解密Prompt7. 偏好對齊RLHF-OpenAI·DeepMind·Anthropic對比分析
前三章都圍繞指令微調,這一章來嘮嘮RLHF。何為優秀的人工智慧?抽象說是可以幫助人類解決問題的AI, 也可以簡化成3H原則:Helpful + Honesty + Harmless。面向以上1個或多個原則,RLHF只是其中一種對齊方案,把模型輸出和人類偏好進行對齊。大體分成3個步驟
- 人類偏好資料的標註
- 基於標註資料訓練獎勵模型
- 基於獎勵模型使用RL微調語言模型
以OpenAI為基礎,本章會對比DeepMind, Anthropic在以上3個步驟上的異同,並嘗試回答以下幾個問題
- RLHF究竟做了什麼
- 偏好對齊用RL和SFT有什麼差異
- 什麼模型適合作為RL的起點
考慮篇幅已經超出了我自己的閱讀耐心,RL演演算法和其他偏好對齊方案會再用兩章來說,只關注以上問題的同學,也可以直接劃到文末去看~
OpenAI
- paper: InstructGPT, Training language models to follow instructions with human feedback
- paper: Learning to summarize from human feedback
- https://openai.com/blog/chatgpt
解密Prompt系列4介紹了InstructGPT指令微調的部分,這裡只看偏好對齊的部分
樣本構建
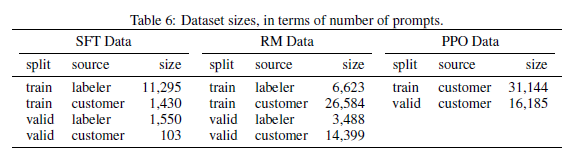
RL的資料來源有兩塊,一部分是使用者在playground裡面真實請求的資料,另一部分來自標註同學自己寫的指令樣本。標註指令樣本包括3種形式:單一指令,few-shot指令,根據使用者之前提交的使用場景編寫的指令,量級分佈如下
在標註偏好樣本上,OpenAI基於3H原則,設計了詳細的標註標準詳見論文。需要注意的一點是在訓練樣本標註時Helpful比Harmless和honest更重要,但是在評估樣本的標註上Harmless和honest更重要。這樣區別標註是OpenAI發現Helpful和Harmless存在衝突,如果模型過度擬合無害性,會導致模型拒絕回答很多問題。OpenAI認為不同場景下風險的定義是不同的,應該把拒絕回答的能力放到下游場景中, 後面Anthropic也碰到了相似的問題,我個人更偏好Anthropic的方案。
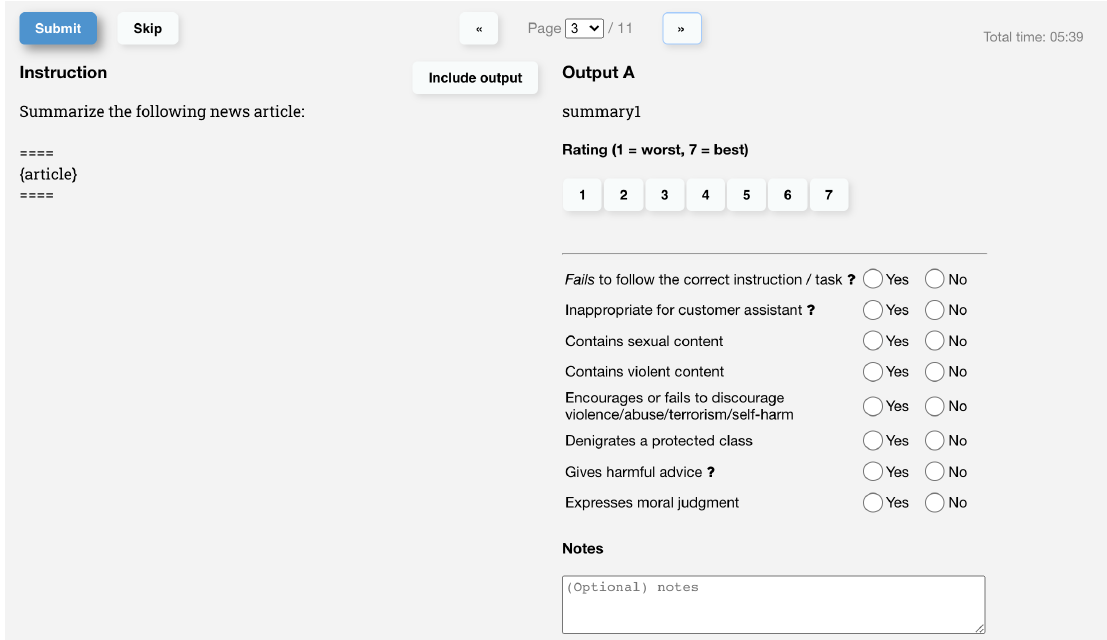
