Redis 高階特性 Redis Stream使用
Redis Stream 簡介
Redis Stream 是 Redis 5.0 版本新增加的資料結構。
Stream從字面上看是流型別,但其實從功能上看,應該是Redis對訊息佇列(MQ,Message Queue)的完善實現。下文稱Stream為佇列
Stream 出現原因:
Stream的出現是為了給Redis提供完善的訊息佇列功能
基於Reids的訊息佇列實現有很多種,例如:
- PUB/SUB,訂閱/釋出模式
- 基於List的 LPUSH+BRPOP 的實現
- 基於有序集合的實現
| 型別 | 優點 | 缺點 |
|---|---|---|
| List | 支援阻塞式的獲取訊息 | 沒有訊息多播功能,沒有ACK機制,無法重複消費等等 |
| Pub/Sub | 支援訊息多播 | 訊息無法持久化,只管傳送,如果出現網路斷開、Redis宕機等,訊息就直接沒了,自然也沒有ACK機制。 |
| Sorted Set | 支援延時訊息 | 不支援阻塞式獲取訊息、不允許重複消費、不支援分組。 |
釋出訂閱模式
Redis 釋出訂閱 (pub/sub) 是一種訊息通訊模式:傳送者 (pub) 傳送訊息,訂閱者 (sub) 接收訊息。
