程式碼壞味道(一)
GC 優化
1.防止大物件Buffer到記憶體中
現象:當大包請求時,YGC 耗時嚴重
原因:預設情況下 Zuul2 並不會快取請求體(DirectByteBuffer),也就意味著它會先傳送接收到的請求 Headers 到後端服務,之後接收到請求體再繼續傳送到後端服務,傳送請求體的時候,也不是組裝為一個完整資料之後才發,而是接收到一部分,就轉發一部分。
如果需要快取請求體:
需要 Override needsBodyBuffered 方法, com.netflix.zuul.netty.filter.BaseZuulFilterRunner#filter
針對大包請求時,閘道器效能降低,體現在:閘道器操作會將請求體 Buffer 到使用者空間來實現提取請求體做 WAF 攔截
優化:
- 判斷大包,大包不快取(Content-Length)
2.防止多次建立重複物件
現象:YGC 次數多
原因:
如何快速獲取 Body?Zuul 貼心的為我們提供瞭如下兩種方式,封裝在過 Request 中供開發者使用
com.netflix.zuul.message.ZuulMessageImpl#getBodyAsText
com.netflix.zuul.message.ZuulMessageImpl#getBody
但不幸的是,內部每次獲取物件繁瑣,並且 new String() 建立返回
優化:
取一次,快取在 Context 中,需要時從 Context 獲取
3.防止多次建立中間物件
現象:YGC 次數多
原因 :多次建立中間無用物件,例如:ProtobufSerializer#serialize
@Override
public byte[] serialize(String topic, Object data) {
if (data == null) {
return null;
}
return JSON.toJSONString(data).getBytes();
}
優化:直接序列化成 byte,不需要先建立中間物件 String,再 getBytes()
CPU 優化
1.減少執行緒個數,降低上下文切換次數
現象:無關執行緒太多,影響記憶體(JVM+作業系統)+CPU 爭搶
原因:閘道器內有生產者,消費者,每個消費者都會有消費軌跡的執行緒池(10),閘道器有針對不同場景下的消費者,故會建立諸多訊息軌跡執行緒
優化:
- 禁用訊息軌跡
- 調整消費者執行緒數
2.減少字串比較次數
現象:每次請求到自定義的 Route Filter,都要通過 Loop 快取獲取到和當前 RequestMethod 一致的 Rest API。通過火焰圖可以看出,單位時間內,該部分邏輯 CPU 計算佔比高
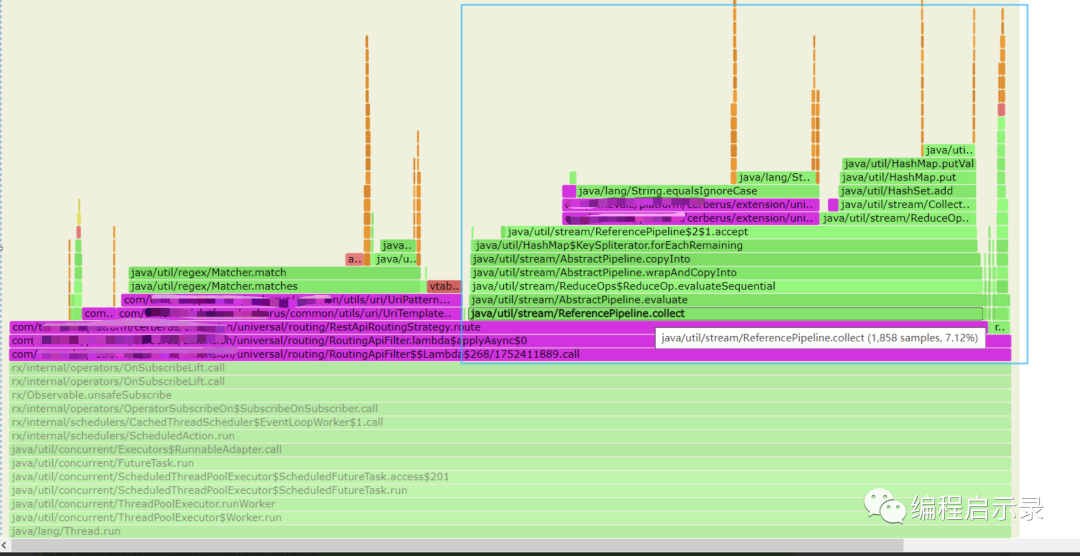
原因 :
Set<String> apis=restApiManager.getApis().stream().filter(a -> method.equalsIgnoreCase(a.getHttpMethod())).collect(Collectors.toSet());
本意是過濾掉和當前 Request Method 不一致的,但是每請求一次,都需要重複計算過濾:O(n)
優化:O(1),改為 HashMap,Key 為 Method,Value 為 Set <String> apis,封裝統一方法獲取,RestApiManager#getApis(String method)
3.減少正規表示式計算次數
現象:API 路由需要正則匹配,最終確定需要路由的 Service。通過火焰圖可以看出,單位時間內,該部分邏輯 CPU 計算佔比高

原因:API 路由需要正則匹配,最終確定需要路由的 Service
優化:通過字首匹配,過濾掉非法的API。比如存取:/v1/accounts/{accountId}/getAllInfo,先過濾掉非 /v1/accounts 開頭的 API,因為正則肯定不匹配
4.減少序列化
現象:序列化需要CPU運算,減少不必要的序列化場景可以提高吞吐量
原因:針對相同請求的話,WAF 裡需要計算出一個簽名,減少攻擊驗證次數。
因為計算相同內容的 MD5,將物件序列化成 JSON。在高並行下序列化會大量佔用 CPU。
signature = buildSignature(objectMapper.writeValueAsString(requestMessage));
優化:
使用 ToString 來替換序列化:
signature = buildSignature(requestMessage.toString())
其他優化
- 不打無用紀錄檔,紀錄檔需要編碼,需要 CPU 消耗