C#使用詞嵌入向量與向量資料庫為大語言模型(LLM)賦能長期記憶實現私域問答機器人落地之openai介面平替
------------恢復內容開始------------
在上一篇文章中我們大致講述了一下如何通過詞嵌入向量的方式為大語言模型增加長期記憶,用於落地在私域場景的問題。其中涉及到使用openai的介面進行詞嵌入向量的生成以及chat模型的呼叫
由於眾所周知的原因,國內呼叫openai介面並不友好,所以今天介紹兩款開源平替實現分別替代詞嵌入向量和文字生成。
照例還是簡單繪製一下拓撲圖:
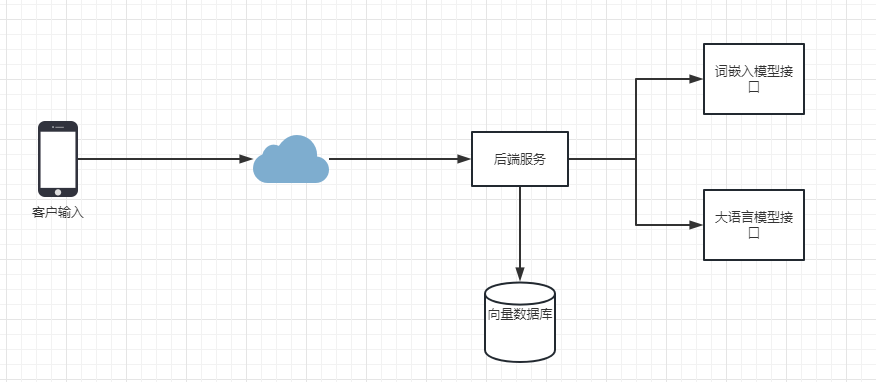
從拓撲上來看還是比較簡單的,一個後端服務用於業務處理,兩個AI模型服務用於詞嵌入向量和文字生成以及一個向量資料庫(這裡依然採用es,下同),接著我們來看看流程圖:
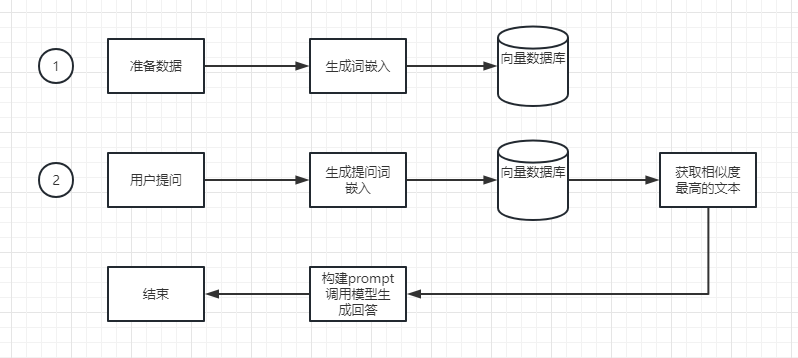
從流程圖上來講,我們依然需要有兩個階段的準備,在一階段,我們需要構建私域回答的文字,這些文字往往以字串的形式被輸入到嵌入介面,然後獲取到嵌入介面的嵌入向量。再以es索引的方式被寫入到向量庫。而在第二階段,也就是對外提供服務的階段,我們會將使用者的問題呼叫嵌入介面生成它的詞嵌入向量,然後通過向量資料庫的文字相似度匹配獲取到近似的回答,比如提問「青椒炒肉時我的鹽應該放多少」。向量庫相似的文字裡如果包含了和該烹飪有關的文字會返回1到多條回答。接著我們在後端構建一個prompt,和之前的文章類似。最後呼叫我們的文字生成模型進行問題的回答。整個流程結束。
接下來我們看看如何使用和部署這些模型以及c#相關程式碼的編寫
重要:在開始之前,請確保你的部署環境安裝了16G視訊記憶體的Nvidia顯示卡或者48G以上的記憶體。前者用於基於顯示卡做模型推理,效果比較好,速度生成合理。後者基於CPU推理,速度較慢,僅可用於部署測試。如果基於顯示卡部署,需要單獨安裝CUDA11.8同時需要安裝nvidia-docker2套件用於docker上的gpu支援,這裡不再贅述安裝過程
首先我們需要下載詞嵌入模型,這裡推薦使用text2vec-large-chinese這個模型,該模型針對中文文字進行過微調。效果較好。
下載地址如下:https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main
我們需要下載它的pytorch_model.bin、config.json、vocab.txt這三個檔案用於構建我們的詞嵌入服務
接著我們在下載好的資料夾裡,新建一個web.py。輸入以下內容:
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
from transformers import AutoTokenizer, AutoModel
import torch
app = FastAPI()
# Load the model and tokenizer
model = AutoModel.from_pretrained("/app").half().cuda()
tokenizer = AutoTokenizer.from_pretrained("/app")
# Request body
class Sentence(BaseModel):
sentence: str
@app.post("/embed")
async def embed(sentence: Sentence):
# Tokenize the sentence and get the input tensors
inputs = tokenizer(sentence.sentence, return_tensors='pt', padding=True, truncation=True, max_length=512)
# Move inputs to GPU
for key in inputs.keys():
inputs[key] = inputs[key].to('cuda')
# Run the model
with torch.no_grad():
outputs = model(**inputs)
# Get the embeddings
embeddings = outputs.last_hidden_state[0].cpu().numpy()
# Return the embeddings as a JSON response
return embeddings.tolist()
以上是基於gpu版本的api。如果你沒有gpu支援,那麼可以使用以下程式碼:
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
from transformers import AutoTokenizer, AutoModel