在標註過程中,模型會生成4-7個回覆,標註同學需要綜合考慮有用性,無害性和真實性,對模型的每一個回覆進行絕對打分後續用於評估,同時給出多個模型回覆間的相對排序用於RM模型訓練,標註介面如下:

ChatGPT對話訓練部分未公開細節,從官網能獲得細節是,ChatGPT的樣本是人工寫的對話樣本+InstructGPT樣本轉換成對話格式的混合樣本,更多基於對話形式的標註可以參考後面的DeepMind和Anthropic。
獎勵模型
OpenAI使用了指令微調16個epoch的6B模型作為獎勵模型的初始模型。訓練方式是兩兩對比計算crossentropy,其中\(r_\theta\)是獎勵函數對指令x和回覆y的打分,如下
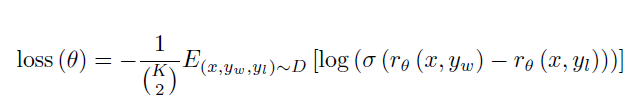
不過OpenAI發現如果對資料進行Shuffle,則訓練一輪就會過擬合,但如果把針對1個指令模型的K個回覆,K在4~9之間,得到的\(C_k^2\)個pairwise對,放在一個batch裡進行訓練,會得到顯著更高的準確率。這裡一個batch包括64個指令生成的所有回覆對,其中排名相同的樣本對被剔除。
這裡感覺和對比學習要用大batch_size進行擬合的思路有些相似,是為了保證對比的全面性和充分性,使用全面對比後計算的梯度對模型進行更新。另一個原因可能是不同標註人員之間的偏好差異,shuffle之後這種偏好差異帶來的樣本之間的衝突性更高。
之所以選擇6B的模型,論文指出儘管175B的RM模型有更高的準確率和更小的驗證集loss,但是訓練過程並不穩定,以及太大的RM模型會導致RL部分的訓練成本太高。
RLHF
- RL初始模型
OpenAI使用了SFT指令微調之後的模型作為RL的起點。RL初始模型的訓練細節在附錄C.3和E.8,基於GPT3的預訓練模型,SFT微調2個epoch並混入10%的預訓練資料進行訓練得到。這裡混入預訓練是因為在RL微調的過程中發現加入預訓練資料可以防止RL微調降低模型語言能力,因此在SFT微調過程中也做了相同的處理。這裡我好奇的是,指令微調和預訓練的核心差異其實只在指令輸入的部分是否計算梯度,因此是否可以直接把指令微調和預訓練混合變成一個步驟"文字+指令預訓練",我們準備沿這個方向去嘗試下~
- RL樣本
OpenAI是完全基於在playground裡使用者真實提交的指令請求來進行訓練,沒有使用人工標註,為了完全面向用戶使用進行偏好優化。
- RL訓練
RL微調的部分,OpenAI使用了PPO演演算法,基於Reward模型的打分進行微調,微調了2個epoch。在此基礎上加入了兩個目標:
- 微調模型和原始模型在token預測上的KL散度:避免模型過度擬合獎勵函數偏離原始模型。後面也論證了KL的加入,可以加速RL收斂,核心是在相同的KL下最大化模型偏好的提升
- 10%的預訓練目標(PPO-PTX): 降低RL對模型語言能力的影響
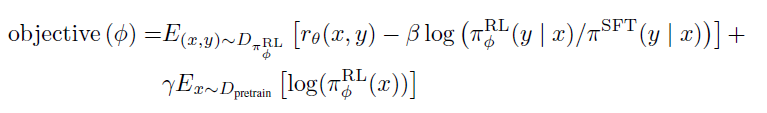
且論文提到樣本的收集和RL訓練是多次迭代的,也就是使用RL微調後的模型上線收集更多的使用者請求,重新訓練RM,再更新模型。不停在優化後的模型上收集使用者反饋,會讓RM模型學習到更充分的高偏好樣本,強者愈強。
- 效果
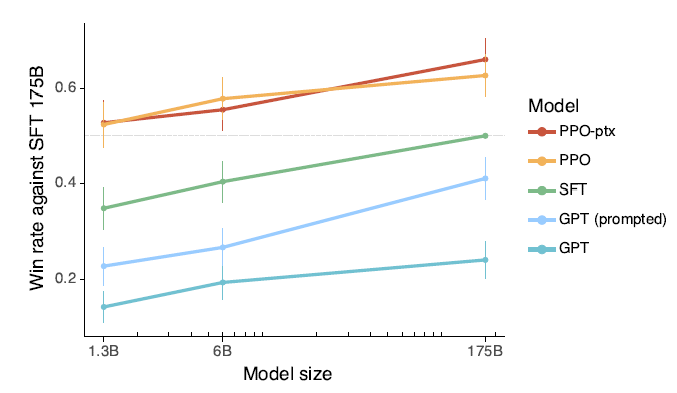
對比175B指令微調的模型,1.3B的模型經過RLHF微調,在喜愛度上就能打過175B的SFT模型!2點Insights如下
- RLHF對齊帶來的模型有用性的提升,效率遠超訓練更大的模型
- 使用PPO-PTX的RLHF微調沒有產生很大的Alignment-Tax
DeepMind
- paper: Teaching language models to support answers with verified quotes
- paper: Sparrow, Improving alignment of dialogue agents via
DeepMind的Sparrow使用了基於Google搜尋的事實性資訊的引入,這部分我們放到Agent呼叫的章節一起說,這裡只關注偏好對齊的部分。
樣本構建
不考慮搜尋呼叫的部分,DeepMind的偏好對齊部分只關注2H,有用性和無害性。樣本標註的基礎模型是Chinchilla-70B,和OpenAI的差異在於,DeepMind把人類偏好和違反2H原則拆成了兩個標註任務
- 人類偏好標註:基於進行中的對話,從模型多個回覆中選擇最喜歡的一條,這裡對話中的人機問答都是由模型生成的
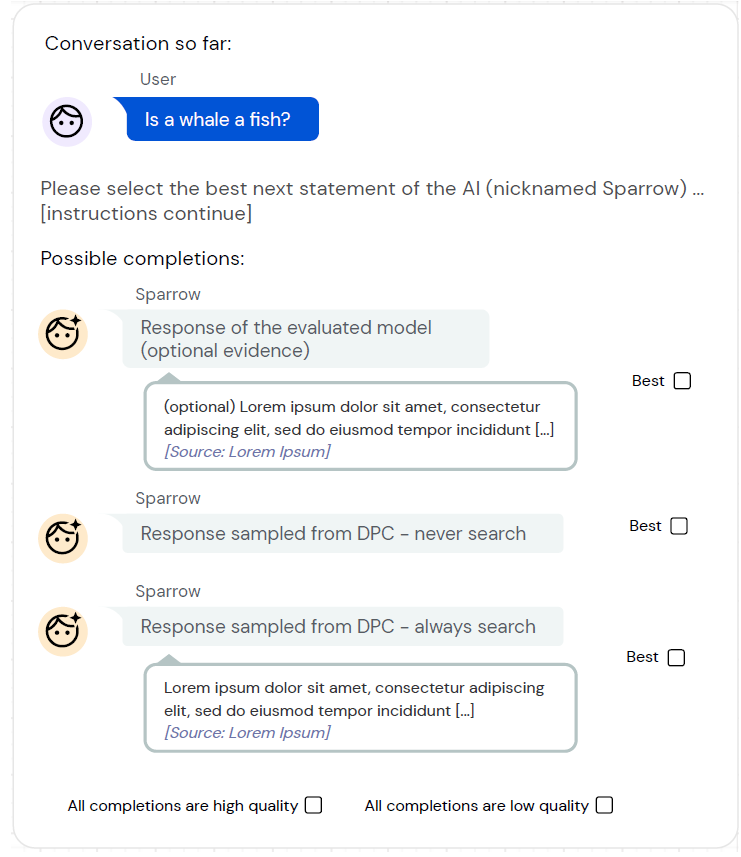
- 對抗標註/釣魚執法:基於隨機分配的標註規則,標註同學需要刻意引導模型給出違反該規則的回答,和風控紅藍對抗的思路相似
獎勵模型
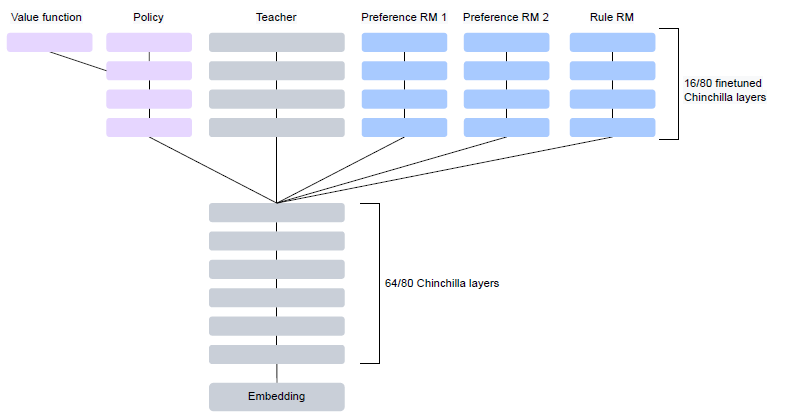
基於以上兩份樣本,論文通過微調Chinchilla-70B,分別訓練了兩個模型PM和RM, 微調的方式都是固定前64層,只微調後16層。
![]()
- PM:Preference Reward Model
PM的資料是在以上每輪對話多選一的基礎上,從其他對話中隨機取樣更多的負樣本構成的多分類任務,這裡補充負樣本是為了懲罰off-topic的模型回覆。因此損失函數是多分類的CrossEntropy,以及在此基礎上加入了Bradley-Taley(Elo)和正則項,如下
