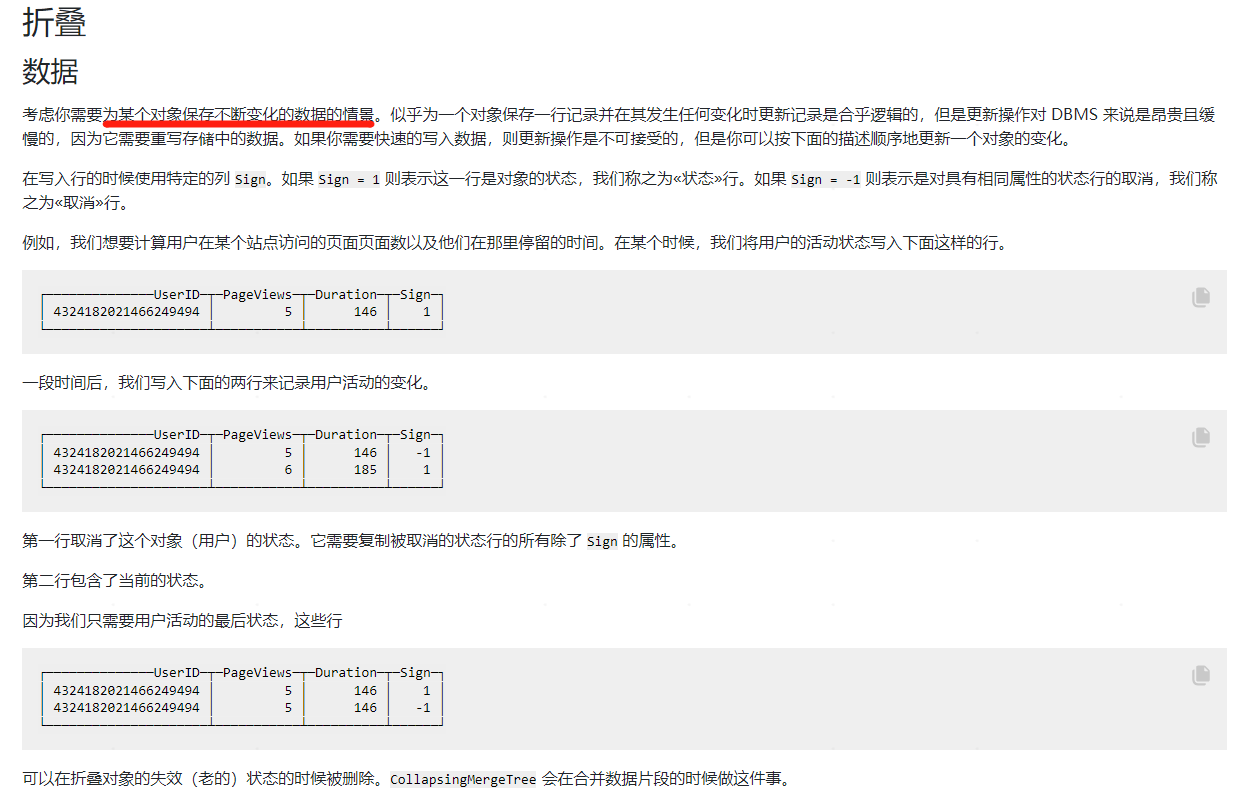
CollapsingMergeTree通過定義一個sign標記位欄位,記錄資料行的狀態。如果sign標記位1(《狀態》行), 則表示這是一行有效的資料, 如果sign標記位為 -1(《取消》行),則表示這行資料需要被刪除。需要注意的是資料主鍵相同才可能會被摺疊。
- 如果sign=1比sign=-1的資料多至少一行,則保留最後一行sign=1的資料。
- 如果sign=-1比sign=1多至少一行,則保留第一行sign=-1的行。
- 如果sign=1與sign=-1的行數一樣多,最後一行是sign=1,則保留第一行sign=-1和最後一行sign=1的資料。
- 如果sign=1與sign=-1的行數一樣多,最後一行是sign=-1,則什麼都不保留。
- 其他情況ClickHouse不會報錯但會列印告警紀錄檔,這種情況下,查詢的結果是不確定不可預知的。
在使用CollapsingMergeTree時候需要注意
1)與ReplacingMergeTree一樣,摺疊資料不是實時觸發的,是在分割區合併的時候才會體現,在合併之前還是會查詢到重複資料。解決方式有兩種
- 使用optimize強制合併,同樣也不建議在生產環境中使用效率極低並且消耗資源的強制合併。
- 改寫查詢方式,通過group by 配合有符號的sign列來完成。這種方式增加了使用的編碼成本
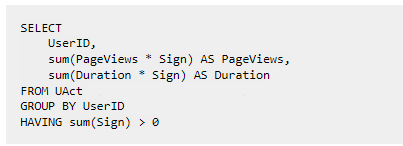
2)在寫入方面通過《取消》行刪除或修改資料的方式需要寫入資料的程式記錄《狀態》行的資料,極大的增加儲存成本和程式設計的複雜性。Flink在上線或者某些情況下會重跑資料,會丟失程式中的記錄的資料行,可能會造成sign=1與sign=-1不對等不能進行合併,這一點是我們無法接受的問題。
CollapsingMergeTree還有一個弊端,對寫入的順序有嚴格的要求,如果按照正常順序寫入,先寫入sign=1的行再寫入sign=-1的行,能夠正常合併,如果順序反過來則不能正常合併。ClickHouse提供了VersionedCollapsingMergeTree,通過增加版本號來解決順序問題。但是其他的特性與CollapsingMergeTree完全一致,也不能滿足我們的需求
3.4 表引擎總結
我們詳細介紹了MergeTree系列中的MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree四種表引擎,還有SummingMergeTree、AggregatingMergeTree沒有介紹,SummingMergeTree是為不關心明細資料,只關心彙總資料設計的表引擎。MergeTree也能夠滿足這種只關注彙總資料的需求,通過group by配合sum,count聚合函數就可以滿足,但是每次查詢都進行實時聚合會增加很大的開銷。我們既有明細資料需求,又需要彙總指標需求,所以SummingMergeTree不能滿足我們的需求。AggregatingMergeTree是SummingMergeTree升級版,本質上還是相同的,區別在於:SummingMergeTree對非主鍵列進行sum聚合,而AggregatingMergeTree則可以指定各種聚合函數。同樣也滿足不了需求。

最終我們選用了ReplacingMergeTree引擎,分散式表通過業務主鍵sipHash64(docId)進行shard保證同一業務主鍵資料落在同一分片,同時使用業務單據建立時間按月/按天進行分割區。配合final進行查詢去重。這種方案在雙十一期間資料日增3000W,業務高峰資料庫QPS93,32C 128G 6分片 2副本的叢集CPU使用率最高在60%,系統整體穩定。下文的所有實踐優化也都是基於ReplacingMergeTree引擎。
4 Flink如何寫入ClickHouse
4.1 Flink版本問題
Flink支援通過JDBC Connector將資料寫入JDBC資料庫,但是Flink不同版本的JDBC connector寫入方式有很大區別。因為Flink在1.11版本對JDBC Connector進行了一次較大的重構:
- 1.11版本之前包名為flink-jdbc
- 1.11版本(包含)之後包名為flink-connector-jdbc
兩者對Flink中以不同方式寫入ClickHouse Sink的支援情況如下:
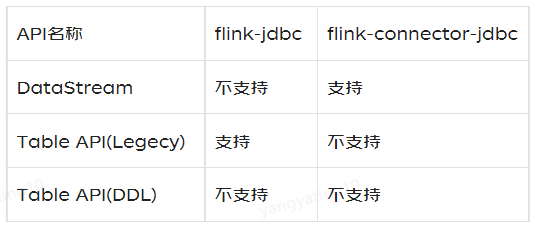
起初我們使用1.10.3版本的Flink,flink-jdbc不支援使用DataStream流寫入,需要升級Flink版本至1.11.x及以上版本來使用flink-connector-jdbc來寫入資料到ClickHouse。
4.2 構造ClickHouse Sink
/** * 構造Sink * @param clusterPrefix clickhouse 資料庫名稱 * @param sql insert 預留位置 eq:insert into demo (id, name) values (?, ?) */public static SinkFunction getSink(String clusterPrefix, String sql) { String clusterUrl = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_URL); String clusterUsername = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_USER_NAME); String clusterPassword = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_PASSWORD); return JdbcSink.sink(sql, new CkSinkBuilder<>(), new JdbcExecutionOptions.Builder().withBatchSize(200000).build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withDriverName("ru.yandex.clickhouse.ClickHouseDriver") .withUrl(clusterUrl) .withUsername(clusterUsername) .withPassword(clusterPassword) .build());}
使用flink-connector-jdbc的JdbcSink.sink() api來構造Flink sink。JdbcSink.sink()入參含義如下
- sql:預留位置形式的sql語句,例如:insert into demo (id, name) values (?, ?)