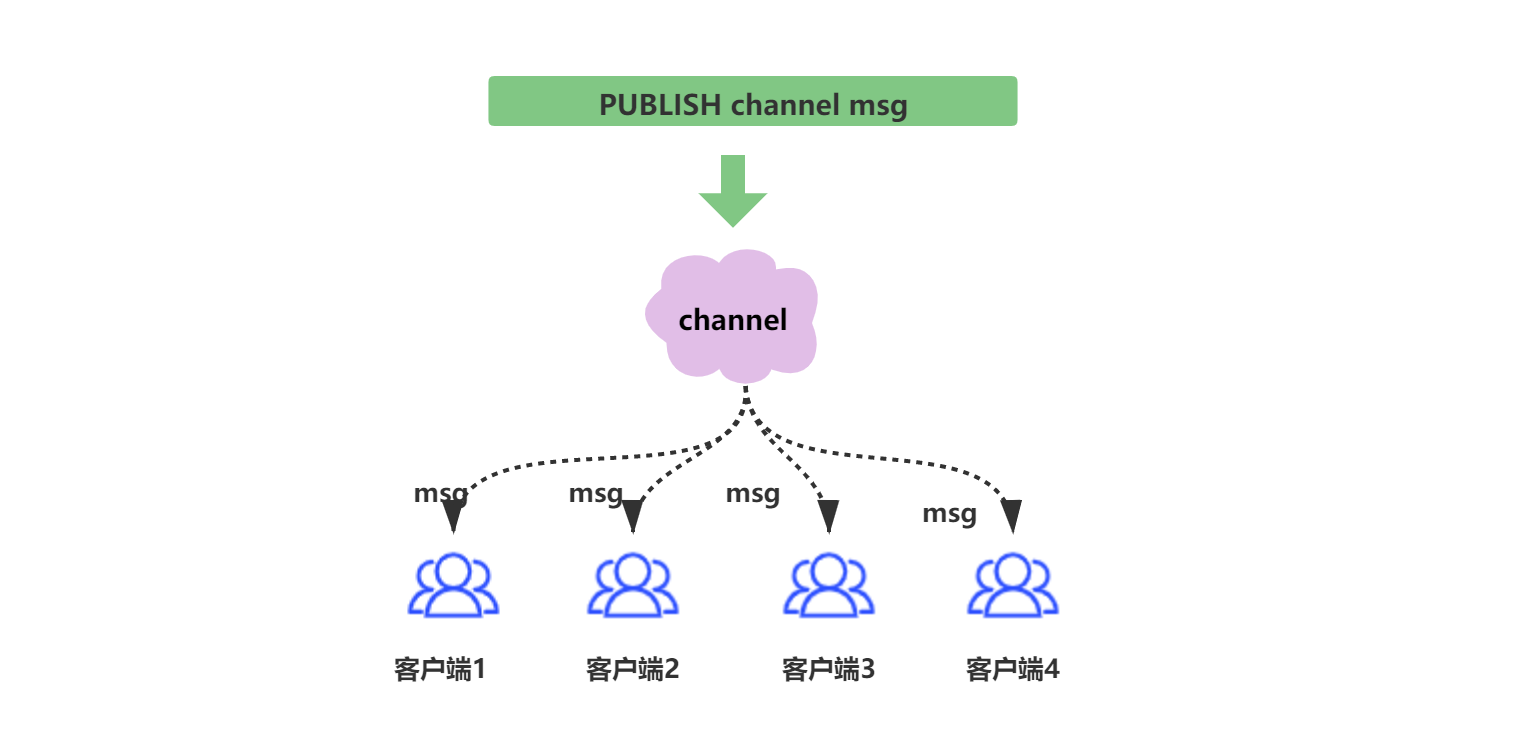
當釋出者向channel中釋出訊息時,所有訂閱了channel的使用者端都會收到訊息。
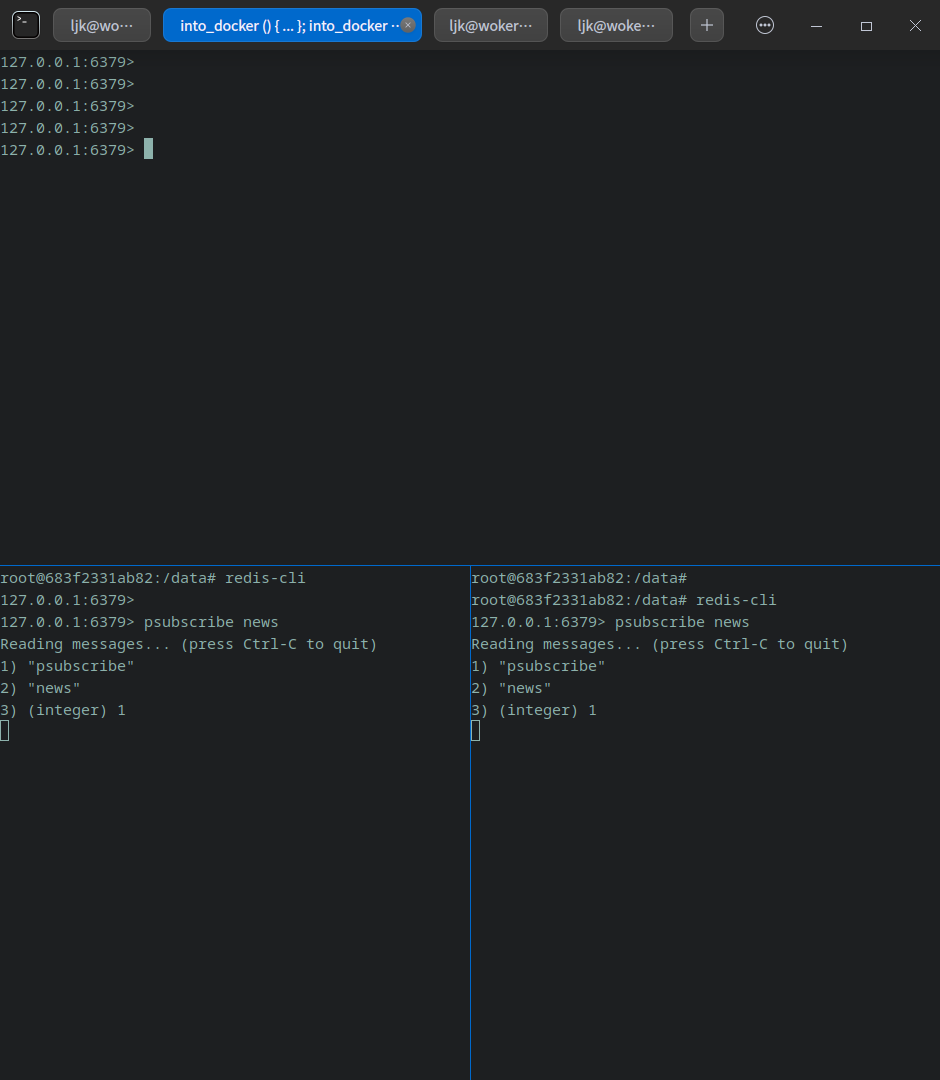
訂閱者首先訂閱channel
psubscribe news
釋出者釋出訊息
publish news "hello world"
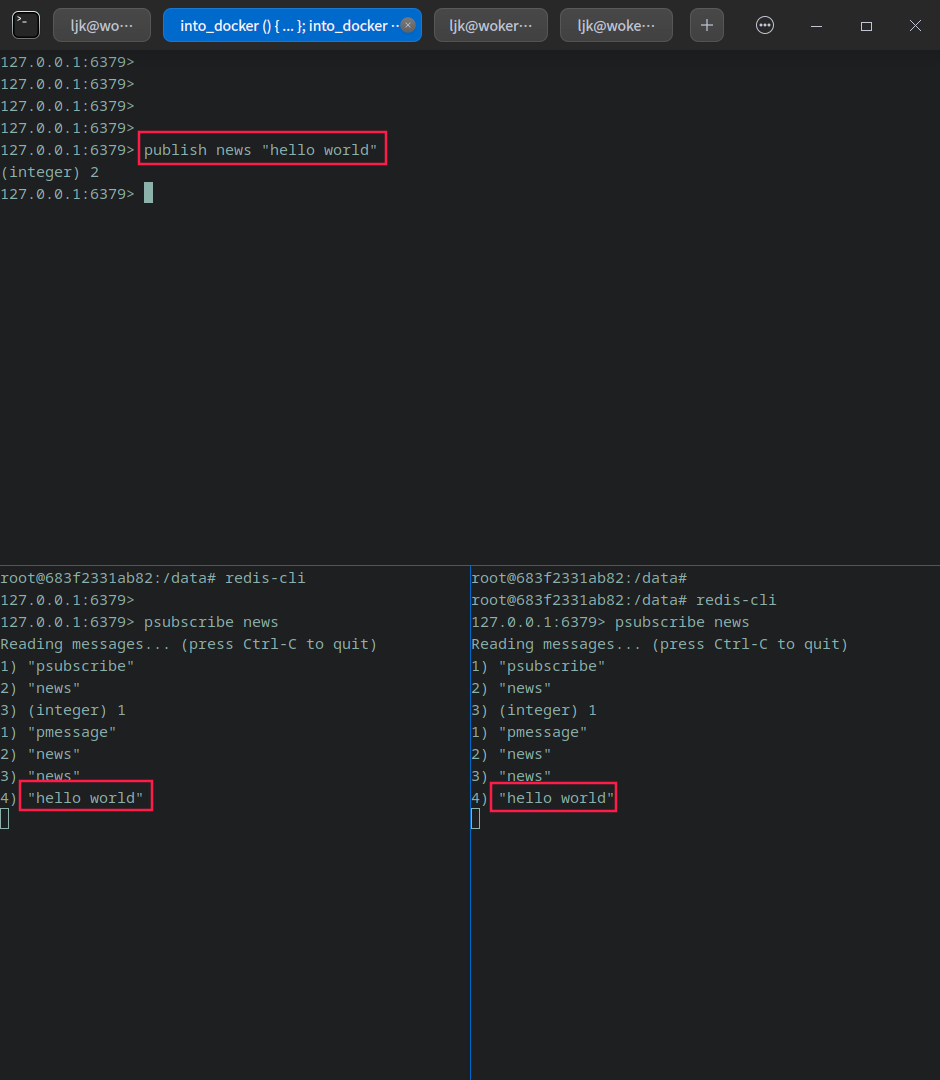
所有的訂閱者都收到了訊息。
致命缺點:
Redis的Pub/Sub為什麼被拋棄?
最主要的原因是它無法持久化,沒有實現持久化機制的Pub/Sub,無法做到訊息的不丟失,在使用者端宕機或者Redis服務宕機的情況下,都會導致訊息丟失。
Stream
Stream彌補了Redis作為訊息佇列技術選型上的不足之處。
Redis 5.0釋出的Stream相比Pub/Sub模組,Stream支援訊息持久化,結合叢集使其成為了一個比較可靠的訊息佇列。
佇列結構圖:
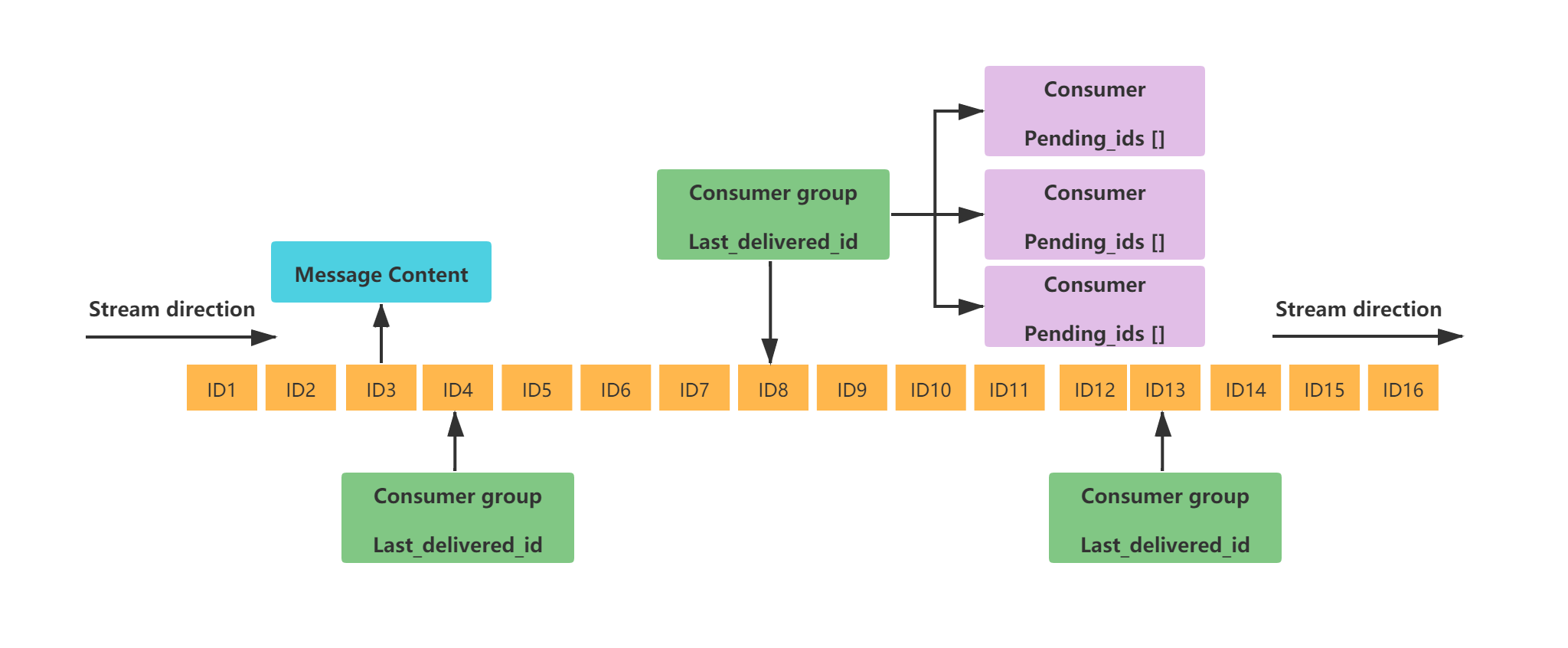
