Redis記憶體兜底策略——記憶體淘汰及回收機制
Redis記憶體兜底策略——記憶體淘汰及回收機制
Redis記憶體淘汰及回收策略都是Redis記憶體優化兜底的策略,那它們是如何進行兜底的呢?先來說明一下什麼是記憶體淘汰和記憶體回收策略:
- Redis記憶體淘汰:當Redis的記憶體使用超過設定的限制時,根據一定的策略刪除一些鍵,以釋放記憶體空間
- Redis記憶體回收:Redis通過定期刪除和惰性刪除兩種方式來清除過期的鍵,以保證資料的時效性和減少記憶體佔用
記憶體淘汰策略
Redis記憶體淘汰策略是指當Redis的記憶體使用超過設定的最大值時,如何選擇一些鍵進行刪除,以釋放空間給新的資料。Redis提供了八種記憶體淘汰策略,分別是:
- noeviction:不會淘汰任何鍵,達到記憶體限制後返回錯誤
- allkeys-random:在所有鍵中,隨機刪除鍵
- volatile-random:在設定了過期時間的鍵中,隨機刪除鍵
- allkeys-lru:通過LRU演演算法淘汰最近最少使用的鍵,保留最近使用的鍵
- volatile-lru:從設定了過期時間的鍵中,通過LRU演演算法淘汰最近最少使用的鍵
- allkeys-lfu:從所有鍵中淘汰使用頻率最少的鍵。從所有鍵中驅逐使用頻率最少的鍵
- volatile-lfu:從設定了過期時間的鍵中,通過LFU演演算法淘汰使用頻率最少的鍵
- volatile-ttl:從設定了過期時間的鍵中,淘汰馬上就要過期的鍵
LRU和LFU
LRU(least frequently used)演演算法為最近最少使用演演算法,根據資料的歷史存取記錄來進行淘汰資料,優先移除最近最少使用的資料,這種演演算法認為最近使用的資料很大概率將會再次被使用
LFU(least frequently used)演演算法為最少頻率使用演演算法,優先移除使用頻率最少的資料,這種演演算法認為使用頻率高的資料很大概率將會再次被使用
LRU和Redis的近似LRU
LRU(least frequently used)演演算法為最近最少使用演演算法,根據資料的歷史存取記錄來進行淘汰資料,優先移除最近最少使用的資料,這種演演算法認為最近使用的資料很大概率將會再次被使用
什麼是LRU
在演演算法的選擇上,Redis需要能夠快速地查詢、新增、刪除資料,也就是說查詢、新增、刪除的時間複雜讀需為O(1)。雜湊表能保證查詢資料的時間複雜度為O(1)。而雙向連結串列能保證新增、刪除資料的時間複雜度為O(1),如下:
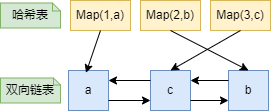
Redis的近似LRU
如前文所述,真實的 LRU 演演算法需要用連結串列管理所有的資料,每次存取一個資料就要移動連結串列節點,這樣會佔用額外的空間和時間。而Redis通過近似 LRU 演演算法,隨機抽樣一些鍵,然後比較它們的存取時間戳,這樣可以節省記憶體和提高效能。而Redis 的近似 LRU 演演算法的具體實現如下:
- 每個鍵值對物件(
redisObject)中有一個 24 位的 lru 欄位,用於記錄每個資料最近一次被存取的時間戳 - 每次按鍵獲取一個值的時候,都會呼叫
lookupKey函數,如果設定使用了 LRU 模式,該函數會更新 value 中的 lru 欄位為當前秒級別的時間戳 - 當記憶體達到限制時,Redis 會維護一個候選集合(
pool),大小為 16 - Redis 會隨機從字典中取出 N 個鍵(N 可以通過
maxmemory-samples引數設定,預設為 5),將 lru 欄位值最小的鍵放入候選集合中,並按照 lru 大小排序 - 如果候選集合已滿,那麼新加入的鍵必須有比集合中最大的 lru 值更小的 lru 值,才能替換掉原來的鍵
- 當需要淘汰資料時,直接從候選集合中選擇一個 lru 最小的鍵進行淘汰
舉個例子,假設我們按照下面的順序存取快取中的資料:h,e,l,l,o,w,o,r,l,d且記憶體中只能儲存3個字元,下面是每次存取或插入後快取的狀態,其中括號內是lru欄位的值,假設初始時間戳為0
| 快取 | 狀態 |
|---|---|
| 存取h | h(0) |
| 存取e | e(1),h(0) |
| 存取l | l(2),e(1),h(0) |
| 存取l | l(3),e(1),h(0) |
| 插入o | o(4),l(3),e(1) |
| 插入w | w(5),o(4),l(3) |
| 存取o | o(6),w(5),l(3) |
| 插入r | r(7),o(6),w(5) |
| 插入l | l(8),r(7),o(6) |
| 插入d | d(9),l(8),r(7) |
LFU