- new CkSinkBuilder<>():org.apache.flink.connector.jdbc.JdbcStatementBuilder介面的實現類,主要是將流中資料對映到java.sql.PreparedStatement 來構造PreparedStatement ,具體不再贅述。
- 第三個入參:flink sink的執行策略。
- 第四個入參:jdbc的驅動,連線,賬號與密碼。

- 使用時直接在DataStream流中addSink即可。
5 Flink寫入ClickHouse策略
Flink同時寫入ES和Clikhouse,但是在進行資料查詢的時候發現ClickHouse永遠要比ES慢一些,開始懷疑是ClickHouse合併等處理會耗費一些時間,但是ClickHouse這些合併操作不會影響查詢。後來查閱Flink寫入策略程式碼發現是我們使用的策略有問題。
上段(4.2)程式碼中new JdbcExecutionOptions.Builder().withBatchSize(200000).build()為寫入策略,ClickHouse為了提高寫入效能建議進行不少於1000行的批次寫入,或每秒不超過一個寫入請求。策略是20W行記錄進行寫入一次,Flink進行Checkpoint的時候也會進行寫入提交。所以當資料量積攢到20W或者Flink記性Checkpoint的時候ClickHouse裡面才會有資料。我們的ES sink策略是1000行或5s進行寫入提交,所以出現了寫入ClickHouse要比寫入ES慢的現象。
到達20W或者進行Checkpoint的時候進行提交有一個弊端,當資料量小達不到20W這個量級,Checkpoint時間間隔t1,一次checkpoint時間為t2,那麼從接收到JDQ訊息到寫入到ClickHouse最長時間間隔為t1+t2,完全依賴Checkpoint時間,有時候有資料積壓最慢有1~2min。進而對ClickHouse的寫入策略進行優化,new JdbcExecutionOptions.Builder().withBatchIntervalMs(30 * 1000).build() 優化為沒30s進行提交一次。這樣如果Checkpoint慢的話可以觸發30s提交策略,否則Checkpoint的時候提交,這也是一種比較折中的策略,可以根據自己的業務特性進行調整,在偵錯提交時間的時候發現如果間隔過小,zookeeper的cpu使用率會提升,10s提交一次zk使用率會從5%以下提升到10%左右。
Flink中的org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat#open處理邏輯如下圖。

6 寫入分散式表還是本地表
先說結果,我們是寫入分散式表。
網上的資料和ClickHouse雲服務的同事都建議寫入本地表。分散式表實際上是一張邏輯表並不儲存真實的物理資料。如查詢分散式表,分散式表會把查詢請求發到每一個分片的本地表上進行查詢,然後再集合每個分片本地表的結果,彙總之後再返回。寫入分散式表,分散式表會根據一定規則,將寫入的資料按照規則儲存到不同的分片上。如果寫入分散式表也只是單純的網路轉發,影響也不大,但是寫入分散式表並非單純的轉發,實際情況見下圖。
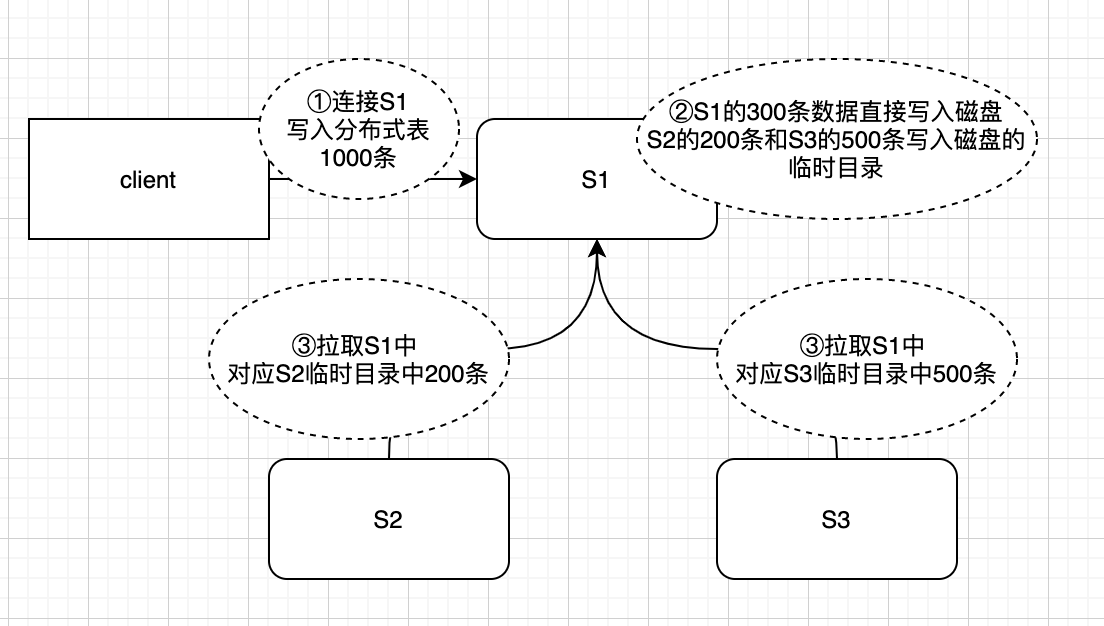
有三個分片S1、S2、S3,使用者端連線到S1節點,進行寫入分散式表操作。
- 第一步:寫入分散式表1000條資料,分散式表會根據路由規則,假設按照規則300條分配到S1,200條到S2,500條到S3
- 第二步:client給過來1000條資料,屬於S1的300條資料直接寫入磁碟,資料S2,S3的資料也會寫入到S1的臨時目錄
- 第三步:S2,S3接收到zk的變更通知,生成拉取S1中當前分片對應的臨時目錄資料的任務,並且將任務放到一個佇列,等到某個時機會將資料拉到自身節點。
從分散式表的寫入方式可以看到,會將所有資料落到client連線分片的磁碟上。如果資料量大,磁碟的IO會造成瓶頸。並且MergeTree系列引擎存在合併行為,本身就有寫放大(一條資料合併多次),佔用一定磁碟效能。在網上看到寫入本地表的案例都是日增量百億,千億。我們選擇寫入分散式表主要有兩點,一是簡單,因為寫入本地表需要改造程式碼,自己指定寫入哪個節點,另一個是開發過程中寫入本地表並未出現什麼嚴重的效能瓶頸。雙十一期間資料日增3000W(合併後)行並未造成寫入壓力。如果後續產生瓶頸,可能會放棄寫入分散式表。
7 為什麼只有某個分片CPU使用率高
7.1 資料分佈不均勻,導致部分節點CPU高
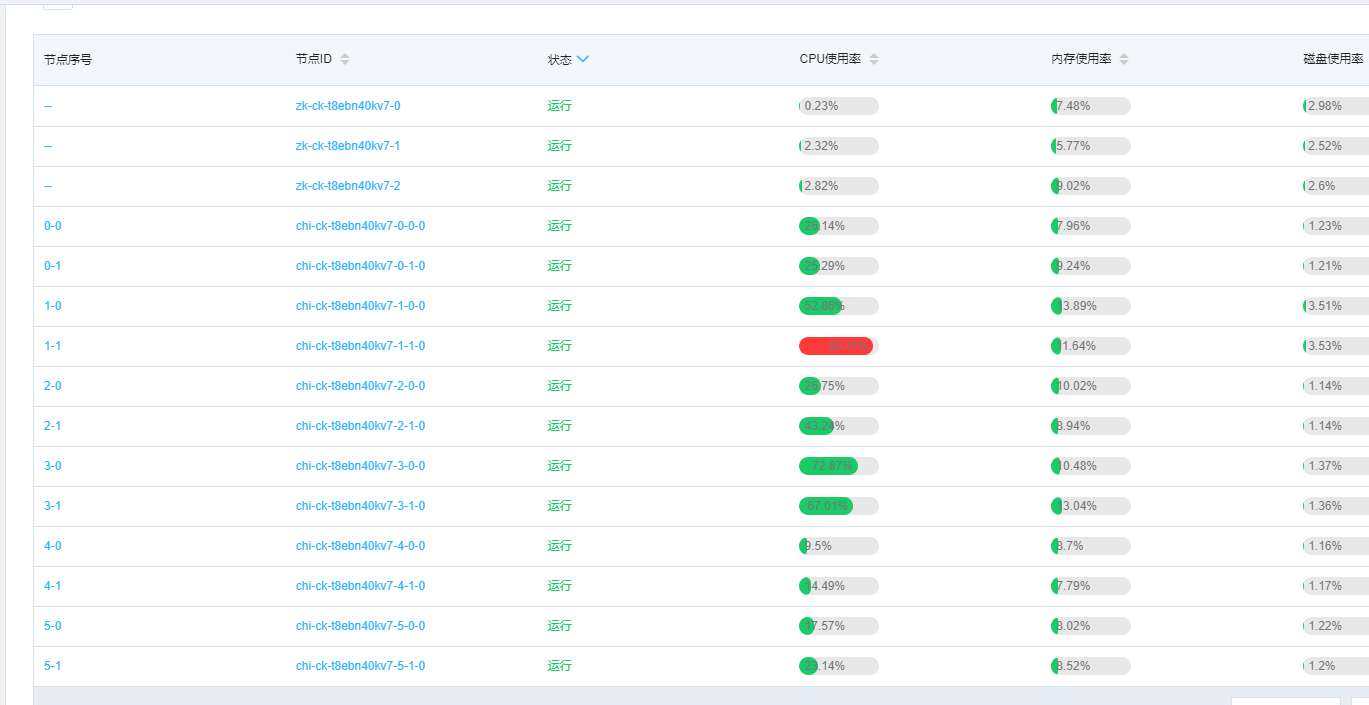
上圖是在接入ClickHouse過程中遇到的一個問題,其中7-1節點CPU使用率非常高,不同節點的差異非常大。後來通過SQL定位發現不同節點上的資料量差異也非常大,其中7-1節點資料量是最多的,導致7-1節點相比其他節點需要處理的資料行數非常多,所以CPU相對會高很多。因為我們使用網格站編碼,分揀倉編碼hash後做分散式表的資料分片策略,但是分揀倉編碼和網站編碼的基數比較小,導致hash後不夠分散造成這種資料傾斜的現象。後來改用業務主鍵做hash,解決了這種部分節點CPU高的問題。
7.2 某節點觸發合併,導致該節點CPU高
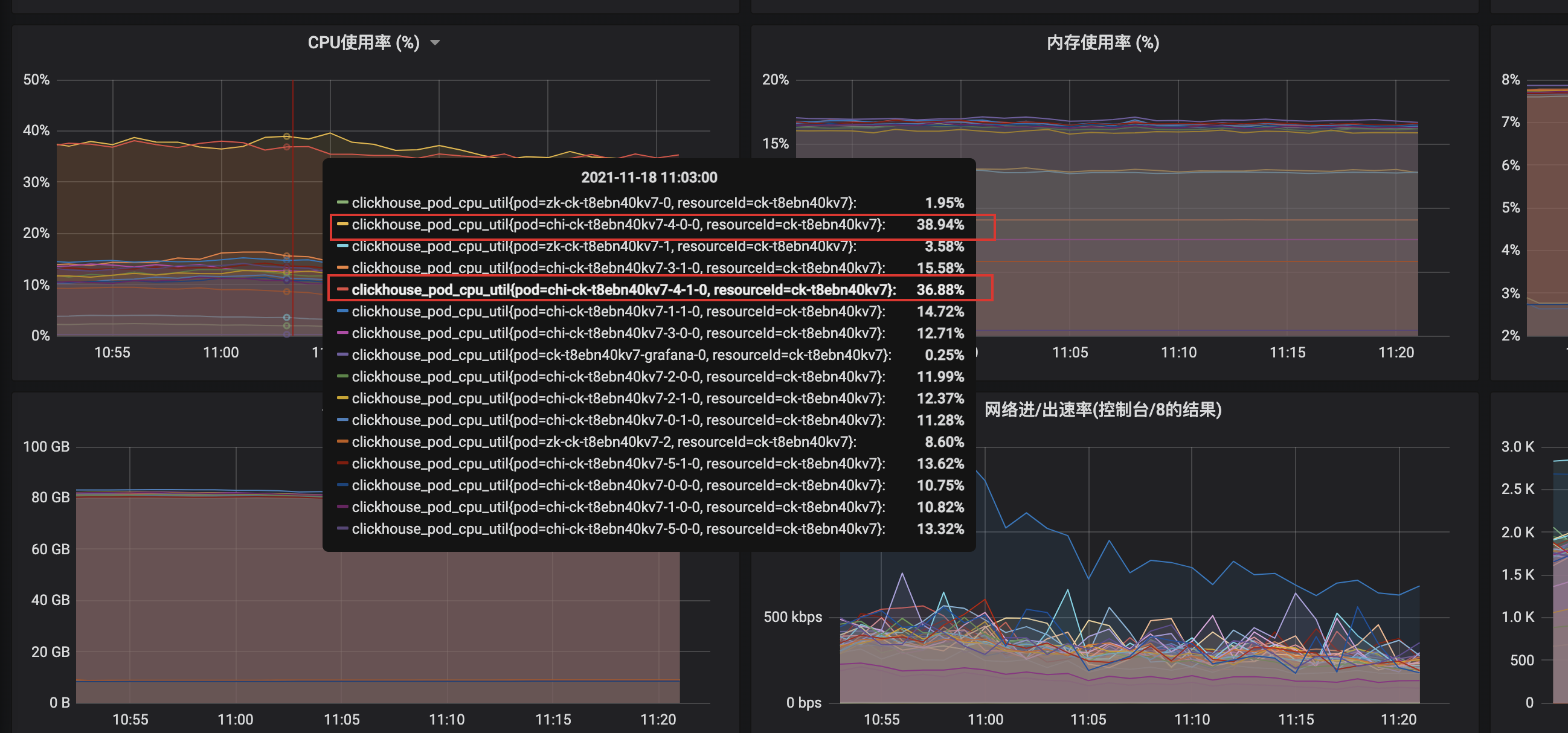
7-4節點(主節點和副本),CPU毫無徵兆的比其他節點高很多,在排除新業務上線、大促等突發情況後進行慢SQL定位,通過query_log進行分析每個節點的慢查詢,具體語句見第8小節。
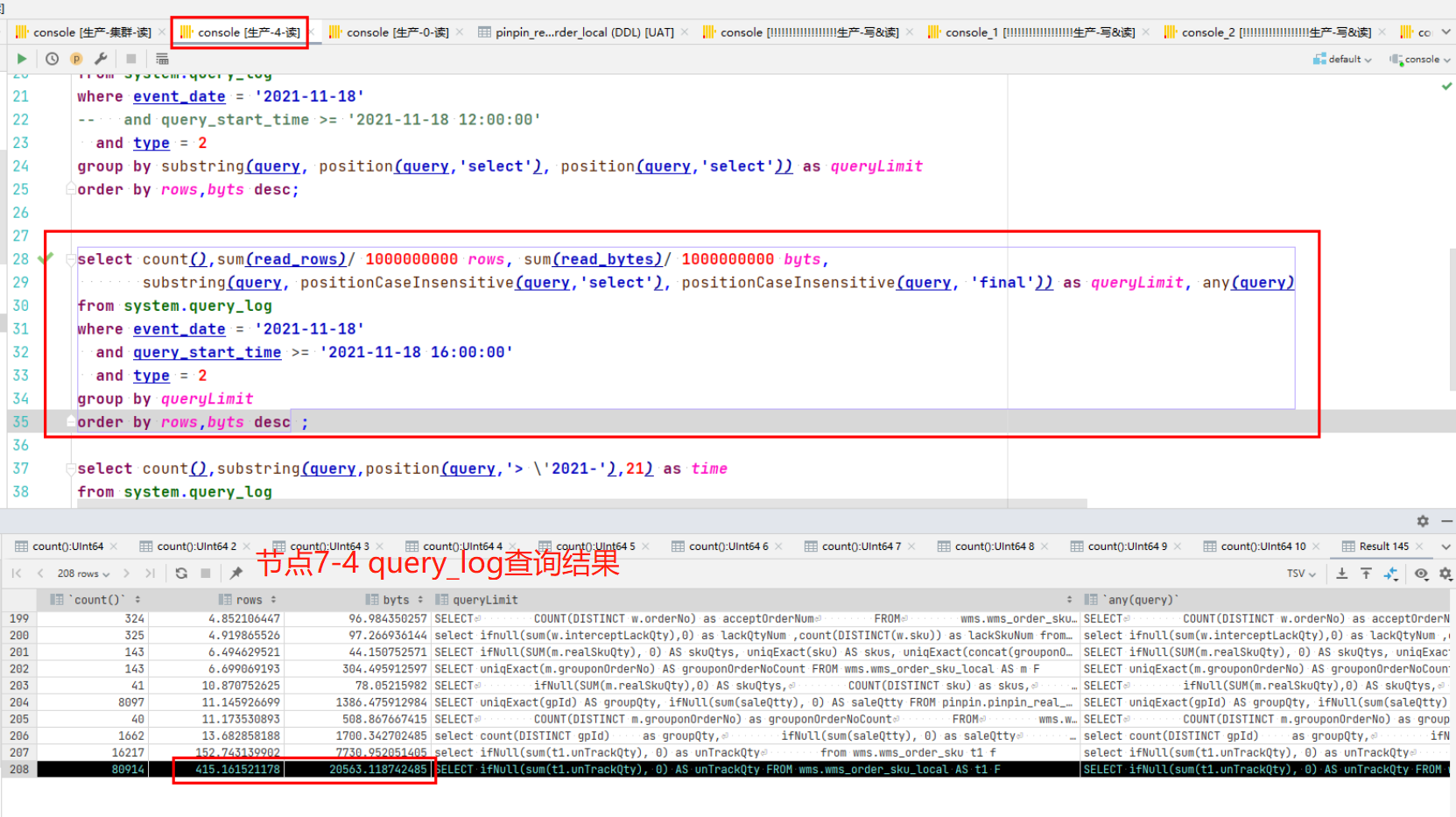
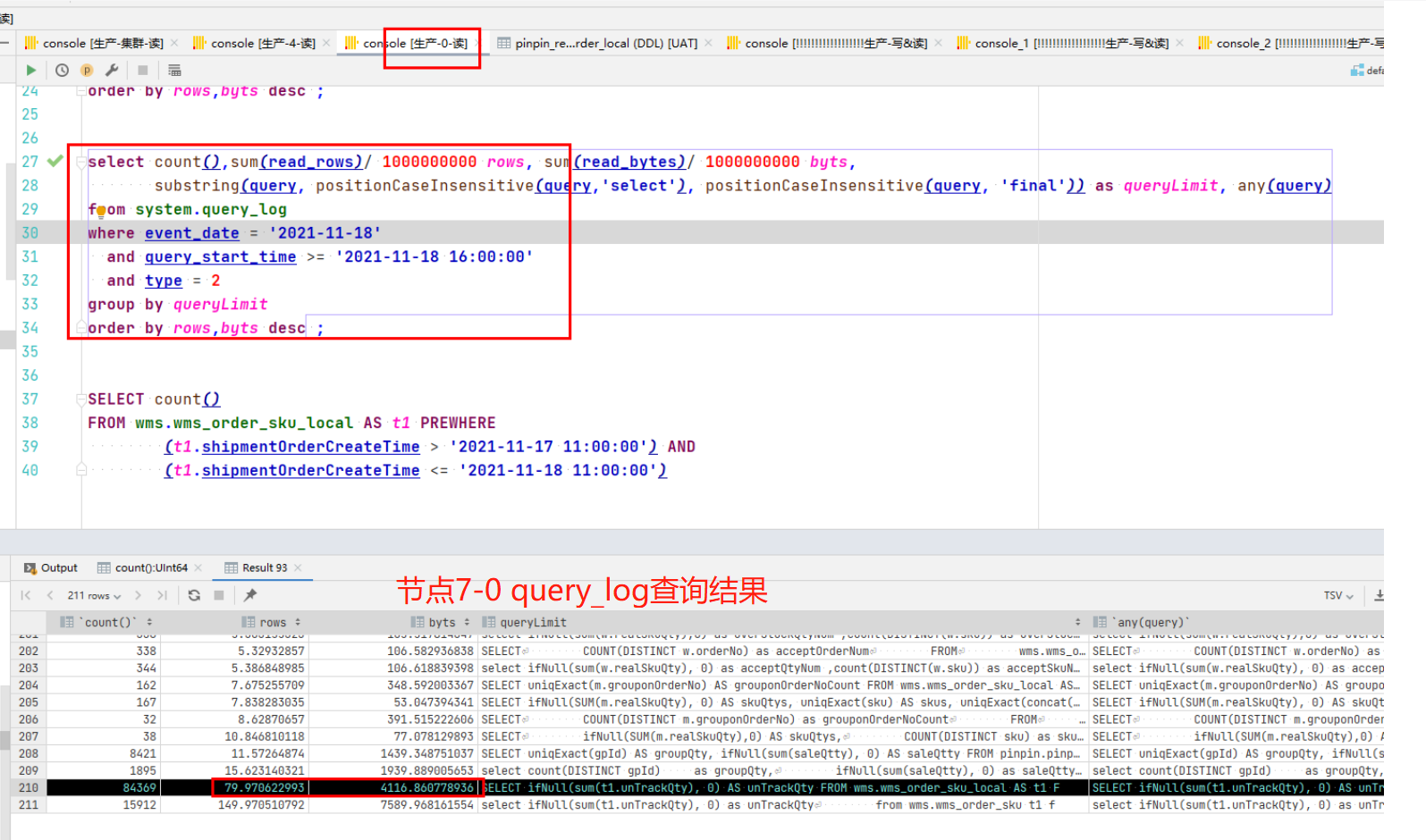
通過兩個節點的慢SQL進行對比,發現是如下SQL的查詢情況有較大差異。
