【重學C++】04 | 說透C++右值參照、移動語意、完美轉發(上)
文章首發
【重學C++】04 | 說透C++右值參照、移動語意、完美轉發(上)
引言
大家好,我是隻講技術乾貨的會玩code,今天是【重學C++】的第四講,在前面《03 | 手擼C++智慧指標實戰教學》中,我們或多或少接觸了右值參照和移動的一些用法。
右值參照是 C++11 標準中一個很重要的特性。第一次接觸時,可能會很亂,不清楚它們的目的是什麼或者它們解決了什麼問題。接下來兩節課,我們詳細講講右值參照及其相關應用。內容很乾,注意收藏!
左值 vs 右值
簡單來說,左值是指可以使用&符號獲取到記憶體地址的表示式,一般出現在賦值語句的左邊,比如變數、陣列元素和指標等。
int i = 42;
i = 43; // ok, i是一個左值
int* p = &i; // ok, i是一個左值,可以通過&符號獲取記憶體地址
int& lfoo() { // 返回了一個參照,所以lfoo()返回值是一個左值
int a = 1;
return a;
};
lfoo() = 42; // ok, lfoo() 是一個左值
int* p1 = &lfoo(); // ok, lfoo()是一個左值
相反,右值是指無法獲取到記憶體地址的表達是,一般出現在賦值語句的右邊。常見的有字面值常數、表示式結果、臨時物件等。
int rfoo() { // 返回了一個int型別的臨時物件,所以rfoo()返回值是一個右值
return 5;
};
int j = 0;
j = 42; // ok, 42是一個右值
j = rfoo(); // ok, rfoo()是右值
int* p2 = &rfoo(); // error, rfoo()是右值,無法獲取記憶體地址
左值參照 vs 右值參照
C++中的參照是一種別名,可以通過一個變數名存取另一個變數的值。
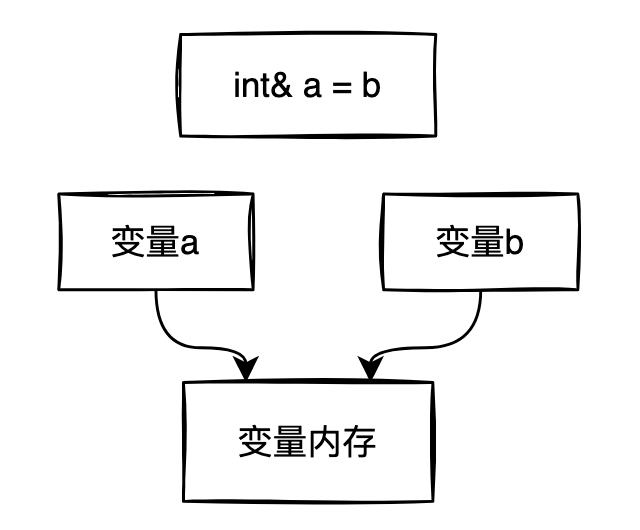
上圖中,變數a和變數b指向同一塊記憶體地址,也可以說變數a是變數b的別名。
在C++中,參照分為左值參照和右值參照兩種型別。左值參照是指對左值進行參照的參照型別,通常使用&符號定義;右值參照是指對右值進行參照的參照型別,通常使用&&符號定義。
class X {...};
// 接收一個左值參照
void foo(X& x);
// 接收一個右值參照
void foo(X&& x);
X x;
foo(x); // 傳入引數為左值,呼叫foo(X&);
X bar();
foo(bar()); // 傳入引數為右值,呼叫foo(X&&);
所以,通過過載左值參照和右值參照兩種函數版本,滿足在傳入左值和右值時觸發不同的函數分支。
值得注意的是,void foo(const X& x);同時接受左值和右值傳參。
void foo(const X& x);
X x;
foo(x); // ok, foo(const X& x)能夠接收左值傳參
X bar();
foo(bar()); // ok, foo(const X& x)能夠接收右值傳參
// 新增右值參照版本
void foo(X&& x);
foo(bar()); // ok, 精準匹配呼叫foo(X&& x)
到此,我們先簡單對右值和右值參照做個小結:
- 像字面值常數、表示式結果、臨時物件等這類無法通過
&符號獲取變數記憶體地址的,稱為右值。 - 右值參照是一種參照型別,表示對右值進行參照,通常使用
&&符號定義。
右值參照主要解決一下兩個問題:
- 實現移動語意
- 實現完美轉發
這一節我們先詳細講講右值是如何實現移動效果的,以及相關的注意事項。完美轉發篇幅有點多,我們留到下節講。
複製 vs 移動
假設有一個自定義類X,該類包含一個指標成員變數,該指標指向另一個自定義類物件。假設O佔用了很大記憶體,建立/複製O物件需要較大成本。
class O {
public:
O() {