import torch
app = FastAPI()
# Load the model and tokenizer
model = AutoModel.from_pretrained("/app").half()
tokenizer = AutoTokenizer.from_pretrained("/app")
# Request body
class Sentence(BaseModel):
sentence: str
@app.post("/embed")
async def embed(sentence: Sentence):
# Tokenize the sentence and get the input tensors
inputs = tokenizer(sentence.sentence, return_tensors='pt', padding=True, truncation=True, max_length=512)
# No need to move inputs to GPU as we are using CPU
# Run the model
with torch.no_grad():
outputs = model(**inputs)
# Get the embeddings
embeddings = outputs.last_hidden_state[0].cpu().numpy()
# Return the embeddings as a JSON response
return embeddings.tolist()
這裡我們使用一個簡單的pyhont web框架fastapi對外提供服務。接著我們將之前下載的模型和py程式碼放在一起,並且建立一個 requirements.txt用於構建映象時下載依賴, requirements.txt包含
torch transformers fastapi uvicorn
其中前兩個是模型需要使用的庫/框架,後兩個是web服務需要的庫框架,接著我們在編寫一個Dockerfile用於構建映象:
FROM python:3.8-slim-buster # Set the working directory to /app WORKDIR /app # Copy the current directory contents into the container at /app ADD . /app # Install any needed packages specified in requirements.txt RUN pip install --trusted-host pypi.python.org -r requirements.txt # Run app.py when the container launches ENV MODULE_NAME=web
ENV VARIABLE_NAME=app
ENV HOST=0.0.0.0
ENV PORT=80
# Run the application:
CMD uvicorn ${MODULE_NAME}:${VARIABLE_NAME} --host ${HOST} --port ${PORT}
接著我們就可以基於以上內容構建映象了。直接執行docker build . -t myembed:latest等待編譯即可
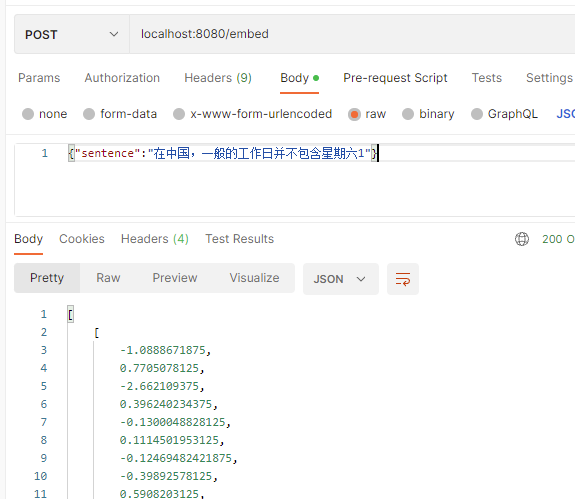
映象編譯完畢後,我們可以在本機執行它:docker run -dit --gpus all -p 8080:80 myembed:latest。注意如果你是cpu環境則不需要新增「--gpus all」。接著我們可以通過postman模擬存取介面,看是否可以生成向量,如果一切順利,它將生成一個巢狀的多維陣列,如下所示:
接著我們需要同樣的辦法去炮製語言大模型的介面,這裡我們採用國內相對成熟的開源大語言模型Chat-glm-6b。首先我們新建一個資料夾,然後用git拉取它的web服務相關的程式碼:
git clone https://github.com/THUDM/ChatGLM-6B.git
接著我們需要下載它的模型權重檔案,地址:https://huggingface.co/THUDM/chatglm-6b/tree/main。下載從pytorch_model-00001-of-00008.bin到pytorch_model-00008-of-00008.bin的8個權重檔案放在git根目錄
接著我們修改api.py的程式碼:
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
import asyncio
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