SELECT ifNull(sum(t1.unTrackQty), 0) AS unTrackQtyFROM wms.wms_order_sku_local AS t1 FINAL PREWHERE t1.shipmentOrderCreateTime > '2021-11-17 11:00:00' AND t1.shipmentOrderCreateTime <= '2021-11-18 11:00:00' AND t1.gridStationNo = 'WG0000514' AND t1.warehouseNo NOT IN ('wms-6-979', 'wms-6-978', '6_979', '6_978') AND t1.orderType = '10'WHERE t1.ckDeliveryTaskStatus = '3'
但是我們有個疑惑,同樣的語句,同樣的執行次數,而且兩個節點的資料量,part數量都沒有差異,為什麼7-4節點掃描的行數是7-0上的5倍,把這個原因找到,應該就能定位到問題的根本原因了。
接下來我們使用clickhouse-client進行SQL查詢,開啟trace級別紀錄檔,檢視SQL的執行過程。具體執行方式以及查詢紀錄檔分析參考下文9.1小節,這裡我們直接分析結果。
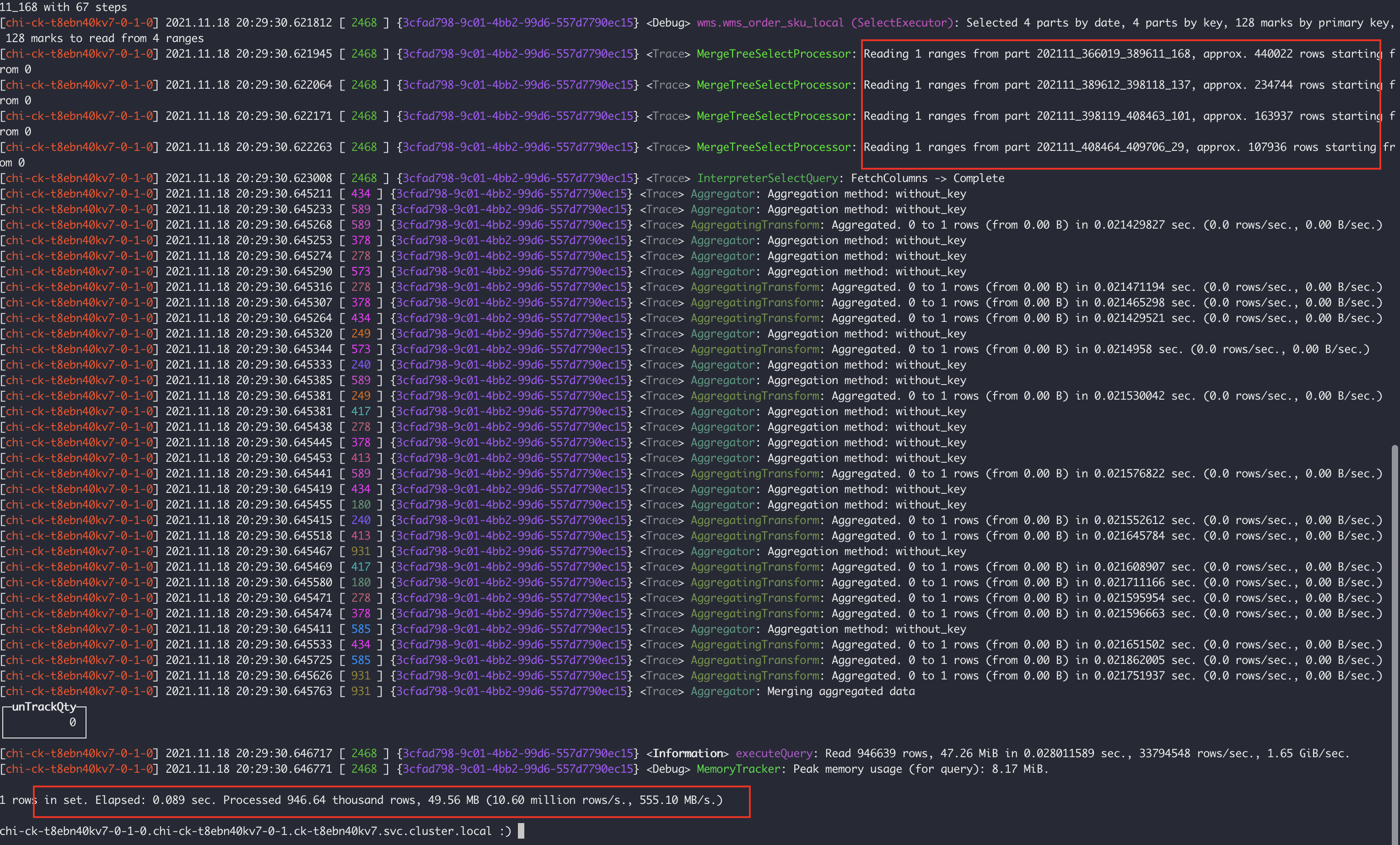
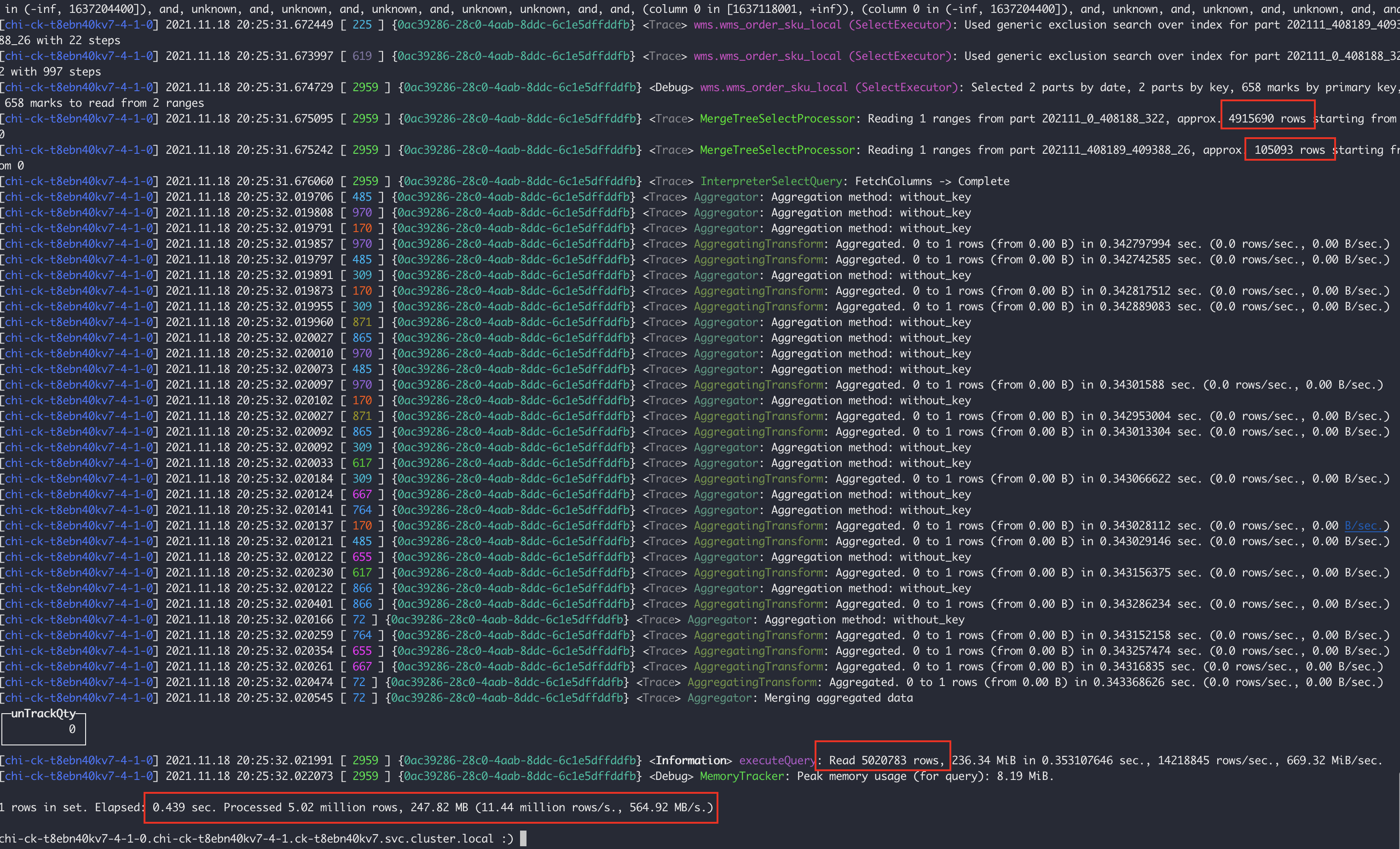
上面兩張圖可以分析出
- 7-0節點:掃描了4個part分割區檔案,共計94W行,耗時0.089s
- 7-4節點:掃描了2個part分割區檔案,其中有一個part491W行,共計502W行,耗時0.439s
很明顯7-4節點的202111_0_408188_322這個分割區比較異常,因為我們是按月分割區的,7-4節點不知道什麼原因發生了分割區合併,導致我們檢索的11月17號的資料落到了這個大分割區上,所以但是查詢會過濾11月初到18號的所有資料,和7-0節點產生了差異。上述的SQL通過 gridStationNo = ‘WG0000514’ 條件進行查詢,所以在對gridStationNo 欄位進行建立二級索引後解決了這個問題。
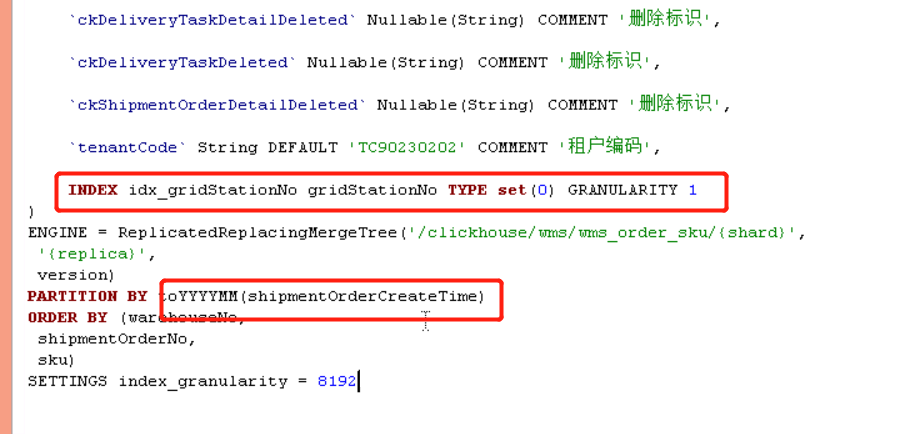
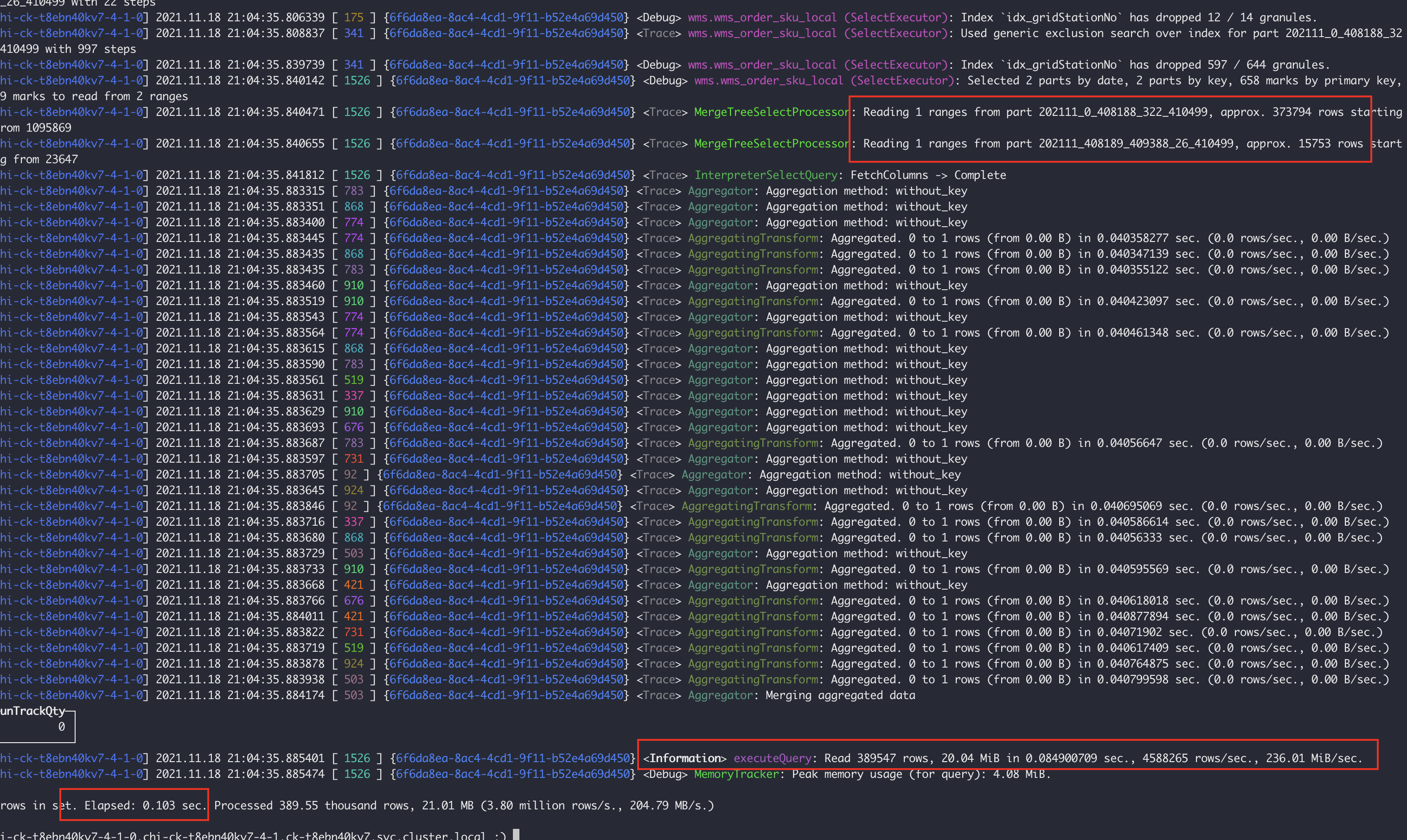
在增加加二級索引後7-4節點:掃描了2個part分割區檔案,共計38W行,耗時0.103s。
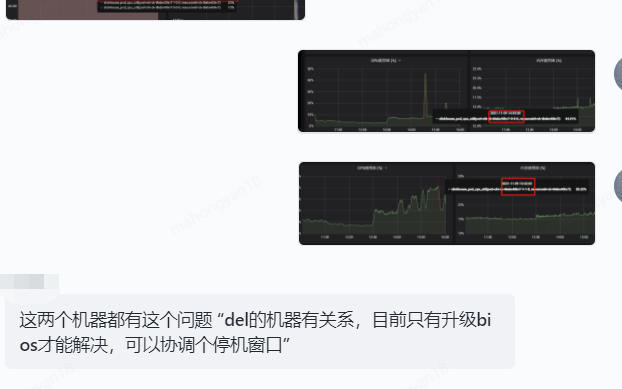
7.3 物理機故障
這種情況少見,但是也遇到過一次
8 如何定位是哪些SQL在消耗CPU
我認為可以通過兩個方向來排查問題,一個是SQL執行頻率是否過高,另一個方向是判斷是否有慢SQL在執行,高頻執行或者慢查詢都會大量消耗CPU的計算資源。下面通過兩個案例來說明一下排查CPU偏高的兩種有效方法,下面兩種雖然操作上是不同的,但是核心都是通過分析query_log來進行分析定位的。
8.1 grafana定位高頻執行SQL
在12月份上線了一些需求,最近發現CPU使用率對比來看使用率偏高,需要排查具體是哪些SQL導致的。
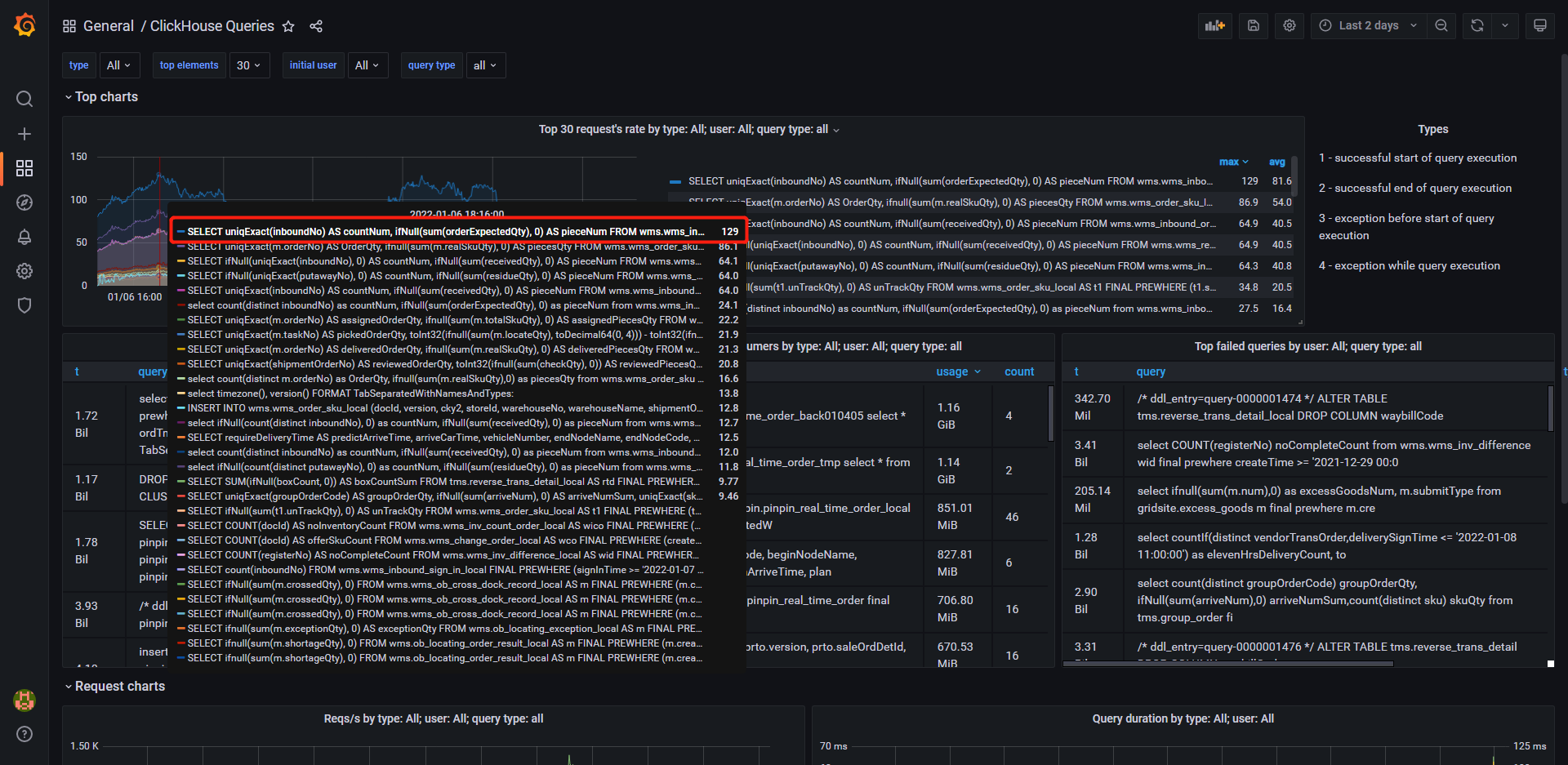
通過上圖自行搭建的grafana監控可以看出(搭建檔案),有幾個查詢語句執行頻率非常高,通過SQL定位到查詢介面程式碼邏輯,發現一次前端介面請求後端介面會執行多條相似條件的SQL語句,只是業務狀態不相同。這種需要統計不同型別、不同狀態的語句,可以進行條件聚合進行優化,9.4.1小節細講。優化後語句執行頻率極大的降低。
8.2 掃描行數高/使用記憶體高:query_log_all分析
上節說SQL執行頻率高,導致CPU使用率高。如果SQL頻率執行頻率很低很低,但是CPU還是很高該怎麼處理。SQL執行頻率低,可能存在掃描的資料行數很大的情況,消耗的磁碟IO,記憶體,CPU這些資源很大,這種情況下就需要換個手段來排查出來這個很壞很壞的SQL(T⌓T)。
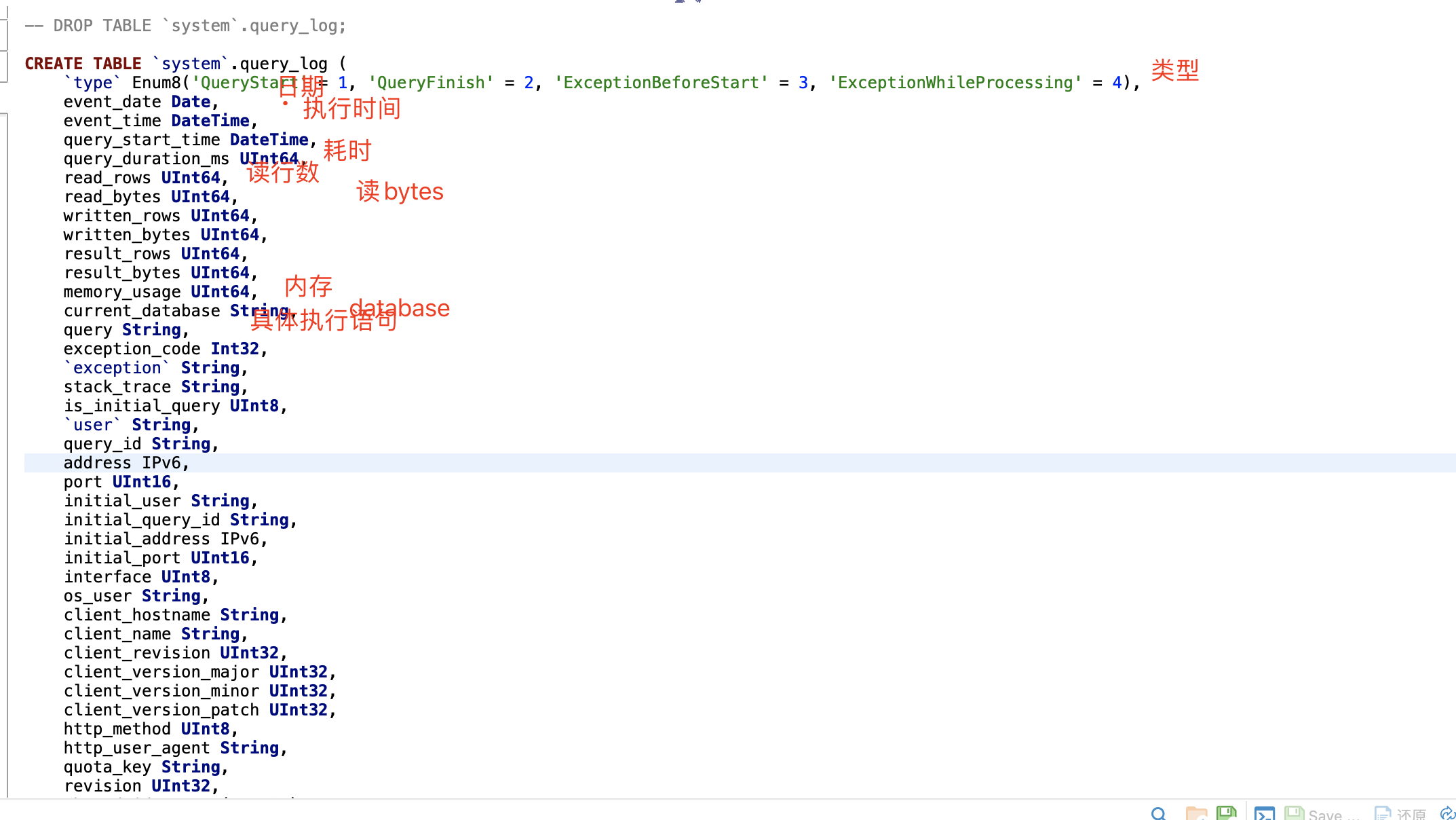
ClickHouse自身有system.query_log表,用於記錄所有的語句的執行紀錄檔,下圖是該表的一些關鍵欄位資訊
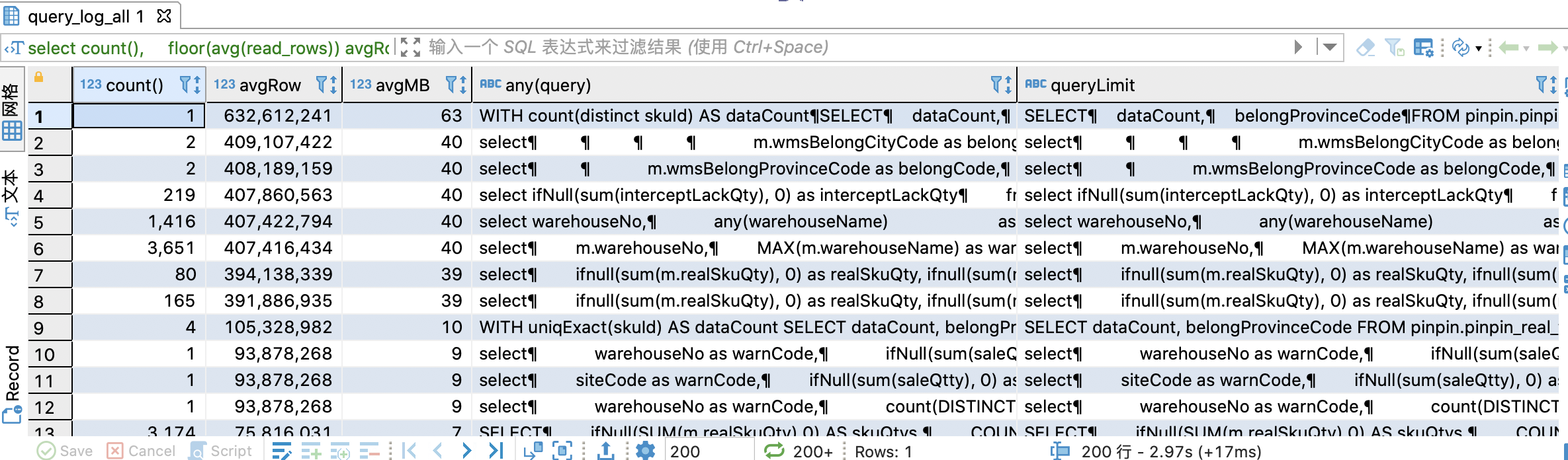
-- 建立query_log分散式表CREATE TABLE IF NOT EXISTS system.query_log_allON CLUSTER defaultAS system.query_logENGINE = Distributed(sht_ck_cluster_pro,system,query_log,rand());-- 查詢語句select -- 執行次數 count(), -- 平均查詢時間 avg(query_duration_ms) avgTime, -- 平均每次讀取資料行數 floor(avg(read_rows)) avgRow, -- 平均每次讀取資料大小 floor(avg(read_rows) / 10000000) avgMB, -- 具體查詢語句 any(query), -- 去除掉where條件,使用者group by歸類 substring(query, positionCaseInsensitive(query, 'select'), positionCaseInsensitive(query, 'from')) as queryLimitfrom system.query_log_all/system.query_logwhere event_date = '2022-01-21' and type = 2group by queryLimitorder by avgRow desc;