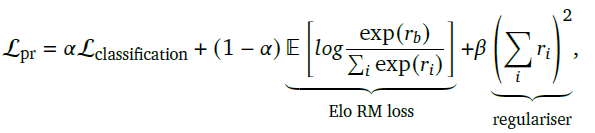
其中\(r_i\)是所有回覆的模型打分,因此正則項是為了保證最終模型輸出的打分是以0為中心的。而Elo部分是為了優化兩兩對比排序,更多細節>>Fitting the Bradley-Terry model to large and potentially sparse datasets
- RM:Rule Violation Model
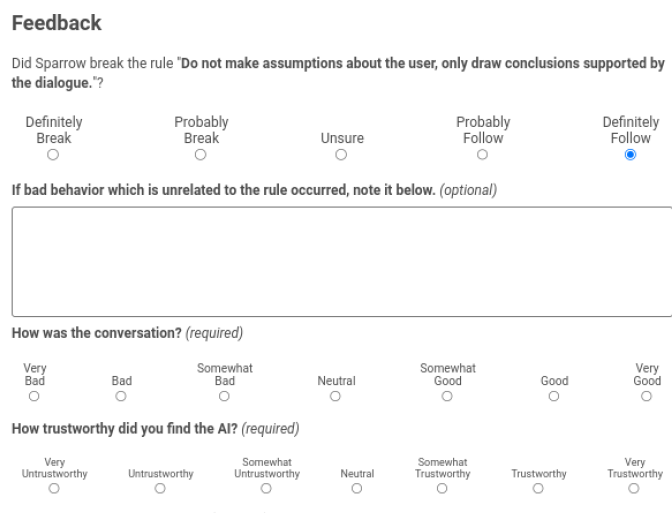
RM模型是一個多標籤任務,判斷對話當前是否違反其中一條標註規則,輸出違反該規則的條件概率。以上5檔標籤被分成兩類,definitely break和probably break]是違反,probably follow和definitely follow是未違反,unsure樣本被丟棄。這裡DeepMind使用如下Hard Prompt Tunning來構建模型,其實就是引入一些前置語意資訊,讓模型在小樣本上表現更好。更多細節>>解密Prompt系列2. 凍結Prompt微調LM

- 整體打分
基於以上兩個模型,整體打分=偏好打分+所有規則的未違反概率之和+長度懲罰(保證回答簡潔)+is_valid(模板檢查)。其中模板檢查包括要求Agent回覆以\n\nSparrow:開始,以\n\nUser:結束,保證所有模型回覆有相同的格式
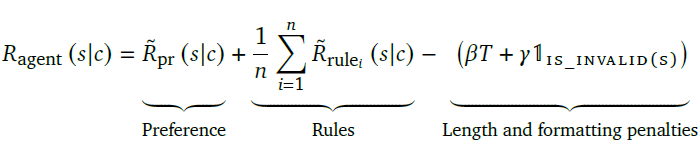
個人感覺分開標註,以及引導式的標註沒啥問題,但分開建模再直接打分融合可能不一定是最優的方案,因為兩個模型的scale不同,很難對比違反部分規則,和偏好程度要如何balance才是最優的整體打分。
RLHF
-
RL起點:和OpenAI相同,DeepMmind也使用監督微調模型作為初始模型。不過DeepMind直接使用了以上RM的標註資料中,多選一標註有用的回覆,和未違反規則的回覆來進行監督微調。
-
RL樣本
對比OpenAI使用純人機對話的樣本,DeepMind的RL的樣本來源包括以下四個部分
- 問題集:GopherCite的Eli5子集
- 人機對話:以上RM和PM的人機對話的樣本集
- 對抗樣本擴充:使用Prompt模板引導Sparrow生成有害問題,擴充有害對話樣本
- self-play:類似self-instruct,會取樣已有對話作為上下文,讓sparrow繼續生成回覆