std::cout << "call o constructor" << std::endl;
};
O(const O& rhs) {
std::cout << "call o copy constructor." << std::endl;
}
};
class X {
public:
O* o_p;
X() {
o_p = new O();
}
~X() {
delete o_p;
}
};
X 對應的拷貝賦值函數如下:
X& X::operator=(X const & rhs) {
// 根據rhs.o_p生成的一個新的O物件資源
O* tmp_p = new O(*rhs.o_p);
// 回收x當前的o_p;
delete this->o_p;
// 將tmp_p 賦值給 this.o_p;
this->o_p = tmp_p;
return *this;
}
假設對X有以下使用場景:
X x1;
X x2;
x1 = x2;
上述程式碼輸出:
call o constructor
call o constructor
call o copy constructor
x1和x2初始化時,都會執行new O(), 所以會呼叫兩次O的建構函式;執行x1=x2時,會呼叫一次O的拷貝建構函式,根據x2.o_p複製一個新的O物件。
由於x2在後續程式碼中可能還會被使用,所以為了避免影響x2,在賦值時呼叫O的拷貝建構函式複製一個新的O物件給x1在這種場景下是沒問題的。
但在某些場景下,這種拷貝顯得比較多餘:
X foo() {
return X();
};
X x1;
x1 = foo();
程式碼輸出與之前一樣:
call o constructor
call o constructor
call o copy constructor
在這個場景下,foo()建立的那個臨時X物件在後續程式碼是不會被用到的。所以我們不需要擔心賦值函數中會不會影響到那個臨時X物件,沒必要去複製一個新的O物件給x1。
更高效的做法,是直接使用swap交換臨時X物件的o_p和x1.o_p。這樣做有兩個好處:1. 不用呼叫耗時的O拷貝建構函式,提高效率;2. 交換後,臨時X物件擁有之前x1.o_p指向的資源,在解構時能自動回收,避免記憶體漏失。
這種避免高昂的複製成本,而直接將資源從一個物件"移動"到另外一個物件的行為,就是C++的移動語意。
哪些場景適用移動操作呢?無法獲取記憶體地址的右值就很合適,我們不需要擔心後續的程式碼會用到該右值。
最後,我們看下行動版本的賦值函數
X& operator=(X&& rhs) noexcept {
std::swap(this->o_p, rhs.o_p);
return *this;
};
看下使用效果:
X x1;
x1 = foo();
輸出結果:
call o constructor
call o constructor
右值參照一定是右值嗎?
假設我們有以下程式碼:
class X {
public:
// 複製版本的賦值函數
X& operator=(const X& rhs);
// 行動版本的賦值函數
X& operator=(X&& rhs) noexcept;
};
void foo(X&& x) {
X x1;
x1 = x;
}
類X過載了複製版本和行動版本的賦值函數。現在問題是:x1=x這個賦值操作呼叫的是X& operator=(const X& rhs)還是 X& operator=(X&& rhs)?
針對這種情況,C++給出了相關的標準:
Things that are declared as rvalue reference can be lvalues or rvalues. The distinguishing criterion is: if it has a name, then it is an lvalue. Otherwise, it is an rvalue.