query_log是本地表,需要建立分散式表,查詢所有節點的查詢紀錄檔,然後再執行查詢分析語句,執行效果見下圖,圖中可以看出有幾個語句平均掃秒行數已經到了億級別,這種語句可能就存在問題。通過掃描行數可以分析出索引,查詢條件等不合理的語句。7.2中的某個節點CPU偏高就是通過這種方式定位到有問題的SQL語句,然後進一步排查從而解決的。
9 如何優化慢查詢
ClickHouse的SQL優化比較簡單,查詢的大部分耗時都在磁碟IO上,可以參考下這個小實驗來理解。核心優化方向就是降低ClickHouse單次查詢處理的資料量,也就是降低磁碟IO。下面介紹下慢查詢分析手段、建表語句優化方式,還有一些查詢語句優化。
9.1 使用服務紀錄檔進行慢查詢分析
雖然ClickHouse在20.6版本之後已經提供檢視查詢計劃的原生EXPLAIN,但是提供的資訊對我們進行慢SQL優化提供的幫助不是很大,在20.6版本前藉助後臺的服務紀錄檔,可以拿到更多的資訊供我們分析。與EXPLAIN相比我更傾向於使用檢視服務紀錄檔這種方式進行分析,這種方式需要使用clickhouse-client進行執行SQL語句,文末有通過docker搭建CK環境檔案。高版本的EXPLAIN提供了ESTIMATE可以查詢到SQL語句掃描的part數量、資料行數等細粒度資訊,EXPLAIN使用方式可以參考官方檔案說明。
用一個慢查詢來進行分析,通過8.2中的query_log_all定位到下列慢SQL。
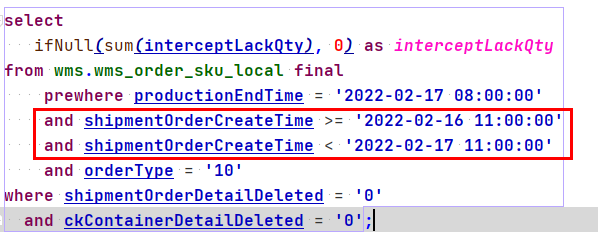
select ifNull(sum(interceptLackQty), 0) as interceptLackQtyfrom wms.wms_order_sku_local final prewhere productionEndTime = '2022-02-17 08:00:00' and orderType = '10'where shipmentOrderDetailDeleted = '0' and ckContainerDetailDeleted = '0'
使用clickhouse-client,send_logs_level引數指定紀錄檔級別為trace。
clickhouse-client -h 地址 --port 埠 --user 使用者名稱 --password 密碼 --send_logs_level=trace
在client中執行上述慢SQL,伺服器端列印紀錄檔如下,紀錄檔量較大,省去部分部分行,不影響整體紀錄檔的完整性。
[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.036317 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Debug> executeQuery: (from 11.77.96.163:35988, user: bjwangjiangbo) select ifNull(sum(interceptLackQty), 0) as interceptLackQty from wms.wms_order_sku_local final prewhere productionEndTime = '2022-02-17 08:00:00' and orderType = '10' where shipmentOrderDetailDeleted = '0' and ckContainerDetailDeleted = '0'[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.037876 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> ContextAccess (bjwangjiangbo): Access granted: SELECT(orderType, interceptLackQty, productionEndTime, shipmentOrderDetailDeleted, ckContainerDetailDeleted) ON wms.wms_order_sku_local[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Debug> wms.wms_order_sku_local (SelectExecutor): Key condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Debug> wms.wms_order_sku_local (SelectExecutor): MinMax index condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038399 [ 1340 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202101_0_0_0_3[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038475 [ 1407 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202103_0_17_2_22[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038491 [ 111 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202103_18_20_1_22..................................省去若干行(此塊含義為:在分割區內檢索有沒有使用索引).