- RL訓練
DeepMind使用了Actor-Critic演演算法進行RL微調, RL演演算法我們會單獨一章來講,整體上A2C可能略弱於PPO。除了演演算法不同,DeepMind的RL微調也只微調Chinchilla模型的後16層。
都選擇微調16層,其實是為了節省訓練視訊記憶體,這樣PM,RM,初始SFT模型,和最終的RL微調模型都共用前64層,後16層通過不同head來實現,從而達到降低視訊記憶體佔用的目的。
- Insight:偏好和遵守規則的矛盾統一
人類偏好和遵守規則的要求存在一定衝突,只使用更偏好的資料訓練會得到更高的規則違反率,只使用遵守規則的資料訓練會降低模型回覆的偏好率,混合樣本的微調效果最好。
Anthropic
- paper: Red Teaming Language Models to Reduce Harms Methods,Scaling Behaviors and Lessons Learned
- paper: A General Language Assistant as a Laboratory for Alignment
- paper:Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
- 資料:https://huggingface.co/datasets/Anthropic/hh-rlhf
樣本構建
從論文標題不難看出,Anthropic也只考慮了2H,有害性和有用性。並且著重研究了對抗有害樣本的生成,受限於篇幅這裡不展開。我個人也更偏好2H,因為我始終沒太想明白Honesty如何能通過對齊實現。因為部分非事實性是來自預訓練樣本中的噪聲,例如預訓練樣本中是"鯤之大一鍋燉不下",如何通過對齊讓模型學到"鯤之大,不知其幾千裡也"?部分非事實性來自訓練樣本的有限性,需要像Bing一樣通過引入實時資訊來解決,要是大家有不一樣的觀點也歡迎留言評論。
同樣是拆分了2個標註任務,和DeepMind的差異是,Anthropic是把有害性和有用性分成了兩個標註任務,針對開放的對話主題進行4輪左右的對話。
- 有害性標註:和DeepMind相同使用了紅藍對抗的方案,目標是引導模型生成有害回覆。每一輪模型會生成2個回答,選擇更有害的一個

- 有用性標註:同樣是每輪2選一,選擇更有幫助的一條回覆,並不強制進行事實性檢查

對抗/引導式的資料標註方式,對比OpenAI直接標註,可以更充分挖掘偏好中更有用和更有害的資料,對於解決模型安全性有更大的幫助,但感覺可能缺少中間部分偏好的樣本,如果能和OpenAI直接標註的方案結合是否會更好?