也就是說,只要一個右值參照有名稱,那對應的變數就是一個左值,否則,就是右值。
回到上面的例子,函數foo的入參雖然是右值參照,但有變數名x,所以x是一個左值,所以operator=(const X& rhs)最終會被呼叫。
再給一個沒有名字的右值參照的例子
X bar();
// 呼叫X& operator=(X&& rhs),因為bar()返回的X物件沒有關聯到一個變數名上
X x = bar();
這麼設計的原因也挺好理解。再改下foo函數的邏輯:
void foo(X&& x) {
X x1;
x1 = x;
...
std::cout << *(x.inner_ptr) << std::endl;
}
我們並不能保證在foo函數的後續邏輯中不會存取到x的資源。所以這種情況下如果呼叫的是行動版本的賦值函數,x的內部資源在完成賦值後就亂了,無法保證後續的正常存取。
std::move
反過來想,如果我們明確知道在x1=x後,不會再存取到x,那有沒有辦法強制走移動賦值函數呢?
C++提供了std::move函數,這個函數做的工作很簡單: 通過隱藏掉入參的名字,返回對應的右值。
X bar();
X x1
// ok. std::move(x1)返回右值,呼叫移動賦值函數
X x2 = std::move(x1);
// ok. std::move(bar())與 bar()效果相同,返回右值,呼叫移動賦值函數
X x3 = std::move(bar());
最後,用一個容易犯錯的例子結束這一環節
class Base {
public:
// 拷貝建構函式
Base(const Base& rhs);
// 移動建構函式
Base(Base&& rhs) noexcept;
};
class Derived : Base {
public:
Derived(Derived&& rhs)
// wrong. rhs是左值,會呼叫到 Base(const Base& rhs).
// 需要修改為Base(std::move(rhs))
: Base(rhs) noexcept {
...
}
}
返回值優化
依照慣例,還是先給出類X的定義
class X {
public:
// 建構函式
X() {
std::cout << "call x constructor" <<std::endl;
};
// 拷貝建構函式
X(const X& rhs) {
std::cout << "call x copy constructor" << std::endl;
};
// 移動建構函式
X(X&& rhs) noexcept {
std::cout << "call x move constructor" << std::endl
};
}
大家先思考下以下兩個函數哪個效能比較高?
X foo() {
X x;
return x;
};
X bar() {
X x;
return std::move(x);
}
很多讀者可能會覺得foo需要一次複製行為:從x複製到返回值;bar由於使用了std::move,滿足移動條件,所以觸發的是移動建構函式:從x移動到返回值。複製成本 > 移動成本,所以bar效能更好。
實際效果與上面的推論相反,bar中使用std::move反倒多餘了。現代C++編譯器會有返回值優化。換句話說,編譯器將直接在foo返回值的位置構造x物件,而不是在本地構造x然後將其複製出去。很明顯,這比在本地構造後移動效率更快。
以下是foo和bar的輸出:
// foo
call x constructor
// bar
call x constructor
call x move constructor
移動需要保證異常安全
細心的讀者可能已經發現了,在前面的幾個小節中,移動構造/賦值函數我都在函數簽名中加了關鍵字noexcept,這是向呼叫者表明,我們的移動函數不會丟擲異常。
這點對於移動函數很重要,因為移動操作會對右值造成破壞。如果移動函數中發生了異常,可能會對程式造成不可逆的錯誤。以下面為例
class X {
public:
int* int_p;
O* o_p;
X(X&& rhs) {
std::swap(int_p, rhs.int_p);
...
其他業務操作
...
std::swap(o_p, rhs.o_p);
}
}
如果在「其他業務操作」中發生了異常,不僅會影響到本次構造,rhs內部也已經被破壞了,後續無法重試構造。所以,除非明確標識noexcept,C++在很多場景下會慎用移動構造。
比較經典的場景是std::vector 擴縮容。當vector由於push_back、insert、reserve、resize 等函數導致記憶體重分配時,如果元素提供了一個noexcept的移動建構函式,vector會呼叫該移動建構函式將元素移動到新的記憶體區域;否則,則會呼叫拷貝建構函式,將元素複製過去。
總結
今天我們主要學了C++中右值參照的相關概念和應用場景,並花了很大篇幅講解移動語意及其相關實現。
右值參照主要解決實現移動語意和完美轉發的問題。我們下節接著講解右值是如何實現完美轉發。歡迎關注,及時收到推播~