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039041 [ 1205 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202202_1723330_1723365_7[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039054 [ 159 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202202_1723367_1723367_0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038928 [ 248 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202201_3675258_3700711_1054[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039355 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Debug> wms.wms_order_sku_local (SelectExecutor): Selected 47 parts by date, 47 parts by key, 9471 marks by primary key, 9471 marks to read from 47 ranges[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039495 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202101_0_0_0_3, approx. 65536 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039583 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202101_1_1_0_3, approx. 16384 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.040291 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202102_0_2_1_4, approx. 146850 rows starting from 0..................................省去若干行(每個分割區讀取的資料行數資訊).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043538 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723330_1723365_7, approx. 24576 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043604 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723366_1723366_0, approx. 8192 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043677 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723367_1723367_0, approx. 8192 rows starting from 0..................................完成資料讀取,開始進行聚合計算.................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.047880 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> InterpreterSelectQuery: FetchColumns -> Complete[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263500 [ 1377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> AggregatingTransform: Aggregating[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263680 [ 1439 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> Aggregator: Aggregation method: without_key..................................省去若干行(資料讀取完成後做聚合操作).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263840 [ 156 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> AggregatingTransform: Aggregated. 12298 to 1 rows (from 36.03 KiB) in 0.215046273 sec. (57187.69187876137 rows/sec., 167.54 KiB/sec.)[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.264283 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> AggregatingTransform: Aggregated. 