越小越好: Q8-Chat,在英特爾至強 CPU 上體驗高效的生成式 AI
大語言模型 (LLM) 正在席捲整個機器學習世界。得益於其 transformer 架構,LLM 擁有從大量非結構化資料 (如文字、影象、視訊或音訊) 中學習的不可思議的能力。它們在 多種任務型別 上表現非常出色,無論是文字分類之類的抽取任務 (extractive task) 還是文字摘要和文生影象之類的生成任務 (generative task)。
顧名思義,LLM 是 _大_模型,其通常擁有超過 100 億個引數,有些甚至擁有超過 1000 億個引數,如 BLOOM 模型。 LLM 需要大量的算力才能滿足某些場景 (如搜尋、對話式應用等) 的低延遲需求。而大算力通常只有高階 GPU 才能提供,不幸的是,對於很多組織而言,相關成本可能高得令人望而卻步,因此它們很難在其應用場景中用上最先進的 LLM。
在本文中,我們將討論有助於減少 LLM 尺寸和推理延遲的優化技術,以使得它們可以在英特爾 CPU 上高效執行。
量化入門
LLM 通常使用 16 位浮點引數 (即 FP16 或 BF16) 進行訓練。因此,儲存一個權重值或啟用值需要 2 個位元組的記憶體。此外,浮點運算比整型運算更復雜、更慢,且需要額外的計算能力。
量化是一種模型壓縮技術,旨在通過減少模型引數的值域來解決上述兩個問題。舉個例子,你可以將模型量化為較低的精度,如 8 位整型 (INT8),以縮小它們的位寬並用更簡單、更快的整型運算代替複雜的浮點運算。
簡而言之,量化將模型引數縮放到一個更小的值域。一旦成功,它會將你的模型縮小至少 2 倍,而不會對模型精度產生任何影響。
你可以進行訓時量化,即量化感知訓練 (QAT),這個方法通常精度更高。如果你需要對已經訓成的模型進行量化,則可以使用訓後量化 (PTQ),它會更快一些,需要的算力也更小。
市面上有不少量化工具。例如,PyTorch 內建了對 量化 的支援。你還可以使用 Hugging Face Optimum-Intel 庫,其中包含面向開發人員的 QAT 和 PTQ API。
量化 LLM
