LLM探索:GPT類模型的幾個常用引數 Top-k, Top-p, Temperature
2023-05-24 12:00:16
前言
上一篇文章介紹了幾個開源LLM的環境搭建和本地部署,在使用ChatGPT介面或者自己本地部署的LLM大模型的時候,經常會遇到這幾個引數,本文簡單介紹一下~
- temperature
- top_p
- top_k
關於LLM
上一篇也有介紹過,這次看到一個不錯的圖
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.
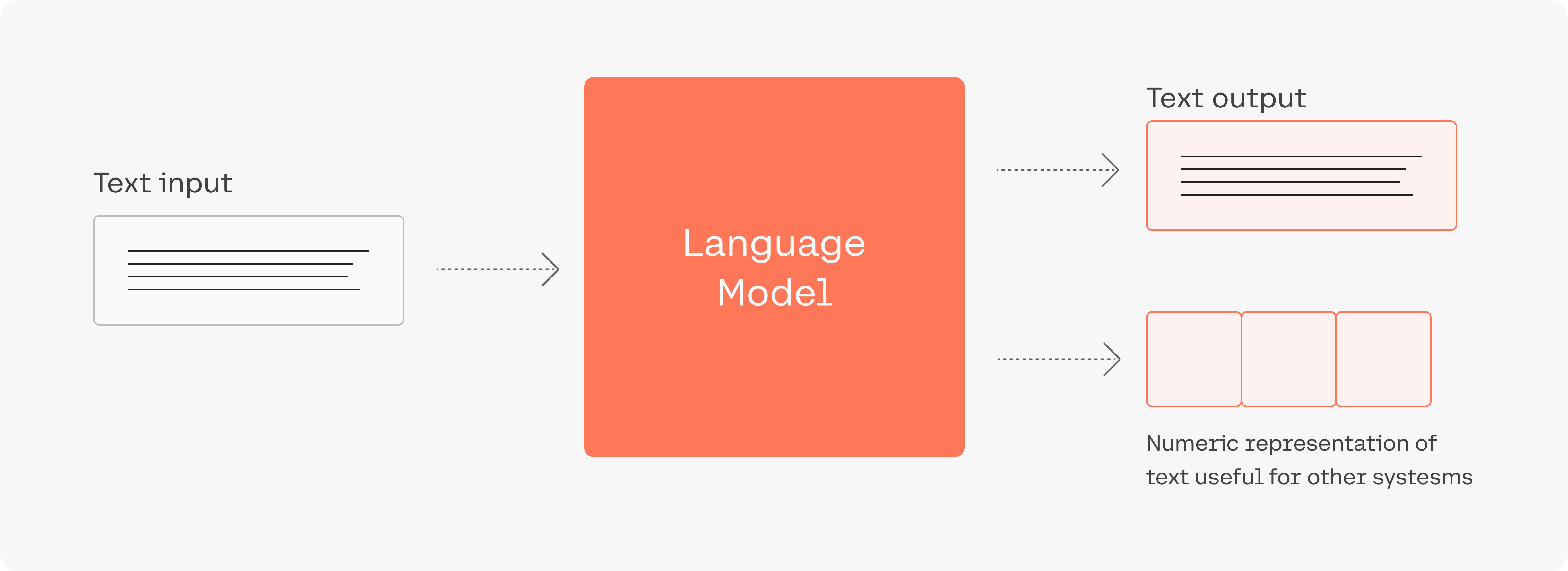
LLM看似很神奇,但本質還是一個概率問題,神經網路根據輸入的文字,從預訓練的模型裡面生成一堆候選詞,選擇概率高的作為輸出,上面這三個引數,都是跟取樣有關(也就是要如何從候選詞裡選擇輸出)。
temperature
用於控制模型輸出的結果的隨機性,這個值越大隨機性越大。一般我們多次輸入相同的prompt之後,模型的每次輸出都不一樣。
- 設定為 0,對每個prompt都生成固定的輸出
- 較低的值,輸出更集中,更有確定性
- 較高的值,輸出更隨機(更有創意