Stream 實現的功能包括如下:
-
提供了訊息多播的功能,同一個訊息可被分發給多個單消費者和消費者組
-
提供了訊息持久化的功能,可以讓任何消費者存取任何時刻的歷史訊息
-
提供了對於消費者和消費者組的阻塞、非阻塞的獲取訊息的功能
-
提供了強大的消費者組的功能:
- 消費者組實現同組多個消費者並行但不重複消費訊息的能力,提升消費能力;
- 消費者組能夠記住最新消費的資訊,保證訊息連續消費;
- 消費者組提供了ACK確認機制,保證訊息被成功消費,不丟失;
Stream本質上是Redis中的key,相關指令根據可以分為兩類,分別是訊息佇列相關指令,消費組相關指令。
訊息佇列相關指令:
| 指令名稱 | 指令作用 |
|---|---|
| XADD | 新增訊息到佇列末尾 |
| XTRIM | 限制Stream的長度,如果已經超長會進行擷取 |
| XDEL | 刪除訊息 |
| XLEN | 獲取Stream中的訊息長度 |
| XRANGE | 獲取訊息列表(可以指定範圍),忽略刪除的訊息 |
| XREVRANGE | 和XRANGE相比區別在於反向獲取,ID從大到小 |
| XREAD | 獲取訊息(阻塞/非阻塞),返回大於指定ID的訊息 |
消費者相關指令:
| 指令名稱 | 指令作用 |
|---|---|
| XGROUP CREATE | 建立消費者組 |
| XREADGROUP | 讀取消費者組中的訊息 |
| XACK | ack訊息,訊息被標記為「已處理」 |
| XGROUP SETID | 設定消費者組最後遞送訊息的ID |
| XGROUP DELCONSUMER | 刪除消費者組 |
| XPENDING | 列印待處理訊息的詳細資訊 |
| XCLAIM | 轉移訊息的∂歸屬權(長期未被處理/無法處理的訊息,轉交給其他消費者組進行處理) |
| XINFO | 列印Stream\Consumer\Group的詳細資訊 |
| XINFO GROUPS | 列印消費者組的詳細資訊 |
| XINFO STREAM | 列印Stream的詳細資訊 |
訊息佇列操作
XADD
使用XADD命令新增訊息到佇列末尾,如果指定的 佇列不存在,則該命令執行時會新建一個佇列。
新增的訊息是一個和多個鍵值對。XADD也是唯一可以向佇列中新增資料的 Redis 命令。
語法格式:
XADD key ID field value [field value ...]