除了2H的任務分開標註之外,每個標註同學進行對話的模型雖然都是52B的模型,但會隨機來自3個不同版本的模型
- HHH Context-Ditill:類似3Hprompt(helpful,harmless, honest)加持的基礎模型,最初只有這個模型
- Rejection Sampling(RS):使用3H模型生成16個回覆,使用訓練後的PM模型對結果排序,選擇有害性最小的2個回覆
- RLHF微調後的模型:後續的資料收集會基於微調後多個版本的模型持續進行
獎勵模型
Anthropic的獎勵模型同樣是基於樣本排序進行訓練的,有用得分高於無用,無害得分高於有害,並且更詳細論證了相對排序模型的效果要好於二分類模型,要好於語言模型。
為了降低對微調資料的需求,Anthropic加入了Preference Model Pretraining(PMP)的繼續預訓練過程,使用Reddit, StackExchange等開源問答的資料讓模型先部分學習什麼是好的什麼是壞的回答。
除此之外Anthropic還討論了PM模型大小對模型穩健性的影響。通過把資料集一分為二,一半訓練,一半驗證,越穩健的PM模型應該在不同資料上有相似的打分分佈。論文使用PM模型在兩份資料上打分的KL散度來衡量穩定性,得到兩個結論
- PM模型越大,KL散度越低
- PM模型打分在低分割區一致性較高,在高分割區一致性較低
第二個結論很符合直覺,因為有害內容的標註一致性更高更易識別,而優質回覆的評價更模糊,另一個原因是模型當前的能力可能導致高分割區的樣本比較稀疏。
但第一個結論,感覺有可能是因為越大的模型預測的置信度越高,打分更容易聚集在一起,才導致的KL散度更低,這個置信度的差異似乎沒有被考慮進去。
RLHF
- RL起點
Anthropic選擇了3H Context Distillation的模型,通過在樣本前加入3H指令詞,引導模型生成更安全有用的回覆,並記錄模型生成的每個位置Top50的詞和概率,把這個概率作為Teacher;然後去掉3H指令詞,對預訓練模型進行微調,微調目標就是去擬合之前有3H時Top50 Token的預測概率,其實就是Teacher-Student蒸餾的思路。
- RL樣本
為了讓模型在更大範圍的指令樣本上進行偏好學習,使用了Self-Instruct,隨機取樣10個已有的真實請求讓模型來生成新的請求,最終是137K真實請求和369K模型生成請求混合作為訓練樣本
- RL訓練:整體和openAI類似
和OpenAI相同,Anthropic也提到了online iter訓練,但論文的出發點是前面提到的PM模型在高分部分不穩定的問題。因為微調後的模型生成的回覆會更好,在更優的模型中持續收集樣本,可以持續補充高分樣本。注意這裡的online和常規意義的online不同,這裡每次訓練會混合多個snapshot模型收集的偏好資料和最初的偏好樣本,重頭訓練PM,並重新微調RLHF。
- Insight:有用性和無害性的矛盾統一
和OpenAI相似,Anthropic也舉報了有用性和無害性的標註矛盾。在RLHF微調過程中,只要使用者的請求有輕微不滿,模型就讓使用者去看醫生哈哈哈哈~其實我們在不充分微調的ChatGLM中也發現了類似的現象。經過分析模型是過度擬合了有害性,而對有用性欠擬合,導致模型雖然無害但也沒啥用
論文給出了的解決思路是遇到有害性請求,模型只學到拒絕回答是很簡單的,這就是無用但無害,但是如果模型能學到在拒絕回答的同時,給到拒絕的原因,並勸說使用者不要有類似的有害的請求的話,就是有用且無害了。這部分標註資料當前是缺失的。 個人感覺這個思路比OpenAI適配場景去拒絕請求,似乎可行性更高一些。不過論文沒有重新標樣本,而是選擇了折中的方案,加入更大比例Helpful樣本來提升模型有用性
對比總結
- paper: Scaling Laws for Reward Model Over optimization
- paper: WebGPT: Browser-assisted question-answering with
human feedback- https://openai.com/research/measuring-goodharts-law
粗略看完以上3家超長無比的系列RLHF論文,結合OpenAI對RM模型的一些觀點。我們來討論下文首問題,感悟很玄學!!不一定靠譜!!僅提供一種思路~
RLHF究竟學了啥?