@app.post("/chat", response_class=StreamingResponse)
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
last_response = ''
async def stream_chat():
nonlocal last_response,history
for response, history in model.stream_chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95):
new_part = response[len(last_response):]
last_response = response
yield json.dumps(new_part,ensure_ascii=False)
return StreamingResponse(stream_chat(), media_type="text/plain")
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("/app", trust_remote_code=True)
model = AutoModel.from_pretrained("/app", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=80, workers=1)
同樣的如果你是cpu版本的環境,你需要將(這裡注意,如果你有顯示卡,但是視訊記憶體並不足16G。那麼可以考慮8bit或者4bit量化,具體參閱https://github.com/THUDM/ChatGLM-6B的readme.md)
model = AutoModel.from_pretrained("/app", trust_remote_code=True).half().cuda()
修改為
model = AutoModel.from_pretrained("/app", trust_remote_code=True)
剩餘的流程和之前部署向量模型類似,由於專案中已經包含了,建立對應的 requirements.txt,我們只需要建立類似詞嵌入向量的Dockerfile即可編譯。
FROM python:3.8-slim-buster WORKDIR /app ADD . /app RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple CMD ["python", "api.py"]
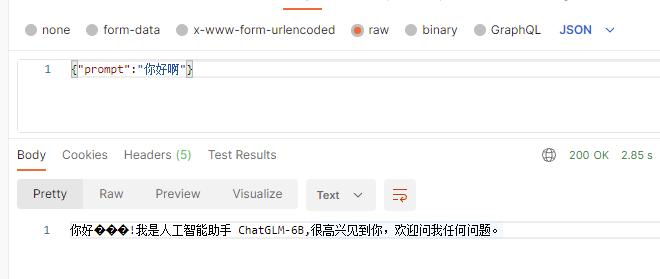
完成後可以使用docker run -dit --gpus all -p 8081:80 myllm:latest啟動測試,同樣的使用postman模擬存取介面,順利的話我們應該能夠看到如下內容不要在意亂碼的部分那是emoji沒有正確解析的問題:
接下來我們需要構建c#後端程式碼,將這些基礎服務連線起來,這裡我使用一個本地靜態字典來模擬詞嵌入向量的儲存和餘弦相似度查詢相似文字,就不再贅述使用es做向量庫,兩者的效果基本一致的。感興趣的同學去搜尋NEST庫和es基於餘弦相似度搜尋相關的內容即可
核心程式碼如下,這裡我提供兩個介面,第一個介面用於獲取前端輸入的文字做詞嵌入並進行儲存,第二個介面用於回答問題。
///用於模擬向量庫
private Dictionary<string, List<double>> MemoryList = new Dictionary<string, List<double>>();
///用於計算相似度
double Compute(List<double> vector1, List<double> vector2) => vector1.Zip(vector2, (a, b) => a * b).Sum() / (Math.Sqrt(vector1.Sum(a => a * a)) * Math.Sqrt(vector2.Sum(b => b * b)));
...
[HttpPost("/api/save")]
public async Task<int> SaveMemory(string str)
{
if (!string.IsNullOrEmpty(str))
{
foreach (var x in memory.Split("\n").ToList())
{
if (!MemoryList.ContainsKey(x))
{
MemoryList.Add(x, await GetEmbeding(x));
StateHasChanged();
}
}
}
return MemoryList.Count;
}
...