- key:佇列名稱,如果不存在就建立
- ID:訊息id,使用*表示由redis生成。可以自定義,但是要自己保證遞增性
- field value:記錄,當前訊息內容,由一個或多個key-value構成
命令使用:
建立兩條訊息,分別是(name=tom, age=22),(height=180, use=iphone)
127.0.0.1:6379> xadd mystream * name tom age 22
"1674984765438-0"
127.0.0.1:6379> xadd mystream * height 180 use iphone
"1674985213802-0"
建立訊息時會生成一個序號,支援自定義序號和自動生成序號。*表示自動生成序號
XLEN
使用XLEN獲取佇列包含的元素數量,即訊息長度
語法格式:
XLEN key
命令使用:
127.0.0.1:6379> xlen mystream
(integer) 2
XDEL
使用XDEL刪除訊息。語法格式:
XDEL key ID [ID ...]
XDEL刪除訊息的指令,並不會從記憶體上刪除訊息,它只是給訊息打上標記位,下次通過XRANGE指令忽略這些訊息
XRANGE
使用XRANGE獲取訊息列表,會自動過濾已經刪除的訊息,語法格式:
XRANGE key start end [COUNT count]
- key:佇列名
- start:開始值,-表示最小值
- end:結束值,+表示最大值
- count:數量
命令使用:
不指定count預設查詢所有
127.0.0.1:6379> xrange mystream - +
1) 1) "1674984765438-0"
2) 1) "name"
2) "tom"
3) "age"
4) "22"
2) 1) "1674985213802-0"
2) 1) "height"
2) "180"
3) "use"
4) "iphone"
127.0.0.1:6379>
XREAD
XREAD命令提供讀取佇列訊息的能力,返回大於指定ID的訊息。
XREAD常用於用於迭代佇列的訊息,所以傳遞給 XREAD 的通常是上一次從該佇列接收到的最後一個訊息的ID。
語法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count:用於限定獲取的訊息數量
- BLOCK milliseconds:用於設定XREAD為阻塞模式以及阻塞的時長,單位毫秒,預設為非阻塞模式
- ID:設定開始讀取的訊息ID,使用0表示從第一條訊息開始。
訊息佇列ID是單調遞增的,所以通過設定起點,可以向後讀取。
在阻塞模式中,可以使用$,表示最新的訊息ID, block 0表示永久阻塞。(非阻塞模式下$無意義)。
命令使用:
非阻塞讀取
從第一條訊息開始
127.0.0.1:6379> xread streams mystream 0
1) 1) "mystream"
2) 1) 1) "1674984765438-0"
2) 1) "name"
2) "tom"
3) "age"
4) "22"
2) 1) "1674985213802-0"
2) 1) "height"
2) "180"
3) "use"
4) "iphone"
127.0.0.1:6379>
阻塞讀取
127.0.0.1:6379> xread block 10000 streams mystream $
(nil)
(10.04s)
127.0.0.1:6379>
阻塞模式讀,阻塞時長為10s。如果10s內未讀取到訊息則退出阻塞。另開一個終端向佇列中寫入一條訊息,阻塞讀的終端就能接收到訊息。

消費者操作
XGROUP CREATE
建立消費組。消費組用於管理消費者和佇列讀取記錄。Stream中的消費組有兩個特點:
- 從資源結構上說消費者從屬於一個消費組
- 一個佇列可以擁有多個消費組。不同消費組之間讀取佇列互不干擾
語法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key:佇列名稱,如果不存在就建立
- groupname:組名
- id: $表示從尾部開始消費,只接受新訊息,當前Stream訊息會全部忽略
命令使用:
為佇列mystream建立一個消費組 mqGroup,從第一個訊息開始讀
127.0.0.1:6379> XGROUP CREATE mystream mqGroup 0
OK
XREADGROUP
讀取佇列的訊息。在讀取訊息時需要指定消費者,只需要指定名字,不用預先建立。
語法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds]
[NOACK] STREAMS key [key ...] id [id ...]