LFU(Least Frequently Used)是最不經常使用演演算法,它的思想是淘汰存取頻率最低的資料。Redis在3.0版本之後引入了LFU演演算法,並對lru欄位進行了拆分。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
我們看lru:LRU_BITS這個欄位,這個欄位在LRU演演算法中的意義是時間戳,精確到秒。而在LFU 演演算法中,將它拆為兩部分前16bits為時間戳,精確到分;後8為則表示該物件在一定時間段內被存取的次數。如下:

當Redis需要淘汰資料時,它會從記憶體中隨機抽取一定數量(預設為5個,可以通過 maxmemory-samples 引數設定)的鍵值對物件,然後比較它們的存取次數和存取時間戳,找出其中最小的那個,也就是最不經常使用且最早被存取的那個,將其從記憶體中刪除。
例如,假設我們有以下鍵值對和頻率計數器:
| 鍵 | 值 | 頻率 |
|---|---|---|
| A | 1 | 3 |
| B | 2 | 2 |
| C | 3 | 1 |
| D | 4 | 4 |
如果我們要新增一個新的鍵值對(E,5),並且快取已經滿了,那麼我們就需要淘汰一箇舊的鍵值對。我們可以隨機選擇A,B,C中的一個,並且發現C的頻率最低,為1,所以我們就淘汰C,並且新增E到快取中,並且將E的頻率設為1。這樣,快取中的資料就變成了:
| 鍵 | 值 | 頻率 |
|---|---|---|
| A | 1 | 3 |
| B | 2 | 2 |
| D | 4 | 4 |
| E | 5 | 1 |
如何選擇
在選擇上,需要根據不同的適用場景選擇不同策略,如下:
| 策略 | 特點 | 適用場景 |
|---|---|---|
| noeviction | 不刪除任何資料,當記憶體不足時返回錯誤 | 資料都是永久有效的,且記憶體足夠大 |
| allkeys-lru | 根據所有資料的存取時間來淘汰最久未存取的資料 | 資料都是永久有效的,且存取時間具有明顯規律 |
| volatile-lru | 根據設定了過期時間的資料的存取時間來淘汰最久未存取的資料 | 資料都有過期時間,且存取時間具有明顯規律 |
| allkeys-random | 隨機淘汰所有型別的資料 | 資料都是永久有效的,且存取時間沒有明顯規律 |
| volatile-random | 隨機淘汰設定了過期時間的資料 | 資料都有過期時間,且存取時間沒有明顯規律 |
| volatile-ttl | 根據設定了過期時間的資料的剩餘生命週期來淘汰即將過期的資料 | 資料都有過期時間,且剩餘生命週期具有明顯規律 |
| allkeys-lfu | 根據所有資料的存取頻率來淘汰最少存取的資料 | 資料都是永久有效的,且存取頻率具有明顯規律 |
| volatile-lfu | 根據設定了過期時間的資料的存取頻率來淘汰最少存取的資料 | 資料都有過期時間,且存取頻率具有明顯規律 |
根據8種策略的特性,也從資料完整性、快取命中率及淘汰效率這三個方面詳細對比了,如下:
- 資料完整性(是否會刪除永久有效的資料)
noeviction、volatile-lru、volatile-lfu和volatile-random都可以保證資料完整性,因為它們不會刪除永久有效的資料allkeys-lru、allkeys-lfu和allkeys-random系列的策略則會影響資料完整性,因為它們會無差別地刪除所有型別的資料
- 快取命中率(是否能夠儘可能保留最有價值的資料)
allkeys-lru和volatile-lru策略可以提高快取命中率,因為它們會根據資料的存取時間來淘汰資料allkeys-random和volatile-random策略則會降低快取命中率,因為它們會隨機淘汰資料allkeys-lfu和volatile-lfu策略也可以提高快取命中率,因為它們會根據資料的存取頻率來淘汰資料volatile-ttl策略則會降低快取命中率,因為它會根據資料的剩餘生命週期來淘汰資料
- 淘汰效率(是否能夠快速地找到並刪除目標資料)
allkeys-random和volatile-random策略可以提高執行效率,因為它們只需要隨機選擇一些資料進行刪除allkeys-lru和volatile-lru策略則會降低執行效率,因為它們需要對所有或部分資料進行排序allkeys-lfu和volatile-lfu策略也會降低執行效率,因為它們需要對所有或部分資料進行計數和排序volatile-ttl策略則會提高執行效率,因為它只需要對設定了過期時間的資料進行排序
記憶體回收策略
Redis的過期鍵刪除有兩種方式,一種是定期刪除,一種是惰性刪除
惰性刪除
Redis惰性刪除是指當一個鍵過期後,它並不會立即被刪除,而是在使用者端嘗試存取這個鍵時,Redis會檢查這個鍵是否過期,如果過期了,就會刪除這個鍵。惰性刪除由db.c/expireIfNeeded函數實現。