最近,有研究 [1][2] 表明目前的量化技術不適用於 LLM。LLM 中有一個特別的現象,即在每層及每個詞向量中都能觀察到某些特定的啟用通道的幅度異常,即某些通道的啟用值的幅度比其他通道更大。舉個例子,下圖來自於 OPT-13B 模型,你可以看到在所有詞向量中,其中一個通道的啟用值比其他所有通道的大得多。這種現象在每個 transformer 層中都存在。
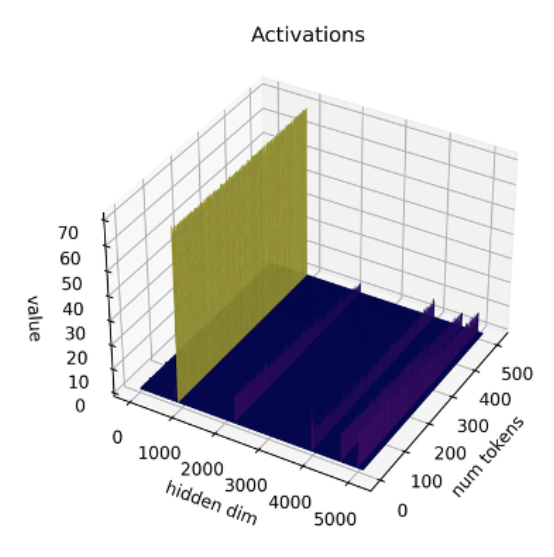
圖源: SmoothQuant 論文
迄今為止,最好的啟用量化技術是逐詞量化,而逐詞量化會導致要麼離群值 (outlier) 被截斷或要麼幅度小的啟用值出現下溢,它們都會顯著降低模型質量。而量化感知訓練又需要額外的訓練,由於缺乏計算資源和資料,這在大多數情況下是不切實際的。
SmoothQuant [3][4] 作為一種新的量化技術可以解決這個問題。其通過對權重和啟用進行聯合數學變換,以增加權重中離群值和非離群值之間的比率為代價降低啟用中離群值和非離群值之間的比率,從而行平滑之實。該變換使 transformer 模型的各層變得「量化友好」,並在不損害模型質量的情況下使得 8 位量化重新成為可能。因此,SmoothQuant 可以幫助生成更小、更快的模型,而這些模型能夠在英特爾 CPU 平臺上執行良好。
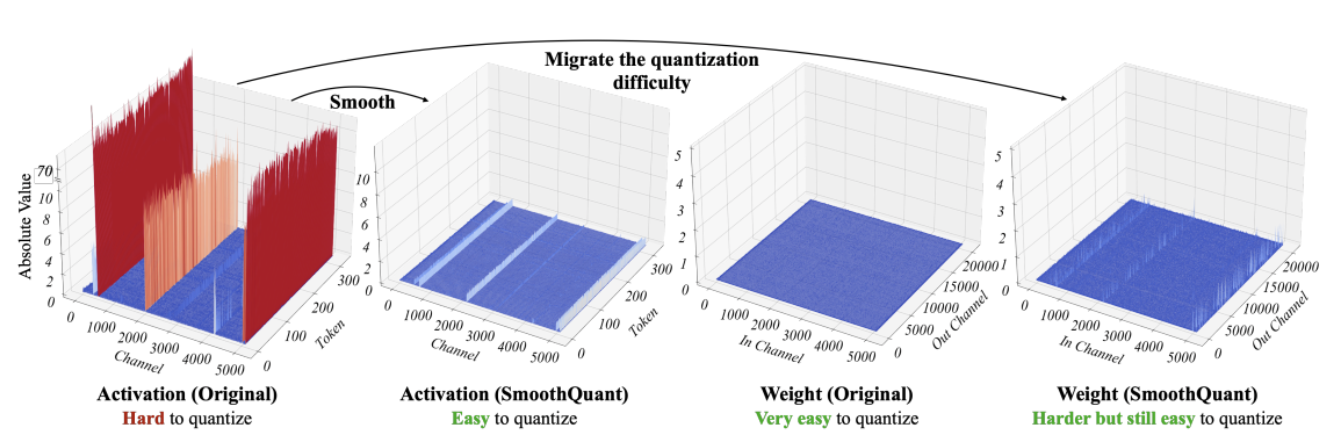
圖源: SmoothQuant 論文
現在,我們看看 SmoothQuant 在流行的 LLM 上效果如何。
使用 SmoothQuant 量化 LLM
我們在英特爾的合作伙伴使用 SmoothQuant-O3 量化了幾個 LLM,分別是: OPT 2.7B、6.7B [5],LLaMA 7B [6],Alpaca 7B [7],Vicuna 7B [8],BloomZ 7.1B [9] 以及 MPT-7B-chat [10]。他們還使用 EleutherAI 的語言模型評估工具 對量化模型的準確性進行了評估。
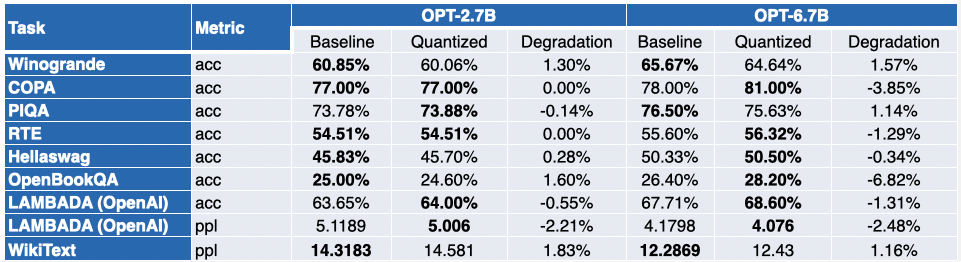