- 可類比拒絕取樣(Best-of-N):讓模型隨機取樣生成N個回覆,選擇RM打分最高的回覆
在WebGPT中OpenAI就把Best-of-N和RL進行了對比,best-of-64的效果甚至超過RLHF,而DeepMind在RL微調後加入best-of-n效果會有進一步提升。感覺RLHF和Best-of-N的差異就是前者把排序擇優放在了微調階段訓練耗時,後者放在了推理階段推理耗時。本質上二者是相似的,都是讓模型在相似文字打分的文字序列中,挑選偏好打分更高的序列
那再想一步,Best-of-N的本質是啥?是Rejection-Sampling。啥是拒絕取樣?簡單說,就是針對無法直接取樣的分佈F,可以從G取樣,例如G服從正態分佈, 再通過特定的拒絕策略,拒絕不符合F分佈的樣本,則得到的樣本可以近似F分佈。對應到RLHF中,G其實就是RL初始模型生成的回覆,拒絕策略是拒絕RM打分低的回覆,則得到的就是符合人類偏好F的回覆。
偏好對齊使用RL和SFT的差異?
- 優化整個文字序列 vs 優化token級別的偏好:類似序列標註任務中CrossEntropy對比CRF
同樣使用偏好標註資料來進行微調,RL微調是針對整個文字序列的RM打分進行優化,而SFT是對每個token的預測概率進行優化。SFT在偏好優化場景上有幾個問題
- 每個token在損失函數中的權重是相同的
- 沒有考慮文字整體對偏好的影響
- 針對很多開放問題,最優答案是不固定的,只對1條回答做token級別的擬合,可能會影響泛化
綜合以上3點RL似乎更合適,但是針對有標準答案的場景,例如所有非開放生成的NLP任務,摘要,分類,抽取等等,用SFT來擬合偏好似乎也沒啥毛病,就像序列標註任務用CrossEntropy效果也不會比CRF差太多。
除此之外RL的另一個優點是可以部分降低人工標註,因為訓練的RM模型後續可用於偏好打分,而SFT的每一個偏好樣本都需要人工標註。
什麼模型適合作為RLHF的初始模型?
- 從拒絕取樣的本質出發,RL的初始模型需要有能夠生成人類偏好回答的能力
拒絕取樣的前提假設是F分佈的集合是G分佈集合的子集,因為拒絕取樣只是拒絕G取樣的部分樣本來得到F分佈。對應到RLHF其實就是RL的初始模型要有能夠生成人類偏好回覆的能力,因此通過指令微調來解鎖指令理解能力,似乎是RL初始模型的必須條件,畢竟純續寫模型是無法生成人類偏好的回覆的。
當前的RL其實還存在很多問題。首先人類偏好本身就是存在噪聲的,標註的一致率不到80%;其次獎勵模型是對標註偏好的進一步抽象,又受到一步準確率的限制;而使用不完美的獎勵模型進一步微調模型,則可能帶來更進一步的擬合問題。這些問題還有待進一步解決,這一章我們就先說這麼多啦
想看更全的大模型相關論文梳理·微調及預訓練資料和框架·AIGC應用,移步Github >> DecryptPropmt