惰性刪除的優點是節約CPU效能,發現必須刪除的時候才刪除。缺點是記憶體壓力很大,出現長期佔用記憶體的資料。惰性刪除是Redis的預設策略,它不需要額外的設定。
惰性刪除的缺點是可能會導致過期鍵長時間佔用記憶體,如果存取頻率較低的鍵過期了,但沒有被存取到,那麼它們就不會被惰性刪除,從而浪費記憶體空間。
為了解決這個問題,Redis還採用了定期刪除和記憶體淘汰機制來配合惰性刪除,以達到更好的清理效果
定期刪除
Redis會將設定了過期時間的鍵放到一個獨立的字典中,稱為過期字典。Redis會對這個字典進行每秒10次(由組態檔中的hz引數控制)的過期掃描,過期掃描不會遍歷字典中所有的鍵,而是採用了一種簡單的貪心策略。該策略的刪除邏輯如下:
- 從過期字典中隨機選擇20個鍵
- 刪除其中已經過期的鍵
- 如果超過25%的鍵被刪除,則重複步驟1
- 如果本次掃描耗時超過1毫秒,則停止掃描
這種策略可以在一定程度上保證過期鍵能夠及時被刪除,同時也避免了對CPU時間的過度佔用。但是它也有一些缺點,比如可能會誤刪一些有效的鍵(因為隨機性),或者漏刪一些無效的鍵(因為限制了掃描時間)
因此,Redis還結合了惰性刪除策略,即在每次存取一個鍵之前,都會檢查這個鍵是否過期,如果過期就刪除,然後返回空值。這樣可以保證不返回過期的資料,也可以節省CPU時間,但是它可能會導致一些過期的鍵長期佔用記憶體,如果這些鍵很少被存取或者一直不被存取,那麼它們就永遠不會被刪除
組態檔說明
Redis記憶體淘汰、記憶體回收策略相關的組態檔如下:
# 記憶體淘汰策略
maxmemory-policy noeviction
# 抽取數量
maxmemory-samples 5
# 最大記憶體
maxmemory 100mb
# 記憶體淘汰韌性
maxmemory-eviction-tenacity 10
# 後臺任務執行間隔
hz 10
# 是否開啟動態間隔
dynamic-hz yes
組態檔說明:
- maxmemory-policy:記憶體淘汰策略,可選值為noeviction、allkeys-random、volatile-random、allkeys-lru、volatile-lru、allkeys-lfu、volatile-lfu、volatile-ttl其中的一個
- maxmemory:預設值為0,也就是不限制記憶體的使用。
- maxmemory-samples:抽取數量,預設為5,如果設為10將非常接近真實的LRU,但需要更多CPU資源,如果設為3將非常快,但是非常不準確。
- maxmemory-eviction-tenacity:記憶體淘汰韌性,預設為10
- maxmemory-eviction-tenacity為0時,表示不進行任何淘汰,相當於noeviction策略
- maxmemory-eviction-tenacity為10時,表示每次淘汰鍵的數量為記憶體使用量的0.1%,每秒最多淘汰10次
- hz:Redis後臺任務執行間隔,如超時關閉使用者端連線、定期刪除等。預設值為10。範圍在 1 到 500 之間,官方建議不要超過100,大多數應使用預設值,並且只有在極低延遲的環境中才能設為 100
- dynamic-hz:此設定用於動態調整hz的值,預設開啟。如果有大量使用者端連線進來時,會以
hz的設定值將作為基線,將hz的實際值設定為hz的設定值的整數倍,用來節省CPU資源。
總結
總結如下:
- Redis記憶體淘汰機制是指在Redis的用於快取的記憶體不足時,怎麼處理需要新寫入且需要申請額外空間的資料
- Redis提供了八種記憶體淘汰策略,分別是:
- noeviction:不會淘汰任何鍵,達到記憶體限制後返回錯誤
- allkeys-random:在所有鍵中,隨機刪除鍵
- volatile-random:在設定了過期時間的鍵中,隨機刪除鍵
- allkeys-lru:通過LRU演演算法淘汰最近最少使用的鍵,保留最近使用的鍵
- volatile-lru:從設定了過期時間的鍵中,通過LRU演演算法淘汰最近最少使用的鍵
- allkeys-lfu:從所有鍵中淘汰使用頻率最少的鍵。從所有鍵中驅逐使用頻率最少的鍵
- volatile-lfu:從設定了過期時間的鍵中,通過LFU演演算法淘汰使用頻率最少的鍵
- volatile-ttl:從設定了過期時間的鍵中,淘汰馬上就要過期的鍵
- Redis記憶體回收機制是指在Redis中如何刪除已經過期或者被淘汰的資料,釋放記憶體空間
- Redis提供了兩種記憶體回收策略,分別是:
- 定期刪除:Redis會每隔一定時間(預設100ms)隨機抽取一些設定了過期時間的鍵,檢查它們是否過期,如果過期就刪除。這種策略可以減少CPU開銷,但可能會導致一些過期鍵佔用記憶體
- 惰性刪除:Redis在使用者端存取一個鍵時,會檢查這個鍵是否過期,如果過期就刪除。這種策略可以及時釋放記憶體空間,但可能會增加CPU開銷和延遲