- group:消費組名
- consumer:消費者名
- count:讀取數量
- BLOCK milliseconds:阻塞讀以及阻塞毫秒數。預設非阻塞。和XREAD類似
- key:佇列名
- id:訊息ID。ID可以填寫特殊符號
>,表示未被組內消費的起始訊息
命令使用:
建立消費者consumerA和consumerB,各讀取一條訊息
127.0.0.1:6379> XREADGROUP GROUP mqGroup consumerA COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1674984765438-0"
2) 1) "name"
2) "tom"
3) "age"
4) "22"
127.0.0.1:6379> XREADGROUP group mqGroup consumerB count 1 streams mystream >
1) 1) "mystream"
2) 1) 1) "1674985213802-0"
2) 1) "height"
2) "180"
3) "use"
4) "iphone"
可以進行組內消費的基本原理是,STREAM型別會為每個組記錄一個最後讀取的訊息ID(last_delivered_id),這樣在組內消費時,就可以從這個值後面開始讀取,保證不重複消費。
消費組消費時,還有一個必須要考慮的問題,就是若某個消費者,消費了某條訊息,但是並沒有處理成功時(例如消費者程序宕機),這條訊息可能會丟失,因為組內其他消費者不能再次消費到該訊息了
XPENDING
為了解決組內訊息讀取但處理期間消費者崩潰帶來的訊息丟失問題,Stream 設計了 Pending 列表,用於記錄讀取但並未確認完畢的訊息。
語法格式:
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
- key:佇列名
- group: 消費組名
- start:開始值,-表示最小值
- end:結束值,+表示最大值
- count:數量
命令使用:
首先檢視佇列中的訊息數量有3個,然後檢視已讀取未處理的訊息有兩個。
127.0.0.1:6379> xlen mystream
(integer) 3
127.0.0.1:6379> xpending mystream mqGroup
1) (integer) 2 # 2個已讀取但未處理的訊息
2) "1674984765438-0" # 起始ID
3) "1674985213802-0" # 結束ID
4) 1) 1) "consumerA" # 消費者A有1個
2) "1"
2) 1) "consumerB" # 消費者B有1個
2) "1"
佇列中一共三條資訊,有兩條被消費但未處理完畢,也就是上面XREADGROUP消費的兩條。一個是消費者consumerA,另一個是consumerB。
獲取未確認的詳細資訊
127.0.0.1:6379> xpending mystream mqGroup - + 10
1) 1) "1674984765438-0"
2) "consumerA"
3) (integer) 12110001
4) (integer) 1
2) 1) "1674985213802-0"
2) "consumerB"
3) (integer) 89140701
4) (integer) 1
XACK
對於已讀取未處理的訊息,使用命令 XACK 完成告知訊息處理完成
XACK 命令確認消費的資訊,一旦資訊被確認處理,就表示資訊被完善處理。
語法格式:
XACK key group id [id ...]
- key: stream 名
- group:消費組
- id:訊息ID
命令使用:
確認訊息1674985213802-0
127.0.0.1:6379> XACK mystream mqGroup 1674985213802-0
(integer) 1
127.0.0.1:6379>
XCLAIM
某個消費者讀取了訊息但沒有處理,這時消費者宕機或重啟等就會導致該訊息失蹤。那麼就需要該訊息轉移給其他的消費者處理,就是訊息轉移。XCLAIM來實現訊息轉移的操作。
語法格式:
XCLAIM key group consumer min-idle-time id [id ...] [IDLE ms]
[TIME unix-time-milliseconds] [RETRYCOUNT count] [FORCE] [JUSTID]
[LASTID id]
- key: 佇列名稱
- group :消費組
- consumer:消費組裡的消費者
- min-idle-time 最小時間。空閒時間大於min-idle-time的訊息才會被轉移成功
- id:訊息的ID
轉移除了要指定ID外,還需要指定min-idle-time,min-idle-time是最小空閒時間,該值要小於訊息的空閒時間,這個引數是為了保證是多於多長時間的訊息未處理的才被轉移。比如超過24小時的處於pending未xack的訊息要進行轉移