12176 to 1 rows (from 35.67 KiB) in 0.215476999 sec. (56507.191284950095 rows/sec., 165.55 KiB/sec.)[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.264307 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Trace> Aggregator: Merging aggregated data..................................完成聚合計算,返回最終結果.................................................┌─interceptLackQty─┐│ 563 │└──────────────────┘...................................資料處理耗時,速度,資訊展示................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Information> executeQuery: Read 73645604 rows, 1.20 GiB in 0.229100749 sec., 321455099 rows/sec., 5.22 GiB/sec.[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} <Debug> MemoryTracker: Peak memory usage (for query): 60.37 MiB.1 rows in set. Elapsed: 0.267 sec. Processed 73.65 million rows, 1.28 GB (276.03 million rows/s., 4.81 GB/s.)
現在分析下,從上述紀錄檔中能夠拿到什麼資訊,首先該查詢語句沒有使用主鍵索引,具體資訊如下
2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Key condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and
同樣也沒有使用分割區索引,具體資訊如下
2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): MinMax index condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and
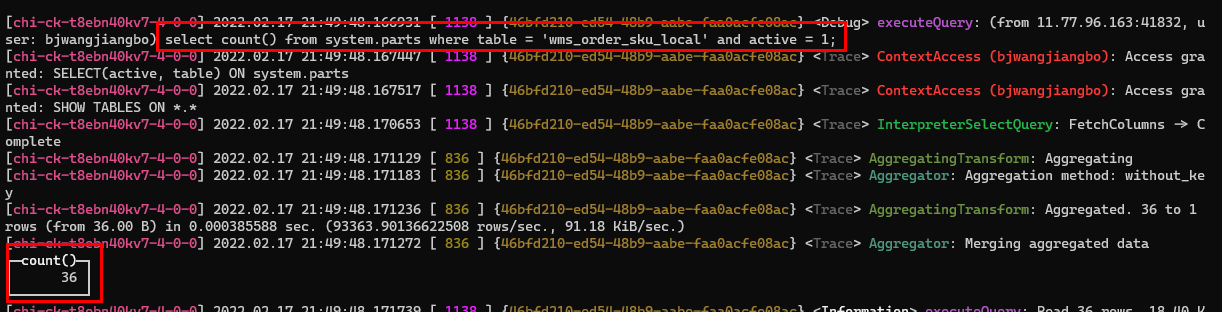
此次查詢一共掃描36個parts,9390個MarkRange,通過查詢system.parts系統分割區資訊表發現當前表一共擁有36個活躍的分割區,相當於全表掃描。
2022.02.17 21:44:58.012832 [ 1138 ] {f1561330-4988-4598-a95d-bd12b15bc750} wms.wms_order_sku_local (SelectExecutor): Selected 36 parts by date, 36 parts by key, 9390 marks by primary key, 9390 marks to read from 36 ranges
此次查詢總共讀取了73645604 行資料,這個行數也是這個表的總資料行數,讀取耗時0.229100749s,共讀取1.20GB的資料。
2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Read 73645604 rows, 1.20 GiB in 0.229100749 sec., 321455099 rows/sec., 5.22 GiB/sec.
此次查詢語句消耗的記憶體最大為60.37MB
2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Peak memory usage (for query): 60.37 MiB.
最後彙總了下資訊,此次查詢總共耗費了0.267s,處理了7365W資料,共1.28GB,並且給出了資料處理速度。
1 rows in set. Elapsed: 0.267 sec. Processed 73.65 million rows, 1.28 GB (276.03 million rows/s., 4.81 GB/s.)
通過上述可以發現兩點嚴重問題
- 沒有使用主鍵索引:導致全表掃描
- 沒有使用分割區索引:導致全表掃描
所以需要再查詢條件上新增主鍵欄位或者分割區索引來進行優化。
shipmentOrderCreateTime為分割區鍵,在新增這個條件後再看下效果。
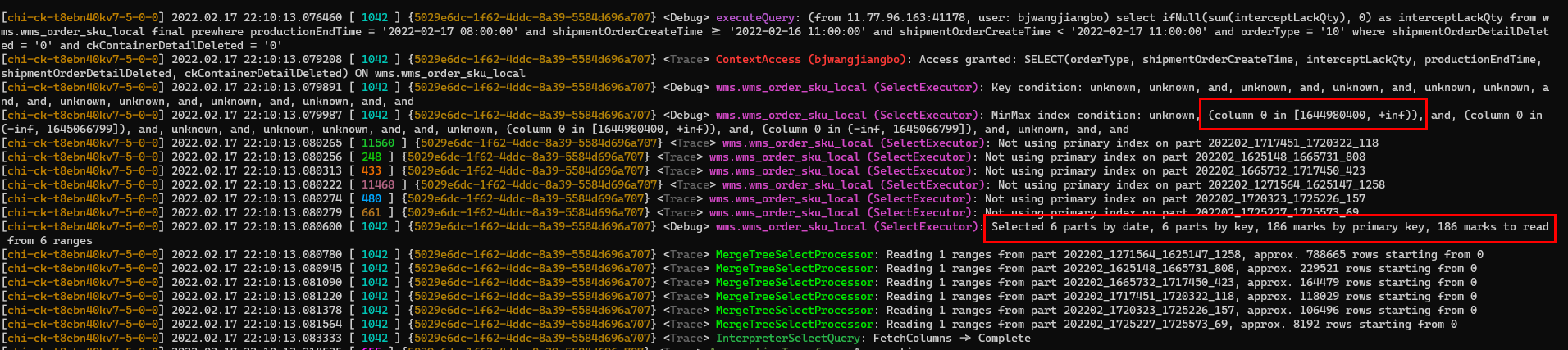

通過分析紀錄檔可以看到沒有使用主鍵索引,但是使用了分割區索引,掃描分片數為6,MarkRange 186,共掃描1409001行資料,使用記憶體40.76MB,掃描資料大小等大幅度降低節省大量伺服器資源,並且提升了查詢速度,0.267s降低到0.18s。
9.2 建表優化
9.2.1 儘量不使用Nullable型別
從實踐上看,設定成Nullable對效能影響也沒有多大,可能是因為我們資料量比較小。不過官方已經明確指出儘量不要使用Nullable型別,因為Nullable欄位不能被索引,而且Nullable列除了有一個儲存正常值的檔案,還會有一個額外的檔案來儲存Null標記。
Using Nullable almost always negatively affects performance, keep this in mind when designing your databases.