下表總結了他們的發現。第二列展示了量化後效能反而得到提升的任務數。第三列展示了量化後各個任務平均效能退化的均值 (* 負值表示量化後模型的平均效能提高了)。你可以在文末找到詳細結果。
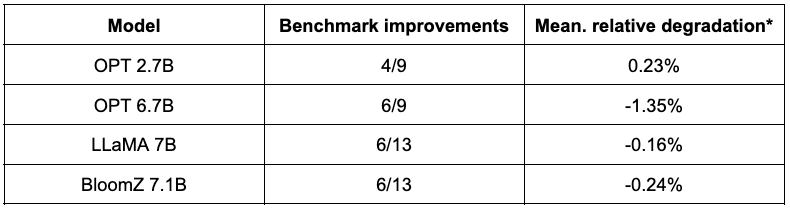
如你所見,OPT 模型非常適合 SmoothQuant 量化。模型比預訓練的 16 位模型約小 2 倍。大多數指標都會有所改善,而那些沒有改善的指標僅有輕微的降低。
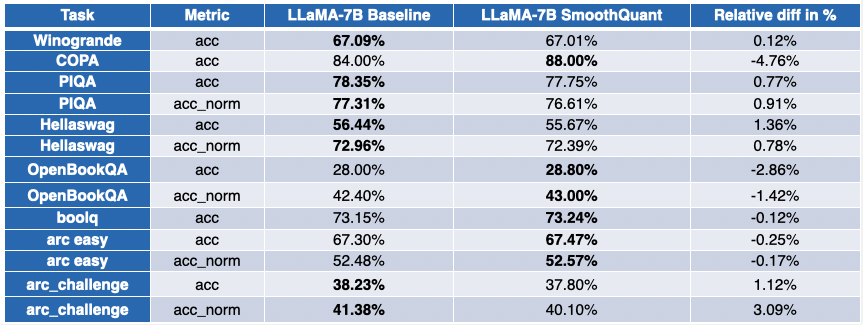
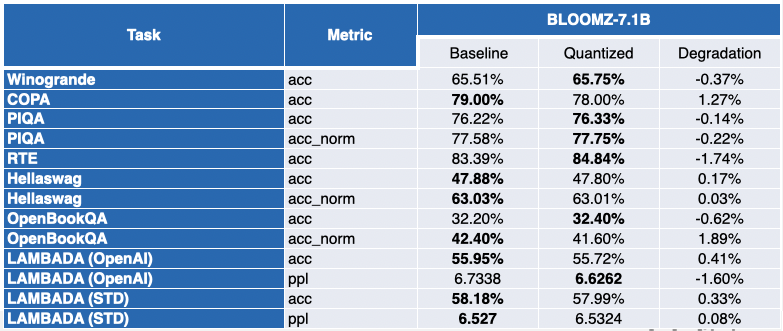
對於 LLaMA 7B 和 BloomZ 7.1B,情況則好壞參半。模型被壓縮了約 2 倍,大約一半的任務的指標有所改進。但同樣,另一半的指標僅受到輕微影響,僅有一個任務的相對退化超過了 3%。
使用較小模型的明顯好處是推理延遲得到了顯著的降低。該 視訊 演示了在一個 32 核心的單路英特爾 Sapphire Rapids CPU 上使用 MPT-7B-chat 模型以 batch size 1 實時生成文字的效果。
在這個例子中,我們問模型: 「 What is the role of Hugging Face in democratizing NLP? 」。程式會向模型傳送以下提示:
「 A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions. USER: What is the role of Hugging Face in democratizing NLP? ASSISTANT: 」
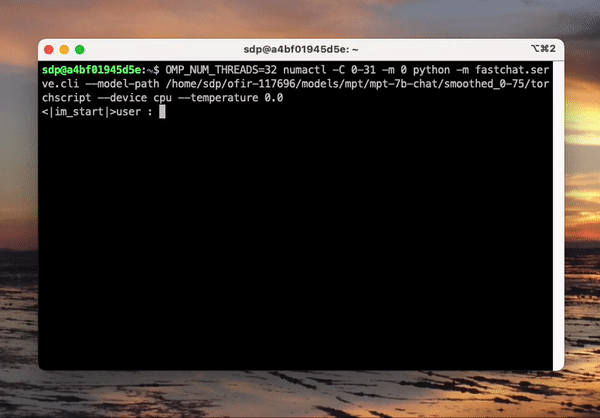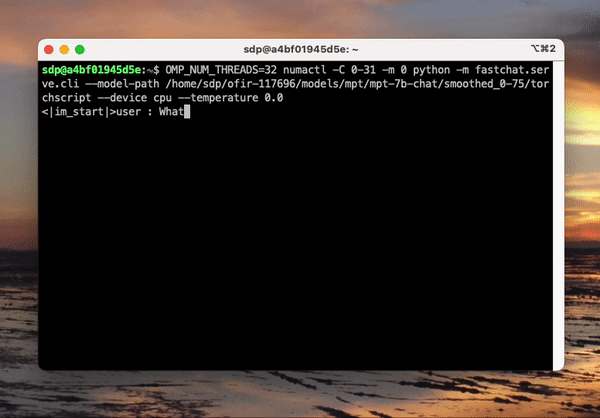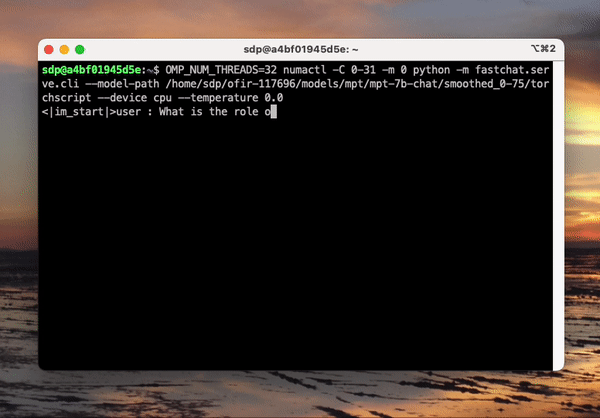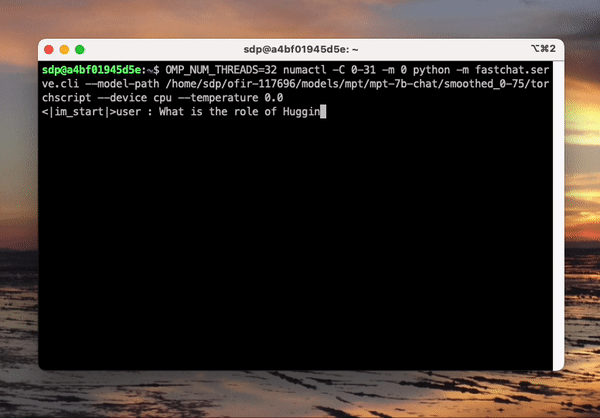