[HttpPost("/api/chat")]
public async IAsyncEnumerable<string> SendData(string content)
{
if (!string.IsNullOrEmpty(content))
{
var userquestionEmbeding = await GetEmbeding(content);
var prompt = "";
if (MemoryList.Any())
{ //這裡從向量庫中獲取到第一條,你可以根據實際情況設定比如相似度閾值或者返回多條等等
prompt = MemoryList.OrderByDescending(x => Compute(userquestionEmbeding, x.Value)).FirstOrDefault().Key;
prompt = $"你是一個問答小助手,你需要基於以下事實依據回答問題,事實依據如下:{prompt}。使用者的問題如下:{Content}。不要編造事實依據,請回答:";
}
else
prompt = Content;
await foreach (var item in ChatStream(prompt))
{
yield return item;
}
}
}
同時我們需要提供兩個函數用於使用httpclient存取AI模型的api:
async IAsyncEnumerable<string> ChatStream(string x)
{
HttpClient hc = new HttpClient();
var reqcontent = new StringContent(System.Text.Json.JsonSerializer.Serialize(new { prompt = x }));
reqcontent.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("application/json");
var response = await hc.PostAsync("http://192.168.1.100:8081/chat", reqcontent);
if (response.IsSuccessStatusCode)
{
var responseStream = await response.Content.ReadAsStreamAsync();
using (var reader = new StreamReader(responseStream, Encoding.UTF8))
{
string line;
while ((line = await reader.ReadLineAsync()) != null)
{
yield return line;
}
}
}
}
async Task<List<double>> GetEmbeding(string x)
{
HttpClient hc = new HttpClient();
var reqcontent = new StringContent(System.Text.Json.JsonSerializer.Serialize(new { sentence = x }));
reqcontent.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("application/json");
var result = await hc.PostAsync("http://192.168.1.100:8080/embed", reqcontent);
var content = await result.Content.ReadAsStringAsync();
var embed = System.Text.Json.JsonSerializer.Deserialize<List<List<double>>>(content);
var embedresult = new List<double>();
for (var i = 0; i < 1024; i++)
{
double sum = 0;
foreach (List<double> sublist in embed)
{
sum += (sublist[i]);
}
embedresult.Add(sum / 1024);
}
return embedresult;
}
接下來我們可以測試一下效果,當模型沒有引入記憶的情況下,詢問一個問題,它會自己編造回答:

接著我們在向量庫中新增多條記憶後再進行問詢,模型即可基本正確的對內容進行回答。
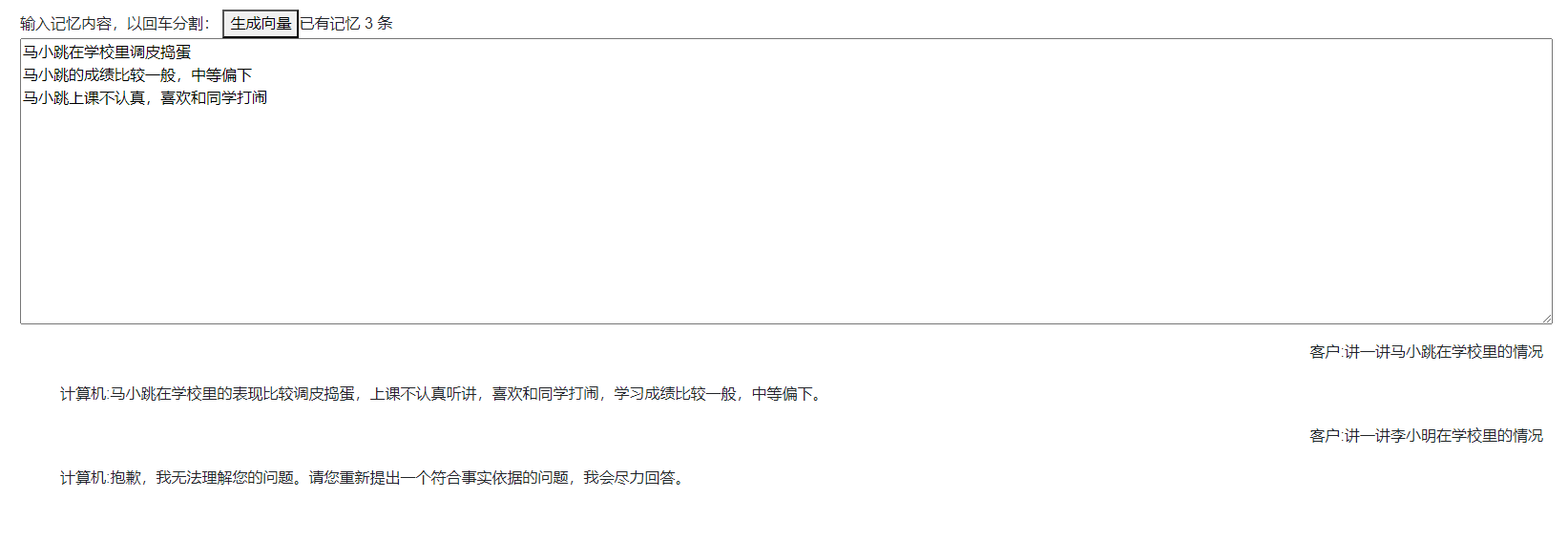
以上就是本次部落格的全部內容,相比上一個章節我們使用基於openai的介面來講基於本地部署應該更符合大多數人的情況,以上