同時min-idle-time還有一個功能是能夠避免兩個消費者同時轉移一條訊息。被轉移的訊息的IDLE會被重置為0。假設兩個消費者都以2min來轉移,第一個成功之後IDLE被重置為0,第二個消費者就會因為min-idle-time大與空閒時間而是失敗。
命令使用:
目前未確認的訊息
127.0.0.1:6379> xpending mystream mqGroup - + 10
1) 1) "1674984765438-0"
2) "consumerA"
3) (integer) 12145595
4) (integer) 1
id: 1674984765438-0
空閒時間:12145595,單位ms
讀取次數:1
將cosumerA未處理的訊息轉移給consumerB。
127.0.0.1:6379> XCLAIM mystream mqGroup consumerB 3600000 1674984765438-0
1) 1) "1674984765438-0"
2) 1) "name"
2) "tom"
3) "age"
4) "22"
檢視未確認的訊息
訊息已經從consumerA轉移給consumerB,IDLE重置,讀取次數加1。轉移之後就可以繼續處理這條訊息。
127.0.0.1:6379> xpending mystream mqGroup - + 10
1) 1) "1674984765438-0"
2) "consumerB"
3) (integer) 5729 # 注意IDLE,被重置了
4) (integer) 2 # 注意,讀取次數也累加了1次
通常轉移操作的完整流程是:
- 先用xpending命令找出所有未確認的訊息
- 再用xclaim命令轉移所有未確認訊息
在redis6.2.0之後有一個命令XAUTOCLAIM,可以將xpending查詢未確認訊息和xclaim轉移訊息合併成一個操作。
XINFO
Stream提供了XINFO來實現對伺服器資訊的監控
檢視佇列資訊
127.0.0.1:6379> xinfo stream mystream
1) "length"
2) (integer) 3
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "groups"
8) (integer) 1
9) "last-generated-id"
10) "1674985995856-0"
11) "first-entry"
12) 1) "1674984765438-0"
2) 1) "name"
2) "tom"
3) "age"
4) "22"
13) "last-entry"
14) 1) "1674985995856-0"
2) 1) "name"
2) "jack"
消費組資訊
127.0.0.1:6379> xinfo groups mystream
1) 1) "name"
2) "mqGroup"
3) "consumers"
4) (integer) 2
5) "pending"
6) (integer) 1
7) "last-delivered-id"
8) "1674985213802-0"
消費者組成員資訊
127.0.0.1:6379> xinfo consumers mystream mqGroup
1) 1) "name"
2) "consumerA"
3) "pending"
4) (integer) 0
5) "idle"
6) (integer) 12904777
2) 1) "name"
2) "consumerB"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 696457
127.0.0.1:6379>
專案中中Stream的使用
專案中部分web請求的處理是非同步處理,web服務呼叫底層模組非同步執行。當底層模組處理完成後需要儲存結果並通知web服務,所以使用Stream作為儲存的載體。
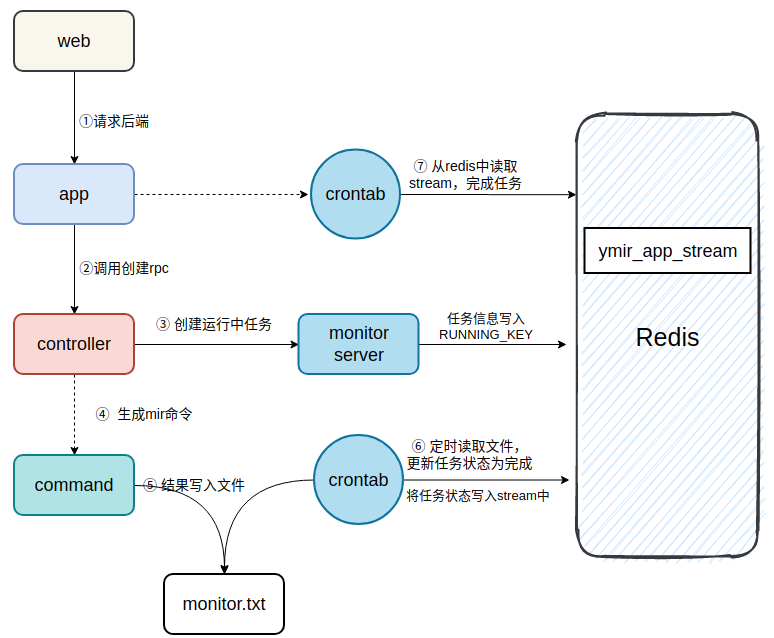
Stream 的生產和消費
生產
向佇列中寫訊息
def batch_xadd(self, name: str, payloads: List[Dict]) -> None:
pipe = self._redis.pipeline()
for payload in payloads:
pipe.xadd(name, payload)
pipe.execute()
消費
定時任務間隔10s從佇列中讀訊息
while True:
_, payloads = await self._conn.xautoclaim(
self.stream_name, self.group_name, self.consumer_name, min_idle_time
)
id_ = last_id if check_backlog else ">"
for _, messages in await self._conn.xreadgroup(
groupname=self.group_name,
consumername=self.consumer_name,
streams={self.stream_name: id_},
block=block_timeout,
):
...