這個例子展示了 8 位量化可以在第 4 代至強處理器上獲得額外的延遲增益,從而使每個詞的生成時間非常短。這種效能水平無疑使得在 CPU 平臺上執行 LLM 成為可能,從而為客戶提供比以往任何時候都更大的 IT 靈活性和更好的價效比。
在至強 CPU 上體驗聊天應用
HuggingFace 的執行長 Clement 最近表示: 「專注於訓練和執行成本更低的小尺寸、垂域模型,會使更多的公司會收益。」 Alpaca、BloomZ 以及 Vicuna 等小模型的興起,為企業在生產中降低微調和推理成本的創造了新機會。如上文我們展示的,高質量的量化為英特爾 CPU 平臺帶來了高質量的聊天體驗,而無需龐大的 LLM 和複雜的 AI 加速器。
我們與英特爾一起在 Spaces 中建立了一個很有意思的新應用演示,名為 Q8-Chat (發音為 Cute chat)。Q8-Chat 提供了類似於 ChatGPT 的聊天體驗,而僅需一個有 32 核心的單路英特爾 Sapphire Rapids CPU 即可 (batch size 為 1)。
Space 體驗地址: https://intel-q8-chat.hf.space
下一步
我們正致力於將 Intel Neural Compressor 整合入 Hugging Face Optimum Intel,從而使得 Optimum Intel 能夠利用這一新量化技術。一旦完成,你只需幾行程式碼就可以復現我們的結果。
敬請關注。
未來屬於 8 位元!
本文保證純純不含 ChatGPT。
致謝
本文系與來自英特爾實驗室的 Ofir Zafrir、Igor Margulis、Guy Boudoukh 和 Moshe Wasserblat 共同完成。特別感謝他們的寶貴意見及合作。
附錄: 詳細結果
負值表示量化後效能有所提高。

英文原文: https://hf.co/blog/generative-ai-models-on-intel-cpu
原文作者: Julien Simon
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態資料上的應用及大規模模型的訓練推理。
審校/排版: zhongdongy (阿東)