CREATE TABLE test_Nullable( orderNo String, number Nullable(Int16), createTime DateTime) ENGINE = MergeTree()PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);
上述建表語句為例,number 列會生成number.null.*兩個額外檔案,佔用額外儲存空間,而orderNo列則沒有額外的null標識的儲存檔案。
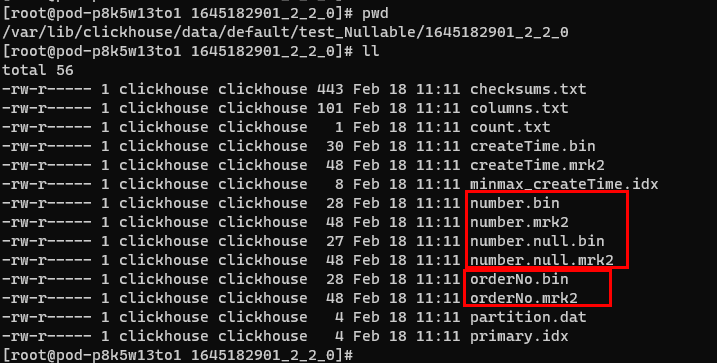
我們實際應用中建表,難免會遇到這種可能為null的欄位,這種情況下可以使用不可能出現的一個值作為預設值,例如將狀態列位都是0及以上的值,那麼可以設定為-1為預設值,而不是使用nullable。
9.2.2 分割區粒度
分割區粒度根據業務場景特性來設定,不宜過粗也不宜過細。我們的資料一般都是按照時間來嚴格劃分,所以都是按天、按月來劃分分割區。如果索引粒度過細按分鐘、按小時等劃分會產生大量的分割區目錄,更不能直接PARTITION BY create_time ,會導致分割區數量驚人的多,幾乎每條資料都有一個分割區會嚴重的影響效能。如果索引粒度過粗,會導致單個分割區的資料量級比較大,上面7.2節的問題和索引粒度也有關係,按月分割區,單個分割區資料量到達500W級,資料範圍1號到18號,只查詢17號,18號兩天的資料量,但是優化按月分割區,分割區合併之後不得不處理不相關的1號到16號的額外資料,如果按天分割區就不會產生CPU飆升的現象。所以要根據自己業務特性來建立,保持一個原則就是查詢只處理本次查詢條件範圍內的資料,不額外處理不相關的資料。
9.2.3 分散式表選擇合適的分片規則
以上文7.1中為例,分散式表選擇的分片規則不合理,導致資料傾斜嚴重落到了少數幾個分片中。沒有發揮出分散式資料庫整個叢集的計算能力,而是把壓力全壓在了少部分機器上。這樣整體叢集的效能肯定是上不來的,所以根據業務場景選擇合適的分片規則,比如我們將sipHash64(warehouseNo)優化為sipHash64(docId),其中docId是業務上唯一的一個標識。
9.3 效能測試,對比優化效果
在聊查詢優化之前先說一個小工具,clickhouse提供的一個clickhouse-benchmark效能測試工具,環境和前文提到的一樣通過docker搭建CK環境,壓測引數可參考官方檔案,這裡我舉一個簡單的單並行測試範例。
clickhouse-benchmark -c 1 -h 連結地址 --port 埠號 --user 賬號 --password 密碼 <<< "具體SQL語句"
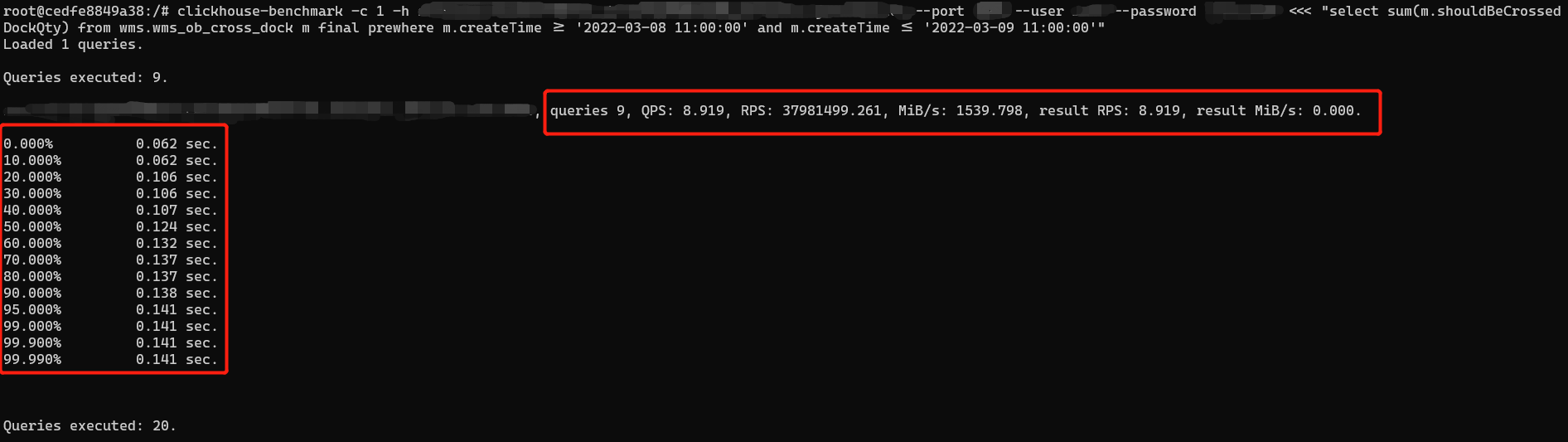
通過這種方式可以瞭解SQL級別的QPS和TP99等資訊,這樣就可以測試語句優化前後的效能差異。
9.4 查詢優化
9.4.1 條件聚合函數降低掃描資料行數
假設一個介面要統計某天的」入庫件量」,」有效出庫單量」,」複核件量」。
-- 入庫件量select sum(qty) from table_1 final prewhere type = 'inbound' and dt = '2021-01-01';-- 有效出庫單量select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;-- 複核件量select sum(qty) from table_1 final prewhere type = 'check' and dt = '2021-01-01';
一個介面出三個指標需要上述三個SQL語句查詢table_1 來完成,但是我們不難發現dt是一致的,區別在於type和status兩個條件。假設dt = ‘2021-01-1’ 每次查詢需要掃描100W行資料,那麼一次介面請求將會掃描300W行資料。通過條件聚合函數優化後將三次查詢改成一次,那麼掃描行數將降低為100W行,所以能極大的節省叢集的計算資源。
select sumIf(qty, type = 'inbound'), -- 入庫件量countIf(distinct orderNo, type = 'outbound' and status = '1'), -- 有效出庫單量sumIf(qty, type = 'check') -- 複核件量prewhere dt = '2021-01-01';
條件聚合函數是比較靈活的,可根據自己業務情況自由發揮,記住一個宗旨就是減少整體的掃描量,就能到達提升查詢效能的目的。
9.4.2 二級索引
MergeTree 系列的表引擎可以指定跳數索引。
跳數索引是指資料片段按照粒度(建表時指定的index_granularity)分割成小塊後,將granularity_value數量的小塊組合成一個大的塊,對這些大塊寫入索引資訊,這樣有助於使用where篩選時跳過大量不必要的資料,減少SELECT需要讀取的資料量。
CREATE TABLE table_name( u64 UInt64, i32 Int32, s String, ... INDEX a (u64 * i32, s) TYPE minmax GRANULARITY 3, INDEX b (u64 * length(s)) TYPE set(1000) GRANULARITY 4) ENGINE = MergeTree()...