last_id = messages[-1][0]
payloads += messages
# 處理佇列中取出的訊息,耗時操作
successful_ids = await f_processor(payloads)
if successful_ids:
await self._conn.xack(self.stream_name, self.group_name, *successful_ids)
Stream和專業訊息佇列對比
專業的訊息佇列包括:
- RabbitMQ
- RocketMQ
- Kafka
一個專業的訊息佇列,必須要滿足兩個條件:
- 訊息不丟
- 訊息可堆積
下面從這兩個方面來對比Stream和專業訊息佇列。
訊息不丟
訊息佇列的使用模型如下:

要保證訊息不丟,就需要在生產者、中介軟體、消費者這三個方面來分析。
生產者:訊息傳送失敗或傳送超時,這兩種情況會導致資料丟失,可以使用重試來解決。不依賴訊息中介軟體,需要業務實現。
消費者:消費者存在讀取訊息未處理完就異常宕機了,消費者要還能重新讀取訊息。Stream和其他訊息中介軟體都能做到。
佇列中介軟體:中介軟體要保證資料不丟失。 Redis 在以下 2 個場景下,都會導致資料丟失:
- AOF 持久化設定為每秒寫盤,Redis 宕機時會存在丟失最後1秒資料的可能
- 主從複製的叢集,主從切換時,從庫還未同步完成主庫發來的資料,就被提成主庫,也存在丟失資料的可能。
基於以上原因可以推斷出,Redis 本身的無法保證嚴格的資料完整性。
專業佇列如何解決資料丟失問題:
RabbitMQ 或 Kafka 這類專業的佇列中介軟體,在使用時一般是部署一個叢集。生產者在釋出訊息時,佇列中介軟體通常會寫「多個節點」,以此保證訊息冗餘。這樣一來,即便其中一個節點掛了,叢集也能的資料不丟失。
訊息積壓
因為 Redis 的資料都儲存在記憶體中,這就意味著一旦發生訊息積壓,則會導致 Redis 的記憶體持續增長,如果超過機器記憶體上限,就會面臨 OOM 的風險。
所以,Redis 的 Stream 提供了可以指定佇列最大長度的功能,就是為了避免這種情況發生。
但 Kafka、RabbitMQ 這類訊息佇列就不一樣了,它們的資料都會儲存在磁碟上,磁碟的成本要比記憶體小得多,當訊息積壓時,無非就是多佔用一些磁碟空間,磁碟相比於記憶體在面對積壓時能輕鬆應對。
總結
綜上可以看到,把 Redis 當作佇列來使用時,始終面臨兩個問題:
- Redis 本身可能會丟資料
- 面對訊息積壓,Redis 記憶體資源緊張
優缺點
優點:
- 使用成本低。幾乎每一個專案都會使用Redis,用Stream做訊息佇列就不需要額外再引入中介軟體,減少系統複雜性,運維成本,硬體資源。
缺點:
- Redis 的資料都儲存在記憶體中,記憶體持續增長超過機器記憶體上限,就會面臨 OOM 的風險
- Stream 作為Redis的一種資料結構,Redis 在持久化或主從切換時有丟失資料的風險,所以Stream也有丟失訊息的風險
- 所有的訊息會一直儲存在Stream中,沒有刪除機制。要麼定時清除,那麼設定佇列的長度自動丟棄先入列訊息
使用場景
適用
適用業務場景:
- 場景足夠簡單
- 對於資料丟失不敏感
- 訊息積壓概率比較小
滿足以上場景把 Redis 當作佇列是完全可以的。
基於redis的高效能和使用記憶體的機制使得其的效能優於大部分訊息佇列。在小規模場景會有更出色的表現。
不適用
不適用業務場景:
- 對於資料丟失非常敏感,如訂單系統
- 寫入量非常大,並行請求大
- 訊息積壓時會佔用很多的記憶體資源,訊息資料量大
這些業務場景下建議使用專業的訊息佇列中介軟體。
題外話
技術選型出了技術本身之外還要考慮公司團隊能否匹配技術。
Kafka、RabbitMQ 是非常專業的訊息中介軟體,但它們的部署和運維,相比於 Redis 來說,也會更復雜一些。
如果在一個大公司,公司本身就有優秀的運維團隊,那麼使用這些中介軟體肯定沒問題,因為有足夠優秀的人能 hold 住這些中介軟體,公司也會投入人力和時間在這個方向上。
但是在一個初創公司,業務正處在快速發展期,暫時沒有能 hold 住這些中介軟體的團隊和人,如果貿然使用這些元件,當發生故障時,排查問題也會變得很困難,甚至會阻礙業務的發展。
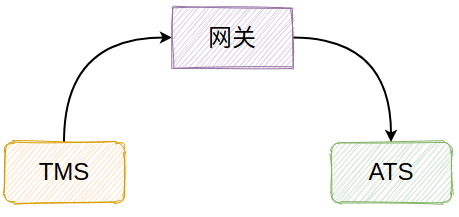
實際案例討論
同一個大型專案中子專案的互相呼叫。TMS呼叫ATS獲取資料集
改用Stream完成
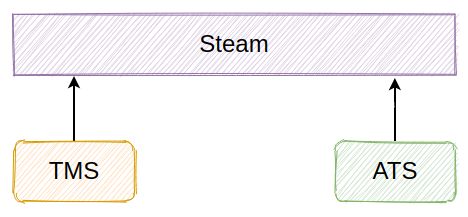
理由:
- 丟失資料不敏感
- 業務場景簡單
- 訊息積壓概率比較小
參考:
https://zhuanlan.zhihu.com/p/60501638
https://redis.io/commands/xclaim/
https://liziba.blog.csdn.net/article/details/120320018
https://juejin.cn/post/6962423461071290375
準備連載一系列關於python非同步程式設計的文章。包括同非同步框架效能對比、非同步事情驅動原理等。首發微信公眾號,歡迎關注第一時間閱讀。