上例中的索引能讓 ClickHouse 執行下面這些查詢時減少讀取資料量。
SELECT count() FROM table WHERE s < 'z'SELECT count() FROM table WHERE u64 * i32 == 10 AND u64 * length(s) >= 1234
支援的索引型別
- minmax:以index granularity為單位,儲存指定表示式計算後的min、max值;在等值和範圍查詢中能夠幫助快速跳過不滿足要求的塊,減少IO。
- set(max_rows):以index granularity為單位,儲存指定表示式的distinct value集合,用於快速判斷等值查詢是否命中該塊,減少IO。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):將string進行ngram分詞後,構建bloom filter,能夠優化等值、like、in等查詢條件。
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 與ngrambf_v1類似,區別是不使用ngram進行分詞,而是通過標點符號進行詞語分割。
- bloom_filter([false_positive]):對指定列構建bloom filter,用於加速等值、like、in等查詢條件的執行。
建立二級索引範例
Alter table wms.wms_order_sku_local ON cluster default ADD INDEX belongProvinceCode_idx belongProvinceCode TYPE set(0) GRANULARITY 5;Alter table wms.wms_order_sku_local ON cluster default ADD INDEX productionEndTime_idx productionEndTime TYPE minmax GRANULARITY 5;
重建分割區索引資料:在建立二級索引前插入的資料,不能走二級索引,需要重建每個分割區的索引資料後才能生效
-- 拼接出所有資料分割區的MATERIALIZE語句select concat('alter table wms.wms_order_sku_local on cluster default ', 'MATERIALIZE INDEX productionEndTime_idx in PARTITION '||partition_id||',')from system.partswhere database = 'wms' and table = 'wms_order_sku_local'group by partition_id-- 執行上述SQL查詢出的所有MATERIALIZE語句進行重建分割區索引資料
9.4.3 final替換argMax進行去重
對比下final和argMax兩種方式的效能差距,如下SQL
-- final方式select count(distinct groupOrderCode), sum(arriveNum), count(distinct sku) from tms.group_order final prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1'-- argMax方式select count(distinct groupOrderCode), sum(arriveNumTemp), count(distinct sku) from (select argMax(groupOrderCode,version) as groupOrderCode, argMax(arriveNum,version) as arriveNumTemp, argMax(sku,version) as sku from tms.group_order prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1' group by docId)
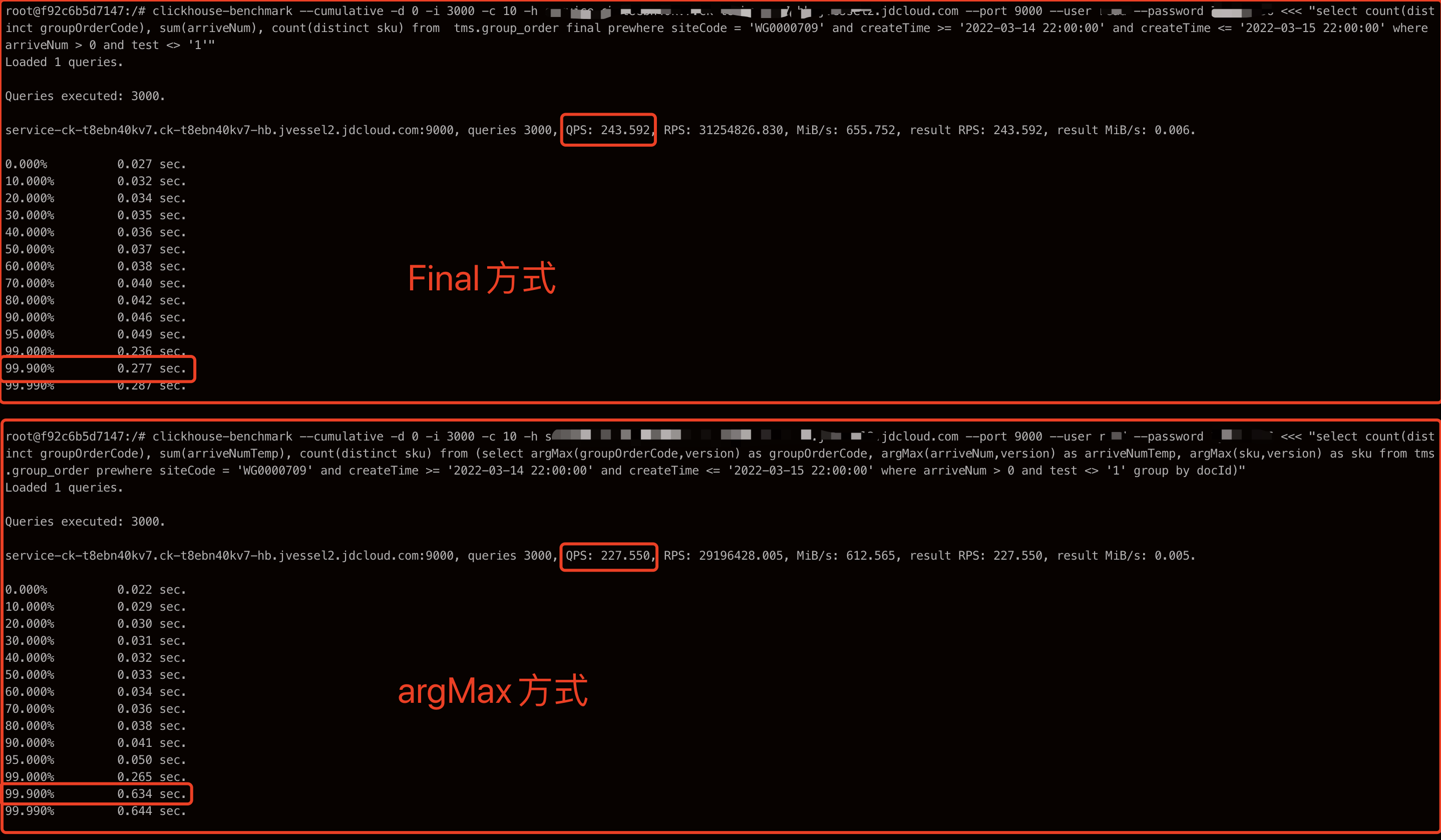
final方式的TP99明顯要比argMax方式優秀很多
9.4.4 prewhere替代where
ClickHouse的語法支援了額外的prewhere過濾條件,它會先於where條件進行判斷,可以看做是更高效率的where,作用都是過濾資料。當在sql的filter條件中加上prewhere過濾條件時,儲存掃描會分兩階段進行,先讀取prewhere表示式中依賴的列值儲存塊,檢查是否有記錄滿足條件,在把滿足條件的其他列讀出來,以下述的SQL為例,其中prewhere方式會優先掃描type,dt欄位,將符合條件的列取出來,當沒有任何記錄滿足條件時,其他列的資料就可以跳過不讀了。相當於在Mark Range的基礎上進一步縮小掃描範圍。prewhere相比where而言,處理的資料量會更少,效能會更高。看這段話可能不太容易理解,
-- 常規方式select count(distinct orderNo) final from table_1 where type = 'outbound' and status = '1' and dt = '2021-01-01';-- prewhere方式select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;
上節我們說了使用final進行去重優化。通過final去重,並且使用prewhere進行查詢條件優化時有個坑需要注意,prewhere會優先於final進行執行,所以對於status這種值可變的欄位處理過程中,能夠查詢到中間狀態的資料行,導致最終資料不一致。

如上圖所示,docId:123_1的業務資料,進行三次寫入,到version=103的資料是最新版本資料,當我們使用where過濾status這個可變值欄位時,語句1,語句2結果如下。
--語句1:使用where + status=1 查詢,無法命中docId:123_1這行資料select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '1';--語句2:使用where + status=2 查詢,可以查詢到docId:123_1這行資料select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '2';
當我們引入prewhere後,語句3寫法:prewhere過濾status欄位時將status=1,version=102的資料會過濾出來,導致我們查詢結果不正確。正確的寫法是語句2,將不可變欄位使用prewhere進行優化。
-- 語句3:錯誤方式,將status放到prewhereselect count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' and status = '1';-- 語句4:正確prewhere方式,status可變欄位放到where上select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;
其他限制:prewhere目前只能用於MergeTree系列的表引擎
9.4.5 列裁剪,分割區裁剪
ClickHouse 非常適合儲存巨量資料量的寬表,因此我們應該避免使用 SELECT * 操作,這是一個非常影響的操作。應當對列進行裁剪,只選擇你需要的列,因為欄位越少,消耗的 IO 資源就越少,從而效能就越高。
而分割區裁剪就是唯讀取需要分割區,控制好分割區欄位查詢範圍。
9.4.6 where、group by 順序
where和group by中的列順序,要和建表語句中order by的列順序統一,並且放在最前面使得它們有連續不間斷的公共字首,否則會影響查詢效能。
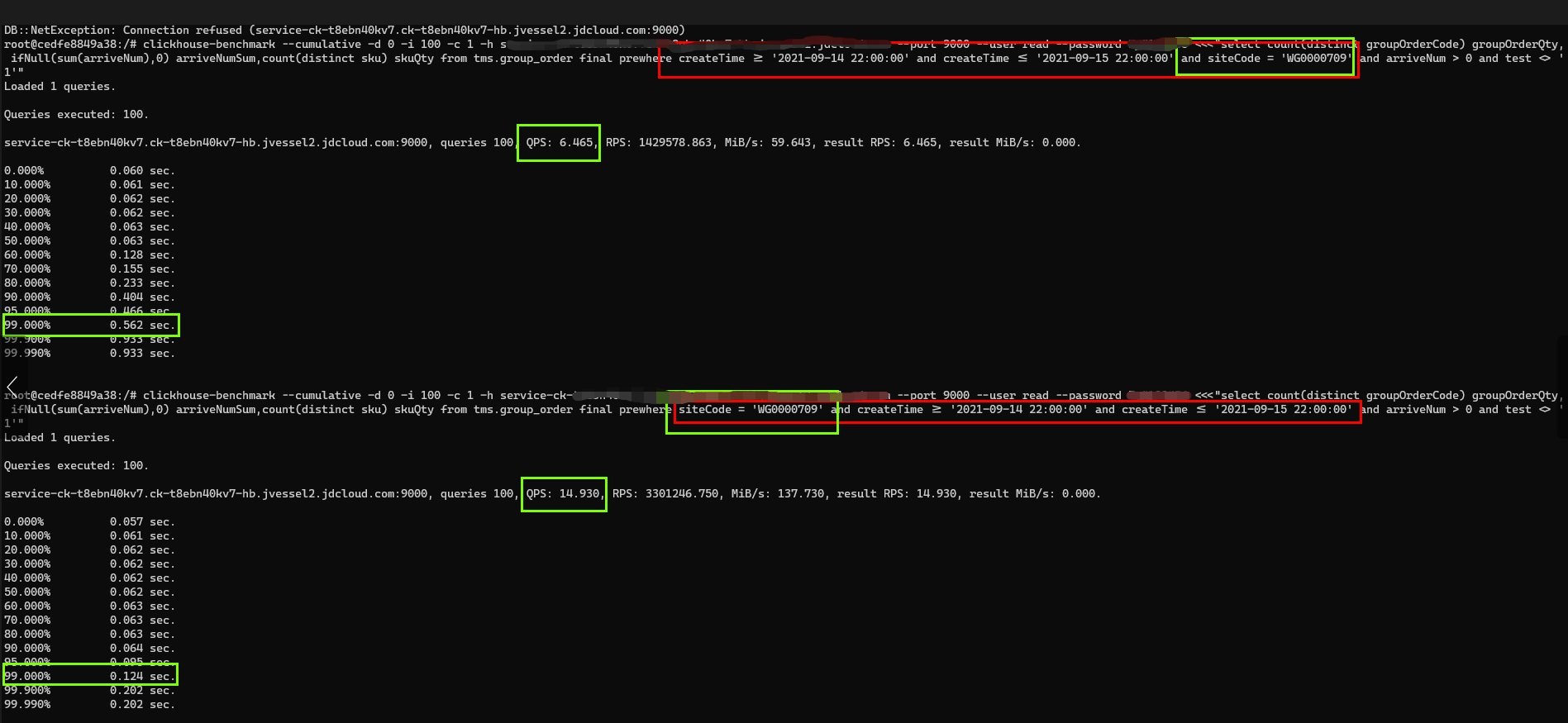
-- 建表語句create table group_order_local( docId String, version UInt64, siteCode String, groupOrderCode String, sku String, ... 省略非關鍵欄位 ... createTime DateTime) engine = ReplicatedReplacingMergeTree('/clickhouse/tms/group_order/{shard}', '{replica}', version)PARTITION BY toYYYYMM(createTime)ORDER BY (siteCode, groupOrderCode, sku);--查詢語句1select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere createTime >= '2021-09-14 22:00:00' and createTime <= '2021-09-15 22:00:00'and siteCode = 'WG0000709'where arriveNum > 0 and test <> '1'--查詢語句2 (where/prewhere中欄位)select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere siteCode = 'WG0000709' and createTime >= '2021-09-14 22:00:00' and createTime <= '2021-09-15 22:00:00'where arriveNum > 0 and test <> '1'
建表語句 ORDER BY (siteCode, groupOrderCode, sku),語句1沒有符合要求經過壓測QPS6.4,TP99 0.56s,語句2符合要求經過壓測QPS 14.9,TP99 0.12s
10 如何抗住高並行、保證ClickHouse可用性
1)降低查詢速度,提高吞吐量
max_threads:位於 users.xml 中,表示單個查詢所能使用的最大 CPU 個數,預設是 CPU 核數,假如機器是32C,則會起32個執行緒來處理當前請求。可以把max_threads調低,犧牲單次查詢速度來保證ClickHouse的可用性,提升並行能力。可通過jdbc的url來設定

下圖是基於32C128G設定,在保證CK叢集能夠提供穩定服務CPU使用率在50%的情況下針對max_threads做的一個壓測,介面級別壓測,一次請求執行5次SQL,處理資料量508W行。可以看出max_threads越小,QPS越優秀TP99越差。可根據自身業務情況來進行調整一個合適的設定值。

2)介面增加一定時間的快取
3)非同步任務執行查詢語句,將聚合指標結果落到ES中,應用查詢ES中的聚合結果
4)物化檢視,通過預聚合方式解決這種問題,但是我們這種業務場景不適用
11 資料集合
•更改ORDER BY欄位,PARTITION BY,備份資料,單表遷移資料等操作
•基於docker搭建clickhouse-client連結ck叢集
作者:京東物流 馬紅巖
內容來源:京東雲開發者社群